
NSCC Concepts of Biology BIOL 1046 & 1047 by Charles Molnar, Jane Gair, Jung Choi, Mary Ann Clark, and Matthew Douglas is licensed under a Creative Commons Attribution 4.0 International License, except where otherwise noted.
NSCC Concepts of Biology BIOL 1046 & 1047 by Charles Molnar, Jane Gair, Jung Choi, Mary Ann Clark, and Matthew Douglas is licensed under a Creative Commons Attribution 4.0 International License, except where otherwise noted.
Welcome to Concepts of Biology, an OpenStax College resource. This textbook has been created with several goals in mind: accessibility, customization, and student engagement—all while encouraging students toward high levels of academic scholarship. Instructors and students alike will find that this textbook offers a strong introduction to biology in an accessible format.
OpenStax College is a non-profit organization committed to improving student access to quality learning materials. Our free textbooks are developed and peer-reviewed by educators to ensure they are readable, accurate, and meet the scope and sequence requirements of today’s college courses. Unlike traditional textbooks, OpenStax College resources live online and are owned by the community of educators using them. Through our partnerships with companies and foundations committed to reducing costs for students, OpenStax College is working to improve access to higher education for all. OpenStax College is an initiative of Rice University and is made possible through the generous support of several philanthropic foundations.
OpenStax College resources provide quality academic instruction. Three key features set our materials apart from others: they can be customized by instructors for each class, they are a “living” resource that grows online through contributions from science educators, and they are available free or for minimal cost.
OpenStax College learning resources are designed to be customized for each course. Our textbooks provide a solid foundation on which instructors can build, and our resources are conceived and written with flexibility in mind. Instructors can select the sections most relevant to their curricula and create a textbook that speaks directly to the needs of their classes and student body. Teachers are encouraged to expand on existing examples by adding unique context via geographically localized applications and topical connections.
Concepts of Biology can be easily customized using our online platform. Simply select the content most relevant to your syllabus and create a textbook that speaks directly to the needs of your class. Concepts of Biology is organized as a collection of sections that can be rearranged, modified, and enhanced through localized examples or to incorporate a specific theme of your course. This customization feature will help bring biology to life for your students and will ensure that your textbook truly reflects the goals of your course.
To broaden access and encourage community curation, Concepts of Biology is “open source” licensed under a Creative Commons Attribution (CC-BY) license. The scientific community is invited to submit examples, emerging research, and other feedback to enhance and strengthen the material and keep it current and relevant for today’s students. Submit your suggestions to info@openstaxcollege.org, and check in on edition status, alternate versions, errata, and news on the StaxDash at http://openstaxcollege.org.
Our textbooks are available for free online, and in low-cost print and e-book editions.
Concepts of Biology is designed for the single-semester introduction to biology course for non-science majors, which for many students is their only college-level science course. As such, this course represents an important opportunity for students to develop the necessary knowledge, tools, and skills to make informed decisions as they continue with their lives. Rather than being mired down with facts and vocabulary, the typical non-science major student needs information presented in a way that is easy to read and understand. Even more importantly, the content should be meaningful. Students do much better when they understand why biology is relevant to their everyday lives. For these reasons, Concepts of Biology is grounded on an evolutionary basis and includes exciting features that highlight careers in the biological sciences and everyday applications of the concepts at hand. We also strive to show the interconnectedness of topics within this extremely broad discipline. In order to meet the needs of today’s instructors and students, we maintain the overall organization and coverage found in most syllabi for this course. A strength of Concepts of Biology is that instructors can customize the book, adapting it to the approach that works best in their classroom. Concepts of Biology also includes an innovative art program that incorporates critical thinking and clicker questions to help students understand—and apply—key concepts.
Our Concepts of Biology textbook adheres to the scope and sequence of most one-semester non-majors courses nationwide. We also strive to make biology, as a discipline, interesting and accessible to students. In addition to a comprehensive coverage of core concepts and foundational research, we have incorporated features that draw learners into the discipline in meaningful ways. Our scope of content was developed after surveying over a hundred biology professors and listening to their coverage needs. We provide a thorough treatment of biology’s fundamental concepts with a scope that is manageable for instructors and students alike.
Because of the impact science has on students and society, an important goal of science education is to achieve a scientifically literate population that consistently makes informed decisions. Scientific literacy transcends a basic understanding of scientific principles and processes to include the ability to make sense of the myriad instances where people encounter science in day-to-day life. Thus, a scientifically literate person is one who uses science content knowledge to make informed decisions, either personally or socially, about topics or issues that have a connection with science. Concepts of Biology is grounded on a solid scientific base and designed to promote scientific literacy. Throughout the text, you will find features that engage the students in scientific inquiry by taking selected topics a step further.
Our art program takes a straightforward approach designed to help students learn the concepts of biology through simple, effective illustrations, photos, and micrographs. Concepts of Biology also incorporates links to relevant animations and interactive exercises that help bring biology to life for students.
Concepts of Biology would not be possible if not for the tremendous contributions of the authors and community reviewing team
Preface to the 1st Canadian Edition, by Charles Molnar and Jane Gair, adapters of Concepts of Biology
In this survey text, directed at those not majoring in biology, we dispel the assumption that a little learning is a dangerous thing. We hope that by skimming the surface of a very deep subject, biology, we may inspire you to drink more deeply and make more informed choices relating to your health, the environment, politics, and the greatest subject that all of us are entwined in, life itself.
In the adapted textbook, Concepts of Biology — 1st Canadian Edition, you will find the following units:
Adaptations to the original textbook Concepts of Biology by OpenStax College include:
Thanks to BCcampus and Camosun College for funding and support. We are most grateful to the Let’s Talk Science organization from their trove of science links.

Viewed from space, Earth offers few clues about the diversity of life forms that reside there. The first forms of life on Earth are thought to have been microorganisms that existed for billions of years before plants and animals appeared. The mammals, birds, and flowers so familiar to us are all relatively recent, originating 130 to 200 million years ago. Humans have inhabited this planet for only the last 2.5 million years, and only in the last 200,000 years have humans started looking like we do today.
The goal of interactive learning is to promote engagement with and retention of the concepts and information being studied. The interactive learning activities in this open textbook support self directed practice and are not recorded assessments. Use the interactive learning activities to:
Watch an introduction to interactive videos
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=23#h5p-1
Get to know your open textbook.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=23#h5p-2
By the end of this section, you will be able to:
Watch a video about Evolution by Natural Selection.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=39#h5p-3
Biology is the science that studies life. What exactly is life? This may sound like a silly question with an obvious answer, but it is not easy to define life. For example, a branch of biology called virology studies viruses, which exhibit some of the characteristics of living entities but lack others. It turns out that although viruses can attack living organisms, cause diseases, and even reproduce, they do not meet the criteria that biologists use to define life.
From its earliest beginnings, biology has wrestled with four questions: What are the shared properties that make something “alive”? How do those various living things function? When faced with the remarkable diversity of life, how do we organize the different kinds of organisms so that we can better understand them? And, finally—what biologists ultimately seek to understand—how did this diversity arise and how is it continuing? As new organisms are discovered every day, biologists continue to seek answers to these and other questions.
All groups of living organisms share multiple key characteristics or functions: order, sensitivity or response to stimuli, reproduction, adaptation, growth and development, regulation, homeostasis, and energy processing. When viewed together, these eight characteristics serve to define life.
Organisms are highly organized structures that consist of one or more cells. Even very simple, single-celled organisms are remarkably complex. Inside each cell, atoms make up molecules. These in turn make up cell components or organelles. Multicellular organisms, which may consist of millions of individual cells, have an advantage over single-celled organisms in that their cells can be specialized to perform specific functions, and even sacrificed in certain situations for the good of the organism as a whole. How these specialized cells come together to form organs such as the heart, lung, or skin in organisms like the toad shown in Figure 1. 2 will be discussed later.

Organisms respond to diverse stimuli. For example, plants can bend toward a source of light or respond to touch. Even tiny bacteria can move toward or away from chemicals (a process called chemotaxis) or light (phototaxis). Movement toward a stimulus is considered a positive response, while movement away from a stimulus is considered a negative response.

Single-celled organisms reproduce by first duplicating their DNA, which is the genetic material, and then dividing it equally as the cell prepares to divide to form two new cells. Many multicellular organisms (those made up of more than one cell) produce specialized reproductive cells that will form new individuals. When reproduction occurs, DNA containing genes is passed along to an organism’s offspring. These genes are the reason that the offspring will belong to the same species and will have characteristics similar to the parent, such as fur color and blood type.
All living organisms exhibit a “fit” to their environment. Biologists refer to this fit as adaptation and it is a consequence of evolution by natural selection, which operates in every lineage of reproducing organisms. Examples of adaptations are diverse and unique, from heat-resistant Archaea that live in boiling hot springs to the tongue length of a nectar-feeding moth that matches the size of the flower from which it feeds. All adaptations enhance the reproductive potential of the individual exhibiting them, including their ability to survive to reproduce. Adaptations are not constant. As an environment changes, natural selection causes the characteristics of the individuals in a population to track those changes.
Organisms grow and develop according to specific instructions coded for by their genes. These genes provide instructions that will direct cellular growth and development, ensuring that a species’ young will grow up to exhibit many of the same characteristics as its parents.

Even the smallest organisms are complex and require multiple regulatory mechanisms to coordinate internal functions, such as the transport of nutrients, response to stimuli, and coping with environmental stresses. For example, organ systems such as the digestive or circulatory systems perform specific functions like carrying oxygen throughout the body, removing wastes, delivering nutrients to every cell, and cooling the body.
To function properly, cells require appropriate conditions such as proper temperature, pH, and concentrations of diverse chemicals. These conditions may, however, change from one moment to the next. Organisms are able to maintain internal conditions within a narrow range almost constantly, despite environmental changes, through a process called homeostasis or “steady state”—the ability of an organism to maintain constant internal conditions. For example, many organisms regulate their body temperature in a process known as thermoregulation. Organisms that live in cold climates, such as the polar bear, have body structures that help them withstand low temperatures and conserve body heat. In hot climates, organisms have methods (such as perspiration in humans or panting in dogs) that help them to shed excess body heat.

All organisms (such as the California condor shown in Figure 1.6) use a source of energy for their metabolic activities. Some organisms capture energy from the sun and convert it into chemical energy in food; others use chemical energy from molecules they take in.

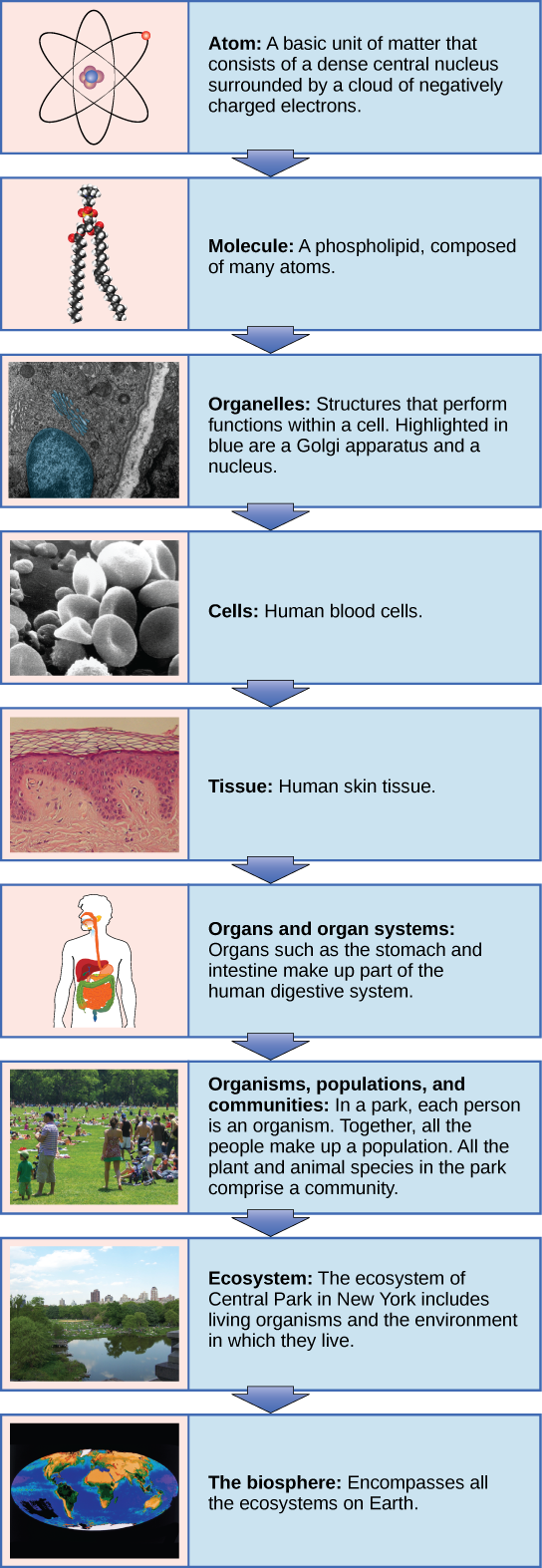
Living things are highly organized and structured, following a hierarchy on a scale from small to large. The atom is the smallest and most fundamental unit of matter. It consists of a nucleus surrounded by electrons. Atoms form molecules. A molecule is a chemical structure consisting of at least two atoms held together by a chemical bond. Many molecules that are biologically important are macromolecules, large molecules that are typically formed by combining smaller units called monomers. An example of a macromolecule is deoxyribonucleic acid (DNA), which contains the instructions for the functioning of the organism that contains it.
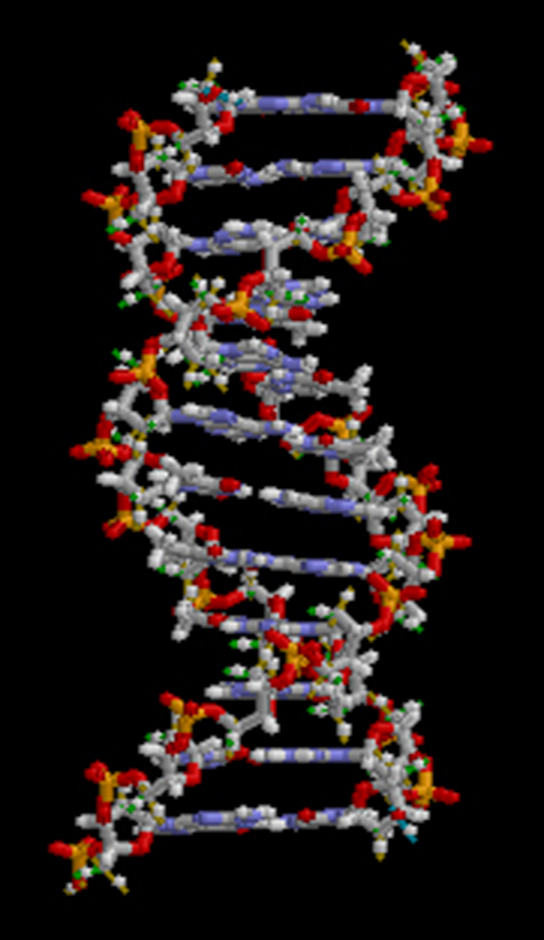
Some cells contain aggregates of macromolecules surrounded by membranes; these are called organelles. Organelles are small structures that exist within cells and perform specialized functions. All living things are made of cells; the cell itself is the smallest fundamental unit of structure and function in living organisms. (This requirement is why viruses are not considered living: they are not made of cells. To make new viruses, they have to invade and hijack a living cell; only then can they obtain the materials they need to reproduce.) Some organisms consist of a single cell and others are multicellular. Cells are classified as prokaryotic or eukaryotic. Prokaryotes are single-celled organisms that lack organelles surrounded by a membrane and do not have nuclei surrounded by nuclear membranes; in contrast, the cells of eukaryotes do have membrane-bound organelles and nuclei.
In most multicellular organisms, cells combine to make tissues, which are groups of similar cells carrying out the same function. Organs are collections of tissues grouped together based on a common function. Organs are present not only in animals but also in plants. An organ system is a higher level of organization that consists of functionally related organs. For example vertebrate animals have many organ systems, such as the circulatory system that transports blood throughout the body and to and from the lungs; it includes organs such as the heart and blood vessels. Organisms are individual living entities. For example, each tree in a forest is an organism. Single-celled prokaryotes and single-celled eukaryotes are also considered organisms and are typically referred to as microorganisms.
Which of the following statements is false?
All the individuals of a species living within a specific area are collectively called a population. For example, a forest may include many white pine trees. All of these pine trees represent the population of white pine trees in this forest. Different populations may live in the same specific area. For example, the forest with the pine trees includes populations of flowering plants and also insects and microbial populations. A community is the set of populations inhabiting a particular area. For instance, all of the trees, flowers, insects, and other populations in a forest form the forest’s community. The forest itself is an ecosystem. An ecosystem consists of all the living things in a particular area together with the abiotic, or non-living, parts of that environment such as nitrogen in the soil or rainwater. At the highest level of organization, the biosphere is the collection of all ecosystems, and it represents the zones of life on Earth. It includes land, water, and portions of the atmosphere.
The science of biology is very broad in scope because there is a tremendous diversity of life on Earth. The source of this diversity is evolution, the process of gradual change during which new species arise from older species. Evolutionary biologists study the evolution of living things in everything from the microscopic world to ecosystems.
In the 18th century, a scientist named Carl Linnaeus first proposed organizing the known species of organisms into a hierarchical taxonomy. In this system, species that are most similar to each other are put together within a grouping known as a genus. Furthermore, similar genera (the plural of genus) are put together within a family. This grouping continues until all organisms are collected together into groups at the highest level. The current taxonomic system now has eight levels in its hierarchy, from lowest to highest, they are: species, genus, family, order, class, phylum, kingdom, and domain. Thus species are grouped within genera, genera are grouped within families, families are grouped within orders, and so on.
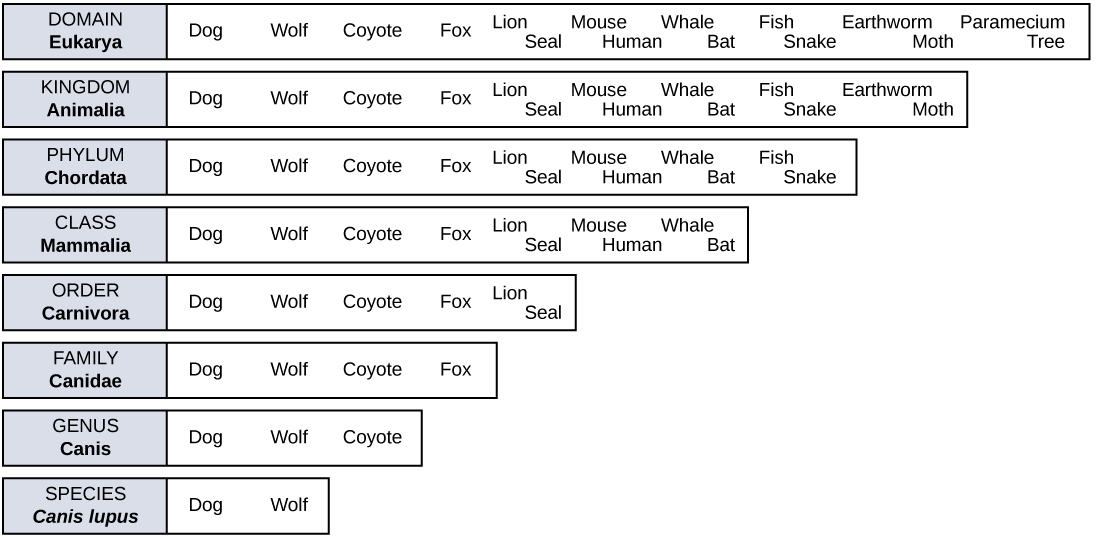
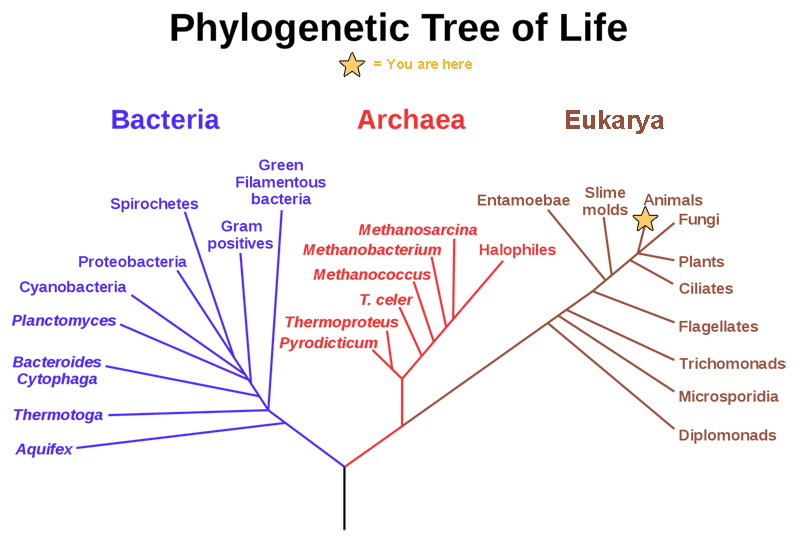
The highest level, domain, is a relatively new addition to the system since the 1990s. Scientists now recognize three domains of life, the Eukarya, the Archaea, and the Bacteria. The domain Eukarya contains organisms that have cells with nuclei. It includes the kingdoms of fungi, plants, animals, and several kingdoms of protists. The Archaea, are single-celled organisms without nuclei and include many extremophiles that live in harsh environments like hot springs. The Bacteria are another quite different group of single-celled organisms without nuclei. Both the Archaea and the Bacteria are prokaryotes, an informal name for cells without nuclei. The recognition in the 1990s that certain “bacteria,” now known as the Archaea, were as different genetically and biochemically from other bacterial cells as they were from eukaryotes, motivated the recommendation to divide life into three domains. This dramatic change in our knowledge of the tree of life demonstrates that classifications are not permanent and will change when new information becomes available.
In addition to the hierarchical taxonomic system, Linnaeus was the first to name organisms using two unique names, now called the binomial naming system. Before Linnaeus, the use of common names to refer to organisms caused confusion because there were regional differences in these common names. Binomial names consist of the genus name (which is capitalized) and the species name (all lower-case). Both names are set in italics when they are printed. Every species is given a unique binomial which is recognized the world over, so that a scientist in any location can know which organism is being referred to. For example, the North American blue jay is known uniquely as Cyanocitta cristata. Our own species is Homo sapiens.

Carl Woese and the Phylogenetic Tree
The evolutionary relationships of various life forms on Earth can be summarized in a phylogenetic tree. A phylogenetic tree is a diagram showing the evolutionary relationships among biological species based on similarities and differences in genetic or physical traits or both. A phylogenetic tree is composed of branch points, or nodes, and branches. The internal nodes represent ancestors and are points in evolution when, based on scientific evidence, an ancestor is thought to have diverged to form two new species. The length of each branch can be considered as estimates of relative time.
In the past, biologists grouped living organisms into five kingdoms: animals, plants, fungi, protists, and bacteria. The pioneering work of American microbiologist Carl Woese in the early 1970s has shown, however, that life on Earth has evolved along three lineages, now called domains—Bacteria, Archaea, and Eukarya. Woese proposed the domain as a new taxonomic level and Archaea as a new domain, to reflect the new phylogenetic tree. Many organisms belonging to the Archaea domain live under extreme conditions and are called extremophiles. To construct his tree, Woese used genetic relationships rather than similarities based on morphology (shape). Various genes were used in phylogenetic studies. Woese’s tree was constructed from comparative sequencing of the genes that are universally distributed, found in some slightly altered form in every organism, conserved (meaning that these genes have remained only slightly changed throughout evolution), and of an appropriate length.
Watch a video about Science and Medicine
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=39#h5p-4
The scope of biology is broad and therefore contains many branches and sub disciplines. Biologists may pursue one of those sub disciplines and work in a more focused field. For instance, molecular biology studies biological processes at the molecular level, including interactions among molecules such as DNA, RNA, and proteins, as well as the way they are regulated. Microbiology is the study of the structure and function of microorganisms. It is quite a broad branch itself, and depending on the subject of study, there are also microbial physiologists, ecologists, and geneticists, among others.
Another field of biological study, neurobiology, studies the biology of the nervous system, and although it is considered a branch of biology, it is also recognized as an interdisciplinary field of study known as neuroscience. Because of its interdisciplinary nature, this sub discipline studies different functions of the nervous system using molecular, cellular, developmental, medical, and computational approaches.

Paleontology, another branch of biology, uses fossils to study life’s history. Zoology and botany are the study of animals and plants, respectively. Biologists can also specialize as biotechnologists, ecologists, or physiologists, to name just a few areas. Biotechnologists apply the knowledge of biology to create useful products. Ecologists study the interactions of organisms in their environments. Physiologists study the workings of cells, tissues and organs. This is just a small sample of the many fields that biologists can pursue. From our own bodies to the world we live in, discoveries in biology can affect us in very direct and important ways. We depend on these discoveries for our health, our food sources, and the benefits provided by our ecosystem. Because of this, knowledge of biology can benefit us in making decisions in our day-to-day lives.
The development of technology in the twentieth century that continues today, particularly the technology to describe and manipulate the genetic material, DNA, has transformed biology. This transformation will allow biologists to continue to understand the history of life in greater detail, how the human body works, our human origins, and how humans can survive as a species on this planet despite the stresses caused by our increasing numbers. Biologists continue to decipher huge mysteries about life suggesting that we have only begun to understand life on the planet, its history, and our relationship to it. For this and other reasons, the knowledge of biology gained through this textbook and other printed and electronic media should be a benefit in whichever field you enter.
Forensic science is the application of science to answer questions related to the law. Biologists as well as chemists and biochemists can be forensic scientists. Forensic scientists provide scientific evidence for use in courts, and their job involves examining trace material associated with crimes. Interest in forensic science has increased in the last few years, possibly because of popular television shows that feature forensic scientists on the job. Also, the development of molecular techniques and the establishment of DNA databases have updated the types of work that forensic scientists can do. Their job activities are primarily related to crimes against people such as murder, rape, and assault. Their work involves analyzing samples such as hair, blood, and other body fluids and also processing DNA found in many different environments and materials. Forensic scientists also analyze other biological evidence left at crime scenes, such as insect parts or pollen grains. Students who want to pursue careers in forensic science will most likely be required to take chemistry and biology courses as well as some intensive math courses.

Biology is the science of life. All living organisms share several key properties such as order, sensitivity or response to stimuli, reproduction, adaptation, growth and development, regulation, homeostasis, and energy processing. Living things are highly organized following a hierarchy that includes atoms, molecules, organelles, cells, tissues, organs, and organ systems. Organisms, in turn, are grouped as populations, communities, ecosystems, and the biosphere. Evolution is the source of the tremendous biological diversity on Earth today. A diagram called a phylogenetic tree can be used to show evolutionary relationships among organisms. Biology is very broad and includes many branches and sub disciplines. Examples include molecular biology, microbiology, neurobiology, zoology, and botany, among others.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=39#h5p-5
atom: a basic unit of matter that cannot be broken down by normal chemical reactions
biology: the study of living organisms and their interactions with one another and their environments
biosphere: a collection of all ecosystems on Earth
cell: the smallest fundamental unit of structure and function in living things
community: a set of populations inhabiting a particular area
ecosystem: all living things in a particular area together with the abiotic, nonliving parts of that environment
eukaryote: an organism with cells that have nuclei and membrane-bound organelles
evolution: the process of gradual change in a population that can also lead to new species arising from older species
homeostasis: the ability of an organism to maintain constant internal conditions
macromolecule: a large molecule typically formed by the joining of smaller molecules
molecule: a chemical structure consisting of at least two atoms held together by a chemical bond
organ: a structure formed of tissues operating together to perform a common function
organ system: the higher level of organization that consists of functionally related organs
organelle: a membrane-bound compartment or sac within a cell
organism: an individual living entity
phylogenetic tree: a diagram showing the evolutionary relationships among biological species based on similarities and differences in genetic or physical traits or both
population: all individuals within a species living within a specific area
prokaryote: a unicellular organism that lacks a nucleus or any other membrane-bound organelle
tissue: a group of similar cells carrying out the same function
By the end of this section, you will be able to:
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=47#h5p-6

Like geology, physics, and chemistry, biology is a science that gathers knowledge about the natural world. Specifically, biology is the study of life. The discoveries of biology are made by a community of researchers who work individually and together using agreed-on methods. In this sense, biology, like all sciences is a social enterprise like politics or the arts. The methods of science include careful observation, record keeping, logical and mathematical reasoning, experimentation, and submitting conclusions to the scrutiny of others. Science also requires considerable imagination and creativity; a well-designed experiment is commonly described as elegant, or beautiful. Like politics, science has considerable practical implications and some science is dedicated to practical applications, such as the prevention of disease. Other science proceeds largely motivated by curiosity. Whatever its goal, there is no doubt that science, including biology, has transformed human existence and will continue to do so.
Watch a video about the reductional approach of western science.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=47#h5p-7
Biology is a science, but what exactly is science? What does the study of biology share with other scientific disciplines? Science (from the Latin scientia, meaning “knowledge”) can be defined as knowledge about the natural world.
Science is a very specific way of learning, or knowing, about the world. The history of the past 500 years demonstrates that science is a very powerful way of knowing about the world; it is largely responsible for the technological revolutions that have taken place during this time. There are however, areas of knowledge and human experience that the methods of science cannot be applied to. These include such things as answering purely moral questions, aesthetic questions, or what can be generally categorized as spiritual questions. Science has cannot investigate these areas because they are outside the realm of material phenomena, the phenomena of matter and energy, and cannot be observed and measured.
The scientific method is a method of research with defined steps that include experiments and careful observation. The steps of the scientific method will be examined in detail later, but one of the most important aspects of this method is the testing of hypotheses. A hypothesis is a suggested explanation for an event, which can be tested. Hypotheses, or tentative explanations, are generally produced within the context of a scientific theory. A scientific theory is a generally accepted, thoroughly tested and confirmed explanation for a set of observations or phenomena. Scientific theory is the foundation of scientific knowledge. In addition, in many scientific disciplines (less so in biology) there are scientific laws, often expressed in mathematical formulas, which describe how elements of nature will behave under certain specific conditions. There is not an evolution of hypotheses through theories to laws as if they represented some increase in certainty about the world. Hypotheses are the day-to-day material that scientists work with and they are developed within the context of theories. Laws are concise descriptions of parts of the world that are amenable to formulaic or mathematical description.
What would you expect to see in a museum of natural sciences? Frogs? Plants? Dinosaur skeletons? Exhibits about how the brain functions? A planetarium? Gems and minerals? Or maybe all of the above? Science includes such diverse fields as astronomy, biology, computer sciences, geology, logic, physics, chemistry, and mathematics. However, those fields of science related to the physical world and its phenomena and processes are considered natural sciences. Thus, a museum of natural sciences might contain any of the items listed above.
There is no complete agreement when it comes to defining what the natural sciences include. For some experts, the natural sciences are astronomy, biology, chemistry, earth science, and physics. Other scholars choose to divide natural sciences into life sciences, which study living things and include biology, and physical sciences, which study nonliving matter and include astronomy, physics, and chemistry. Some disciplines such as biophysics and biochemistry build on two sciences and are interdisciplinary.
One thing is common to all forms of science: an ultimate goal “to know.” Curiosity and inquiry are the driving forces for the development of science. Scientists seek to understand the world and the way it operates. Two methods of logical thinking are used: inductive reasoning and deductive reasoning.
Inductive reasoning is a form of logical thinking that uses related observations to arrive at a general conclusion. This type of reasoning is common in descriptive science. A life scientist such as a biologist makes observations and records them. These data can be qualitative (descriptive) or quantitative (consisting of numbers), and the raw data can be supplemented with drawings, pictures, photos, or videos. From many observations, the scientist can infer conclusions (inductions) based on evidence. Inductive reasoning involves formulating generalizations inferred from careful observation and the analysis of a large amount of data. Brain studies often work this way. Many brains are observed while people are doing a task. The part of the brain that lights up, indicating activity, is then demonstrated to be the part controlling the response to that task.
Deductive reasoning or deduction is the type of logic used in hypothesis-based science. In deductive reasoning, the pattern of thinking moves in the opposite direction as compared to inductive reasoning. Deductive reasoning is a form of logical thinking that uses a general principle or law to forecast specific results. From those general principles, a scientist can extrapolate and predict the specific results that would be valid as long as the general principles are valid. For example, a prediction would be that if the climate is becoming warmer in a region, the distribution of plants and animals should change. Comparisons have been made between distributions in the past and the present, and the many changes that have been found are consistent with a warming climate. Finding the change in distribution is evidence that the climate change conclusion is a valid one.
Both types of logical thinking are related to the two main pathways of scientific study: descriptive science and hypothesis-based science. Descriptive (or discovery) science aims to observe, explore, and discover, while hypothesis-based science begins with a specific question or problem and a potential answer or solution that can be tested. The boundary between these two forms of study is often blurred, because most scientific endeavors combine both approaches. Observations lead to questions, questions lead to forming a hypothesis as a possible answer to those questions, and then the hypothesis is tested. Thus, descriptive science and hypothesis-based science are in continuous dialogue.
Biologists study the living world by posing questions about it and seeking science-based responses. This approach is common to other sciences as well and is often referred to as the scientific method. The scientific method was used even in ancient times, but it was first documented by England’s Sir Francis Bacon (1561–1626), who set up inductive methods for scientific inquiry. The scientific method is not exclusively used by biologists but can be applied to almost anything as a logical problem-solving method.

The scientific process typically starts with an observation (often a problem to be solved) that leads to a question. Let’s think about a simple problem that starts with an observation and apply the scientific method to solve the problem. One Monday morning, a student arrives at class and quickly discovers that the classroom is too warm. That is an observation that also describes a problem: the classroom is too warm. The student then asks a question: “Why is the classroom so warm?”
Recall that a hypothesis is a suggested explanation that can be tested. To solve a problem, several hypotheses may be proposed. For example, one hypothesis might be, “The classroom is warm because no one turned on the air conditioning.” But there could be other responses to the question, and therefore other hypotheses may be proposed. A second hypothesis might be, “The classroom is warm because there is a power failure, and so the air conditioning doesn’t work.”
Once a hypothesis has been selected, a prediction may be made. A prediction is similar to a hypothesis but it typically has the format “If . . . then . . . .” For example, the prediction for the first hypothesis might be, “If the student turns on the air conditioning, then the classroom will no longer be too warm.”
A hypothesis must be testable to ensure that it is valid. For example, a hypothesis that depends on what a bear thinks is not testable, because it can never be known what a bear thinks. It should also be falsifiable, meaning that it can be disproven by experimental results. An example of an unfalsifiable hypothesis is “Botticelli’s Birth of Venus is beautiful.” There is no experiment that might show this statement to be false. To test a hypothesis, a researcher will conduct one or more experiments designed to eliminate one or more of the hypotheses. This is important. A hypothesis can be disproven, or eliminated, but it can never be proven. Science does not deal in proofs like mathematics. If an experiment fails to disprove a hypothesis, then we find support for that explanation, but this is not to say that down the road a better explanation will not be found, or a more carefully designed experiment will be found to falsify the hypothesis.
Each experiment will have one or more variables and one or more controls. A variable is any part of the experiment that can vary or change during the experiment. A control is a part of the experiment that does not change. Look for the variables and controls in the example that follows. As a simple example, an experiment might be conducted to test the hypothesis that phosphate limits the growth of algae in freshwater ponds. A series of artificial ponds are filled with water and half of them are treated by adding phosphate each week, while the other half are treated by adding a salt that is known not to be used by algae. The variable here is the phosphate (or lack of phosphate), the experimental or treatment cases are the ponds with added phosphate and the control ponds are those with something inert added, such as the salt. Just adding something is also a control against the possibility that adding extra matter to the pond has an effect. If the treated ponds show lesser growth of algae, then we have found support for our hypothesis. If they do not, then we reject our hypothesis. Be aware that rejecting one hypothesis does not determine whether or not the other hypotheses can be accepted; it simply eliminates one hypothesis that is not valid . Using the scientific method, the hypotheses that are inconsistent with experimental data are rejected.
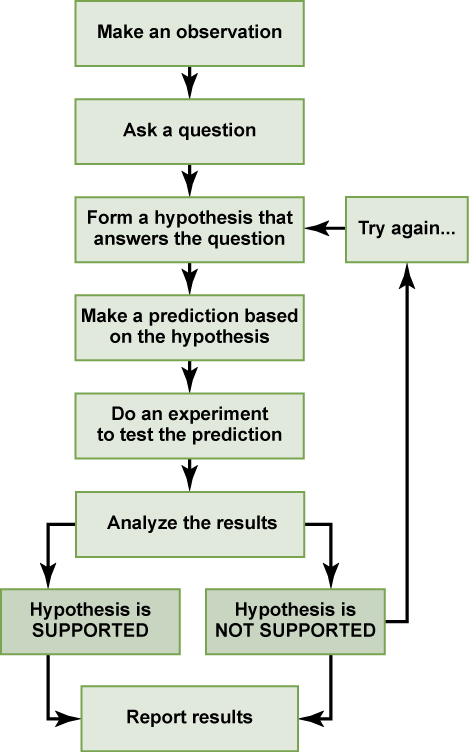
In the example below, the scientific method is used to solve an everyday problem. Which part in the example below is the hypothesis? Which is the prediction? Based on the results of the experiment, is the hypothesis supported? If it is not supported, propose some alternative hypotheses.
In practice, the scientific method is not as rigid and structured as it might at first appear. Sometimes an experiment leads to conclusions that favour a change in approach; often, an experiment brings entirely new scientific questions to the puzzle. Many times, science does not operate in a linear fashion; instead, scientists continually draw inferences and make generalizations, finding patterns as their research proceeds. Scientific reasoning is more complex than the scientific method alone suggests.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=47#h5p-4
The scientific community has been debating for the last few decades about the value of different types of science. Is it valuable to pursue science for the sake of simply gaining knowledge, or does scientific knowledge only have worth if we can apply it to solving a specific problem or bettering our lives? This question focuses on the differences between two types of science: basic science and applied science.
Basic science or “pure” science seeks to expand knowledge regardless of the short-term application of that knowledge. It is not focused on developing a product or a service of immediate public or commercial value. The immediate goal of basic science is knowledge for knowledge’s sake, though this does not mean that in the end it may not result in an application.
In contrast, applied science or “technology,” aims to use science to solve real-world problems, making it possible, for example, to improve a crop yield, find a cure for a particular disease, or save animals threatened by a natural disaster. In applied science, the problem is usually defined for the researcher.
Some individuals may perceive applied science as “useful” and basic science as “useless.” A question these people might pose to a scientist advocating knowledge acquisition would be, “What for?” A careful look at the history of science, however, reveals that basic knowledge has resulted in many remarkable applications of great value. Many scientists think that a basic understanding of science is necessary before an application is developed; therefore, applied science relies on the results generated through basic science. Other scientists think that it is time to move on from basic science and instead to find solutions to actual problems. Both approaches are valid. It is true that there are problems that demand immediate attention; however, few solutions would be found without the help of the knowledge generated through basic science.
One example of how basic and applied science can work together to solve practical problems occurred after the discovery of DNA structure led to an understanding of the molecular mechanisms governing DNA replication. Strands of DNA, unique in every human, are found in our cells, where they provide the instructions necessary for life. During DNA replication, new copies of DNA are made, shortly before a cell divides to form new cells. Understanding the mechanisms of DNA replication enabled scientists to develop laboratory techniques that are now used to identify genetic diseases, pinpoint individuals who were at a crime scene, and determine paternity. Without basic science, it is unlikely that applied science would exist.
Another example of the link between basic and applied research is the Human Genome Project, a study in which each human chromosome was analyzed and mapped to determine the precise sequence of DNA subunits and the exact location of each gene. (The gene is the basic unit of heredity; an individual’s complete collection of genes is his or her genome.) Other organisms have also been studied as part of this project to gain a better understanding of human chromosomes. The Human Genome Project relied on basic research carried out with non-human organisms and, later, with the human genome. An important end goal eventually became using the data for applied research seeking cures for genetically related diseases.

While research efforts in both basic science and applied science are usually carefully planned, it is important to note that some discoveries are made by serendipity, that is, by means of a fortunate accident or a lucky surprise. Penicillin was discovered when biologist Alexander Fleming accidentally left a petri dish of Staphylococcus bacteria open. An unwanted mold grew, killing the bacteria. The mold turned out to be Penicillium, and a new antibiotic was discovered. Even in the highly organized world of science, luck—when combined with an observant, curious mind—can lead to unexpected breakthroughs.
Whether scientific research is basic science or applied science, scientists must share their findings for other researchers to expand and build upon their discoveries. Communication and collaboration within and between sub disciplines of science are key to the advancement of knowledge in science. For this reason, an important aspect of a scientist’s work is disseminating results and communicating with peers. Scientists can share results by presenting them at a scientific meeting or conference, but this approach can reach only the limited few who are present. Instead, most scientists present their results in peer-reviewed articles that are published in scientific journals. Peer-reviewed articles are scientific papers that are reviewed, usually anonymously by a scientist’s colleagues, or peers. These colleagues are qualified individuals, often experts in the same research area, who judge whether or not the scientist’s work is suitable for publication. The process of peer review helps to ensure that the research described in a scientific paper or grant proposal is original, significant, logical, and thorough. Grant proposals, which are requests for research funding, are also subject to peer review. Scientists publish their work so other scientists can reproduce their experiments under similar or different conditions to expand on the findings. The experimental results must be consistent with the findings of other scientists.
There are many journals and the popular press that do not use a peer-review system. A large number of online open-access journals, journals with articles available without cost, are now available many of which use rigorous peer-review systems, but some of which do not. Results of any studies published in these forums without peer review are not reliable and should not form the basis for other scientific work. In one exception, journals may allow a researcher to cite a personal communication from another researcher about unpublished results with the cited author’s permission.
Biology is the science that studies living organisms and their interactions with one another and their environments. Science attempts to describe and understand the nature of the universe in whole or in part. Science has many fields; those fields related to the physical world and its phenomena are considered natural sciences.
A hypothesis is a tentative explanation for an observation. A scientific theory is a well-tested and consistently verified explanation for a set of observations or phenomena. A scientific law is a description, often in the form of a mathematical formula, of the behaviour of an aspect of nature under certain circumstances. Two types of logical reasoning are used in science. Inductive reasoning uses results to produce general scientific principles. Deductive reasoning is a form of logical thinking that predicts results by applying general principles. The common thread throughout scientific research is the use of the scientific method. Scientists present their results in peer-reviewed scientific papers published in scientific journals.
Science can be basic or applied. The main goal of basic science is to expand knowledge without any expectation of short-term practical application of that knowledge. The primary goal of applied research, however, is to solve practical problems.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=47#h5p-8
applied science: a form of science that solves real-world problems
basic science: science that seeks to expand knowledge regardless of the short-term application of that knowledge
control: a part of an experiment that does not change during the experiment
deductive reasoning: a form of logical thinking that uses a general statement to forecast specific results
descriptive science: a form of science that aims to observe, explore, and find things out
falsifiable: able to be disproven by experimental results
hypothesis: a suggested explanation for an event, which can be tested
hypothesis-based science: a form of science that begins with a specific explanation that is then tested
inductive reasoning: a form of logical thinking that uses related observations to arrive at a general conclusion
life science: a field of science, such as biology, that studies living things
natural science: a field of science that studies the physical world, its phenomena, and processes
peer-reviewed article: a scientific report that is reviewed by a scientist’s colleagues before publication
physical science: a field of science, such as astronomy, physics, and chemistry, that studies nonliving matter
science: knowledge that covers general truths or the operation of general laws, especially when acquired and tested by the scientific method
scientific law: a description, often in the form of a mathematical formula, for the behavior of some aspect of nature under certain specific conditions
scientific method: a method of research with defined steps that include experiments and careful observation
scientific theory: a thoroughly tested and confirmed explanation for observations or phenomena
variable: a part of an experiment that can vary or change

The elements carbon, hydrogen, nitrogen, oxygen, sulfur, and phosphorus are the key building blocks of the chemicals found in living things. They form the carbohydrates, nucleic acids, proteins, and lipids (all of which will be defined later in this chapter) that are the fundamental molecular components of all organisms. In this chapter, we will discuss these important building blocks and learn how the unique properties of the atoms of different elements affect their interactions with other atoms to form the molecules of life. These interactions determine what atoms combine and the ultimate shape of the molecules and macromolecules, that shape will determine their function.
Food provides an organism with nutrients—the matter it needs to survive. Many of these critical nutrients come in the form of biological macromolecules, or large molecules necessary for life. These macromolecules are built from different combinations of smaller organic molecules. What specific types of biological macromolecules do living things require? How are these molecules formed? What functions do they serve? In this chapter, we will explore these questions.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=50#h5p-9
By the end of this section, you will be able to:
Watch a video about electrons and how the electrons in chemical bonds influence the shape and function of molecules.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=58#h5p-10
At its most fundamental level, life is made up of matter. Matter occupies space and has mass. All matter is composed of elements, substances that cannot be broken down or transformed chemically into other substances. Each element is made of atoms, each with a constant number of protons and unique properties. A total of 118 elements have been defined; however, only 92 occur naturally, and fewer than 30 are found in living cells. The remaining 26 elements are unstable and, therefore, do not exist for very long or are theoretical and have yet to be detected.
Each element is designated by its chemical symbol (such as H, N, O, C, and Na), and possesses unique properties. These unique properties allow elements to combine and to bond with each other in specific ways.
An atom is the smallest component of an element that retains all of the chemical properties of that element. For example, one hydrogen atom has all of the properties of the element hydrogen, such as it exists as a gas at room temperature, and it bonds with oxygen to create a water molecule. Hydrogen atoms cannot be broken down into anything smaller while still retaining the properties of hydrogen. If a hydrogen atom were broken down into subatomic particles, it would no longer have the properties of hydrogen.
At the most basic level, all organisms are made of a combination of elements. They contain atoms that combine together to form molecules. In multicellular organisms, such as animals, molecules can interact to form cells that combine to form tissues, which make up organs. These combinations continue until entire multicellular organisms are formed.
All atoms contain protons, electrons, and neutrons. The only exception is hydrogen (H), which is made of one proton and one electron. A proton is a positively charged particle that resides in the nucleus (the core of the atom) of an atom and has a mass of 1 and a charge of +1. An electron is a negatively charged particle that travels in the space around the nucleus. In other words, it resides outside of the nucleus. It has a negligible mass and has a charge of –1.
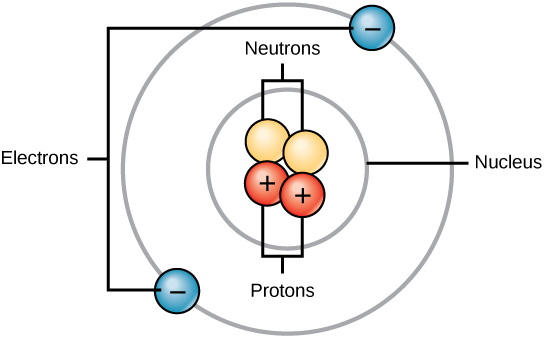
Neutrons, like protons, reside in the nucleus of an atom. They have a mass of 1 and no charge. The positive (protons) and negative (electrons) charges balance each other in a neutral atom, which has a net zero charge.
Because protons and neutrons each have a mass of 1, the mass of an atom is equal to the number of protons and neutrons of that atom. The number of electrons does not factor into the overall mass, because their mass is so small.
As stated earlier, each element has its own unique properties. Each contains a different number of protons and neutrons, giving it its own atomic number and mass number. The atomic number of an element is equal to the number of protons that element contains. The mass number, or atomic mass, is the number of protons plus the number of neutrons of that element. Therefore, it is possible to determine the number of neutrons by subtracting the atomic number from the mass number.
These numbers provide information about the elements and how they will react when combined. Different elements have different melting and boiling points, and are in different states (liquid, solid, or gas) at room temperature. They also combine in different ways. Some form specific types of bonds, whereas others do not. How they combine is based on the number of electrons present. Because of these characteristics, the elements are arranged into the periodic table of elements, a chart of the elements that includes the atomic number and relative atomic mass of each element. The periodic table also provides key information about the properties of elements —often indicated by color-coding. The arrangement of the table also shows how the electrons in each element are organized and provides important details about how atoms will react with each other to form molecules.
Isotopes are different forms of the same element that have the same number of protons, but a different number of neutrons. Some elements, such as carbon, potassium, and uranium, have naturally occurring isotopes. Carbon-12, the most common isotope of carbon, contains six protons and six neutrons. Therefore, it has a mass number of 12 (six protons and six neutrons) and an atomic number of 6 (which makes it carbon). Carbon-14 contains six protons and eight neutrons. Therefore, it has a mass number of 14 (six protons and eight neutrons) and an atomic number of 6, meaning it is still the element carbon. These two alternate forms of carbon are isotopes. Some isotopes are unstable and will lose protons, other subatomic particles, or energy to form more stable elements. These are called radioactive isotopes or radioisotopes.

How many neutrons do (K) potassium-39 and potassium-40 have, respectively?
Carbon-14 (14C) is a naturally occurring radioisotope that is created in the atmosphere by cosmic rays. This is a continuous process, so more 14C is always being created. As a living organism develops, the relative level of 14C in its body is equal to the concentration of 14C in the atmosphere. When an organism dies, it is no longer ingesting 14C, so the ratio will decline. 14C decays to 14N by a process called beta decay; it gives off energy in this slow process.
After approximately 5,730 years, only one-half of the starting concentration of 14C will have been converted to 14N. The time it takes for half of the original concentration of an isotope to decay to its more stable form is called its half-life. Because the half-life of 14C is long, it is used to age formerly living objects, such as fossils. Using the ratio of the 14C concentration found in an object to the amount of 14C detected in the atmosphere, the amount of the isotope that has not yet decayed can be determined. Based on this amount, the age of the fossil can be calculated to about 50,000 years. Isotopes with longer half-lives, such as potassium-40, are used to calculate the ages of older fossils. Through the use of carbon dating, scientists can reconstruct the ecology and biogeography of organisms living within the past 50,000 years.


To learn more about atoms and isotopes, and how you can tell one isotope from another, visit this site and run the simulation.
How elements interact with one another depends on how their electrons are arranged and how many openings for electrons exist at the outermost region where electrons are present in an atom. Electrons exist at energy levels that form shells around the nucleus. The closest shell can hold up to two electrons. The closest shell to the nucleus is always filled first, before any other shell can be filled. Hydrogen has one electron; therefore, it has only one spot occupied within the lowest shell. Helium has two electrons; therefore, it can completely fill the lowest shell with its two electrons. If you look at the periodic table, you will see that hydrogen and helium are the only two elements in the first row. This is because they only have electrons in their first shell. Hydrogen and helium are the only two elements that have the lowest shell and no other shells.
The second and third energy levels can hold up to eight electrons. The eight electrons are arranged in four pairs and one position in each pair is filled with an electron before any pairs are completed.
Looking at the periodic table again, you will notice that there are seven rows. These rows correspond to the number of shells that the elements within that row have. The elements within a particular row have increasing numbers of electrons as the columns proceed from left to right. Although each element has the same number of shells, not all of the shells are completely filled with electrons. If you look at the second row of the periodic table, you will find lithium (Li), beryllium (Be), boron (B), carbon (C), nitrogen (N), oxygen (O), fluorine (F), and neon (Ne). These all have electrons that occupy only the first and second shells. Lithium has only one electron in its outermost shell, beryllium has two electrons, boron has three, and so on, until the entire shell is filled with eight electrons, as is the case with neon.
Not all elements have enough electrons to fill their outermost shells, but an atom is at its most stable when all of the electron positions in the outermost shell are filled. Because of these vacancies in the outermost shells, we see the formation of chemical bonds, or interactions between two or more of the same or different elements that result in the formation of molecules. To achieve greater stability, atoms will tend to completely fill their outer shells and will bond with other elements to accomplish this goal by sharing electrons, accepting electrons from another atom, or donating electrons to another atom. Because the outermost shells of the elements with low atomic numbers (up to calcium, with atomic number 20) can hold eight electrons, this is referred to as the octet rule. An element can donate, accept, or share electrons with other elements to fill its outer shell and satisfy the octet rule.
When an atom does not contain equal numbers of protons and electrons, it is called an ion. Because the number of electrons does not equal the number of protons, each ion has a net charge. Positive ions are formed by losing electrons and are called cations. Negative ions are formed by gaining electrons and are called anions.
For example, sodium only has one electron in its outermost shell. It takes less energy for sodium to donate that one electron than it does to accept seven more electrons to fill the outer shell. If sodium loses an electron, it now has 11 protons and only 10 electrons, leaving it with an overall charge of +1. It is now called a sodium ion.
The chlorine atom has seven electrons in its outer shell. Again, it is more energy-efficient for chlorine to gain one electron than to lose seven. Therefore, it tends to gain an electron to create an ion with 17 protons and 18 electrons, giving it a net negative (–1) charge. It is now called a chloride ion. This movement of electrons from one element to another is referred to as electron transfer. As illustrates, a sodium atom (Na) only has one electron in its outermost shell, whereas a chlorine atom (Cl) has seven electrons in its outermost shell. A sodium atom will donate its one electron to empty its shell, and a chlorine atom will accept that electron to fill its shell, becoming chloride. Both ions now satisfy the octet rule and have complete outermost shells. Because the number of electrons is no longer equal to the number of protons, each is now an ion and has a +1 (sodium) or –1 (chloride) charge.
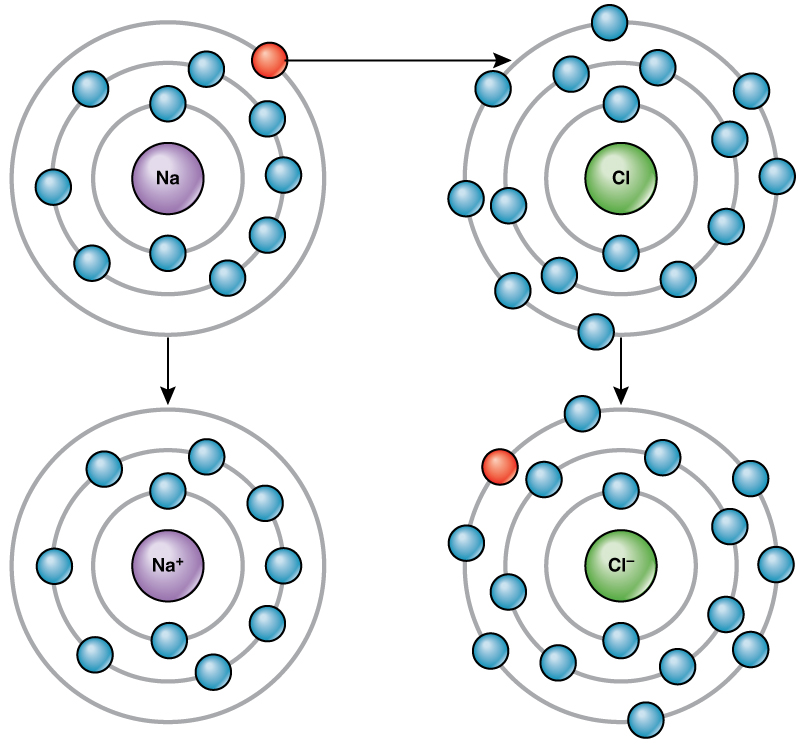
There are four types of bonds or interactions: ionic, covalent, hydrogen bonds, and van der Waals interactions. Ionic and covalent bonds are strong interactions that require a larger energy input to break apart. When an element donates an electron from its outer shell, as in the sodium atom example above, a positive ion is formed. The element accepting the electron is now negatively charged. Because positive and negative charges attract, these ions stay together and form an ionic bond, or a bond between ions. The elements bond together with the electron from one element staying predominantly with the other element. When Na+ and Cl– ions combine to produce NaCl, an electron from a sodium atom stays with the other seven from the chlorine atom, and the sodium and chloride ions attract each other in a lattice of ions with a net zero charge.
Another type of strong chemical bond between two or more atoms is a covalent bond. These bonds form when a pair of electrons is shared between two elements and are the strongest and most common form of chemical bond in living organisms. Covalent bonds form between the elements that make up the biological molecules in our cells. Unlike ionic bonds, covalent bonds do not dissociate in water.
The hydrogen and oxygen atoms that combine to form water molecules are bound together by covalent bonds. The electron from the hydrogen atom divides its time between the outer shell of the hydrogen atom and the incomplete outer shell of the oxygen atom. To completely fill the outer shell of an oxygen atom, two electrons from two hydrogen atoms are needed, hence the subscript “2” in H2O. The electrons are shared between the atoms, dividing their time between them to “fill” the outer shell of each. This sharing is a lower energy state for all of the atoms involved than if they existed without their outer shells filled.
There are two types of covalent bonds: polar and nonpolar. Nonpolar covalent bonds form between two atoms of the same element or between different elements that share the electrons equally. For example, an oxygen atom can bond with another oxygen atom to fill their outer shells. This association is nonpolar because the electrons will be equally distributed between each oxygen atom. Two covalent bonds form between the two oxygen atoms because oxygen requires two shared electrons to fill its outermost shell. Nitrogen atoms will form three covalent bonds (also called triple covalent) between two atoms of nitrogen because each nitrogen atom needs three electrons to fill its outermost shell. Another example of a nonpolar covalent bond is found in the methane (CH4) molecule. The carbon atom has four electrons in its outermost shell and needs four more to fill it. It gets these four from four hydrogen atoms, each atom providing one. These elements all share the electrons equally, creating four nonpolar covalent bonds.
In a polar covalent bond, the electrons shared by the atoms spend more time closer to one nucleus than to the other nucleus. Because of the unequal distribution of electrons between the different nuclei, a slightly positive (δ+) or slightly negative (δ–) charge develops. The covalent bonds between hydrogen and oxygen atoms in water are polar covalent bonds. The shared electrons spend more time near the oxygen nucleus, giving it a small negative charge, than they spend near the hydrogen nuclei, giving these molecules a small positive charge.
Ionic and covalent bonds are strong bonds that require considerable energy to break. However, not all bonds between elements are ionic or covalent bonds. Weaker bonds can also form. These are attractions that occur between positive and negative charges that do not require much energy to break. Two weak bonds that occur frequently are hydrogen bonds and van der Waals interactions. These bonds give rise to the unique properties of water and the unique structures of DNA and proteins.
When polar covalent bonds containing a hydrogen atom form, the hydrogen atom in that bond has a slightly positive charge. This is because the shared electron is pulled more strongly toward the other element and away from the hydrogen nucleus. Because the hydrogen atom is slightly positive (δ+), it will be attracted to neighboring negative partial charges (δ–). When this happens, a weak interaction occurs between the δ+ charge of the hydrogen atom of one molecule and the δ– charge of the other molecule. This interaction is called a hydrogen bond. This type of bond is common; for example, the liquid nature of water is caused by the hydrogen bonds between water molecules. Hydrogen bonds give water the unique properties that sustain life. If it were not for hydrogen bonding, water would be a gas rather than a liquid at room temperature.

Hydrogen bonds can form between different molecules and they do not always have to include a water molecule. Hydrogen atoms in polar bonds within any molecule can form bonds with other adjacent molecules. For example, hydrogen bonds hold together two long strands of DNA to give the DNA molecule its characteristic double-stranded structure. Hydrogen bonds are also responsible for some of the three-dimensional structure of proteins.
Like hydrogen bonds, van der Waals interactions are weak attractions or interactions between molecules. They occur between polar, covalently bound, atoms in different molecules. Some of these weak attractions are caused by temporary partial charges formed when electrons move around a nucleus. These weak interactions between molecules are important in biological systems.
Have you or anyone you know ever had a magnetic resonance imaging (MRI) scan, a mammogram, or an X-ray? These tests produce images of your soft tissues and organs (as with an MRI or mammogram) or your bones (as happens in an X-ray) by using either radio waves or special isotopes (radiolabeled or fluorescently labeled) that are ingested or injected into the body. These tests provide data for disease diagnoses by creating images of your organs or skeletal system.
MRI imaging works by subjecting hydrogen nuclei, which are abundant in the water in soft tissues, to fluctuating magnetic fields, which cause them to emit their own magnetic field. This signal is then read by sensors in the machine and interpreted by a computer to form a detailed image.
Some radiography technologists and technicians specialize in computed tomography, MRI, and mammography. They produce films or images of the body that help medical professionals examine and diagnose. Radiologists work directly with patients, explaining machinery, preparing them for exams, and ensuring that their body or body parts are positioned correctly to produce the needed images. Physicians or radiologists then analyze the test results.
Radiography technicians can work in hospitals, doctors’ offices, or specialized imaging centers. Training to become a radiography technician happens at hospitals, colleges, and universities that offer certificates, associate’s degrees, or bachelor’s degrees in radiography.
Matter is anything that occupies space and has mass. It is made up of atoms of different elements. All of the 92 elements that occur naturally have unique qualities that allow them to combine in various ways to create compounds or molecules. Atoms, which consist of protons, neutrons, and electrons, are the smallest units of an element that retain all of the properties of that element. Electrons can be donated or shared between atoms to create bonds, including ionic, covalent, and hydrogen bonds, as well as van der Waals interactions.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=58#h5p-11
anion: a negative ion formed by gaining electrons
atomic number: the number of protons in an atom
cation: a positive ion formed by losing electrons
chemical bond: an interaction between two or more of the same or different elements that results in the formation of molecules
covalent bond: a type of strong bond between two or more of the same or different elements; forms when electrons are shared between elements
electron: a negatively charged particle that resides outside of the nucleus in the electron orbital; lacks functional mass and has a charge of –1
electron transfer: the movement of electrons from one element to another
element: one of 118 unique substances that cannot be broken down into smaller substances and retain the characteristic of that substance; each element has a specified number of protons and unique properties
hydrogen bond: a weak bond between partially positively charged hydrogen atoms and partially negatively charged elements or molecules
ion: an atom or compound that does not contain equal numbers of protons and electrons, and therefore has a net charge
ionic bond: a chemical bond that forms between ions of opposite charges
isotope: one or more forms of an element that have different numbers of neutrons
mass number: the number of protons plus neutrons in an atom
matter: anything that has mass and occupies space
neutron: a particle with no charge that resides in the nucleus of an atom; has a mass of 1
nonpolar covalent bond: a type of covalent bond that forms between atoms when electrons are shared equally between atoms, resulting in no regions with partial charges as in polar covalent bonds
nucleus: (chemistry) the dense center of an atom made up of protons and (except in the case of a hydrogen atom) neutrons
octet rule: states that the outermost shell of an element with a low atomic number can hold eight electrons
periodic table of elements: an organizational chart of elements, indicating the atomic number and mass number of each element; also provides key information about the properties of elements
polar covalent bond:a type of covalent bond in which electrons are pulled toward one atom and away from another, resulting in slightly positive and slightly negative charged regions of the molecule
proton: a positively charged particle that resides in the nucleus of an atom; has a mass of 1 and a charge of +1
radioactive isotope: an isotope that spontaneously emits particles or energy to form a more stable element
van der Waals interaction: a weak attraction or interaction between molecules caused by slightly positively charged or slightly negatively charged atoms
By the end of this section, you will be able to:
Watch a video about why we need oxygen and how it causes problems for living things.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=66#h5p-12
Do you ever wonder why scientists spend time looking for water on other planets? It is because water is essential to life; even minute traces of it on another planet can indicate that life could or did exist on that planet. Water is one of the more abundant molecules in living cells and the one most critical to life as we know it. Approximately 60–70 percent of your body is made up of water. Without it, life simply would not exist.
The hydrogen and oxygen atoms within water molecules form polar covalent bonds. The shared electrons spend more time associated with the oxygen atom than they do with hydrogen atoms. There is no overall charge to a water molecule, but there is a slight positive charge on each hydrogen atom and a slight negative charge on the oxygen atom. Because of these charges, the slightly positive hydrogen atoms repel each other and form the unique shape. Each water molecule attracts other water molecules because of the positive and negative charges in the different parts of the molecule. Water also attracts other polar molecules (such as sugars), forming hydrogen bonds. When a substance readily forms hydrogen bonds with water, it can dissolve in water and is referred to as hydrophilic (“water-loving”). Hydrogen bonds are not readily formed with nonpolar substances like oils and fats . These nonpolar compounds are hydrophobic (“water-fearing”) and will not dissolve in water.

The hydrogen bonds in water allow it to absorb and release heat energy more slowly than many other substances. Temperature is a measure of the motion (kinetic energy) of molecules. As the motion increases, energy is higher and thus temperature is higher. Water absorbs a great deal of energy before its temperature rises. Increased energy disrupts the hydrogen bonds between water molecules. Because these bonds can be created and disrupted rapidly, water absorbs an increase in energy and temperature changes only minimally. This means that water moderates temperature changes within organisms and in their environments. As energy input continues, the balance between hydrogen-bond formation and destruction swings toward the destruction side. More bonds are broken than are formed. This process results in the release of individual water molecules at the surface of the liquid (such as a body of water, the leaves of a plant, or the skin of an organism) in a process called evaporation. Evaporation of sweat, which is 90 percent water, allows for cooling of an organism, because breaking hydrogen bonds requires an input of energy and takes heat away from the body.
Conversely, as molecular motion decreases and temperatures drop, less energy is present to break the hydrogen bonds between water molecules. These bonds remain intact and begin to form a rigid, lattice-like structure (e.g., ice) (Figure 2.8 a). When frozen, ice is less dense than liquid water (the molecules are farther apart). This means that ice floats on the surface of a body of water (Figure 2.8 b). In lakes, ponds, and oceans, ice will form on the surface of the water, creating an insulating barrier to protect the animal and plant life beneath from freezing in the water. If this did not happen, plants and animals living in water would freeze in a block of ice and could not move freely, making life in cold temperatures difficult or impossible.

Because water is polar, with slight positive and negative charges, ionic compounds and polar molecules can readily dissolve in it. Water is, therefore, what is referred to as a solvent—a substance capable of dissolving another substance. The charged particles will form hydrogen bonds with a surrounding layer of water molecules. This is referred to as a sphere of hydration and serves to keep the particles separated or dispersed in the water. In the case of table salt (NaCl) mixed in water, the sodium and chloride ions separate, or dissociate, in the water, and spheres of hydration are formed around the ions. A positively charged sodium ion is surrounded by the partially negative charges of oxygen atoms in water molecules. A negatively charged chloride ion is surrounded by the partially positive charges of hydrogen atoms in water molecules. These spheres of hydration are also referred to as hydration shells. The polarity of the water molecule makes it an effective solvent and is important in its many roles in living systems.
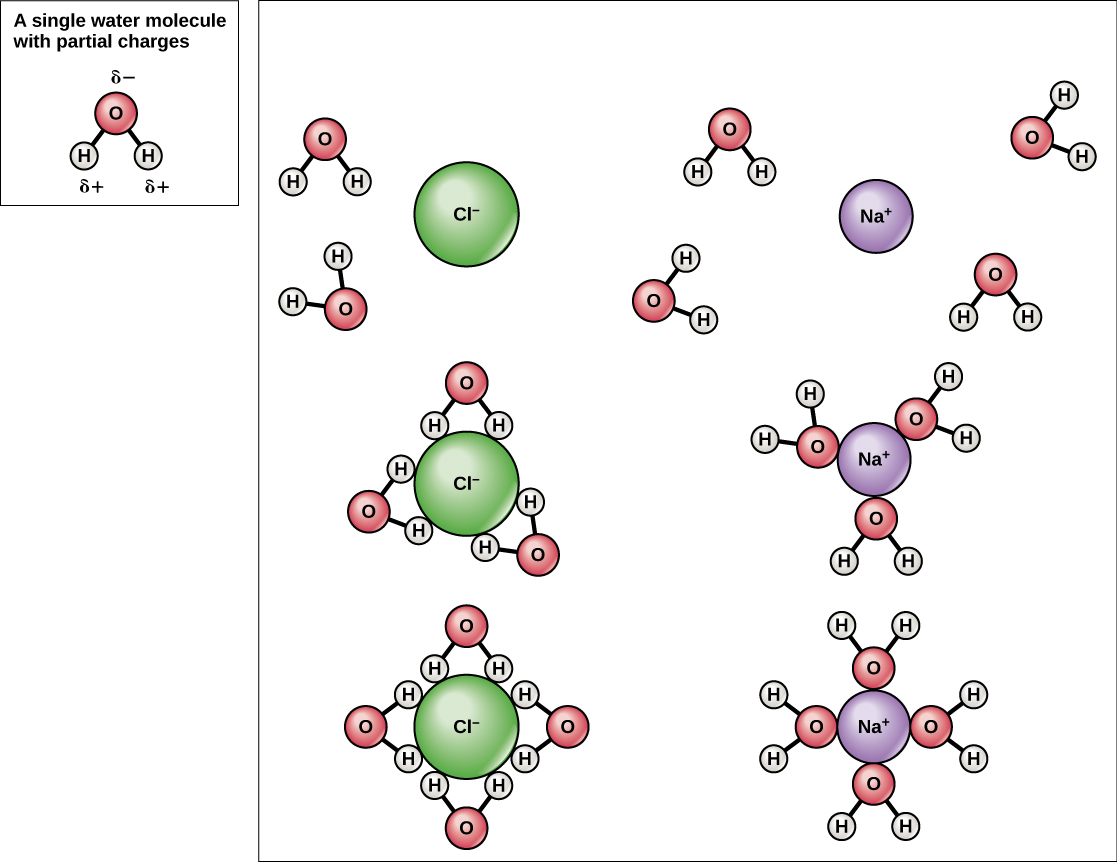
Have you ever filled up a glass of water to the very top and then slowly added a few more drops? Before it overflows, the water actually forms a dome-like shape above the rim of the glass. This water can stay above the glass because of the property of cohesion. In cohesion, water molecules are attracted to each other (because of hydrogen bonding), keeping the molecules together at the liquid-air (gas) interface, although there is no more room in the glass. Cohesion gives rise to surface tension, the capacity of a substance to withstand rupture when placed under tension or stress. When you drop a small scrap of paper onto a droplet of water, the paper floats on top of the water droplet, although the object is denser (heavier) than the water. This occurs because of the surface tension that is created by the water molecules. Cohesion and surface tension keep the water molecules intact and the item floating on the top. It is even possible to “float” a steel needle on top of a glass of water if you place it gently, without breaking the surface tension.

These cohesive forces are also related to the water’s property of adhesion, or the attraction between water molecules and other molecules. This is observed when water “climbs” up a straw placed in a glass of water. You will notice that the water appears to be higher on the sides of the straw than in the middle. This is because the water molecules are attracted to the straw and therefore adhere to it.
Cohesive and adhesive forces are important for sustaining life. For example, because of these forces, water can flow up from the roots to the tops of plants to feed the plant.

To learn more about water, visit the U.S. Geological Survey Water Science for Schools: All About Water! website.
The pH of a solution is a measure of its acidity or alkalinity. You have probably used litmus paper, paper that has been treated with a natural water-soluble dye so it can be used as a pH indicator, to test how much acid or base (alkalinity) exists in a solution. You might have even used some to make sure the water in an outdoor swimming pool is properly treated. In both cases, this pH test measures the amount of hydrogen ions that exists in a given solution. High concentrations of hydrogen ions yield a low pH, whereas low levels of hydrogen ions result in a high pH. The overall concentration of hydrogen ions is inversely related to its pH and can be measured on the pH scale (Figure 2.11). Therefore, the more hydrogen ions present, the lower the pH; conversely, the fewer hydrogen ions, the higher the pH.
The pH scale ranges from 0 to 14. A change of one unit on the pH scale represents a change in the concentration of hydrogen ions by a factor of 10, a change in two units represents a change in the concentration of hydrogen ions by a factor of 100. Thus, small changes in pH represent large changes in the concentrations of hydrogen ions. Pure water is neutral. It is neither acidic nor basic, and has a pH of 7.0. Anything below 7.0 (ranging from 0.0 to 6.9) is acidic, and anything above 7.0 (from 7.1 to 14.0) is alkaline. The blood in your veins is slightly alkaline (pH = 7.4). The environment in your stomach is highly acidic (pH = 1 to 2). Orange juice is mildly acidic (pH = approximately 3.5), whereas baking soda is basic (pH = 9.0).

Acids are substances that provide hydrogen ions (H+) and lower pH, whereas bases provide hydroxide ions (OH–) and raise pH. The stronger the acid, the more readily it donates H+. For example, hydrochloric acid and lemon juice are very acidic and readily give up H+ when added to water. Conversely, bases are those substances that readily donate OH–. The OH– ions combine with H+ to produce water, which raises a substance’s pH. Sodium hydroxide and many household cleaners are very alkaline and give up OH– rapidly when placed in water, thereby raising the pH.
Most cells in our bodies operate within a very narrow window of the pH scale, typically ranging only from 7.2 to 7.6. If the pH of the body is outside of this range, the respiratory system malfunctions, as do other organs in the body. Cells no longer function properly, and proteins will break down. Deviation outside of the pH range can induce coma or even cause death.
So how is it that we can ingest or inhale acidic or basic substances and not die? Buffers are the key. Buffers readily absorb excess H+ or OH–, keeping the pH of the body carefully maintained in the aforementioned narrow range. Carbon dioxide is part of a prominent buffer system in the human body; it keeps the pH within the proper range. This buffer system involves carbonic acid (H2CO3) and bicarbonate (HCO3–) anion. If too much H+ enters the body, bicarbonate will combine with the H+ to create carbonic acid and limit the decrease in pH. Likewise, if too much OH– is introduced into the system, carbonic acid will rapidly dissociate into bicarbonate and H+ ions. The H+ ions can combine with the OH– ions, limiting the increase in pH. While carbonic acid is an important product in this reaction, its presence is fleeting because the carbonic acid is released from the body as carbon dioxide gas each time we breathe. Without this buffer system, the pH in our bodies would fluctuate too much and we would fail to survive.
Water has many properties that are critical to maintaining life. It is polar, allowing for the formation of hydrogen bonds, which allow ions and other polar molecules to dissolve in water. Therefore, water is an excellent solvent. The hydrogen bonds between water molecules give water the ability to hold heat better than many other substances. As the temperature rises, the hydrogen bonds between water continually break and reform, allowing for the overall temperature to remain stable, although increased energy is added to the system. Water’s cohesive forces allow for the property of surface tension. All of these unique properties of water are important in the chemistry of living organisms.
The pH of a solution is a measure of the concentration of hydrogen ions in the solution. A solution with a high number of hydrogen ions is acidic and has a low pH value. A solution with a high number of hydroxide ions is basic and has a high pH value. The pH scale ranges from 0 to 14, with a pH of 7 being neutral. Buffers are solutions that moderate pH changes when an acid or base is added to the buffer system. Buffers are important in biological systems because of their ability to maintain constant pH conditions.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=66#h5p-13
acid: a substance that donates hydrogen ions and therefore lowers pH
adhesion: the attraction between water molecules and molecules of a different substance
base: a substance that absorbs hydrogen ions and therefore raises pH
buffer: a solution that resists a change in pH by absorbing or releasing hydrogen or hydroxide ions
cohesion: the intermolecular forces between water molecules caused by the polar nature of water; creates surface tension
evaporation: the release of water molecules from liquid water to form water vapor
hydrophilic: describes a substance that dissolves in water; water-loving
hydrophobic: describes a substance that does not dissolve in water; water-fearing
litmus paper: filter paper that has been treated with a natural water-soluble dye so it can be used as a pH indicator
pH scale: a scale ranging from 0 to 14 that measures the approximate concentration of hydrogen ions of a substance
solvent: a substance capable of dissolving another substance
surface tension: the cohesive force at the surface of a body of liquid that prevents the molecules from separating
temperature: a measure of molecular motion
Humphrey, W., Dalke, A. and Schulten, K., “VMD—Visual Molecular Dynamics”, J. Molec. Graphics, 1996, vol. 14, pp. 33-38. http://www.ks.uiuc.edu/Research/vmd/
By the end of this section, you will be able to:
Watch a video about proteins and protein enzymes.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=83#h5p-14
The large molecules necessary for life that are built from smaller organic molecules are called biological macromolecules. There are four major classes of biological macromolecules (carbohydrates, lipids, proteins, and nucleic acids), and each is an important component of the cell and performs a wide array of functions. Combined, these molecules make up the majority of a cell’s mass. Biological macromolecules are organic, meaning that they contain carbon. In addition, they may contain hydrogen, oxygen, nitrogen, phosphorus, sulfur, and additional minor elements.
It is often said that life is “carbon-based.” This means that carbon atoms, bonded to other carbon atoms or other elements, form the fundamental components of many, if not most, of the molecules found uniquely in living things. Other elements play important roles in biological molecules, but carbon certainly qualifies as the “foundation” element for molecules in living things. It is the bonding properties of carbon atoms that are responsible for its important role.
Carbon contains four electrons in its outer shell. Therefore, it can form four covalent bonds with other atoms or molecules. The simplest organic carbon molecule is methane (CH4), in which four hydrogen atoms bind to a carbon atom.
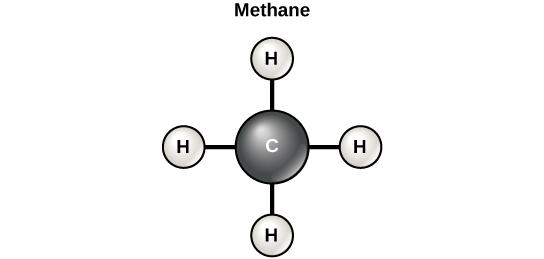
However, structures that are more complex are made using carbon. Any of the hydrogen atoms can be replaced with another carbon atom covalently bonded to the first carbon atom. In this way, long and branching chains of carbon compounds can be made (Figure 2.13 a). The carbon atoms may bond with atoms of other elements, such as nitrogen, oxygen, and phosphorus (Figure 2.13 b). The molecules may also form rings, which themselves can link with other rings (Figure 2.13 c). This diversity of molecular forms accounts for the diversity of functions of the biological macromolecules and is based to a large degree on the ability of carbon to form multiple bonds with itself and other atoms.
Carbohydrates are macromolecules with which most consumers are somewhat familiar. To lose weight, some individuals adhere to “low-carb” diets. Athletes, in contrast, often “carb-load” before important competitions to ensure that they have sufficient energy to compete at a high level. Carbohydrates are, in fact, an essential part of our diet; grains, fruits, and vegetables are all natural sources of carbohydrates. Carbohydrates provide energy to the body, particularly through glucose, a simple sugar. Carbohydrates also have other important functions in humans, animals, and plants.
Carbohydrates can be represented by the formula (CH2O)n, where n is the number of carbon atoms in the molecule. In other words, the ratio of carbon to hydrogen to oxygen is 1:2:1 in carbohydrate molecules. Carbohydrates are classified into three subtypes: monosaccharides, disaccharides, and polysaccharides.
Monosaccharides (mono- = “one”; sacchar- = “sweet”) are simple sugars, the most common of which is glucose. In monosaccharides, the number of carbon atoms usually ranges from three to six. Most monosaccharide names end with the suffix -ose. Depending on the number of carbon atoms in the sugar, they may be known as trioses (three carbon atoms), pentoses (five carbon atoms), and hexoses (six carbon atoms).
Monosaccharides may exist as a linear chain or as ring-shaped molecules; in aqueous solutions, they are usually found in the ring form.
The chemical formula for glucose is C6H12O6. In most living species, glucose is an important source of energy. During cellular respiration, energy is released from glucose, and that energy is used to help make adenosine triphosphate (ATP). Plants synthesize glucose using carbon dioxide and water by the process of photosynthesis, and the glucose, in turn, is used for the energy requirements of the plant. The excess synthesized glucose is often stored as starch that is broken down by other organisms that feed on plants.
Galactose (part of lactose, or milk sugar) and fructose (found in fruit) are other common monosaccharides. Although glucose, galactose, and fructose all have the same chemical formula (C6H12O6), they differ structurally and chemically (and are known as isomers) because of differing arrangements of atoms in the carbon chain.
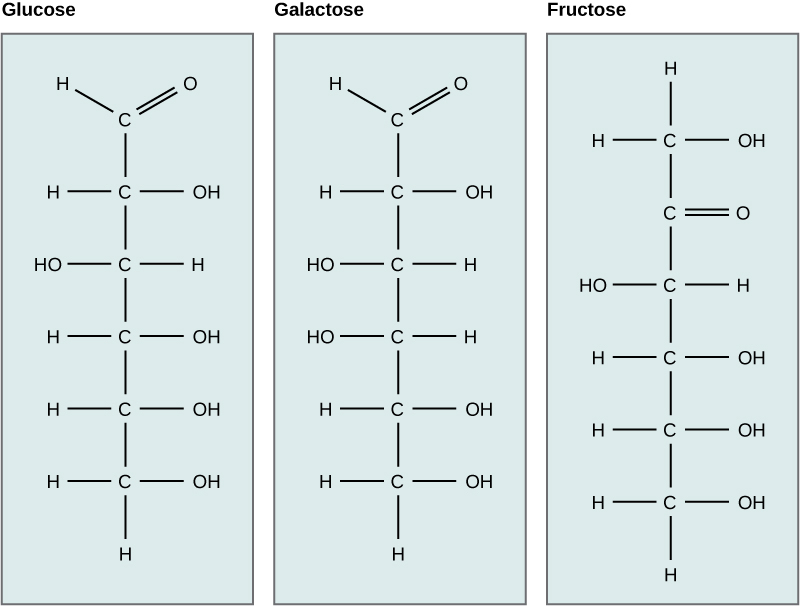
Disaccharides (di- = “two”) form when two monosaccharides undergo a dehydration reaction (a reaction in which the removal of a water molecule occurs). During this process, the hydroxyl group (–OH) of one monosaccharide combines with a hydrogen atom of another monosaccharide, releasing a molecule of water (H2O) and forming a covalent bond between atoms in the two sugar molecules.
Common disaccharides include lactose, maltose, and sucrose. Lactose is a disaccharide consisting of the monomers glucose and galactose. It is found naturally in milk. Maltose, or malt sugar, is a disaccharide formed from a dehydration reaction between two glucose molecules. The most common disaccharide is sucrose, or table sugar, which is composed of the monomers glucose and fructose.
A long chain of monosaccharides linked by covalent bonds is known as a polysaccharide (poly- = “many”). The chain may be branched or unbranched, and it may contain different types of monosaccharides. Polysaccharides may be very large molecules. Starch, glycogen, cellulose, and chitin are examples of polysaccharides.
Starch is the stored form of sugars in plants and is made up of amylose and amylopectin (both polymers of glucose). Plants are able to synthesize glucose, and the excess glucose is stored as starch in different plant parts, including roots and seeds. The starch that is consumed by animals is broken down into smaller molecules, such as glucose. The cells can then absorb the glucose.
Glycogen is the storage form of glucose in humans and other vertebrates, and is made up of monomers of glucose. Glycogen is the animal equivalent of starch and is a highly branched molecule usually stored in liver and muscle cells. Whenever glucose levels decrease, glycogen is broken down to release glucose.
Cellulose is one of the most abundant natural biopolymers. The cell walls of plants are mostly made of cellulose, which provides structural support to the cell. Wood and paper are mostly cellulosic in nature. Cellulose is made up of glucose monomers that are linked by bonds between particular carbon atoms in the glucose molecule.
Every other glucose monomer in cellulose is flipped over and packed tightly as extended long chains. This gives cellulose its rigidity and high tensile strength—which is so important to plant cells. Cellulose passing through our digestive system is called dietary fiber. While the glucose-glucose bonds in cellulose cannot be broken down by human digestive enzymes, herbivores such as cows, buffalos, and horses are able to digest grass that is rich in cellulose and use it as a food source. In these animals, certain species of bacteria reside in the rumen (part of the digestive system of herbivores) and secrete the enzyme cellulase. The appendix also contains bacteria that break down cellulose, giving it an important role in the digestive systems of ruminants. Cellulases can break down cellulose into glucose monomers that can be used as an energy source by the animal.
Carbohydrates serve other functions in different animals. Arthropods, such as insects, spiders, and crabs, have an outer skeleton, called the exoskeleton, which protects their internal body parts. This exoskeleton is made of the biological macromolecule chitin, which is a nitrogenous carbohydrate. It is made of repeating units of a modified sugar containing nitrogen.
Thus, through differences in molecular structure, carbohydrates are able to serve the very different functions of energy storage (starch and glycogen) and structural support and protection (cellulose and chitin).
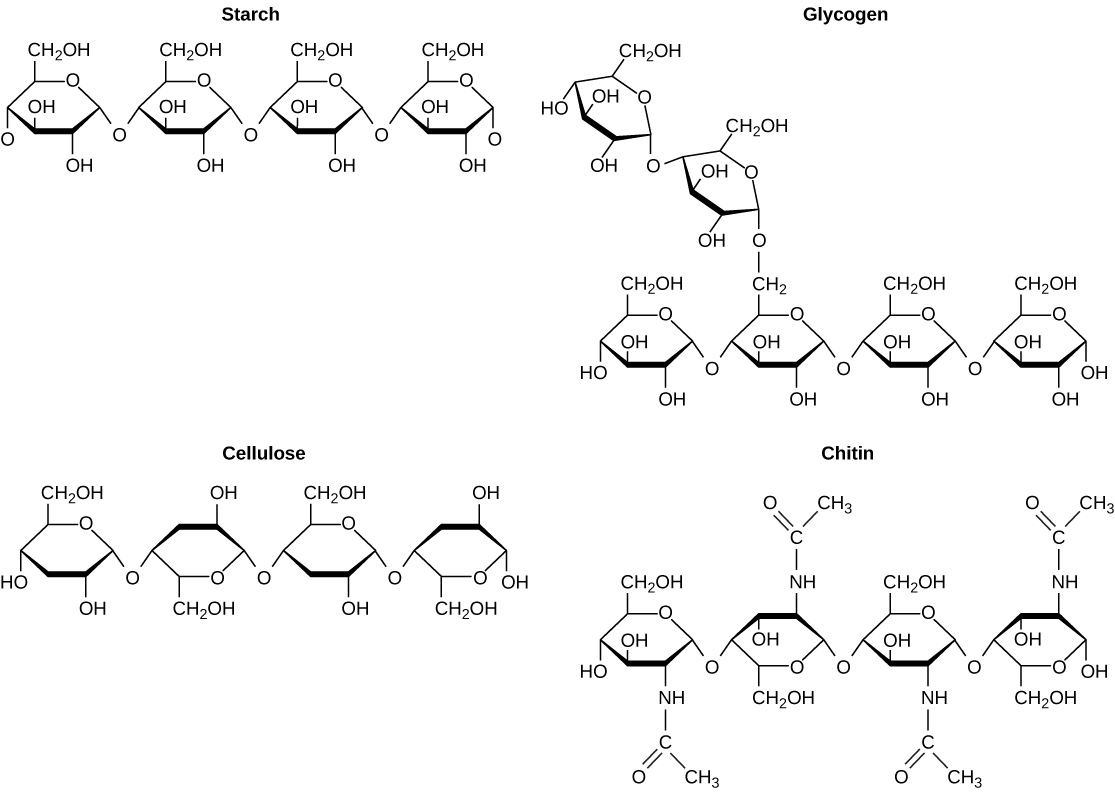
Registered Dietitian: Obesity is a worldwide health concern, and many diseases, such as diabetes and heart disease, are becoming more prevalent because of obesity. This is one of the reasons why registered dietitians are increasingly sought after for advice. Registered dietitians help plan food and nutrition programs for individuals in various settings. They often work with patients in health-care facilities, designing nutrition plans to prevent and treat diseases. For example, dietitians may teach a patient with diabetes how to manage blood-sugar levels by eating the correct types and amounts of carbohydrates. Dietitians may also work in nursing homes, schools, and private practices.
To become a registered dietitian, one needs to earn at least a bachelor’s degree in dietetics, nutrition, food technology, or a related field. In addition, registered dietitians must complete a supervised internship program and pass a national exam. Those who pursue careers in dietetics take courses in nutrition, chemistry, biochemistry, biology, microbiology, and human physiology. Dietitians must become experts in the chemistry and functions of food (proteins, carbohydrates, and fats).
I work at Camosun College located in beautiful Victoria, British Columbia with campuses on the Traditional Territories of the Lekwungen and W̱SÁNEĆ peoples. The underground storage bulb of the camas flower shown below has been an important food source for many of the Indigenous peoples of Vancouver Island and throughout the western area of North America. Camas bulbs are still eaten as a traditional food source and the preparation of the camas bulbs relates to this text section about carbohydrates.

Most often plants create starch as the stored form of carbohydrate. Some plants, like camas create inulin. Inulin is used as dietary fibre however, it is not readily digested by humans. If you were to bite into a raw camas bulb it would taste bitter and has a gummy texture. The method used by Indigenous peoples to make camas both digestible and tasty is to bake the bulbs slowly for a long period in an underground firepit covered with specific leaves and soil. The heat acts like our pancreatic amylase enzyme and breaks down the long chains of inulin into digestible mono and di-saccharides.
Properly baked, the camas bulbs taste like a combination of baked pear and cooked fig. It is important to note that while the blue camas is a food source, it should not be confused with the white death camas, which is particularly toxic and deadly. The flowers look different, but the bulbs look very similar.
Lipids include a diverse group of compounds that are united by a common feature. Lipids are hydrophobic (“water-fearing”), or insoluble in water, because they are nonpolar molecules. This is because they are hydrocarbons that include only nonpolar carbon-carbon or carbon-hydrogen bonds. Lipids perform many different functions in a cell. Cells store energy for long-term use in the form of lipids called fats. Lipids also provide insulation from the environment for plants and animals. For example, they help keep aquatic birds and mammals dry because of their water-repelling nature. Lipids are also the building blocks of many hormones and are an important constituent of the plasma membrane. Lipids include fats, oils, waxes, phospholipids, and steroids.

A fat molecule, such as a triglyceride, consists of two main components—glycerol and fatty acids. Glycerol is an organic compound with three carbon atoms, five hydrogen atoms, and three hydroxyl (–OH) groups. Fatty acids have a long chain of hydrocarbons to which an acidic carboxyl group is attached, hence the name “fatty acid.” The number of carbons in the fatty acid may range from 4 to 36; most common are those containing 12–18 carbons. In a fat molecule, a fatty acid is attached to each of the three oxygen atoms in the –OH groups of the glycerol molecule with a covalent bond.
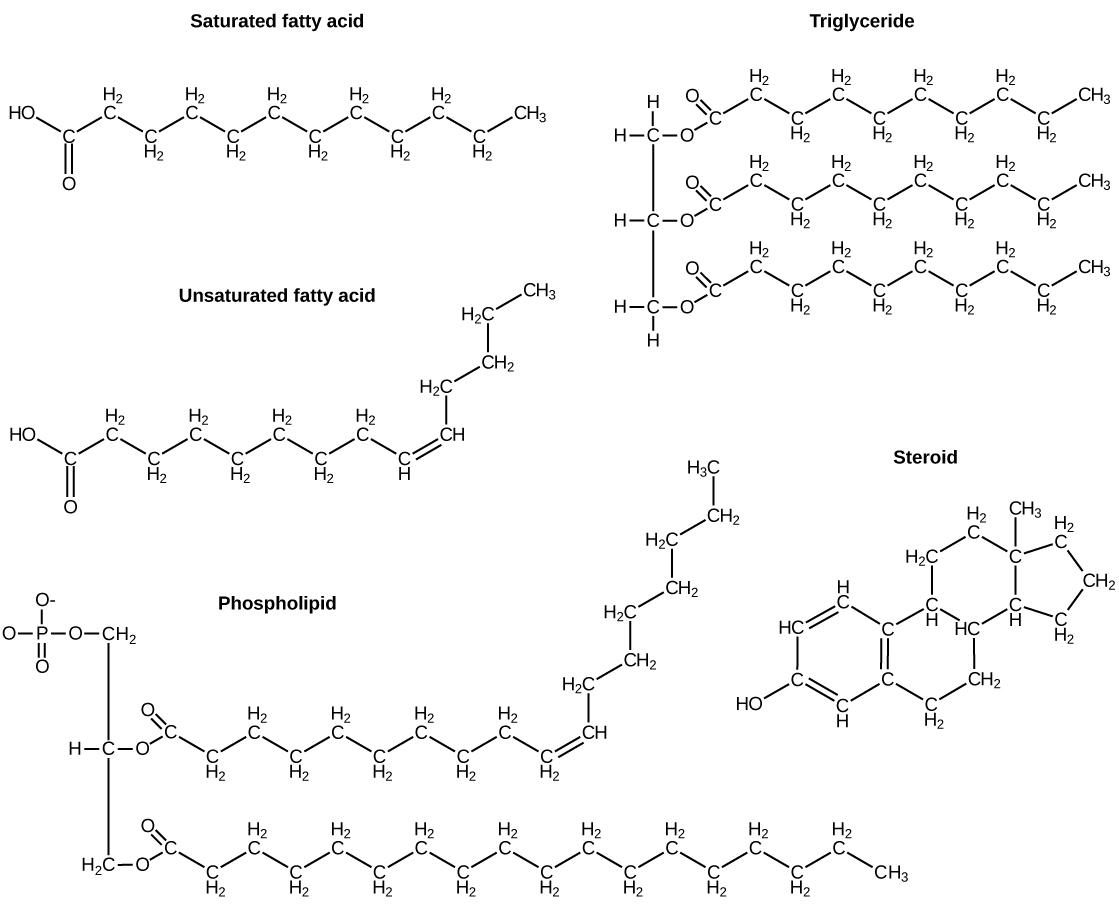
During this covalent bond formation, three water molecules are released. The three fatty acids in the fat may be similar or dissimilar. These fats are also called triglycerides because they have three fatty acids. Some fatty acids have common names that specify their origin. For example, palmitic acid, a saturated fatty acid, is derived from the palm tree. Arachidic acid is derived from Arachis hypogaea, the scientific name for peanuts.
Fatty acids may be saturated or unsaturated. In a fatty acid chain, if there are only single bonds between neighboring carbons in the hydrocarbon chain, the fatty acid is saturated. Saturated fatty acids are saturated with hydrogen; in other words, the number of hydrogen atoms attached to the carbon skeleton is maximized.
When the hydrocarbon chain contains a double bond, the fatty acid is an unsaturated fatty acid.
Most unsaturated fats are liquid at room temperature and are called oils. If there is one double bond in the molecule, then it is known as a monounsaturated fat (e.g., olive oil), and if there is more than one double bond, then it is known as a polyunsaturated fat (e.g., canola oil).
Saturated fats tend to get packed tightly and are solid at room temperature. Animal fats with stearic acid and palmitic acid contained in meat, and the fat with butyric acid contained in butter, are examples of saturated fats. Mammals store fats in specialized cells called adipocytes, where globules of fat occupy most of the cell. In plants, fat or oil is stored in seeds and is used as a source of energy during embryonic development.
Unsaturated fats or oils are usually of plant origin and contain unsaturated fatty acids. The double bond causes a bend or a “kink” that prevents the fatty acids from packing tightly, keeping them liquid at room temperature. Olive oil, corn oil, canola oil, and cod liver oil are examples of unsaturated fats. Unsaturated fats help to improve blood cholesterol levels, whereas saturated fats contribute to plaque formation in the arteries, which increases the risk of a heart attack.
In the food industry, oils are artificially hydrogenated to make them semi-solid, leading to less spoilage and increased shelf life. Simply speaking, hydrogen gas is bubbled through oils to solidify them. During this hydrogenation process, double bonds of the cis-conformation in the hydrocarbon chain may be converted to double bonds in the trans-conformation. This forms a trans-fat from a cis-fat. The orientation of the double bonds affects the chemical properties of the fat.
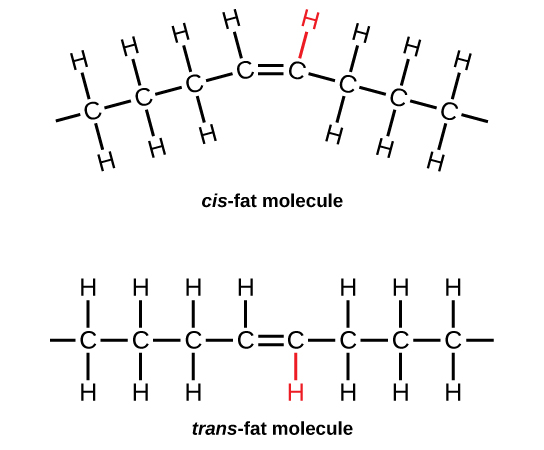
Margarine, some types of peanut butter, and shortening are examples of artificially hydrogenated trans-fats. Recent studies have shown that an increase in trans-fats in the human diet may lead to an increase in levels of low-density lipoprotein (LDL), or “bad” cholesterol, which, in turn, may lead to plaque deposition in the arteries, resulting in heart disease. Many fast food restaurants have recently eliminated the use of trans-fats, and U.S. food labels are now required to list their trans-fat content.
Essential fatty acids are fatty acids that are required but not synthesized by the human body. Consequently, they must be supplemented through the diet. Omega-3 fatty acids fall into this category and are one of only two known essential fatty acids for humans (the other being omega-6 fatty acids). They are a type of polyunsaturated fat and are called omega-3 fatty acids because the third carbon from the end of the fatty acid participates in a double bond.
Salmon, trout, and tuna are good sources of omega-3 fatty acids. Omega-3 fatty acids are important in brain function and normal growth and development. They may also prevent heart disease and reduce the risk of cancer.
Like carbohydrates, fats have received a lot of bad publicity. It is true that eating an excess of fried foods and other “fatty” foods leads to weight gain. However, fats do have important functions. Fats serve as long-term energy storage. They also provide insulation for the body. Therefore, “healthy” unsaturated fats in moderate amounts should be consumed on a regular basis.
Phospholipids are the major constituent of the plasma membrane. Like fats, they are composed of fatty acid chains attached to a glycerol or similar backbone. Instead of three fatty acids attached, however, there are two fatty acids and the third carbon of the glycerol backbone is bound to a phosphate group. The phosphate group is modified by the addition of an alcohol.
A phospholipid has both hydrophobic and hydrophilic regions. The fatty acid chains are hydrophobic and exclude themselves from water, whereas the phosphate is hydrophilic and interacts with water.
Cells are surrounded by a membrane, which has a bilayer of phospholipids. The fatty acids of phospholipids face inside, away from water, whereas the phosphate group can face either the outside environment or the inside of the cell, which are both aqueous.
For the First peoples of the Pacific Northwest the fat rich fish ooligan, with 20% fat by body weight, was a crucial part of the diet of several First Nations. Why? Because fat is the most calorie dense food and having a storable, high calorie compact energy source would be important to survival. The nature of its fat also made it an important trade good. Like salmon, ooligan returns to its birth stream after years at sea. Its arrival in the early spring made it the first fresh food of the year. In the Tsimshianic languages the arrival of the ooligan … was traditionally announced with the cry, ‘Hlaa aat’ixshi halimootxw!’ … meaning ‘Our Saviour has just arrived!’

As you learned above all fats are hydrophobic (water hating). To isolate the fat, the fish is boiled and the floating fat skimmed off. Ooligan fat composition is 30% saturated fat (like butter) and 55% monounsaturated fat (like plant oils). Importantly it is a solid grease at room temperature. Because it is low in polyunsaturated fats (which oxidize and spoil quickly) it can be stored for later use and used as a trade item. Its composition is said to make it as healthy as olive oil, or better as it has omega 3 fatty acids that reduce risk for diabetes and stroke. It also is rich in three fat soluble vitamins A, E and K.
Unlike the phospholipids and fats discussed earlier, steroids have a ring structure. Although they do not resemble other lipids, they are grouped with them because they are also hydrophobic. All steroids have four, linked carbon rings and several of them, like cholesterol, have a short tail.
Cholesterol is a steroid. Cholesterol is mainly synthesized in the liver and is the precursor of many steroid hormones, such as testosterone and estradiol. It is also the precursor of vitamins E and K. Cholesterol is the precursor of bile salts, which help in the breakdown of fats and their subsequent absorption by cells. Although cholesterol is often spoken of in negative terms, it is necessary for the proper functioning of the body. It is a key component of the plasma membranes of animal cells.
Waxes are made up of a hydrocarbon chain with an alcohol (–OH) group and a fatty acid. Examples of animal waxes include beeswax and lanolin. Plants also have waxes, such as the coating on their leaves, that helps prevent them from drying out.

For an additional perspective on lipids, explore “Biomolecules: The Lipids” through this interactive animation.
Proteins are one of the most abundant organic molecules in living systems and have the most diverse range of functions of all macromolecules. Proteins may be structural, regulatory, contractile, or protective; they may serve in transport, storage, or membranes; or they may be toxins or enzymes. Each cell in a living system may contain thousands of different proteins, each with a unique function. Their structures, like their functions, vary greatly. They are all, however, polymers of amino acids, arranged in a linear sequence.
The functions of proteins are very diverse because there are 20 different chemically distinct amino acids that form long chains, and the amino acids can be in any order. For example, proteins can function as enzymes or hormones. Enzymes, which are produced by living cells, are catalysts in biochemical reactions (like digestion) and are usually proteins. Each enzyme is specific for the substrate (a reactant that binds to an enzyme) upon which it acts. Enzymes can function to break molecular bonds, to rearrange bonds, or to form new bonds. An example of an enzyme is salivary amylase, which breaks down amylose, a component of starch.
Hormones are chemical signaling molecules, usually proteins or steroids, secreted by an endocrine gland or group of endocrine cells that act to control or regulate specific physiological processes, including growth, development, metabolism, and reproduction. For example, insulin is a protein hormone that maintains blood glucose levels.
Proteins have different shapes and molecular weights; some proteins are globular in shape whereas others are fibrous in nature. For example, hemoglobin is a globular protein, but collagen, found in our skin, is a fibrous protein. Protein shape is critical to its function. Changes in temperature, pH, and exposure to chemicals may lead to permanent changes in the shape of the protein, leading to a loss of function or denaturation (to be discussed in more detail later). All proteins are made up of different arrangements of the same 20 kinds of amino acids.
Amino acids are the monomers that make up proteins. Each amino acid has the same fundamental structure, which consists of a central carbon atom bonded to an amino group (–NH2), a carboxyl group (–COOH), and a hydrogen atom. Every amino acid also has another variable atom or group of atoms bonded to the central carbon atom known as the R group. The R group is the only difference in structure between the 20 amino acids; otherwise, the amino acids are identical.
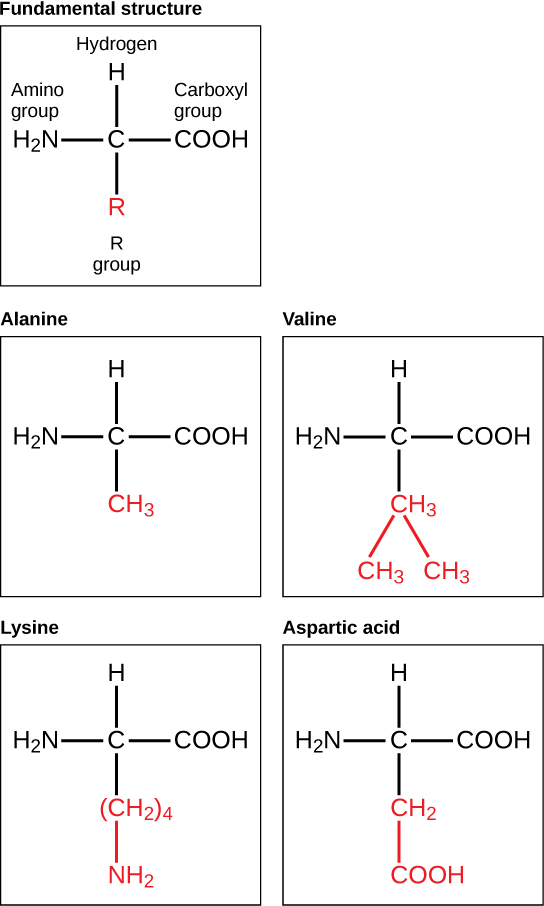
The chemical nature of the R group determines the chemical nature of the amino acid within its protein (that is, whether it is acidic, basic, polar, or nonpolar).
The sequence and number of amino acids ultimately determine a protein’s shape, size, and function. Each amino acid is attached to another amino acid by a covalent bond, known as a peptide bond, which is formed by a dehydration reaction. The carboxyl group of one amino acid and the amino group of a second amino acid combine, releasing a water molecule. The resulting bond is the peptide bond.
The products formed by such a linkage are called polypeptides. While the terms polypeptide and protein are sometimes used interchangeably, a polypeptide is technically a polymer of amino acids, whereas the term protein is used for a polypeptide or polypeptides that have combined together, have a distinct shape, and have a unique function.
The Evolutionary Significance of Cytochrome cCytochrome c is an important component of the molecular machinery that harvests energy from glucose. Because this protein’s role in producing cellular energy is crucial, it has changed very little over millions of years. Protein sequencing has shown that there is a considerable amount of sequence similarity among cytochrome c molecules of different species; evolutionary relationships can be assessed by measuring the similarities or differences among various species’ protein sequences.
For example, scientists have determined that human cytochrome c contains 104 amino acids. For each cytochrome c molecule that has been sequenced to date from different organisms, 37 of these amino acids appear in the same position in each cytochrome c. This indicates that all of these organisms are descended from a common ancestor. On comparing the human and chimpanzee protein sequences, no sequence difference was found. When human and rhesus monkey sequences were compared, a single difference was found in one amino acid. In contrast, human-to-yeast comparisons show a difference in 44 amino acids, suggesting that humans and chimpanzees have a more recent common ancestor than humans and the rhesus monkey, or humans and yeast.
As discussed earlier, the shape of a protein is critical to its function. To understand how the protein gets its final shape or conformation, we need to understand the four levels of protein structure: primary, secondary, tertiary, and quaternary.
The unique sequence and number of amino acids in a polypeptide chain is its primary structure. The unique sequence for every protein is ultimately determined by the gene that encodes the protein. Any change in the gene sequence may lead to a different amino acid being added to the polypeptide chain, causing a change in protein structure and function. In sickle cell anemia, the hemoglobin β chain has a single amino acid substitution, causing a change in both the structure and function of the protein. What is most remarkable to consider is that a hemoglobin molecule is made up of two alpha chains and two beta chains that each consist of about 150 amino acids. The molecule, therefore, has about 600 amino acids. The structural difference between a normal hemoglobin molecule and a sickle cell molecule—that dramatically decreases life expectancy in the affected individuals—is a single amino acid of the 600.
Because of this change of one amino acid in the chain, the normally biconcave, or disc-shaped, red blood cells assume a crescent or “sickle” shape, which clogs arteries. This can lead to a myriad of serious health problems, such as breathlessness, dizziness, headaches, and abdominal pain for those who have this disease.
Folding patterns resulting from interactions between the non-R group portions of amino acids give rise to the secondary structure of the protein. The most common are the alpha (α)-helix and beta (β)-pleated sheet structures. Both structures are held in shape by hydrogen bonds. In the alpha helix, the bonds form between every fourth amino acid and cause a twist in the amino acid chain.
In the β-pleated sheet, the “pleats” are formed by hydrogen bonding between atoms on the backbone of the polypeptide chain. The R groups are attached to the carbons, and extend above and below the folds of the pleat. The pleated segments align parallel to each other, and hydrogen bonds form between the same pairs of atoms on each of the aligned amino acids. The α-helix and β-pleated sheet structures are found in many globular and fibrous proteins.
The unique three-dimensional structure of a polypeptide is known as its tertiary structure. This structure is caused by chemical interactions between various amino acids and regions of the polypeptide. Primarily, the interactions among R groups create the complex three-dimensional tertiary structure of a protein. There may be ionic bonds formed between R groups on different amino acids, or hydrogen bonding beyond that involved in the secondary structure. When protein folding takes place, the hydrophobic R groups of nonpolar amino acids lay in the interior of the protein, whereas the hydrophilic R groups lay on the outside. The former types of interactions are also known as hydrophobic interactions.
In nature, some proteins are formed from several polypeptides, also known as subunits, and the interaction of these subunits forms the quaternary structure. Weak interactions between the subunits help to stabilize the overall structure. For example, hemoglobin is a combination of four polypeptide subunits.

Each protein has its own unique sequence and shape held together by chemical interactions. If the protein is subject to changes in temperature, pH, or exposure to chemicals, the protein structure may change, losing its shape in what is known as denaturation as discussed earlier. Denaturation is often reversible because the primary structure is preserved if the denaturing agent is removed, allowing the protein to resume its function. Sometimes denaturation is irreversible, leading to a loss of function. One example of protein denaturation can be seen when an egg is fried or boiled. The albumin protein in the liquid egg white is denatured when placed in a hot pan, changing from a clear substance to an opaque white substance. Not all proteins are denatured at high temperatures; for instance, bacteria that survive in hot springs have proteins that are adapted to function at those temperatures.

For an additional perspective on proteins, explore “Biomolecules: The Proteins” through this interactive animation.
Nucleic acids are key macromolecules in the continuity of life. They carry the genetic blueprint of a cell and carry instructions for the functioning of the cell.
The two main types of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA is the genetic material found in all living organisms, ranging from single-celled bacteria to multicellular mammals.
The other type of nucleic acid, RNA, is mostly involved in protein synthesis. The DNA molecules never leave the nucleus, but instead use an RNA intermediary to communicate with the rest of the cell. Other types of RNA are also involved in protein synthesis and its regulation.
DNA and RNA are made up of monomers known as nucleotides. The nucleotides combine with each other to form a polynucleotide, DNA or RNA. Each nucleotide is made up of three components: a nitrogenous base, a pentose (five-carbon) sugar, and a phosphate group . Each nitrogenous base in a nucleotide is attached to a sugar molecule, which is attached to a phosphate group.
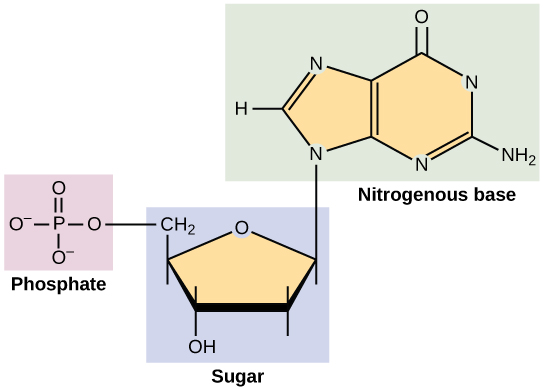
DNA has a double-helical structure. It is composed of two strands, or polymers, of nucleotides. The strands are formed with bonds between phosphate and sugar groups of adjacent nucleotides. The strands are bonded to each other at their bases with hydrogen bonds, and the strands coil about each other along their length, hence the “double helix” description, which means a double spiral.

The alternating sugar and phosphate groups lie on the outside of each strand, forming the backbone of the DNA. The nitrogenous bases are stacked in the interior, like the steps of a staircase, and these bases pair; the pairs are bound to each other by hydrogen bonds. The bases pair in such a way that the distance between the backbones of the two strands is the same all along the molecule. The rule is that nucleotide A pairs with nucleotide T, and G with C, see section 9.1 for more details.
Living things are carbon-based because carbon plays such a prominent role in the chemistry of living things. The four covalent bonding positions of the carbon atom can give rise to a wide diversity of compounds with many functions, accounting for the importance of carbon in living things. Carbohydrates are a group of macromolecules that are a vital energy source for the cell, provide structural support to many organisms, and can be found on the surface of the cell as receptors or for cell recognition. Carbohydrates are classified as monosaccharides, disaccharides, and polysaccharides, depending on the number of monomers in the molecule.
Lipids are a class of macromolecules that are nonpolar and hydrophobic in nature. Major types include fats and oils, waxes, phospholipids, and steroids. Fats and oils are a stored form of energy and can include triglycerides. Fats and oils are usually made up of fatty acids and glycerol.
Proteins are a class of macromolecules that can perform a diverse range of functions for the cell. They help in metabolism by providing structural support and by acting as enzymes, carriers or as hormones. The building blocks of proteins are amino acids. Proteins are organized at four levels: primary, secondary, tertiary, and quaternary. Protein shape and function are intricately linked; any change in shape caused by changes in temperature, pH, or chemical exposure may lead to protein denaturation and a loss of function.
Nucleic acids are molecules made up of repeating units of nucleotides that direct cellular activities such as cell division and protein synthesis. Each nucleotide is made up of a pentose sugar, a nitrogenous base, and a phosphate group. There are two types of nucleic acids: DNA and RNA.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=83#h5p-15
amino acid: a monomer of a protein
carbohydrate: a biological macromolecule in which the ratio of carbon to hydrogen to oxygen is 1:2:1; carbohydrates serve as energy sources and structural support in cells
cellulose: a polysaccharide that makes up the cell walls of plants and provides structural support to the cell
chitin: a type of carbohydrate that forms the outer skeleton of arthropods, such as insects and crustaceans, and the cell walls of fungi
denaturation: the loss of shape in a protein as a result of changes in temperature, pH, or exposure to chemicals
deoxyribonucleic acid (DNA): a double-stranded polymer of nucleotides that carries the hereditary information of the cell
disaccharide: two sugar monomers that are linked together by a peptide bond
enzyme: a catalyst in a biochemical reaction that is usually a complex or conjugated protein
fat: a lipid molecule composed of three fatty acids and a glycerol (triglyceride) that typically exists in a solid form at room temperature
glycogen: a storage carbohydrate in animals
hormone: a chemical signaling molecule, usually a protein or steroid, secreted by an endocrine gland or group of endocrine cells; acts to control or regulate specific physiological processes
lipids: a class of macromolecules that are nonpolar and insoluble in water
macromolecule: a large molecule, often formed by polymerization of smaller monomers
monosaccharide: a single unit or monomer of carbohydrates
nucleic acid: a biological macromolecule that carries the genetic information of a cell and carries instructions for the functioning of the cell
nucleotide: a monomer of nucleic acids; contains a pentose sugar, a phosphate group, and a nitrogenous base
oil: an unsaturated fat that is a liquid at room temperature
phospholipid: a major constituent of the membranes of cells; composed of two fatty acids and a phosphate group attached to the glycerol backbone
polypeptide: a long chain of amino acids linked by peptide bonds
polysaccharide: a long chain of monosaccharides; may be branched or unbranched
protein: a biological macromolecule composed of one or more chains of amino acids
ribonucleic acid (RNA): a single-stranded polymer of nucleotides that is involved in protein synthesis
saturated fatty acid: a long-chain hydrocarbon with single covalent bonds in the carbon chain; the number of hydrogen atoms attached to the carbon skeleton is maximized
starch: a storage carbohydrate in plants
steroid: a type of lipid composed of four fused hydrocarbon rings
trans-fat: a form of unsaturated fat with the hydrogen atoms neighboring the double bond across from each other rather than on the same side of the double bond
triglyceride: a fat molecule; consists of three fatty acids linked to a glycerol molecule
unsaturated fatty acid: a long-chain hydrocarbon that has one or more than one double bonds in the hydrocarbon chain

Your body has many kinds of cells, each specialized for a specific purpose. Just as a home is made from a variety of building materials, the human body is constructed from many cell types. For example, epithelial cells protect the surface of the body and cover the organs and body cavities within. Bone cells help to support and protect the body. Cells of the immune system fight invading bacteria. Additionally, red blood cells carry oxygen throughout the body. Each of these cell types plays a vital role during the growth, development, and day-to-day maintenance of the body. In spite of their enormous variety, however, all cells share certain fundamental characteristics.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=86#h5p-16
By the end of this section, you will be able to:
Watch a video about eukaryotic cells
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=93#h5p-17
Watch a video about diffusion
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=93#h5p-18
A cell is the smallest unit of a living thing. A living thing, like you, is called an organism. Thus, cells are the basic building blocks of all organisms.
In multicellular organisms, several cells of one particular kind interconnect with each other and perform shared functions to form tissues (for example, muscle tissue, connective tissue, and nervous tissue), several tissues combine to form an organ (for example, stomach, heart, or brain), and several organs make up an organ system (such as the digestive system, circulatory system, or nervous system). Several systems functioning together form an organism (such as an elephant, for example).
There are many types of cells, and all are grouped into one of two broad categories: prokaryotic and eukaryotic. Animal cells, plant cells, fungal cells, and protist cells are classified as eukaryotic, whereas bacteria and archaea cells are classified as prokaryotic. Before discussing the criteria for determining whether a cell is prokaryotic or eukaryotic, let us first examine how biologists study cells.
Cells vary in size. With few exceptions, individual cells are too small to be seen with the naked eye, so scientists use microscopes to study them. A microscope is an instrument that magnifies an object. Most images of cells are taken with a microscope and are called micrographs.
To give you a sense of the size of a cell, a typical human red blood cell is about eight millionths of a meter or eight micrometers (abbreviated as µm) in diameter; the head of a pin is about two thousandths of a meter (millimeters, or mm) in diameter. That means that approximately 250 red blood cells could fit on the head of a pin.
The optics of the lenses of a light microscope changes the orientation of the image. A specimen that is right-side up and facing right on the microscope slide will appear upside-down and facing left when viewed through a microscope, and vice versa. Similarly, if the slide is moved left while looking through the microscope, it will appear to move right, and if moved down, it will seem to move up. This occurs because microscopes use two sets of lenses to magnify the image. Due to the manner in which light travels through the lenses, this system of lenses produces an inverted image (binoculars and a dissecting microscope work in a similar manner, but include an additional magnification system that makes the final image appear to be upright).
Most student microscopes are classified as light microscopes (Figure 3.2 a). Visible light both passes through and is bent by the lens system to enable the user to see the specimen. Light microscopes are advantageous for viewing living organisms, but since individual cells are generally transparent, their components are not distinguishable unless they are colored with special stains. Staining, however, usually kills the cells.
Light microscopes commonly used in the undergraduate college laboratory magnify up to approximately 400 times. Two parameters that are important in microscopy are magnification and resolving power. Magnification is the degree of enlargement of an object. Resolving power is the ability of a microscope to allow the eye to distinguish two adjacent structures as separate; the higher the resolution, the closer those two objects can be, and the better the clarity and detail of the image. When oil immersion lenses are used, magnification is usually increased to 1,000 times for the study of smaller cells, like most prokaryotic cells. Because light entering a specimen from below is focused onto the eye of an observer, the specimen can be viewed using light microscopy. For this reason, for light to pass through a specimen, the sample must be thin or translucent.
A second type of microscope used in laboratories is the dissecting microscope (Figure 3.2 b). These microscopes have a lower magnification (20 to 80 times the object size) than light microscopes and can provide a three-dimensional view of the specimen. Thick objects can be examined with many components in focus at the same time. These microscopes are designed to give a magnified and clear view of tissue structure as well as the anatomy of the whole organism. Like light microscopes, most modern dissecting microscopes are also binocular, meaning that they have two separate lens systems, one for each eye. The lens systems are separated by a certain distance, and therefore provide a sense of depth in the view of their subject to make manipulations by hand easier. Dissecting microscopes also have optics that correct the image so that it appears as if being seen by the naked eye and not as an inverted image. The light illuminating a sample under a dissecting microscope typically comes from above the sample, but may also be directed from below.

In contrast to light microscopes, electron microscopes use a beam of electrons instead of a beam of light. Not only does this allow for higher magnification and, thus, more detail (Figure 3.4), it also provides higher resolving power. Preparation of a specimen for viewing under an electron microscope will kill it; therefore, live cells cannot be viewed using this type of microscopy. In addition, the electron beam moves best in a vacuum, making it impossible to view living materials.
In a scanning electron microscope, a beam of electrons moves back and forth across a cell’s surface, rendering the details of cell surface characteristics by reflection. Cells and other structures are usually coated with a metal like gold. In a transmission electron microscope, the electron beam is transmitted through the cell and provides details of a cell’s internal structures. As you might imagine, electron microscopes are significantly more bulky and expensive than are light microscopes.
Cytotechnologist: Have you ever heard of a medical test called a Pap smear? In this test, a doctor takes a small sample of cells from the uterine cervix of a patient and sends it to a medical lab where a cytotechnologist stains the cells and examines them for any changes that could indicate cervical cancer or a microbial infection.
Cytotechnologists (cyto– = cell) are professionals who study cells through microscopic examinations and other laboratory tests. They are trained to determine which cellular changes are within normal limits or are abnormal. Their focus is not limited to cervical cells; they study cellular specimens that come from all organs. When they notice abnormalities, they consult a pathologist, who is a medical doctor who can make a clinical diagnosis.
Cytotechnologists play vital roles in saving people’s lives. When abnormalities are discovered early, a patient’s treatment can begin sooner, which usually increases the chances of successful treatment.
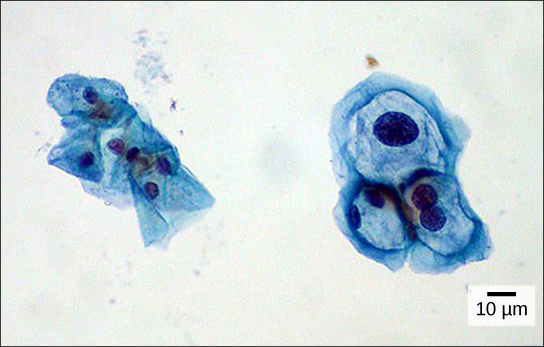
The microscopes we use today are far more complex than those used in the 1600s by Antony van Leeuwenhoek, a Dutch shopkeeper who had great skill in crafting lenses. Despite the limitations of his now-ancient lenses, van Leeuwenhoek observed the movements of protists (a type of single-celled organism) and sperm, which he collectively termed “animalcules.”
In a 1665 publication called Micrographia, experimental scientist Robert Hooke coined the term “cell” (from the Latin cella, meaning “small room”) for the box-like structures he observed when viewing cork tissue through a lens. In the 1670s, van Leeuwenhoek discovered bacteria and protozoa. Later advances in lenses and microscope construction enabled other scientists to see different components inside cells.
By the late 1830s, botanist Matthias Schleiden and zoologist Theodor Schwann were studying tissues and proposed the unified cell theory, which states that all living things are composed of one or more cells, that the cell is the basic unit of life, and that all new cells arise from existing cells. These principles still stand today.
A cell is the smallest unit of life. Most cells are so small that they cannot be viewed with the naked eye. Therefore, scientists must use microscopes to study cells. Electron microscopes provide higher magnification, higher resolution, and more detail than light microscopes. The unified cell theory states that all organisms are composed of one or more cells, the cell is the basic unit of life, and new cells arise from existing cells.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=93#h5p-19
microscope: the instrument that magnifies an object
unified cell theory: the biological concept that states that all organisms are composed of one or more cells, the cell is the basic unit of life, and new cells arise from existing cells
By the end of this section, you will be able to:
Cells fall into one of two broad categories: prokaryotic and eukaryotic. The predominantly single-celled organisms of the domains Bacteria and Archaea are classified as prokaryotes (pro– = before; –karyon– = nucleus). Animal cells, plant cells, fungi, and protists are eukaryotes (eu– = true).
All cells share four common components: 1) a plasma membrane, an outer covering that separates the cell’s interior from its surrounding environment; 2) cytoplasm, consisting of a jelly-like region within the cell in which other cellular components are found; 3) DNA, the genetic material of the cell; and 4) ribosomes, particles that synthesize proteins. However, prokaryotes differ from eukaryotic cells in several ways.
A prokaryotic cell is a simple, single-celled (unicellular) organism that lacks a nucleus, or any other membrane-bound organelle. We will shortly come to see that this is significantly different in eukaryotes. Prokaryotic DNA is found in the central part of the cell: a darkened region called the nucleoid.
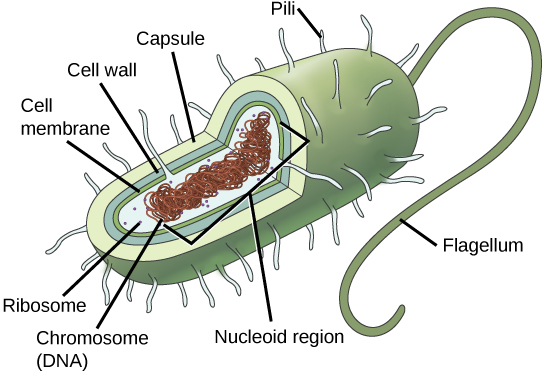
Unlike Archaea and eukaryotes, bacteria have a cell wall made of peptidoglycan, comprised of sugars and amino acids, and many have a polysaccharide capsule (Figure 3.6). The cell wall acts as an extra layer of protection, helps the cell maintain its shape, and prevents dehydration. The capsule enables the cell to attach to surfaces in its environment. Some prokaryotes have flagella, pili, or fimbriae. Flagella are used for locomotion, while most pili are used to exchange genetic material during a type of reproduction called conjugation.
In nature, the relationship between form and function is apparent at all levels, including the level of the cell, and this will become clear as we explore eukaryotic cells. The principle “form follows function” is found in many contexts. For example, birds and fish have streamlined bodies that allow them to move quickly through the medium in which they live, be it air or water. It means that, in general, one can deduce the function of a structure by looking at its form, because the two are matched.
A eukaryotic cell is a cell that has a membrane-bound nucleus and other membrane-bound compartments or sacs, called organelles, which have specialized functions. The word eukaryotic means “true kernel” or “true nucleus,” alluding to the presence of the membrane-bound nucleus in these cells. The word “organelle” means “little organ,” and, as already mentioned, organelles have specialized cellular functions, just as the organs of your body have specialized functions.
At 0.1–5.0 µm in diameter, prokaryotic cells are significantly smaller than eukaryotic cells, which have diameters ranging from 10–100 µm (Figure 3.7). The small size of prokaryotes allows ions and organic molecules that enter them to quickly spread to other parts of the cell. Similarly, any wastes produced within a prokaryotic cell can quickly move out. However, larger eukaryotic cells have evolved different structural adaptations to enhance cellular transport. Indeed, the large size of these cells would not be possible without these adaptations. In general, cell size is limited because volume increases much more quickly than does cell surface area. As a cell becomes larger, it becomes more and more difficult for the cell to acquire sufficient materials to support the processes inside the cell, because the relative size of the surface area across which materials must be transported declines.
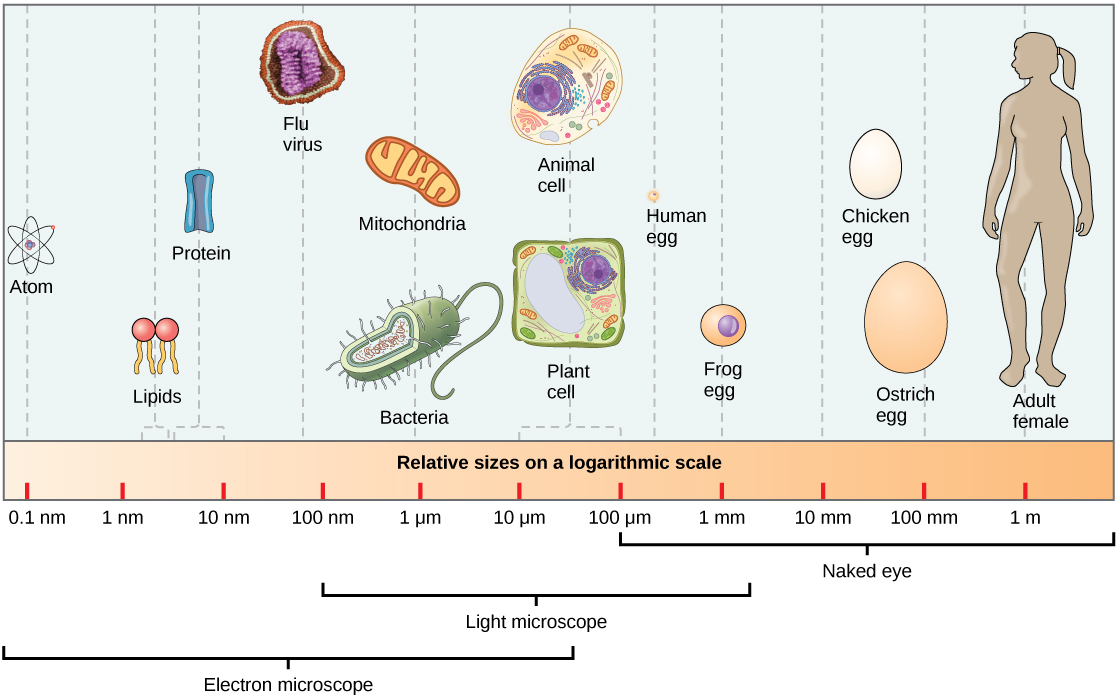
Prokaryotes are predominantly single-celled organisms of the domains Bacteria and Archaea. All prokaryotes have plasma membranes, cytoplasm, ribosomes, a cell wall, DNA, and lack membrane-bound organelles. Many also have polysaccharide capsules. Prokaryotic cells range in diameter from 0.1–5.0 µm.
Like a prokaryotic cell, a eukaryotic cell has a plasma membrane, cytoplasm, and ribosomes, but a eukaryotic cell is typically larger than a prokaryotic cell, has a true nucleus (meaning its DNA is surrounded by a membrane), and has other membrane-bound organelles that allow for compartmentalization of functions. Eukaryotic cells tend to be 10 to 100 times the size of prokaryotic cells.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=97#h5p-20
eukaryotic cell: a cell that has a membrane-bound nucleus and several other membrane-bound compartments or sacs
organelle: a membrane-bound compartment or sac within a cell
prokaryotic cell: a unicellular organism that lacks a nucleus or any other membrane-bound organelle
By the end of this section, you will be able to:
Watch a video about oxygen in the atmosphere.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=113#h5p-21
At this point, it should be clear that eukaryotic cells have a more complex structure than do prokaryotic cells. Organelles allow for various functions to occur in the cell at the same time. Before discussing the functions of organelles within a eukaryotic cell, let us first examine two important components of the cell: the plasma membrane and the cytoplasm.
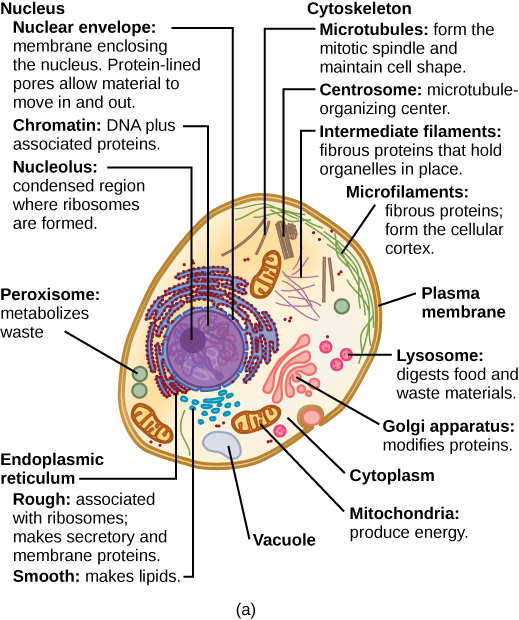
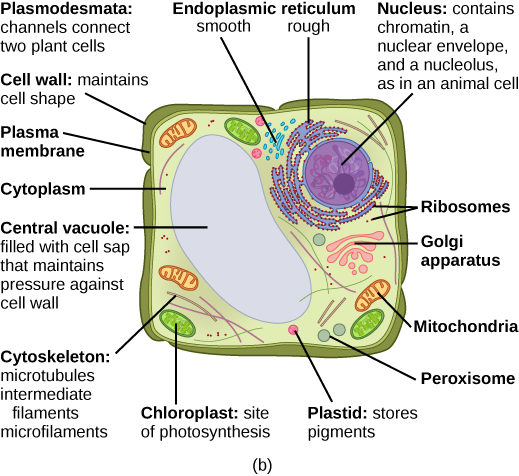
What structures does a plant cell have that an animal cell does not have? What structures does an animal cell have that a plant cell does not have? Plant cells have plasmodesmata, a cell wall, a large central vacuole, chloroplasts, and plastids. Animal cells have lysosomes and centrosomes.
Like prokaryotes, eukaryotic cells have a plasma membrane (Figure 3.9) made up of a phospholipid bilayer with embedded proteins that separates the internal contents of the cell from its surrounding environment. A phospholipid is a lipid molecule composed of two fatty acid chains, a glycerol backbone, and a phosphate group. The plasma membrane regulates the passage of some substances, such as organic molecules, ions, and water, preventing the passage of some to maintain internal conditions, while actively bringing in or removing others. Other compounds move passively across the membrane.

The plasma membranes of cells that specialize in absorption are folded into fingerlike projections called microvilli (singular = microvillus). This folding increases the surface area of the plasma membrane. Such cells are typically found lining the small intestine, the organ that absorbs nutrients from digested food. This is an excellent example of form matching the function of a structure.
People with celiac disease have an immune response to gluten, which is a protein found in wheat, barley, and rye. The immune response damages microvilli, and thus, afflicted individuals cannot absorb nutrients. This leads to malnutrition, cramping, and diarrhea. Patients suffering from celiac disease must follow a gluten-free diet.
The cytoplasm comprises the contents of a cell between the plasma membrane and the nuclear envelope (a structure to be discussed shortly). It is made up of organelles suspended in the gel-like cytosol, the cytoskeleton, and various chemicals. Even though the cytoplasm consists of 70 to 80 percent water, it has a semi-solid consistency, which comes from the proteins within it. However, proteins are not the only organic molecules found in the cytoplasm. Glucose and other simple sugars, polysaccharides, amino acids, nucleic acids, fatty acids, and derivatives of glycerol are found there too. Ions of sodium, potassium, calcium, and many other elements are also dissolved in the cytoplasm. Many metabolic reactions, including protein synthesis, take place in the cytoplasm.
If you were to remove all the organelles from a cell, would the plasma membrane and the cytoplasm be the only components left? No. Within the cytoplasm, there would still be ions and organic molecules, plus a network of protein fibers that helps to maintain the shape of the cell, secures certain organelles in specific positions, allows cytoplasm and vesicles to move within the cell, and enables unicellular organisms to move independently. Collectively, this network of protein fibers is known as the cytoskeleton. There are three types of fibers within the cytoskeleton: microfilaments, also known as actin filaments, intermediate filaments, and microtubules (Figure 3.10).
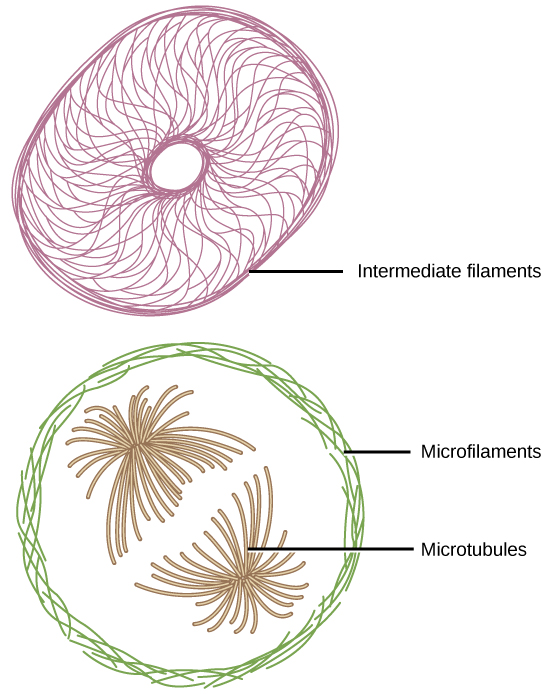
Microfilaments are the thinnest of the cytoskeletal fibers and function in moving cellular components, for example, during cell division. They also maintain the structure of microvilli, the extensive folding of the plasma membrane found in cells dedicated to absorption. These components are also common in muscle cells and are responsible for muscle cell contraction. Intermediate filaments are of intermediate diameter and have structural functions, such as maintaining the shape of the cell and anchoring organelles. Keratin, the compound that strengthens hair and nails, forms one type of intermediate filament. Microtubules are the thickest of the cytoskeletal fibers. These are hollow tubes that can dissolve and reform quickly. Microtubules guide organelle movement and are the structures that pull chromosomes to their poles during cell division. They are also the structural components of flagella and cilia. In cilia and flagella, the microtubules are organized as a circle of nine double microtubules on the outside and two microtubules in the center.
The centrosome is a region near the nucleus of animal cells that functions as a microtubule-organizing center. It contains a pair of centrioles, two structures that lie perpendicular to each other. Each centriole is a cylinder of nine triplets of microtubules.
The centrosome replicates itself before a cell divides, and the centrioles play a role in pulling the duplicated chromosomes to opposite ends of the dividing cell. However, the exact function of the centrioles in cell division is not clear, since cells that have the centrioles removed can still divide, and plant cells, which lack centrioles, are capable of cell division.
Flagella (singular = flagellum) are long, hair-like structures that extend from the plasma membrane and are used to move an entire cell, (for example, sperm, Euglena). When present, the cell has just one flagellum or a few flagella. When cilia (singular = cilium) are present, however, they are many in number and extend along the entire surface of the plasma membrane. They are short, hair-like structures that are used to move entire cells (such as paramecium) or move substances along the outer surface of the cell (for example, the cilia of cells lining the fallopian tubes that move the ovum toward the uterus, or cilia lining the cells of the respiratory tract that move particulate matter toward the throat that mucus has trapped).
The endomembrane system (endo = within) is a group of membranes and organelles in eukaryotic cells that work together to modify, package, and transport lipids and proteins. It includes the nuclear envelope, lysosomes, vesicles, endoplasmic reticulum and the Golgi apparatus, which we will cover shortly. Although not technically within the cell, the plasma membrane is included in the endomembrane system because, as you will see, it interacts with the other endomembranous organelles.
Typically, the nucleus is the most prominent organelle in a cell. The nucleus (plural = nuclei) houses the cell’s DNA in the form of chromatin and directs the synthesis of ribosomes and proteins. Let us look at it in more detail (Figure 3.11).
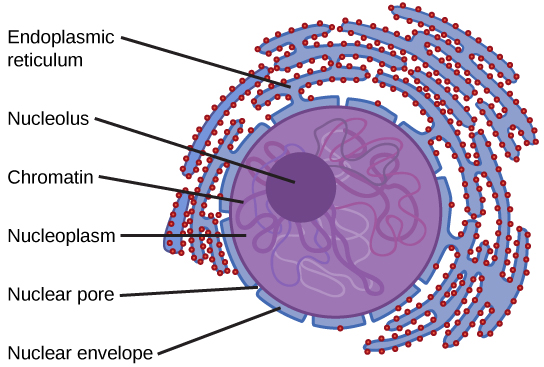
The nuclear envelope is a double-membrane structure that constitutes the outermost portion of the nucleus (Figure 3.11). Both the inner and outer membranes of the nuclear envelope are phospholipid bilayers.
The nuclear envelope is punctuated with pores that control the passage of ions, molecules, and RNA between the nucleoplasm and the cytoplasm.
To understand chromatin, it is helpful to first consider chromosomes. Chromosomes are structures within the nucleus that are made up of DNA, the hereditary material, and proteins. This combination of DNA and proteins is called chromatin. In eukaryotes, chromosomes are linear structures. Every species has a specific number of chromosomes in the nucleus of its body cells. For example, in humans, the chromosome number is 46, whereas in fruit flies, the chromosome number is eight.
Chromosomes are only visible and distinguishable from one another when the cell is getting ready to divide. When the cell is in the growth and maintenance phases of its life cycle, the chromosomes resemble an unwound, jumbled bunch of threads.
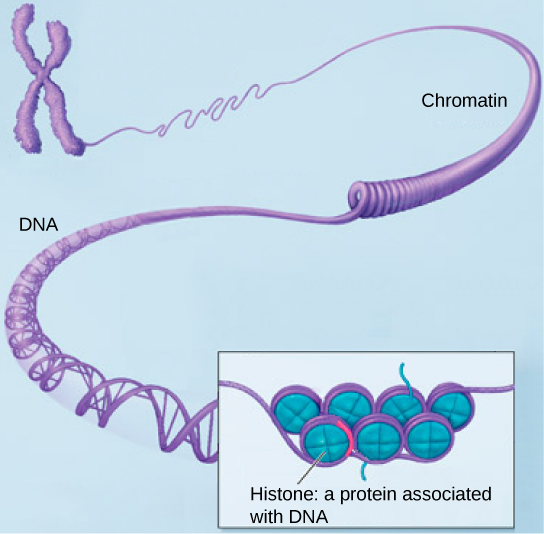
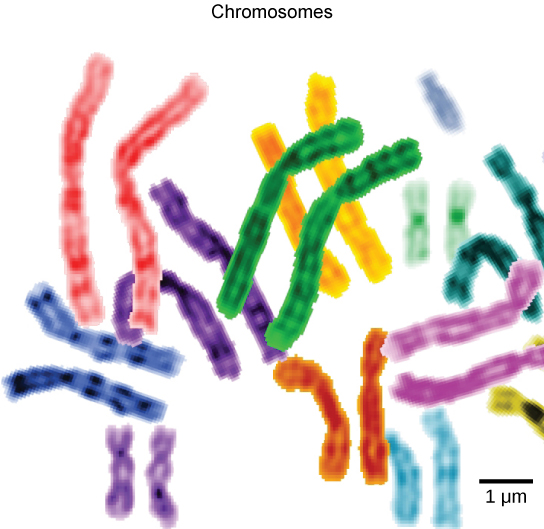
We already know that the nucleus directs the synthesis of ribosomes, but how does it do this? Some chromosomes have sections of DNA that encode ribosomal RNA. A darkly stained area within the nucleus, called the nucleolus (plural = nucleoli), aggregates the ribosomal RNA with associated proteins to assemble the ribosomal subunits that are then transported through the nuclear pores into the cytoplasm.
The endoplasmic reticulum (ER) is a series of interconnected membranous tubules that collectively modify proteins and synthesize lipids. However, these two functions are performed in separate areas of the endoplasmic reticulum: the rough endoplasmic reticulum and the smooth endoplasmic reticulum, respectively.
The hollow portion of the ER tubules is called the lumen or cisternal space. The membrane of the ER, which is a phospholipid bilayer embedded with proteins, is continuous with the nuclear envelope.
The rough endoplasmic reticulum (RER) is so named because the ribosomes attached to its cytoplasmic surface give it a studded appearance when viewed through an electron microscope.
The ribosomes synthesize proteins while attached to the ER, resulting in the transfer of their newly synthesized proteins into the lumen of the RER where they undergo modifications such as folding or addition of sugars. The RER also makes phospholipids for cell membranes.
If the phospholipids or modified proteins are not destined to stay in the RER, they will be packaged within vesicles and transported from the RER by budding from the membrane. Since the RER is engaged in modifying proteins that will be secreted from the cell, it is abundant in cells that secrete proteins, such as the liver.
The smooth endoplasmic reticulum (SER) is continuous with the RER but has few or no ribosomes on its cytoplasmic surface. The SER’s functions include synthesis of carbohydrates, lipids (including phospholipids), and steroid hormones; detoxification of medications and poisons; alcohol metabolism; and storage of calcium ions.
We have already mentioned that vesicles can bud from the ER, but where do the vesicles go? Before reaching their final destination, the lipids or proteins within the transport vesicles need to be sorted, packaged, and tagged so that they wind up in the right place. The sorting, tagging, packaging, and distribution of lipids and proteins take place in the Golgi apparatus (also called the Golgi body), a series of flattened membranous sacs.
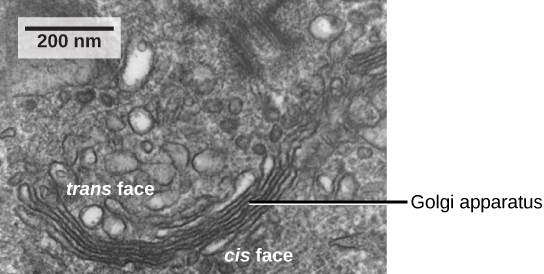
The Golgi apparatus has a receiving face near the endoplasmic reticulum and a releasing face on the side away from the ER, toward the cell membrane. The transport vesicles that form from the ER travel to the receiving face, fuse with it, and empty their contents into the lumen of the Golgi apparatus. As the proteins and lipids travel through the Golgi, they undergo further modifications. The most frequent modification is the addition of short chains of sugar molecules. The newly modified proteins and lipids are then tagged with small molecular groups to enable them to be routed to their proper destinations.
Finally, the modified and tagged proteins are packaged into vesicles that bud from the opposite face of the Golgi. While some of these vesicles, transport vesicles, deposit their contents into other parts of the cell where they will be used, others, secretory vesicles, fuse with the plasma membrane and release their contents outside the cell.
The amount of Golgi in different cell types again illustrates that form follows function within cells. Cells that engage in a great deal of secretory activity (such as cells of the salivary glands that secrete digestive enzymes or cells of the immune system that secrete antibodies) have an abundant number of Golgi.
In plant cells, the Golgi has an additional role of synthesizing polysaccharides, some of which are incorporated into the cell wall and some of which are used in other parts of the cell.
In animal cells, the lysosomes are the cell’s “garbage disposal.” Digestive enzymes within the lysosomes aid the breakdown of proteins, polysaccharides, lipids, nucleic acids, and even worn-out organelles. In single-celled eukaryotes, lysosomes are important for digestion of the food they ingest and the recycling of organelles. These enzymes are active at a much lower pH (more acidic) than those located in the cytoplasm. Many reactions that take place in the cytoplasm could not occur at a low pH, thus the advantage of compartmentalizing the eukaryotic cell into organelles is apparent.
Lysosomes also use their hydrolytic enzymes to destroy disease-causing organisms that might enter the cell. A good example of this occurs in a group of white blood cells called macrophages, which are part of your body’s immune system. In a process known as phagocytosis, a section of the plasma membrane of the macrophage invaginates (folds in) and engulfs a pathogen. The invaginated section, with the pathogen inside, then pinches itself off from the plasma membrane and becomes a vesicle. The vesicle fuses with a lysosome. The lysosome’s hydrolytic enzymes then destroy the pathogen (Figure 3.15).
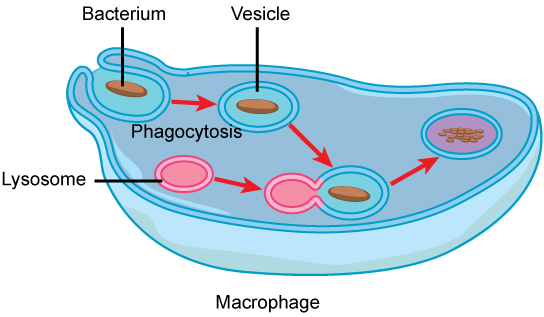
Vesicles and vacuoles are membrane-bound sacs that function in storage and transport. Vacuoles are somewhat larger than vesicles, and the membrane of a vacuole does not fuse with the membranes of other cellular components. Vesicles can fuse with other membranes within the cell system. Additionally, enzymes within plant vacuoles can break down macromolecules.
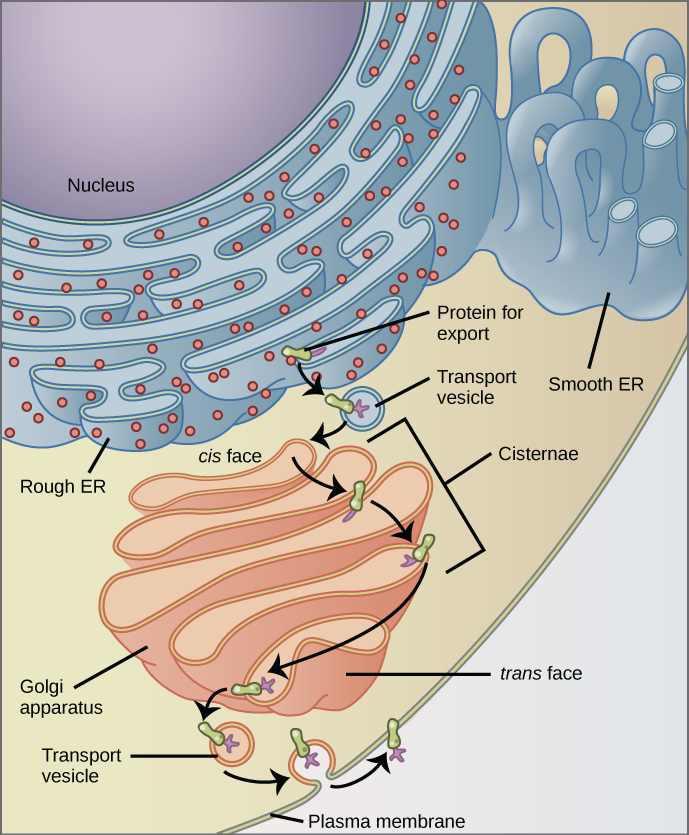
Why does the cis face of the Golgi not face the plasma membrane?
<!– Because that face receives chemicals from the ER, which is toward the center of the cell. –>
Ribosomes are the cellular structures responsible for protein synthesis. When viewed through an electron microscope, free ribosomes appear as either clusters or single tiny dots floating freely in the cytoplasm. Ribosomes may be attached to either the cytoplasmic side of the plasma membrane or the cytoplasmic side of the endoplasmic reticulum. Electron microscopy has shown that ribosomes consist of large and small subunits. Ribosomes are enzyme complexes that are responsible for protein synthesis.
Because protein synthesis is essential for all cells, ribosomes are found in practically every cell, although they are smaller in prokaryotic cells. They are particularly abundant in immature red blood cells for the synthesis of hemoglobin, which functions in the transport of oxygen throughout the body.
Mitochondria (singular = mitochondrion) are often called the “powerhouses” or “energy factories” of a cell because they are responsible for making adenosine triphosphate (ATP), the cell’s main energy-carrying molecule. The formation of ATP from the breakdown of glucose is known as cellular respiration. Mitochondria are oval-shaped, double-membrane organelles (Figure 3.17) that have their own ribosomes and DNA. Each membrane is a phospholipid bilayer embedded with proteins. The inner layer has folds called cristae, which increase the surface area of the inner membrane. The area surrounded by the folds is called the mitochondrial matrix. The cristae and the matrix have different roles in cellular respiration.
In keeping with our theme of form following function, it is important to point out that muscle cells have a very high concentration of mitochondria because muscle cells need a lot of energy to contract.
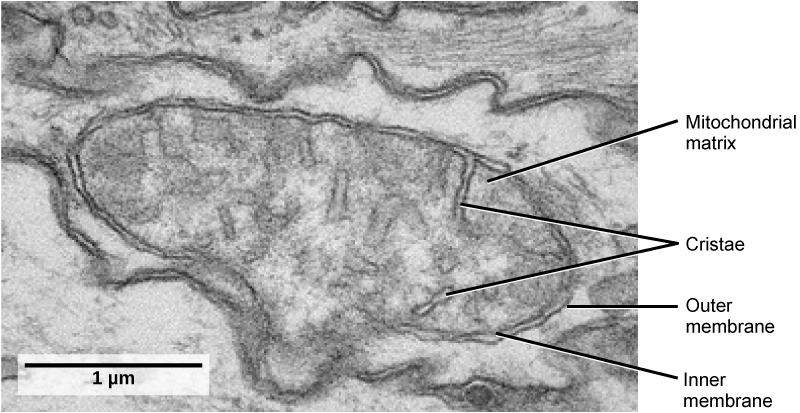
Peroxisomes are small, round organelles enclosed by single membranes. They carry out oxidation reactions that break down fatty acids and amino acids. They also detoxify many poisons that may enter the body. Alcohol is detoxified by peroxisomes in liver cells. A byproduct of these oxidation reactions is hydrogen peroxide, H2O2, which is contained within the peroxisomes to prevent the chemical from causing damage to cellular components outside of the organelle. Hydrogen peroxide is safely broken down by peroxisomal enzymes into water and oxygen.
Despite their fundamental similarities, there are some striking differences between animal and plant cells (see Table 3.1). Animal cells have centrioles, centrosomes (discussed under the cytoskeleton), and lysosomes, whereas plant cells do not. Plant cells have a cell wall, chloroplasts, plasmodesmata, and plastids used for storage, and a large central vacuole, whereas animal cells do not.
In Figure 3.8 b, the diagram of a plant cell, you see a structure external to the plasma membrane called the cell wall. The cell wall is a rigid covering that protects the cell, provides structural support, and gives shape to the cell. Fungal and protist cells also have cell walls.
While the chief component of prokaryotic cell walls is peptidoglycan, the major organic molecule in the plant cell wall is cellulose, a polysaccharide made up of long, straight chains of glucose units. When nutritional information refers to dietary fiber, it is referring to the cellulose content of food.
Like mitochondria, chloroplasts also have their own DNA and ribosomes. Chloroplasts function in photosynthesis and can be found in eukaryotic cells such as plants and algae. In photosynthesis, carbon dioxide, water, and light energy are used to make glucose and oxygen. This is the major difference between plants and animals: Plants (autotrophs) are able to make their own food, like glucose, whereas animals (heterotrophs) must rely on other organisms for their organic compounds or food source.
Like mitochondria, chloroplasts have outer and inner membranes, but within the space enclosed by a chloroplast’s inner membrane is a set of interconnected and stacked, fluid-filled membrane sacs called thylakoids (Figure 3.18). Each stack of thylakoids is called a granum (plural = grana). The fluid enclosed by the inner membrane and surrounding the grana is called the stroma.
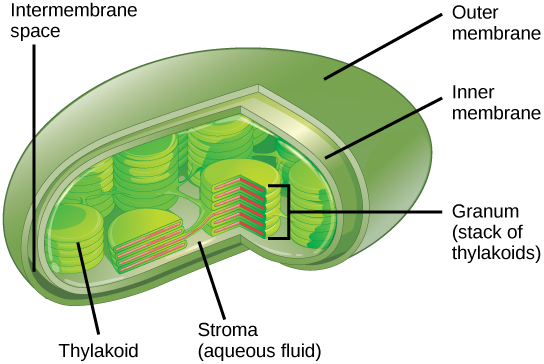
The chloroplasts contain a green pigment called chlorophyll, which captures the energy of sunlight for photosynthesis. Like plant cells, photosynthetic protists also have chloroplasts. Some bacteria also perform photosynthesis, but they do not have chloroplasts. Their photosynthetic pigments are located in the thylakoid membrane within the cell itself.
Endosymbiosis: We have mentioned that both mitochondria and chloroplasts contain DNA and ribosomes. Have you wondered why? Strong evidence points to endosymbiosis as the explanation.
Symbiosis is a relationship in which organisms from two separate species live in close association and typically exhibit specific adaptations to each other. Endosymbiosis (endo-= within) is a relationship in which one organism lives inside the other. Endosymbiotic relationships abound in nature. Microbes that produce vitamin K live inside the human gut. This relationship is beneficial for us because we are unable to synthesize vitamin K. It is also beneficial for the microbes because they are protected from other organisms and are provided a stable habitat and abundant food by living within the large intestine.
Scientists have long noticed that bacteria, mitochondria, and chloroplasts are similar in size. We also know that mitochondria and chloroplasts have DNA and ribosomes, just as bacteria do and they resemble the types found in bacteria. Scientists believe that host cells and bacteria formed a mutually beneficial endosymbiotic relationship when the host cells ingested aerobic bacteria and cyanobacteria but did not destroy them. Through evolution, these ingested bacteria became more specialized in their functions, with the aerobic bacteria becoming mitochondria and the photosynthetic bacteria becoming chloroplasts.
Previously, we mentioned vacuoles as essential components of plant cells. If you look at Figure 3.8 b, you will see that plant cells each have a large, central vacuole that occupies most of the cell. The central vacuole plays a key role in regulating the cell’s concentration of water in changing environmental conditions. In plant cells, the liquid inside the central vacuole provides turgor pressure, which is the outward pressure caused by the fluid inside the cell. Have you ever noticed that if you forget to water a plant for a few days, it wilts? That is because as the water concentration in the soil becomes lower than the water concentration in the plant, water moves out of the central vacuoles and cytoplasm and into the soil. As the central vacuole shrinks, it leaves the cell wall unsupported. This loss of support to the cell walls of a plant results in the wilted appearance. Additionally, this fluid has a very bitter taste, which discourages consumption by insects and animals. The central vacuole also functions to store proteins in developing seed cells.
Most animal cells release materials into the extracellular space. The primary components of these materials are glycoproteins and the protein collagen. Collectively, these materials are called the extracellular matrix (Figure 3.19). Not only does the extracellular matrix hold the cells together to form a tissue, but it also allows the cells within the tissue to communicate with each other.
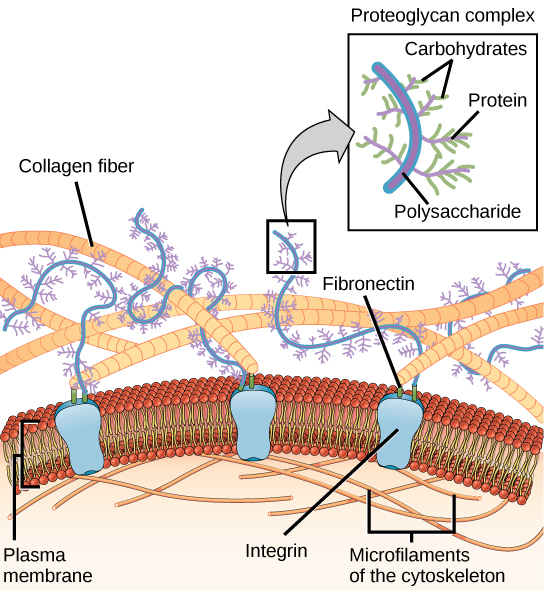
Blood clotting provides an example of the role of the extracellular matrix in cell communication. When the cells lining a blood vessel are damaged, they display a protein receptor called tissue factor. When tissue factor binds with another factor in the extracellular matrix, it causes platelets to adhere to the wall of the damaged blood vessel, stimulates adjacent smooth muscle cells in the blood vessel to contract (thus constricting the blood vessel), and initiates a series of steps that stimulate the platelets to produce clotting factors.
Cells can also communicate with each other by direct contact, referred to as intercellular junctions. There are some differences in the ways that plant and animal cells do this. Plasmodesmata (singular = plasmodesma) are junctions between plant cells, whereas animal cell contacts include tight and gap junctions, and desmosomes.
In general, long stretches of the plasma membranes of neighboring plant cells cannot touch one another because they are separated by the cell walls surrounding each cell. Plasmodesmata are numerous channels that pass between the cell walls of adjacent plant cells, connecting their cytoplasm and enabling signal molecules and nutrients to be transported from cell to cell (Figure 3.20 a).
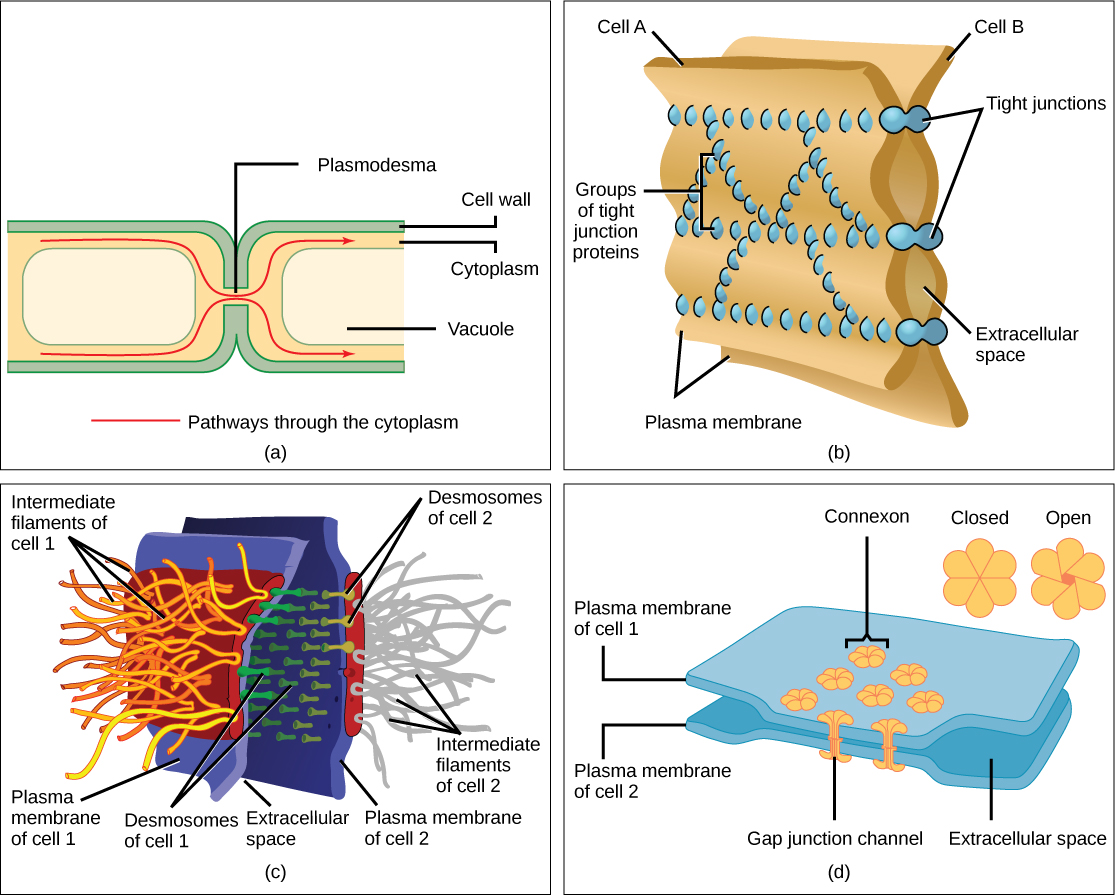
A tight junction is a watertight seal between two adjacent animal cells (Figure 3.20 b). Proteins hold the cells tightly against each other. This tight adhesion prevents materials from leaking between the cells. Tight junctions are typically found in the epithelial tissue that lines internal organs and cavities, and composes most of the skin. For example, the tight junctions of the epithelial cells lining the urinary bladder prevent urine from leaking into the extracellular space.
Also found only in animal cells are desmosomes, which act like spot welds between adjacent epithelial cells (Figure 3.20 c). They keep cells together in a sheet-like formation in organs and tissues that stretch, like the skin, heart, and muscles.
Gap junctions in animal cells are like plasmodesmata in plant cells in that they are channels between adjacent cells that allow for the transport of ions, nutrients, and other substances that enable cells to communicate (Figure 3.20 d). Structurally, however, gap junctions and plasmodesmata differ.
Cell Component | Function | Present in Prokaryotes? | Present in Animal Cells? | Present in Plant Cells? |
|---|---|---|---|---|
| Plasma membrane | Separates cell from external environment; controls passage of organic molecules, ions, water, oxygen, and wastes into and out of the cell | Yes | Yes | Yes |
| Cytoplasm | Provides structure to cell; site of many metabolic reactions; medium in which organelles are found | Yes | Yes | Yes |
| Nucleoid | Location of DNA | Yes | No | No |
| Nucleus | Cell organelle that houses DNA and directs synthesis of ribosomes and proteins | No | Yes | Yes |
| Ribosomes | Protein synthesis | Yes | Yes | Yes |
| Mitochondria | ATP production/cellular respiration | No | Yes | Yes |
| Peroxisomes | Oxidizes and breaks down fatty acids and amino acids, and detoxifies poisons | No | Yes | Yes |
| Vesicles and vacuoles | Storage and transport; digestive function in plant cells | No | Yes | Yes |
| Centrosome | Unspecified role in cell division in animal cells; organizing center of microtubules in animal cells | No | Yes | No |
| Lysosomes | Digestion of macromolecules; recycling of worn-out organelles | No | Yes | No |
| Cell wall | Protection, structural support and maintenance of cell shape | Yes, primarily peptidoglycan in bacteria but not Archaea | No | Yes, primarily cellulose |
| Chloroplasts | Photosynthesis | No | No | Yes |
| Endoplasmic reticulum | Modifies proteins and synthesizes lipids | No | Yes | Yes |
| Golgi apparatus | Modifies, sorts, tags, packages, and distributes lipids and proteins | No | Yes | Yes |
| Cytoskeleton | Maintains cell’s shape, secures organelles in specific positions, allows cytoplasm and vesicles to move within the cell, and enables unicellular organisms to move independently | Yes | Yes | Yes |
| Flagella | Cellular locomotion | Some | Some | No, except for some plant sperm. |
| Cilia | Cellular locomotion, movement of particles along extracellular surface of plasma membrane, and filtration | No | Some | No |
Section Summary
Like a prokaryotic cell, a eukaryotic cell has a plasma membrane, cytoplasm, and ribosomes, but a eukaryotic cell is typically larger than a prokaryotic cell, has a true nucleus (meaning its DNA is surrounded by a membrane), and has other membrane-bound organelles that allow for compartmentalization of functions. The plasma membrane is a phospholipid bilayer embedded with proteins. The nucleolus within the nucleus is the site for ribosome assembly. Ribosomes are found in the cytoplasm or are attached to the cytoplasmic side of the plasma membrane or endoplasmic reticulum. They perform protein synthesis. Mitochondria perform cellular respiration and produce ATP. Peroxisomes break down fatty acids, amino acids, and some toxins. Vesicles and vacuoles are storage and transport compartments. In plant cells, vacuoles also help break down macromolecules.
Animal cells also have a centrosome and lysosomes. The centrosome has two bodies, the centrioles, with an unknown role in cell division. Lysosomes are the digestive organelles of animal cells.
Plant cells have a cell wall, chloroplasts, and a central vacuole. The plant cell wall, whose primary component is cellulose, protects the cell, provides structural support, and gives shape to the cell. Photosynthesis takes place in chloroplasts. The central vacuole expands, enlarging the cell without the need to produce more cytoplasm.
The endomembrane system includes the nuclear envelope, the endoplasmic reticulum, Golgi apparatus, lysosomes, vesicles, as well as the plasma membrane. These cellular components work together to modify, package, tag, and transport membrane lipids and proteins.
The cytoskeleton has three different types of protein elements. Microfilaments provide rigidity and shape to the cell, and facilitate cellular movements. Intermediate filaments bear tension and anchor the nucleus and other organelles in place. Microtubules help the cell resist compression, serve as tracks for motor proteins that move vesicles through the cell, and pull replicated chromosomes to opposite ends of a dividing cell. They are also the structural elements of centrioles, flagella, and cilia.
Animal cells communicate through their extracellular matrices and are connected to each other by tight junctions, desmosomes, and gap junctions. Plant cells are connected and communicate with each other by plasmodesmata.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=113#h5p-22
cell wall: a rigid cell covering made of cellulose in plants, peptidoglycan in bacteria, non-peptidoglycan compounds in Archaea, and chitin in fungi that protects the cell, provides structural support, and gives shape to the cell
central vacuole: a large plant cell organelle that acts as a storage compartment, water reservoir, and site of macromolecule degradation
chloroplast: a plant cell organelle that carries out photosynthesis
cilium: (plural: cilia) a short, hair-like structure that extends from the plasma membrane in large numbers and is used to move an entire cell or move substances along the outer surface of the cell
cytoplasm: the entire region between the plasma membrane and the nuclear envelope, consisting of organelles suspended in the gel-like cytosol, the cytoskeleton, and various chemicals
cytoskeleton: the network of protein fibers that collectively maintains the shape of the cell, secures some organelles in specific positions, allows cytoplasm and vesicles to move within the cell, and enables unicellular organisms to move
cytosol: the gel-like material of the cytoplasm in which cell structures are suspended
desmosome: a linkage between adjacent epithelial cells that forms when cadherins in the plasma membrane attach to intermediate filaments
endomembrane system: the group of organelles and membranes in eukaryotic cells that work together to modify, package, and transport lipids and proteins
endoplasmic reticulum (ER): a series of interconnected membranous structures within eukaryotic cells that collectively modify proteins and synthesize lipids
extracellular matrix: the material, primarily collagen, glycoproteins, and proteoglycans, secreted from animal cells that holds cells together as a tissue, allows cells to communicate with each other, and provides mechanical protection and anchoring for cells in the tissue
flagellum: (plural: flagella) the long, hair-like structure that extends from the plasma membrane and is used to move the cell
gap junction: a channel between two adjacent animal cells that allows ions, nutrients, and other low-molecular weight substances to pass between the cells, enabling the cells to communicate
Golgi apparatus: a eukaryotic organelle made up of a series of stacked membranes that sorts, tags, and packages lipids and proteins for distribution
lysosome: an organelle in an animal cell that functions as the cell’s digestive component; it breaks down proteins, polysaccharides, lipids, nucleic acids, and even worn-out organelles
mitochondria: (singular: mitochondrion) the cellular organelles responsible for carrying out cellular respiration, resulting in the production of ATP, the cell’s main energy-carrying molecule
nuclear envelope: the double-membrane structure that constitutes the outermost portion of the nucleus
nucleolus: the darkly staining body within the nucleus that is responsible for assembling ribosomal subunits
nucleus: the cell organelle that houses the cell’s DNA and directs the synthesis of ribosomes and proteins
peroxisome: a small, round organelle that contains hydrogen peroxide, oxidizes fatty acids and amino acids, and detoxifies many poisons
plasma membrane: a phospholipid bilayer with embedded (integral) or attached (peripheral) proteins that separates the internal contents of the cell from its surrounding environment
plasmodesma: (plural: plasmodesmata) a channel that passes between the cell walls of adjacent plant cells, connects their cytoplasm, and allows materials to be transported from cell to cell
ribosome: a cellular structure that carries out protein synthesis
rough endoplasmic reticulum (RER): the region of the endoplasmic reticulum that is studded with ribosomes and engages in protein modification
smooth endoplasmic reticulum (SER): the region of the endoplasmic reticulum that has few or no ribosomes on its cytoplasmic surface and synthesizes carbohydrates, lipids, and steroid hormones; detoxifies chemicals like pesticides, preservatives, medications, and environmental pollutants, and stores calcium ions
tight junction: a firm seal between two adjacent animal cells created by protein adherence
vacuole: a membrane-bound sac, somewhat larger than a vesicle, that functions in cellular storage and transport
vesicle: a small, membrane-bound sac that functions in cellular storage and transport; its membrane is capable of fusing with the plasma membrane and the membranes of the endoplasmic reticulum and Golgi apparatus
By the end of this section, you will be able to:
A cell’s plasma membrane defines the boundary of the cell and determines the nature of its contact with the environment. Cells exclude some substances, take in others, and excrete still others, all in controlled quantities. Plasma membranes enclose the borders of cells, but rather than being a static bag, they are dynamic and constantly in flux. The plasma membrane must be sufficiently flexible to allow certain cells, such as red blood cells and white blood cells, to change shape as they pass through narrow capillaries. These are the more obvious functions of a plasma membrane. In addition, the surface of the plasma membrane carries markers that allow cells to recognize one another, which is vital as tissues and organs form during early development, and which later plays a role in the “self” versus “non-self” distinction of the immune response.
The plasma membrane also carries receptors, which are attachment sites for specific substances that interact with the cell. Each receptor is structured to bind with a specific substance. For example, surface receptors of the membrane create changes in the interior, such as changes in enzymes of metabolic pathways. These metabolic pathways might be vital for providing the cell with energy, making specific substances for the cell, or breaking down cellular waste or toxins for disposal. Receptors on the plasma membrane’s exterior surface interact with hormones or neurotransmitters, and allow their messages to be transmitted into the cell. Some recognition sites are used by viruses as attachment points. Although they are highly specific, pathogens like viruses may evolve to exploit receptors to gain entry to a cell by mimicking the specific substance that the receptor is meant to bind. This specificity helps to explain why human immunodeficiency virus (HIV) or any of the five types of hepatitis viruses invade only specific cells.
In 1972, S. J. Singer and Garth L. Nicolson proposed a new model of the plasma membrane that, compared to earlier understanding, better explained both microscopic observations and the function of the plasma membrane. This was called the fluid mosaic model. The model has evolved somewhat over time, but still best accounts for the structure and functions of the plasma membrane as we now understand them. The fluid mosaic model describes the structure of the plasma membrane as a mosaic of components—including phospholipids, cholesterol, proteins, and carbohydrates—in which the components are able to flow and change position, while maintaining the basic integrity of the membrane. Both phospholipid molecules and embedded proteins are able to diffuse rapidly and laterally in the membrane. The fluidity of the plasma membrane is necessary for the activities of certain enzymes and transport molecules within the membrane. Plasma membranes range from 5–10 nm thick. As a comparison, human red blood cells, visible via light microscopy, are approximately 8 µm thick, or approximately 1,000 times thicker than a plasma membrane.
The plasma membrane is made up primarily of a bilayer of phospholipids with embedded proteins, carbohydrates, glycolipids, and glycoproteins, and, in animal cells, cholesterol. The amount of cholesterol in animal plasma membranes regulates the fluidity of the membrane and changes based on the temperature of the cell’s environment. In other words, cholesterol acts as antifreeze in the cell membrane and is more abundant in animals that live in cold climates.
The main fabric of the membrane is composed of two layers of phospholipid molecules, and the polar ends of these molecules (which look like a collection of balls in an artist’s rendition of the model) (Figure 3.22) are in contact with aqueous fluid both inside and outside the cell. Thus, both surfaces of the plasma membrane are hydrophilic. In contrast, the interior of the membrane, between its two surfaces, is a hydrophobic or nonpolar region because of the fatty acid tails. This region has no attraction for water or other polar molecules.
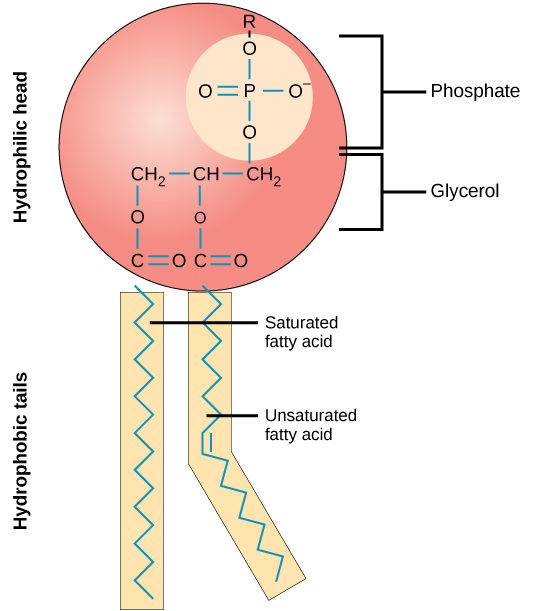
Proteins make up the second major chemical component of plasma membranes. Integral proteins are embedded in the plasma membrane and may span all or part of the membrane. Integral proteins may serve as channels or pumps to move materials into or out of the cell. Peripheral proteins are found on the exterior or interior surfaces of membranes, attached either to integral proteins or to phospholipid molecules. Both integral and peripheral proteins may serve as enzymes, as structural attachments for the fibers of the cytoskeleton, or as part of the cell’s recognition sites.
Carbohydrates are the third major component of plasma membranes. They are always found on the exterior surface of cells and are bound either to proteins (forming glycoproteins) or to lipids (forming glycolipids). These carbohydrate chains may consist of 2–60 monosaccharide units and may be either straight or branched. Along with peripheral proteins, carbohydrates form specialized sites on the cell surface that allow cells to recognize each other.
How Viruses Infect Specific OrgansSpecific glycoprotein molecules exposed on the surface of the cell membranes of host cells are exploited by many viruses to infect specific organs. For example, HIV is able to penetrate the plasma membranes of specific kinds of white blood cells called T-helper cells and monocytes, as well as some cells of the central nervous system. The hepatitis virus attacks only liver cells.
These viruses are able to invade these cells, because the cells have binding sites on their surfaces that the viruses have exploited with equally specific glycoproteins in their coats. (Figure 3.23). The cell is tricked by the mimicry of the virus coat molecules, and the virus is able to enter the cell. Other recognition sites on the virus’s surface interact with the human immune system, prompting the body to produce antibodies. Antibodies are made in response to the antigens (or proteins associated with invasive pathogens). These same sites serve as places for antibodies to attach, and either destroy or inhibit the activity of the virus. Unfortunately, these sites on HIV are encoded by genes that change quickly, making the production of an effective vaccine against the virus very difficult. The virus population within an infected individual quickly evolves through mutation into different populations, or variants, distinguished by differences in these recognition sites. This rapid change of viral surface markers decreases the effectiveness of the person’s immune system in attacking the virus, because the antibodies will not recognize the new variations of the surface patterns.
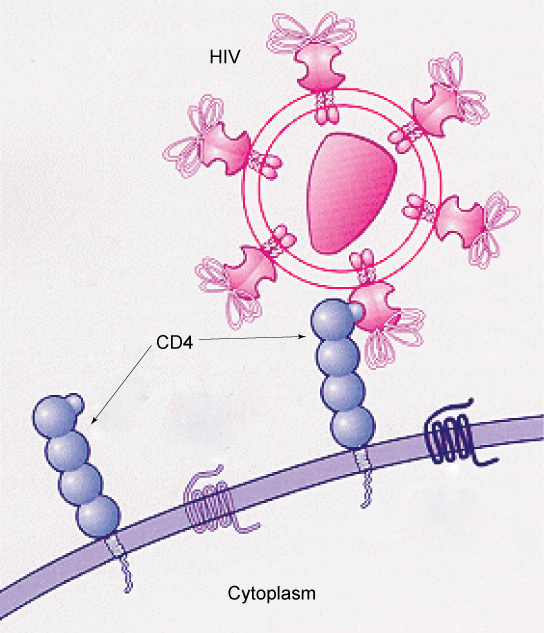
The modern understanding of the plasma membrane is referred to as the fluid mosaic model. The plasma membrane is composed of a bilayer of phospholipids, with their hydrophobic, fatty acid tails in contact with each other. The landscape of the membrane is studded with proteins, some of which span the membrane. Some of these proteins serve to transport materials into or out of the cell. Carbohydrates are attached to some of the proteins and lipids on the outward-facing surface of the membrane. These form complexes that function to identify the cell to other cells. The fluid nature of the membrane owes itself to the configuration of the fatty acid tails, the presence of cholesterol embedded in the membrane (in animal cells), and the mosaic nature of the proteins and protein-carbohydrate complexes, which are not firmly fixed in place. Plasma membranes enclose the borders of cells, but rather than being a static bag, they are dynamic and constantly in flux.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=117#h5p-23
By the end of this section, you will be able to:
Plasma membranes must allow certain substances to enter and leave a cell, while preventing harmful material from entering and essential material from leaving. In other words, plasma membranes are selectively permeable—they allow some substances through but not others. If they were to lose this selectivity, the cell would no longer be able to sustain itself, and it would be destroyed. Some cells require larger amounts of specific substances than do other cells; they must have a way of obtaining these materials from the extracellular fluids. This may happen passively, as certain materials move back and forth, or the cell may have special mechanisms that ensure transport. Most cells expend most of their energy, in the form of adenosine triphosphate (ATP), to create and maintain an uneven distribution of ions on the opposite sides of their membranes. The structure of the plasma membrane contributes to these functions, but it also presents some problems.
The most direct forms of membrane transport are passive. Passive transport is a naturally occurring phenomenon and does not require the cell to expend energy to accomplish the movement. In passive transport, substances move from an area of higher concentration to an area of lower concentration in a process called diffusion. A physical space in which there is a different concentration of a single substance is said to have a concentration gradient.
Plasma membranes are asymmetric, meaning that despite the mirror image formed by the phospholipids, the interior of the membrane is not identical to the exterior of the membrane. Integral proteins that act as channels or pumps work in one direction. Carbohydrates, attached to lipids or proteins, are also found on the exterior surface of the plasma membrane. These carbohydrate complexes help the cell bind substances that the cell needs in the extracellular fluid. This adds considerably to the selective nature of plasma membranes.
Recall that plasma membranes have hydrophilic and hydrophobic regions. This characteristic helps the movement of certain materials through the membrane and hinders the movement of others. Lipid-soluble material can easily slip through the hydrophobic lipid core of the membrane. Substances such as the fat-soluble vitamins A, D, E, and K readily pass through the plasma membranes in the digestive tract and other tissues. Fat-soluble drugs also gain easy entry into cells and are readily transported into the body’s tissues and organs. Molecules of oxygen and carbon dioxide have no charge and pass through by simple diffusion.
Polar substances, with the exception of water, present problems for the membrane. While some polar molecules connect easily with the outside of a cell, they cannot readily pass through the lipid core of the plasma membrane. Additionally, whereas small ions could easily slip through the spaces in the mosaic of the membrane, their charge prevents them from doing so. Ions such as sodium, potassium, calcium, and chloride must have a special means of penetrating plasma membranes. Simple sugars and amino acids also need help with transport across plasma membranes.
Diffusion is a passive process of transport. A single substance tends to move from an area of high concentration to an area of low concentration until the concentration is equal across the space. You are familiar with diffusion of substances through the air. For example, think about someone opening a bottle of perfume in a room filled with people. The perfume is at its highest concentration in the bottle and is at its lowest at the edges of the room. The perfume vapor will diffuse, or spread away, from the bottle, and gradually, more and more people will smell the perfume as it spreads. Materials move within the cell’s cytosol by diffusion, and certain materials move through the plasma membrane by diffusion (Figure 3.24). Diffusion expends no energy. Rather the different concentrations of materials in different areas are a form of potential energy, and diffusion is the dissipation of that potential energy as materials move down their concentration gradients, from high to low.
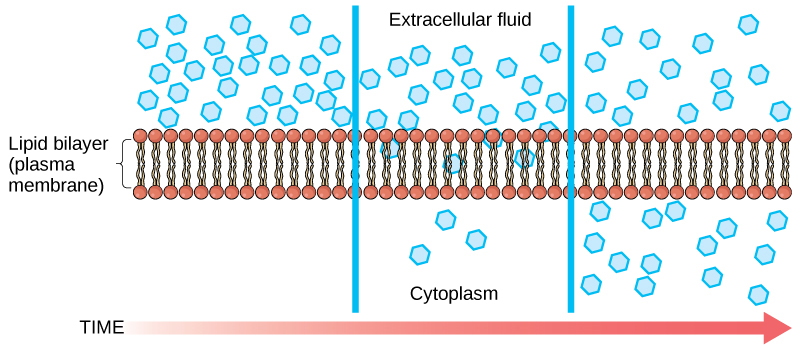
Each separate substance in a medium, such as the extracellular fluid, has its own concentration gradient, independent of the concentration gradients of other materials. Additionally, each substance will diffuse according to that gradient.
Several factors affect the rate of diffusion.
For an animation of the diffusion process in action, view this short video on cell membrane transport.


A YouTube element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=124
In facilitated transport, also called facilitated diffusion, material moves across the plasma membrane with the assistance of transmembrane proteins down a concentration gradient (from high to low concentration) without the expenditure of cellular energy. However, the substances that undergo facilitated transport would otherwise not diffuse easily or quickly across the plasma membrane. The solution to moving polar substances and other substances across the plasma membrane rests in the proteins that span its surface. The material being transported is first attached to protein or glycoprotein receptors on the exterior surface of the plasma membrane. This allows the material that is needed by the cell to be removed from the extracellular fluid. The substances are then passed to specific integral proteins that facilitate their passage, because they form channels or pores that allow certain substances to pass through the membrane. The integral proteins involved in facilitated transport are collectively referred to as transport proteins, and they function as either channels for the material or carriers.
Osmosis is the diffusion of water through a semipermeable membrane according to the concentration gradient of water across the membrane. Whereas diffusion transports material across membranes and within cells, osmosis transports only water across a membrane and the membrane limits the diffusion of solutes in the water. Osmosis is a special case of diffusion. Water, like other substances, moves from an area of higher concentration to one of lower concentration. Imagine a beaker with a semipermeable membrane, separating the two sides or halves (Figure 3.25). On both sides of the membrane, the water level is the same, but there are different concentrations on each side of a dissolved substance, or solute, that cannot cross the membrane. If the volume of the water is the same, but the concentrations of solute are different, then there are also different concentrations of water, the solvent, on either side of the membrane.
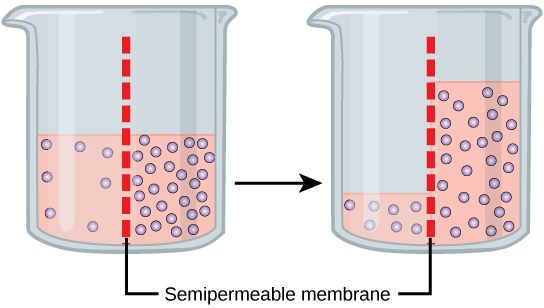
A principle of diffusion is that the molecules move around and will spread evenly throughout the medium if they can. However, only the material capable of getting through the membrane will diffuse through it. In this example, the solute cannot diffuse through the membrane, but the water can. Water has a concentration gradient in this system. Therefore, water will diffuse down its concentration gradient, crossing the membrane to the side where it is less concentrated. This diffusion of water through the membrane—osmosis—will continue until the concentration gradient of water goes to zero. Osmosis proceeds constantly in living systems.
Tonicity describes the amount of solute in a solution. The measure of the tonicity of a solution, or the total amount of solutes dissolved in a specific amount of solution, is called its osmolarity. Three terms—hypotonic, isotonic, and hypertonic—are used to relate the osmolarity of a cell to the osmolarity of the extracellular fluid that contains the cells. In a hypotonic solution, such as tap water, the extracellular fluid has a lower concentration of solutes than the fluid inside the cell, and water enters the cell. (In living systems, the point of reference is always the cytoplasm, so the prefix hypo– means that the extracellular fluid has a lower concentration of solutes, or a lower osmolarity, than the cell cytoplasm.) It also means that the extracellular fluid has a higher concentration of water than does the cell. In this situation, water will follow its concentration gradient and enter the cell. This may cause an animal cell to burst, or lyse.
In a hypertonic solution (the prefix hyper– refers to the extracellular fluid having a higher concentration of solutes than the cell’s cytoplasm), the fluid contains less water than the cell does, such as seawater. Because the cell has a lower concentration of solutes, the water will leave the cell. In effect, the solute is drawing the water out of the cell. This may cause an animal cell to shrivel, or crenate.
In an isotonic solution, the extracellular fluid has the same osmolarity as the cell. If the concentration of solutes of the cell matches that of the extracellular fluid, there will be no net movement of water into or out of the cell. Blood cells in hypertonic, isotonic, and hypotonic solutions take on characteristic appearances (Figure 3.26).

A doctor injects a patient with what the doctor thinks is isotonic saline solution. The patient dies, and autopsy reveals that many red blood cells have been destroyed. Do you think the solution the doctor injected was really isotonic?
<!– No, it must have been hypotonic, as a hypotonic solution would cause water to enter the cells, thereby making them burst. –>
Some organisms, such as plants, fungi, bacteria, and some protists, have cell walls that surround the plasma membrane and prevent cell lysis. The plasma membrane can only expand to the limit of the cell wall, so the cell will not lyse. In fact, the cytoplasm in plants is always slightly hypertonic compared to the cellular environment, and water will always enter a cell if water is available. This influx of water produces turgor pressure, which stiffens the cell walls of the plant (Figure 3.27). In nonwoody plants, turgor pressure supports the plant. If the plant cells become hypertonic, as occurs in drought or if a plant is not watered adequately, water will leave the cell. Plants lose turgor pressure in this condition and wilt.

The passive forms of transport, diffusion and osmosis, move material of small molecular weight. Substances diffuse from areas of high concentration to areas of low concentration, and this process continues until the substance is evenly distributed in a system. In solutions of more than one substance, each type of molecule diffuses according to its own concentration gradient. Many factors can affect the rate of diffusion, including concentration gradient, the sizes of the particles that are diffusing, and the temperature of the system.
In living systems, diffusion of substances into and out of cells is mediated by the plasma membrane. Some materials diffuse readily through the membrane, but others are hindered, and their passage is only made possible by protein channels and carriers. The chemistry of living things occurs in aqueous solutions, and balancing the concentrations of those solutions is an ongoing problem. In living systems, diffusion of some substances would be slow or difficult without membrane proteins.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=124#h5p-24
concentration gradient: an area of high concentration across from an area of low concentration
diffusion: a passive process of transport of low-molecular weight material down its concentration gradient
facilitated transport: a process by which material moves down a concentration gradient (from high to low concentration) using integral membrane proteins
hypertonic: describes a solution in which extracellular fluid has higher osmolarity than the fluid inside the cell
hypotonic: describes a solution in which extracellular fluid has lower osmolarity than the fluid inside the cell
isotonic: describes a solution in which the extracellular fluid has the same osmolarity as the fluid inside the cell
osmolarity: the total amount of substances dissolved in a specific amount of solution
osmosis: the transport of water through a semipermeable membrane from an area of high water concentration to an area of low water concentration across a membrane
passive transport: a method of transporting material that does not require energy
selectively permeable: the characteristic of a membrane that allows some substances through but not others
solute: a substance dissolved in another to form a solution
tonicity: the amount of solute in a solution.
By the end of this section, you will be able to:
Active transport mechanisms require the use of the cell’s energy, usually in the form of adenosine triphosphate (ATP). If a substance must move into the cell against its concentration gradient, that is, if the concentration of the substance inside the cell must be greater than its concentration in the extracellular fluid, the cell must use energy to move the substance. Some active transport mechanisms move small-molecular weight material, such as ions, through the membrane.
In addition to moving small ions and molecules through the membrane, cells also need to remove and take in larger molecules and particles. Some cells are even capable of engulfing entire unicellular microorganisms. You might have correctly hypothesized that the uptake and release of large particles by the cell requires energy. A large particle, however, cannot pass through the membrane, even with energy supplied by the cell.
We have discussed simple concentration gradients—differential concentrations of a substance across a space or a membrane—but in living systems, gradients are more complex. Because cells contain proteins, most of which are negatively charged, and because ions move into and out of cells, there is an electrical gradient, a difference of charge, across the plasma membrane. The interior of living cells is electrically negative with respect to the extracellular fluid in which they are bathed; at the same time, cells have higher concentrations of potassium (K+) and lower concentrations of sodium (Na+) than does the extracellular fluid. Thus, in a living cell, the concentration gradient and electrical gradient of Na+ promotes diffusion of the ion into the cell, and the electrical gradient of Na+ (a positive ion) tends to drive it inward to the negatively charged interior. The situation is more complex, however, for other elements such as potassium. The electrical gradient of K+ promotes diffusion of the ion into the cell, but the concentration gradient of K+ promotes diffusion out of the cell (Figure 3.28). The combined gradient that affects an ion is called its electrochemical gradient, and it is especially important to muscle and nerve cells.
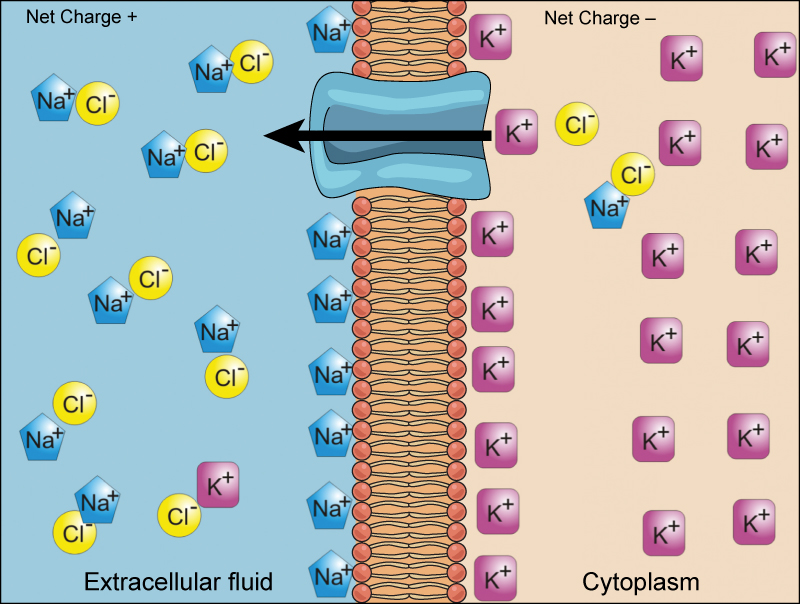
To move substances against a concentration or an electrochemical gradient, the cell must use energy. This energy is harvested from ATP that is generated through cellular metabolism. Active transport mechanisms, collectively called pumps or carrier proteins, work against electrochemical gradients. With the exception of ions, small substances constantly pass through plasma membranes. Active transport maintains concentrations of ions and other substances needed by living cells in the face of these passive changes. Much of a cell’s supply of metabolic energy may be spent maintaining these processes. Because active transport mechanisms depend on cellular metabolism for energy, they are sensitive to many metabolic poisons that interfere with the supply of ATP.
Two mechanisms exist for the transport of small-molecular weight material and macromolecules. Primary active transport moves ions across a membrane and creates a difference in charge across that membrane. The primary active transport system uses ATP to move a substance, such as an ion, into the cell, and often at the same time, a second substance is moved out of the cell. The sodium-potassium pump, an important pump in animal cells, expends energy to move potassium ions into the cell and a different number of sodium ions out of the cell (Figure 3.29). The action of this pump results in a concentration and charge difference across the membrane.
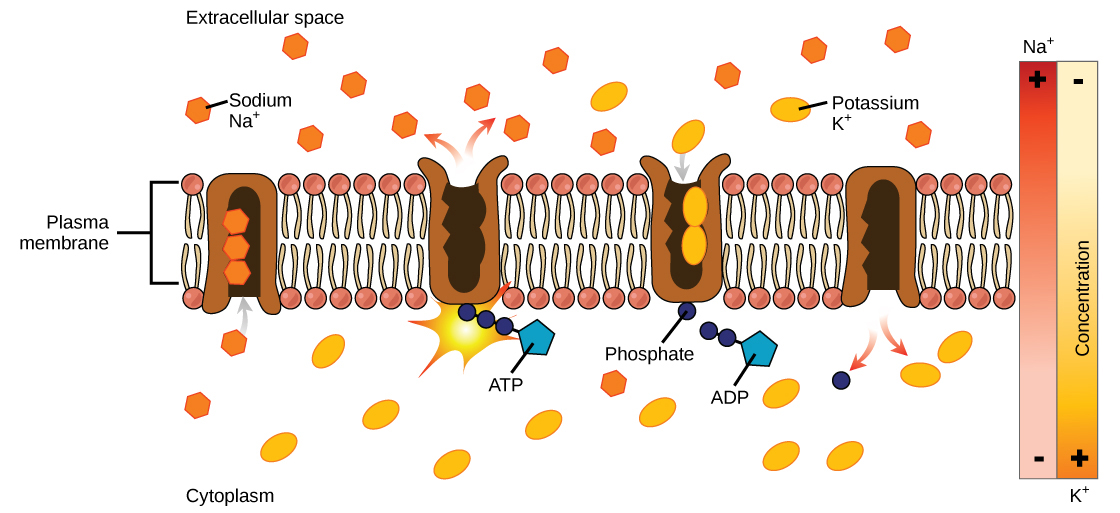
Secondary active transport describes the movement of material using the energy of the electrochemical gradient established by primary active transport. Using the energy of the electrochemical gradient created by the primary active transport system, other substances such as amino acids and glucose can be brought into the cell through membrane channels. ATP itself is formed through secondary active transport using a hydrogen ion gradient in the mitochondrion.
Endocytosis is a type of active transport that moves particles, such as large molecules, parts of cells, and even whole cells, into a cell. There are different variations of endocytosis, but all share a common characteristic: The plasma membrane of the cell invaginates, forming a pocket around the target particle. The pocket pinches off, resulting in the particle being contained in a newly created vacuole that is formed from the plasma membrane.
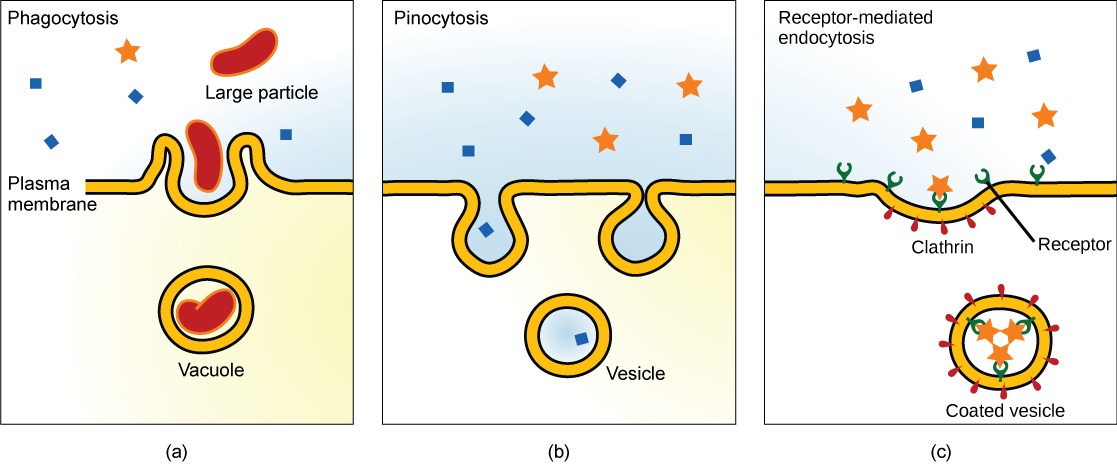
Phagocytosis is the process by which large particles, such as cells, are taken in by a cell. For example, when microorganisms invade the human body, a type of white blood cell called a neutrophil removes the invader through this process, surrounding and engulfing the microorganism, which is then destroyed by the neutrophil (Figure 3.30).
A variation of endocytosis is called pinocytosis. This literally means “cell drinking” and was named at a time when the assumption was that the cell was purposefully taking in extracellular fluid. In reality, this process takes in solutes that the cell needs from the extracellular fluid (Figure 3.30).
A targeted variation of endocytosis employs binding proteins in the plasma membrane that are specific for certain substances (Figure 3.30). The particles bind to the proteins and the plasma membrane invaginates, bringing the substance and the proteins into the cell. If passage across the membrane of the target of receptor-mediated endocytosis is ineffective, it will not be removed from the tissue fluids or blood. Instead, it will stay in those fluids and increase in concentration. Some human diseases are caused by a failure of receptor-mediated endocytosis. For example, the form of cholesterol termed low-density lipoprotein or LDL (also referred to as “bad” cholesterol) is removed from the blood by receptor-mediated endocytosis. In the human genetic disease familial hypercholesterolemia, the LDL receptors are defective or missing entirely. People with this condition have life-threatening levels of cholesterol in their blood, because their cells cannot clear the chemical from their blood.
In contrast to these methods of moving material into a cell is the process of exocytosis. Exocytosis is the opposite of the processes discussed above in that its purpose is to expel material from the cell into the extracellular fluid. A particle enveloped in membrane fuses with the interior of the plasma membrane. This fusion opens the membranous envelope to the exterior of the cell, and the particle is expelled into the extracellular space (Figure 3.31).
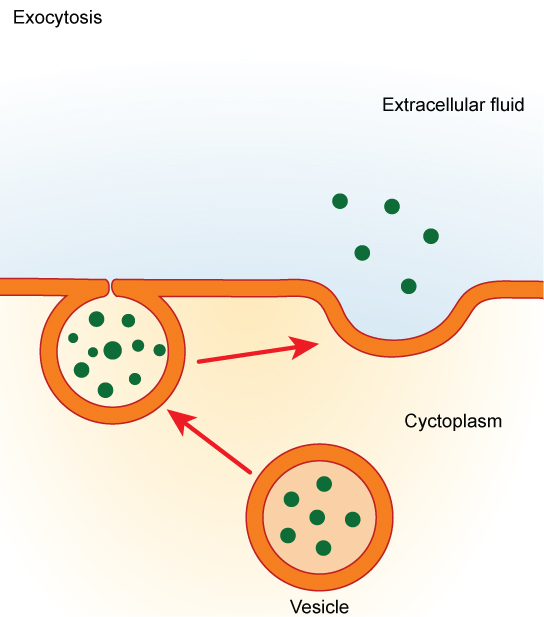
The combined gradient that affects an ion includes its concentration gradient and its electrical gradient. Living cells need certain substances in concentrations greater than they exist in the extracellular space. Moving substances up their electrochemical gradients requires energy from the cell. Active transport uses energy stored in ATP to fuel the transport. Active transport of small molecular-size material uses integral proteins in the cell membrane to move the material—these proteins are analogous to pumps. Some pumps, which carry out primary active transport, couple directly with ATP to drive their action. In secondary transport, energy from primary transport can be used to move another substance into the cell and up its concentration gradient.
Endocytosis methods require the direct use of ATP to fuel the transport of large particles such as macromolecules; parts of cells or whole cells can be engulfed by other cells in a process called phagocytosis. In phagocytosis, a portion of the membrane invaginates and flows around the particle, eventually pinching off and leaving the particle wholly enclosed by an envelope of plasma membrane. Vacuoles are broken down by the cell, with the particles used as food or dispatched in some other way. Pinocytosis is a similar process on a smaller scale. The cell expels waste and other particles through the reverse process, exocytosis. Wastes are moved outside the cell, pushing a membranous vesicle to the plasma membrane, allowing the vesicle to fuse with the membrane and incorporating itself into the membrane structure, releasing its contents to the exterior of the cell.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=130#h5p-25
active transport: the method of transporting material that requires energy
electrochemical gradient: a gradient produced by the combined forces of the electrical gradient and the chemical gradient
endocytosis: a type of active transport that moves substances, including fluids and particles, into a cell
exocytosis: a process of passing material out of a cell
phagocytosis: a process that takes macromolecules that the cell needs from the extracellular fluid; a variation of endocytosis
pinocytosis: a process that takes solutes that the cell needs from the extracellular fluid; a variation of endocytosis
receptor-mediated endocytosis: a variant of endocytosis that involves the use of specific binding proteins in the plasma membrane for specific molecules or particles

Virtually every task performed by living organisms requires energy. Energy is needed to perform heavy labor and exercise, but humans also use energy while thinking, and even during sleep. In fact, the living cells of every organism constantly use energy. Nutrients and other molecules are imported into the cell, metabolized (broken down) and possibly synthesized into new molecules, modified if needed, transported around the cell, and possibly distributed to the entire organism. For example, the large proteins that make up muscles are built from smaller molecules imported from dietary amino acids. Complex carbohydrates are broken down into simple sugars that the cell uses for energy. Just as energy is required to both build and demolish a building, energy is required for the synthesis and breakdown of molecules as well as the transport of molecules into and out of cells. In addition, processes such as ingesting and breaking down pathogenic bacteria and viruses, exporting wastes and toxins, and movement of the cell require energy. From where, and in what form, does this energy come? How do living cells obtain energy, and how do they use it? This chapter will discuss different forms of energy and the physical laws that govern energy transfer. This chapter will also describe how cells use energy and replenish it, and how chemical reactions in the cell are performed with great efficiency.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=133#h5p-26
By the end of this section, you will be able to:
Watch a video about heterotrophs.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=150#h5p-27
Scientists use the term bioenergetics to describe the concept of energy flow (Figure 4.2) through living systems, such as cells. Cellular processes such as the building and breaking down of complex molecules occur through stepwise chemical reactions. Some of these chemical reactions are spontaneous and release energy, whereas others require energy to proceed. Just as living things must continually consume food to replenish their energy supplies, cells must continually produce more energy to replenish that used by the many energy-requiring chemical reactions that constantly take place. Together, all of the chemical reactions that take place inside cells, including those that consume or generate energy, are referred to as the cell’s metabolism.
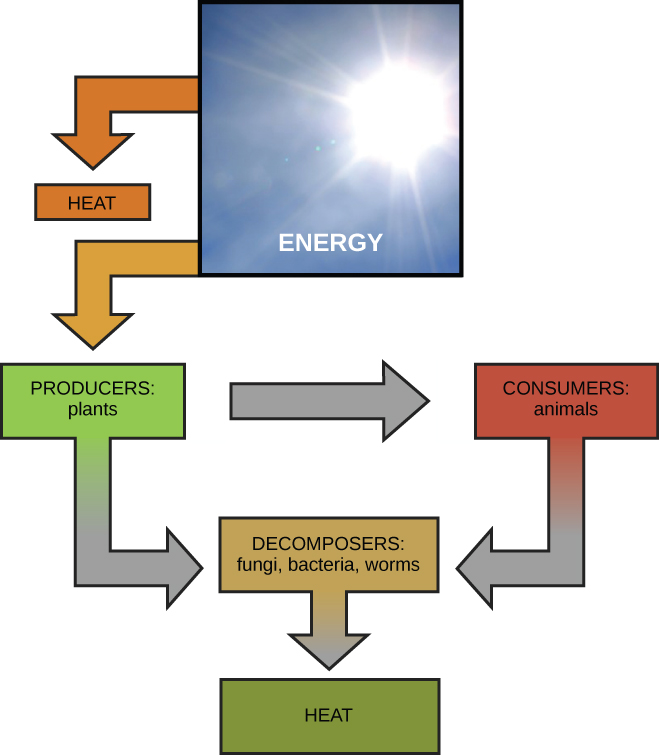
Consider the metabolism of sugar. This is a classic example of one of the many cellular processes that use and produce energy. Living things consume sugars as a major energy source, because sugar molecules have a great deal of energy stored within their bonds. For the most part, photosynthesizing organisms like plants produce these sugars. During photosynthesis, plants use energy (originally from sunlight) to convert carbon dioxide gas (CO2) into sugar molecules (like glucose: C6H12O6). They consume carbon dioxide and produce oxygen as a waste product. This reaction is summarized as:
6CO2 + 6H2O + energy ——-> C6H12O6+ 6O2
Because this process involves synthesizing an energy-storing molecule, it requires energy input to proceed. During the light reactions of photosynthesis, energy is provided by a molecule called adenosine triphosphate (ATP), which is the primary energy currency of all cells. Just as the dollar is used as currency to buy goods, cells use molecules of ATP as energy currency to perform immediate work. In contrast, energy-storage molecules such as glucose are consumed only to be broken down to use their energy. The reaction that harvests the energy of a sugar molecule in cells requiring oxygen to survive can be summarized by the reverse reaction to photosynthesis. In this reaction, oxygen is consumed and carbon dioxide is released as a waste product. The reaction is summarized as:
C6H12O6 + 6O2 ——> 6CO2 + 6H2O + energy
Both of these reactions involve many steps.
The processes of making and breaking down sugar molecules illustrate two examples of metabolic pathways. A metabolic pathway is a series of chemical reactions that takes a starting molecule and modifies it, step-by-step, through a series of metabolic intermediates, eventually yielding a final product. In the example of sugar metabolism, the first metabolic pathway synthesized sugar from smaller molecules, and the other pathway broke sugar down into smaller molecules. These two opposite processes—the first requiring energy and the second producing energy—are referred to as anabolic pathways (building polymers) and catabolic pathways (breaking down polymers into their monomers), respectively. Consequently, metabolism is composed of synthesis (anabolism) and degradation (catabolism) (Figure 4.3).
It is important to know that the chemical reactions of metabolic pathways do not take place on their own. Each reaction step is facilitated, or catalyzed, by a protein called an enzyme. Enzymes are important for catalyzing all types of biological reactions—those that require energy as well as those that release energy.
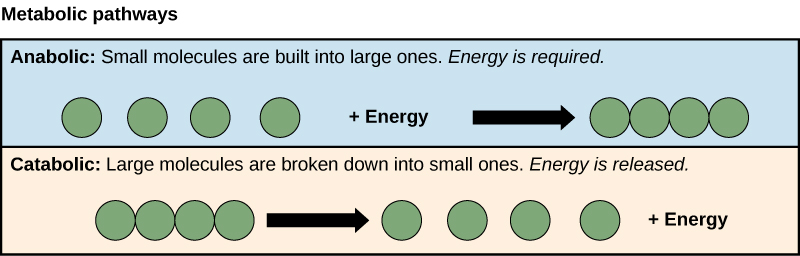
Thermodynamics refers to the study of energy and energy transfer involving physical matter. The matter relevant to a particular case of energy transfer is called a system, and everything outside of that matter is called the surroundings. For instance, when heating a pot of water on the stove, the system includes the stove, the pot, and the water. Energy is transferred within the system (between the stove, pot, and water). There are two types of systems: open and closed. In an open system, energy can be exchanged with its surroundings. The stovetop system is open because heat can be lost to the air. A closed system cannot exchange energy with its surroundings.
Biological organisms are open systems. Energy is exchanged between them and their surroundings as they use energy from the sun to perform photosynthesis or consume energy-storing molecules and release energy to the environment by doing work and releasing heat. Like all things in the physical world, energy is subject to physical laws. The laws of thermodynamics govern the transfer of energy in and among all systems in the universe.
In general, energy is defined as the ability to do work, or to create some kind of change. Energy exists in different forms. For example, electrical energy, light energy, and heat energy are all different types of energy. To appreciate the way energy flows into and out of biological systems, it is important to understand two of the physical laws that govern energy.
The first law of thermodynamics states that the total amount of energy in the universe is constant and conserved. In other words, there has always been, and always will be, exactly the same amount of energy in the universe. Energy exists in many different forms. According to the first law of thermodynamics, energy may be transferred from place to place or transformed into different forms, but it cannot be created or destroyed. The transfers and transformations of energy take place around us all the time. Light bulbs transform electrical energy into light and heat energy. Gas stoves transform chemical energy from natural gas into heat energy. Plants perform one of the most biologically useful energy transformations on earth: that of converting the energy of sunlight to chemical energy stored within organic molecules (Figure 4.2). Some examples of energy transformations are shown in Figure 4.4.
The challenge for all living organisms is to obtain energy from their surroundings in forms that they can transfer or transform into usable energy to do work. Living cells have evolved to meet this challenge. Chemical energy stored within organic molecules such as sugars and fats is transferred and transformed through a series of cellular chemical reactions into energy within molecules of ATP. Energy in ATP molecules is easily accessible to do work. Examples of the types of work that cells need to do include building complex molecules, transporting materials, powering the motion of cilia or flagella, and contracting muscle fibers to create movement.

A living cell’s primary tasks of obtaining, transforming, and using energy to do work may seem simple. However, the second law of thermodynamics explains why these tasks are harder than they appear. All energy transfers and transformations are never completely efficient. In every energy transfer, some amount of energy is lost in a form that is unusable. In most cases, this form is heat energy. Thermodynamically, heat energy is defined as the energy transferred from one system to another that is not work. For example, when a light bulb is turned on, some of the energy being converted from electrical energy into light energy is lost as heat energy. Likewise, some energy is lost as heat energy during cellular metabolic reactions.
An important concept in physical systems is that of order and disorder. The more energy that is lost by a system to its surroundings, the less ordered and more random the system is. Scientists refer to the measure of randomness or disorder within a system as entropy. High entropy means high disorder and low energy. Molecules and chemical reactions have varying entropy as well. For example, entropy increases as molecules at a high concentration in one place diffuse and spread out. The second law of thermodynamics says that energy will always be lost as heat in energy transfers or transformations.
Living things are highly ordered, requiring constant energy input to be maintained in a state of low entropy.
When an object is in motion, there is energy associated with that object. Think of a wrecking ball. Even a slow-moving wrecking ball can do a great deal of damage to other objects. Energy associated with objects in motion is called kinetic energy (Figure 4.5). A speeding bullet, a walking person, and the rapid movement of molecules in the air (which produces heat) all have kinetic energy.
Now what if that same motionless wrecking ball is lifted two stories above ground with a crane? If the suspended wrecking ball is unmoving, is there energy associated with it? The answer is yes. The energy that was required to lift the wrecking ball did not disappear, but is now stored in the wrecking ball by virtue of its position and the force of gravity acting on it. This type of energy is called potential energy (Figure 4.5). If the ball were to fall, the potential energy would be transformed into kinetic energy until all of the potential energy was exhausted when the ball rested on the ground. Wrecking balls also swing like a pendulum; through the swing, there is a constant change of potential energy (highest at the top of the swing) to kinetic energy (highest at the bottom of the swing). Other examples of potential energy include the energy of water held behind a dam or a person about to skydive out of an airplane.

Potential energy is not only associated with the location of matter, but also with the structure of matter. Even a spring on the ground has potential energy if it is compressed; so does a rubber band that is pulled taut. On a molecular level, the bonds that hold the atoms of molecules together exist in a particular structure that has potential energy. Remember that anabolic cellular pathways require energy to synthesize complex molecules from simpler ones and catabolic pathways release energy when complex molecules are broken down. The fact that energy can be released by the breakdown of certain chemical bonds implies that those bonds have potential energy. In fact, there is potential energy stored within the bonds of all the food molecules we eat, which is eventually harnessed for use. This is because these bonds can release energy when broken. The type of potential energy that exists within chemical bonds, and is released when those bonds are broken, is called chemical energy. Chemical energy is responsible for providing living cells with energy from food. The release of energy occurs when the molecular bonds within food molecules are broken.
Watch a video about kilocalories.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=150#h5p-28

Visit the site and select “Pendulum” from the “Work and Energy” menu to see the shifting kinetic and potential energy of a pendulum in motion.
After learning that chemical reactions release energy when energy-storing bonds are broken, an important next question is the following: How is the energy associated with these chemical reactions quantified and expressed? How can the energy released from one reaction be compared to that of another reaction? A measurement of free energy is used to quantify these energy transfers. Recall that according to the second law of thermodynamics, all energy transfers involve the loss of some amount of energy in an unusable form such as heat. Free energy specifically refers to the energy associated with a chemical reaction that is available after the losses are accounted for. In other words, free energy is usable energy, or energy that is available to do work.
If energy is released during a chemical reaction, then the change in free energy, signified as ∆G (delta G) will be a negative number. A negative change in free energy also means that the products of the reaction have less free energy than the reactants, because they release some free energy during the reaction. Reactions that have a negative change in free energy and consequently release free energy are called exergonic reactions. Think: exergonic means energy is exiting the system. These reactions are also referred to as spontaneous reactions, and their products have less stored energy than the reactants. An important distinction must be drawn between the term spontaneous and the idea of a chemical reaction occurring immediately. Contrary to the everyday use of the term, a spontaneous reaction is not one that suddenly or quickly occurs. The rusting of iron is an example of a spontaneous reaction that occurs slowly, little by little, over time.
If a chemical reaction absorbs energy rather than releases energy on balance, then the ∆G for that reaction will be a positive value. In this case, the products have more free energy than the reactants. Thus, the products of these reactions can be thought of as energy-storing molecules. These chemical reactions are called endergonic reactions and they are non-spontaneous. An endergonic reaction will not take place on its own without the addition of free energy.

Look at each of the processes shown and decide if it is endergonic or exergonic.
There is another important concept that must be considered regarding endergonic and exergonic reactions. Exergonic reactions require a small amount of energy input to get going, before they can proceed with their energy-releasing steps. These reactions have a net release of energy, but still require some energy input in the beginning. This small amount of energy input necessary for all chemical reactions to occur is called the activation energy.

Watch an animation of the move from free energy to transition state of the reaction.
A substance that helps a chemical reaction to occur is called a catalyst, and the molecules that catalyze biochemical reactions are called enzymes. Most enzymes are proteins and perform the critical task of lowering the activation energies of chemical reactions inside the cell. Most of the reactions critical to a living cell happen too slowly at normal temperatures to be of any use to the cell. Without enzymes to speed up these reactions, life could not persist. Enzymes do this by binding to the reactant molecules and holding them in such a way as to make the chemical bond-breaking and -forming processes take place more easily. It is important to remember that enzymes do not change whether a reaction is exergonic (spontaneous) or endergonic. This is because they do not change the free energy of the reactants or products. They only reduce the activation energy required for the reaction to go forward (Figure 4.7). In addition, an enzyme itself is unchanged by the reaction it catalyzes. Once one reaction has been catalyzed, the enzyme is able to participate in other reactions.
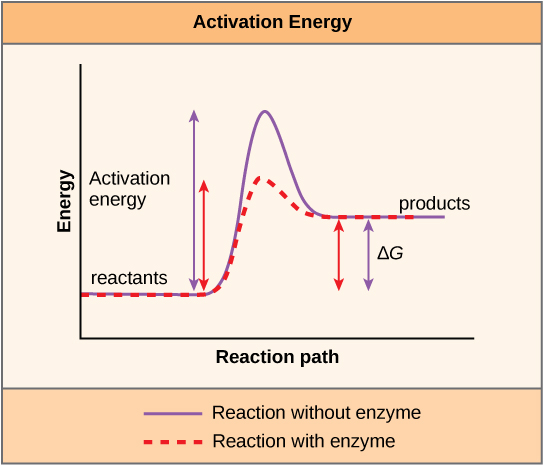
The chemical reactants to which an enzyme binds are called the enzyme’s substrates. There may be one or more substrates, depending on the particular chemical reaction. In some reactions, a single reactant substrate is broken down into multiple products. In others, two substrates may come together to create one larger molecule. Two reactants might also enter a reaction and both become modified, but they leave the reaction as two products. The location within the enzyme where the substrate binds is called the enzyme’s active site. The active site is where the “action” happens. Since enzymes are proteins, there is a unique combination of amino acid side chains within the active site. Each side chain is characterized by different properties. They can be large or small, weakly acidic or basic, hydrophilic or hydrophobic, positively or negatively charged, or neutral. The unique combination of side chains creates a very specific chemical environment within the active site. This specific environment is suited to bind to one specific chemical substrate (or substrates).
Active sites are subject to influences of the local environment. Increasing the environmental temperature generally increases reaction rates, enzyme-catalyzed or otherwise. However, temperatures outside of an optimal range reduce the rate at which an enzyme catalyzes a reaction. Hot temperatures will eventually cause enzymes to denature, an irreversible change in the three-dimensional shape and therefore the function of the enzyme. Enzymes are also suited to function best within a certain pH and salt concentration range, and, as with temperature, extreme pH, and salt concentrations can cause enzymes to denature.
For many years, scientists thought that enzyme-substrate binding took place in a simple “lock and key” fashion. This model asserted that the enzyme and substrate fit together perfectly in one instantaneous step. However, current research supports a model called induced fit (Figure 4.8). The induced-fit model expands on the lock-and-key model by describing a more dynamic binding between enzyme and substrate. As the enzyme and substrate come together, their interaction causes a mild shift in the enzyme’s structure that forms an ideal binding arrangement between enzyme and substrate.
When an enzyme binds its substrate, an enzyme-substrate complex is formed. This complex lowers the activation energy of the reaction and promotes its rapid progression in one of multiple possible ways. On a basic level, enzymes promote chemical reactions that involve more than one substrate by bringing the substrates together in an optimal orientation for reaction. Another way in which enzymes promote the reaction of their substrates is by creating an optimal environment within the active site for the reaction to occur. The chemical properties that emerge from the particular arrangement of amino acid R groups within an active site create the perfect environment for an enzyme’s specific substrates to react.
The enzyme-substrate complex can also lower activation energy by compromising the bond structure so that it is easier to break. Finally, enzymes can also lower activation energies by taking part in the chemical reaction itself. In these cases, it is important to remember that the enzyme will always return to its original state by the completion of the reaction. One of the hallmark properties of enzymes is that they remain ultimately unchanged by the reactions they catalyze. After an enzyme has catalyzed a reaction, it releases its product(s) and can catalyze a new reaction.
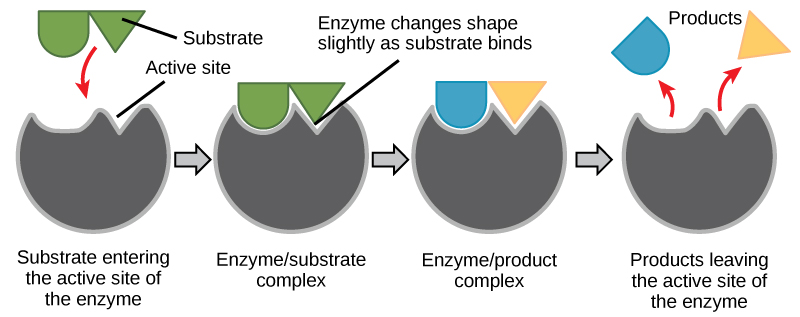
It would seem ideal to have a scenario in which all of an organism’s enzymes existed in abundant supply and functioned optimally under all cellular conditions, in all cells, at all times. However, a variety of mechanisms ensures that this does not happen. Cellular needs and conditions constantly vary from cell to cell, and change within individual cells over time. The required enzymes of stomach cells differ from those of fat storage cells, skin cells, blood cells, and nerve cells. Furthermore, a digestive organ cell works much harder to process and break down nutrients during the time that closely follows a meal compared with many hours after a meal. As these cellular demands and conditions vary, so must the amounts and functionality of different enzymes.
Since the rates of biochemical reactions are controlled by activation energy, and enzymes lower and determine activation energies for chemical reactions, the relative amounts and functioning of the variety of enzymes within a cell ultimately determine which reactions will proceed and at what rates. This determination is tightly controlled in cells. In certain cellular environments, enzyme activity is partly controlled by environmental factors like pH, temperature, salt concentration, and, in some cases, cofactors or coenzymes.
Enzymes can also be regulated in ways that either promote or reduce enzyme activity. There are many kinds of molecules that inhibit or promote enzyme function, and various mechanisms by which they do so. In some cases of enzyme inhibition, an inhibitor molecule is similar enough to a substrate that it can bind to the active site and simply block the substrate from binding. When this happens, the enzyme is inhibited through competitive inhibition, because an inhibitor molecule competes with the substrate for binding to the active site.
On the other hand, in noncompetitive inhibition, an inhibitor molecule binds to the enzyme in a location other than the active site, called an allosteric site, but still manages to block substrate binding to the active site. Some inhibitor molecules bind to enzymes in a location where their binding induces a conformational change that reduces the affinity of the enzyme for its substrate. This type of inhibition is called allosteric inhibition (Figure 4.9). Most allosterically regulated enzymes are made up of more than one polypeptide, meaning that they have more than one protein subunit. When an allosteric inhibitor binds to a region on an enzyme, all active sites on the protein subunits are changed slightly such that they bind their substrates with less efficiency. There are allosteric activators as well as inhibitors. Allosteric activators bind to locations on an enzyme away from the active site, inducing a conformational change that increases the affinity of the enzyme’s active site(s) for its substrate(s) (Figure 4.9).
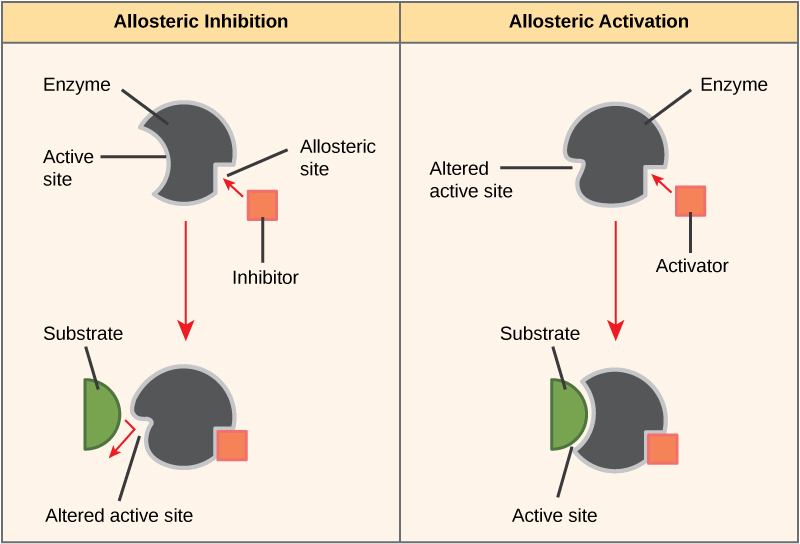
Plants cannot run or hide from their predators and have evolved many strategies to deter those who would eat them. Think of thorns, irritants and secondary metabolites: these are compounds that do not directly help the plant grow, but are made specifically to keep predators away. Secondary metabolites are the most common way plants deter predators. Some examples of secondary metabolites are atropine, nicotine, THC and caffeine. Humans have found these secondary metabolite compounds a rich source of materials for medicines. It is estimated that 90% of the drugs in the modern pharmacy have their “roots” in these secondary metabolites.
First peoples herbal treatments revealed these secondary metabolites to the world. For example, Indigenous peoples have long used the bark of willow shrubs and alder trees for a tea, tonic or poultice to reduce inflammation. You will learn more about the inflammation response by the immune system in chapter 11.

Both willow and alder bark contain the compound salicin. Most of us have this compound in our medicine cupboard in the form of salicylic acid or aspirin. Aspirin has been proved to reduce pain and inflammation, and once in our cells salicin converts to salicylic acid.
So how does it work? Salicin or aspirin acts as an enzyme inhibitor. In the inflammatory response two enzymes, COX1 and COX2 are key to this process. Salicin or aspirin specifically modifies an amino acid (serine) in the active site of these two related enzymes. This modification of the active sites does not allow the normal substrate to bind and so the inflammatory process is disrupted. As you have read in this chapter, this makes it competitive enzyme inhibitor.
Pharmaceutical Drug Developer

Enzymes are key components of metabolic pathways. Understanding how enzymes work and how they can be regulated are key principles behind the development of many of the pharmaceutical drugs on the market today. Biologists working in this field collaborate with other scientists to design drugs (Figure 4.11).
Consider statins for example—statins is the name given to one class of drugs that can reduce cholesterol levels. These compounds are inhibitors of the enzyme HMG-CoA reductase, which is the enzyme that synthesizes cholesterol from lipids in the body. By inhibiting this enzyme, the level of cholesterol synthesized in the body can be reduced. Similarly, acetaminophen, popularly marketed under the brand name Tylenol, is an inhibitor of the enzyme cyclooxygenase. While it is used to provide relief from fever and inflammation (pain), its mechanism of action is still not completely understood.
How are drugs discovered? One of the biggest challenges in drug discovery is identifying a drug target. A drug target is a molecule that is literally the target of the drug. In the case of statins, HMG-CoA reductase is the drug target. Drug targets are identified through painstaking research in the laboratory. Identifying the target alone is not enough; scientists also need to know how the target acts inside the cell and which reactions go awry in the case of disease. Once the target and the pathway are identified, then the actual process of drug design begins. In this stage, chemists and biologists work together to design and synthesize molecules that can block or activate a particular reaction. However, this is only the beginning: If and when a drug prototype is successful in performing its function, then it is subjected to many tests from in vitro experiments to clinical trials before it can get approval from the U.S. Food and Drug Administration to be on the market.
Many enzymes do not work optimally, or even at all, unless bound to other specific non-protein helper molecules. They may bond either temporarily through ionic or hydrogen bonds, or permanently through stronger covalent bonds. Binding to these molecules promotes optimal shape and function of their respective enzymes. Two examples of these types of helper molecules are cofactors and coenzymes. Cofactors are inorganic ions such as ions of iron and magnesium. Coenzymes are organic helper molecules, those with a basic atomic structure made up of carbon and hydrogen. Like enzymes, these molecules participate in reactions without being changed themselves and are ultimately recycled and reused. Vitamins are the source of coenzymes. Some vitamins are the precursors of coenzymes and others act directly as coenzymes. Vitamin C is a direct coenzyme for multiple enzymes that take part in building the important connective tissue, collagen. Therefore, enzyme function is, in part, regulated by the abundance of various cofactors and coenzymes, which may be supplied by an organism’s diet or, in some cases, produced by the organism.
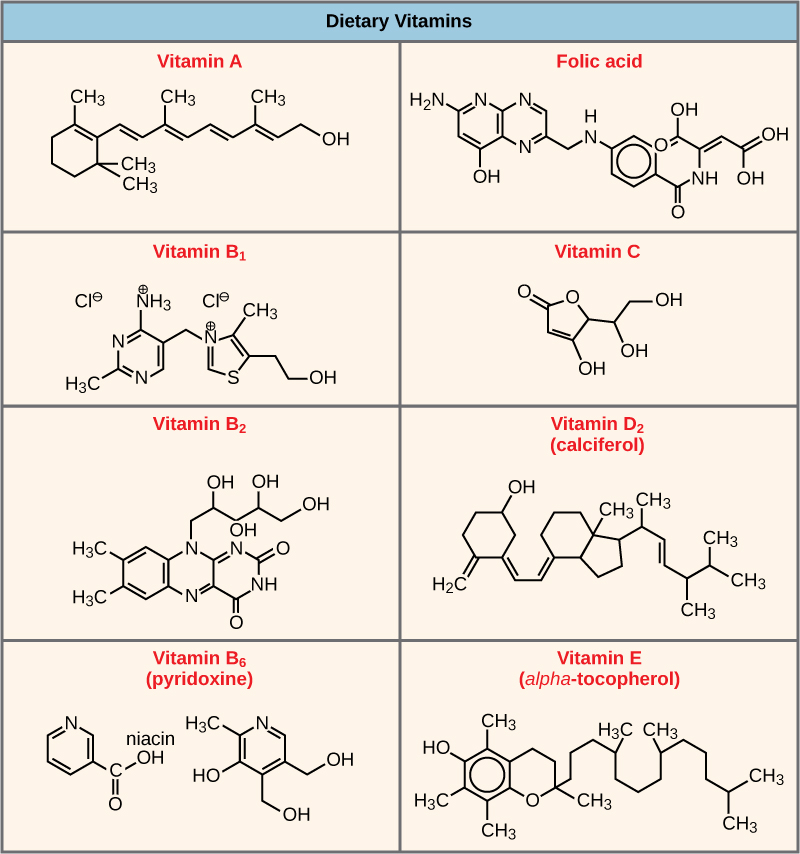
Molecules can regulate enzyme function in many ways. The major question remains, however: What are these molecules and where do they come from? Some are cofactors and coenzymes, as you have learned. What other molecules in the cell provide enzymatic regulation such as allosteric modulation, and competitive and non-competitive inhibition? Perhaps the most relevant sources of regulatory molecules, with respect to enzymatic cellular metabolism, are the products of the cellular metabolic reactions themselves. In a most efficient and elegant way, cells have evolved to use the products of their own reactions for feedback inhibition of enzyme activity. Feedback inhibition involves the use of a reaction product to regulate its own further production (Figure 4.12). The cell responds to an abundance of the products by slowing down production during anabolic or catabolic reactions. Such reaction products may inhibit the enzymes that catalyzed their production through the mechanisms described above.
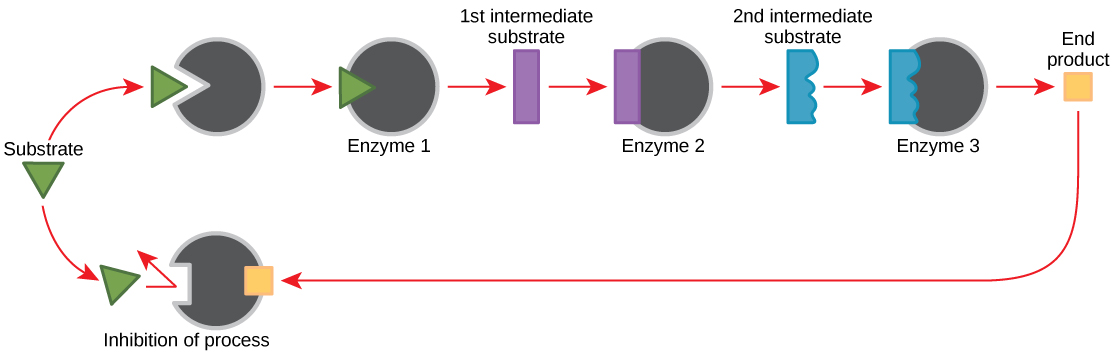
The production of both amino acids and nucleotides is controlled through feedback inhibition. Additionally, ATP is an allosteric regulator of some of the enzymes involved in the catabolic breakdown of sugar, the process that creates ATP. In this way, when ATP is in abundant supply, the cell can prevent the production of ATP. On the other hand, ADP serves as a positive allosteric regulator (an allosteric activator) for some of the same enzymes that are inhibited by ATP. Thus, when relative levels of ADP are high compared to ATP, the cell is triggered to produce more ATP through sugar catabolism.
Cells perform the functions of life through various chemical reactions. A cell’s metabolism refers to the combination of chemical reactions that take place within it. Catabolic reactions break down complex chemicals into simpler ones and are associated with energy release. Anabolic processes build complex molecules out of simpler ones and require energy.
In studying energy, the term system refers to the matter and environment involved in energy transfers. Entropy is a measure of the disorder of a system. The physical laws that describe the transfer of energy are the laws of thermodynamics. The first law states that the total amount of energy in the universe is constant. The second law of thermodynamics states that every energy transfer involves some loss of energy in an unusable form, such as heat energy. Energy comes in different forms: kinetic, potential, and free. The change in free energy of a reaction can be negative (releases energy, exergonic) or positive (consumes energy, endergonic). All reactions require an initial input of energy to proceed, called the activation energy.
Enzymes are chemical catalysts that speed up chemical reactions by lowering their activation energy. Enzymes have an active site with a unique chemical environment that fits particular chemical reactants for that enzyme, called substrates. Enzymes and substrates are thought to bind according to an induced-fit model. Enzyme action is regulated to conserve resources and respond optimally to the environment.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=150#h5p-29
activation energy: the amount of initial energy necessary for reactions to occur
active site: a specific region on the enzyme where the substrate binds
allosteric inhibition: the mechanism for inhibiting enzyme action in which a regulatory molecule binds to a second site (not the active site) and initiates a conformation change in the active site, preventing binding with the substrate
anabolic: describes the pathway that requires a net energy input to synthesize complex molecules from simpler ones
bioenergetics: the concept of energy flow through living systems
catabolic: describes the pathway in which complex molecules are broken down into simpler ones, yielding energy as an additional product of the reaction
competitive inhibition: a general mechanism of enzyme activity regulation in which a molecule other than the enzyme’s substrate is able to bind the active site and prevent the substrate itself from binding, thus inhibiting the overall rate of reaction for the enzyme
endergonic: describes a chemical reaction that results in products that store more chemical potential energy than the reactants
enzyme: a molecule that catalyzes a biochemical reaction
exergonic: describes a chemical reaction that results in products with less chemical potential energy than the reactants, plus the release of free energy
feedback inhibition: a mechanism of enzyme activity regulation in which the product of a reaction or the final product of a series of sequential reactions inhibits an enzyme for an earlier step in the reaction series
heat energy: the energy transferred from one system to another that is not work
kinetic energy: the type of energy associated with objects in motion
metabolism: all the chemical reactions that take place inside cells, including those that use energy and those that release energy
noncompetitive inhibition: a general mechanism of enzyme activity regulation in which a regulatory molecule binds to a site other than the active site and prevents the active site from binding the substrate; thus, the inhibitor molecule does not compete with the substrate for the active site; allosteric inhibition is a form of noncompetitive inhibition
potential energy: the type of energy that refers to the potential to do work
substrate: a molecule on which the enzyme acts
thermodynamics: the science of the relationships between heat, energy, and work
By the end of this section, you will be able to:
Energy production within a cell involves many coordinated chemical pathways. Most of these pathways are combinations of oxidation and reduction reactions. Oxidation and reduction occur in tandem. An oxidation reaction strips an electron from an atom in a compound, and the addition of this electron to another compound is a reduction reaction. Because oxidation and reduction usually occur together, these pairs of reactions are called oxidation-reduction reactions, or redox reactions.
The removal of an electron from a molecule, oxidizing it, results in a decrease in potential energy in the oxidized compound. The electron (sometimes as part of a hydrogen atom) does not remain unbonded, however, in the cytoplasm of a cell. Rather, the electron is shifted to a second compound, reducing the second compound. The shift of an electron from one compound to another removes some potential energy from the first compound (the oxidized compound) and increases the potential energy of the second compound (the reduced compound). The transfer of electrons between molecules is important because most of the energy stored in atoms and used to fuel cell functions is in the form of high-energy electrons. The transfer of energy in the form of electrons allows the cell to transfer and use energy in an incremental fashion—in small packages rather than in a single, destructive burst. This chapter focuses on the extraction of energy from food. You will see that as you track the path of the transfers, you are tracking the path of electrons moving through metabolic pathways.
In living systems, a small class of compounds functions as electron shuttles: they bind and carry high-energy electrons between compounds in pathways. The principal electron carriers we will consider are derived from the B vitamin group and are derivatives of nucleotides. These compounds can be easily reduced (that is, they accept electrons) or oxidized (they lose electrons). Nicotinamide adenine dinucleotide (NAD) (Figure 4.13) is derived from vitamin B3, niacin. NAD+ is the oxidized form of the molecule; NADH is the reduced form of the molecule after it has accepted two electrons and a proton (which together are the equivalent of a hydrogen atom with an extra electron).
NAD+ can accept electrons from an organic molecule according to the general equation:
RH (Reducing Agent) + NAD + (Oxidizing Agent) —-> NADH (Reduced) + R (Oxidized)
When electrons are added to a compound, they are reduced. A compound that reduces another is called a reducing agent. In the above equation, RH is a reducing agent, and NAD+ is reduced to NADH. When electrons are removed from compound, it is oxidized. A compound that oxidizes another is called an oxidizing agent. In the above equation, NAD+ is an oxidizing agent, and RH is oxidized to R.
Similarly, flavin adenine dinucleotide (FAD+) is derived from vitamin B2, also called riboflavin. Its reduced form is FADH2. A second variation of NAD, NADP, contains an extra phosphate group. Both NAD+ and FAD+ are extensively used in energy extraction from sugars, and NADP plays an important role in anabolic reactions and photosynthesis.

A living cell cannot store significant amounts of free energy. Excess free energy would result in an increase of heat in the cell, which would result in excessive thermal motion that could damage and then destroy the cell. Rather, a cell must be able to handle that energy in a way that enables the cell to store the energy safely and release it for use only as needed. Living cells accomplish this by using the compound adenosine triphosphate (ATP). ATP is often called the “energy currency” of the cell, and, like currency, this versatile compound can be used to fill any energy need of the cell. How? It functions similarly to a rechargeable battery.
When ATP is broken down, usually by the removal of its terminal phosphate group, energy is released. The cell uses the energy to do work, usually by the released phosphate binding to another molecule, activating it. For example, in the mechanical work of muscle contraction, ATP supplies the energy to move the contractile muscle proteins. Recall the active transport work of the sodium-potassium pump in cell membranes. ATP alters the structure of the integral protein that functions as the pump, changing its affinity for sodium and potassium. In this way, the cell performs work, pumping ions against their electrochemical gradients.
At the heart of ATP is a molecule of adenosine monophosphate (AMP), which is composed of an adenine molecule bonded to a ribose molecule and a single phosphate group (Figure 4.14). Ribose is a five-carbon sugar found in RNA, and AMP is one of the nucleotides in RNA. The addition of a second phosphate group to this core molecule results in the formation of adenosine diphosphate (ADP); the addition of a third phosphate group forms adenosine triphosphate (ATP).
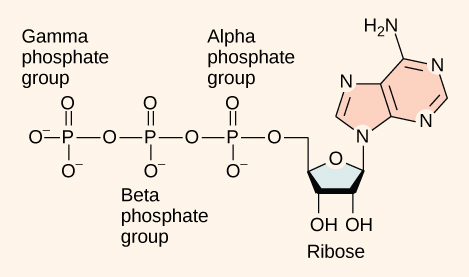
The addition of a phosphate group to a molecule requires energy. Phosphate groups are negatively charged and thus repel one another when they are arranged in series, as they are in ADP and ATP. This repulsion makes the ADP and ATP molecules inherently unstable. The release of one or two phosphate groups from ATP, a process called dephosphorylation, releases energy.
Even exergonic, energy-releasing reactions require a small amount of activation energy to proceed. However, consider endergonic reactions, which require much more energy input because their products have more free energy than their reactants. Within the cell, where does energy to power such reactions come from? The answer lies with an energy-supplying molecule called adenosine triphosphate, or ATP. ATP is a small, relatively simple molecule, but within its bonds contains the potential for a quick burst of energy that can be harnessed to perform cellular work. This molecule can be thought of as the primary energy currency of cells in the same way that money is the currency that people exchange for things they need. ATP is used to power the majority of energy-requiring cellular reactions.
A living cell cannot store significant amounts of free energy. Excess free energy would result in an increase of heat in the cell, which would denature enzymes and other proteins, and thus destroy the cell. Rather, a cell must be able to store energy safely and release it for use only as needed. Living cells accomplish this using ATP, which can be used to fill any energy need of the cell. How? It functions as a rechargeable battery.
When ATP is broken down, usually by the removal of its terminal phosphate group, energy is released. This energy is used to do work by the cell, usually by the binding of the released phosphate to another molecule, thus activating it. For example, in the mechanical work of muscle contraction, ATP supplies energy to move the contractile muscle proteins.
At the heart of ATP is a molecule of adenosine monophosphate (AMP), which is composed of an adenine molecule bonded to both a ribose molecule and a single phosphate group (Figure 4.15). Ribose is a five-carbon sugar found in RNA and AMP is one of the nucleotides in RNA. The addition of a second phosphate group to this core molecule results in adenosine diphosphate (ADP); the addition of a third phosphate group forms adenosine triphosphate (ATP).
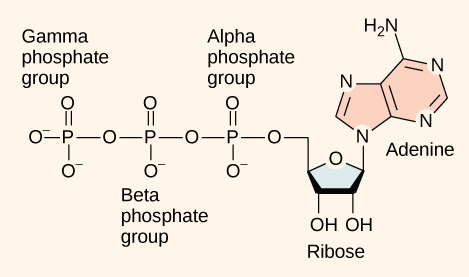
The addition of a phosphate group to a molecule requires a high amount of energy and results in a high-energy bond. Phosphate groups are negatively charged and thus repel one another when they are arranged in series, as they are in ADP and ATP. This repulsion makes the ADP and ATP molecules inherently unstable. The release of one or two phosphate groups from ATP, a process called hydrolysis, releases energy.
You have read that nearly all of the energy used by living things comes to them in the bonds of the sugar, glucose. Glycolysis is the first step in the breakdown of glucose to extract energy for cell metabolism. Many living organisms carry out glycolysis as part of their metabolism. Glycolysis takes place in the cytoplasm of most prokaryotic and all eukaryotic cells.
Glycolysis begins with the six-carbon, ring-shaped structure of a single glucose molecule and ends with two molecules of a three-carbon sugar called pyruvate. Glycolysis consists of two distinct phases. In the first part of the glycolysis pathway, energy is used to make adjustments so that the six-carbon sugar molecule can be split evenly into two three-carbon pyruvate molecules. In the second part of glycolysis, ATP and nicotinamide-adenine dinucleotide (NADH) are produced (Figure 4.16).
If the cell cannot catabolize the pyruvate molecules further, it will harvest only two ATP molecules from one molecule of glucose. For example, mature mammalian red blood cells are only capable of glycolysis, which is their sole source of ATP. If glycolysis is interrupted, these cells would eventually die.
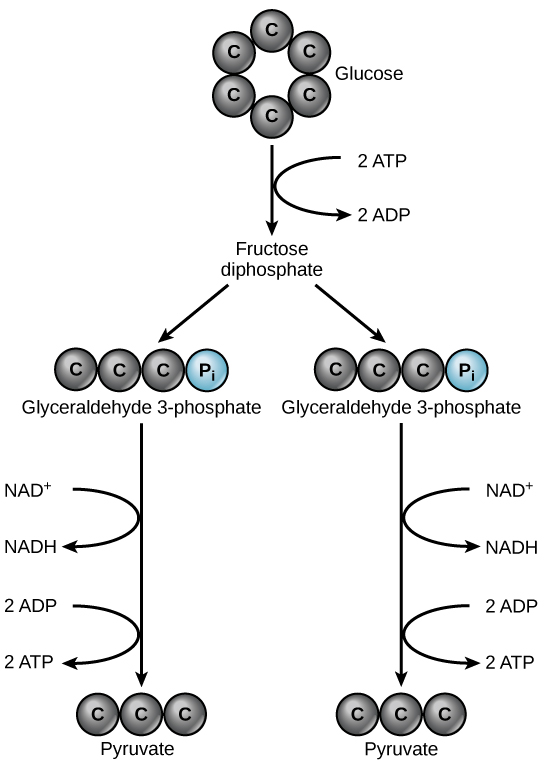
ATP functions as the energy currency for cells. It allows cells to store energy briefly and transport it within itself to support endergonic chemical reactions. The structure of ATP is that of an RNA nucleotide with three phosphate groups attached. As ATP is used for energy, a phosphate group is detached, and ADP is produced. Energy derived from glucose catabolism is used to recharge ADP into ATP.
Glycolysis is the first pathway used in the breakdown of glucose to extract energy. Because it is used by nearly all organisms on earth, it must have evolved early in the history of life. Glycolysis consists of two parts: The first part prepares the six-carbon ring of glucose for separation into two three-carbon sugars. Energy from ATP is invested into the molecule during this step to energize the separation. The second half of glycolysis extracts ATP and high-energy electrons from hydrogen atoms and attaches them to NAD+. Two ATP molecules are invested in the first half and four ATP molecules are formed during the second half. This produces a net gain of two ATP molecules per molecule of glucose for the cell.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=156#h5p-30
ATP: (also, adenosine triphosphate) the cell’s energy currency
glycolysis: the process of breaking glucose into two three-carbon molecules with the production of ATP and NADH
By the end of this section, you will be able to:
In eukaryotic cells, the pyruvate molecules produced at the end of glycolysis are transported into mitochondria, which are sites of cellular respiration. If oxygen is available, aerobic respiration will go forward. In mitochondria, pyruvate will be transformed into a two-carbon acetyl group (by removing a molecule of carbon dioxide) that will be picked up by a carrier compound called coenzyme A (CoA), which is made from vitamin B5. The resulting compound is called acetyl CoA. (Figure 4.17). Acetyl CoA can be used in a variety of ways by the cell, but its major function is to deliver the acetyl group derived from pyruvate to the next pathway in glucose catabolism.
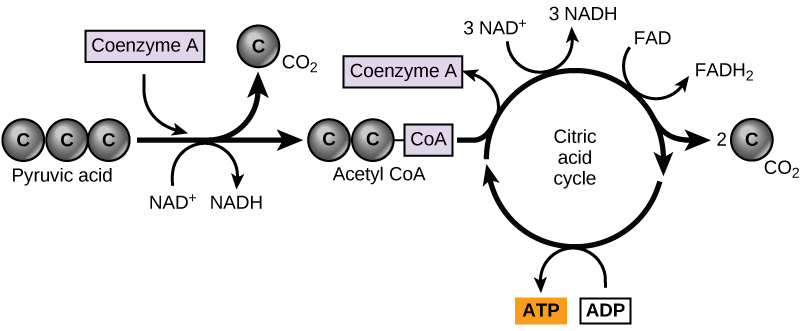
Like the conversion of pyruvate to acetyl CoA, the citric acid cycle in eukaryotic cells takes place in the matrix of the mitochondria. Unlike glycolysis, the citric acid cycle is a closed loop: The last part of the pathway regenerates the compound used in the first step. The eight steps of the cycle are a series of chemical reactions that produces two carbon dioxide molecules, one ATP molecule (or an equivalent), and reduced forms (NADH and FADH2) of NAD+ and FAD+, important coenzymes in the cell. Part of this is considered an aerobic pathway (oxygen-requiring) because the NADH and FADH2 produced must transfer their electrons to the next pathway in the system, which will use oxygen. If oxygen is not present, this transfer does not occur.
Two carbon atoms come into the citric acid cycle from each acetyl group. Two carbon dioxide molecules are released on each turn of the cycle; however, these do not contain the same carbon atoms contributed by the acetyl group on that turn of the pathway. The two acetyl-carbon atoms will eventually be released on later turns of the cycle; in this way, all six carbon atoms from the original glucose molecule will be eventually released as carbon dioxide. It takes two turns of the cycle to process the equivalent of one glucose molecule. Each turn of the cycle forms three high-energy NADH molecules and one high-energy FADH2 molecule. These high-energy carriers will connect with the last portion of aerobic respiration to produce ATP molecules. One ATP (or an equivalent) is also made in each cycle. Several of the intermediate compounds in the citric acid cycle can be used in synthesizing non-essential amino acids; therefore, the cycle is both anabolic and catabolic.
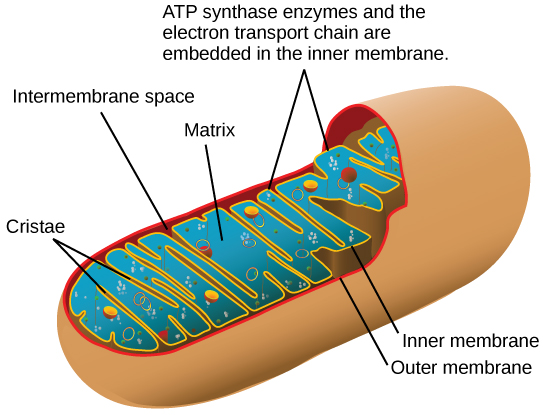
You have just read about two pathways in glucose catabolism—glycolysis and the citric acid cycle—that generate ATP. Most of the ATP generated during the aerobic catabolism of glucose, however, is not generated directly from these pathways. Rather, it derives from a process that begins with passing electrons through a series of chemical reactions to a final electron acceptor, oxygen. These reactions take place in specialized protein complexes located in the inner membrane of the mitochondria of eukaryotic organisms and on the inner part of the cell membrane of prokaryotic organisms. The energy of the electrons is harvested and used to generate a electrochemical gradient across the inner mitochondrial membrane. The potential energy of this gradient is used to generate ATP. The entirety of this process is called oxidative phosphorylation.
The electron transport chain (Figure 4.19 a) is the last component of aerobic respiration and is the only part of metabolism that uses atmospheric oxygen. Oxygen continuously diffuses into plants for this purpose. In animals, oxygen enters the body through the respiratory system. Electron transport is a series of chemical reactions that resembles a bucket brigade in that electrons are passed rapidly from one component to the next, to the endpoint of the chain where oxygen is the final electron acceptor and water is produced. There are four complexes composed of proteins, labeled I through IV in Figure 4.19 c, and the aggregation of these four complexes, together with associated mobile, accessory electron carriers, is called the electron transport chain. The electron transport chain is present in multiple copies in the inner mitochondrial membrane of eukaryotes and in the plasma membrane of prokaryotes. In each transfer of an electron through the electron transport chain, the electron loses energy, but with some transfers, the energy is stored as potential energy by using it to pump hydrogen ions across the inner mitochondrial membrane into the intermembrane space, creating an electrochemical gradient.
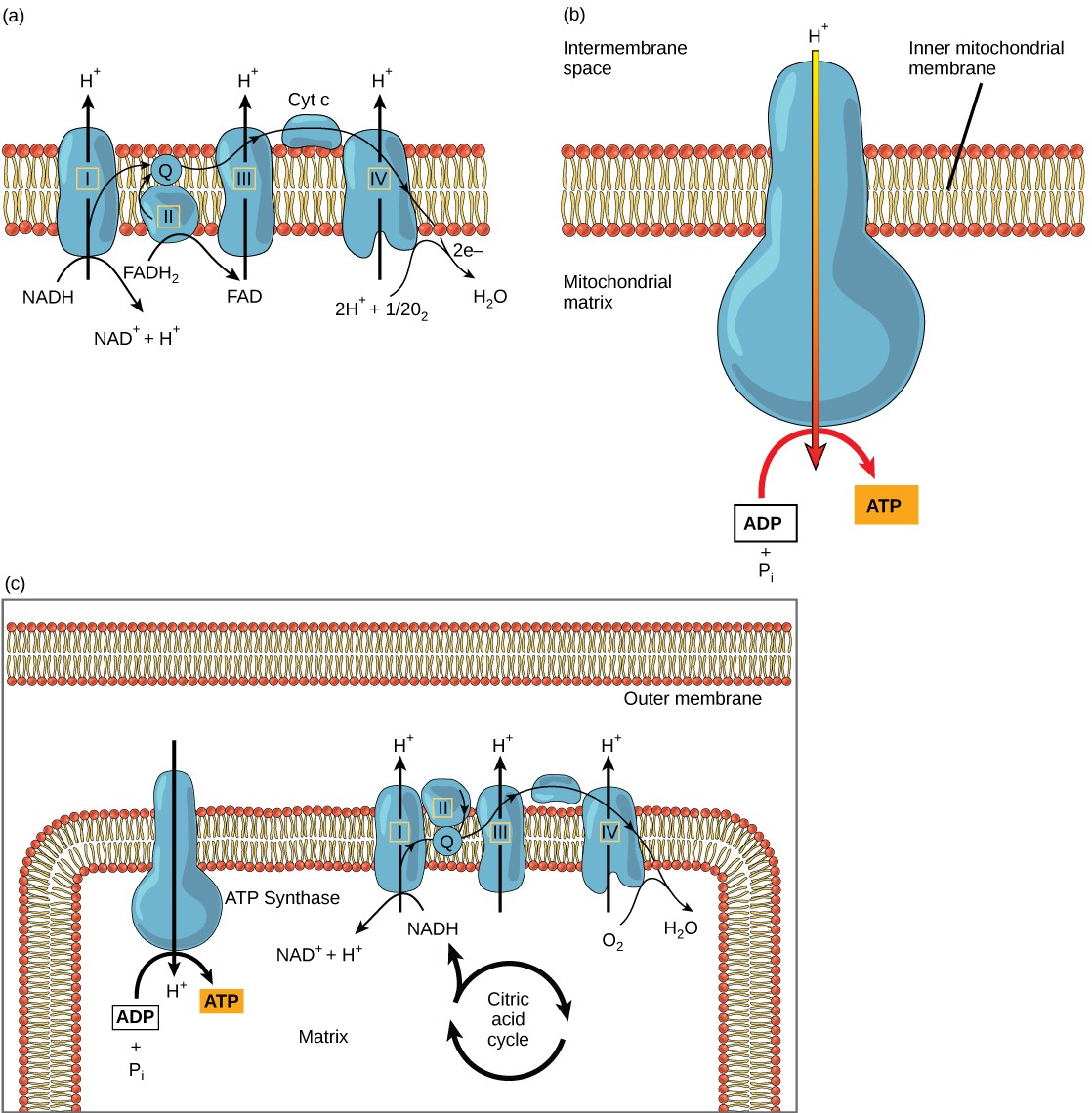
Cyanide inhibits cytochrome c oxidase, a component of the electron transport chain. If cyanide poisoning occurs, would you expect the pH of the intermembrane space to increase or decrease? What affect would cyanide have on ATP synthesis?
Electrons from NADH and FADH2 are passed to protein complexes in the electron transport chain. As they are passed from one complex to another (there are a total of four), the electrons lose energy, and some of that energy is used to pump hydrogen ions from the mitochondrial matrix into the intermembrane space. In the fourth protein complex, the electrons are accepted by oxygen, the terminal acceptor. The oxygen with its extra electrons then combines with two hydrogen ions, further enhancing the electrochemical gradient, to form water. If there were no oxygen present in the mitochondrion, the electrons could not be removed from the system, and the entire electron transport chain would back up and stop. The mitochondria would be unable to generate new ATP in this way, and the cell would ultimately die from lack of energy. This is the reason we must breathe to draw in new oxygen.
In the electron transport chain, the free energy from the series of reactions just described is used to pump hydrogen ions across the membrane. The uneven distribution of H+ ions across the membrane establishes an electrochemical gradient, owing to the H+ ions’ positive charge and their higher concentration on one side of the membrane.
Hydrogen ions diffuse through the inner membrane through an integral membrane protein called ATP synthase (Figure 4.19 b). This complex protein acts as a tiny generator, turned by the force of the hydrogen ions diffusing through it, down their electrochemical gradient from the intermembrane space, where there are many mutually repelling hydrogen ions to the matrix, where there are few. The turning of the parts of this molecular machine regenerate ATP from ADP. This flow of hydrogen ions across the membrane through ATP synthase is called chemiosmosis.
Chemiosmosis (Figure 4.19 c) is used to generate 90 percent of the ATP made during aerobic glucose catabolism. The result of the reactions is the production of ATP from the energy of the electrons removed from hydrogen atoms. These atoms were originally part of a glucose molecule. At the end of the electron transport system, the electrons are used to reduce an oxygen molecule to oxygen ions. The extra electrons on the oxygen ions attract hydrogen ions (protons) from the surrounding medium, and water is formed. The electron transport chain and the production of ATP through chemiosmosis are collectively called oxidative phosphorylation.
The number of ATP molecules generated from the catabolism of glucose varies. For example, the number of hydrogen ions that the electron transport chain complexes can pump through the membrane varies between species. Another source of variance stems from the shuttle of electrons across the mitochondrial membrane. The NADH generated from glycolysis cannot easily enter mitochondria. Thus, electrons are picked up on the inside of the mitochondria by either NAD+ or FAD+. Fewer ATP molecules are generated when FAD+ acts as a carrier. NAD+ is used as the electron transporter in the liver and FAD+ in the brain, so ATP yield depends on the tissue being considered.
Another factor that affects the yield of ATP molecules generated from glucose is that intermediate compounds in these pathways are used for other purposes. Glucose catabolism connects with the pathways that build or break down all other biochemical compounds in cells, and the result is somewhat messier than the ideal situations described thus far. For example, sugars other than glucose are fed into the glycolytic pathway for energy extraction. Other molecules that would otherwise be used to harvest energy in glycolysis or the citric acid cycle may be removed to form nucleic acids, amino acids, lipids, or other compounds. Overall, in living systems, these pathways of glucose catabolism extract about 34 percent of the energy contained in glucose.
What happens when the critical reactions of cellular respiration do not proceed correctly? Mitochondrial diseases are genetic disorders of metabolism. Mitochondrial disorders can arise from mutations in nuclear or mitochondrial DNA, and they result in the production of less energy than is normal in body cells. Symptoms of mitochondrial diseases can include muscle weakness, lack of coordination, stroke-like episodes, and loss of vision and hearing. Most affected people are diagnosed in childhood, although there are some adult-onset diseases. Identifying and treating mitochondrial disorders is a specialized medical field. The educational preparation for this profession requires a college education, followed by medical school with a specialization in medical genetics. Medical geneticists can be board certified by the American Board of Medical Genetics and go on to become associated with professional organizations devoted to the study of mitochondrial disease, such as the Mitochondrial Medicine Society and the Society for Inherited Metabolic Disease.
The citric acid cycle is a series of chemical reactions that removes high-energy electrons and uses them in the electron transport chain to generate ATP. One molecule of ATP (or an equivalent) is produced per each turn of the cycle.
The electron transport chain is the portion of aerobic respiration that uses free oxygen as the final electron acceptor for electrons removed from the intermediate compounds in glucose catabolism. The electrons are passed through a series of chemical reactions, with a small amount of free energy used at three points to transport hydrogen ions across the membrane. This contributes to the gradient used in chemiosmosis. As the electrons are passed from NADH or FADH2 down the electron transport chain, they lose energy. The products of the electron transport chain are water and ATP. A number of intermediate compounds can be diverted into the anabolism of other biochemical molecules, such as nucleic acids, non-essential amino acids, sugars, and lipids. These same molecules, except nucleic acids, can serve as energy sources for the glucose pathway.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=161#h5p-31
acetyl CoA: the combination of an acetyl group derived from pyruvic acid and coenzyme A which is made from pantothenic acid (a B-group vitamin)
ATP synthase: a membrane-embedded protein complex that regenerates ATP from ADP with energy from protons diffusing through it
chemiosmosis: the movement of hydrogen ions down their electrochemical gradient across a membrane through ATP synthase to generate ATP
citric acid cycle: a series of enzyme-catalyzed chemical reactions of central importance in all living cells that harvests the energy in carbon-carbon bonds of sugar molecules to generate ATP; the citric acid cycle is an aerobic metabolic pathway because it requires oxygen in later reactions to proceed
electron transport chain: a series of four large, multi-protein complexes embedded in the inner mitochondrial membrane that accepts electrons from donor compounds and harvests energy from a series of chemical reactions to generate a hydrogen ion gradient across the membrane
oxidative phosphorylation: the production of ATP by the transfer of electrons down the electron transport chain to create a proton gradient that is used by ATP synthase to add phosphate groups to ADP molecules
By the end of this section, you will be able to:
In aerobic respiration, the final electron acceptor is an oxygen molecule, O2. If aerobic respiration occurs, then ATP will be produced using the energy of the high-energy electrons carried by NADH or FADH2 to the electron transport chain. If aerobic respiration does not occur, NADH must be reoxidized to NAD+ for reuse as an electron carrier for glycolysis to continue. How is this done? Some living systems use an organic molecule as the final electron acceptor. Processes that use an organic molecule to regenerate NAD+ from NADH are collectively referred to as fermentation. In contrast, some living systems use an inorganic molecule as a final electron acceptor; both methods are a type of anaerobic cellular respiration. Anaerobic respiration enables organisms to convert energy for their use in the absence of oxygen.
The fermentation method used by animals and some bacteria like those in yogurt is lactic acid fermentation (Figure 4.20). This occurs routinely in mammalian red blood cells and in skeletal muscle that has insufficient oxygen supply to allow aerobic respiration to continue (that is, in muscles used to the point of fatigue). In muscles, lactic acid produced by fermentation must be removed by the blood circulation and brought to the liver for further metabolism. The chemical reaction of lactic acid fermentation is the following:
The enzyme that catalyzes this reaction is lactate dehydrogenase. The reaction can proceed in either direction, but the left-to-right reaction is inhibited by acidic conditions. This lactic acid build-up causes muscle stiffness and fatigue. Once the lactic acid has been removed from the muscle and is circulated to the liver, it can be converted back to pyruvic acid and further catabolized for energy.
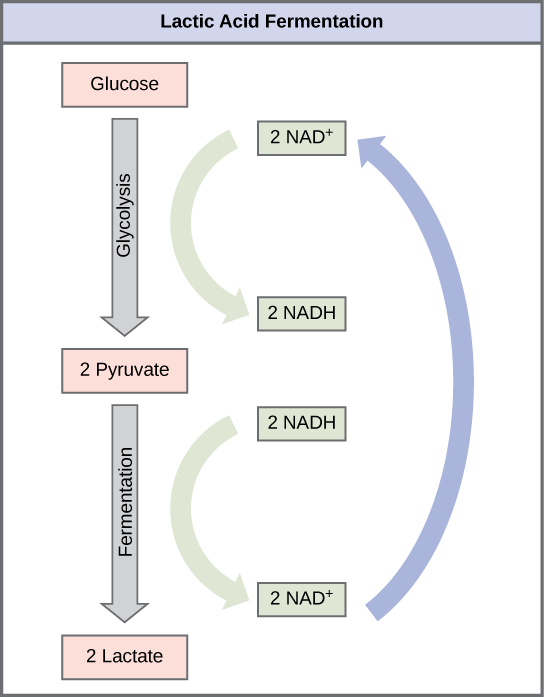
Tremetol, a metabolic poison found in white snake root plant, prevents the metabolism of lactate. When cows eat this plant, Tremetol is concentrated in the milk. Humans who consume the milk become ill. Symptoms of this disease, which include vomiting, abdominal pain, and tremors, become worse after exercise. Why do you think this is the case?
<!– The illness is caused by lactic acid build-up. Lactic acid levels rise after exercise, making the symptoms worse. Milk sickness is rare today, but was common in the Midwestern United States in the early 1800s. –>
Another familiar fermentation process is alcohol fermentation (Figure 4.21), which produces ethanol, an alcohol. The alcohol fermentation reaction is the following:

In the first reaction, a carboxyl group is removed from pyruvic acid, releasing carbon dioxide as a gas. The loss of carbon dioxide reduces the molecule by one carbon atom, making acetaldehyde. The second reaction removes an electron from NADH, forming NAD+ and producing ethanol from the acetaldehyde, which accepts the electron. The fermentation of pyruvic acid by yeast produces the ethanol found in alcoholic beverages (Figure 4.22). If the carbon dioxide produced by the reaction is not vented from the fermentation chamber, for example in beer and sparkling wines, it remains dissolved in the medium until the pressure is released. Ethanol above 12 percent is toxic to yeast, so natural levels of alcohol in wine occur at a maximum of 12 percent.

Certain prokaryotes, including some species of bacteria and Archaea, use anaerobic respiration. For example, the group of Archaea called methanogens reduces carbon dioxide to methane to oxidize NADH. These microorganisms are found in soil and in the digestive tracts of ruminants, such as cows and sheep. Similarly, sulfate-reducing bacteria and Archaea, most of which are anaerobic (Figure 4.23), reduce sulfate to hydrogen sulfide to regenerate NAD+ from NADH.

Other fermentation methods occur in bacteria. Many prokaryotes are facultatively anaerobic. This means that they can switch between aerobic respiration and fermentation, depending on the availability of oxygen. Certain prokaryotes, like Clostridia bacteria, are obligate anaerobes. Obligate anaerobes live and grow in the absence of molecular oxygen. Oxygen is a poison to these microorganisms and kills them upon exposure. It should be noted that all forms of fermentation, except lactic acid fermentation, produce gas. The production of particular types of gas is used as an indicator of the fermentation of specific carbohydrates, which plays a role in the laboratory identification of the bacteria. The various methods of fermentation are used by different organisms to ensure an adequate supply of NAD+ for the sixth step in glycolysis. Without these pathways, that step would not occur, and no ATP would be harvested from the breakdown of glucose.
If NADH cannot be metabolized through aerobic respiration, another electron acceptor is used. Most organisms will use some form of fermentation to accomplish the regeneration of NAD+, ensuring the continuation of glycolysis. The regeneration of NAD+ in fermentation is not accompanied by ATP production; therefore, the potential for NADH to produce ATP using an electron transport chain is not utilized.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=168#h5p-32
anaerobic cellular respiration: the use of an electron acceptor other than oxygen to complete metabolism using electron transport-based chemiosmosis
fermentation: the steps that follow the partial oxidation of glucose via glycolysis to regenerate NAD+; occurs in the absence of oxygen and uses an organic compound as the final electron acceptor
By the end of this section, you will be able to:
You have learned about the catabolism of glucose, which provides energy to living cells. But living things consume more than just glucose for food. How does a turkey sandwich, which contains protein, provide energy to your cells? This happens because all of the catabolic pathways for carbohydrates, proteins, and lipids eventually connect into glycolysis and the citric acid cycle pathways (Figure 4.24). Metabolic pathways should be thought of as porous—that is, substances enter from other pathways, and other substances leave for other pathways. These pathways are not closed systems. Many of the products in a particular pathway are reactants in other pathways.
Glycogen, a polymer of glucose, is a short-term energy storage molecule in animals. When there is adequate ATP present, excess glucose is converted into glycogen for storage. Glycogen is made and stored in the liver and muscle. Glycogen will be taken out of storage if blood sugar levels drop. The presence of glycogen in muscle cells as a source of glucose allows ATP to be produced for a longer time during exercise.
Sucrose is a disaccharide made from glucose and fructose bonded together. Sucrose is broken down in the small intestine, and the glucose and fructose are absorbed separately. Fructose is one of the three dietary monosaccharides, along with glucose and galactose (which is part of milk sugar, the disaccharide lactose), that are absorbed directly into the bloodstream during digestion. The catabolism of both fructose and galactose produces the same number of ATP molecules as glucose.
Proteins are broken down by a variety of enzymes in cells. Most of the time, amino acids are recycled into new proteins. If there are excess amino acids, however, or if the body is in a state of famine, some amino acids will be shunted into pathways of glucose catabolism. Each amino acid must have its amino group removed prior to entry into these pathways. The amino group is converted into ammonia. In mammals, the liver synthesizes urea from two ammonia molecules and a carbon dioxide molecule. Thus, urea is the principal waste product in mammals from the nitrogen originating in amino acids, and it leaves the body in urine.
The lipids that are connected to the glucose pathways are cholesterol and triglycerides. Cholesterol is a lipid that contributes to cell membrane flexibility and is a precursor of steroid hormones. The synthesis of cholesterol starts with acetyl CoA and proceeds in only one direction. The process cannot be reversed, and ATP is not produced.
Triglycerides are a form of long-term energy storage in animals. Triglycerides store about twice as much energy as carbohydrates. Triglycerides are made of glycerol and three fatty acids. Animals can make most of the fatty acids they need. Triglycerides can be both made and broken down through parts of the glucose catabolism pathways. Glycerol can be phosphorylated and proceeds through glycolysis. Fatty acids are broken into two-carbon units that enter the citric acid cycle.
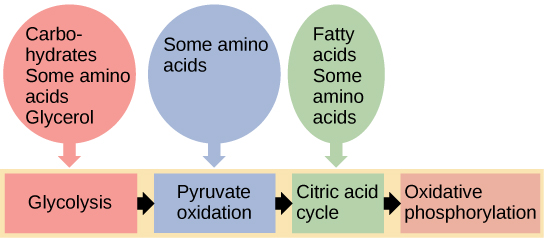
Pathways of Photosynthesis and Cellular Metabolism Photosynthesis and cellular metabolism consist of several very complex pathways. It is generally thought that the first cells arose in an aqueous environment—a “soup” of nutrients. If these cells reproduced successfully and their numbers climbed steadily, it follows that the cells would begin to deplete the nutrients from the medium in which they lived, as they shifted the nutrients into their own cells. This hypothetical situation would have resulted in natural selection favoring those organisms that could exist by using the nutrients that remained in their environment and by manipulating these nutrients into materials that they could use to survive. Additionally, selection would favor those organisms that could extract maximal value from the available nutrients.
An early form of photosynthesis developed that harnessed the sun’s energy using compounds other than water as a source of hydrogen atoms, but this pathway did not produce free oxygen. It is thought that glycolysis developed prior to this time and could take advantage of simple sugars being produced, but these reactions were not able to fully extract the energy stored in the carbohydrates. A later form of photosynthesis used water as a source of hydrogen ions and generated free oxygen. Over time, the atmosphere became oxygenated. Living things adapted to exploit this new atmosphere and allowed respiration as we know it to evolve. When the full process of photosynthesis as we know it developed and the atmosphere became oxygenated, cells were finally able to use the oxygen expelled by photosynthesis to extract more energy from the sugar molecules using the citric acid cycle.
The breakdown and synthesis of carbohydrates, proteins, and lipids connect with the pathways of glucose catabolism. The carbohydrates that can also feed into glucose catabolism include galactose, fructose, and glycogen. These connect with glycolysis. The amino acids from proteins connect with glucose catabolism through pyruvate, acetyl CoA, and components of the citric acid cycle. Cholesterol synthesis starts with acetyl CoA, and the components of triglycerides are picked up by acetyl CoA and enter the citric acid cycle.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=171#h5p-33

The individual sexually reproducing organism—including humans—begins life as a fertilized egg, or zygote. Trillions of cell divisions subsequently occur in a controlled manner to produce a complex, multicellular human. In other words, that original single cell was the ancestor of every other cell in the body. Once a human individual is fully grown, cell reproduction is still necessary to repair or regenerate tissues. For example, new blood and skin cells are constantly being produced. All multicellular organisms use cell division for growth, and in most cases, the maintenance and repair of cells and tissues. Single-celled organisms use cell division as their method of reproduction.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=174#h5p-34
By the end of this section, you will be able to:
The continuity of life from one cell to another has its foundation in the reproduction of cells by way of the cell cycle. The cell cycle is an orderly sequence of events in the life of a cell from the division of a single parent cell to produce two new daughter cells, to the subsequent division of those daughter cells. The mechanisms involved in the cell cycle are highly conserved across eukaryotes. Organisms as diverse as protists, plants, and animals employ similar steps.
Before discussing the steps a cell undertakes to replicate, a deeper understanding of the structure and function of a cell’s genetic information is necessary. A cell’s complete complement of DNA is called its genome. In prokaryotes, the genome is composed of a single, double-stranded DNA molecule in the form of a loop or circle. The region in the cell containing this genetic material is called a nucleoid. Some prokaryotes also have smaller loops of DNA called plasmids that are not essential for normal growth.
In eukaryotes, the genome comprises several double-stranded, linear DNA molecules (Figure 5.2) bound with proteins to form complexes called chromosomes. Each species of eukaryote has a characteristic number of chromosomes in the nuclei of its cells. Human body cells (somatic cells) have 46 chromosomes. A somatic cell contains two matched sets of chromosomes, a configuration known as diploid. The letter n is used to represent a single set of chromosomes; therefore a diploid organism is designated 2n. Human cells that contain one set of 23 chromosomes are called gametes, or sex cells; these eggs and sperm are designated n, or haploid.
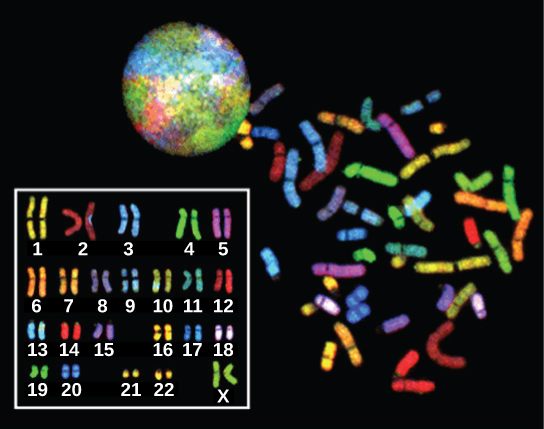
The matched pairs of chromosomes in a diploid organism are called homologous chromosomes. Homologous chromosomes are the same length and have specific nucleotide segments called genes in exactly the same location, or locus. Genes, the functional units of chromosomes, determine specific characteristics by coding for specific proteins. Traits are the different forms of a characteristic. For example, the shape of earlobes is a characteristic with traits of free or attached.
Each copy of the homologous pair of chromosomes originates from a different parent; therefore, the copies of each of the genes themselves may not be identical. The variation of individuals within a species is caused by the specific combination of the genes inherited from both parents. For example, there are three possible gene sequences on the human chromosome that codes for blood type: sequence A, sequence B, and sequence O. Because all diploid human cells have two copies of the chromosome that determines blood type, the blood type (the trait) is determined by which two versions of the marker gene are inherited. It is possible to have two copies of the same gene sequence, one on each homologous chromosome (for example, AA, BB, or OO), or two different sequences, such as AB.
Minor variations in traits such as those for blood type, eye color, and height contribute to the natural variation found within a species. The sex chromosomes, X and Y, are the single exception to the rule of homologous chromosomes; other than a small amount of homology that is necessary to reliably produce gametes, the genes found on the X and Y chromosomes are not the same.
Prokaryotes have a single loop chromosome, whereas eukaryotes have multiple, linear chromosomes surrounded by a nuclear membrane. Human somatic cells have 46 chromosomes consisting of two sets of 22 homologous chromosomes and a pair of nonhomologous sex chromosomes. This is the 2n, or diploid, state. Human gametes have 23 chromosomes or one complete set of chromosomes. This is the n, or haploid, state. Genes are segments of DNA that code for a specific protein or RNA molecule. An organism’s traits are determined in large part by the genes inherited from each parent, but also by the environment that they experience. Genes are expressed as characteristics of the organism and each characteristic may have different variants called traits that are caused by differences in the DNA sequence for a gene.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=177#h5p-35
diploid: describes a cell, nucleus, or organism containing two sets of chromosomes (2n)
gamete: a haploid reproductive cell or sex cell (sperm or egg)
gene: the physical and functional unit of heredity; a sequence of DNA that codes for a specific peptide or RNA molecule
genome: the entire genetic complement (DNA) of an organism
haploid: describes a cell, nucleus, or organism containing one set of chromosomes (n)
homologous chromosomes: chromosomes of the same length with genes in the same location; diploid organisms have pairs of homologous chromosomes, and the members of each pair come from different parents
locus: the position of a gene on a chromosome
By the end of this section, you will be able to:
The cell cycle is an ordered series of events involving cell growth and cell division that produces two new daughter cells. Cells on the path to cell division proceed through a series of precisely timed and carefully regulated stages of growth, DNA replication, and division that produce two genetically identical cells. The cell cycle has two major phases: interphase and the mitotic phase (Figure 5.3). During interphase, the cell grows and DNA is replicated. During the mitotic phase, the replicated DNA and cytoplasmic contents are separated and the cell divides.
Watch this video about the cell cycle: https://www.youtube.com/watch?v=Wy3N5NCZBHQ
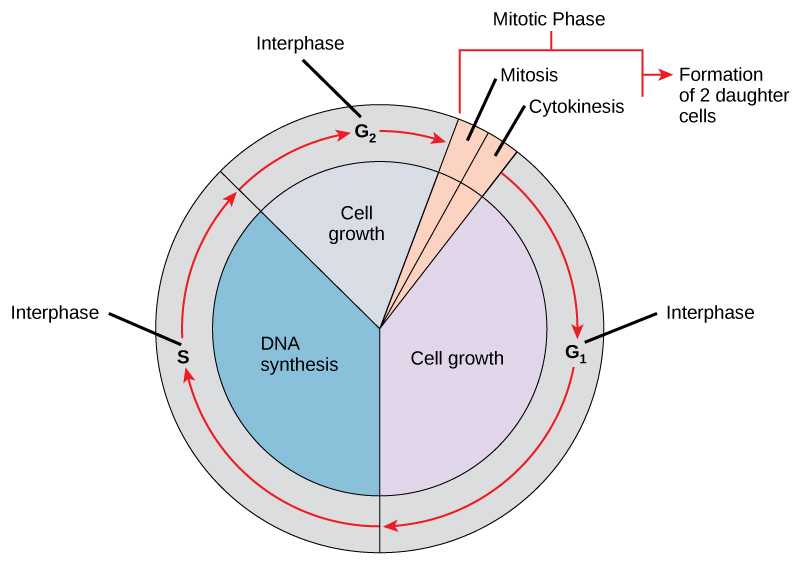
During interphase, the cell undergoes normal processes while also preparing for cell division. For a cell to move from interphase to the mitotic phase, many internal and external conditions must be met. The three stages of interphase are called G1, S, and G2.
The first stage of interphase is called the G1 phase, or first gap, because little change is visible. However, during the G1 stage, the cell is quite active at the biochemical level. The cell is accumulating the building blocks of chromosomal DNA and the associated proteins, as well as accumulating enough energy reserves to complete the task of replicating each chromosome in the nucleus.
Throughout interphase, nuclear DNA remains in a semi-condensed chromatin configuration. In the S phase (synthesis phase), DNA replication results in the formation of two identical copies of each chromosome—sister chromatids—that are firmly attached at the centromere region. At this stage, each chromosome is made of two sister chromatids and is a duplicated chromosome. The centrosome is duplicated during the S phase. The two centrosomes will give rise to the mitotic spindle, the apparatus that orchestrates the movement of chromosomes during mitosis. The centrosome consists of a pair of rod-like centrioles at right angles to each other. Centrioles help organize cell division. Centrioles are not present in the centrosomes of many eukaryotic species, such as plants and most fungi.
In the G2 phase, or second gap, the cell replenishes its energy stores and synthesizes the proteins necessary for chromosome manipulation. Some cell organelles are duplicated, and the cytoskeleton is dismantled to provide resources for the mitotic spindle. There may be additional cell growth during G2. The final preparations for the mitotic phase must be completed before the cell is able to enter the first stage of mitosis.
To make two daughter cells, the contents of the nucleus and the cytoplasm must be divided. The mitotic phase is a multistep process during which the duplicated chromosomes are aligned, separated, and moved to opposite poles of the cell, and then the cell is divided into two new identical daughter cells. The first portion of the mitotic phase, mitosis, is composed of five stages, which accomplish nuclear division. The second portion of the mitotic phase, called cytokinesis, is the physical separation of the cytoplasmic components into two daughter cells.
Mitosis is divided into a series of phases—prophase, prometaphase, metaphase, anaphase, and telophase—that result in the division of the cell nucleus (Figure 5.4).
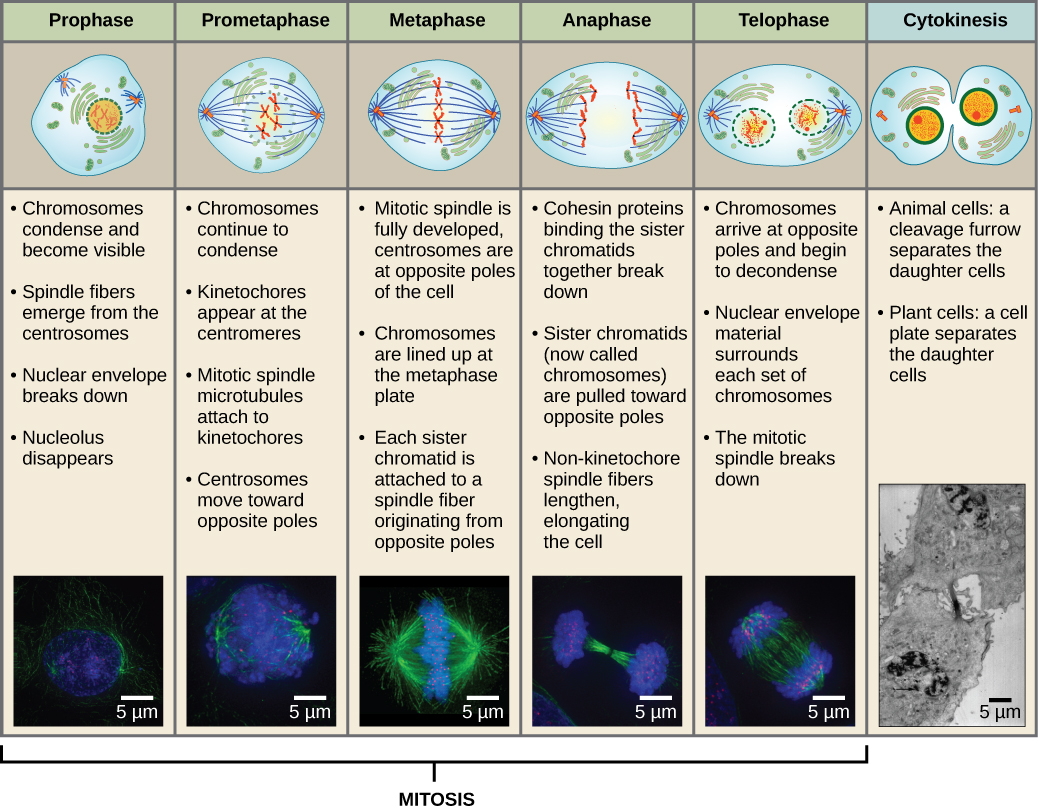
Which of the following is the correct order of events in mitosis?
During prophase, the “first phase,” several events must occur to provide access to the chromosomes in the nucleus. The nuclear envelope starts to break into small vesicles, and the Golgi apparatus and endoplasmic reticulum fragment and disperse to the periphery of the cell. The nucleolus disappears. The centrosomes begin to move to opposite poles of the cell. The microtubules that form the basis of the mitotic spindle extend between the centrosomes, pushing them farther apart as the microtubule fibers lengthen. The sister chromatids begin to coil more tightly and become visible under a light microscope.
During prometaphase, many processes that were begun in prophase continue to advance and culminate in the formation of a connection between the chromosomes and cytoskeleton. The remnants of the nuclear envelope disappear. The mitotic spindle continues to develop as more microtubules assemble and stretch across the length of the former nuclear area. Chromosomes become more condensed and visually discrete. Each sister chromatid attaches to spindle microtubules at the centromere via a protein complex called the kinetochore.
During metaphase, all of the chromosomes are aligned in a plane called the metaphase plate, or the equatorial plane, midway between the two poles of the cell. The sister chromatids are still tightly attached to each other. At this time, the chromosomes are maximally condensed.
During anaphase, the sister chromatids at the equatorial plane are split apart at the centromere. Each chromatid, now called a chromosome, is pulled rapidly toward the centrosome to which its microtubule was attached. The cell becomes visibly elongated as the non-kinetochore microtubules slide against each other at the metaphase plate where they overlap.
During telophase, all of the events that set up the duplicated chromosomes for mitosis during the first three phases are reversed. The chromosomes reach the opposite poles and begin to decondense (unravel). The mitotic spindles are broken down into monomers that will be used to assemble cytoskeleton components for each daughter cell. Nuclear envelopes form around chromosomes.

This page of movies illustrates different aspects of mitosis. Watch the movie entitled “DIC microscopy of cell division in a newt lung cell” and identify the phases of mitosis.
Cytokinesis is the second part of the mitotic phase during which cell division is completed by the physical separation of the cytoplasmic components into two daughter cells. Although the stages of mitosis are similar for most eukaryotes, the process of cytokinesis is quite different for eukaryotes that have cell walls, such as plant cells.
In cells such as animal cells that lack cell walls, cytokinesis begins following the onset of anaphase. A contractile ring composed of actin filaments forms just inside the plasma membrane at the former metaphase plate. The actin filaments pull the equator of the cell inward, forming a fissure. This fissure, or “crack,” is called the cleavage furrow. The furrow deepens as the actin ring contracts, and eventually the membrane and cell are cleaved in two (Figure 5.5).
In plant cells, a cleavage furrow is not possible because of the rigid cell walls surrounding the plasma membrane. A new cell wall must form between the daughter cells. During interphase, the Golgi apparatus accumulates enzymes, structural proteins, and glucose molecules prior to breaking up into vesicles and dispersing throughout the dividing cell. During telophase, these Golgi vesicles move on microtubules to collect at the metaphase plate. There, the vesicles fuse from the center toward the cell walls; this structure is called a cell plate. As more vesicles fuse, the cell plate enlarges until it merges with the cell wall at the periphery of the cell. Enzymes use the glucose that has accumulated between the membrane layers to build a new cell wall of cellulose. The Golgi membranes become the plasma membrane on either side of the new cell wall (Figure 5.5).
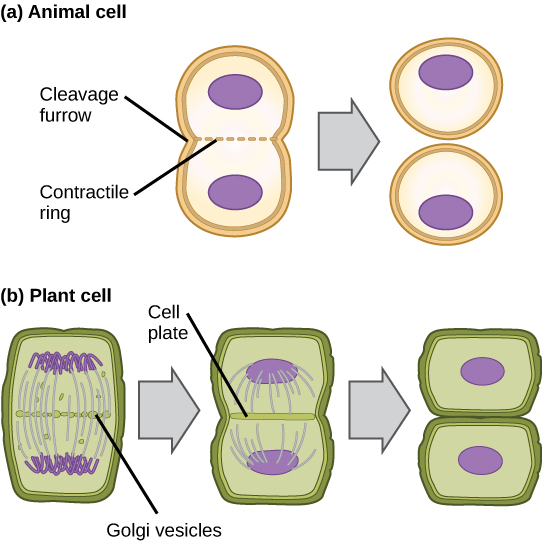
Not all cells adhere to the classic cell-cycle pattern in which a newly formed daughter cell immediately enters interphase, closely followed by the mitotic phase. Cells in the G0 phase are not actively preparing to divide. The cell is in a quiescent (inactive) stage, having exited the cell cycle. Some cells enter G0 temporarily until an external signal triggers the onset of G1. Other cells that never or rarely divide, such as mature cardiac muscle and nerve cells, remain in G0 permanently (Figure 5.6).
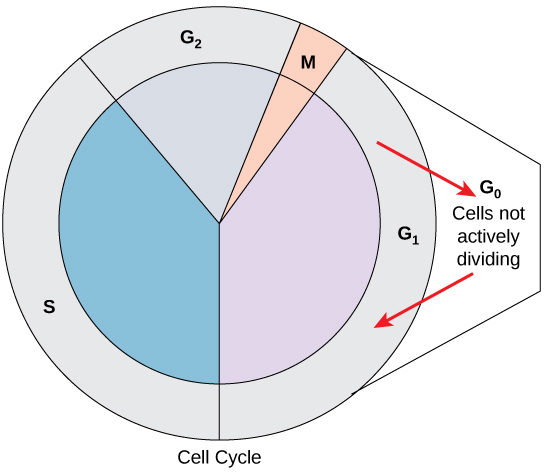
The length of the cell cycle is highly variable even within the cells of an individual organism. In humans, the frequency of cell turnover ranges from a few hours in early embryonic development to an average of two to five days for epithelial cells, or to an entire human lifetime spent in G0 by specialized cells such as cortical neurons or cardiac muscle cells. There is also variation in the time that a cell spends in each phase of the cell cycle. When fast-dividing mammalian cells are grown in culture (outside the body under optimal growing conditions), the length of the cycle is approximately 24 hours. In rapidly dividing human cells with a 24-hour cell cycle, the G1 phase lasts approximately 11 hours. The timing of events in the cell cycle is controlled by mechanisms that are both internal and external to the cell.
It is essential that daughter cells be exact duplicates of the parent cell. Mistakes in the duplication or distribution of the chromosomes lead to mutations that may be passed forward to every new cell produced from the abnormal cell. To prevent a compromised cell from continuing to divide, there are internal control mechanisms that operate at three main cell cycle checkpoints at which the cell cycle can be stopped until conditions are favorable. These checkpoints occur near the end of G1, at the G2–M transition, and during metaphase (Figure 5.7).
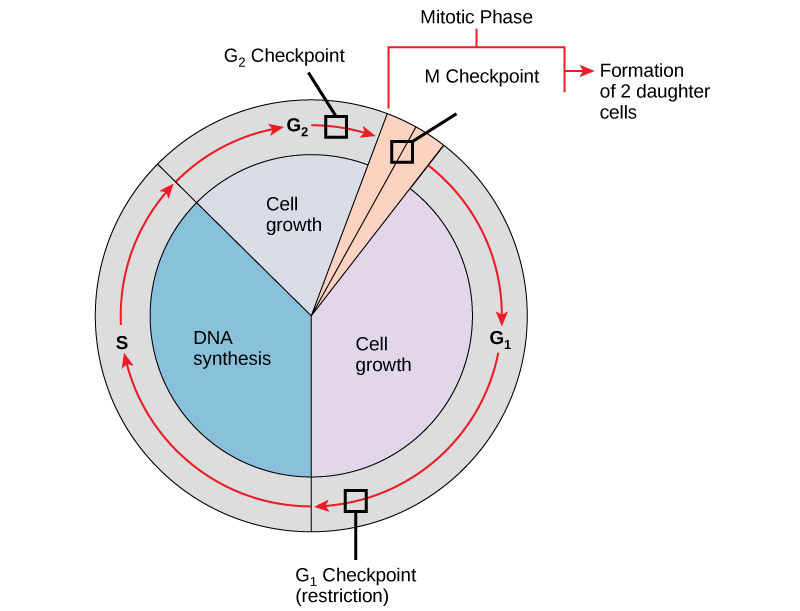
The G1 checkpoint determines whether all conditions are favorable for cell division to proceed. The G1 checkpoint, also called the restriction point, is the point at which the cell irreversibly commits to the cell-division process. In addition to adequate reserves and cell size, there is a check for damage to the genomic DNA at the G1 checkpoint. A cell that does not meet all the requirements will not be released into the S phase.
The G2 checkpoint bars the entry to the mitotic phase if certain conditions are not met. As in the G1 checkpoint, cell size and protein reserves are assessed. However, the most important role of the G2 checkpoint is to ensure that all of the chromosomes have been replicated and that the replicated DNA is not damaged.
The M checkpoint occurs near the end of the metaphase stage of mitosis. The M checkpoint is also known as the spindle checkpoint because it determines if all the sister chromatids are correctly attached to the spindle microtubules. Because the separation of the sister chromatids during anaphase is an irreversible step, the cycle will not proceed until the kinetochores of each pair of sister chromatids are firmly anchored to spindle fibers arising from opposite poles of the cell.

Watch what occurs at the G1, G2, and M checkpoints by visiting this animation of the cell cycle.
The cell cycle is an orderly sequence of events. Cells on the path to cell division proceed through a series of precisely timed and carefully regulated stages. In eukaryotes, the cell cycle consists of a long preparatory period, called interphase. Interphase is divided into G1, S, and G2 phases. Mitosis consists of five stages: prophase, prometaphase, metaphase, anaphase, and telophase. Mitosis is usually accompanied by cytokinesis, during which the cytoplasmic components of the daughter cells are separated either by an actin ring (animal cells) or by cell plate formation (plant cells).
Each step of the cell cycle is monitored by internal controls called checkpoints. There are three major checkpoints in the cell cycle: one near the end of G1, a second at the G2–M transition, and the third during metaphase.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=186#h5p-36
anaphase: the stage of mitosis during which sister chromatids are separated from each other
cell cycle: the ordered sequence of events that a cell passes through between one cell division and the next
cell cycle checkpoints: mechanisms that monitor the preparedness of a eukaryotic cell to advance through the various cell cycle stages
cell plate: a structure formed during plant-cell cytokinesis by Golgi vesicles fusing at the metaphase plate; will ultimately lead to formation of a cell wall to separate the two daughter cells
centriole: a paired rod-like structure constructed of microtubules at the center of each animal cell centrosome
cleavage furrow: a constriction formed by the actin ring during animal-cell cytokinesis that leads to cytoplasmic division
cytokinesis: the division of the cytoplasm following mitosis to form two daughter cells
G0 phase: a cell-cycle phase distinct from the G1 phase of interphase; a cell in G0 is not preparing to divide
G1 phase: (also, first gap) a cell-cycle phase; first phase of interphase centered on cell growth during mitosis
G2 phase: (also, second gap) a cell-cycle phase; third phase of interphase where the cell undergoes the final preparations for mitosis
interphase: the period of the cell cycle leading up to mitosis; includes G1, S, and G2 phases; the interim between two consecutive cell divisions
kinetochore: a protein structure in the centromere of each sister chromatid that attracts and binds spindle microtubules during prometaphase
metaphase plate: the equatorial plane midway between two poles of a cell where the chromosomes align during metaphase
metaphase: the stage of mitosis during which chromosomes are lined up at the metaphase plate
mitosis: the period of the cell cycle at which the duplicated chromosomes are separated into identical nuclei; includes prophase, prometaphase, metaphase, anaphase, and telophase
mitotic phase: the period of the cell cycle when duplicated chromosomes are distributed into two nuclei and the cytoplasmic contents are divided; includes mitosis and cytokinesis
mitotic spindle: the microtubule apparatus that orchestrates the movement of chromosomes during mitosis
prometaphase: the stage of mitosis during which mitotic spindle fibers attach to kinetochores
prophase: the stage of mitosis during which chromosomes condense and the mitotic spindle begins to form
quiescent: describes a cell that is performing normal cell functions and has not initiated preparations for cell division
S phase: the second, or synthesis phase, of interphase during which DNA replication occurs
telophase: the stage of mitosis during which chromosomes arrive at opposite poles, decondense, and are surrounded by new nuclear envelopes
From Chapter 6 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
Cancer is a collective name for many different diseases caused by a common mechanism: uncontrolled cell division. Despite the redundancy and overlapping levels of cell-cycle control, errors occur. One of the critical processes monitored by the cell-cycle checkpoint surveillance mechanism is the proper replication of DNA during the S phase. Even when all of the cell-cycle controls are fully functional, a small percentage of replication errors (mutations) will be passed on to the daughter cells. If one of these changes to the DNA nucleotide sequence occurs within a gene, a gene mutation results. All cancers begin when a gene mutation gives rise to a faulty protein that participates in the process of cell reproduction. The change in the cell that results from the malformed protein may be minor. Even minor mistakes, however, may allow subsequent mistakes to occur more readily. Over and over, small, uncorrected errors are passed from parent cell to daughter cells and accumulate as each generation of cells produces more non-functional proteins from uncorrected DNA damage. Eventually, the pace of the cell cycle speeds up as the effectiveness of the control and repair mechanisms decreases. Uncontrolled growth of the mutated cells outpaces the growth of normal cells in the area, and a tumor can result.
The genes that code for the positive cell-cycle regulators are called proto-oncogenes. Proto-oncogenes are normal genes that, when mutated, become oncogenes—genes that cause a cell to become cancerous. Consider what might happen to the cell cycle in a cell with a recently acquired oncogene. In most instances, the alteration of the DNA sequence will result in a less functional (or non-functional) protein. The result is detrimental to the cell and will likely prevent the cell from completing the cell cycle; however, the organism is not harmed because the mutation will not be carried forward. If a cell cannot reproduce, the mutation is not propagated and the damage is minimal. Occasionally, however, a gene mutation causes a change that increases the activity of a positive regulator. For example, a mutation that allows Cdk, a protein involved in cell-cycle regulation, to be activated before it should be could push the cell cycle past a checkpoint before all of the required conditions are met. If the resulting daughter cells are too damaged to undertake further cell divisions, the mutation would not be propagated and no harm comes to the organism. However, if the atypical daughter cells are able to divide further, the subsequent generation of cells will likely accumulate even more mutations, some possibly in additional genes that regulate the cell cycle.
The Cdk example is only one of many genes that are considered proto-oncogenes. In addition to the cell-cycle regulatory proteins, any protein that influences the cycle can be altered in such a way as to override cell-cycle checkpoints. Once a proto-oncogene has been altered such that there is an increase in the rate of the cell cycle, it is then called an oncogene.
Like proto-oncogenes, many of the negative cell-cycle regulatory proteins were discovered in cells that had become cancerous. Tumor suppressor genes are genes that code for the negative regulator proteins, the type of regulator that—when activated—can prevent the cell from undergoing uncontrolled division. The collective function of the best-understood tumor suppressor gene proteins, retinoblastoma protein (RB1), p53, and p21, is to put up a roadblock to cell-cycle progress until certain events are completed. A cell that carries a mutated form of a negative regulator might not be able to halt the cell cycle if there is a problem.
Mutated p53 genes have been identified in more than half of all human tumor cells. This discovery is not surprising in light of the multiple roles that the p53 protein plays at the G1 checkpoint. The p53 protein activates other genes whose products halt the cell cycle (allowing time for DNA repair), activates genes whose products participate in DNA repair, or activates genes that initiate cell death when DNA damage cannot be repaired. A damaged p53 gene can result in the cell behaving as if there are no mutations (Figure 5.8). This allows cells to divide, propagating the mutation in daughter cells and allowing the accumulation of new mutations. In addition, the damaged version of p53 found in cancer cells cannot trigger cell death.
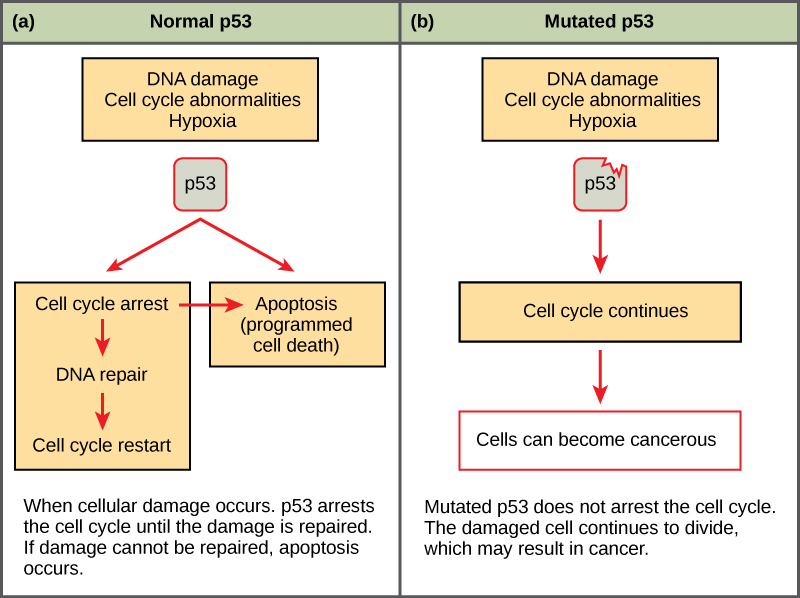


A YouTube element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=190
Go to this website to watch an animation of how cancer results from errors in the cell cycle.
Cancer is the result of unchecked cell division caused by a breakdown of the mechanisms regulating the cell cycle. The loss of control begins with a change in the DNA sequence of a gene that codes for one of the regulatory molecules. Faulty instructions lead to a protein that does not function as it should. Any disruption of the monitoring system can allow other mistakes to be passed on to the daughter cells. Each successive cell division will give rise to daughter cells with even more accumulated damage. Eventually, all checkpoints become nonfunctional, and rapidly reproducing cells crowd out normal cells, resulting in tumorous growth.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=190#h5p-37
oncogene: a mutated version of a proto-oncogene, which allows for uncontrolled progression of the cell cycle, or uncontrolled cell reproduction
proto-oncogene: a normal gene that controls cell division by regulating the cell cycle that becomes an oncogene if it is mutated
tumor suppressor gene: a gene that codes for regulator proteins that prevent the cell from undergoing uncontrolled division
From Chapter 6 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
Prokaryotes such as bacteria propagate by binary fission. For unicellular organisms, cell division is the only method to produce new individuals. In both prokaryotic and eukaryotic cells, the outcome of cell reproduction is a pair of daughter cells that are genetically identical to the parent cell. In unicellular organisms, daughter cells are individuals.
To achieve the outcome of identical daughter cells, some steps are essential. The genomic DNA must be replicated and then allocated into the daughter cells; the cytoplasmic contents must also be divided to give both new cells the machinery to sustain life. In bacterial cells, the genome consists of a single, circular DNA chromosome; therefore, the process of cell division is simplified. Mitosis is unnecessary because there is no nucleus or multiple chromosomes. This type of cell division is called binary fission.
The cell division process of prokaryotes, called binary fission, is a less complicated and much quicker process than cell division in eukaryotes. Because of the speed of bacterial cell division, populations of bacteria can grow very rapidly. The single, circular DNA chromosome of bacteria is not enclosed in a nucleus, but instead occupies a specific location, the nucleoid, within the cell. As in eukaryotes, the DNA of the nucleoid is associated with proteins that aid in packaging the molecule into a compact size. The packing proteins of bacteria are, however, related to some of the proteins involved in the chromosome compaction of eukaryotes.
The starting point of replication, the origin, is close to the binding site of the chromosome to the plasma membrane (Figure 5.9). Replication of the DNA is bidirectional—moving away from the origin on both strands of the DNA loop simultaneously. As the new double strands are formed, each origin point moves away from the cell-wall attachment toward opposite ends of the cell. As the cell elongates, the growing membrane aids in the transport of the chromosomes. After the chromosomes have cleared the midpoint of the elongated cell, cytoplasmic separation begins. A septum is formed between the nucleoids from the periphery toward the center of the cell. When the new cell walls are in place, the daughter cells separate.
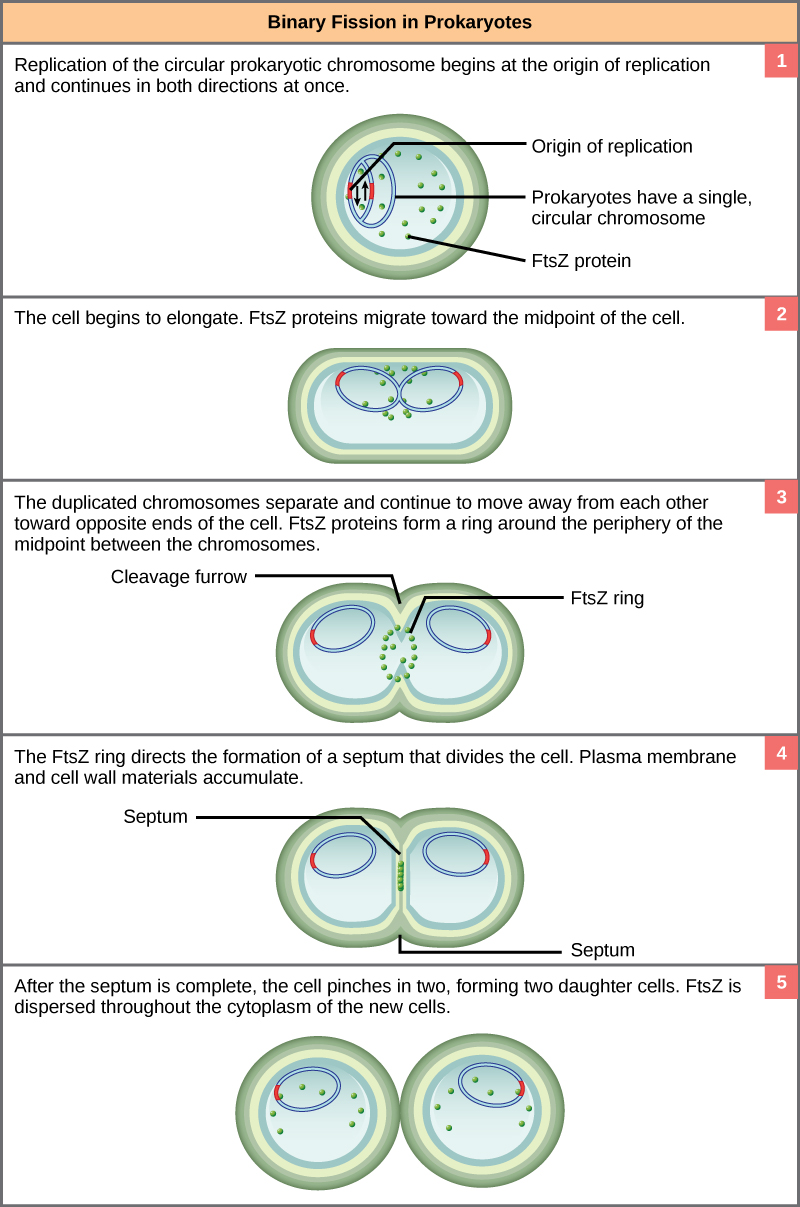
Mitotic Spindle Apparatus
The precise timing and formation of the mitotic spindle is critical to the success of eukaryotic cell division. Prokaryotic cells, on the other hand, do not undergo mitosis and therefore have no need for a mitotic spindle. However, the FtsZ protein that plays such a vital role in prokaryotic cytokinesis is structurally and functionally very similar to tubulin, the building block of the microtubules that make up the mitotic spindle fibers that are necessary for eukaryotes. The formation of a ring composed of repeating units of a protein called FtsZ directs the partition between the nucleoids in prokaryotes. Formation of the FtsZ ring triggers the accumulation of other proteins that work together to recruit new membrane and cell-wall materials to the site. FtsZ proteins can form filaments, rings, and other three-dimensional structures resembling the way tubulin forms microtubules, centrioles, and various cytoskeleton components. In addition, both FtsZ and tubulin employ the same energy source, GTP (guanosine triphosphate), to rapidly assemble and disassemble complex structures.
FtsZ and tubulin are an example of homology, structures derived from the same evolutionary origins. In this example, FtsZ is presumed to be similar to the ancestor protein to both the modern FtsZ and tubulin. While both proteins are found in extant organisms, tubulin function has evolved and diversified tremendously since the evolution from its FtsZ-like prokaryotic origin. A survey of cell-division machinery in present-day unicellular eukaryotes reveals crucial intermediary steps to the complex mitotic machinery of multicellular eukaryotes.
The mitotic spindle fibers of eukaryotes are composed of microtubules. Microtubules are polymers of the protein tubulin. The FtsZ protein active in prokaryote cell division is very similar to tubulin in the structures it can form and its energy source. Single-celled eukaryotes (such as yeast) display possible intermediary steps between FtsZ activity during binary fission in prokaryotes and the mitotic spindle in multicellular eukaryotes, during which the nucleus breaks down and is reformed.
| Structure of genetic material | Division of nuclear material | Separation of daughter cells | |
|---|---|---|---|
| Prokaryotes | There is no nucleus. The single, circular chromosome exists in a region of cytoplasm called the nucleoid. | Occurs through binary fission. As the chromosome is replicated, the two copies move to opposite ends of the cell by an unknown mechanism. | FtsZ proteins assemble into a ring that pinches the cell in two. |
| Some protists | Linear chromosomes exist in the nucleus. | Chromosomes attach to the nuclear envelope, which remains intact. The mitotic spindle passes through the envelope and elongates the cell. No centrioles exist. | Microfilaments form a cleavage furrow that pinches the cell in two. |
| Other protists | Linear chromosomes exist in the nucleus. | A mitotic spindle forms from the centrioles and passes through the nuclear membrane, which remains intact. Chromosomes attach to the mitotic spindle. The mitotic spindle separates the chromosomes and elongates the cell. | Microfilaments form a cleavage furrow that pinches the cell in two. |
| Animal cells | Linear chromosomes exist in the nucleus. | A mitotic spindle forms from the centrioles. The nuclear envelope dissolves. Chromosomes attach to the mitotic spindle, which separates them and elongates the cell. | Microfilaments form a cleavage furrow that pinches the cell in two. |
In both prokaryotic and eukaryotic cell division, the genomic DNA is replicated and each copy is allocated into a daughter cell. The cytoplasmic contents are also divided evenly to the new cells. However, there are many differences between prokaryotic and eukaryotic cell division. Bacteria have a single, circular DNA chromosome and no nucleus. Therefore, mitosis is not necessary in bacterial cell division. Bacterial cytokinesis is directed by a ring composed of a protein called FtsZ. Ingrowth of membrane and cell-wall material from the periphery of the cells results in a septum that eventually forms the separate cell walls of the daughter cells.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=193#h5p-38
binary fission: the process of prokaryotic cell division
FtsZ: a tubulin-like protein component of the prokaryotic cytoskeleton that is important in prokaryotic cytokinesis (name origin: Filamenting temperature-sensitive mutant Z)
origin: the region of the prokaryotic chromosome at which replication begins
septum: a wall formed between bacterial daughter cells as a precursor to cell separation
From Chapter 6 in Concepts of Biology: 1st Canadian Edition

The ability to reproduce in kind is a basic characteristic of all living things. In kind means that the offspring of any organism closely resembles its parent or parents. Hippopotamuses give birth to hippopotamus calves; Monterey pine trees produce seeds from which Monterey pine seedlings emerge; and adult flamingos lay eggs that hatch into flamingo chicks. In kind does not generally mean exactly the same. While many single-celled organisms and a few multicellular organisms can produce genetically identical clones of themselves through mitotic cell division, many single-celled organisms and most multicellular organisms reproduce regularly using another method.
Sexual reproduction is the production by parents of haploid cells and the fusion of a haploid cell from each parent to form a single, unique diploid cell. In multicellular organisms, the new diploid cell will then undergo mitotic cell divisions to develop into an adult organism. A type of cell division called meiosis leads to the haploid cells that are part of the sexual reproductive cycle. Sexual reproduction, specifically meiosis and fertilization, introduces variation into offspring that may account for the evolutionary success of sexual reproduction. The vast majority of eukaryotic organisms can or must employ some form of meiosis and fertilization to reproduce.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=196#h5p-39
Chapter 7 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=199#h5p-40
However, multicellular organisms that exclusively depend on asexual reproduction are exceedingly rare. Why is sexual reproduction so common? This is one of the important questions in biology and has been the focus of much research from the latter half of the twentieth century until now. A likely explanation is that the variation that sexual reproduction creates among offspring is very important to the survival and reproduction of those offspring. The only source of variation in asexual organisms is mutation. This is the ultimate source of variation in sexual organisms. In addition, those different mutations are continually reshuffled from one generation to the next when different parents combine their unique genomes, and the genes are mixed into different combinations by the process of meiosis. Meiosis is the division of the contents of the nucleus that divides the chromosomes among gametes. Variation is introduced during meiosis, as well as when the gametes combine in fertilization.
There is no question that sexual reproduction provides evolutionary advantages to organisms that employ this mechanism to produce offspring. The problematic question is why, even in the face of fairly stable conditions, sexual reproduction persists when it is more difficult and produces fewer offspring for individual organisms? Variation is the outcome of sexual reproduction, but why are ongoing variations necessary? Enter the Red Queen hypothesis, first proposed by Leigh Van Valen in 1973.1 The concept was named in reference to the Red Queen’s race in Lewis Carroll’s book, Through the Looking-Glass, in which the Red Queen says one must run at full speed just to stay where one is.
All species coevolve with other organisms. For example, predators coevolve with their prey, and parasites coevolve with their hosts. A remarkable example of coevolution between predators and their prey is the unique coadaptation of night flying bats and their moth prey. Bats find their prey by emitting high-pitched clicks, but moths have evolved simple ears to hear these clicks so they can avoid the bats. The moths have also adapted behaviors, such as flying away from the bat when they first hear it, or dropping suddenly to the ground when the bat is upon them. Bats have evolved “quiet” clicks in an attempt to evade the moth’s hearing. Some moths have evolved the ability to respond to the bats’ clicks with their own clicks as a strategy to confuse the bats echolocation abilities.
Each tiny advantage gained by favorable variation gives a species an edge over close competitors, predators, parasites, or even prey. The only method that will allow a coevolving species to keep its own share of the resources is also to continually improve its ability to survive and produce offspring. As one species gains an advantage, other species must also develop an advantage or they will be outcompeted. No single species progresses too far ahead because genetic variation among progeny of sexual reproduction provides all species with a mechanism to produce adapted individuals. Species whose individuals cannot keep up become extinct. The Red Queen’s catchphrase was, “It takes all the running you can do to stay in the same place.” This is an apt description of coevolution between competing species.
Fertilization and meiosis alternate in sexual life cycles. What happens between these two events depends on the organism. The process of meiosis reduces the resulting gamete’s chromosome number by half. Fertilization, the joining of two haploid gametes, restores the diploid condition. There are three main categories of life cycles in multicellular organisms: diploid-dominant, in which the multicellular diploid stage is the most obvious life stage (and there is no multicellular haploid stage), as with most animals including humans; haploid-dominant, in which the multicellular haploid stage is the most obvious life stage (and there is no multicellular diploid stage), as with all fungi and some algae; and alternation of generations, in which the two stages, haploid and diploid, are apparent to one degree or another depending on the group, as with plants and some algae.
Nearly all animals employ a diploid-dominant life-cycle strategy in which the only haploid cells produced by the organism are the gametes. The gametes are produced from diploid germ cells, a special cell line that only produces gametes. Once the haploid gametes are formed, they lose the ability to divide again. There is no multicellular haploid life stage. Fertilization occurs with the fusion of two gametes, usually from different individuals, restoring the diploid state (Figure 6.2 a).
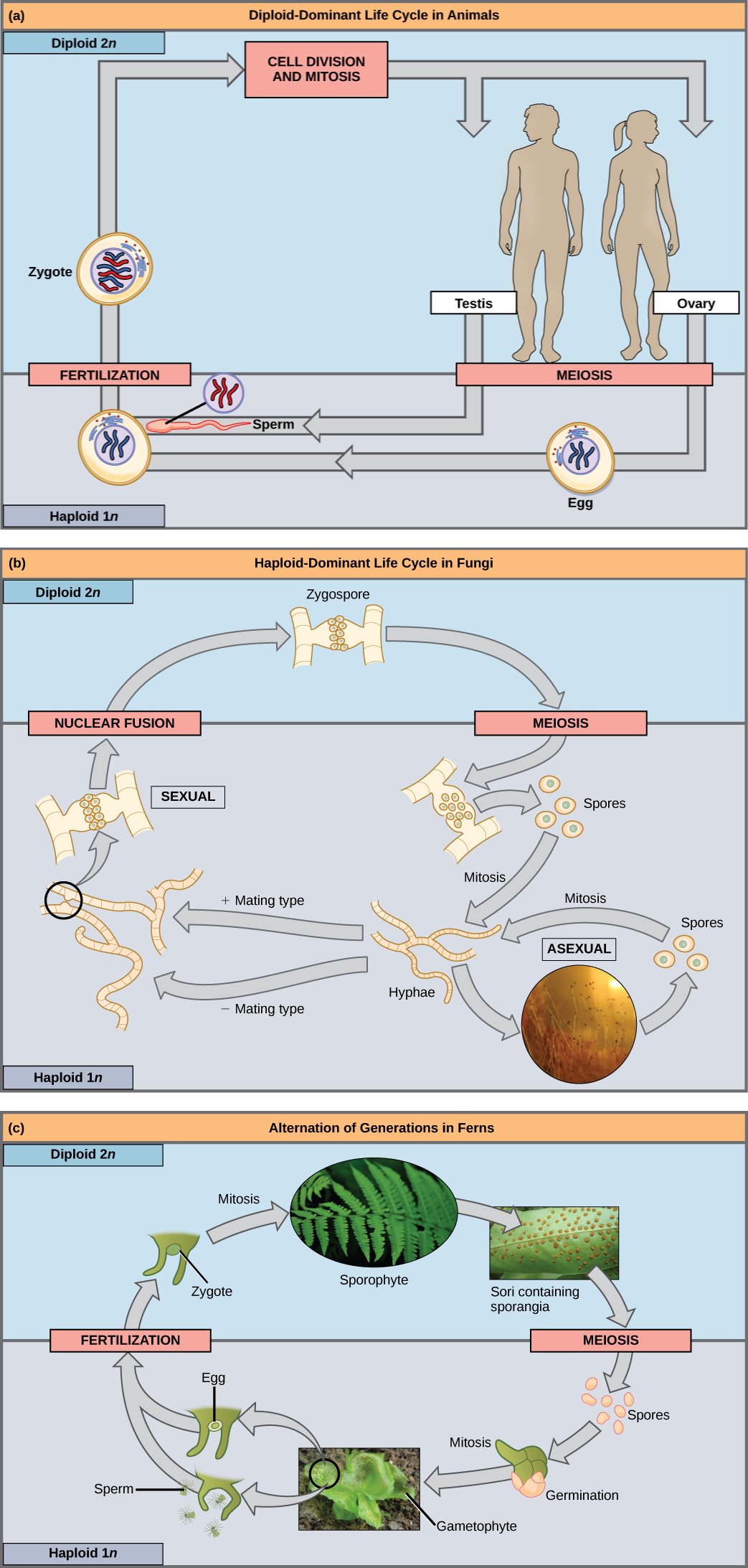
If a mutation occurs so that a fungus is no longer able to produce a minus mating type, will it still be able to reproduce?
Most fungi and algae employ a life-cycle strategy in which the multicellular “body” of the organism is haploid. During sexual reproduction, specialized haploid cells from two individuals join to form a diploid zygote. The zygote immediately undergoes meiosis to form four haploid cells called spores (Figure 6.2 b).
The third life-cycle type, employed by some algae and all plants, is called alternation of generations. These species have both haploid and diploid multicellular organisms as part of their life cycle. The haploid multicellular plants are called gametophytes because they produce gametes. Meiosis is not involved in the production of gametes in this case, as the organism that produces gametes is already haploid. Fertilization between the gametes forms a diploid zygote. The zygote will undergo many rounds of mitosis and give rise to a diploid multicellular plant called a sporophyte. Specialized cells of the sporophyte will undergo meiosis and produce haploid spores. The spores will develop into the gametophytes (Figure 6. 2 c).
Nearly all eukaryotes undergo sexual reproduction. The variation introduced into the reproductive cells by meiosis appears to be one of the advantages of sexual reproduction that has made it so successful. Meiosis and fertilization alternate in sexual life cycles. The process of meiosis produces genetically unique reproductive cells called gametes, which have half the number of chromosomes as the parent cell. Fertilization, the fusion of haploid gametes from two individuals, restores the diploid condition. Thus, sexually reproducing organisms alternate between haploid and diploid stages. However, the ways in which reproductive cells are produced and the timing between meiosis and fertilization vary greatly. There are three main categories of life cycles: diploid-dominant, demonstrated by most animals; haploid-dominant, demonstrated by all fungi and some algae; and alternation of generations, demonstrated by plants and some algae.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=199#h5p-41
alternation of generations: a life-cycle type in which the diploid and haploid stages alternate
diploid-dominant: a life-cycle type in which the multicellular diploid stage is prevalent
haploid-dominant: a life-cycle type in which the multicellular haploid stage is prevalent
gametophyte: a multicellular haploid life-cycle stage that produces gametes
germ cell: a specialized cell that produces gametes, such as eggs or sperm
life cycle: the sequence of events in the development of an organism and the production of cells that produce offspring
meiosis: a nuclear division process that results in four haploid cells
sporophyte: a multicellular diploid life-cycle stage that produces spores
1 Leigh Van Valen, “A new evolutionary law,” Evolutionary Theory 1 (1973): 1–30.
Chapter 7 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
Sexual reproduction requires fertilization, a union of two cells from two individual organisms. If those two cells each contain one set of chromosomes, then the resulting cell contains two sets of chromosomes. The number of sets of chromosomes in a cell is called its ploidy level. Haploid cells contain one set of chromosomes. Cells containing two sets of chromosomes are called diploid. If the reproductive cycle is to continue, the diploid cell must somehow reduce its number of chromosome sets before fertilization can occur again, or there will be a continual doubling in the number of chromosome sets in every generation. So, in addition to fertilization, sexual reproduction includes a nuclear division, known as meiosis, that reduces the number of chromosome sets.
Most animals and plants are diploid, containing two sets of chromosomes; in each somatic cell (the nonreproductive cells of a multicellular organism), the nucleus contains two copies of each chromosome that are referred to as homologous chromosomes. Somatic cells are sometimes referred to as “body” cells. Homologous chromosomes are matched pairs containing genes for the same traits in identical locations along their length. Diploid organisms inherit one copy of each homologous chromosome from each parent; all together, they are considered a full set of chromosomes. In animals, haploid cells containing a single copy of each homologous chromosome are found only within gametes. Gametes fuse with another haploid gamete to produce a diploid cell.
The nuclear division that forms haploid cells, which is called meiosis, is related to mitosis. As you have learned, mitosis is part of a cell reproduction cycle that results in identical daughter nuclei that are also genetically identical to the original parent nucleus. In mitosis, both the parent and the daughter nuclei contain the same number of chromosome sets—diploid for most plants and animals. Meiosis employs many of the same mechanisms as mitosis. However, the starting nucleus is always diploid and the nuclei that result at the end of a meiotic cell division are haploid. To achieve the reduction in chromosome number, meiosis consists of one round of chromosome duplication and two rounds of nuclear division. Because the events that occur during each of the division stages are analogous to the events of mitosis, the same stage names are assigned. However, because there are two rounds of division, the stages are designated with a “I” or “II.” Thus, meiosis I is the first round of meiotic division and consists of prophase I, prometaphase I, and so on. Meiosis I reduces the number of chromosome sets from two to one. The genetic information is also mixed during this division to create unique recombinant chromosomes. Meiosis II, in which the second round of meiotic division takes place in a way that is similar to mitosis, includes prophase II, prometaphase II, and so on.
Meiosis is preceded by an interphase consisting of the G1, S, and G2 phases, which are nearly identical to the phases preceding mitosis. The G1 phase is the first phase of interphase and is focused on cell growth. In the S phase, the DNA of the chromosomes is replicated. Finally, in the G2 phase, the cell undergoes the final preparations for meiosis.
During DNA duplication of the S phase, each chromosome becomes composed of two identical copies (called sister chromatids) that are held together at the centromere until they are pulled apart during meiosis II. In an animal cell, the centrosomes that organize the microtubules of the meiotic spindle also replicate. This prepares the cell for the first meiotic phase.
Early in prophase I, the chromosomes can be seen clearly microscopically. As the nuclear envelope begins to break down, the proteins associated with homologous chromosomes bring the pair close to each other. The tight pairing of the homologous chromosomes is called synapsis. In synapsis, the genes on the chromatids of the homologous chromosomes are precisely aligned with each other. An exchange of chromosome segments between non-sister homologous chromatids occurs and is called crossing over. This process is revealed visually after the exchange as chiasmata (singular = chiasma) (Figure 6.3).
As prophase I progresses, the close association between homologous chromosomes begins to break down, and the chromosomes continue to condense, although the homologous chromosomes remain attached to each other at chiasmata. The number of chiasmata varies with the species and the length of the chromosome. At the end of prophase I, the pairs are held together only at chiasmata (Figure 6.3) and are called tetrads because the four sister chromatids of each pair of homologous chromosomes are now visible.
The crossover events are the first source of genetic variation produced by meiosis. A single crossover event between homologous non-sister chromatids leads to a reciprocal exchange of equivalent DNA between a maternal chromosome and a paternal chromosome. Now, when that sister chromatid is moved into a gamete, it will carry some DNA from one parent of the individual and some DNA from the other parent. The recombinant sister chromatid has a combination of maternal and paternal genes that did not exist before the crossover.
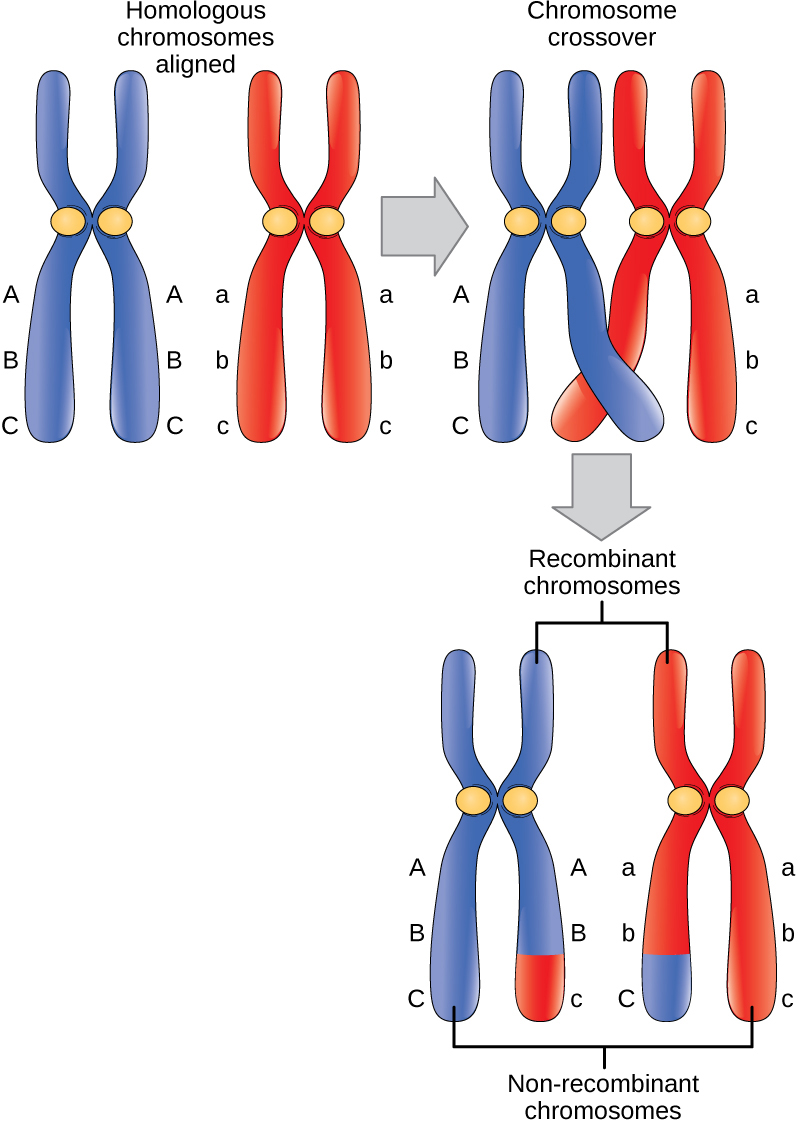
The key event in prometaphase I is the attachment of the spindle fiber microtubules to the kinetochore proteins at the centromeres. The microtubules assembled from centrosomes at opposite poles of the cell grow toward the middle of the cell. At the end of prometaphase I, each tetrad is attached to microtubules from both poles, with one homologous chromosome attached at one pole and the other homologous chromosome attached to the other pole. The homologous chromosomes are still held together at chiasmata. In addition, the nuclear membrane has broken down entirely.
During metaphase I, the homologous chromosomes are arranged in the center of the cell with the kinetochores facing opposite poles. The orientation of each pair of homologous chromosomes at the center of the cell is random.
This randomness, called independent assortment, is the physical basis for the generation of the second form of genetic variation in offspring. Consider that the homologous chromosomes of a sexually reproducing organism are originally inherited as two separate sets, one from each parent. Using humans as an example, one set of 23 chromosomes is present in the egg donated by the mother. The father provides the other set of 23 chromosomes in the sperm that fertilizes the egg. In metaphase I, these pairs line up at the midway point between the two poles of the cell. Because there is an equal chance that a microtubule fiber will encounter a maternally or paternally inherited chromosome, the arrangement of the tetrads at the metaphase plate is random. Any maternally inherited chromosome may face either pole. Any paternally inherited chromosome may also face either pole. The orientation of each tetrad is independent of the orientation of the other 22 tetrads.
In each cell that undergoes meiosis, the arrangement of the tetrads is different. The number of variations depends on the number of chromosomes making up a set. There are two possibilities for orientation (for each tetrad); thus, the possible number of alignments equals 2n where n is the number of chromosomes per set. Humans have 23 chromosome pairs, which results in over eight million (223) possibilities. This number does not include the variability previously created in the sister chromatids by crossover. Given these two mechanisms, it is highly unlikely that any two haploid cells resulting from meiosis will have the same genetic composition (Figure 6.4).
To summarize the genetic consequences of meiosis I: the maternal and paternal genes are recombined by crossover events occurring on each homologous pair during prophase I; in addition, the random assortment of tetrads at metaphase produces a unique combination of maternal and paternal chromosomes that will make their way into the gametes.
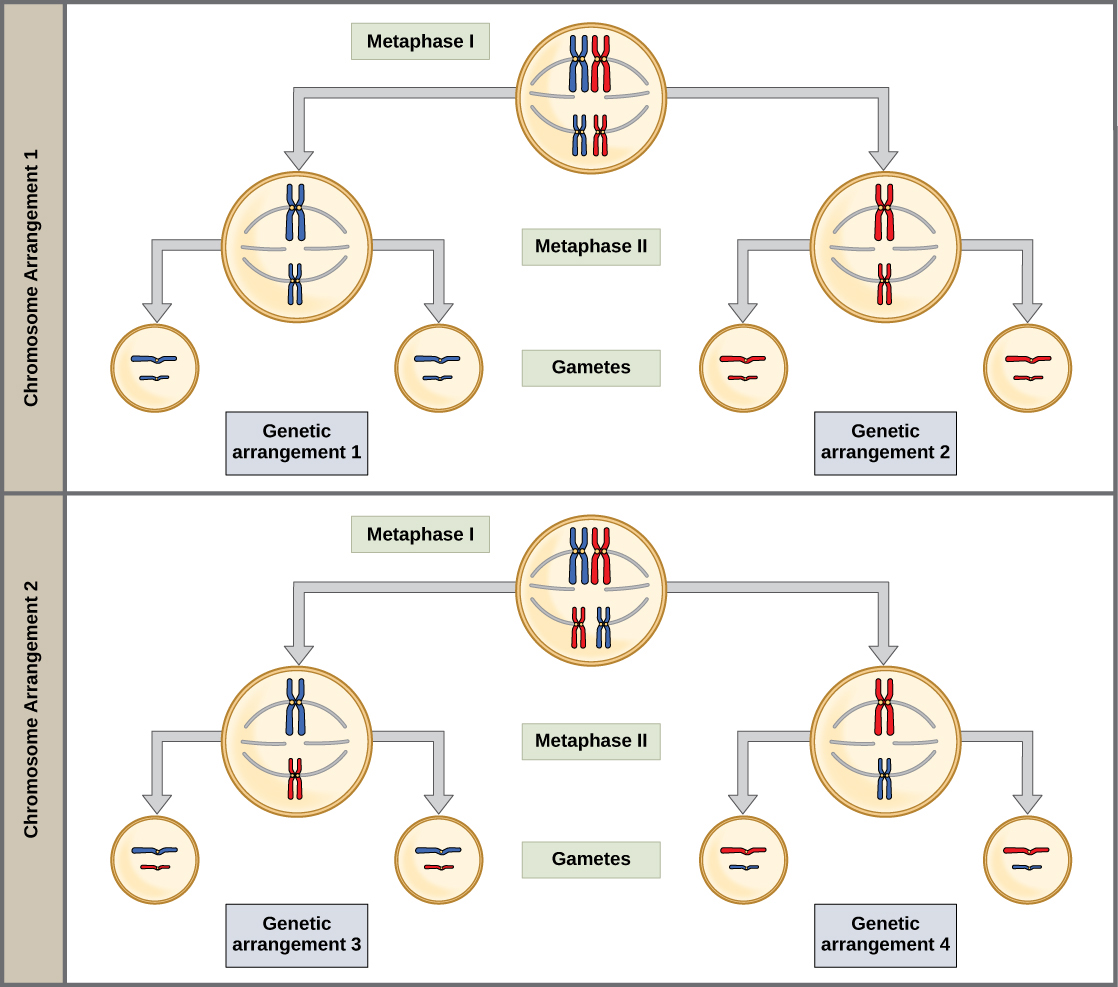
In anaphase I, the spindle fibers pull the linked chromosomes apart. The sister chromatids remain tightly bound together at the centromere. It is the chiasma connections that are broken in anaphase I as the fibers attached to the fused kinetochores pull the homologous chromosomes apart.
In telophase I, the separated chromosomes arrive at opposite poles. The remainder of the typical telophase events may or may not occur depending on the species. In some organisms, the chromosomes decondense and nuclear envelopes form around the chromatids in telophase I.
Cytokinesis, the physical separation of the cytoplasmic components into two daughter cells, occurs without reformation of the nuclei in other organisms. In nearly all species, cytokinesis separates the cell contents by either a cleavage furrow (in animals and some fungi), or a cell plate that will ultimately lead to formation of cell walls that separate the two daughter cells (in plants). At each pole, there is just one member of each pair of the homologous chromosomes, so only one full set of the chromosomes is present. This is why the cells are considered haploid—there is only one chromosome set, even though there are duplicate copies of the set because each homolog still consists of two sister chromatids that are still attached to each other. However, although the sister chromatids were once duplicates of the same chromosome, they are no longer identical at this stage because of crossovers.

Review the process of meiosis, observing how chromosomes align and migrate, at this site.
In meiosis II, the connected sister chromatids remaining in the haploid cells from meiosis I will be split to form four haploid cells. In some species, cells enter a brief interphase, or interkinesis, that lacks an S phase, before entering meiosis II. Chromosomes are not duplicated during interkinesis. The two cells produced in meiosis I go through the events of meiosis II in synchrony. Overall, meiosis II resembles the mitotic division of a haploid cell.
In prophase II, if the chromosomes decondensed in telophase I, they condense again. If nuclear envelopes were formed, they fragment into vesicles. The centrosomes duplicated during interkinesis move away from each other toward opposite poles, and new spindles are formed. In prometaphase II, the nuclear envelopes are completely broken down, and the spindle is fully formed. Each sister chromatid forms an individual kinetochore that attaches to microtubules from opposite poles. In metaphase II, the sister chromatids are maximally condensed and aligned at the center of the cell. In anaphase II, the sister chromatids are pulled apart by the spindle fibers and move toward opposite poles.
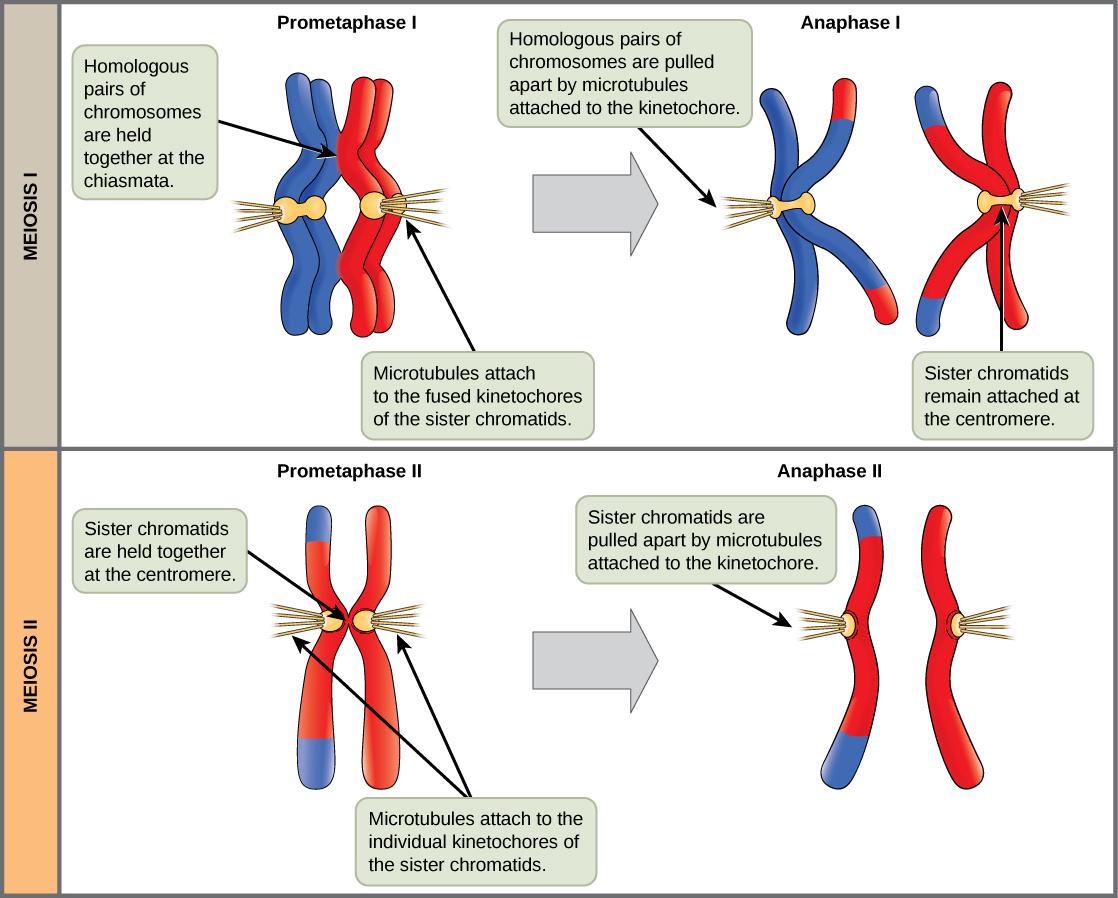
In telophase II, the chromosomes arrive at opposite poles and begin to decondense. Nuclear envelopes form around the chromosomes. Cytokinesis separates the two cells into four genetically unique haploid cells. At this point, the nuclei in the newly produced cells are both haploid and have only one copy of the single set of chromosomes. The cells produced are genetically unique because of the random assortment of paternal and maternal homologs and because of the recombination of maternal and paternal segments of chromosomes—with their sets of genes—that occurs during crossover.
Mitosis and meiosis, which are both forms of division of the nucleus in eukaryotic cells, share some similarities, but also exhibit distinct differences that lead to their very different outcomes. Mitosis is a single nuclear division that results in two nuclei, usually partitioned into two new cells. The nuclei resulting from a mitotic division are genetically identical to the original. They have the same number of sets of chromosomes: one in the case of haploid cells, and two in the case of diploid cells. On the other hand, meiosis is two nuclear divisions that result in four nuclei, usually partitioned into four new cells. The nuclei resulting from meiosis are never genetically identical, and they contain one chromosome set only—this is half the number of the original cell, which was diploid.
The differences in the outcomes of meiosis and mitosis occur because of differences in the behavior of the chromosomes during each process. Most of these differences in the processes occur in meiosis I, which is a very different nuclear division than mitosis. In meiosis I, the homologous chromosome pairs become associated with each other, are bound together, experience chiasmata and crossover between sister chromatids, and line up along the metaphase plate in tetrads with spindle fibers from opposite spindle poles attached to each kinetochore of a homolog in a tetrad. All of these events occur only in meiosis I, never in mitosis.
Homologous chromosomes move to opposite poles during meiosis I so the number of sets of chromosomes in each nucleus-to-be is reduced from two to one. For this reason, meiosis I is referred to as a reduction division. There is no such reduction in ploidy level in mitosis.
Meiosis II is much more analogous to a mitotic division. In this case, duplicated chromosomes (only one set of them) line up at the center of the cell with divided kinetochores attached to spindle fibers from opposite poles. During anaphase II, as in mitotic anaphase, the kinetochores divide and one sister chromatid is pulled to one pole and the other sister chromatid is pulled to the other pole. If it were not for the fact that there had been crossovers, the two products of each meiosis II division would be identical as in mitosis; instead, they are different because there has always been at least one crossover per chromosome. Meiosis II is not a reduction division because, although there are fewer copies of the genome in the resulting cells, there is still one set of chromosomes, as there was at the end of meiosis I.
Cells produced by mitosis will function in different parts of the body as a part of growth or replacing dead or damaged cells. They may even be involved in asexual reproduction in some organisms. Cells produced by meiosis in a diploid-dominant organism such as an animal will only participate in sexual reproduction.
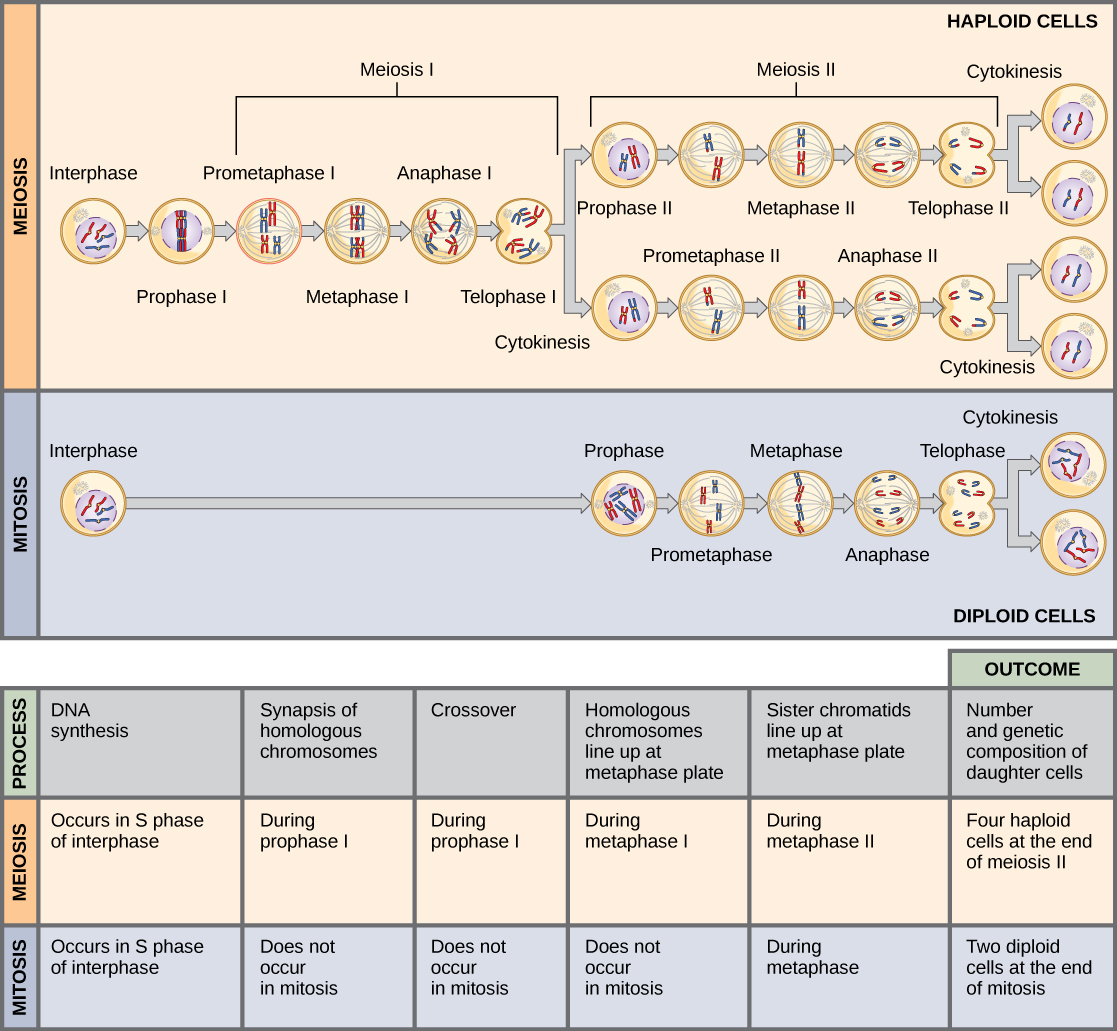
Sexual reproduction requires that diploid organisms produce haploid cells that can fuse during fertilization to form diploid offspring. The process that results in haploid cells is called meiosis. Meiosis is a series of events that arrange and separate chromosomes into daughter cells. During the interphase of meiosis, each chromosome is duplicated. In meiosis, there are two rounds of nuclear division resulting in four nuclei and usually four haploid daughter cells, each with half the number of chromosomes as the parent cell. During meiosis, variation in the daughter nuclei is introduced because of crossover in prophase I and random alignment at metaphase I. The cells that are produced by meiosis are genetically unique.
Meiosis and mitosis share similarities, but have distinct outcomes. Mitotic divisions are single nuclear divisions that produce daughter nuclei that are genetically identical and have the same number of chromosome sets as the original cell. Meiotic divisions are two nuclear divisions that produce four daughter nuclei that are genetically different and have one chromosome set rather than the two sets the parent cell had. The main differences between the processes occur in the first division of meiosis. The homologous chromosomes separate into different nuclei during meiosis I causing a reduction of ploidy level. The second division of meiosis is much more similar to a mitotic division.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=207#h5p-42
chiasmata: (singular = chiasma) the structure that forms at the crossover points after genetic material is exchanged
crossing over: (also, recombination) the exchange of genetic material between homologous chromosomes resulting in chromosomes that incorporate genes from both parents of the organism forming reproductive cells
fertilization: the union of two haploid cells typically from two individual organisms
interkinesis: a period of rest that may occur between meiosis I and meiosis II; there is no replication of DNA during interkinesis
meiosis I: the first round of meiotic cell division; referred to as reduction division because the resulting cells are haploid
meiosis II: the second round of meiotic cell division following meiosis I; sister chromatids are separated from each other, and the result is four unique haploid cells
recombinant: describing something composed of genetic material from two sources, such as a chromosome with both maternal and paternal segments of DNA
reduction division: a nuclear division that produces daughter nuclei each having one-half as many chromosome sets as the parental nucleus; meiosis I is a reduction division
somatic cell: all the cells of a multicellular organism except the gamete-forming cells
synapsis: the formation of a close association between homologous chromosomes during prophase I
tetrad: two duplicated homologous chromosomes (four chromatids) bound together by chiasmata during prophase I
Chapter 7 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
Inherited disorders can arise when chromosomes behave abnormally during meiosis. Chromosome disorders can be divided into two categories: abnormalities in chromosome number and chromosome structural rearrangements. Because even small segments of chromosomes can span many genes, chromosomal disorders are characteristically dramatic and often fatal.
The isolation and microscopic observation of chromosomes forms the basis of cytogenetics and is the primary method by which clinicians detect chromosomal abnormalities in humans. A karyotype is the number and appearance of chromosomes, including their length, banding pattern, and centromere position. To obtain a view of an individual’s karyotype, cytologists photograph the chromosomes and then cut and paste each chromosome into a chart, or karyogram (Figure 6.7).
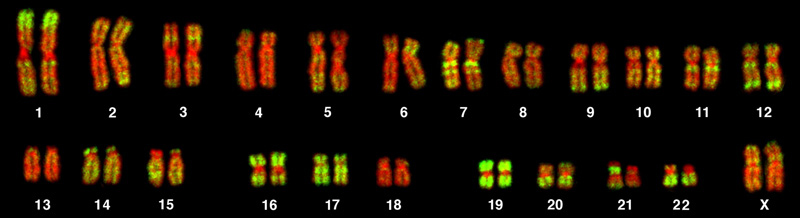
The karyotype is a method by which traits characterized by chromosomal abnormalities can be identified from a single cell. To observe an individual’s karyotype, a person’s cells (like white blood cells) are first collected from a blood sample or other tissue. In the laboratory, the isolated cells are stimulated to begin actively dividing. A chemical is then applied to the cells to arrest mitosis during metaphase. The cells are then fixed to a slide.
The geneticist then stains chromosomes with one of several dyes to better visualize the distinct and reproducible banding patterns of each chromosome pair. Following staining, chromosomes are viewed using bright-field microscopy. An experienced cytogeneticist can identify each band. In addition to the banding patterns, chromosomes are further identified on the basis of size and centromere location. To obtain the classic depiction of the karyotype in which homologous pairs of chromosomes are aligned in numerical order from longest to shortest, the geneticist obtains a digital image, identifies each chromosome, and manually arranges the chromosomes into this pattern.
At its most basic, the karyogram may reveal genetic abnormalities in which an individual has too many or too few chromosomes per cell. Examples of this are Down syndrome, which is identified by a third copy of chromosome 21, and Turner syndrome, which is characterized by the presence of only one X chromosome in women instead of two. Geneticists can also identify large deletions or insertions of DNA. For instance, Jacobsen syndrome, which involves distinctive facial features as well as heart and bleeding defects, is identified by a deletion on chromosome 11. Finally, the karyotype can pinpoint translocations, which occur when a segment of genetic material breaks from one chromosome and reattaches to another chromosome or to a different part of the same chromosome. Translocations are implicated in certain cancers, including chronic myelogenous leukemia.
By observing a karyogram, geneticists can actually visualize the chromosomal composition of an individual to confirm or predict genetic abnormalities in offspring even before birth.
Of all the chromosomal disorders, abnormalities in chromosome number are the most easily identifiable from a karyogram. Disorders of chromosome number include the duplication or loss of entire chromosomes, as well as changes in the number of complete sets of chromosomes. They are caused by nondisjunction, which occurs when pairs of homologous chromosomes or sister chromatids fail to separate during meiosis. The risk of nondisjunction increases with the age of the parents.
Nondisjunction can occur during either meiosis I or II, with different results (Figure 6.8). If homologous chromosomes fail to separate during meiosis I, the result is two gametes that lack that chromosome and two gametes with two copies of the chromosome. If sister chromatids fail to separate during meiosis II, the result is one gamete that lacks that chromosome, two normal gametes with one copy of the chromosome, and one gamete with two copies of the chromosome.
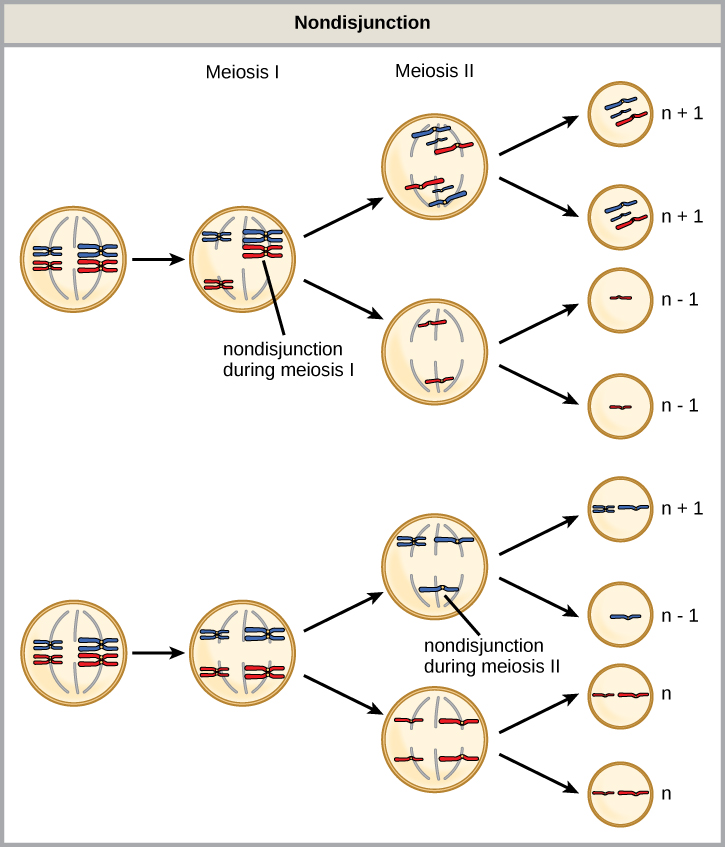
An individual with the appropriate number of chromosomes for their species is called euploid; in humans, euploidy corresponds to 22 pairs of autosomes and one pair of sex chromosomes. An individual with an error in chromosome number is described as aneuploid, a term that includes monosomy (loss of one chromosome) or trisomy (gain of an extraneous chromosome). Monosomic human zygotes missing any one copy of an autosome invariably fail to develop to birth because they have only one copy of essential genes. Most autosomal trisomies also fail to develop to birth; however, duplications of some of the smaller chromosomes (13, 15, 18, 21, or 22) can result in offspring that survive for several weeks to many years. Trisomic individuals suffer from a different type of genetic imbalance: an excess in gene dose. Cell functions are calibrated to the amount of gene product produced by two copies (doses) of each gene; adding a third copy (dose) disrupts this balance. The most common trisomy is that of chromosome 21, which leads to Down syndrome. Individuals with this inherited disorder have characteristic physical features and developmental delays in growth and cognition. The incidence of Down syndrome is correlated with maternal age, such that older women are more likely to give birth to children with Down syndrome (Figure 6.9).
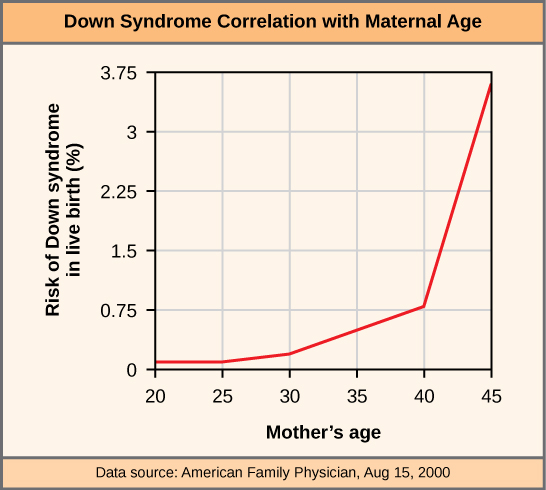

Visualize the addition of a chromosome that leads to Down syndrome in this video simulation.
Humans display dramatic deleterious effects with autosomal trisomies and monosomies. Therefore, it may seem counterintuitive that human females and males can function normally, despite carrying different numbers of the X chromosome. In part, this occurs because of a process called X inactivation. Early in development, when female mammalian embryos consist of just a few thousand cells, one X chromosome in each cell inactivates by condensing into a structure called a Barr body. The genes on the inactive X chromosome are not expressed. The particular X chromosome (maternally or paternally derived) that is inactivated in each cell is random, but once the inactivation occurs, all cells descended from that cell will have the same inactive X chromosome. By this process, females compensate for their double genetic dose of X chromosome.
In so-called “tortoiseshell” cats, X inactivation is observed as coat-color variegation (Figure 6.10). Females heterozygous for an X-linked coat color gene will express one of two different coat colors over different regions of their body, corresponding to whichever X chromosome is inactivated in the embryonic cell progenitor of that region. When you see a tortoiseshell cat, you will know that it has to be a female.

In an individual carrying an abnormal number of X chromosomes, cellular mechanisms will inactivate all but one X in each of her cells. As a result, X-chromosomal abnormalities are typically associated with mild mental and physical defects, as well as sterility. If the X chromosome is absent altogether, the individual will not develop.
Several errors in sex chromosome number have been characterized. Individuals with three X chromosomes, called triplo-X, appear female but express developmental delays and reduced fertility. The XXY chromosome complement, corresponding to one type of Klinefelter syndrome, corresponds to male individuals with small testes, enlarged breasts, and reduced body hair. The extra X chromosome undergoes inactivation to compensate for the excess genetic dosage. Turner syndrome, characterized as an X0 chromosome complement (i.e., only a single sex chromosome), corresponds to a female individual with short stature, webbed skin in the neck region, hearing and cardiac impairments, and sterility.
An individual with more than the correct number of chromosome sets (two for diploid species) is called polyploid. For instance, fertilization of an abnormal diploid egg with a normal haploid sperm would yield a triploid zygote. Polyploid animals are extremely rare, with only a few examples among the flatworms, crustaceans, amphibians, fish, and lizards. Triploid animals are sterile because meiosis cannot proceed normally with an odd number of chromosome sets. In contrast, polyploidy is very common in the plant kingdom, and polyploid plants tend to be larger and more robust than euploids of their species.
Cytologists have characterized numerous structural rearrangements in chromosomes, including partial duplications, deletions, inversions, and translocations. Duplications and deletions often produce offspring that survive but exhibit physical and mental abnormalities. Cri-du-chat (from the French for “cry of the cat”) is a syndrome associated with nervous system abnormalities and identifiable physical features that results from a deletion of most of the small arm of chromosome 5 (Figure 6.11). Infants with this genotype emit a characteristic high-pitched cry upon which the disorder’s name is based.
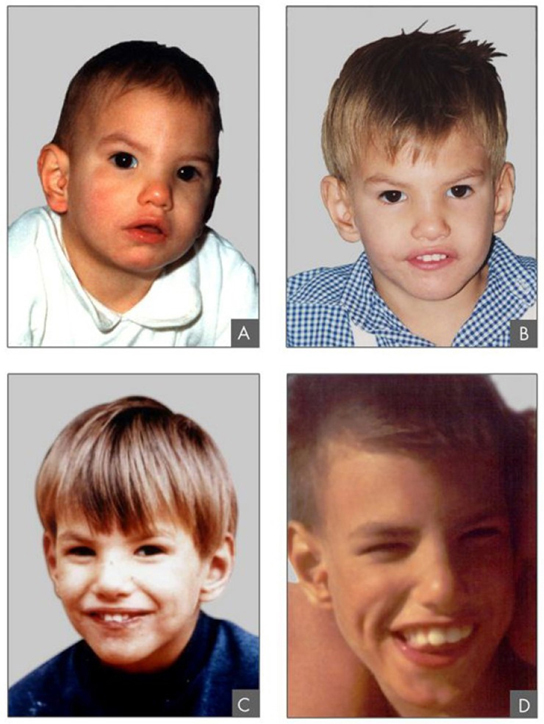
Chromosome inversions and translocations can be identified by observing cells during meiosis because homologous chromosomes with a rearrangement in one of the pair must contort to maintain appropriate gene alignment and pair effectively during prophase I.
A chromosome inversion is the detachment, 180° rotation, and reinsertion of part of a chromosome. Unless they disrupt a gene sequence, inversions only change the orientation of genes and are likely to have more mild effects than aneuploid errors.
The Chromosome 18 InversionNot all structural rearrangements of chromosomes produce nonviable, impaired, or infertile individuals. In rare instances, such a change can result in the evolution of a new species. In fact, an inversion in chromosome 18 appears to have contributed to the evolution of humans. This inversion is not present in our closest genetic relatives, the chimpanzees.
The chromosome 18 inversion is believed to have occurred in early humans following their divergence from a common ancestor with chimpanzees approximately five million years ago. Researchers have suggested that a long stretch of DNA was duplicated on chromosome 18 of an ancestor to humans, but that during the duplication it was inverted (inserted into the chromosome in reverse orientation.
A comparison of human and chimpanzee genes in the region of this inversion indicates that two genes—ROCK1 and USP14—are farther apart on human chromosome 18 than they are on the corresponding chimpanzee chromosome. This suggests that one of the inversion breakpoints occurred between these two genes. Interestingly, humans and chimpanzees express USP14 at distinct levels in specific cell types, including cortical cells and fibroblasts. Perhaps the chromosome 18 inversion in an ancestral human repositioned specific genes and reset their expression levels in a useful way. Because both ROCK1 and USP14 code for enzymes, a change in their expression could alter cellular function. It is not known how this inversion contributed to hominid evolution, but it appears to be a significant factor in the divergence of humans from other primates.1
A translocation occurs when a segment of a chromosome dissociates and reattaches to a different, nonhomologous chromosome. Translocations can be benign or have devastating effects, depending on how the positions of genes are altered with respect to regulatory sequences. Notably, specific translocations have been associated with several cancers and with schizophrenia. Reciprocal translocations result from the exchange of chromosome segments between two nonhomologous chromosomes such that there is no gain or loss of genetic information (Figure 6.12).
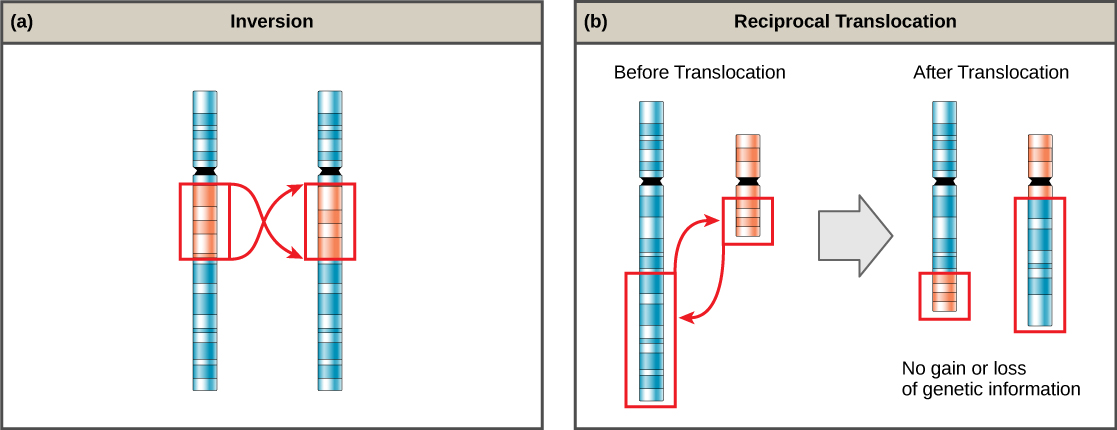
The number, size, shape, and banding pattern of chromosomes make them easily identifiable in a karyogram and allow for the assessment of many chromosomal abnormalities. Disorders in chromosome number, or aneuploidies, are typically lethal to the embryo, although a few trisomic genotypes are viable. Because of X inactivation, aberrations in sex chromosomes typically have milder effects on an individual. Aneuploidies also include instances in which segments of a chromosome are duplicated or deleted. Chromosome structures also may be rearranged, for example by inversion or translocation. Both of these aberrations can result in negative effects on development, or death. Because they force chromosomes to assume contorted pairings during meiosis I, inversions and translocations are often associated with reduced fertility because of the likelihood of nondisjunction.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=216#h5p-43
aneuploid: an individual with an error in chromosome number; includes deletions and duplications of chromosome segments
autosome: any of the non-sex chromosomes
chromosome inversion: the detachment, 180° rotation, and reinsertion of a chromosome arm
euploid: an individual with the appropriate number of chromosomes for their species
karyogram: the photographic image of a karyotype
karyotype: the number and appearance of an individuals chromosomes, including the size, banding patterns, and centromere position
monosomy: an otherwise diploid genotype in which one chromosome is missing
nondisjunction: the failure of synapsed homologs to completely separate and migrate to separate poles during the first cell division of meiosis
polyploid: an individual with an incorrect number of chromosome sets
translocation: the process by which one segment of a chromosome dissociates and reattaches to a different, nonhomologous chromosome
trisomy: an otherwise diploid genotype in which one entire chromosome is duplicated
X inactivation: the condensation of X chromosomes into Barr bodies during embryonic development in females to compensate for the double genetic dose
1 V Goidts, et al., “Segmental duplication associated with the human-specific inversion of chromosome 18: a further example of the impact of segmental duplications on karyotype and genome evolution in primates,” Human Genetics, 115 (2004):116–22.
Chapter 7 in Concepts of Biology: 1st Canadian Edition

Genetics is the study of heredity. Johann Gregor Mendel set the framework for genetics long before chromosomes or genes had been identified, at a time when meiosis was not well understood. Mendel selected a simple biological system and conducted methodical, quantitative analyses using large sample sizes. Because of Mendel’s work, the fundamental principles of heredity were revealed. We now know that genes, carried on chromosomes, are the basic functional units of heredity with the ability to be replicated, expressed, or mutated. Today, the postulates put forth by Mendel form the basis of classical, or Mendelian, genetics. Not all genes are transmitted from parents to offspring according to Mendelian genetics, but Mendel’s experiments serve as an excellent starting point for thinking about inheritance.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=219#h5p-44
Chapter 8 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:

Watch the interactive video
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=225#h5p-45
Johann Gregor Mendel (1822–1884) was a lifelong learner, teacher, scientist, and man of faith. As a young adult, he joined the Augustinian Abbey of St. Thomas in Brno in what is now the Czech Republic. Supported by the monastery, he taught physics, botany, and natural science courses at the secondary and university levels. In 1856, he began a decade-long research pursuit involving inheritance patterns in honeybees and plants, ultimately settling on pea plants as his primary model system (a system with convenient characteristics that is used to study a specific biological phenomenon to gain understanding to be applied to other systems). In 1865, Mendel presented the results of his experiments with nearly 30,000 pea plants to the local natural history society. He demonstrated that traits are transmitted faithfully from parents to offspring in specific patterns. In 1866, he published his work, Experiments in Plant Hybridization,1 in the proceedings of the Natural History Society of Brünn.
Mendel’s work went virtually unnoticed by the scientific community, which incorrectly believed that the process of inheritance involved a blending of parental traits that produced an intermediate physical appearance in offspring. This hypothetical process appeared to be correct because of what we know now as continuous variation. Continuous variation is the range of small differences we see among individuals in a characteristic like human height. It does appear that offspring are a “blend” of their parents’ traits when we look at characteristics that exhibit continuous variation. Mendel worked instead with traits that show discontinuous variation. Discontinuous variation is the variation seen among individuals when each individual shows one of two—or a very few—easily distinguishable traits, such as violet or white flowers. Mendel’s choice of these kinds of traits allowed him to see experimentally that the traits were not blended in the offspring as would have been expected at the time, but that they were inherited as distinct traits. In 1868, Mendel became abbot of the monastery and exchanged his scientific pursuits for his pastoral duties. He was not recognized for his extraordinary scientific contributions during his lifetime; in fact, it was not until 1900 that his work was rediscovered, reproduced, and revitalized by scientists on the brink of discovering the chromosomal basis of heredity.
Mendel’s seminal work was accomplished using the garden pea, Pisum sativum, to study inheritance. This species naturally self-fertilizes, meaning that pollen encounters ova within the same flower. The flower petals remain sealed tightly until pollination is completed to prevent the pollination of other plants. The result is highly inbred, or “true-breeding,” pea plants. These are plants that always produce offspring that look like the parent. By experimenting with true-breeding pea plants, Mendel avoided the appearance of unexpected traits in offspring that might occur if the plants were not true breeding. The garden pea also grows to maturity within one season, meaning that several generations could be evaluated over a relatively short time. Finally, large quantities of garden peas could be cultivated simultaneously, allowing Mendel to conclude that his results did not come about simply by chance.
Mendel performed hybridizations, which involve mating two true-breeding individuals that have different traits. In the pea, which is naturally self-pollinating, this is done by manually transferring pollen from the anther of a mature pea plant of one variety to the stigma of a separate mature pea plant of the second variety.
Plants used in first-generation crosses were called P, or parental generation, plants (Figure 7.3). Mendel collected the seeds produced by the P plants that resulted from each cross and grew them the following season. These offspring were called the F1, or the first filial (filial = daughter or son), generation. Once Mendel examined the characteristics in the F1 generation of plants, he allowed them to self-fertilize naturally. He then collected and grew the seeds from the F1 plants to produce the F2, or second filial, generation. Mendel’s experiments extended beyond the F2 generation to the F3 generation, F4 generation, and so on, but it was the ratio of characteristics in the P, F1, and F2 generations that were the most intriguing and became the basis of Mendel’s postulates.
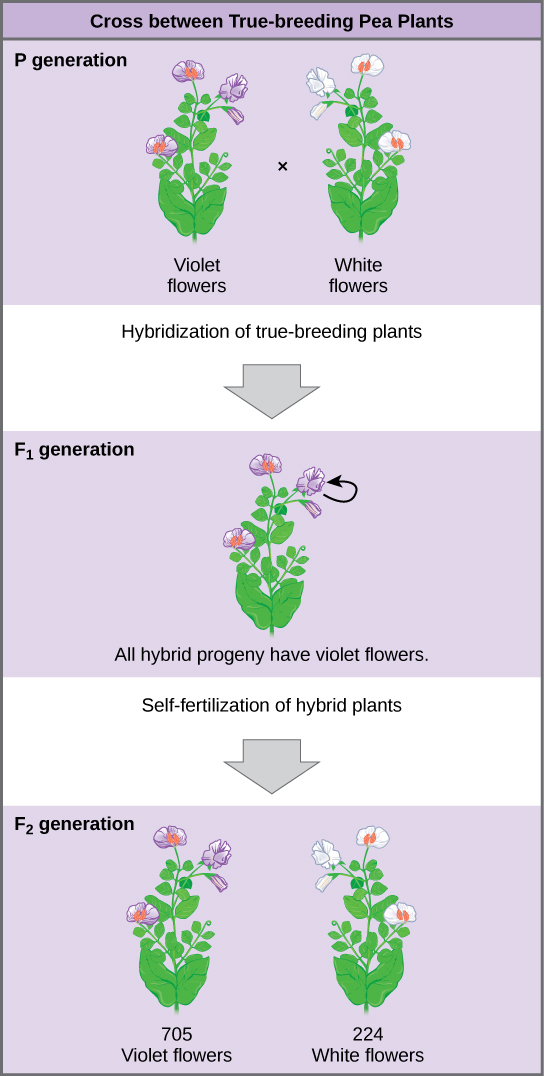
In his 1865 publication, Mendel reported the results of his crosses involving seven different characteristics, each with two contrasting traits. A trait is defined as a variation in the physical appearance of a heritable characteristic. The characteristics included plant height, seed texture, seed color, flower color, pea-pod size, pea-pod color, and flower position. For the characteristic of flower color, for example, the two contrasting traits were white versus violet. To fully examine each characteristic, Mendel generated large numbers of F1 and F2 plants and reported results from thousands of F2 plants.
What results did Mendel find in his crosses for flower color? First, Mendel confirmed that he was using plants that bred true for white or violet flower color. Irrespective of the number of generations that Mendel examined, all self-crossed offspring of parents with white flowers had white flowers, and all self-crossed offspring of parents with violet flowers had violet flowers. In addition, Mendel confirmed that, other than flower color, the pea plants were physically identical. This was an important check to make sure that the two varieties of pea plants only differed with respect to one trait, flower color.
Once these validations were complete, Mendel applied the pollen from a plant with violet flowers to the stigma of a plant with white flowers. After gathering and sowing the seeds that resulted from this cross, Mendel found that 100 percent of the F1 hybrid generation had violet flowers. Conventional wisdom at that time would have predicted the hybrid flowers to be pale violet or for hybrid plants to have equal numbers of white and violet flowers. In other words, the contrasting parental traits were expected to blend in the offspring. Instead, Mendel’s results demonstrated that the white flower trait had completely disappeared in the F1 generation.
Importantly, Mendel did not stop his experimentation there. He allowed the F1 plants to self-fertilize and found that 705 plants in the F2generation had violet flowers and 224 had white flowers. This was a ratio of 3.15 violet flowers to one white flower, or approximately 3:1. When Mendel transferred pollen from a plant with violet flowers to the stigma of a plant with white flowers and vice versa, he obtained approximately the same ratio irrespective of which parent—male or female—contributed which trait. This is called a reciprocal cross—a paired cross in which the respective traits of the male and female in one cross become the respective traits of the female and male in the other cross. For the other six characteristics that Mendel examined, the F1 and F2 generations behaved in the same way that they behaved for flower color. One of the two traits would disappear completely from the F1 generation, only to reappear in the F2 generation at a ratio of roughly 3:1 (Figure 7.4).
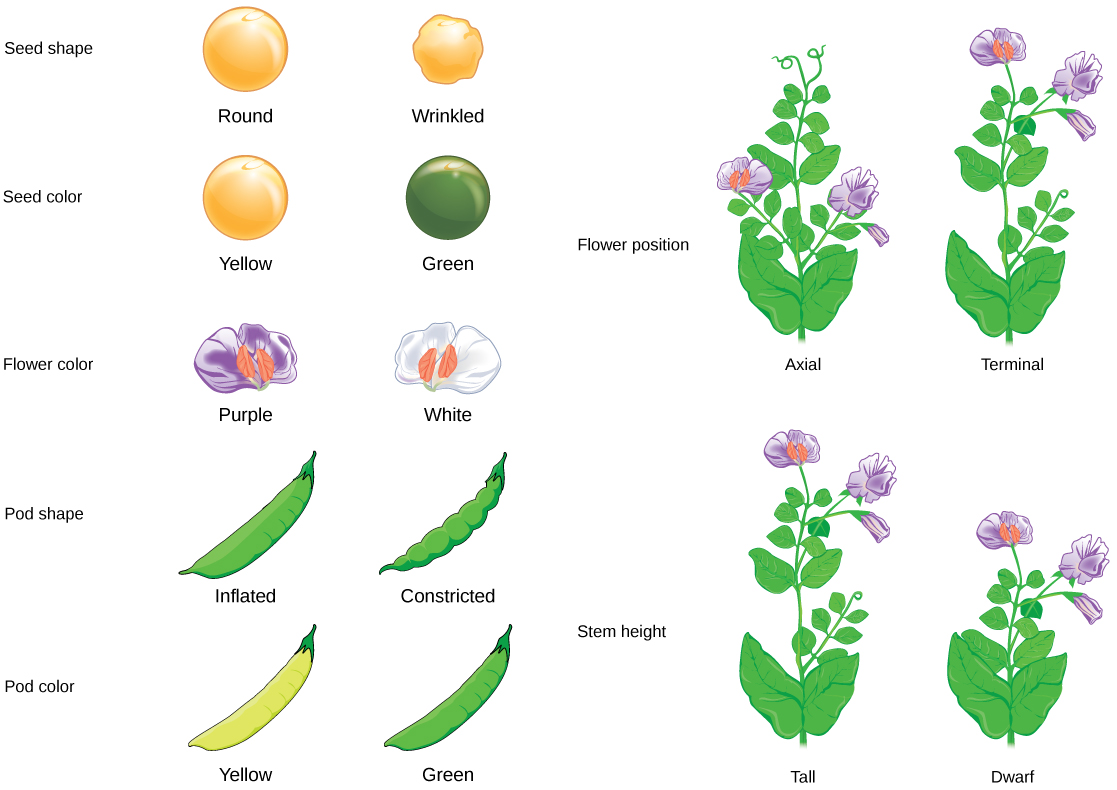
Upon compiling his results for many thousands of plants, Mendel concluded that the characteristics could be divided into expressed and latent traits. He called these dominant and recessive traits, respectively. Dominant traits are those that are inherited unchanged in a hybridization. Recessive traits become latent, or disappear in the offspring of a hybridization. The recessive trait does, however, reappear in the progeny of the hybrid offspring. An example of a dominant trait is the violet-colored flower trait. For this same characteristic (flower color), white-colored flowers are a recessive trait. The fact that the recessive trait reappeared in the F2 generation meant that the traits remained separate (and were not blended) in the plants of the F1 generation. Mendel proposed that this was because the plants possessed two copies of the trait for the flower-color characteristic, and that each parent transmitted one of their two copies to their offspring, where they came together. Moreover, the physical observation of a dominant trait could mean that the genetic composition of the organism included two dominant versions of the characteristic, or that it included one dominant and one recessive version. Conversely, the observation of a recessive trait meant that the organism lacked any dominant versions of this characteristic.

For an excellent review of Mendel’s experiments and to perform your own crosses and identify patterns of inheritance, visit the Mendel’s Peas web lab.
Working with garden pea plants, Mendel found that crosses between parents that differed for one trait produced F1 offspring that all expressed one parent’s traits. The traits that were visible in the F1 generation are referred to as dominant, and traits that disappear in the F1 generation are described as recessive. When the F1 plants in Mendel’s experiment were self-crossed, the F2 offspring exhibited the dominant trait or the recessive trait in a 3:1 ratio, confirming that the recessive trait had been transmitted faithfully from the original P parent. Reciprocal crosses generated identical F1 and F2 offspring ratios. By examining sample sizes, Mendel showed that traits were inherited as independent events.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=225#h5p-46
continuous variation: a variation in a characteristic in which individuals show a range of traits with small differences between them
discontinuous variation: a variation in a characteristic in which individuals show two, or a few, traits with large differences between them
dominant: describes a trait that masks the expression of another trait when both versions of the gene are present in an individual
F1: the first filial generation in a cross; the offspring of the parental generation
F2: the second filial generation produced when F1 individuals are self-crossed or fertilized with each other
hybridization: the process of mating two individuals that differ, with the goal of achieving a certain characteristic in their offspring
model system: a species or biological system used to study a specific biological phenomenon to gain understanding that will be applied to other species
P: the parental generation in a cross
recessive: describes a trait whose expression is masked by another trait when the alleles for both traits are present in an individual
reciprocal cross: a paired cross in which the respective traits of the male and female in one cross become the respective traits of the female and male in the other cross
trait: a variation in an inherited characteristic
1 Johann Gregor Mendel, “Versuche über Pflanzenhybriden.” Verhandlungen des naturforschenden Vereines in Brünn, Bd. IV für das Jahr, 1865 Abhandlungen (1866):3–47. [for English translation, see http://www.mendelweb.org/Mendel.plain.html]
Chapter 8 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
The seven characteristics that Mendel evaluated in his pea plants were each expressed as one of two versions, or traits. Mendel deduced from his results that each individual had two discrete copies of the characteristic that are passed individually to offspring. We now call those two copies genes, which are carried on chromosomes. The reason we have two copies of each gene is that we inherit one from each parent. In fact, it is the chromosomes we inherit and the two copies of each gene are located on paired chromosomes. Recall that in meiosis these chromosomes are separated out into haploid gametes. This separation, or segregation, of the homologous chromosomes means also that only one of the copies of the gene gets moved into a gamete. The offspring are formed when that gamete unites with one from another parent and the two copies of each gene (and chromosome) are restored.
For cases in which a single gene controls a single characteristic, a diploid organism has two genetic copies that may or may not encode the same version of that characteristic. For example, one individual may carry a gene that determines white flower color and a gene that determines violet flower color. Gene variants that arise by mutation and exist at the same relative locations on homologous chromosomes are called alleles. Mendel examined the inheritance of genes with just two allele forms, but it is common to encounter more than two alleles for any given gene in a natural population.
Two alleles for a given gene in a diploid organism are expressed and interact to produce physical characteristics. The observable traits expressed by an organism are referred to as its phenotype. An organism’s underlying genetic makeup, consisting of both the physically visible and the non-expressed alleles, is called its genotype. Mendel’s hybridization experiments demonstrate the difference between phenotype and genotype. For example, the phenotypes that Mendel observed in his crosses between pea plants with differing traits are connected to the diploid genotypes of the plants in the P, F1, and F2 generations. We will use a second trait that Mendel investigated, seed color, as an example. Seed color is governed by a single gene with two alleles. The yellow-seed allele is dominant and the green-seed allele is recessive. When true-breeding plants were cross-fertilized, in which one parent had yellow seeds and one had green seeds, all of the F1 hybrid offspring had yellow seeds. That is, the hybrid offspring were phenotypically identical to the true-breeding parent with yellow seeds. However, we know that the allele donated by the parent with green seeds was not simply lost because it reappeared in some of the F2 offspring (Figure 7.5). Therefore, the F1 plants must have been genotypically different from the parent with yellow seeds.
The P plants that Mendel used in his experiments were each homozygous for the trait he was studying. Diploid organisms that are homozygous for a gene have two identical alleles, one on each of their homologous chromosomes. The genotype is often written as YY or yy, for which each letter represents one of the two alleles in the genotype. The dominant allele is capitalized and the recessive allele is lower case. The letter used for the gene (seed color in this case) is usually related to the dominant trait (yellow allele, in this case, or “Y”). Mendel’s parental pea plants always bred true because both produced gametes carried the same allele. When P plants with contrasting traits were cross-fertilized, all of the offspring were heterozygous for the contrasting trait, meaning their genotype had different alleles for the gene being examined. For example, the F1 yellow plants that received a Y allele from their yellow parent and a y allele from their green parent had the genotype Yy.
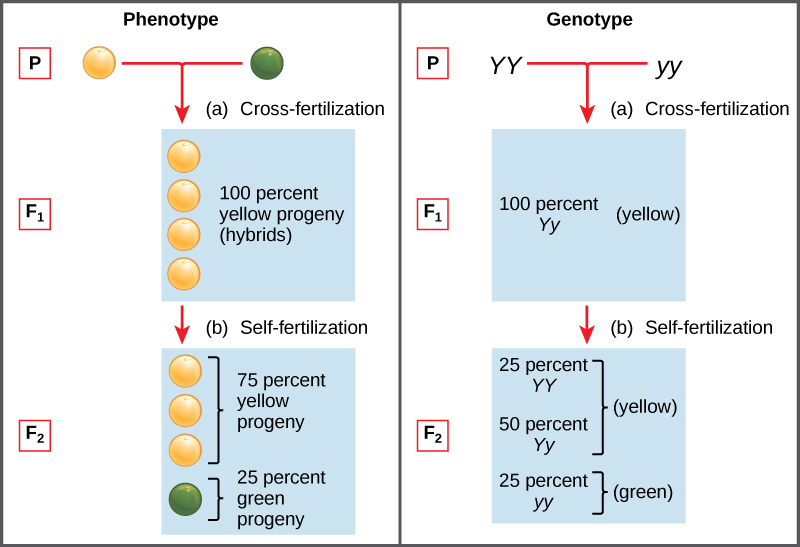
Our discussion of homozygous and heterozygous organisms brings us to why the F1 heterozygous offspring were identical to one of the parents, rather than expressing both alleles. In all seven pea-plant characteristics, one of the two contrasting alleles was dominant, and the other was recessive. Mendel called the dominant allele the expressed unit factor; the recessive allele was referred to as the latent unit factor. We now know that these so-called unit factors are actually genes on homologous chromosomes. For a gene that is expressed in a dominant and recessive pattern, homozygous dominant and heterozygous organisms will look identical (that is, they will have different genotypes but the same phenotype), and the recessive allele will only be observed in homozygous recessive individuals.
| Homozygous | Heterozygous | Homozygous | |
|---|---|---|---|
| Genotype | YY | Yy | yy |
| Phenotype | yellow | yellow | green |
Mendel’s law of dominance states that in a heterozygote, one trait will conceal the presence of another trait for the same characteristic. For example, when crossing true-breeding violet-flowered plants with true-breeding white-flowered plants, all of the offspring were violet-flowered, even though they all had one allele for violet and one allele for white. Rather than both alleles contributing to a phenotype, the dominant allele will be expressed exclusively. The recessive allele will remain latent, but will be transmitted to offspring in the same manner as that by which the dominant allele is transmitted. The recessive trait will only be expressed by offspring that have two copies of this allele (Figure 7.6), and these offspring will breed true when self-crossed.

When fertilization occurs between two true-breeding parents that differ by only the characteristic being studied, the process is called a monohybrid cross, and the resulting offspring are called monohybrids. Mendel performed seven types of monohybrid crosses, each involving contrasting traits for different characteristics. Out of these crosses, all of the F1 offspring had the phenotype of one parent, and the F2 offspring had a 3:1 phenotypic ratio. On the basis of these results, Mendel postulated that each parent in the monohybrid cross contributed one of two paired unit factors to each offspring, and every possible combination of unit factors was equally likely.
The results of Mendel’s research can be explained in terms of probabilities, which are mathematical measures of likelihood. The probability of an event is calculated by the number of times the event occurs divided by the total number of opportunities for the event to occur. A probability of one (100 percent) for some event indicates that it is guaranteed to occur, whereas a probability of zero (0 percent) indicates that it is guaranteed to not occur, and a probability of 0.5 (50 percent) means it has an equal chance of occurring or not occurring.
To demonstrate this with a monohybrid cross, consider the case of true-breeding pea plants with yellow versus green seeds. The dominant seed color is yellow; therefore, the parental genotypes were YY for the plants with yellow seeds and yy for the plants with green seeds. A Punnett square, devised by the British geneticist Reginald Punnett, is useful for determining probabilities because it is drawn to predict all possible outcomes of all possible random fertilization events and their expected frequencies. Figure 7.9 shows a Punnett square for a cross between a plant with yellow peas and one with green peas. To prepare a Punnett square, all possible combinations of the parental alleles (the genotypes of the gametes) are listed along the top (for one parent) and side (for the other parent) of a grid. The combinations of egg and sperm gametes are then made in the boxes in the table on the basis of which alleles are combining. Each box then represents the diploid genotype of a zygote, or fertilized egg. Because each possibility is equally likely, genotypic ratios can be determined from a Punnett square. If the pattern of inheritance (dominant and recessive) is known, the phenotypic ratios can be inferred as well. For a monohybrid cross of two true-breeding parents, each parent contributes one type of allele. In this case, only one genotype is possible in the F1 offspring. All offspring are Yy and have yellow seeds.
When the F1 offspring are crossed with each other, each has an equal probability of contributing either a Y or a y to the F2 offspring. The result is a 1 in 4 (25 percent) probability of both parents contributing a Y, resulting in an offspring with a yellow phenotype; a 25 percent probability of parent A contributing a Y and parent B a y, resulting in offspring with a yellow phenotype; a 25 percent probability of parent A contributing a y and parent B a Y, also resulting in a yellow phenotype; and a (25 percent) probability of both parents contributing a y, resulting in a green phenotype. When counting all four possible outcomes, there is a 3 in 4 probability of offspring having the yellow phenotype and a 1 in 4 probability of offspring having the green phenotype. This explains why the results of Mendel’s F2 generation occurred in a 3:1 phenotypic ratio. Using large numbers of crosses, Mendel was able to calculate probabilities, found that they fit the model of inheritance, and use these to predict the outcomes of other crosses.
Observing that true-breeding pea plants with contrasting traits gave rise to F1 generations that all expressed the dominant trait and F2 generations that expressed the dominant and recessive traits in a 3:1 ratio, Mendel proposed the law of segregation. This law states that paired unit factors (genes) must segregate equally into gametes such that offspring have an equal likelihood of inheriting either factor. For the F2 generation of a monohybrid cross, the following three possible combinations of genotypes result: homozygous dominant, heterozygous, or homozygous recessive. Because heterozygotes could arise from two different pathways (receiving one dominant and one recessive allele from either parent), and because heterozygotes and homozygous dominant individuals are phenotypically identical, the law supports Mendel’s observed 3:1 phenotypic ratio. The equal segregation of alleles is the reason we can apply the Punnett square to accurately predict the offspring of parents with known genotypes. The physical basis of Mendel’s law of segregation is the first division of meiosis in which the homologous chromosomes with their different versions of each gene are segregated into daughter nuclei. This process was not understood by the scientific community during Mendel’s lifetime (Figure 7.7).
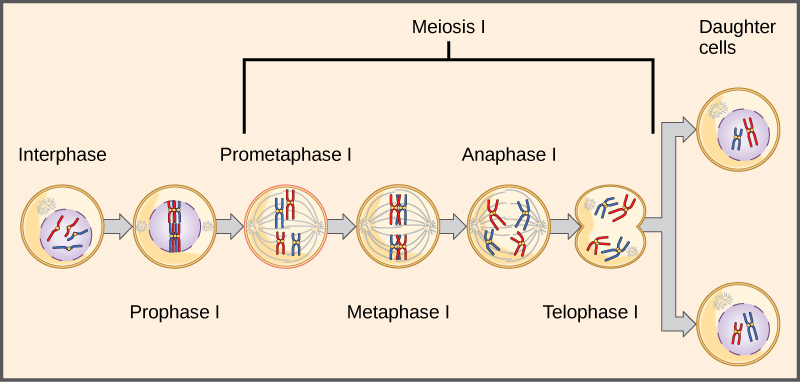
Beyond predicting the offspring of a cross between known homozygous or heterozygous parents, Mendel also developed a way to determine whether an organism that expressed a dominant trait was a heterozygote or a homozygote. Called the test cross, this technique is still used by plant and animal breeders. In a test cross, the dominant-expressing organism is crossed with an organism that is homozygous recessive for the same characteristic. If the dominant-expressing organism is a homozygote, then all F1 offspring will be heterozygotes expressing the dominant trait (Figure 7.8). Alternatively, if the dominant-expressing organism is a heterozygote, the F1 offspring will exhibit a 1:1 ratio of heterozygotes and recessive homozygotes (Figure 7.9). The test cross further validates Mendel’s postulate that pairs of unit factors segregate equally.
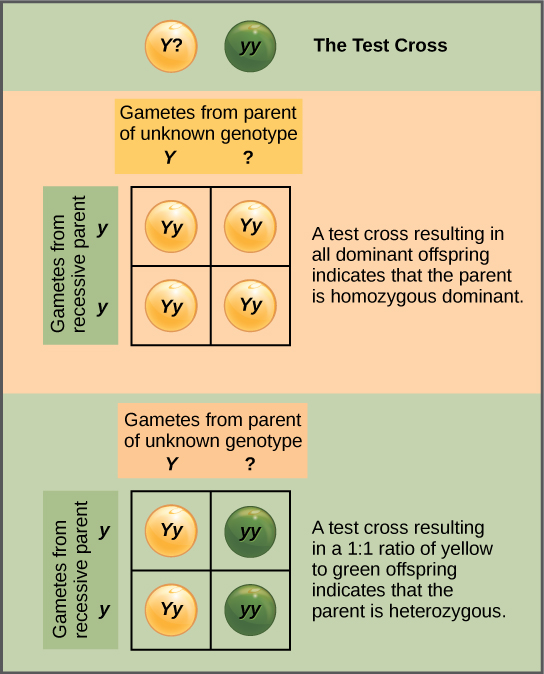
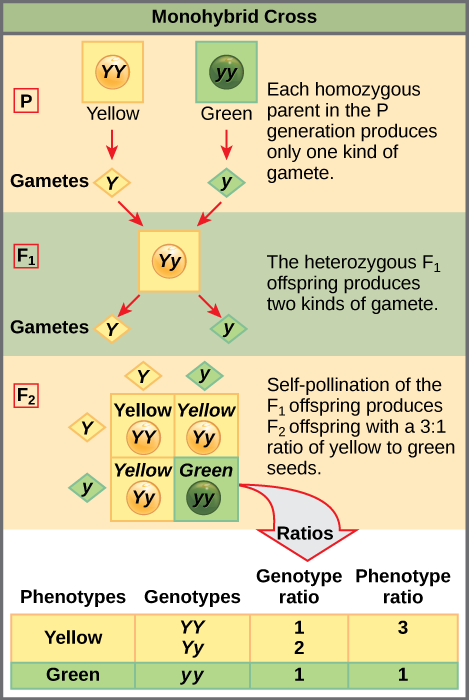
In pea plants, round peas (R) are dominant to wrinkled peas (r). You do a test cross between a pea plant with wrinkled peas (genotype rr) and a plant of unknown genotype that has round peas. You end up with three plants, all which have round peas. From this data, can you tell if the parent plant is homozygous dominant or heterozygous?
You cannot be sure if the plant is homozygous or heterozygous as the data set is too small: by random chance, all three plants might have acquired only the dominant gene even if the recessive one is present.
Mendel’s law of independent assortment states that genes do not influence each other with regard to the sorting of alleles into gametes, and every possible combination of alleles for every gene is equally likely to occur. Independent assortment of genes can be illustrated by the dihybrid cross, a cross between two true-breeding parents that express different traits for two characteristics. Consider the characteristics of seed color and seed texture for two pea plants, one that has wrinkled, green seeds (rryy) and another that has round, yellow seeds (RRYY). Because each parent is homozygous, the law of segregation indicates that the gametes for the wrinkled–green plant all are ry, and the gametes for the round–yellow plant are all RY. Therefore, the F1 generation of offspring all are RrYy (Figure 7.10).
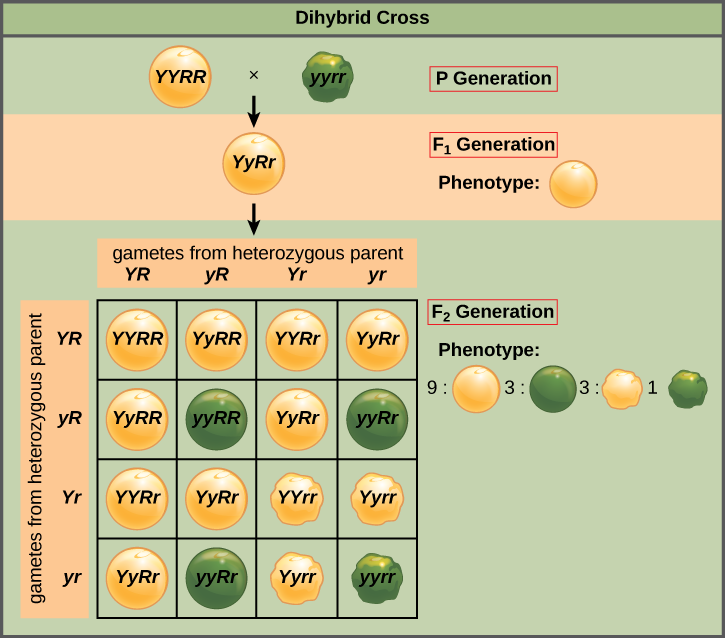
In pea plants, purple flowers (P) are dominant to white (p), and yellow peas (Y) are dominant to green (y). What are the possible genotypes and phenotypes for a cross between PpYY and ppYy pea plants? How many squares would you need to complete a Punnett square analysis of this cross?
The possible genotypes are PpYY, PpYy, ppYY, and ppYy. The former two genotypes would result in plants with purple flowers and yellow peas, while the latter two genotypes would result in plants with white flowers with yellow peas, for a 1:1 ratio of each phenotype. You only need a 2 × 2 Punnett square (four squares total) to do this analysis because two of the alleles are homozygous.
The gametes produced by the F1 individuals must have one allele from each of the two genes. For example, a gamete could get an R allele for the seed shape gene and either a Y or a y allele for the seed color gene. It cannot get both an R and an r allele; each gamete can have only one allele per gene. The law of independent assortment states that a gamete into which an r allele is sorted would be equally likely to contain either a Y or a y allele. Thus, there are four equally likely gametes that can be formed when the RrYy heterozygote is self-crossed, as follows: RY, rY, Ry, and ry. Arranging these gametes along the top and left of a 4 × 4 Punnett square gives us 16 equally likely genotypic combinations. From these genotypes, we find a phenotypic ratio of 9 round–yellow:3 round–green:3 wrinkled–yellow:1 wrinkled–green. These are the offspring ratios we would expect, assuming we performed the crosses with a large enough sample size.
The physical basis for the law of independent assortment also lies in meiosis I, in which the different homologous pairs line up in random orientations. Each gamete can contain any combination of paternal and maternal chromosomes (and therefore the genes on them) because the orientation of tetrads on the metaphase plane is random (Figure 7.11).
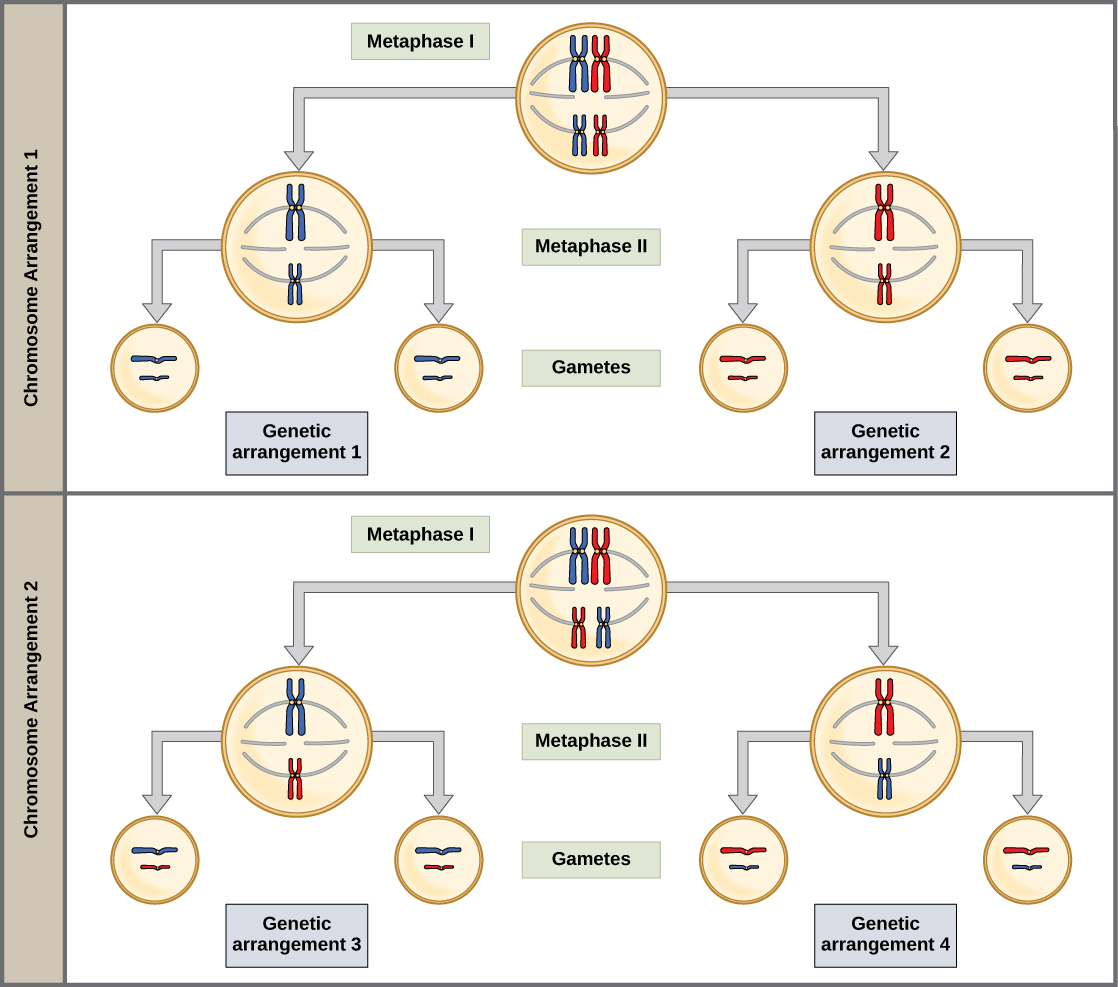
Probabilities are mathematical measures of likelihood. The empirical probability of an event is calculated by dividing the number of times the event occurs by the total number of opportunities for the event to occur. It is also possible to calculate theoretical probabilities by dividing the number of times that an event is expected to occur by the number of times that it could occur. Empirical probabilities come from observations, like those of Mendel. Theoretical probabilities come from knowing how the events are produced and assuming that the probabilities of individual outcomes are equal. A probability of one for some event indicates that it is guaranteed to occur, whereas a probability of zero indicates that it is guaranteed not to occur. An example of a genetic event is a round seed produced by a pea plant. In his experiment, Mendel demonstrated that the probability of the event “round seed” occurring was one in the F1 offspring of true-breeding parents, one of which has round seeds and one of which has wrinkled seeds. When the F1 plants were subsequently self-crossed, the probability of any given F2 offspring having round seeds was now three out of four. In other words, in a large population of F2 offspring chosen at random, 75 percent were expected to have round seeds, whereas 25 percent were expected to have wrinkled seeds. Using large numbers of crosses, Mendel was able to calculate probabilities and use these to predict the outcomes of other crosses.
Mendel demonstrated that the pea-plant characteristics he studied were transmitted as discrete units from parent to offspring. As will be discussed, Mendel also determined that different characteristics, like seed color and seed texture, were transmitted independently of one another and could be considered in separate probability analyses. For instance, performing a cross between a plant with green, wrinkled seeds and a plant with yellow, round seeds still produced offspring that had a 3:1 ratio of green:yellow seeds (ignoring seed texture) and a 3:1 ratio of round:wrinkled seeds (ignoring seed color). The characteristics of color and texture did not influence each other.
The product rule of probability can be applied to this phenomenon of the independent transmission of characteristics. The product rule states that the probability of two independent events occurring together can be calculated by multiplying the individual probabilities of each event occurring alone. To demonstrate the product rule, imagine that you are rolling a six-sided die (D) and flipping a penny (P) at the same time. The die may roll any number from 1–6 (D#), whereas the penny may turn up heads (PH) or tails (PT). The outcome of rolling the die has no effect on the outcome of flipping the penny and vice versa. There are 12 possible outcomes of this action, and each event is expected to occur with equal probability.
| Rolling Die | Flipping Penny |
|---|---|
| D1 | PH |
| D1 | PT |
| D2 | PH |
| D2 | PT |
| D3 | PH |
| D3 | PT |
| D4 | PH |
| D4 | PT |
| D5 | PH |
| D5 | PT |
| D6 | PH |
| D6 | PT |
Of the 12 possible outcomes, the die has a 2/12 (or 1/6) probability of rolling a two, and the penny has a 6/12 (or 1/2) probability of coming up heads. By the product rule, the probability that you will obtain the combined outcome 2 and heads is: (D2) x (PH) = (1/6) x (1/2) or 1/12. Notice the word “and” in the description of the probability. The “and” is a signal to apply the product rule. For example, consider how the product rule is applied to the dihybrid cross: the probability of having both dominant traits in the F2 progeny is the product of the probabilities of having the dominant trait for each characteristic, as shown here:
On the other hand, the sum rule of probability is applied when considering two mutually exclusive outcomes that can come about by more than one pathway. The sum rule states that the probability of the occurrence of one event or the other event, of two mutually exclusive events, is the sum of their individual probabilities. Notice the word “or” in the description of the probability. The “or” indicates that you should apply the sum rule. In this case, let’s imagine you are flipping a penny (P) and a quarter (Q). What is the probability of one coin coming up heads and one coin coming up tails? This outcome can be achieved by two cases: the penny may be heads (PH) and the quarter may be tails (QT), or the quarter may be heads (QH) and the penny may be tails (PT). Either case fulfills the outcome. By the sum rule, we calculate the probability of obtaining one head and one tail as [(PH) × (QT)] + [(QH) × (PT)] = [(1/2) × (1/2)] + [(1/2) × (1/2)] = 1/2. You should also notice that we used the product rule to calculate the probability of PH and QT, and also the probability of PT and QH, before we summed them. Again, the sum rule can be applied to show the probability of having just one dominant trait in the F2 generation of a dihybrid cross:
| Product Rule | Sum Rule |
|---|---|
| For independent events A and B, the probability (P) of them both occurring (A and B) is (PA × PB) | For mutually exclusive events A and B, the probability (P) that at least one occurs (A or B) is (PA + PB) |
To use probability laws in practice, it is necessary to work with large sample sizes because small sample sizes are prone to deviations caused by chance. The large quantities of pea plants that Mendel examined allowed him calculate the probabilities of the traits appearing in his F2 generation. As you will learn, this discovery meant that when parental traits were known, the offspring’s traits could be predicted accurately even before fertilization.
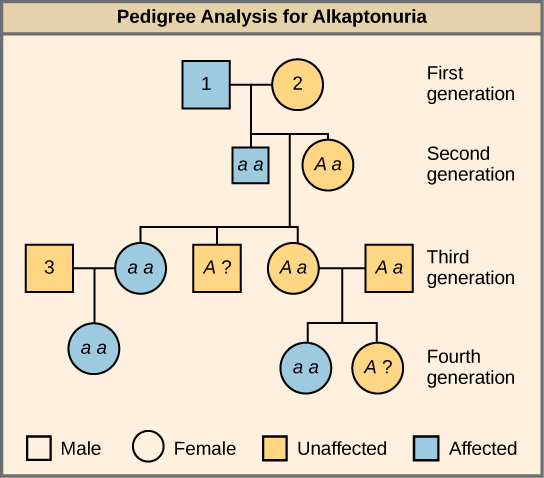
Alkaptonuria is a recessive genetic disorder in which two amino acids, phenylalanine and tyrosine, are not properly metabolized. Affected individuals may have darkened skin and brown urine, and may suffer joint damage and other complications. In this pedigree, individuals with the disorder are indicated in blue and have the genotype aa. Unaffected individuals are indicated in yellow and have the genotype AA or Aa. Note that it is often possible to determine a person’s genotype from the genotype of their offspring. For example, if neither parent has the disorder but their child does, they must be heterozygous. Two individuals on the pedigree have an unaffected phenotype but unknown genotype. Because they do not have the disorder, they must have at least one normal allele, so their genotype gets the “A?” designation.
What are the genotypes of the individuals labeled 1, 2 and 3?
When true-breeding, or homozygous, individuals that differ for a certain trait are crossed, all of the offspring will be heterozygous for that trait. If the traits are inherited as dominant and recessive, the F1 offspring will all exhibit the same phenotype as the parent homozygous for the dominant trait. If these heterozygous offspring are self-crossed, the resulting F2 offspring will be equally likely to inherit gametes carrying the dominant or recessive trait, giving rise to offspring of which one quarter are homozygous dominant, half are heterozygous, and one quarter are homozygous recessive. Because homozygous dominant and heterozygous individuals are phenotypically identical, the observed traits in the F2 offspring will exhibit a ratio of three dominant to one recessive.
Mendel postulated that genes (characteristics) are inherited as pairs of alleles (traits) that behave in a dominant and recessive pattern. Alleles segregate into gametes such that each gamete is equally likely to receive either one of the two alleles present in a diploid individual. In addition, genes are assorted into gametes independently of one another. That is, in general, alleles are not more likely to segregate into a gamete with a particular allele of another gene.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=235#h5p-47
allele: one of two or more variants of a gene that determines a particular trait for a characteristic
dihybrid: the result of a cross between two true-breeding parents that express different traits for two characteristics
genotype: the underlying genetic makeup, consisting of both physically visible and non-expressed alleles, of an organism
heterozygous: having two different alleles for a given gene on the homologous chromosomes
homozygous: having two identical alleles for a given gene on the homologous chromosomes
law of dominance: in a heterozygote, one trait will conceal the presence of another trait for the same characteristic
law of independent assortment: genes do not influence each other with regard to sorting of alleles into gametes; every possible combination of alleles is equally likely to occur
law of segregation: paired unit factors (i.e., genes) segregate equally into gametes such that offspring have an equal likelihood of inheriting any combination of factors
monohybrid: the result of a cross between two true-breeding parents that express different traits for only one characteristic
phenotype: the observable traits expressed by an organism
Punnett square: a visual representation of a cross between two individuals in which the gametes of each individual are denoted along the top and side of a grid, respectively, and the possible zygotic genotypes are recombined at each box in the grid
test cross: a cross between a dominant expressing individual with an unknown genotype and a homozygous recessive individual; the offspring phenotypes indicate whether the unknown parent is heterozygous or homozygous for the dominant trait
Chapter 8 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
Mendel studied traits with only one mode of inheritance in pea plants. The inheritance of the traits he studied all followed the relatively simple pattern of dominant and recessive alleles for a single characteristic. There are several important modes of inheritance, discovered after Mendel’s work, that do not follow the dominant and recessive, single-gene model.
Mendel’s experiments with pea plants suggested that: 1) two types of “units” or alleles exist for every gene; 2) alleles maintain their integrity in each generation (no blending); and 3) in the presence of the dominant allele, the recessive allele is hidden, with no contribution to the phenotype. Therefore, recessive alleles can be “carried” and not expressed by individuals. Such heterozygous individuals are sometimes referred to as “carriers.” Since then, genetic studies in other organisms have shown that much more complexity exists, but that the fundamental principles of Mendelian genetics still hold true. In the sections to follow, we consider some of the extensions of Mendelism.
Mendel’s results, demonstrating that traits are inherited as dominant and recessive pairs, contradicted the view at that time that offspring exhibited a blend of their parents’ traits. However, the heterozygote phenotype occasionally does appear to be intermediate between the two parents. For example, in the snapdragon, Antirrhinum majus (Figure 7.13), a cross between a homozygous parent with white flowers (CWCW) and a homozygous parent with red flowers (CRCR) will produce offspring with pink flowers (CRCW). (Note that different genotypic abbreviations are used for Mendelian extensions to distinguish these patterns from simple dominance and recessiveness.) This pattern of inheritance is described as incomplete dominance, meaning that one of the alleles appears in the phenotype in the heterozygote, but not to the exclusion of the other, which can also be seen. The allele for red flowers is incompletely dominant over the allele for white flowers. However, the results of a heterozygote self-cross can still be predicted, just as with Mendelian dominant and recessive crosses. In this case, the genotypic ratio would be 1 CRCR:2 CRCW:1 CWCW, and the phenotypic ratio would be 1:2:1 for red:pink:white. The basis for the intermediate color in the heterozygote is simply that the pigment produced by the red allele (anthocyanin) is diluted in the heterozygote and therefore appears pink because of the white background of the flower petals.

A variation on incomplete dominance is codominance, in which both alleles for the same characteristic are simultaneously expressed in the heterozygote. An example of codominance occurs in the ABO blood groups of humans. The A and B alleles are expressed in the form of A or B molecules present on the surface of red blood cells. Homozygotes (IAIA and IBIB) express either the A or the B phenotype, and heterozygotes (IAIB) express both phenotypes equally. The IAIB individual has blood type AB. In a self-cross between heterozygotes expressing a codominant trait, the three possible offspring genotypes are phenotypically distinct. However, the 1:2:1 genotypic ratio characteristic of a Mendelian monohybrid cross still applies (Figure 7.14).
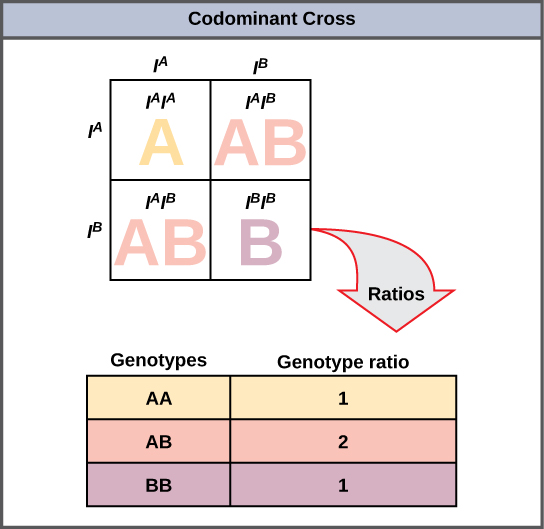
Mendel implied that only two alleles, one dominant and one recessive, could exist for a given gene. We now know that this is an oversimplification. Although individual humans (and all diploid organisms) can only have two alleles for a given gene, multiple alleles may exist at the population level, such that many combinations of two alleles are observed. Note that when many alleles exist for the same gene, the convention is to denote the most common phenotype or genotype in the natural population as the wild type (often abbreviated “+”). All other phenotypes or genotypes are considered variants (mutants) of this typical form, meaning they deviate from the wild type. The variant may be recessive or dominant to the wild-type allele.
An example of multiple alleles is the ABO blood-type system in humans. In this case, there are three alleles circulating in the population. The IA allele codes for A molecules on the red blood cells, the IB allele codes for B molecules on the surface of red blood cells, and the i allele codes for no molecules on the red blood cells. In this case, the IA and IB alleles are codominant with each other and are both dominant over the i allele. Although there are three alleles present in a population, each individual only gets two of the alleles from their parents. This produces the genotypes and phenotypes shown in Figure 7.15. Notice that instead of three genotypes, there are six different genotypes when there are three alleles. The number of possible phenotypes depends on the dominance relationships between the three alleles.
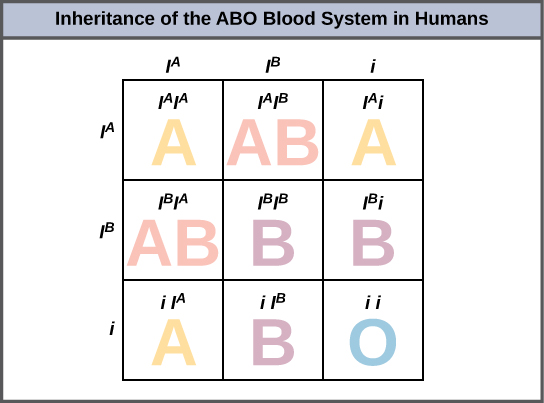
Malaria is a parasitic disease in humans that is transmitted by infected female mosquitoes, including Anopheles gambiae, and is characterized by cyclic high fevers, chills, flu-like symptoms, and severe anemia. Plasmodium falciparum and P. vivax are the most common causative agents of malaria, and P. falciparum is the most deadly. When promptly and correctly treated, P. falciparum malaria has a mortality rate of 0.1 percent. However, in some parts of the world, the parasite has evolved resistance to commonly used malaria treatments, so the most effective malarial treatments can vary by geographic region.
In Southeast Asia, Africa, and South America, P. falciparum has developed resistance to the anti-malarial drugs chloroquine, mefloquine, and sulfadoxine-pyrimethamine. P. falciparum, which is haploid during the life stage in which it is infective to humans, has evolved multiple drug-resistant mutant alleles of the dhps gene. Varying degrees of sulfadoxine resistance are associated with each of these alleles. Being haploid, P. falciparum needs only one drug-resistant allele to express this trait.
In Southeast Asia, different sulfadoxine-resistant alleles of the dhps gene are localized to different geographic regions. This is a common evolutionary phenomenon that comes about because drug-resistant mutants arise in a population and interbreed with other P. falciparum isolates in close proximity. Sulfadoxine-resistant parasites cause considerable human hardship in regions in which this drug is widely used as an over-the-counter malaria remedy. As is common with pathogens that multiply to large numbers within an infection cycle, P. falciparum evolves relatively rapidly (over a decade or so) in response to the selective pressure of commonly used anti-malarial drugs. For this reason, scientists must constantly work to develop new drugs or drug combinations to combat the worldwide malaria burden.1
In humans, as well as in many other animals and some plants, the sex of the individual is determined by sex chromosomes—one pair of non-homologous chromosomes. Until now, we have only considered inheritance patterns among non-sex chromosomes, or autosomes. In addition to 22 homologous pairs of autosomes, human females have a homologous pair of X chromosomes, whereas human males have an XY chromosome pair. Although the Y chromosome contains a small region of similarity to the X chromosome so that they can pair during meiosis, the Y chromosome is much shorter and contains fewer genes. When a gene being examined is present on the X, but not the Y, chromosome, it is X-linked.
Eye color in Drosophila, the common fruit fly, was the first X-linked trait to be identified. Thomas Hunt Morgan mapped this trait to the X chromosome in 1910. Like humans, Drosophila males have an XY chromosome pair, and females are XX. In flies the wild-type eye color is red (XW) and is dominant to white eye color (Xw) (Figure 7.16). Because of the location of the eye-color gene, reciprocal crosses do not produce the same offspring ratios. Males are said to be hemizygous, in that they have only one allele for any X-linked characteristic. Hemizygosity makes descriptions of dominance and recessiveness irrelevant for XY males. Drosophila males lack the white gene on the Y chromosome; that is, their genotype can only be XWY or XwY. In contrast, females have two allele copies of this gene and can be XWXW, XWXw, or XwXw.

In an X-linked cross, the genotypes of F1 and F2 offspring depend on whether the recessive trait was expressed by the male or the female in the P generation. With respect to Drosophila eye color, when the P male expresses the white-eye phenotype and the female is homozygously red-eyed, all members of the F1 generation exhibit red eyes (Figure 7.17). The F1 females are heterozygous (XWXw), and the males are all XWY, having received their X chromosome from the homozygous dominant P female and their Y chromosome from the P male. A subsequent cross between the XWXw female and the XWY male would produce only red-eyed females (with XWXW or XWXw genotypes) and both red- and white-eyed males (with XWY or XwY genotypes). Now, consider a cross between a homozygous white-eyed female and a male with red eyes. The F1 generation would exhibit only heterozygous red-eyed females (XWXw) and only white-eyed males (XwY). Half of the F2 females would be red-eyed (XWXw) and half would be white-eyed (XwXw). Similarly, half of the F2 males would be red-eyed (XWY) and half would be white-eyed (XwY).
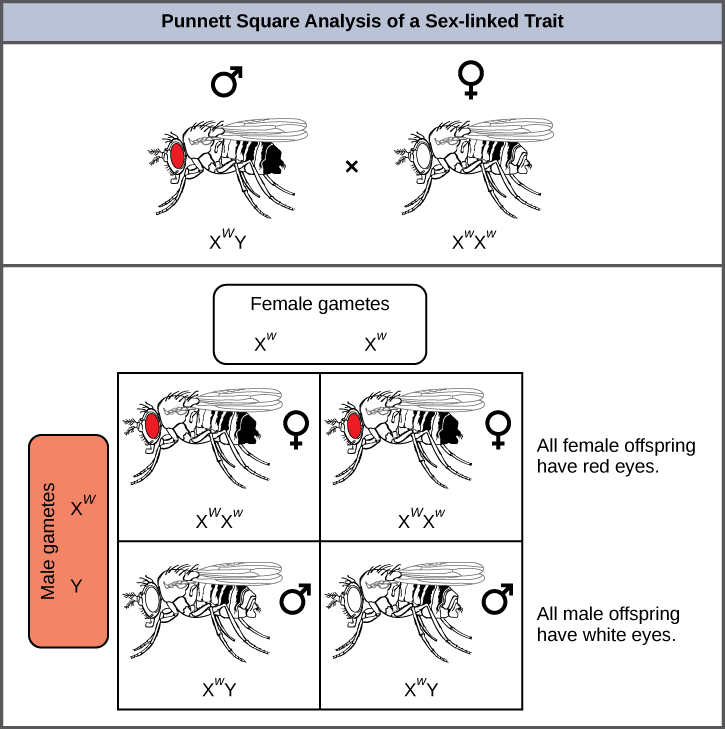
What ratio of offspring would result from a cross between a white-eyed male and a female that is heterozygous for red eye color?
Half of the female offspring would be heterozygous (XWXw) with red eyes, and half would be homozygous recessive (XwXw) with white eyes. Half of the male offspring would be hemizygous dominant (XWY) with red eyes, and half would be hemizygous recessive (XwY) with white eyes.
Discoveries in fruit fly genetics can be applied to human genetics. When a female parent is homozygous for a recessive X-linked trait, she will pass the trait on to 100 percent of her male offspring, because the males will receive the Y chromosome from the male parent. In humans, the alleles for certain conditions (some color-blindness, hemophilia, and muscular dystrophy) are X-linked. Females who are heterozygous for these diseases are said to be carriers and may not exhibit any phenotypic effects. These females will pass the disease to half of their sons and will pass carrier status to half of their daughters; therefore, X-linked traits appear more frequently in males than females.
In some groups of organisms with sex chromosomes, the sex with the non-homologous sex chromosomes is the female rather than the male. This is the case for all birds. In this case, sex-linked traits will be more likely to appear in the female, in whom they are hemizygous.

Watch this video to learn more about sex-linked traits.
Although all of Mendel’s pea plant characteristics behaved according to the law of independent assortment, we now know that some allele combinations are not inherited independently of each other. Genes that are located on separate, non-homologous chromosomes will always sort independently. However, each chromosome contains hundreds or thousands of genes, organized linearly on chromosomes like beads on a string. The segregation of alleles into gametes can be influenced by linkage, in which genes that are located physically close to each other on the same chromosome are more likely to be inherited as a pair. However, because of the process of recombination, or “crossover,” it is possible for two genes on the same chromosome to behave independently, or as if they are not linked. To understand this, let us consider the biological basis of gene linkage and recombination.
Homologous chromosomes possess the same genes in the same order, though the specific alleles of the gene can be different on each of the two chromosomes. Recall that during interphase and prophase I of meiosis, homologous chromosomes first replicate and then synapse, with like genes on the homologs aligning with each other. At this stage, segments of homologous chromosomes exchange linear segments of genetic material (Figure 7.18). This process is called recombination, or crossover, and it is a common genetic process. Because the genes are aligned during recombination, the gene order is not altered. Instead, the result of recombination is that maternal and paternal alleles are combined onto the same chromosome. Across a given chromosome, several recombination events may occur, causing extensive shuffling of alleles.
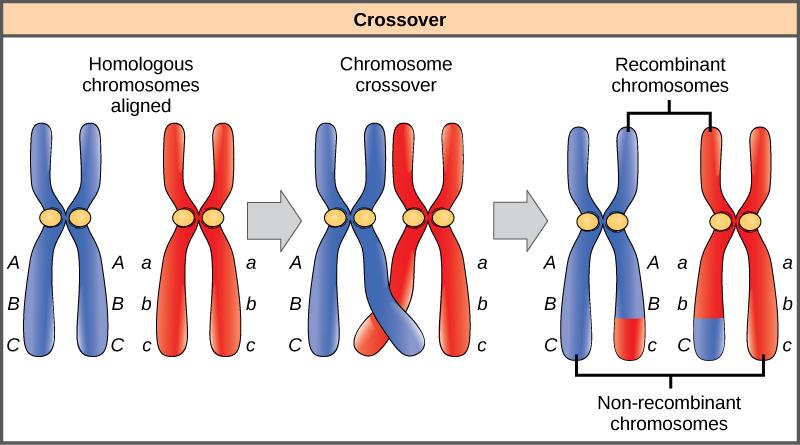
When two genes are located on the same chromosome, they are considered linked, and their alleles tend to be transmitted through meiosis together. To exemplify this, imagine a dihybrid cross involving flower color and plant height in which the genes are next to each other on the chromosome. If one homologous chromosome has alleles for tall plants and red flowers, and the other chromosome has genes for short plants and yellow flowers, then when the gametes are formed, the tall and red alleles will tend to go together into a gamete and the short and yellow alleles will go into other gametes. These are called the parental genotypes because they have been inherited intact from the parents of the individual producing gametes. But unlike if the genes were on different chromosomes, there will be no gametes with tall and yellow alleles and no gametes with short and red alleles. If you create a Punnett square with these gametes, you will see that the classical Mendelian prediction of a 9:3:3:1 outcome of a dihybrid cross would not apply. As the distance between two genes increases, the probability of one or more crossovers between them increases and the genes behave more like they are on separate chromosomes. Geneticists have used the proportion of recombinant gametes (the ones not like the parents) as a measure of how far apart genes are on a chromosome. Using this information, they have constructed linkage maps of genes on chromosomes for well-studied organisms, including humans.
Mendel’s seminal publication makes no mention of linkage, and many researchers have questioned whether he encountered linkage but chose not to publish those crosses out of concern that they would invalidate his independent assortment postulate. The garden pea has seven chromosomes, and some have suggested that his choice of seven characteristics was not a coincidence. However, even if the genes he examined were not located on separate chromosomes, it is possible that he simply did not observe linkage because of the extensive shuffling effects of recombination.
Mendel’s studies in pea plants implied that the sum of an individual’s phenotype was controlled by genes (or as he called them, unit factors), such that every characteristic was distinctly and completely controlled by a single gene. In fact, single observable characteristics are almost always under the influence of multiple genes (each with two or more alleles) acting in unison. For example, at least eight genes contribute to eye color in humans.

Eye color in humans is determined by multiple alleles. Use the Eye Color Calculator to predict the eye color of children from parental eye color.
In some cases, several genes can contribute to aspects of a common phenotype without their gene products ever directly interacting. In the case of organ development, for instance, genes may be expressed sequentially, with each gene adding to the complexity and specificity of the organ. Genes may function in complementary or synergistic fashions, such that two or more genes expressed simultaneously affect a phenotype. An apparent example of this occurs with human skin color, which appears to involve the action of at least three (and probably more) genes. Cases in which inheritance for a characteristic like skin color or human height depend on the combined effects of numerous genes are called polygenic inheritance.
Genes may also oppose each other, with one gene suppressing the expression of another. In epistasis, the interaction between genes is antagonistic, such that one gene masks or interferes with the expression of another. “Epistasis” is a word composed of Greek roots meaning “standing upon.” The alleles that are being masked or silenced are said to be hypostatic to the epistatic alleles that are doing the masking. Often the biochemical basis of epistasis is a gene pathway in which expression of one gene is dependent on the function of a gene that precedes or follows it in the pathway.
An example of epistasis is pigmentation in mice. The wild-type coat color, agouti (AA) is dominant to solid-colored fur (aa). However, a separate gene C, when present as the recessive homozygote (cc), negates any expression of pigment from the A gene and results in an albino mouse (Figure 7.19). Therefore, the genotypes AAcc, Aacc, and aacc all produce the same albino phenotype. A cross between heterozygotes for both genes (AaCc x AaCc) would generate offspring with a phenotypic ratio of 9 agouti:3 black:4 albino (Figure 7.19). In this case, the C gene is epistatic to the A gene.
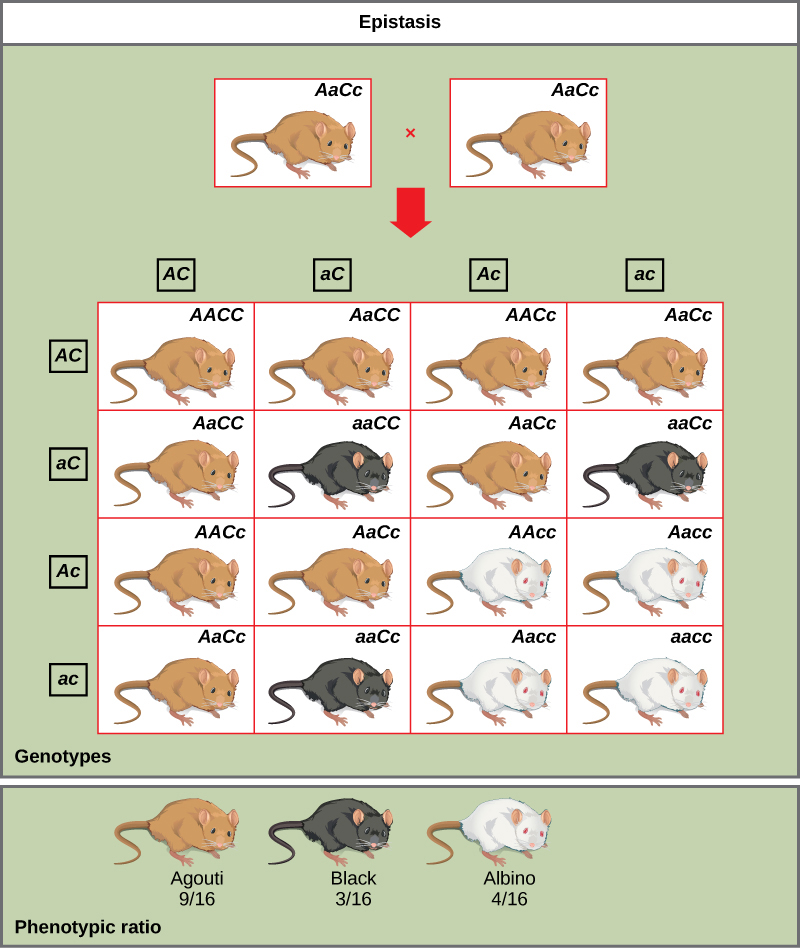
Alleles do not always behave in dominant and recessive patterns. Incomplete dominance describes situations in which the heterozygote exhibits a phenotype that is intermediate between the homozygous phenotypes. Codominance describes the simultaneous expression of both of the alleles in the heterozygote. Although diploid organisms can only have two alleles for any given gene, it is common for more than two alleles for a gene to exist in a population. In humans, as in many animals and some plants, females have two X chromosomes and males have one X and one Y chromosome. Genes that are present on the X but not the Y chromosome are said to be X-linked, such that males only inherit one allele for the gene, and females inherit two.
According to Mendel’s law of independent assortment, genes sort independently of each other into gametes during meiosis. This occurs because chromosomes, on which the genes reside, assort independently during meiosis and crossovers cause most genes on the same chromosomes to also behave independently. When genes are located in close proximity on the same chromosome, their alleles tend to be inherited together. This results in offspring ratios that violate Mendel’s law of independent assortment. However, recombination serves to exchange genetic material on homologous chromosomes such that maternal and paternal alleles may be recombined on the same chromosome. This is why alleles on a given chromosome are not always inherited together. Recombination is a random event occurring anywhere on a chromosome. Therefore, genes that are far apart on the same chromosome are likely to still assort independently because of recombination events that occurred in the intervening chromosomal space.
Whether or not they are sorting independently, genes may interact at the level of gene products, such that the expression of an allele for one gene masks or modifies the expression of an allele for a different gene. This is called epistasis.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=246#h5p-48
codominance: in a heterozygote, complete and simultaneous expression of both alleles for the same characteristic
epistasis: an interaction between genes such that one gene masks or interferes with the expression of another
hemizygous: the presence of only one allele for a characteristic, as in X-linkage; hemizygosity makes descriptions of dominance and recessiveness irrelevant
incomplete dominance: in a heterozygote, expression of two contrasting alleles such that the individual displays an intermediate phenotype
linkage: a phenomenon in which alleles that are located in close proximity to each other on the same chromosome are more likely to be inherited together
recombination: the process during meiosis in which homologous chromosomes exchange linear segments of genetic material, thereby dramatically increasing genetic variation in the offspring and separating linked genes
wild type: the most commonly occurring genotype or phenotype for a given characteristic found in a population
X-linked: a gene present on the X chromosome, but not the Y chromosome
1 Sumiti Vinayak et al., “Origin and Evolution of Sulfadoxine Resistant Plasmodium falciparum,” PLoS Pathogens 6 (2010): e1000830.
Chapter 8 in Concepts of Biology: 1st Canadian Edition

The three letters “DNA” have now become associated with crime solving, paternity testing, human identification, and genetic testing. DNA can be retrieved from hair, blood, or saliva. With the exception of identical twins, each person’s DNA is unique and it is possible to detect differences between human beings on the basis of their unique DNA sequence.
DNA analysis has many practical applications beyond forensics and paternity testing. DNA testing is used for tracing genealogy and identifying pathogens. In the medical field, DNA is used in diagnostics, new vaccine development, and cancer therapy. It is now possible to determine predisposition to many diseases by analyzing genes.
DNA is the genetic material passed from parent to offspring for all life on Earth. The technology of molecular genetics developed in the last half century has enabled us to see deep into the history of life to deduce the relationships between living things in ways never thought possible. It also allows us to understand the workings of evolution in populations of organisms. Over a thousand species have had their entire genome sequenced, and there have been thousands of individual human genome sequences completed. These sequences will allow us to understand human disease and the relationship of humans to the rest of the tree of life. Finally, molecular genetics techniques have revolutionized plant and animal breeding for human agricultural needs. All of these advances in biotechnology depended on basic research leading to the discovery of the structure of DNA in 1953, and the research since then that has uncovered the details of DNA replication and the complex process leading to the expression of DNA in the form of proteins in the cell.
Search for Key Points in Chapter 9
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=251#h5p-49
Chapter 9 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
In the 1950s, Francis Crick and James Watson worked together at the University of Cambridge, England, to determine the structure of DNA. Other scientists, such as Linus Pauling and Maurice Wilkins, were also actively exploring this field. Pauling had discovered the secondary structure of proteins using X-ray crystallography. X-ray crystallography is a method for investigating molecular structure by observing the patterns formed by X-rays shot through a crystal of the substance. The patterns give important information about the structure of the molecule of interest. In Wilkins’ lab, researcher Rosalind Franklin was using X-ray crystallography to understand the structure of DNA. Watson and Crick were able to piece together the puzzle of the DNA molecule using Franklin’s data (Figure 8.2). Watson and Crick also had key pieces of information available from other researchers such as Chargaff’s rules. Chargaff had shown that of the four kinds of monomers (nucleotides) present in a DNA molecule, two types were always present in equal amounts and the remaining two types were also always present in equal amounts. This meant they were always paired in some way. In 1962, James Watson, Francis Crick, and Maurice Wilkins were awarded the Nobel Prize in Medicine for their work in determining the structure of DNA.

Now let’s consider the structure of the two types of nucleic acids, deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). The building blocks of DNA are nucleotides, which are made up of three parts: a deoxyribose (5-carbon sugar), a phosphate group, and a nitrogenous base (Figure 8.3). There are four types of nitrogenous bases in DNA. Adenine (A) and guanine (G) are double-ringed purines, and cytosine (C) and thymine (T) are smaller, single-ringed pyrimidines. The nucleotide is named according to the nitrogenous base it contains.

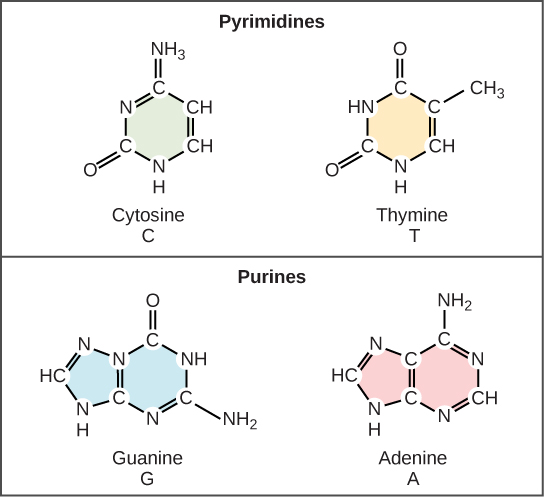
The phosphate group of one nucleotide bonds covalently with the sugar molecule of the next nucleotide, and so on, forming a long polymer of nucleotide monomers. The sugar–phosphate groups line up in a “backbone” for each single strand of DNA, and the nucleotide bases stick out from this backbone. The carbon atoms of the five-carbon sugar are numbered clockwise from the oxygen as 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”). The phosphate group is attached to the 5′ carbon of one nucleotide and the 3′ carbon of the next nucleotide. In its natural state, each DNA molecule is actually composed of two single strands held together along their length with hydrogen bonds between the bases.
Watson and Crick proposed that the DNA is made up of two strands that are twisted around each other to form a right-handed helix, called a double helix. Base-pairing takes place between a purine and pyrimidine: namely, A pairs with T, and G pairs with C. In other words, adenine and thymine are complementary base pairs, and cytosine and guanine are also complementary base pairs. This is the basis for Chargaff’s rule; because of their complementarity, there is as much adenine as thymine in a DNA molecule and as much guanine as cytosine. Adenine and thymine are connected by two hydrogen bonds, and cytosine and guanine are connected by three hydrogen bonds. The two strands are anti-parallel in nature; that is, one strand will have the 3′ carbon of the sugar in the “upward” position, whereas the other strand will have the 5′ carbon in the upward position. The diameter of the DNA double helix is uniform throughout because a purine (two rings) always pairs with a pyrimidine (one ring) and their combined lengths are always equal. (Figure 8.4).
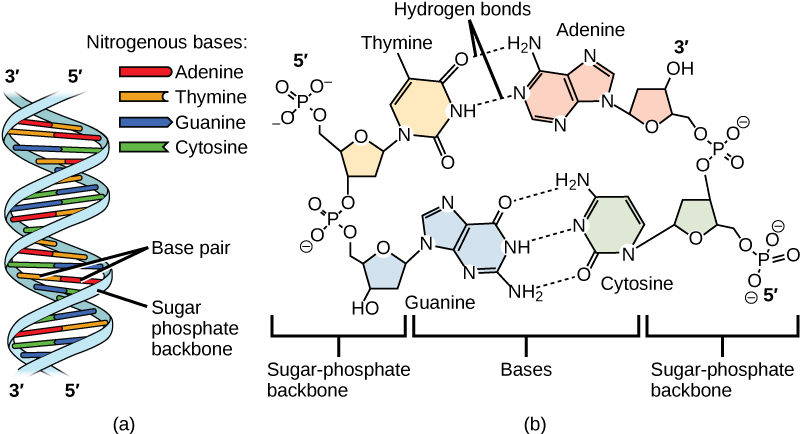
There is a second nucleic acid in all cells called ribonucleic acid, or RNA. Like DNA, RNA is a polymer of nucleotides. Each of the nucleotides in RNA is made up of a nitrogenous base, a five-carbon sugar, and a phosphate group. In the case of RNA, the five-carbon sugar is ribose, not deoxyribose. Ribose has a hydroxyl group at the 2′ carbon, unlike deoxyribose, which has only a hydrogen atom (Figure 8.5).
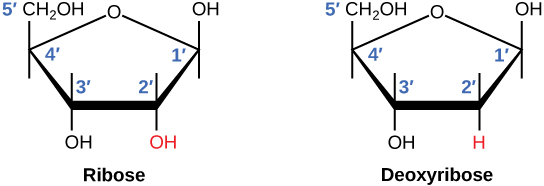
RNA nucleotides contain the nitrogenous bases adenine, cytosine, and guanine. However, they do not contain thymine, which is instead replaced by uracil, symbolized by a “U.” RNA exists as a single-stranded molecule rather than a double-stranded helix. Molecular biologists have named several kinds of RNA on the basis of their function. These include messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA)—molecules that are involved in the production of proteins from the DNA code.
DNA is a working molecule; it must be replicated when a cell is ready to divide, and it must be “read” to produce the molecules, such as proteins, to carry out the functions of the cell. For this reason, the DNA is protected and packaged in very specific ways. In addition, DNA molecules can be very long. Stretched end-to-end, the DNA molecules in a single human cell would come to a length of about 2 meters. Thus, the DNA for a cell must be packaged in a very ordered way to fit and function within a structure (the cell) that is not visible to the naked eye. The chromosomes of prokaryotes are much simpler than those of eukaryotes in many of their features (Figure 8.6). Most prokaryotes contain a single, circular chromosome that is found in an area in the cytoplasm called the nucleoid.
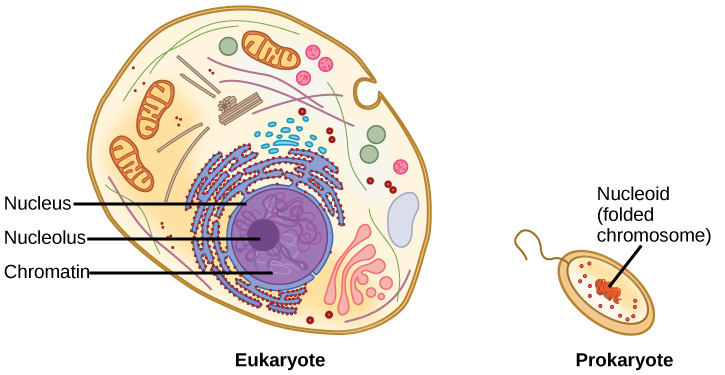
The size of the genome in one of the most well-studied prokaryotes, Escherichia coli, is 4.6 million base pairs, which would extend a distance of about 1.6 mm if stretched out. So how does this fit inside a small bacterial cell? The DNA is twisted beyond the double helix in what is known as supercoiling. Some proteins are known to be involved in the supercoiling; other proteins and enzymes help in maintaining the supercoiled structure.
Eukaryotes, whose chromosomes each consist of a linear DNA molecule, employ a different type of packing strategy to fit their DNA inside the nucleus. At the most basic level, DNA is wrapped around proteins known as histones to form structures called nucleosomes. The DNA is wrapped tightly around the histone core. This nucleosome is linked to the next one by a short strand of DNA that is free of histones. This is also known as the “beads on a string” structure; the nucleosomes are the “beads” and the short lengths of DNA between them are the “string.” The nucleosomes, with their DNA coiled around them, stack compactly onto each other to form a 30-nm–wide fiber. This fiber is further coiled into a thicker and more compact structure. At the metaphase stage of mitosis, when the chromosomes are lined up in the center of the cell, the chromosomes are at their most compacted. They are approximately 700 nm in width, and are found in association with scaffold proteins.
In interphase, the phase of the cell cycle between mitoses at which the chromosomes are decondensed, eukaryotic chromosomes have two distinct regions that can be distinguished by staining. There is a tightly packaged region that stains darkly, and a less dense region. The darkly staining regions usually contain genes that are not active, and are found in the regions of the centromere and telomeres. The lightly staining regions usually contain genes that are active, with DNA packaged around nucleosomes but not further compacted.
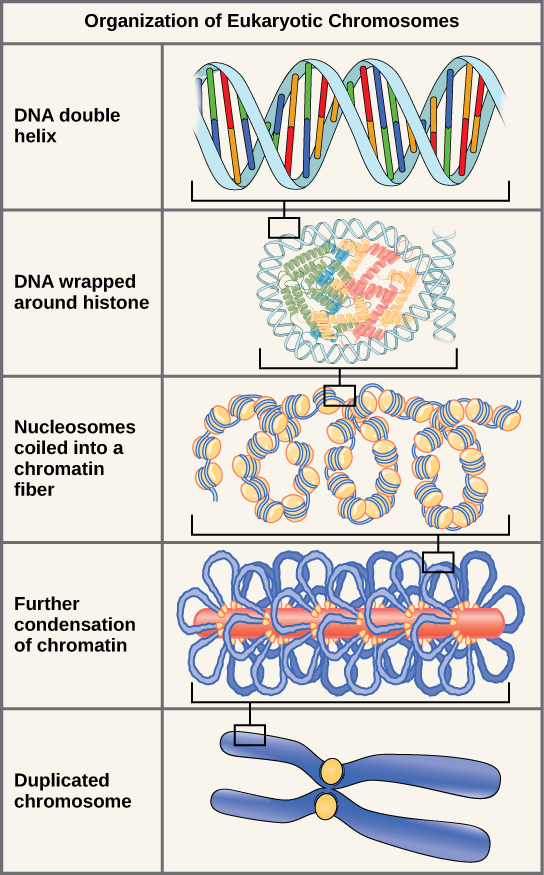
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=261#h5p-50
The model of the double-helix structure of DNA was proposed by Watson and Crick. The DNA molecule is a polymer of nucleotides. Each nucleotide is composed of a nitrogenous base, a five-carbon sugar (deoxyribose), and a phosphate group. There are four nitrogenous bases in DNA, two purines (adenine and guanine) and two pyrimidines (cytosine and thymine). A DNA molecule is composed of two strands. Each strand is composed of nucleotides bonded together covalently between the phosphate group of one and the deoxyribose sugar of the next. From this backbone extend the bases. The bases of one strand bond to the bases of the second strand with hydrogen bonds. Adenine always bonds with thymine, and cytosine always bonds with guanine. The bonding causes the two strands to spiral around each other in a shape called a double helix. Ribonucleic acid (RNA) is a second nucleic acid found in cells. RNA is a single-stranded polymer of nucleotides. It also differs from DNA in that it contains the sugar ribose, rather than deoxyribose, and the nucleotide uracil rather than thymine. Various RNA molecules function in the process of forming proteins from the genetic code in DNA.
Prokaryotes contain a single, double-stranded circular chromosome. Eukaryotes contain double-stranded linear DNA molecules packaged into chromosomes. The DNA helix is wrapped around proteins to form nucleosomes. The protein coils are further coiled, and during mitosis and meiosis, the chromosomes become even more greatly coiled to facilitate their movement. Chromosomes have two distinct regions which can be distinguished by staining, reflecting different degrees of packaging and determined by whether the DNA in a region is being expressed (euchromatin) or not (heterochromatin).
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=261#h5p-51
deoxyribose: a five-carbon sugar molecule with a hydrogen atom rather than a hydroxyl group in the 2′ position; the sugar component of DNA nucleotides
double helix: the molecular shape of DNA in which two strands of nucleotides wind around each other in a spiral shape
nitrogenous base: a nitrogen-containing molecule that acts as a base; often referring to one of the purine or pyrimidine components of nucleic acids
phosphate group: a molecular group consisting of a central phosphorus atom bound to four oxygen atoms
Chapter 9 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
When a cell divides, it is important that each daughter cell receives an identical copy of the DNA. This is accomplished by the process of DNA replication. The replication of DNA occurs during the synthesis phase, or S phase, of the cell cycle, before the cell enters mitosis or meiosis.
The elucidation of the structure of the double helix provided a hint as to how DNA is copied. Recall that adenine nucleotides pair with thymine nucleotides, and cytosine with guanine. This means that the two strands are complementary to each other. For example, a strand of DNA with a nucleotide sequence of AGTCATGA will have a complementary strand with the sequence TCAGTACT (Figure 8.8).
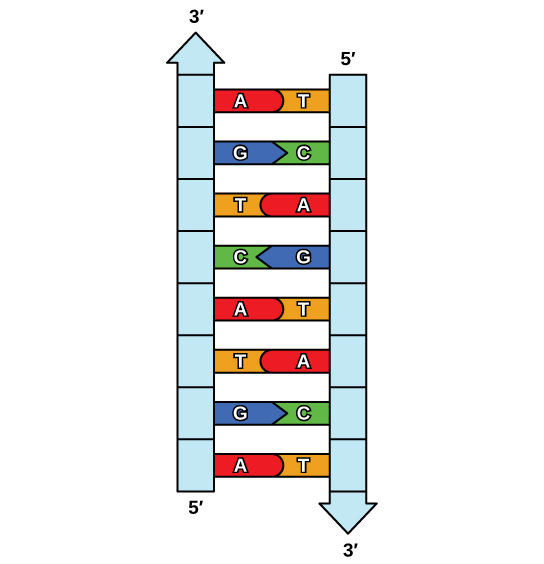
Because of the complementarity of the two strands, having one strand means that it is possible to recreate the other strand. This model for replication suggests that the two strands of the double helix separate during replication, and each strand serves as a template from which the new complementary strand is copied (Figure 8.9).
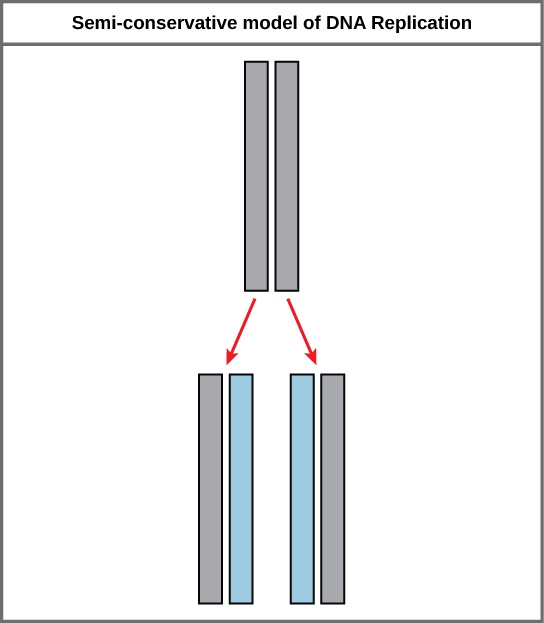
During DNA replication, each of the two strands that make up the double helix serves as a template from which new strands are copied. The new strand will be complementary to the parental or “old” strand. Each new double strand consists of one parental strand and one new daughter strand. This is known as semiconservative replication. When two DNA copies are formed, they have an identical sequence of nucleotide bases and are divided equally into two daughter cells.
Because eukaryotic genomes are very complex, DNA replication is a very complicated process that involves several enzymes and other proteins. It occurs in three main stages: initiation, elongation, and termination.
Recall that eukaryotic DNA is bound to proteins known as histones to form structures called nucleosomes. During initiation, the DNA is made accessible to the proteins and enzymes involved in the replication process. How does the replication machinery know where on the DNA double helix to begin? It turns out that there are specific nucleotide sequences called origins of replication at which replication begins. Certain proteins bind to the origin of replication while an enzyme called helicase unwinds and opens up the DNA helix. As the DNA opens up, Y-shaped structures called replication forks are formed (Figure 8.10). Two replication forks are formed at the origin of replication, and these get extended in both directions as replication proceeds. There are multiple origins of replication on the eukaryotic chromosome, such that replication can occur simultaneously from several places in the genome.
During elongation, an enzyme called DNA polymerase adds DNA nucleotides to the 3′ end of the template. Because DNA polymerase can only add new nucleotides at the end of a backbone, a primer sequence, which provides this starting point, is added with complementary RNA nucleotides. This primer is removed later, and the nucleotides are replaced with DNA nucleotides. One strand, which is complementary to the parental DNA strand, is synthesized continuously toward the replication fork so the polymerase can add nucleotides in this direction. This continuously synthesized strand is known as the leading strand. Because DNA polymerase can only synthesize DNA in a 5′ to 3′ direction, the other new strand is put together in short pieces called Okazaki fragments. The Okazaki fragments each require a primer made of RNA to start the synthesis. The strand with the Okazaki fragments is known as the lagging strand. As synthesis proceeds, an enzyme removes the RNA primer, which is then replaced with DNA nucleotides, and the gaps between fragments are sealed by an enzyme called DNA ligase.
The process of DNA replication can be summarized as follows:
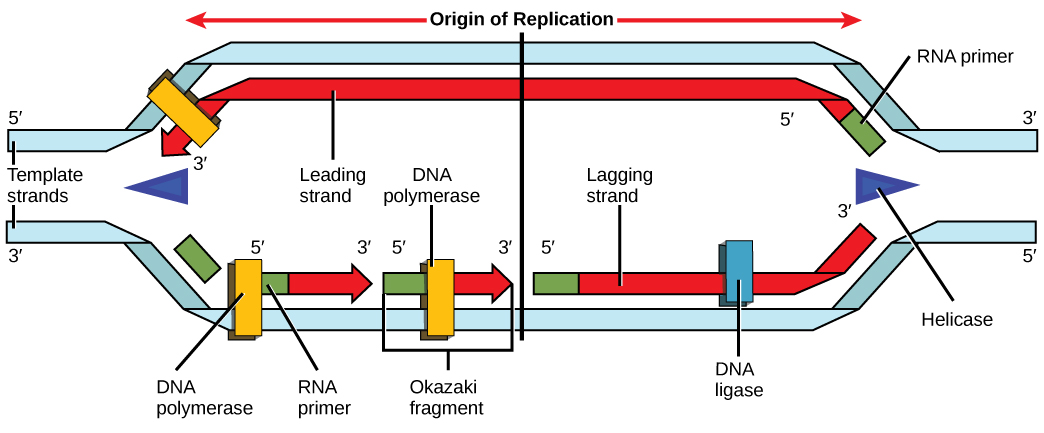
You isolate a cell strain in which the joining together of Okazaki fragments is impaired and suspect that a mutation has occurred in an enzyme found at the replication fork. Which enzyme is most likely to be mutated?
Because eukaryotic chromosomes are linear, DNA replication comes to the end of a line in eukaryotic chromosomes. As you have learned, the DNA polymerase enzyme can add nucleotides in only one direction. In the leading strand, synthesis continues until the end of the chromosome is reached; however, on the lagging strand there is no place for a primer to be made for the DNA fragment to be copied at the end of the chromosome. This presents a problem for the cell because the ends remain unpaired, and over time these ends get progressively shorter as cells continue to divide. The ends of the linear chromosomes are known as telomeres, which have repetitive sequences that do not code for a particular gene. As a consequence, it is telomeres that are shortened with each round of DNA replication instead of genes. For example, in humans, a six base-pair sequence, TTAGGG, is repeated 100 to 1000 times. The discovery of the enzyme telomerase (Figure 8.11) helped in the understanding of how chromosome ends are maintained. The telomerase attaches to the end of the chromosome, and complementary bases to the RNA template are added on the end of the DNA strand. Once the lagging strand template is sufficiently elongated, DNA polymerase can now add nucleotides that are complementary to the ends of the chromosomes. Thus, the ends of the chromosomes are replicated.
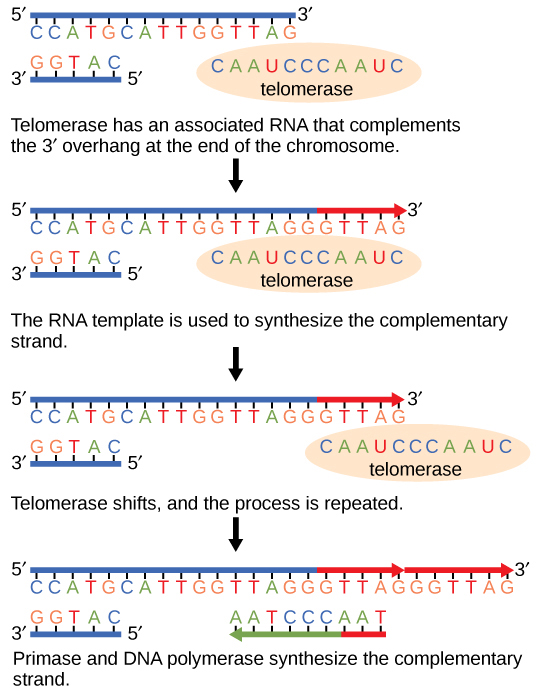
Telomerase is typically found to be active in germ cells, adult stem cells, and some cancer cells. For her discovery of telomerase and its action, Elizabeth Blackburn (Figure 8.12) received the Nobel Prize for Medicine and Physiology in 2009.

Telomerase is not active in adult somatic cells. Adult somatic cells that undergo cell division continue to have their telomeres shortened. This essentially means that telomere shortening is associated with aging. In 2010, scientists found that telomerase can reverse some age-related conditions in mice, and this may have potential in regenerative medicine.1 Telomerase-deficient mice were used in these studies; these mice have tissue atrophy, stem-cell depletion, organ system failure, and impaired tissue injury responses. Telomerase reactivation in these mice caused extension of telomeres, reduced DNA damage, reversed neurodegeneration, and improved functioning of the testes, spleen, and intestines. Thus, telomere reactivation may have potential for treating age-related diseases in humans.
Recall that the prokaryotic chromosome is a circular molecule with a less extensive coiling structure than eukaryotic chromosomes. The eukaryotic chromosome is linear and highly coiled around proteins. While there are many similarities in the DNA replication process, these structural differences necessitate some differences in the DNA replication process in these two life forms.
DNA replication has been extremely well-studied in prokaryotes, primarily because of the small size of the genome and large number of variants available. Escherichia coli has 4.6 million base pairs in a single circular chromosome, and all of it gets replicated in approximately 42 minutes, starting from a single origin of replication and proceeding around the chromosome in both directions. This means that approximately 1000 nucleotides are added per second. The process is much more rapid than in eukaryotes. The table below summarizes the differences between prokaryotic and eukaryotic replications.
| Property | Prokaryotes | Eukaryotes |
|---|---|---|
| Origin of replication | Single | Multiple |
| Rate of replication | 1000 nucleotides/s | 50 to 100 nucleotides/s |
| Chromosome structure | circular | linear |
| Telomerase | Not present | Present |
DNA polymerase can make mistakes while adding nucleotides. It edits the DNA by proofreading every newly added base. Incorrect bases are removed and replaced by the correct base, and then polymerization continues (Figure 8.13 a). Most mistakes are corrected during replication, although when this does not happen, the mismatch repair mechanism is employed. Mismatch repair enzymes recognize the wrongly incorporated base and excise it from the DNA, replacing it with the correct base (Figure 8.13 b). In yet another type of repair, nucleotide excision repair, the DNA double strand is unwound and separated, the incorrect bases are removed along with a few bases on the 5′ and 3′ end, and these are replaced by copying the template with the help of DNA polymerase (Figure 8.13 c). Nucleotide excision repair is particularly important in correcting thymine dimers, which are primarily caused by ultraviolet light. In a thymine dimer, two thymine nucleotides adjacent to each other on one strand are covalently bonded to each other rather than their complementary bases. If the dimer is not removed and repaired it will lead to a mutation. Individuals with flaws in their nucleotide excision repair genes show extreme sensitivity to sunlight and develop skin cancers early in life.
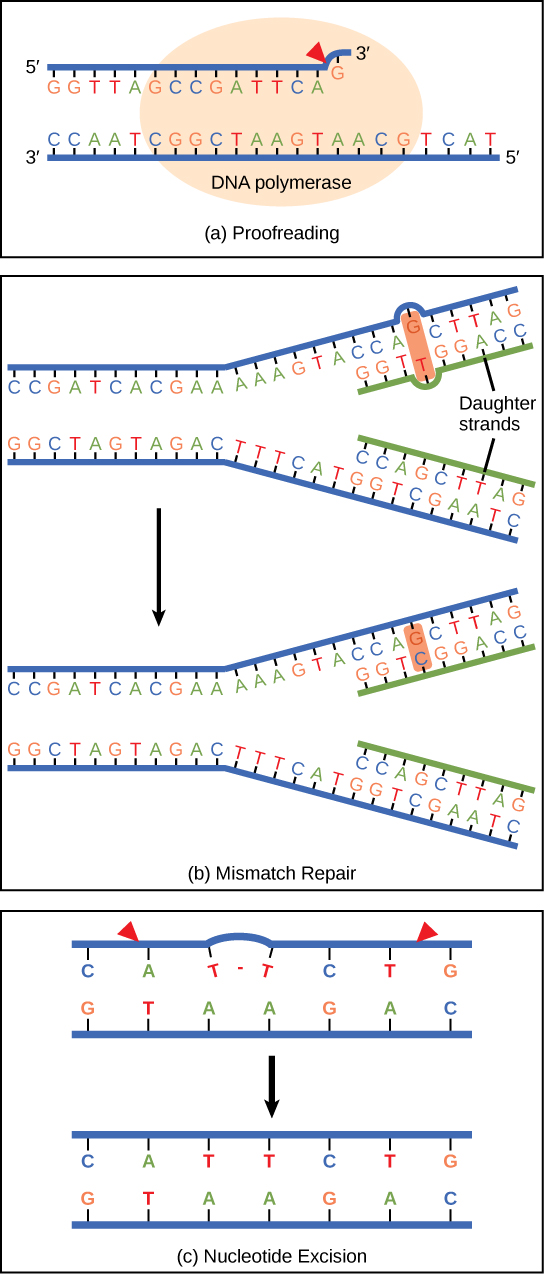
Most mistakes are corrected; if they are not, they may result in a mutation—defined as a permanent change in the DNA sequence. Mutations in repair genes may lead to serious consequences like cancer.
DNA replicates by a semi-conservative method in which each of the two parental DNA strands act as a template for new DNA to be synthesized. After replication, each DNA has one parental or “old” strand, and one daughter or “new” strand.
Replication in eukaryotes starts at multiple origins of replication, while replication in prokaryotes starts from a single origin of replication. The DNA is opened with enzymes, resulting in the formation of the replication fork. Primase synthesizes an RNA primer to initiate synthesis by DNA polymerase, which can add nucleotides in only one direction. One strand is synthesized continuously in the direction of the replication fork; this is called the leading strand. The other strand is synthesized in a direction away from the replication fork, in short stretches of DNA known as Okazaki fragments. This strand is known as the lagging strand. Once replication is completed, the RNA primers are replaced by DNA nucleotides and the DNA is sealed with DNA ligase.
The ends of eukaryotic chromosomes pose a problem, as polymerase is unable to extend them without a primer. Telomerase, an enzyme with an inbuilt RNA template, extends the ends by copying the RNA template and extending one end of the chromosome. DNA polymerase can then extend the DNA using the primer. In this way, the ends of the chromosomes are protected. Cells have mechanisms for repairing DNA when it becomes damaged or errors are made in replication. These mechanisms include mismatch repair to replace nucleotides that are paired with a non-complementary base and nucleotide excision repair, which removes bases that are damaged such as thymine dimers.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=270#h5p-52
DNA ligase: the enzyme that catalyzes the joining of DNA fragments together
DNA polymerase: an enzyme that synthesizes a new strand of DNA complementary to a template strand
helicase: an enzyme that helps to open up the DNA helix during DNA replication by breaking the hydrogen bonds
lagging strand: during replication of the 3′ to 5′ strand, the strand that is replicated in short fragments and away from the replication fork
leading strand: the strand that is synthesized continuously in the 5′ to 3′ direction that is synthesized in the direction of the replication fork
mismatch repair: a form of DNA repair in which non-complementary nucleotides are recognized, excised, and replaced with correct nucleotides
mutation: a permanent variation in the nucleotide sequence of a genome
nucleotide excision repair: a form of DNA repair in which the DNA molecule is unwound and separated in the region of the nucleotide damage, the damaged nucleotides are removed and replaced with new nucleotides using the complementary strand, and the DNA strand is resealed and allowed to rejoin its complement
Okazaki fragments: the DNA fragments that are synthesized in short stretches on the lagging strand
primer: a short stretch of RNA nucleotides that is required to initiate replication and allow DNA polymerase to bind and begin replication
replication fork: the Y-shaped structure formed during the initiation of replication
semiconservative replication: the method used to replicate DNA in which the double-stranded molecule is separated and each strand acts as a template for a new strand to be synthesized, so the resulting DNA molecules are composed of one new strand of nucleotides and one old strand of nucleotides
telomerase: an enzyme that contains a catalytic part and an inbuilt RNA template; it functions to maintain telomeres at chromosome ends
telomere: the DNA at the end of linear chromosomes
1 Mariella Jaskelioff, et al., “Telomerase reactivation reverses tissue degeneration in aged telomerase-deficient mice,” Nature, 469 (2011):102–7.
Chapter 9 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
In both prokaryotes and eukaryotes, the second function of DNA (the first was replication) is to provide the information needed to construct the proteins necessary so that the cell can perform all of its functions. To do this, the DNA is “read” or transcribed into an mRNA molecule. The mRNA then provides the code to form a protein by a process called translation. Through the processes of transcription and translation, a protein is built with a specific sequence of amino acids that was originally encoded in the DNA. This module discusses the details of transcription.
The flow of genetic information in cells from DNA to mRNA to protein is described by the central dogma (Figure 8.14), which states that genes specify the sequences of mRNAs, which in turn specify the sequences of proteins.
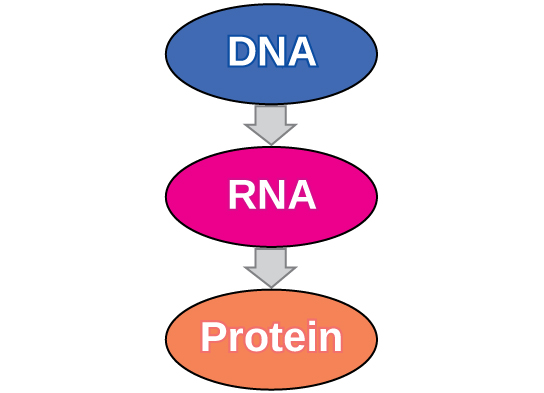
The copying of DNA to mRNA is relatively straightforward, with one nucleotide being added to the mRNA strand for every complementary nucleotide read in the DNA strand. The translation to protein is more complex because groups of three mRNA nucleotides correspond to one amino acid of the protein sequence. However, as we shall see in the next module, the translation to protein is still systematic, such that nucleotides 1 to 3 correspond to amino acid 1, nucleotides 4 to 6 correspond to amino acid 2, and so on.
Both prokaryotes and eukaryotes perform fundamentally the same process of transcription, with the important difference of the membrane-bound nucleus in eukaryotes. With the genes bound in the nucleus, transcription occurs in the nucleus of the cell and the mRNA transcript must be transported to the cytoplasm. The prokaryotes, which include bacteria and archaea, lack membrane-bound nuclei and other organelles, and transcription occurs in the cytoplasm of the cell. In both prokaryotes and eukaryotes, transcription occurs in three main stages: initiation, elongation, and termination.
Transcription requires the DNA double helix to partially unwind in the region of mRNA synthesis. The region of unwinding is called a transcription bubble. The DNA sequence onto which the proteins and enzymes involved in transcription bind to initiate the process is called a promoter. In most cases, promoters exist upstream of the genes they regulate. The specific sequence of a promoter is very important because it determines whether the corresponding gene is transcribed all of the time, some of the time, or hardly at all (Figure 8.15).
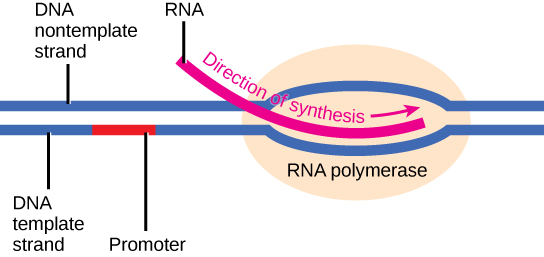
Transcription always proceeds from one of the two DNA strands, which is called the template strand. The mRNA product is complementary to the template strand and is almost identical to the other DNA strand, called the nontemplate strand, with the exception that RNA contains a uracil (U) in place of the thymine (T) found in DNA. During elongation, an enzyme called RNA polymerase proceeds along the DNA template adding nucleotides by base pairing with the DNA template in a manner similar to DNA replication, with the difference that an RNA strand is being synthesized that does not remain bound to the DNA template. As elongation proceeds, the DNA is continuously unwound ahead of the core enzyme and rewound behind it (Figure 8.16).
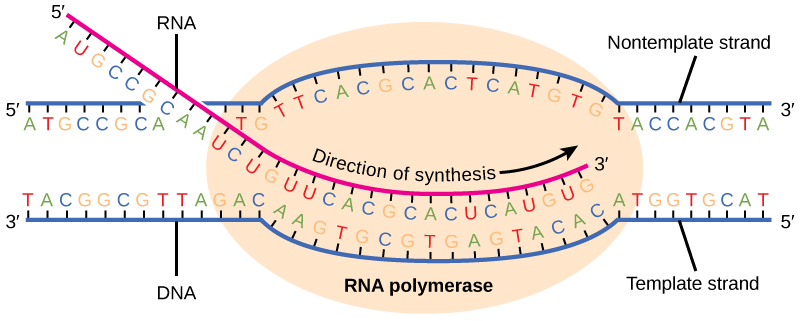
Once a gene is transcribed, the prokaryotic polymerase needs to be instructed to dissociate from the DNA template and liberate the newly made mRNA. Depending on the gene being transcribed, there are two kinds of termination signals, but both involve repeated nucleotide sequences in the DNA template that result in RNA polymerase stalling, leaving the DNA template, and freeing the mRNA transcript.
On termination, the process of transcription is complete. In a prokaryotic cell, by the time termination occurs, the transcript would already have been used to partially synthesize numerous copies of the encoded protein because these processes can occur concurrently using multiple ribosomes (polyribosomes) (Figure 8.17). In contrast, the presence of a nucleus in eukaryotic cells precludes simultaneous transcription and translation.
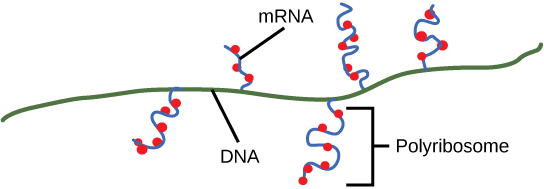
The newly transcribed eukaryotic mRNAs must undergo several processing steps before they can be transferred from the nucleus to the cytoplasm and translated into a protein. The additional steps involved in eukaryotic mRNA maturation create a molecule that is much more stable than a prokaryotic mRNA. For example, eukaryotic mRNAs last for several hours, whereas the typical prokaryotic mRNA lasts no more than five seconds.
The mRNA transcript is first coated in RNA-stabilizing proteins to prevent it from degrading while it is processed and exported out of the nucleus. This occurs while the pre-mRNA still is being synthesized by adding a special nucleotide “cap” to the 5′ end of the growing transcript. In addition to preventing degradation, factors involved in protein synthesis recognize the cap to help initiate translation by ribosomes.
Once elongation is complete, an enzyme then adds a string of approximately 200 adenine residues to the 3′ end, called the poly-A tail. This modification further protects the pre-mRNA from degradation and signals to cellular factors that the transcript needs to be exported to the cytoplasm.
Eukaryotic genes are composed of protein-coding sequences called exons (ex-on signifies that they are expressed) and intervening sequences called introns (int-ron denotes their intervening role). Introns are removed from the pre-mRNA during processing. Intron sequences in mRNA do not encode functional proteins. It is essential that all of a pre-mRNA’s introns be completely and precisely removed before protein synthesis so that the exons join together to code for the correct amino acids. If the process errs by even a single nucleotide, the sequence of the rejoined exons would be shifted, and the resulting protein would be nonfunctional. The process of removing introns and reconnecting exons is called splicing (Figure 8.18). Introns are removed and degraded while the pre-mRNA is still in the nucleus.
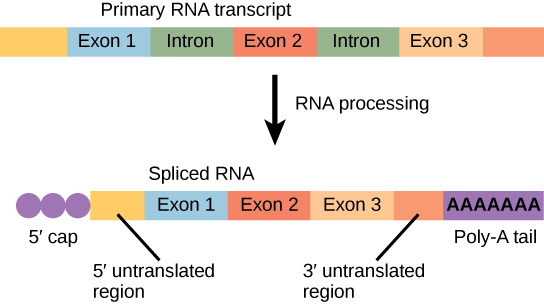
In prokaryotes, mRNA synthesis is initiated at a promoter sequence on the DNA template. Elongation synthesizes new mRNA. Termination liberates the mRNA and occurs by mechanisms that stall the RNA polymerase and cause it to fall off the DNA template. Newly transcribed eukaryotic mRNAs are modified with a cap and a poly-A tail. These structures protect the mature mRNA from degradation and help export it from the nucleus. Eukaryotic mRNAs also undergo splicing, in which introns are removed and exons are reconnected with single-nucleotide accuracy. Only finished mRNAs are exported from the nucleus to the cytoplasm.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=277#h5p-53
exon: a sequence present in protein-coding mRNA after completion of pre-mRNA splicing
intron: non–protein-coding intervening sequences that are spliced from mRNA during processing
mRNA: messenger RNA; a form of RNA that carries the nucleotide sequence code for a protein sequence that is translated into a polypeptide sequence
nontemplate strand: the strand of DNA that is not used to transcribe mRNA; this strand is identical to the mRNA except that T nucleotides in the DNA are replaced by U nucleotides in the mRNA
promoter: a sequence on DNA to which RNA polymerase and associated factors bind and initiate transcription
RNA polymerase: an enzyme that synthesizes an RNA strand from a DNA template strand
splicing: the process of removing introns and reconnecting exons in a pre-mRNA
template strand: the strand of DNA that specifies the complementary mRNA molecule
transcription bubble: the region of locally unwound DNA that allows for transcription of mRNA
Chapter 9 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
The synthesis of proteins is one of a cell’s most energy-consuming metabolic processes. In turn, proteins account for more mass than any other component of living organisms (with the exception of water), and proteins perform a wide variety of the functions of a cell. The process of translation, or protein synthesis, involves decoding an mRNA message into a polypeptide product. Amino acids are covalently strung together in lengths ranging from approximately 50 amino acids to more than 1,000.
In addition to the mRNA template, many other molecules contribute to the process of translation. The composition of each component may vary across species; for instance, ribosomes may consist of different numbers of ribosomal RNAs (rRNA) and polypeptides depending on the organism. However, the general structures and functions of the protein synthesis machinery are comparable from bacteria to human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors (Figure 8.19).
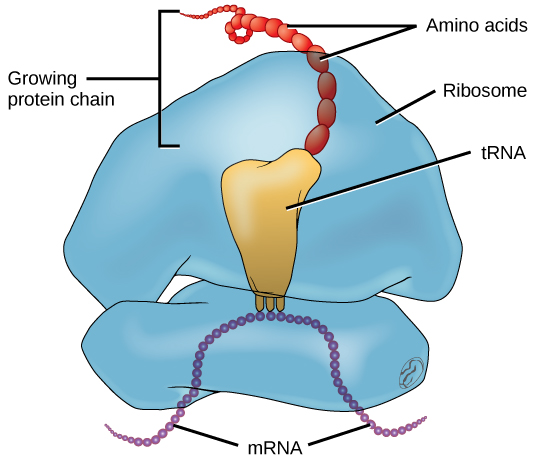
In E. coli, there are 200,000 ribosomes present in every cell at any given time. A ribosome is a complex macromolecule composed of structural and catalytic rRNAs, and many distinct polypeptides. In eukaryotes, the nucleolus is completely specialized for the synthesis and assembly of rRNAs.
Ribosomes are located in the cytoplasm in prokaryotes and in the cytoplasm and endoplasmic reticulum of eukaryotes. Ribosomes are made up of a large and a small subunit that come together for translation. The small subunit is responsible for binding the mRNA template, whereas the large subunit sequentially binds tRNAs, a type of RNA molecule that brings amino acids to the growing chain of the polypeptide. Each mRNA molecule is simultaneously translated by many ribosomes, all synthesizing protein in the same direction.
Depending on the species, 40 to 60 types of tRNA exist in the cytoplasm. Serving as adaptors, specific tRNAs bind to sequences on the mRNA template and add the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins. For each tRNA to function, it must have its specific amino acid bonded to it. In the process of tRNA “charging,” each tRNA molecule is bonded to its correct amino acid.
Universality of the Genetic Code
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=283#h5p-54
Mutations
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=283#h5p-55
To summarize what we know to this point, the cellular process of transcription generates messenger RNA (mRNA), a mobile molecular copy of one or more genes with an alphabet of A, C, G, and uracil (U). Translation of the mRNA template converts nucleotide-based genetic information into a protein product. Protein sequences consist of 20 commonly occurring amino acids; therefore, it can be said that the protein alphabet consists of 20 letters. Each amino acid is defined by a three-nucleotide sequence called the triplet codon. The relationship between a nucleotide codon and its corresponding amino acid is called the genetic code.
Given the different numbers of “letters” in the mRNA and protein “alphabets,” combinations of nucleotides corresponded to single amino acids. Using a three-nucleotide code means that there are a total of 64 (4 × 4 × 4) possible combinations; therefore, a given amino acid is encoded by more than one nucleotide triplet (Figure 8.20).
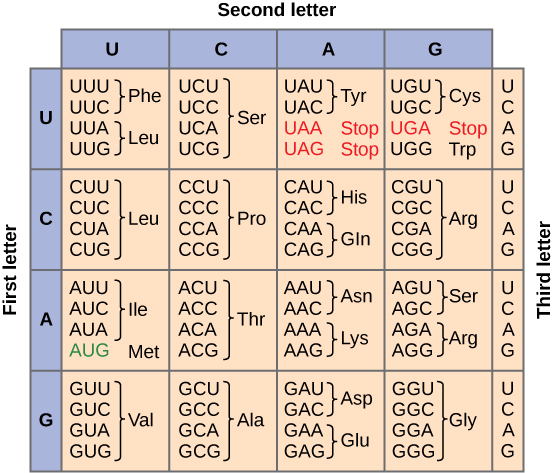
Three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery. These triplets are called stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5′ end of the mRNA. The genetic code is universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all life on Earth shares a common origin.
Just as with mRNA synthesis, protein synthesis can be divided into three phases: initiation, elongation, and termination. The process of translation is similar in prokaryotes and eukaryotes. Here we will explore how translation occurs in E. coli, a representative prokaryote, and specify any differences between prokaryotic and eukaryotic translation.
Protein synthesis begins with the formation of an initiation complex. In E. coli, this complex involves the small ribosome subunit, the mRNA template, three initiation factors, and a special initiator tRNA. The initiator tRNA interacts with the AUG start codon, and links to a special form of the amino acid methionine that is typically removed from the polypeptide after translation is complete.
In prokaryotes and eukaryotes, the basics of polypeptide elongation are the same, so we will review elongation from the perspective of E. coli. The large ribosomal subunit of E. coli consists of three compartments: the A site binds incoming charged tRNAs (tRNAs with their attached specific amino acids). The P site binds charged tRNAs carrying amino acids that have formed bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E site releases dissociated tRNAs so they can be recharged with free amino acids. The ribosome shifts one codon at a time, catalyzing each process that occurs in the three sites. With each step, a charged tRNA enters the complex, the polypeptide becomes one amino acid longer, and an uncharged tRNA departs. The energy for each bond between amino acids is derived from GTP, a molecule similar to ATP (Figure 8.21). Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200-amino acid polypeptide could be translated in just 10 seconds.
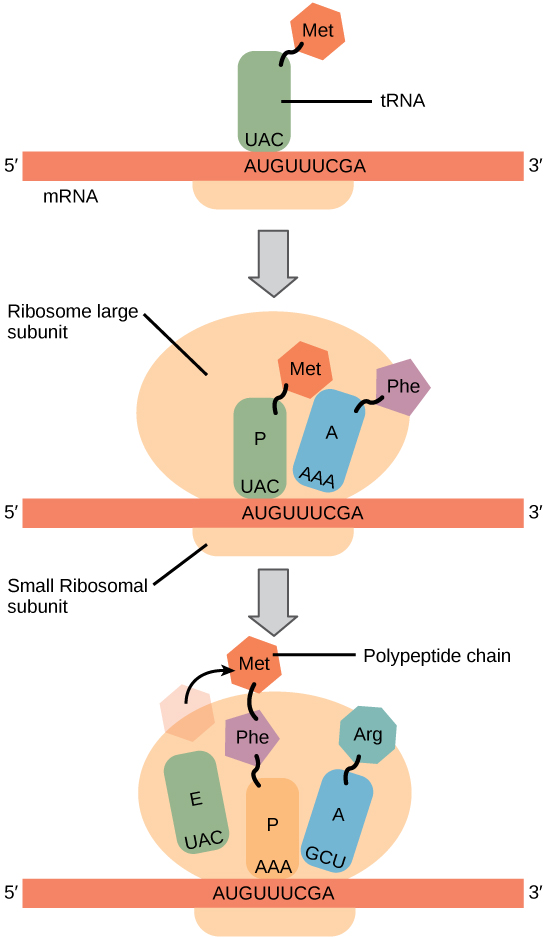
Termination of translation occurs when a stop codon (UAA, UAG, or UGA) is encountered. When the ribosome encounters the stop codon, the growing polypeptide is released and the ribosome subunits dissociate and leave the mRNA. After many ribosomes have completed translation, the mRNA is degraded so the nucleotides can be reused in another transcription reaction.

Transcribe a gene and translate it to protein using complementary pairing and the genetic code at this site.
The central dogma describes the flow of genetic information in the cell from genes to mRNA to proteins. Genes are used to make mRNA by the process of transcription; mRNA is used to synthesize proteins by the process of translation. The genetic code is the correspondence between the three-nucleotide mRNA codon and an amino acid. The genetic code is “translated” by the tRNA molecules, which associate a specific codon with a specific amino acid. The genetic code is degenerate because 64 triplet codons in mRNA specify only 20 amino acids and three stop codons. This means that more than one codon corresponds to an amino acid. Almost every species on the planet uses the same genetic code.
The players in translation include the mRNA template, ribosomes, tRNAs, and various enzymatic factors. The small ribosomal subunit binds to the mRNA template. Translation begins at the initiating AUG on the mRNA. The formation of bonds occurs between sequential amino acids specified by the mRNA template according to the genetic code. The ribosome accepts charged tRNAs, and as it steps along the mRNA, it catalyzes bonding between the new amino acid and the end of the growing polypeptide. The entire mRNA is translated in three-nucleotide “steps” of the ribosome. When a stop codon is encountered, a release factor binds and dissociates the components and frees the new protein.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=283#h5p-56
codon: three consecutive nucleotides in mRNA that specify the addition of a specific amino acid or the release of a polypeptide chain during translation
genetic code: the amino acids that correspond to three-nucleotide codons of mRNA
rRNA: ribosomal RNA; molecules of RNA that combine to form part of the ribosome
stop codon: one of the three mRNA codons that specifies termination of translation
start codon: the AUG (or, rarely GUG) on an mRNA from which translation begins; always specifies methionine
tRNA: transfer RNA; an RNA molecule that contains a specific three-nucleotide anticodon sequence to pair with the mRNA codon and also binds to a specific amino acid
Chapter 9 in Concepts of Biology: 1st Canadian Edition
By the end of this section, you will be able to:
For a cell to function properly, necessary proteins must be synthesized at the proper time. All organisms and cells control or regulate the transcription and translation of their DNA into protein. The process of turning on a gene to produce RNA and protein is called gene expression. Whether in a simple unicellular organism or in a complex multicellular organism, each cell controls when and how its genes are expressed. For this to occur, there must be a mechanism to control when a gene is expressed to make RNA and protein, how much of the protein is made, and when it is time to stop making that protein because it is no longer needed.
Cells in multicellular organisms are specialized; cells in different tissues look very different and perform different functions. For example, a muscle cell is very different from a liver cell, which is very different from a skin cell. These differences are a consequence of the expression of different sets of genes in each of these cells. All cells have certain basic functions they must perform for themselves, such as converting the energy in sugar molecules into energy in ATP. Each cell also has many genes that are not expressed, and expresses many that are not expressed by other cells, such that it can carry out its specialized functions. In addition, cells will turn on or off certain genes at different times in response to changes in the environment or at different times during the development of the organism. Unicellular organisms, both eukaryotic and prokaryotic, also turn on and off genes in response to the demands of their environment so that they can respond to special conditions.
The control of gene expression is extremely complex. Malfunctions in this process are detrimental to the cell and can lead to the development of many diseases, including cancer.
To understand how gene expression is regulated, we must first understand how a gene becomes a functional protein in a cell. The process occurs in both prokaryotic and eukaryotic cells, just in slightly different fashions.
Because prokaryotic organisms lack a cell nucleus, the processes of transcription and translation occur almost simultaneously. When the protein is no longer needed, transcription stops. As a result, the primary method to control what type and how much protein is expressed in a prokaryotic cell is through the regulation of DNA transcription into RNA. All the subsequent steps happen automatically. When more protein is required, more transcription occurs. Therefore, in prokaryotic cells, the control of gene expression is almost entirely at the transcriptional level.
The first example of such control was discovered using E. coli in the 1950s and 1960s by French researchers and is called the lac operon. The lac operon is a stretch of DNA with three adjacent genes that code for proteins that participate in the absorption and metabolism of lactose, a food source for E. coli. When lactose is not present in the bacterium’s environment, the lac genes are transcribed in small amounts. When lactose is present, the genes are transcribed and the bacterium is able to use the lactose as a food source. The operon also contains a promoter sequence to which the RNA polymerase binds to begin transcription; between the promoter and the three genes is a region called the operator. When there is no lactose present, a protein known as a repressor binds to the operator and prevents RNA polymerase from binding to the promoter, except in rare cases. Thus very little of the protein products of the three genes is made. When lactose is present, an end product of lactose metabolism binds to the repressor protein and prevents it from binding to the operator. This allows RNA polymerase to bind to the promoter and freely transcribe the three genes, allowing the organism to metabolize the lactose.
Eukaryotic cells, in contrast, have intracellular organelles and are much more complex. Recall that in eukaryotic cells, the DNA is contained inside the cell’s nucleus and it is transcribed into mRNA there. The newly synthesized mRNA is then transported out of the nucleus into the cytoplasm, where ribosomes translate the mRNA into protein. The processes of transcription and translation are physically separated by the nuclear membrane; transcription occurs only within the nucleus, and translation only occurs outside the nucleus in the cytoplasm. The regulation of gene expression can occur at all stages of the process (Figure 8.22). Regulation may occur when the DNA is uncoiled and loosened from nucleosomes to bind transcription factors (epigenetic level), when the RNA is transcribed (transcriptional level), when RNA is processed and exported to the cytoplasm after it is transcribed (post-transcriptional level), when the RNA is translated into protein (translational level), or after the protein has been made (post-translational level).
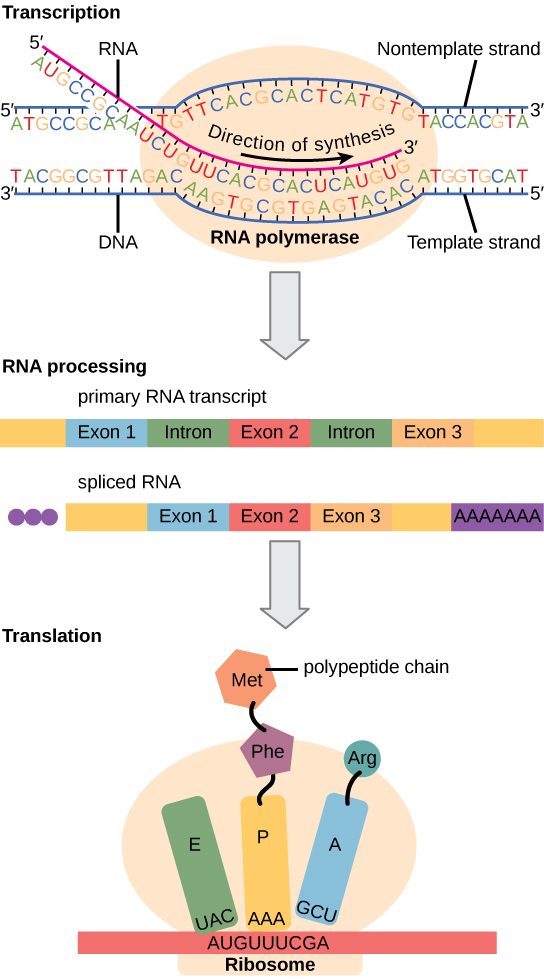
The differences in the regulation of gene expression between prokaryotes and eukaryotes are summarized in the table below.
| Prokaryotic organisms | Eukaryotic organisms |
|---|---|
| Lack nucleus | Contain nucleus |
| RNA transcription and protein translation occur almost simultaneously |
|
| Gene expression is regulated primarily at the transcriptional level | Gene expression is regulated at many levels (epigenetic, transcriptional, post-transcriptional, translational, and post-translational) |
In the 1970s, genes were first observed that exhibited alternative RNA splicing. Alternative RNA splicing is a mechanism that allows different protein products to be produced from one gene when different combinations of introns (and sometimes exons) are removed from the transcript (Figure 8.23). This alternative splicing can be haphazard, but more often it is controlled and acts as a mechanism of gene regulation, with the frequency of different splicing alternatives controlled by the cell as a way to control the production of different protein products in different cells, or at different stages of development. Alternative splicing is now understood to be a common mechanism of gene regulation in eukaryotes; according to one estimate, 70% of genes in humans are expressed as multiple proteins through alternative splicing.
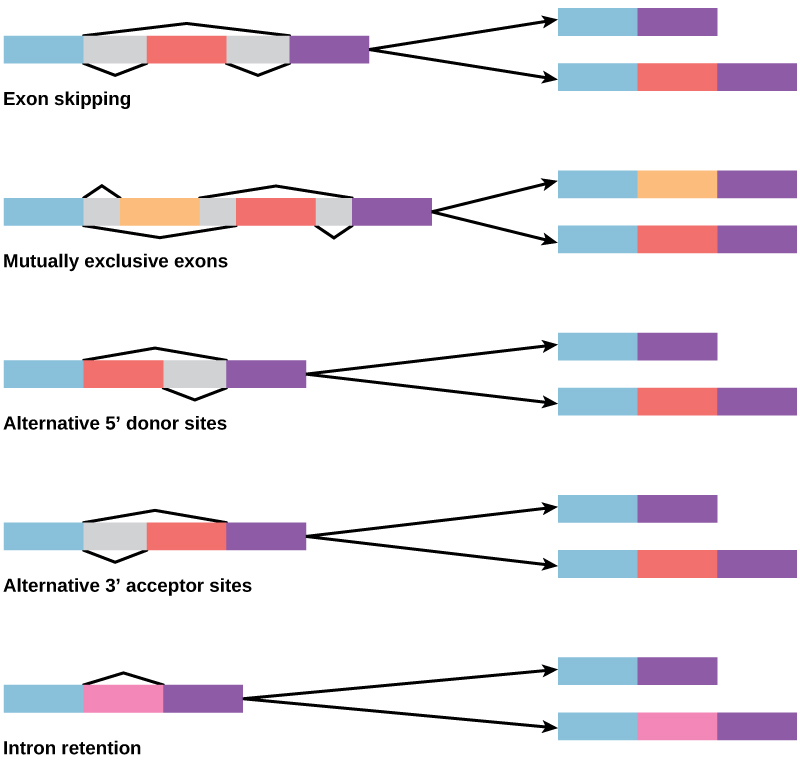
How could alternative splicing evolve? Introns have a beginning and ending recognition sequence, and it is easy to imagine the failure of the splicing mechanism to identify the end of an intron and find the end of the next intron, thus removing two introns and the intervening exon. In fact, there are mechanisms in place to prevent such exon skipping, but mutations are likely to lead to their failure. Such “mistakes” would more than likely produce a nonfunctional protein. Indeed, the cause of many genetic diseases is alternative splicing rather than mutations in a sequence. However, alternative splicing would create a protein variant without the loss of the original protein, opening up possibilities for adaptation of the new variant to new functions. Gene duplication has played an important role in the evolution of new functions in a similar way—by providing genes that may evolve without eliminating the original functional protein.
While all somatic cells within an organism contain the same DNA, not all cells within that organism express the same proteins. Prokaryotic organisms express the entire DNA they encode in every cell, but not necessarily all at the same time. Proteins are expressed only when they are needed. Eukaryotic organisms express a subset of the DNA that is encoded in any given cell. In each cell type, the type and amount of protein is regulated by controlling gene expression. To express a protein, the DNA is first transcribed into RNA, which is then translated into proteins. In prokaryotic cells, these processes occur almost simultaneously. In eukaryotic cells, transcription occurs in the nucleus and is separate from the translation that occurs in the cytoplasm. Gene expression in prokaryotes is regulated only at the transcriptional level, whereas in eukaryotic cells, gene expression is regulated at the epigenetic, transcriptional, post-transcriptional, translational, and post-translational levels.
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=287#h5p-57
alternative RNA splicing: a post-transcriptional gene regulation mechanism in eukaryotes in which multiple protein products are produced by a single gene through alternative splicing combinations of the RNA transcript
epigenetic: describing non-genetic regulatory factors, such as changes in modifications to histone proteins and DNA that control accessibility to genes in chromosomes
gene expression: processes that control whether a gene is expressed
post-transcriptional: control of gene expression after the RNA molecule has been created but before it is translated into protein
post-translational: control of gene expression after a protein has been created
Chapter 9 in Concepts of Biology: 1st Canadian Edition

All living organisms, from bacteria to baboons to blueberries, evolved at some point from a different species. Although it may seem that living things today stay much the same, that is not the case—evolution is an ongoing process.
The theory of evolution is the unifying theory of biology, meaning it is the framework within which biologists ask questions about the living world. Its power is that it provides direction for predictions about living things that are borne out in ongoing experiments. The Ukrainian-born American geneticist Theodosius Dobzhansky famously wrote that “nothing makes sense in biology except in the light of evolution.”1 He meant that the tenet that all life has evolved and diversified from a common ancestor is the foundation from which we approach all questions in biology.
Chapter 18 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Evolution by natural selection describes a mechanism for how species change over time. Scientists, philosophers, researchers, and others had made suggestions and debated this topic well before Darwin began to explore this idea. Classical Greek philosopher Plato emphasized in his writings that species were static and unchanging, yet there were also ancient Greeks who expressed evolutionary ideas. In the eighteenth century, naturalist Georges-Louis Leclerc Comte de Buffon reintroduced ideas about the evolution of animals and observed that various geographic regions have different plant and animal populations, even when the environments are similar. Some at this time also accepted that there were extinct species.
Also during the eighteenth century, James Hutton, a Scottish geologist and naturalist, proposed that geological change occurred gradually by accumulating small changes from processes operating like they are today over long periods of time. This contrasted with the predominant view that the planet’s geology was a consequence of catastrophic events occurring during a relatively brief past. Nineteenth century geologist Charles Lyell popularized Hutton’s view. A friend to Darwin. Lyell’s ideas were influential on Darwin’s thinking: Lyell’s notion of the greater age of Earth gave more time for gradual change in species, and the process of change provided an analogy for this change. In the early nineteenth century, Jean-Baptiste Lamarck published a book that detailed a mechanism for evolutionary change. We now refer to this mechanism as an inheritance of acquired characteristics by which the environment causes modifications in an individual, or offspring could use or disuse of a structure during its lifetime, and thus bring about change in a species. While many discredited this mechanism for evolutionary change, Lamarck’s ideas were an important influence on evolutionary thought.
In the mid-nineteenth century, two naturalists, Charles Darwin and Alfred Russel Wallace, independently conceived and described the actual mechanism for evolution. Importantly, each naturalist spent time exploring the natural world on expeditions to the tropics. From 1831 to 1836, Darwin traveled around the world on H.M.S. Beagle, including stops in South America, Australia, and the southern tip of Africa. Wallace traveled to Brazil to collect insects in the Amazon rainforest from 1848 to 1852 and to the Malay Archipelago from 1854 to 1862. Darwin’s journey, like Wallace’s later journeys to the Malay Archipelago, included stops at several island chains, the last being the Galápagos Islands west of Ecuador. On these islands, Darwin observed species of organisms on different islands that were clearly similar, yet had distinct differences. For example, the ground finches inhabiting the Galápagos Islands comprised several species with a unique beak shape (figure 9.2-1). The species on the islands had a graded series of beak sizes and shapes with very small differences between the most similar. He observed that these finches closely resembled another finch species on the South American mainland. Darwin imagined that the island species might be species modified from one of the original mainland species. Upon further study, he realized that each finch’s varied beaks helped the birds acquire a specific type of food. For example, seed-eating finches had stronger, thicker beaks for breaking seeds, and insect-eating finches had spear-like beaks for stabbing their prey.
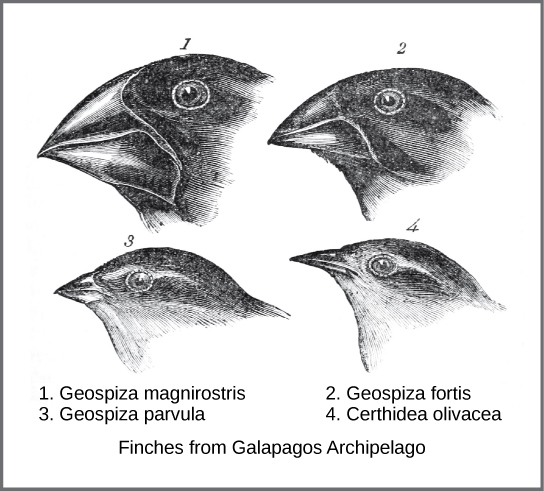
Wallace and Darwin both observed similar patterns in other organisms and they independently developed the same explanation for how and why such changes could take place. Darwin called this mechanism natural selection. Natural selection, or “survival of the fittest,” is the more prolific reproduction of individuals with favorable traits that survive environmental change because of those traits. This leads to evolutionary change.
For example, Darwin observed a population of giant tortoises in the Galápagos Archipelago to have longer necks than those that lived on other islands with dry lowlands. These tortoises were “selected” because they could reach more leaves and access more food than those with short necks. In times of drought when fewer leaves would be available, those that could reach more leaves had a better chance to eat and survive than those that couldn’t reach the food source. Consequently, long-necked tortoises would be more likely to be reproductively successful and pass the long-necked trait to their offspring. Over time, only long-necked tortoises would be present in the population.
Natural selection, Darwin argued, was an inevitable outcome of three principles that operated in nature. First, most characteristics of organisms are inherited, or passed from parent to offspring. Although no one, including Darwin and Wallace, knew how this happened at the time, it was a common understanding. Second, more offspring are produced than are able to survive, so resources for survival and reproduction are limited. The capacity for reproduction in all organisms outstrips the availability of resources to support their numbers. Thus, there is competition for those resources in each generation. Both Darwin and Wallace’s understanding of this principle came from reading economist Thomas Malthus’ essay that explained this principle in relation to human populations. Third, offspring vary among each other in regard to their characteristics and those variations are inherited. Darwin and Wallace reasoned that offspring with inherited characteristics which allow them to best compete for limited resources will survive and have more offspring than those individuals with variations that are less able to compete. Because characteristics are inherited, these traits will be better represented in the next generation. This will lead to change in populations over generations in a process that Darwin called descent with modification. Ultimately, natural selection leads to greater adaptation of the population to its local environment. It is the only mechanism known for adaptive evolution.
In 1858, Darwin and Wallace (Figure 9.2-3) presented papers at the Linnean Society in London that discussed the idea of natural selection. The following year Darwin’s book, On the Origin of Species, was published. His book outlined in considerable detail his arguments for evolution by natural selection.

It is difficult and time-consuming to document and present examples of evolution by natural selection. The Galápagos finches are an excellent example. Peter and Rosemary Grant and their colleagues have studied Galápagos finch populations every year since 1976 and have provided important evidence of natural selection. The Grants found changes from one generation to the next in beak shape distribution with the medium ground finch on the Galápagos island of Daphne Major. The birds have inherited a variation in their bill shape with some having wide deep bills and others having thinner bills. During a period in which rainfall was higher than normal because of an El Niño, there was a lack of large hard seeds of which the large-billed birds ate; however, there was an abundance of the small soft seeds which the small-billed birds ate. Therefore, the small-billed birds were able to survive and reproduce. In the years following this El Niño, the Grants measured beak sizes in the population and found that the average bill size was smaller. Since bill size is an inherited trait, parents with smaller bills had more offspring and the bill evolved into a much smaller size. As conditions improved in 1987 and larger seeds became more available, the trend toward smaller average bill size ceased.
Many people hike, explore caves, scuba dive, or climb mountains for recreation. People often participate in these activities hoping to see wildlife. Experiencing the outdoors can be incredibly enjoyable and invigorating. What if your job entailed working in the wilderness? Field biologists by definition work outdoors in the “field.” The term field in this case refers to any location outdoors, even under water.

One objective of many field biologists includes discovering new, unrecorded species. Not only do such findings expand our understanding of the natural world, but they also lead to important innovations in fields such as medicine and agriculture. Plant and microbial species, in particular, can reveal new medicinal and nutritive knowledge. Other organisms can play key roles in ecosystems or if rare require protection. When discovered, researchers can use these important species as evidence for environmental regulations and laws.
Natural selection can only take place if there is variation, or differences, among individuals in a population. Importantly, these differences must have some genetic basis; otherwise, the selection will not lead to change in the next generation. This is critical because nongenetic reasons can cause variation among individuals such as an individual’s height because of better nutrition rather than different genes.
Genetic diversity in a population comes from two main mechanisms: mutation and sexual reproduction. Mutation, a change in DNA, is the ultimate source of new alleles, or new genetic variation in any population. The genetic changes that mutation causes can have one of three outcomes on the phenotype. A mutation affects the organism’s phenotype in a way that gives it reduced fitness—lower likelihood of survival or fewer offspring. A mutation may produce a phenotype with a beneficial effect on fitness. Many mutations will also have no effect on the phenotype’s fitness. We call these neutral mutations. Mutations may also have a whole range of effect sizes on the organism’s fitness that expresses them in their phenotype, from a small effect to a great effect. Sexual reproduction also leads to genetic diversity: when two parents reproduce, unique combinations of alleles assemble to produce the unique genotypes and thus phenotypes in each offspring.
We call a heritable trait that helps an organism’s survival and reproduction in its present environment an adaptation. Scientists describe groups of organisms adapting to their environment when a genetic variation occurs over time that increases or maintains the population’s “fit” to its environment. A platypus’s webbed feet are an adaptation for swimming. A snow leopard’s thick fur is an adaptation for living in the cold. A cheetah’s fast speed is an adaptation for catching prey.
Whether or not a trait is favorable depends on the current environmental conditions. The same traits are not always selected because environmental conditions can change. For example, consider a plant species that grew in a moist climate and did not need to conserve water. Large leaves were selected because they allowed the plant to obtain more energy from the sun. Large leaves require more water to maintain than small leaves, and the moist environment provided favorable conditions to support large leaves. After thousands of years, the climate changed, and the area no longer had excess water. The direction of natural selection shifted so that plants with small leaves were selected because those populations were able to conserve water to survive the new environmental conditions.
The evolution of species has resulted in enormous variation in form and function. Sometimes, evolution gives rise to groups of organisms that become tremendously different from each other. We call two species that evolve in diverse directions from a common point divergent evolution. We can see such divergent evolution in the forms of the reproductive organs of flowering plants which share the same basic anatomies; however, they can look very different as a result of selection in different physical environments and adaptation to different kinds of pollinators (Figure 9.2-5).

In other cases, similar phenotypes evolve independently in distantly related species. For example, flight has evolved in both bats and insects, and they both have structures we refer to as wings, which are adaptations to flight. However, bat and insect wings have evolved from very different original structures. We call this phenomenon convergent evolution, where similar traits evolve independently in species that do not share a common ancestry. The two species came to the same function, flying, but did so separately from each other.
These physical changes occur over enormous time spans and help explain how evolution occurs. Natural selection acts on individual organisms, which can then shape an entire species. Although natural selection may work in a single generation on an individual, it can take thousands or even millions of years for an entire species’ genotype to evolve. It is over these large time spans that life on earth has changed and continues to change.
The evidence for evolution is compelling and extensive. Looking at every level of organization in living systems, biologists see the signature of past and present evolution. Darwin dedicated a large portion of his book, On the Origin of Species, to identifying patterns in nature that were consistent with evolution, and since Darwin, our understanding has become clearer and broader.
Fossils provide solid evidence that organisms from the past are not the same as those today, and fossils show a progression of evolution. Scientists determine the age of fossils and categorize them from all over the world to determine when the organisms lived relative to each other. The resulting fossil record tells the story of the past and shows the evolution of form over millions of years ((Figure)). For example, scientists have recovered highly detailed records showing the evolution of humans and horses (Figure 9.2-6). The whale flipper shares a similar morphology to bird and mammal appendages (Figure 9.2-6) indicating that these species share a common ancestor.

Another type of evidence for evolution is the presence of structures in organisms that share the same basic form. For example, the bones in human, dog, bird, and whale appendages all share the same overall construction (Figure 9.2-7) resulting from their origin in a common ancestor’s appendages. Over time, evolution led to changes in the bones’ shapes and sizes different species, but they have maintained the same overall layout. Scientists call these synonymous parts homologous structures.
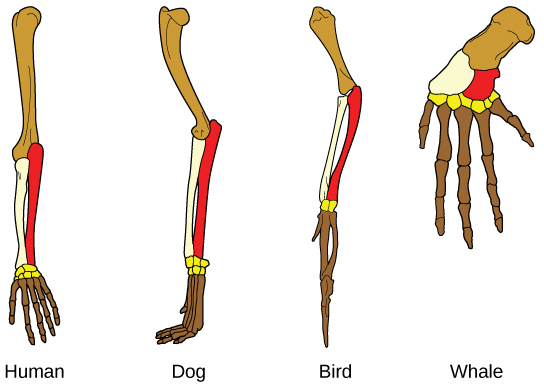
Some structures exist in organisms that have no apparent function at all, and appear to be residual parts from a past common ancestor. We call these unused structures without function vestigial structures. Other examples of vestigial structures are wings on flightless birds, leaves on some cacti, and hind leg bones in whales.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=320
Another evidence of evolution is the convergence of form in organisms that share similar environments. For example, species of unrelated animals, such as the arctic fox and ptarmigan, living in the arctic region have been selected for seasonal white phenotypes during winter to blend with the snow and ice (Figure 9.2-8). These similarities occur not because of common ancestry, but because of similar selection pressures—the benefits of predators not seeing them.

Embryology, the study of the anatomy of an organism’s development to its adult form, also provides evidence of relatedness between now widely divergent groups of organisms. Mutational tweaking in the embryo can have such magnified consequences in the adult that tends to conserve embryo formation. As a result, structures that are absent in some groups often appear in their embryonic forms and disappear when they reach the adult or juvenile form. For example, all vertebrate embryos, including humans, exhibit gill slits and tails at some point in their early development. These disappear in the adults of terrestrial groups but adult forms of aquatic groups such as fish and some amphibians maintain them. Great ape embryos, including humans, have a tail structure during their development that they lose when they are born.
The geographic distribution of organisms on the planet follows patterns that we can explain best by evolution in conjunction with tectonic plate movement over geological time. Broad groups that evolved before the supercontinent Pangaea broke up (about 200 million years ago) are distributed worldwide. Groups that evolved since the breakup appear uniquely in regions of the planet, such as the unique flora and fauna of northern continents that formed from the supercontinent Laurasia and of the southern continents that formed from the supercontinent Gondwana. The presence of members of the plant family Proteaceae in Australia, southern Africa, and South America was most predominant prior to the southern supercontinent Gondwana breaking up.
Marsupial diversification in Australia and the absence of other mammals reflect Australia’s long isolation. Australia has an abundance of endemic species—species found nowhere else—which is typical of islands whose isolation by expanses of water prevents species to migrate. Over time, these species diverge evolutionarily into new species that look very different from their ancestors that may exist on the mainland. Australia’s marsupials, the Galápagos’ finches, and many species on the Hawaiian Islands are all unique to their one point of origin, yet they display distant relationships to ancestral species on mainlands.
Like anatomical structures, the molecular structures of life reflect descent with modification. DNA’s universality reflects evidence of a common ancestor for all of life. Fundamental divisions in life between the genetic code, DNA replication, and expression are reflected in major structural differences in otherwise conservative structures such as ribosome components and membrane structures. In general, the relatedness of groups of organisms is reflected in the similarity of their DNA sequences—exactly the pattern that we would expect from descent and diversification from a common ancestor.
DNA sequences have also shed light on some of the mechanisms of evolution. For example, it is clear that the evolution of new functions for proteins commonly occurs after gene duplication events that allow freely modifying one copy by mutation, selection, or drift (changes in a population’s gene pool resulting from chance), while the second copy continues to produce a functional protein.
Although the theory of evolution generated some controversy when Darwin first proposed it, biologists almost universally accepted it, particularly younger biologists, within 20 years after publication of On the Origin of Species. Nevertheless, the theory of evolution is a difficult concept and misconceptions about how it works abound.
The website Understanding Evolution addresses some of the main misconceptions associated with the theory of evolution.
Critics of the theory of evolution dismiss its importance by purposefully confounding the everyday usage of the word “theory” with the way scientists use the word. In science, we understand a “theory” to be a body of thoroughly tested and verified explanations for a set of observations of the natural world. Scientists have a theory of the atom, a theory of gravity, and the theory of relativity, each which describes understood facts about the world. In the same way, the theory of evolution describes facts about the living world. As such, a theory in science has survived significant efforts to discredit it by scientists. In contrast, a “theory” in common vernacular is a word meaning a guess or suggested explanation. This meaning is more akin to the scientific concept of “hypothesis.” When critics of evolution say it is “just a theory,” they are implying that there is little evidence supporting it and that it is still in the process of rigorous testing. This is a mischaracterization.
Evolution is the change in a population’s genetic composition over time, specifically over generations, resulting from differential reproduction of individuals with certain alleles. Individuals do change over their lifetime, obviously, but this is development and involves changes programmed by the set of genes the individual acquired at birth in coordination with the individual’s environment. When thinking about the evolution of a characteristic, it is probably best to think about the change of the average value of the characteristic in the population over time. For example, when natural selection leads to bill-size change in medium ground finches in the Galápagos, this does not mean that individual bills on the finches are changing. If one measures the average bill size among all individuals in the population at one time and then measures them in the population several years later, this average value will be different as a result of evolution. Although some individuals may survive from the first time to the second, they will still have the same bill size; however, there will be many new individuals who contribute to the shift in average bill size.
It is a common misunderstanding that evolution includes an explanation of life’s origins. Conversely, some of the theory’s critics believe that it cannot explain the origin of life. The theory does not try to explain the origin of life. The theory of evolution explains how populations change over time and how life diversifies the origin of species. It does not shed light on the beginnings of life including the origins of the first cells, which define life. Importantly, biologists believe that the presence of life on Earth precludes the possibility that the events that led to life on Earth can repeat themselves because the intermediate stages would immediately become food for existing living things.
However, once a mechanism of inheritance was in place in the form of a molecule like DNA either within a cell or pre-cell, these entities would be subject to the principle of natural selection. More effective reproducers would increase in frequency at the expense of inefficient reproducers. While evolution does not explain the origin of life, it may have something to say about some of the processes operating once pre-living entities acquired certain properties.
Statements such as “organisms evolve in response to a change in an environment” are quite common, but such statements can lead to two types of misunderstandings. First, do not interpret the statement to mean that individual organisms evolve. The statement is shorthand for “a population evolves in response to a changing environment.” However, a second misunderstanding may arise by interpreting the statement to mean that the evolution is somehow intentional. A changed environment results in some individuals in the population, those with particular phenotypes, benefiting and therefore producing proportionately more offspring than other phenotypes. This results in change in the population if the characteristics are genetically determined.
It is also important to understand that the variation that natural selection works on is already in a population and does not arise in response to an environmental change. For example, applying antibiotics to a population of bacteria will, over time, select a population of bacteria that are resistant to antibiotics. The resistance, which a gene causes, did not arise by mutation because of applying the antibiotic. The gene for resistance was already present in the bacteria’s gene pool, likely at a low frequency. The antibiotic, which kills the bacterial cells without the resistance gene, strongly selects individuals that are resistant, since these would be the only ones that survived and divided. Experiments have demonstrated that mutations for antibiotic resistance do not arise as a result of antibiotic.
In a larger sense, evolution is not goal directed. Species do not become “better” over time. They simply track their changing environment with adaptations that maximize their reproduction in a particular environment at a particular time. Evolution has no goal of making faster, bigger, more complex, or even smarter species, despite the commonness of this kind of language in popular discourse. What characteristics evolve in a species are a function of the variation present and the environment, both of which are constantly changing in a nondirectional way. A trait that fits in one environment at one time may well be fatal at some point in the future. This holds equally well for insect and human species.
Evolution is the process of adaptation through mutation which allows more desirable characteristics to pass to the next generation. Over time, organisms evolve more characteristics that are beneficial to their survival. For living organisms to adapt and change to environmental pressures, genetic variation must be present. With genetic variation, individuals have differences in form and function that allow some to survive certain conditions better than others. These organisms pass their favorable traits to their offspring. Eventually, environments change, and what was once a desirable, advantageous trait may become an undesirable trait and organisms may further evolve. Evolution may be convergent with similar traits evolving in multiple species or divergent with diverse traits evolving in multiple species that came from a common ancestor. We can observe evidence of evolution by means of DNA code and the fossil record, and also by the existence of homologous and vestigial structures.
Exercises
Review Questions
Which scientific concept did Charles Darwin and Alfred Wallace independently discover?
Which of the following situations will lead to natural selection?
Which description is an example of a phenotype?
Which situation is most likely an example of convergent evolution?
Critical Thinking Questions
How does the scientific meaning of “theory” differ from the common vernacular meaning?
Explain why the statement that a monkey is more evolved than a mouse is incorrect.
Glossary
Creation Note: Chapter 18 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Although all life on earth shares various genetic similarities, only certain organisms combine genetic information by sexual reproduction and have offspring that can then successfully reproduce. Scientists call such organisms members of the same biological species.
A species is a group of individual organisms that interbreed and produce fertile, viable offspring. According to this definition, one species is distinguished from another when, in nature, it is not possible for matings between individuals from each species to produce fertile offspring.
Members of the same species share both external and internal characteristics, which develop from their DNA. The closer relationship two organisms share, the more DNA they have in common, just like people and their families. People’s DNA is likely to be more like their father or mother’s DNA than their cousin or grandparent’s DNA. Organisms of the same species have the highest level of DNA alignment and therefore share characteristics and behaviors that lead to successful reproduction.
Species’ appearance can be misleading in suggesting an ability or inability to mate. For example, even though domestic dogs (Canis lupus familiaris) display phenotypic differences, such as size, build, and coat, most dogs can interbreed and produce viable puppies that can mature and sexually reproduce (Figure 9.3 – 9).

In other cases, individuals may appear similar although they are not members of the same species. For example, even though bald eagles (Haliaeetus leucocephalus) and African fish eagles (Haliaeetus vocifer) are both birds and eagles, each belongs to a separate species group (Figure 9.3-10). If humans were to artificially intervene and fertilize a bald eagle’s egg with an African fish eagle’s sperm and a chick did hatch, that offspring, called a hybrid (a cross between two species), would probably be infertile—unable to successfully reproduce after it reached maturity. Different species may have different genes that are active in development; therefore, it may not be possible to develop a viable offspring with two different sets of directions. Thus, even though hybridization may take place, the two species still remain separate.

Populations of species share a gene pool: a collection of all the gene variants in the species. Again, the basis to any changes in a group or population of organisms must be genetic for this is the only way to share and pass on traits. When variations occur within a species, they can only pass to the next generation along two main pathways: asexual reproduction or sexual reproduction. The change will pass on asexually simply if the reproducing cell possesses the changed trait. For the changed trait to pass on by sexual reproduction, a gamete, such as a sperm or egg cell, must possess the changed trait. In other words, sexually-reproducing organisms can experience several genetic changes in their body cells, but if these changes do not occur in a sperm or egg cell, the changed trait will never reach the next generation. Only heritable traits can evolve. Therefore, reproduction plays a paramount role for genetic change to take root in a population or species. In short, organisms must be able to reproduce with each other to pass new traits to offspring.
The biological definition of species, which works for sexually reproducing organisms, is a group of actual or potential interbreeding individuals. There are exceptions to this rule. Many species are similar enough that hybrid offspring are possible and may often occur in nature, but for the majority of species this rule generally holds. The presence in nature of hybrids between similar species suggests that they may have descended from a single interbreeding species, and the speciation process may not yet be completed.
Given the extraordinary diversity of life on the planet there must be mechanisms for speciation: the formation of two species from one original species. Darwin envisioned this process as a branching event and diagrammed the process in the only illustration in On the Origin of Species (Figure 9.3-11). Compare this illustration to the diagram of elephant evolution (Figure 9.3-11), which shows that as one species changes over time, it branches to form more than one new species, repeatedly, as long as the population survives or until the organism becomes extinct.

For speciation to occur, two new populations must form from one original population and they must evolve in such a way that it becomes impossible for individuals from the two new populations to interbreed. Biologists have proposed mechanisms by which this could occur that fall into two broad categories. Allopatric speciation (allo- = “other”; -patric = “homeland”) involves geographic separation of populations from a parent species and subsequent evolution. Sympatric speciation (sym- = “same”; -patric = “homeland”) involves speciation occurring within a parent species remaining in one location.
Biologists think of speciation events as the splitting of one ancestral species into two descendant species. There is no reason why more than two species might not form at one time except that it is less likely and we can conceptualize multiple events as single splits occurring close in time.
A geographically continuous population has a gene pool that is relatively homogeneous. Gene flow, the movement of alleles across a species’ range, is relatively free because individuals can move and then mate with individuals in their new location. Thus, an allele’s frequency at one end of a distribution will be similar to the allele’s frequency at the other end. When populations become geographically discontinuous, it prevents alleles’ free-flow. When that separation lasts for a period of time, the two populations are able to evolve along different trajectories. Thus, their allele frequencies at numerous genetic loci gradually become increasingly different as new alleles independently arise by mutation in each population. Typically, environmental conditions, such as climate, resources, predators, and competitors for the two populations will differ causing natural selection to favor divergent adaptations in each group.
Isolation of populations leading to allopatric speciation can occur in a variety of ways: a river forming a new branch, erosion creating a new valley, a group of organisms traveling to a new location without the ability to return, or seeds floating over the ocean to an island. The nature of the geographic separation necessary to isolate populations depends entirely on the organism’s biology and its potential for dispersal. If two flying insect populations took up residence in separate nearby valleys, chances are, individuals from each population would fly back and forth continuing gene flow. However, if a new lake divided two rodent populations continued gene flow would be unlikely; therefore, speciation would be more likely.
Biologists group allopatric processes into two categories: dispersal and vicariance. Dispersal is when a few members of a species move to a new geographical area, and vicariance is when a natural situation arises to physically divide organisms.
Scientists have documented numerous cases of allopatric speciation taking place. For example, along the west coast of the United States, two separate spotted owl subspecies exist. The northern spotted owl has genetic and phenotypic differences from its close relative: the Mexican spotted owl, which lives in the south (Figure 9.3-12).
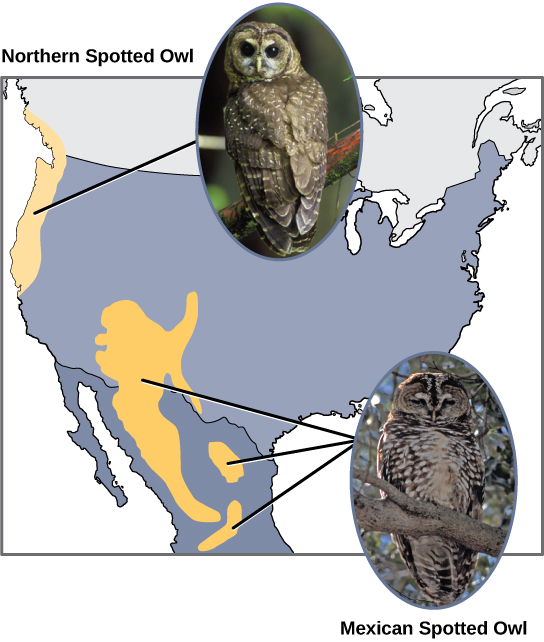
Additionally, scientists have found that the further the distance between two groups that once were the same species, the more likely it is that speciation will occur. This seems logical because as the distance increases, the various environmental factors would likely have less in common than locations in close proximity. Consider the two owls: in the north, the climate is cooler than in the south. The types of organisms in each ecosystem differ, as do their behaviors and habits. Also, the hunting habits and prey choices of the southern owls vary from the northern owls. These variances can lead to evolved differences in the owls, and speciation likely will occur.
In some cases, a population of one species disperses throughout an area, and each finds a distinct niche or isolated habitat. Over time, the varied demands of their new lifestyles lead to multiple speciation events originating from a single species. We call this adaptive radiation because many adaptations evolve from a single point of origin; thus, causing the species to radiate into several new ones. Island archipelagos like the Hawaiian Islands provide an ideal context for adaptive radiation events because water surrounds each island which leads to geographical isolation for many organisms. The Hawaiian honeycreeper illustrates one example of adaptive radiation. From a single species, the founder species, numerous species have evolved, including the six in (Figure 9.3-13).
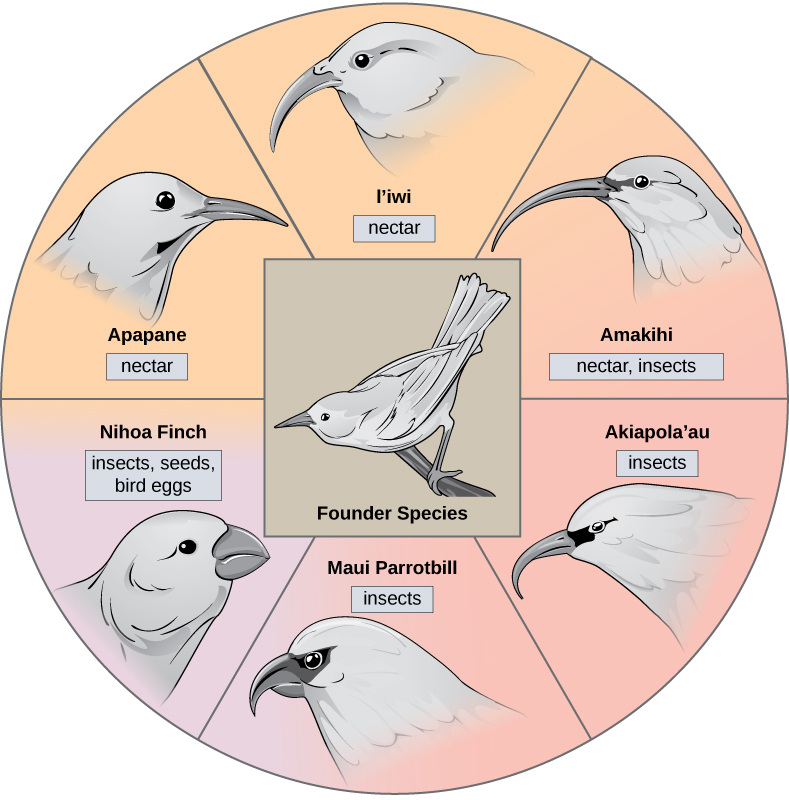
Notice the differences in the species’ beaks in (Figure 9.3-13). Evolution in response to natural selection based on specific food sources in each new habitat led to evolution of a different beak suited to the specific food source. The seed-eating bird has a thicker, stronger beak which is suited to break hard nuts. The nectar-eating birds have long beaks to dip into flowers to reach the nectar. The insect-eating birds have beaks like swords, appropriate for stabbing and impaling insects. Darwin’s finches are another example of adaptive radiation in an archipelago.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=335
Watch the Youtube interactive video The Origin of Birds by Biointeractive to see how island birds evolved in evolutionary increments from 5 million years ago to today.
Can divergence occur if no physical barriers are in place to separate individuals who continue to live and reproduce in the same habitat? The answer is yes. We call the process of speciation within the same space sympatric. The prefix “sym” means same, so “sympatric” means “same homeland” in contrast to “allopatric” meaning “other homeland.” Scientists have proposed and studied many mechanisms.
One form of sympatric speciation can begin with a serious chromosomal error during cell division. In a normal cell division event chromosomes replicate, pair up, and then separate so that each new cell has the same number of chromosomes. However, sometimes the pairs separate and the end cell product has too many or too few individual chromosomes in a condition that we call aneuploidy (Figure 9.3-14 ).

Which is most likely to survive, offspring with 2n+1 chromosomes or offspring with 2n-1 chromosomes?
Polyploidy is a condition in which a cell or organism has an extra set, or sets, of chromosomes. Scientists have identified two main types of polyploidy that can lead to reproductive isolation of an individual in the polyploidy state. Reproductive isolation is the inability to interbreed. In some cases, a polyploid individual will have two or more complete sets of chromosomes from its own species in a condition that we call autopolyploidy (Figure 9.3-15). The prefix “auto-” means “self,” so the term means multiple chromosomes from one’s own species. Polyploidy results from an error in meiosis in which all of the chromosomes move into one cell instead of separating.
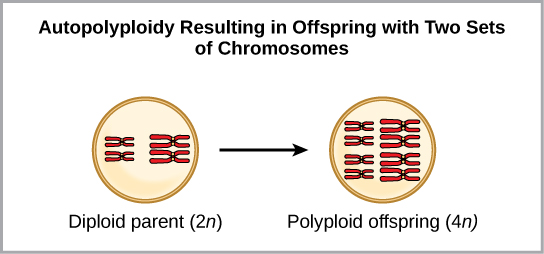
For example, if a plant species with 2n = 6 produces autopolyploid gametes that are also diploid (2n = 6, when they should be n = 3), the gametes now have twice as many chromosomes as they should have. These new gametes will be incompatible with the normal gametes that this plant species produces. However, they could either self-pollinate or reproduce with other autopolyploid plants with gametes having the same diploid number. In this way, sympatric speciation can occur quickly by forming offspring with 4n that we call a tetraploid. These individuals would immediately be able to reproduce only with those of this new kind and not those of the ancestral species.
The other form of polyploidy occurs when individuals of two different species reproduce to form a viable offspring that we call an allopolyploid. The prefix “allo-” means “other” (recall from allopatric): therefore, an allopolyploid occurs when gametes from two different species combine. (Figure 9.3-16) illustrates one possible way an allopolyploid can form. Notice how it takes two generations, or two reproductive acts, before the viable fertile hybrid results.
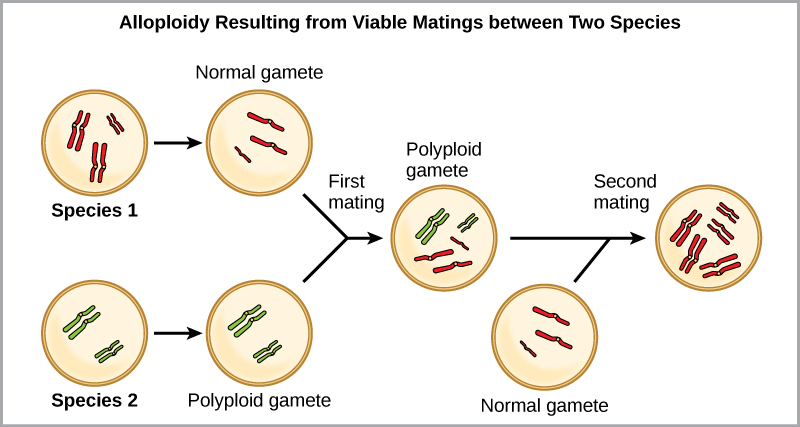
The cultivated forms of wheat, cotton, and tobacco plants are all allopolyploids. Although polyploidy occurs occasionally in animals, it takes place most commonly in plants. (Animals with any of the types of chromosomal aberrations that we describe here are unlikely to survive and produce normal offspring.) Scientists have discovered more than half of all plant species studied relate back to a species evolved through polyploidy. With such a high rate of polyploidy in plants, some scientists hypothesize that this mechanism takes place more as an adaptation than as an error.
Given enough time, the genetic and phenotypic divergence between populations will affect characters that influence reproduction: if individuals of the two populations were brought together, mating would be less likely, but if mating occurred, offspring would be nonviable or infertile. Many types of diverging characters may affect the reproductive isolation, the ability to interbreed, of the two populations.
Reproductive isolation can take place in a variety of ways. Scientists organize them into two groups: prezygotic barriers and postzygotic barriers. Recall that a zygote is a fertilized egg: the first cell of an organism’s development that reproduces sexually. Therefore, a prezygotic barrier is a mechanism that blocks reproduction from taking place. This includes barriers that prevent fertilization when organisms attempt reproduction. A postzygotic barrier occurs after zygote formation. This includes organisms that don’t survive the embryonic stage and those that are born sterile.
Some types of prezygotic barriers prevent reproduction entirely. Many organisms only reproduce at certain times of the year, often just annually. Differences in breeding schedules, which we call temporal isolation, can act as a form of reproductive isolation. For example, two frog species inhabit the same area, but one reproduces from January to March; whereas, the other reproduces from March to May (Figure 9.3-17).

In some cases, populations of a species move or are moved to a new habitat and take up residence in a place that no longer overlaps with the same species’ other populations. We call this situation habitat isolation. Reproduction with the parent species ceases, and a new group exists that is now reproductively and genetically independent. For example, a cricket population that was divided after a flood could no longer interact with each other. Over time, natural selection forces, mutation, and genetic drift will likely result in the two groups diverging (Figure 9.3-18).
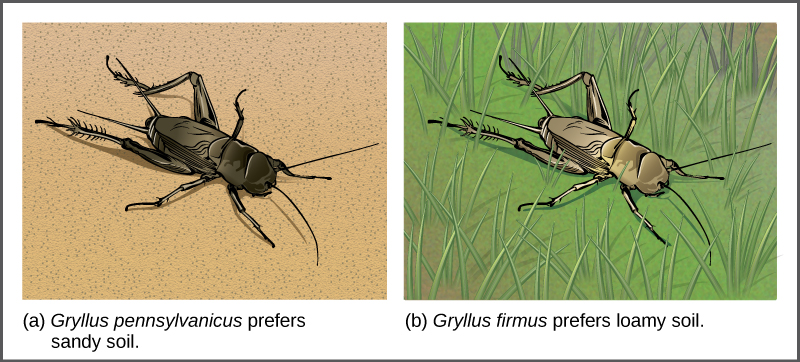
Behavioral isolation occurs when the presence or absence of a specific behavior prevents reproduction. For example, male fireflies use specific light patterns to attract females. Various firefly species display their lights differently. If a male of one species tried to attract the female of another, she would not recognize the light pattern and would not mate with the male.
Other prezygotic barriers work when differences in their gamete cells (eggs and sperm) prevent fertilization from taking place. We call this a gametic barrier. Similarly, in some cases closely related organisms try to mate, but their reproductive structures simply do not fit together. For example, damselfly males of different species have differently shaped reproductive organs. If one species tries to mate with the female of another, their body parts simply do not fit together. (Figure 9.3-19).

In plants, certain structures aimed to attract one type of pollinator simultaneously prevent a different pollinator from accessing the pollen. The tunnel through which an animal must access nectar can vary widely in length and diameter, which prevents the plant from cross-pollinating with a different species (Figure 9.3-20).
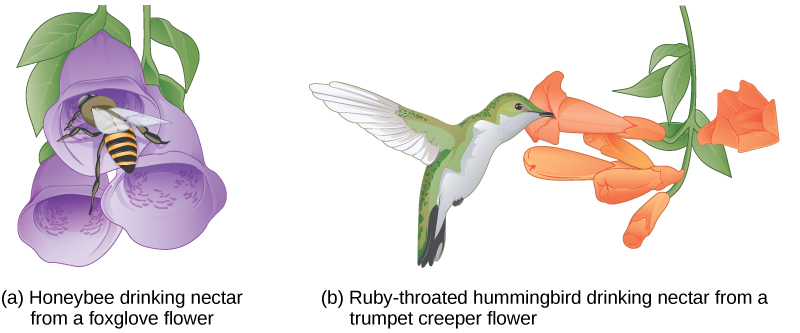
When fertilization takes place and a zygote forms, postzygotic barriers can prevent reproduction. Hybrid individuals in many cases cannot form normally in the womb and simply do not survive past the embryonic stages. We call this hybrid inviability because the hybrid organisms simply are not viable. In another postzygotic situation, reproduction leads to hybrid birth and growth that is sterile. Therefore, the organisms are unable to reproduce offspring of their own. We call this hybrid sterility.
Sympatric speciation may also take place in ways other than polyploidy. For example, consider a fish species that lives in a lake. As the population grows, competition for food increases. Under pressure to find food, suppose that a group of these fish had the genetic flexibility to discover and feed off another resource that other fish did not use. What if this new food source was located at a different depth of the lake? Over time, those feeding on the second food source would interact more with each other than the other fish; therefore, they would breed together as well. Offspring of these fish would likely behave as their parents: feeding and living in the same area and keeping separate from the original population. If this group of fish continued to remain separate from the first population, eventually sympatric speciation might occur as more genetic differences accumulated between them.
This scenario does play out in nature, as do others that lead to reproductive isolation. One such place is Lake Victoria in Africa, famous for its sympatric speciation of cichlid fish. Researchers have found hundreds of sympatric speciation events in these fish, which have not only happened in great number, but also over a short period of time. (Figure 9.3-21) shows this type of speciation among a cichlid fish population in Nicaragua. In this locale, two types of cichlids live in the same geographic location but have come to have different morphologies that allow them to eat various food sources.
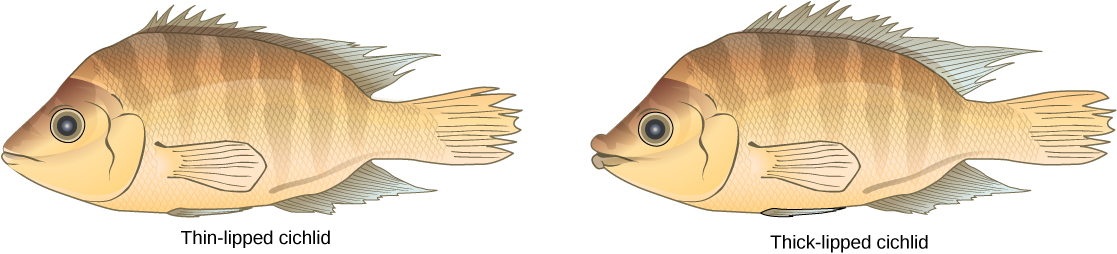
Speciation occurs along two main pathways: geographic separation (allopatric speciation) and through mechanisms that occur within a shared habitat (sympatric speciation). Both pathways isolate a population reproductively in some form. Mechanisms of reproductive isolation act as barriers between closely related species, enabling them to diverge and exist as genetically independent species. Prezygotic barriers block reproduction prior to formation of a zygote; whereas, postzygotic barriers block reproduction after fertilization occurs. For a new species to develop, something must cause a breach in the reproductive barriers. Sympatric speciation can occur through errors in meiosis that form gametes with extra chromosomes (polyploidy). Autopolyploidy occurs within a single species; whereas, allopolyploidy occurs between closely related species.
Review Questions
Visual Connection Question
Figure 9.3-14: Which is most likely to survive, offspring with 2n+1 chromosomes or offspring with 2n-1 chromosomes?Which situation would most likely lead to allopatric speciation?
Review Questions
What is the main difference between dispersal and vicariance?
Which variable increases the likelihood of allopatric speciation taking place more quickly?
What is the main difference between autopolyploid and allopolyploid?
Which reproductive combination produces hybrids?
Which condition is the basis for a species to be reproductively isolated from other members?
Which situation is not an example of a prezygotic barrier?
Critical Thinking Questions
Glossary
Creation Note: Chapter 18 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Speciation occurs over a span of evolutionary time, so when a new species arises, there is a transition period during which the closely related species continue to interact.
After speciation, two species may recombine or even continue interacting indefinitely. Individual organisms will mate with any nearby individual with whom they are capable of breeding. We call an area where two closely related species continue to interact and reproduce, forming hybrids a hybrid zone. Over time, the hybrid zone may change depending on the fitness of the hybrids and the reproductive barriers (Figure 9.4-22). If the hybrids are less fit than the parents, speciation reinforcement occurs, and the species continue to diverge until they can no longer mate and produce viable offspring. If reproductive barriers weaken, fusion occurs and the two species become one. Barriers remain the same if hybrids are fit and reproductive: stability may occur and hybridization continues.

An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=339#h5p-61
Hybrids can be either less fit than the parents, more fit, or about the same. Usually hybrids tend to be less fit; therefore, such reproduction diminishes over time, nudging the two species to diverge further in a process we call reinforcement. Scientists use this term because the hybrids’ low success reinforces the original speciation. If the hybrids are as fit or more fit than the parents, the two species may fuse back into one species (Figure 9.4-22). Scientists have also observed that sometimes two species will remain separate but also continue to interact to produce some individuals. Scientists classify this as stability because no real net change is taking place.
Scientists around the world study speciation, documenting observations both of living organisms and those found in the fossil record. As their ideas take shape and as research reveals new details about how life evolves, they develop models to help explain speciation rates. In terms of how quickly speciation occurs, we can observe two current patterns: gradual speciation model and punctuated equilibrium model.
In the gradual speciation model, species diverge gradually over time in small steps. In the punctuated equilibrium model, a new species undergoes changes quickly from the parent species, and then remains largely unchanged for long periods of time afterward (Figure 9.4-23). We call this early change model punctuated equilibrium, because it begins with a punctuated or periodic change and then remains in balance afterward. While punctuated equilibrium suggests a faster tempo, it does not necessarily exclude gradualism.
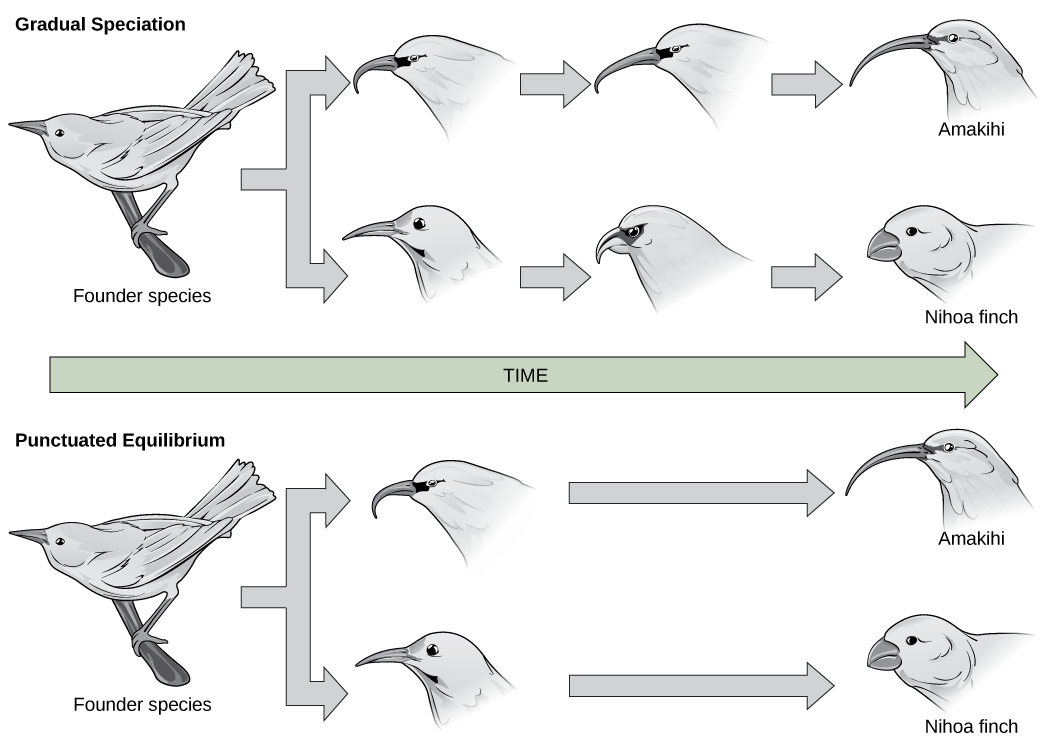
Which of the following statements is false?
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=339#h5p-60
The primary influencing factor on changes in speciation rate is environmental conditions. Under some conditions, selection occurs quickly or radically. Consider a species of snails that had been living with the same basic form for many thousands of years. Layers of their fossils would appear similar for a long time. When a change in the environment takes place—such as a drop in the water level—a small number of organisms are separated from the rest in a brief period of time, essentially forming one large and one tiny population. The tiny population faces new environmental conditions. Because its gene pool quickly became so small, any variation that surfaces and that aids in surviving the new conditions becomes the predominant form.
Visit the website Understanding Evolution to continue the speciation story of the snails.
Speciation is not a precise division: overlap between closely related species can occur in areas called hybrid zones. Organisms reproduce with other similar organisms. The fitness of these hybrid offspring can affect the two species’ evolutionary path. Scientists propose two models for the rate of speciation: one model illustrates how a species can change slowly over time. The other model demonstrates how change can occur quickly from a parent generation to a new species. Both models continue to follow natural selection patterns.
Review Questions
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=339#h5p-58
An interactive H5P element has been excluded from this version of the text. You can view it online here:
https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=339#h5p-59
Critical Thinking Questions
What do both rate of speciation models have in common?
Describe a situation where hybrid reproduction would cause two species to fuse into one.
Glossary
Creation Note: Chapter 18 in OpenStax Concepts of Biology 2E

The arctic fox is an example of a complex animal that has adapted to its environment and illustrates the relationships between an animal’s form and function. The structures of animals consist of primary tissues that make up more complex organs and organ systems. Homeostasis allows an animal to maintain a balance between its internal and external environments.
Chapter 33 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Animals vary in form and function. From a sponge to a worm to a goat, an organism has a distinct body plan that limits its size and shape. Animals’ bodies are also designed to interact with their environments, whether in the deep sea, a rainforest canopy, or the desert. Therefore, a large amount of information about the structure of an organism’s body (anatomy) and the function of its cells, tissues and organs (physiology) can be learned by studying that organism’s environment.
Animal body plans follow set patterns related to symmetry. They are asymmetrical, radial, or bilateral in form as illustrated in Figure 10.2. Asymmetrical animals are animals with no pattern or symmetry; an example of an asymmetrical animal is a sponge. Radial symmetry, as illustrated in Figure 10.2, describes when an animal has an up-and-down orientation: any plane cut along its longitudinal axis through the organism produces equal halves, but not a definite right or left side. This plan is found mostly in aquatic animals, especially organisms that attach themselves to a base, like a rock or a boat, and extract their food from the surrounding water as it flows around the organism. Bilateral symmetry is illustrated in the same figure by a goat. The goat also has an upper and lower component to it, but a plane cut from front to back separates the animal into definite right and left sides. Additional terms used when describing positions in the body are anterior (front), posterior (rear), dorsal (toward the back), and ventral (toward the stomach). Bilateral symmetry is found in both land-based and aquatic animals; it enables a high level of mobility.
Animals with bilateral symmetry that live in water tend to have a fusiform shape: this is a tubular shaped body that is tapered at both ends. This shape decreases the drag on the body as it moves through water and allows the animal to swim at high speeds. Table 10.1 lists the maximum speed of various animals. Certain types of sharks can swim at fifty kilometers per hour and some dolphins at 32 to 40 kilometers per hour. Land animals frequently travel faster, although the tortoise and snail are significantly slower than cheetahs. Another difference in the adaptations of aquatic and land-dwelling organisms is that aquatic organisms are constrained in shape by the forces of drag in the water since water has higher viscosity than air. On the other hand, land-dwelling organisms are constrained mainly by gravity, and drag is relatively unimportant. For example, most adaptations in birds are for gravity not for drag.
| Table 10.1 Maximum Speed of Assorted Land & Marine Animals | ||
|---|---|---|
| Animal | Speed (kmh) | Speed (mph) |
| Cheetah | 113 | 70 |
| Quarter horse | 77 | 48 |
| Fox | 68 | 42 |
| Shortfin mako shark | 50 | 31 |
| Domestic house cat | 48 | 30 |
| Human | 45 | 28 |
| Dolphin | 32–40 | 20–25 |
| Mouse | 13 | 8 |
| Snail | 0.05 | 0.03 |
Most animals have an exoskeleton, including insects, spiders, scorpions, horseshoe crabs, centipedes, and crustaceans. Scientists estimate that, of insects alone, there are over 30 million species on our planet. The exoskeleton is a hard covering or shell that provides benefits to the animal, such as protection against damage from predators and from water loss (for land animals); it also provides for the attachments of muscles.
As the tough and resistant outer cover of an arthropod, the exoskeleton may be constructed of a tough polymer such as chitin and is often biomineralized with materials such as calcium carbonate. This is fused to the animal’s epidermis. Ingrowths of the exoskeleton, called apodemes, function as attachment sites for muscles, similar to tendons in more advanced animals (Figure 10.3). In order to grow, the animal must first synthesize a new exoskeleton underneath the old one and then shed or molt the original covering. This limits the animal’s ability to grow continually, and may limit the individual’s ability to mature if molting does not occur at the proper time. The thickness of the exoskeleton must be increased significantly to accommodate any increase in weight. It is estimated that a doubling of body size increases body weight by a factor of eight. The increasing thickness of the chitin necessary to support this weight limits most animals with an exoskeleton to a relatively small size. The same principles apply to endoskeletons, but they are more efficient because muscles are attached on the outside, making it easier to compensate for increased mass.
An animal with an endoskeleton has its size determined by the amount of skeletal system it needs in order to support the other tissues and the amount of muscle it needs for movement. As the body size increases, both bone and muscle mass increase. The speed achievable by the animal is a balance between its overall size and the bone and muscle that provide support and movement.
The exchange of nutrients and wastes between a cell and its watery environment occurs through the process of diffusion. All living cells are bathed in liquid, whether they are in a single-celled organism or a multicellular one. Diffusion is effective over a specific distance and limits the size that an individual cell can attain. If a cell is a single-celled microorganism, such as an amoeba, it can satisfy all of its nutrient and waste needs through diffusion. If the cell is too large, then diffusion is ineffective and the center of the cell does not receive adequate nutrients nor is it able to effectively dispel its waste.
An important concept in understanding how efficient diffusion is as a means of transport is the surface to volume ratio. Recall that any three-dimensional object has a surface area and volume; the ratio of these two quantities is the surface-to-volume ratio. Consider a cell shaped like a perfect sphere: it has a surface area of 4πr2, and a volume of (4/3)πr3. The surface-to-volume ratio of a sphere is 3/r; as the cell gets bigger, its surface to volume ratio decreases, making diffusion less efficient. The larger the size of the sphere, or animal, the less surface area for diffusion it possesses.
The solution to producing larger organisms is for them to become multicellular. Specialization occurs in complex organisms, allowing cells to become more efficient at doing fewer tasks. For example, circulatory systems bring nutrients and remove waste, while respiratory systems provide oxygen for the cells and remove carbon dioxide from them. Other organ systems have developed further specialization of cells and tissues and efficiently control body functions. Moreover, surface-to-volume ratio applies to other areas of animal development, such as the relationship between muscle mass and cross-sectional surface area in supporting skeletons, and in the relationship between muscle mass and the generation of dissipation of heat.
Visit the Image Data Resource (IDA) to see an entire animal (a zebrafish embryo) at the cellular and sub-cellular level. Use the zoom and navigation functions for a virtual nanoscopy exploration.
All animals must obtain their energy from food they ingest or absorb. These nutrients are converted to adenosine triphosphate (ATP) for short-term storage and use by all cells. Some animals store energy for slightly longer times as glycogen, and others store energy for much longer times in the form of triglycerides housed in specialized adipose tissues. No energy system is one hundred percent efficient, and an animal’s metabolism produces waste energy in the form of heat. If an animal can conserve that heat and maintain a relatively constant body temperature, it is classified as a warm-blooded animal and called an endotherm. The insulation used to conserve the body heat comes in the forms of fur, fat, or feathers. The absence of insulation in ectothermic animals increases their dependence on the environment for body heat.
The amount of energy expended by an animal over a specific time is called its metabolic rate. The rate is measured variously in joules, calories, or kilocalories (1000 calories). Carbohydrates and proteins contain about 4.5 to 5 kcal/g, and fat contains about 9 kcal/g. Metabolic rate is estimated as the basal metabolic rate (BMR) in endothermic animals at rest and as the standard metabolic rate (SMR) in ectotherms. Human males have a BMR of 1600 to 1800 kcal/day, and human females have a BMR of 1300 to 1500 kcal/day. Even with insulation, endothermal animals require extensive amounts of energy to maintain a constant body temperature. An ectotherm such as an alligator has an SMR of 60 kcal/day.
Smaller endothermic animals have a greater surface area for their mass than larger ones ((Figure)). Therefore, smaller animals lose heat at a faster rate than larger animals and require more energy to maintain a constant internal temperature. This results in a smaller endothermic animal having a higher BMR, per body weight, than a larger endothermic animal.

The more active an animal is, the more energy is needed to maintain that activity, and the higher its BMR or SMR. The average daily rate of energy consumption is about two to four times an animal’s BMR or SMR. Humans are more sedentary than most animals and have an average daily rate of only 1.5 times the BMR. The diet of an endothermic animal is determined by its BMR. For example: the type of grasses, leaves, or shrubs that an herbivore eats affects the number of calories that it takes in. The relative caloric content of herbivore foods, in descending order, is tall grasses > legumes > short grasses > forbs (any broad-leaved plant, not a grass) > subshrubs > annuals/biennials.
Animals adapt to extremes of temperature or food availability through torpor. Torpor is a process that leads to a decrease in activity and metabolism and allows animals to survive adverse conditions. Torpor can be used by animals for long periods, such as entering a state of hibernation during the winter months, in which case it enables them to maintain a reduced body temperature. During hibernation, ground squirrels can achieve an abdominal temperature of 0° C (32° F), while a bear’s internal temperature is maintained higher at about 37° C (99° F).
If torpor occurs during the summer months with high temperatures and little water, it is called estivation. Some desert animals use this to survive the harshest months of the year. Torpor can occur on a daily basis; this is seen in bats and hummingbirds. While endothermy is limited in smaller animals by surface to volume ratio, some organisms can be smaller and still be endotherms because they employ daily torpor during the part of the day that is coldest. This allows them to conserve energy during the colder parts of the day, when they consume more energy to maintain their body temperature.
A standing vertebrate animal can be divided by several planes. A sagittal plane divides the body into right and left portions. A midsagittal plane divides the body exactly in the middle, making two equal right and left halves. A frontal plane (also called a coronal plane) separates the front from the back. A transverse plane (or, horizontal plane) divides the animal into upper and lower portions. This is sometimes called a cross section, and, if the transverse cut is at an angle, it is called an oblique plane. Figure 10.5 illustrates these planes on a goat (a four-legged animal) and a human being.
Vertebrate animals have a number of defined body cavities, as illustrated in Figure 10.6. Two of these are major cavities that contain smaller cavities within them. The dorsal cavity contains the cranial and the vertebral (or spinal) cavities. The ventral cavity contains the thoracic cavity, which in turn contains the pleural cavity around the lungs and the pericardial cavity, which surrounds the heart. The ventral cavity also contains the abdominopelvic cavity, which can be separated into the abdominal and the pelvic cavities.
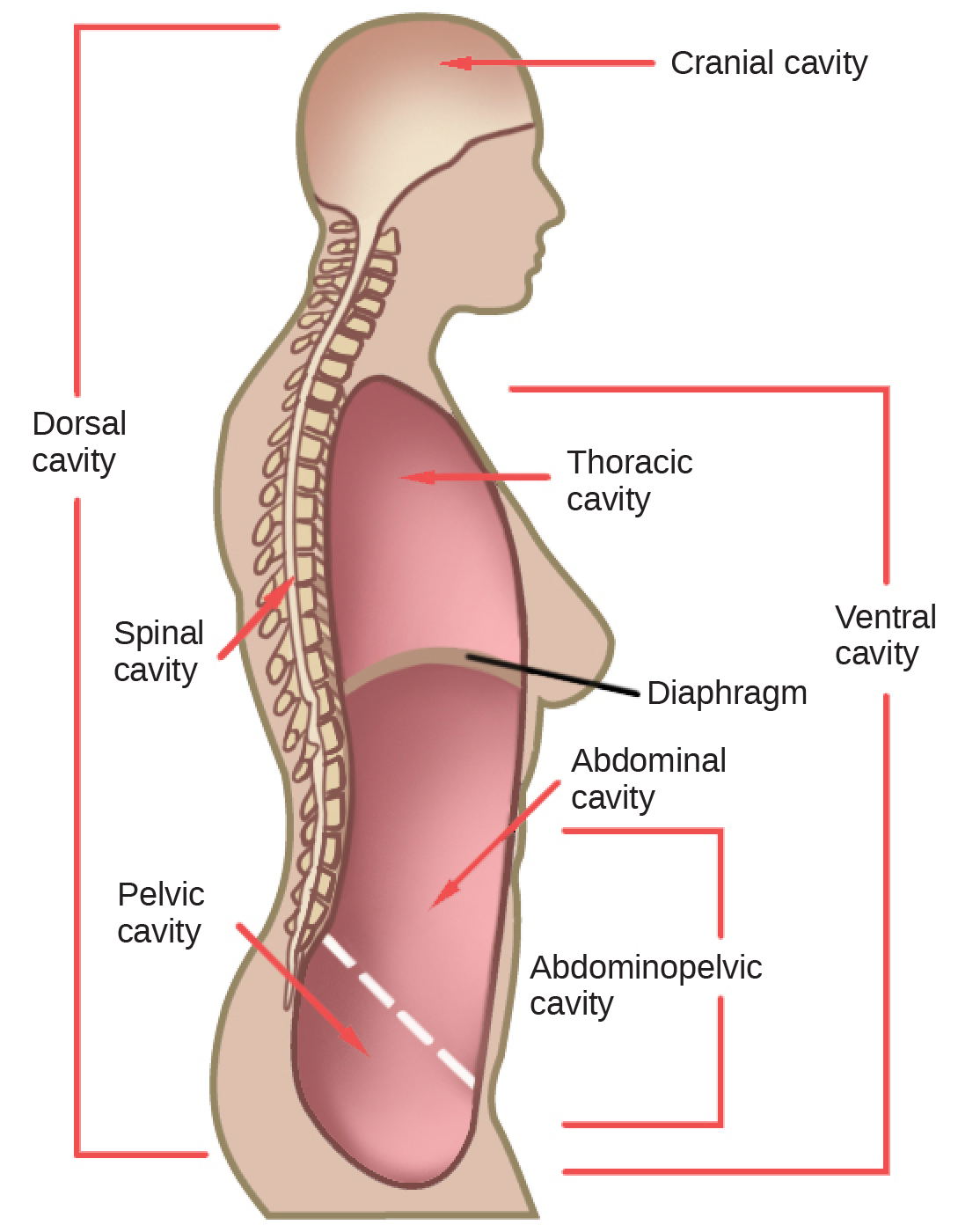
Physical anthropologists study the adaption, variability, and evolution of human beings, plus their living and fossil relatives. They can work in a variety of settings, although most will have an academic appointment at a university, usually in an anthropology department or a biology, genetics, or zoology department.
Nonacademic positions are available in the automotive and aerospace industries where the focus is on human size, shape, and anatomy. Research by these professionals might range from studies of how the human body reacts to car crashes to exploring how to make seats more comfortable. Other nonacademic positions can be obtained in museums of natural history, anthropology, archaeology, or science and technology. These positions involve educating students from grade school through graduate school. Physical anthropologists serve as education coordinators, collection managers, writers for museum publications, and as administrators. Zoos employ these professionals, especially if they have an expertise in primate biology; they work in collection management and captive breeding programs for endangered species. Forensic science utilizes physical anthropology expertise in identifying human and animal remains, assisting in determining the cause of death, and for expert testimony in trials.
Animal bodies come in a variety of sizes and shapes. Limits on animal size and shape include impacts to their movement. Diffusion affects their size and development. Bioenergetics describes how animals use and obtain energy in relation to their body size, activity level, and environment.
Exercises
Review Questions
Which type of animal maintains a constant internal body temperature?
The symmetry found in animals that move swiftly is ________.
What term describes the condition of a desert mouse that lowers its metabolic rate and “sleeps” during the hot day?
A plane that divides an animal into equal right and left portions is ________.
A plane that divides an animal into dorsal and ventral portions is ________.
The pleural cavity is a part of which cavity?
How could the increasing global temperature associated with climate change impact ectotherms?
Although most animals are bilaterally symmetrical, a few exhibit radial symmetry. What is an advantage of radial symmetry?
Critical Thinking Questions
What is the relationship between BMR and body size? Why?
Explain how using an open circulatory system constrains the size of animals.
Describe one key environmental constraint for ectotherms and one for endotherms. Why are they limited by different factors?
Glossary
Chapter 33 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
The tissues of multicellular, complex animals are four primary types: epithelial, connective, muscle, and nervous. Recall that tissues are groups of similar cells (cells carrying out related functions). These tissues combine to form organs—like the skin or kidney—that have specific, specialized functions within the body. Organs are organized into organ systems to perform functions; examples include the circulatory system, which consists of the heart and blood vessels, and the digestive system, consisting of several organs, including the stomach, intestines, liver, and pancreas. Organ systems come together to create an entire organism.
Epithelial tissues cover the outside of organs and structures in the body and line the lumens of organs in a single layer or multiple layers of cells. The types of epithelia are classified by the shapes of cells present and the number of layers of cells. Epithelia composed of a single layer of cells is called simple epithelia; epithelial tissue composed of multiple layers is called stratified epithelia. Table 10.2 summarizes the different types of epithelial tissues.
| Table 10.2 | ||
|---|---|---|
| Different Types of Epithelial Tissues | ||
| Cell shape | Description | Location |
| squamous | flat, irregular round shape | simple: lung alveoli, capillaries; stratified: skin, mouth, vagina |
| cuboidal | cube shaped, central nucleus | glands, renal tubules |
| columnar | tall, narrow, nucleus toward base; tall, narrow, nucleus along cell | simple: digestive tract; pseudostratified: respiratory tract |
| transitional | round, simple but appear stratified | urinary bladder |
Squamous epithelial cells are generally round, flat, and have a small, centrally located nucleus. The cell outline is slightly irregular, and cells fit together to form a covering or lining. When the cells are arranged in a single layer (simple epithelia), they facilitate diffusion in tissues, such as the areas of gas exchange in the lungs and the exchange of nutrients and waste at blood capillaries.
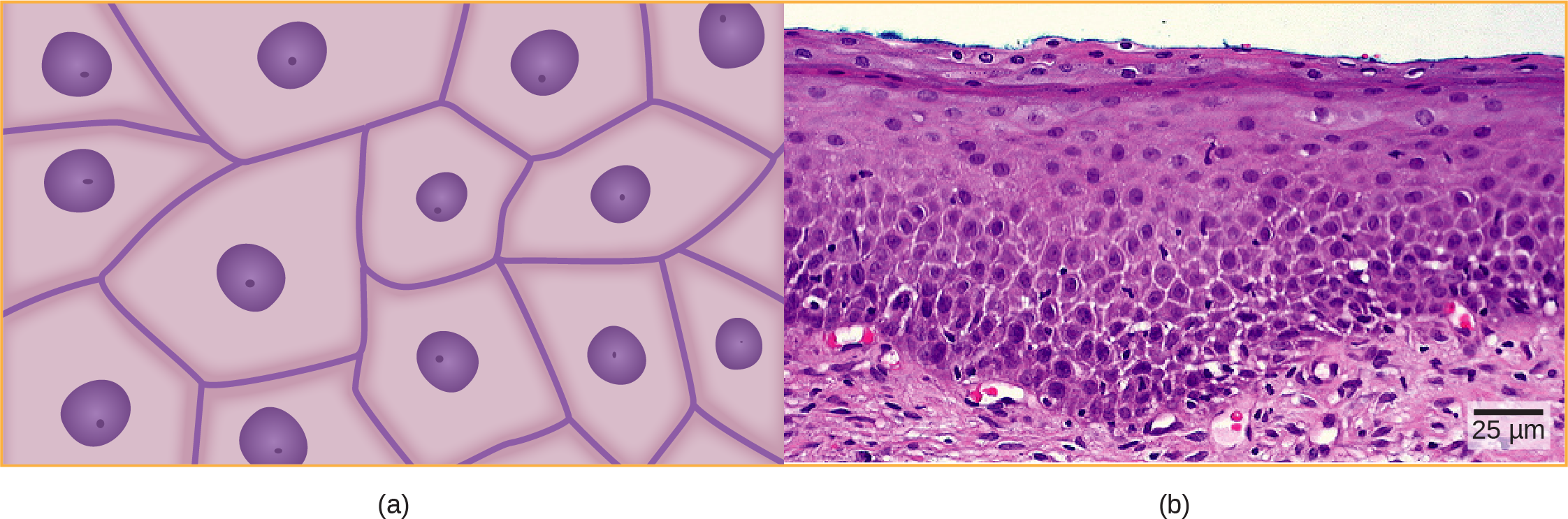
Figure 10.7 a illustrates a layer of squamous cells with their membranes joined together to form an epithelium. Image b illustrates squamous epithelial cells arranged in stratified layers, where protection is needed on the body from outside abrasion and damage. This is called a stratified squamous epithelium and occurs in the skin and in tissues lining the mouth and vagina.
Cuboidal epithelial cells, shown in Figure 10.4 are cube-shaped with a single, central nucleus. They are most commonly found in a single layer representing a simple epithelia in glandular tissues throughout the body where they prepare and secrete glandular material. They are also found in the walls of tubules and in the ducts of the kidney and liver.
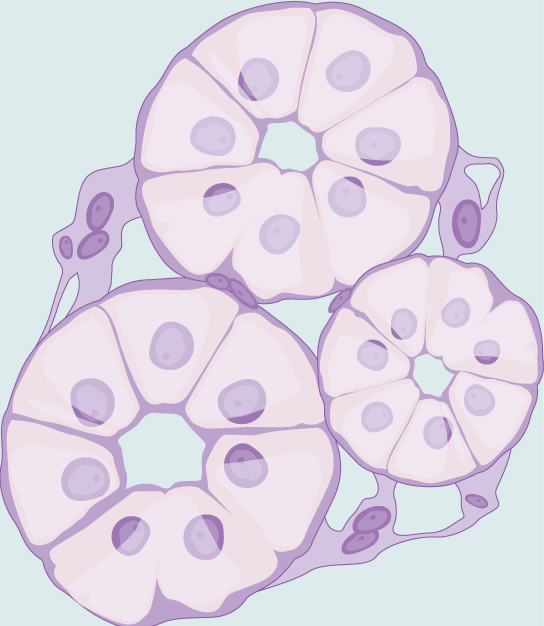
Columnar epithelial cells are taller than they are wide: they resemble a stack of columns in an epithelial layer, and are most commonly found in a single-layer arrangement. The nuclei of columnar epithelial cells in the digestive tract appear to be lined up at the base of the cells, as illustrated in Figure 10.9. These cells absorb material from the lumen of the digestive tract and prepare it for entry into the body through the circulatory and lymphatic systems.
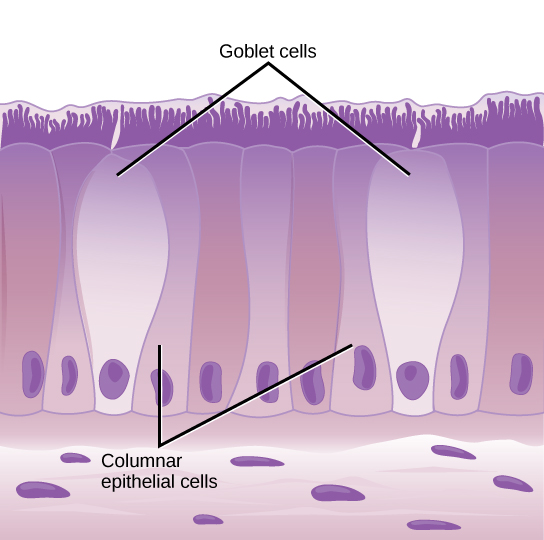
Columnar epithelial cells lining the respiratory tract appear to be stratified. However, each cell is attached to the base membrane of the tissue and, therefore, they are simple tissues. The nuclei are arranged at different levels in the layer of cells, making it appear as though there is more than one layer, as seen in Figure 10.9. This is called pseudostratified, columnar epithelia. This cellular covering has cilia at the apical, or free, surface of the cells. The cilia enhance the movement of mucous and trapped particles out of the respiratory tract, helping to protect the system from invasive microorganisms and harmful material that has been breathed into the body. Goblet cells are interspersed in some tissues (such as the lining of the trachea). The goblet cells contain mucous that traps irritants, which in the case of the trachea keep these irritants from getting into the lungs.
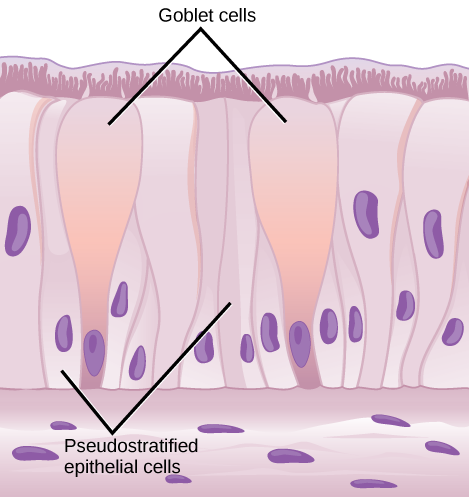
Transitional or uroepithelial cells appear only in the urinary system, primarily in the bladder and ureter. These cells are arranged in a stratified layer, but they have the capability of appearing to pile up on top of each other in a relaxed, empty bladder, as illustrated in Figure 10.11. As the urinary bladder fills, the epithelial layer unfolds and expands to hold the volume of urine introduced into it. As the bladder fills, it expands and the lining becomes thinner. In other words, the tissue transitions from thick to thin.
Which of the following statements about types of epithelial cells is false?
Connective tissues are made up of a matrix consisting of living cells and a nonliving substance, called the ground substance. The ground substance is made of an organic substance (usually a protein) and an inorganic substance (usually a mineral or water). The principal cell of connective tissues is the fibroblast. This cell makes the fibers found in nearly all of the connective tissues. Fibroblasts are motile, able to carry out mitosis, and can synthesize whichever connective tissue is needed. Macrophages, lymphocytes, and, occasionally, leukocytes can be found in some of the tissues. Some tissues have specialized cells that are not found in the others. The matrix in connective tissues gives the tissue its density. When a connective tissue has a high concentration of cells or fibers, it has proportionally a less dense matrix.
The organic portion or protein fibers found in connective tissues are either collagen, elastic, or reticular fibers. Collagen fibers provide strength to the tissue, preventing it from being torn or separated from the surrounding tissues. Elastic fibers are made of the protein elastin; this fiber can stretch to one and one half of its length and return to its original size and shape. Elastic fibers provide flexibility to the tissues. Reticular fibers are the third type of protein fiber found in connective tissues. This fiber consists of thin strands of collagen that form a network of fibers to support the tissue and other organs to which it is connected. The various types of connective tissues, the types of cells and fibers they are made of, and sample locations of the tissues is summarized in Table 10.3.
| Table 10.3 Connective Tissues | |||
|---|---|---|---|
| Tissue | Cells | Fibers | Location |
| loose/areolar | fibroblasts, macrophages, some lymphocytes, some neutrophils | few: collagen, elastic, reticular | around blood vessels; anchors epithelia |
| dense, fibrous connective tissue | fibroblasts, macrophages | mostly collagen | irregular: skin; regular: tendons, ligaments |
| cartilage | chondrocytes, chondroblasts | hyaline: few: collagen fibrocartilage: large amount of collagen | shark skeleton, fetal bones, human ears, intervertebral discs |
| bone | osteoblasts, osteocytes, osteoclasts | some: collagen, elastic | vertebrate skeletons |
| adipose | adipocytes | few | adipose (fat) |
| blood | red blood cells, white blood cells | none | blood |
Loose connective tissue, also called areolar connective tissue, has a sampling of all of the components of a connective tissue. As illustrated in Figure10.12, loose connective tissue has some fibroblasts; macrophages are present as well. Collagen fibers are relatively wide and stain a light pink, while elastic fibers are thin and stain dark blue to black. The space between the formed elements of the tissue is filled with the matrix. The material in the connective tissue gives it a loose consistency similar to a cotton ball that has been pulled apart. Loose connective tissue is found around every blood vessel and helps to keep the vessel in place. The tissue is also found around and between most body organs. In summary, areolar tissue is tough, yet flexible, and comprises membranes.

Fibrous connective tissues contain large amounts of collagen fibers and few cells or matrix material. The fibers can be arranged irregularly or regularly with the strands lined up in parallel. Irregularly arranged fibrous connective tissues are found in areas of the body where stress occurs from all directions, such as the dermis of the skin. Regular fibrous connective tissue, shown in Figure 10.13, is found in tendons (which connect muscles to bones) and ligaments (which connect bones to bones).
Cartilage is a connective tissue with a large amount of the matrix and variable amounts of fibers. The cells, called chondrocytes, make the matrix and fibers of the tissue. Chondrocytes are found in spaces within the tissue called lacunae.
A cartilage with few collagen and elastic fibers is hyaline cartilage, illustrated in (Figure). The lacunae are randomly scattered throughout the tissue and the matrix takes on a milky or scrubbed appearance with routine histological stains. Sharks have cartilaginous skeletons, as does nearly the entire human skeleton during a specific pre-birth developmental stage. A remnant of this cartilage persists in the outer portion of the human nose. Hyaline cartilage is also found at the ends of long bones, reducing friction and cushioning the articulations of these bones.
Elastic cartilage has a large amount of elastic fibers, giving it tremendous flexibility. The ears of most vertebrate animals contain this cartilage as do portions of the larynx, or voice box. Fibrocartilage contains a large amount of collagen fibers, giving the tissue tremendous strength. Fibrocartilage comprises the intervertebral discs in vertebrate animals. Hyaline cartilage found in movable joints such as the knee and shoulder becomes damaged as a result of age or trauma. Damaged hyaline cartilage is replaced by fibrocartilage and results in the joints becoming “stiff.”
Bone, or osseous tissue, is a connective tissue that has a large amount of two different types of matrix material. The organic matrix is similar to the matrix material found in other connective tissues, including some amount of collagen and elastic fibers. This gives strength and flexibility to the tissue. The inorganic matrix consists of mineral salts—mostly calcium salts—that give the tissue hardness. Without adequate organic material in the matrix, the tissue breaks; without adequate inorganic material in the matrix, the tissue bends.
There are three types of cells in bone: osteoblasts, osteocytes, and osteoclasts. Osteoblasts are active in making bone for growth and remodeling. Osteoblasts deposit bone material into the matrix and, after the matrix surrounds them, they continue to live, but in a reduced metabolic state as osteocytes. Osteocytes are found in lacunae of the bone. Osteoclasts are active in breaking down bone for bone remodeling, and they provide access to calcium stored in tissues. Osteoclasts are usually found on the surface of the tissue.
Bone can be divided into two types: compact and spongy. Compact bone is found in the shaft (or diaphysis) of a long bone and the surface of the flat bones, while spongy bone is found in the end (or epiphysis) of a long bone. Compact bone is organized into subunits called osteons, as illustrated in Figure 10.15. A blood vessel and a nerve are found in the center of the structure within the Haversian canal, with radiating circles of lacunae around it known as lamellae. The wavy lines seen between the lacunae are microchannels called canaliculi; they connect the lacunae to aid diffusion between the cells. Spongy bone is made of tiny plates called trabeculae; these plates serve as struts to give the spongy bone strength. Over time, these plates can break causing the bone to become less resilient. Bone tissue forms the internal skeleton of vertebrate animals, providing structure to the animal and points of attachment for tendons.
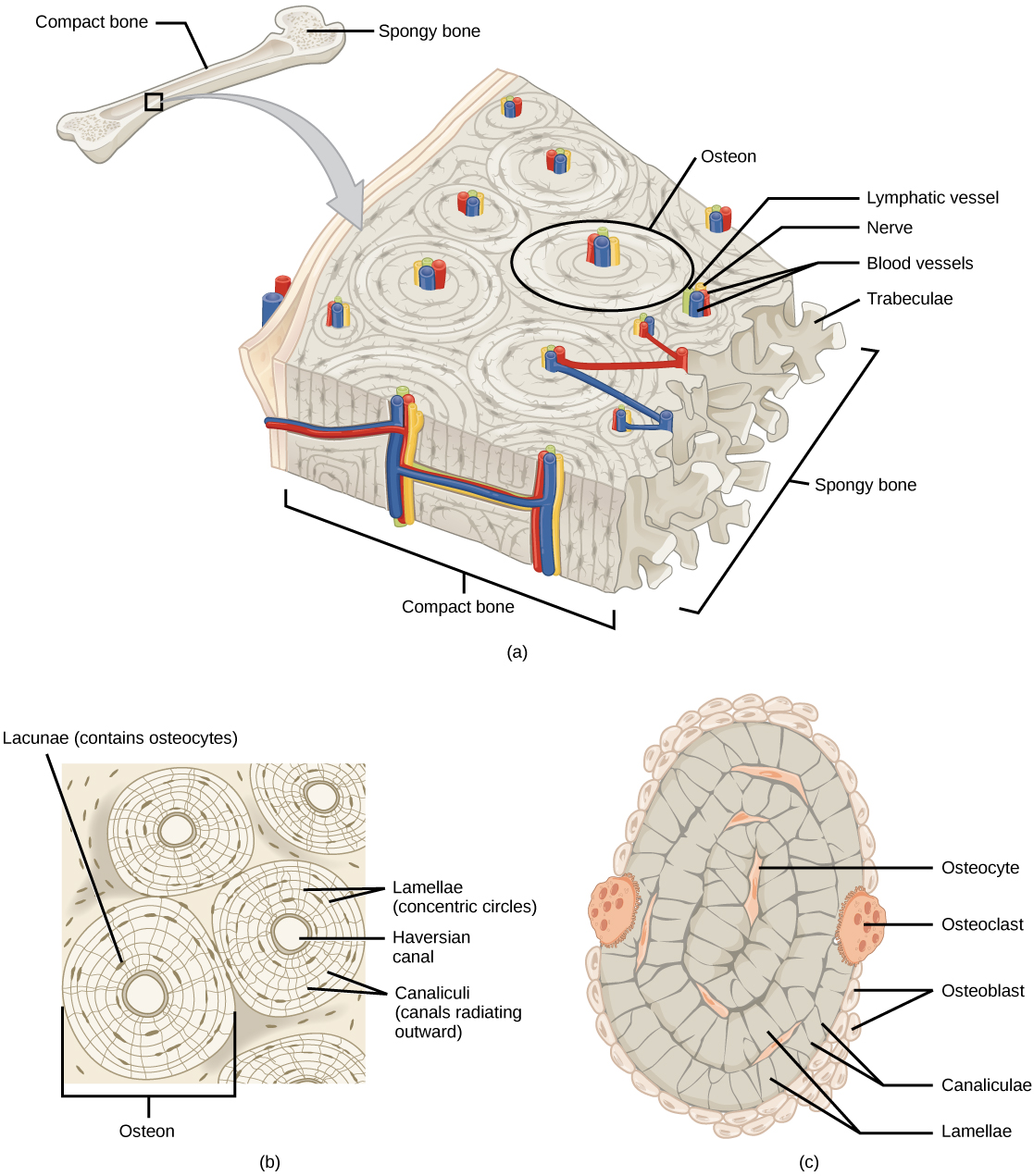
Adipose tissue, or fat tissue, is considered a connective tissue even though it does not have fibroblasts or a real matrix and only has a few fibers. Adipose tissue is made up of cells called adipocytes that collect and store fat in the form of triglycerides, for energy metabolism. Adipose tissues additionally serve as insulation to help maintain body temperatures, allowing animals to be endothermic, and they function as cushioning against damage to body organs. Under a microscope, adipose tissue cells appear empty due to the extraction of fat during the processing of the material for viewing, as seen in Figure 10.16. The thin lines in the image are the cell membranes, and the nuclei are the small, black dots at the edges of the cells.

Blood is considered a connective tissue because it has a matrix, as shown in Figure 10.17. The living cell types are red blood cells (RBC), also called erythrocytes, and white blood cells (WBC), also called leukocytes. The fluid portion of whole blood, its matrix, is commonly called plasma.
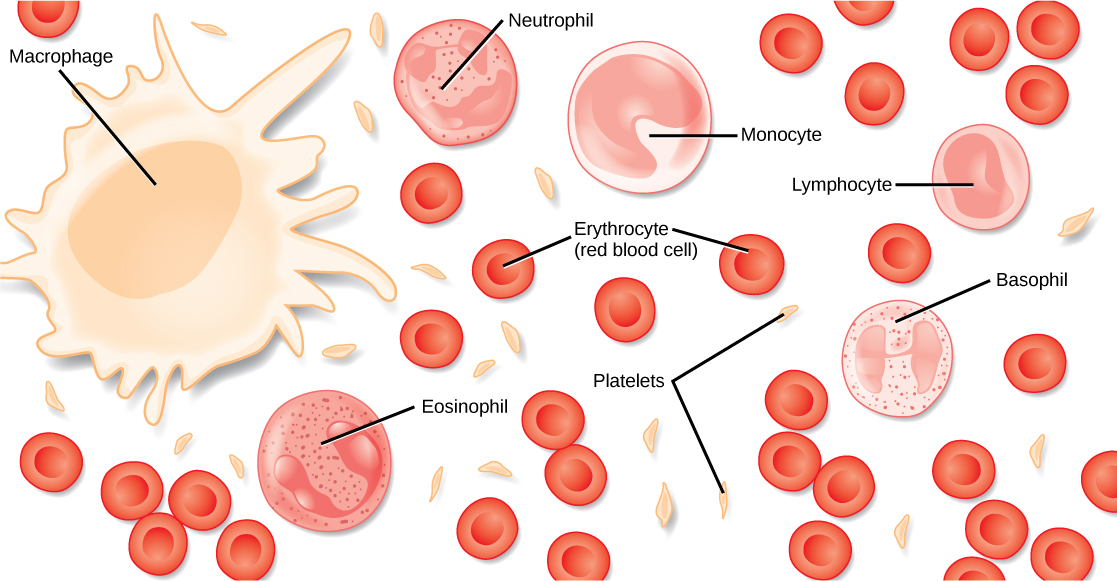
The cell found in greatest abundance in blood is the erythrocyte. Erythrocytes are counted in millions in a blood sample: the average number of red blood cells in primates is 4.7 to 5.5 million cells per microliter. Erythrocytes are consistently the same size in a species, but vary in size between species. For example, the average diameter of a primate red blood cell is 7.5 µl, a dog is close at 7.0 µl, but a cat’s RBC diameter is 5.9 µl. Sheep erythrocytes are even smaller at 4.6 µl. Mammalian erythrocytes lose their nuclei and mitochondria when they are released from the bone marrow where they are made. Fish, amphibian, and avian red blood cells maintain their nuclei and mitochondria throughout the cell’s life. The principal job of an erythrocyte is to carry and deliver oxygen to the tissues.
Leukocytes are the predominant white blood cells found in the peripheral blood. Leukocytes are counted in the thousands in the blood with measurements expressed as ranges: primate counts range from 4,800 to 10,800 cells per µl, dogs from 5,600 to 19,200 cells per µl, cats from 8,000 to 25,000 cells per µl, cattle from 4,000 to 12,000 cells per µl, and pigs from 11,000 to 22,000 cells per µl.
Lymphocytes function primarily in the immune response to foreign antigens or material. Different types of lymphocytes make antibodies tailored to the foreign antigens and control the production of those antibodies. Neutrophils are phagocytic cells and they participate in one of the early lines of defense against microbial invaders, aiding in the removal of bacteria that has entered the body. Another leukocyte that is found in the peripheral blood is the monocyte. Monocytes give rise to phagocytic macrophages that clean up dead and damaged cells in the body, whether they are foreign or from the host animal. Two additional leukocytes in the blood are eosinophils and basophils—both help to facilitate the inflammatory response.
The slightly granular material among the cells is a cytoplasmic fragment of a cell in the bone marrow. This is called a platelet or thrombocyte. Platelets participate in the stages leading up to coagulation of the blood to stop bleeding through damaged blood vessels. Blood has a number of functions, but primarily it transports material through the body to bring nutrients to cells and remove waste material from them.
There are three types of muscle in animal bodies: smooth, skeletal, and cardiac. They differ by the presence or absence of striations or bands, the number and location of nuclei, whether they are voluntarily or involuntarily controlled, and their location within the body. Table 10.4 summarizes these differences.
| Table 10.4 Types of Muscles | ||||
|---|---|---|---|---|
| Type of Muscle | Striations | Nuclei | Control | Location |
| smooth | no | single, in center | involuntary | visceral organs |
| skeletal | yes | many, at periphery | voluntary | skeletal muscles |
| cardiac | yes | single, in center | involuntary | heart |
Smooth muscle does not have striations in its cells. It has a single, centrally located nucleus, as shown in Figure 10.18. Constriction of smooth muscle occurs under involuntary, autonomic nervous control and in response to local conditions in the tissues. Smooth muscle tissue is also called non-striated as it lacks the banded appearance of skeletal and cardiac muscle. The walls of blood vessels, the tubes of the digestive system, and the tubes of the reproductive systems are composed of mostly smooth muscle.

Skeletal muscle has striations across its cells caused by the arrangement of the contractile proteins actin and myosin. These muscle cells are relatively long and have multiple nuclei along the edge of the cell. Skeletal muscle is under voluntary, somatic nervous system control and is found in the muscles that move bones. Figure 10.18 illustrates the histology of skeletal muscle.
Cardiac muscle, shown in Figure 10.18, is found only in the heart. Like skeletal muscle, it has cross striations in its cells, but cardiac muscle has a single, centrally located nucleus. Cardiac muscle is not under voluntary control but can be influenced by the autonomic nervous system to speed up or slow down. An added feature to cardiac muscle cells is a line than extends along the end of the cell as it abuts the next cardiac cell in the row. This line is called an intercalated disc: it assists in passing electrical impulse efficiently from one cell to the next and maintains the strong connection between neighboring cardiac cells.
Nervous tissues are made of cells specialized to receive and transmit electrical impulses from specific areas of the body and to send them to specific locations in the body. The main cell of the nervous system is the neuron, illustrated in Figure 10.19. The large structure with a central nucleus is the cell body of the neuron. Projections from the cell body are either dendrites specialized in receiving input or a single axon specialized in transmitting impulses. Some glial cells are also shown. Astrocytes regulate the chemical environment of the nerve cell, and oligodendrocytes insulate the axon so the electrical nerve impulse is transferred more efficiently. Other glial cells that are not shown support the nutritional and waste requirements of the neuron. Some of the glial cells are phagocytic and remove debris or damaged cells from the tissue. A nerve consists of neurons and glial cells.
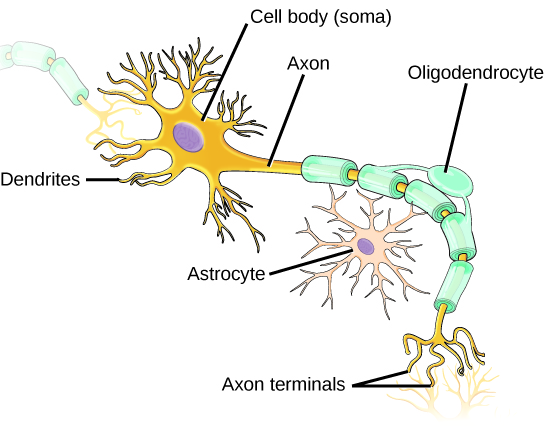
Click to read the interactive review on Nervous and Epithelial Tissue By Barbara Liang to learn more about epithelial tissues.
A pathologist is a medical doctor or veterinarian who has specialized in the laboratory detection of disease in animals, including humans. These professionals complete medical school education and follow it with an extensive post-graduate residency at a medical center. A pathologist may oversee clinical laboratories for the evaluation of body tissue and blood samples for the detection of disease or infection. They examine tissue specimens through a microscope to identify cancers and other diseases. Some pathologists perform autopsies to determine the cause of death and the progression of disease.
The basic building blocks of complex animals are four primary tissues. These are combined to form organs, which have a specific, specialized function within the body, such as the skin or kidney. Organs are organized together to perform common functions in the form of systems. The four primary tissues are epithelia, connective tissues, muscle tissues, and nervous tissues.
(Figure) Which of the following statements about types of epithelial cells is false?
(Figure) A
Exercises
Which type of epithelial cell is best adapted to aid diffusion?
C
Which type of epithelial cell is found in glands?
B
Which type of epithelial cell is found in the urinary bladder?
D
Which type of connective tissue has the most fibers?
B
Which type of connective tissue has a mineralized different matrix?
D
The cell found in bone that breaks it down is called an ________.
C
The cell found in bone that makes the bone is called an ________.
A
Plasma is the ________.
B
The type of muscle cell under voluntary control is the ________.
B
The part of a neuron that contains the nucleus is the
A
Why are intercalated discs essential to the function of cardiac muscle?
C
How can squamous epithelia both facilitate diffusion and prevent damage from abrasion?
Squamous epithelia can be either simple or stratified. As a single layer of cells, it presents a very thin epithelia that minimally inhibits diffusion. As a stratified epithelia, the surface cells can be sloughed off and the cells in deeper layers protect the underlying tissues from damage.
What are the similarities between cartilage and bone?
Both contain cells other than the traditional fibroblast. Both have cells that lodge in spaces within the tissue called lacunae. Both collagen and elastic fibers are found in bone and cartilage. Both tissues participate in vertebrate skeletal development and formation.
Multiple sclerosis is a debilitating autoimmune disease that results in the loss of the insulation around neuron axons. What cell type is the immune system attacking, and how does this disrupt the transfer of messages by the nervous system?
In multiple sclerosis, the immune system attacks the oligodendrocytes. The death of oligodendrocytes results in the loss of the insulating sheath around the axon of the neurons. When the sheath is gone, the electrical impulses travel much more slowly down the length of the axon.
When a person leads a sedentary life his skeletal muscles atrophy, but his smooth muscles do not. Why?
Skeletal muscles are involved in voluntary motion, so the person has to make the choice to work those muscles through exercise or movement. Smooth muscles are involved in involuntary activities of the body (ex. blood vessel expansion and contraction, intestinal peristalsis) so they are active even when a person is sedentary.
Glossary
canaliculus
microchannel that connects the lacunae and aids diffusion between cells
Chapter 33 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Animal organs and organ systems constantly adjust to internal and external changes through a process called homeostasis (“steady state”). These changes might be in the level of glucose or calcium in blood or in external temperatures. Homeostasis means to maintain dynamic equilibrium in the body. It is dynamic because it is constantly adjusting to the changes that the body’s systems encounter. It is equilibrium because body functions are kept within specific ranges. Even an animal that is apparently inactive is maintaining this homeostatic equilibrium.
The goal of homeostasis is the maintenance of equilibrium around a point or value called a set point. While there are normal fluctuations from the set point, the body’s systems will usually attempt to go back to this point. A change in the internal or external environment is called a stimulus and is detected by a receptor; the response of the system is to adjust the deviation parameter toward the set point. For instance, if the body becomes too warm, adjustments are made to cool the animal. If the blood’s glucose rises after a meal, adjustments are made to lower the blood glucose level by getting the nutrient into tissues that need it or to store it for later use.
When a change occurs in an animal’s environment, an adjustment must be made. The receptor senses the change in the environment, then sends a signal to the control center (in most cases, the brain) which in turn generates a response that is signaled to an effector. The effector is a muscle (that contracts or relaxes) or a gland that secretes. Homeostatsis is maintained by negative feedback loops. Positive feedback loops actually push the organism further out of homeostasis, but may be necessary for life to occur. Homeostasis is controlled by the nervous and endocrine system of mammals.
Any homeostatic process that changes the direction of the stimulus is a negative feedback loop. It may either increase or decrease the stimulus, but the stimulus is not allowed to continue as it did before the receptor sensed it. In other words, if a level is too high, the body does something to bring it down, and conversely, if a level is too low, the body does something to make it go up. Hence the term negative feedback. An example is animal maintenance of blood glucose levels. When an animal has eaten, blood glucose levels rise. This is sensed by the nervous system. Specialized cells in the pancreas sense this, and the hormone insulin is released by the endocrine system. Insulin causes blood glucose levels to decrease, as would be expected in a negative feedback system, as illustrated in Figure 10.20. However, if an animal has not eaten and blood glucose levels decrease, this is sensed in another group of cells in the pancreas, and the hormone glucagon is released causing glucose levels to increase. This is still a negative feedback loop, but not in the direction expected by the use of the term “negative.” Another example of an increase as a result of the feedback loop is the control of blood calcium. If calcium levels decrease, specialized cells in the parathyroid gland sense this and release parathyroid hormone (PTH), causing an increased absorption of calcium through the intestines and kidneys and, possibly, the breakdown of bone in order to liberate calcium. The effects of PTH are to raise blood levels of the element. Negative feedback loops are the predominant mechanism used in homeostasis.
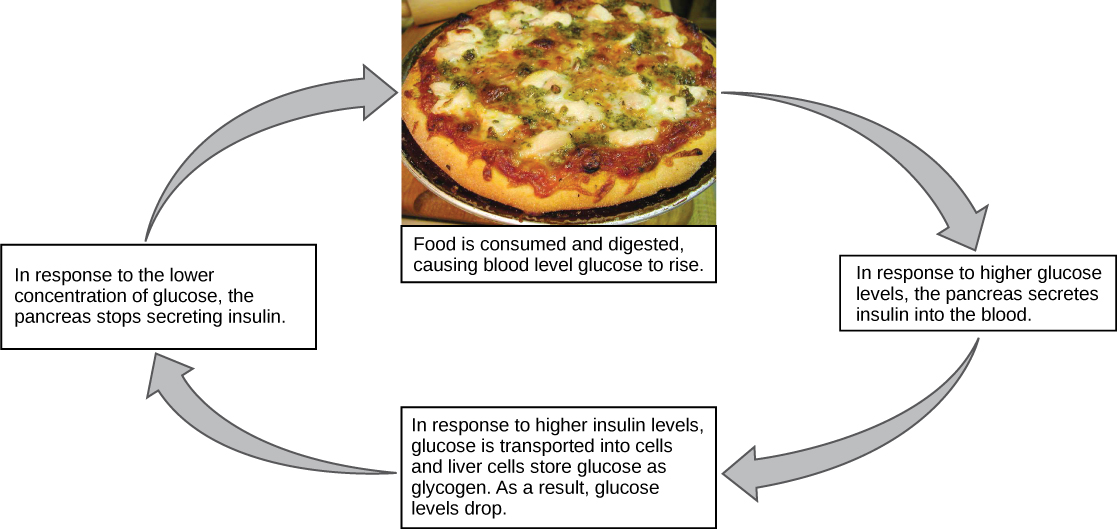
A positive feedback loop maintains the direction of the stimulus, possibly accelerating it. Few examples of positive feedback loops exist in animal bodies, but one is found in the cascade of chemical reactions that result in blood clotting, or coagulation. As one clotting factor is activated, it activates the next factor in sequence until a fibrin clot is achieved. The direction is maintained, not changed, so this is positive feedback. Another example of positive feedback is uterine contractions during childbirth, as illustrated in Figure 10.21. The hormone oxytocin, made by the endocrine system, stimulates the contraction of the uterus. This produces pain sensed by the nervous system. Instead of lowering the oxytocin and causing the pain to subside, more oxytocin is produced until the contractions are powerful enough to produce childbirth.
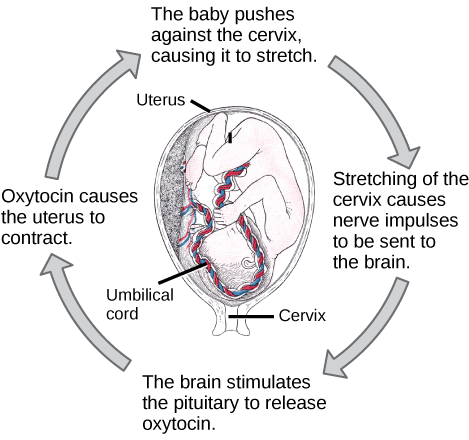
State whether each of the following processes is regulated by a positive feedback loop or a negative feedback loop.
It is possible to adjust a system’s set point. When this happens, the feedback loop works to maintain the new setting. An example of this is blood pressure: over time, the normal or set point for blood pressure can increase as a result of continued increases in blood pressure. The body no longer recognizes the elevation as abnormal and no attempt is made to return to the lower set point. The result is the maintenance of an elevated blood pressure that can have harmful effects on the body. Medication can lower blood pressure and lower the set point in the system to a more healthy level. This is called a process of alteration of the set point in a feedback loop.
Changes can be made in a group of body organ systems in order to maintain a set point in another system. This is called acclimatization. This occurs, for instance, when an animal migrates to a higher altitude than that to which it is accustomed. In order to adjust to the lower oxygen levels at the new altitude, the body increases the number of red blood cells circulating in the blood to ensure adequate oxygen delivery to the tissues. Another example of acclimatization is animals that have seasonal changes in their coats: a heavier coat in the winter ensures adequate heat retention, and a light coat in summer assists in keeping body temperature from rising to harmful levels.
Feedback mechanisms can be understood in terms of driving a race car along a track: watch a short video lesson on positive and negative feedback loops.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=372
Body temperature affects body activities. Generally, as body temperature rises, enzyme activity rises as well. For every ten degree centigrade rise in temperature, enzyme activity doubles, up to a point. Body proteins, including enzymes, begin to denature and lose their function with high heat (around 50oC for mammals). Enzyme activity will decrease by half for every ten degree centigrade drop in temperature, to the point of freezing, with a few exceptions. Some fish can withstand freezing solid and return to normal with thawing.
Watch this Discovery Channel video on thermoregulation to see illustrations of this process in a variety of animals.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=372
Animals can be divided into two groups: some maintain a constant body temperature in the face of differing environmental temperatures, while others have a body temperature that is the same as their environment and thus varies with the environment. Animals that do not control their body temperature are ectotherms. This group has been called cold-blooded, but the term may not apply to an animal in the desert with a very warm body temperature. In contrast to ectotherms, which rely on external temperatures to set their body temperatures, poikilotherms are animals with constantly varying internal temperatures. An animal that maintains a constant body temperature in the face of environmental changes is called a homeotherm. Endotherms are animals that rely on internal sources for body temperature but which can exhibit extremes in temperature. These animals are able to maintain a level of activity at cooler temperature, which an ectotherm cannot due to differing enzyme levels of activity.
Heat can be exchanged between an animal and its environment through four mechanisms: radiation, evaporation, convection, and conduction Figure 10.22. Radiation is the emission of electromagnetic “heat” waves. Heat comes from the sun in this manner and radiates from dry skin the same way. Heat can be removed with liquid from a surface during evaporation. This occurs when a mammal sweats. Convection currents of air remove heat from the surface of dry skin as the air passes over it. Heat will be conducted from one surface to another during direct contact with the surfaces, such as an animal resting on a warm rock.
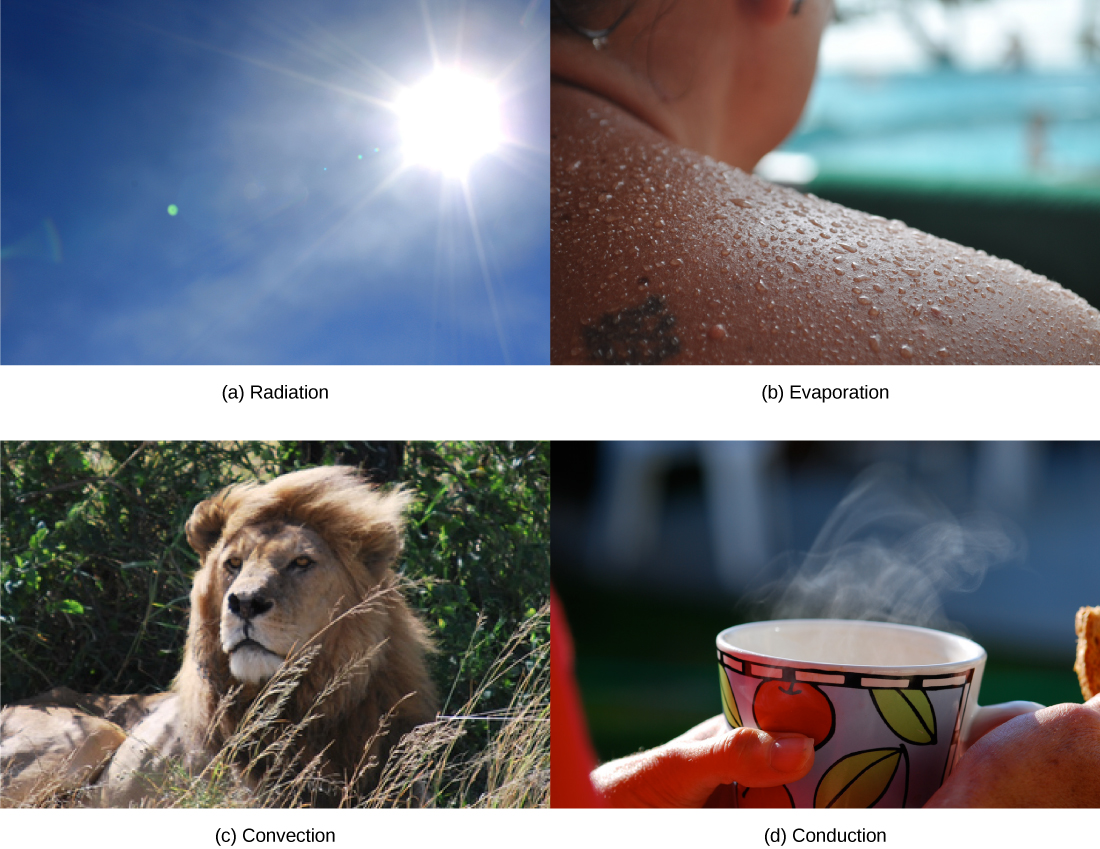
Animals conserve or dissipate heat in a variety of ways. In certain climates, endothermic animals have some form of insulation, such as fur, fat, feathers, or some combination thereof. Animals with thick fur or feathers create an insulating layer of air between their skin and internal organs. Polar bears and seals live and swim in a subfreezing environment and yet maintain a constant, warm, body temperature. The arctic fox, for example, uses its fluffy tail as extra insulation when it curls up to sleep in cold weather. Mammals have a residual effect from shivering and increased muscle activity: arrector pili muscles cause “goose bumps,” causing small hairs to stand up when the individual is cold; this has the intended effect of increasing body temperature. Mammals use layers of fat to achieve the same end. Loss of significant amounts of body fat will compromise an individual’s ability to conserve heat.
Endotherms use their circulatory systems to help maintain body temperature. Vasodilation brings more blood and heat to the body surface, facilitating radiation and evaporative heat loss, which helps to cool the body. Vasoconstriction reduces blood flow in peripheral blood vessels, forcing blood toward the core and the vital organs found there, and conserving heat. Some animals have adaptions to their circulatory system that enable them to transfer heat from arteries to veins, warming blood returning to the heart. This is called a countercurrent heat exchange; it prevents the cold venous blood from cooling the heart and other internal organs. This adaption can be shut down in some animals to prevent overheating the internal organs. The countercurrent adaption is found in many animals, including dolphins, sharks, bony fish, bees, and hummingbirds. In contrast, similar adaptations can help cool endotherms when needed, such as dolphin flukes and elephant ears.
Some ectothermic animals use changes in their behavior to help regulate body temperature. For example, a desert ectothermic animal may simply seek cooler areas during the hottest part of the day in the desert to keep from getting too warm. The same animals may climb onto rocks to capture heat during a cold desert night. Some animals seek water to aid evaporation in cooling them, as seen with reptiles. Other ectotherms use group activity such as the activity of bees to warm a hive to survive winter.
Many animals, especially mammals, use metabolic waste heat as a heat source. When muscles are contracted, most of the energy from the ATP used in muscle actions is wasted energy that translates into heat. Severe cold elicits a shivering reflex that generates heat for the body. Many species also have a type of adipose tissue called brown fat that specializes in generating heat.
The nervous system is important to thermoregulation, as illustrated in (Figure). The processes of homeostasis and temperature control are centered in the hypothalamus of the advanced animal brain.
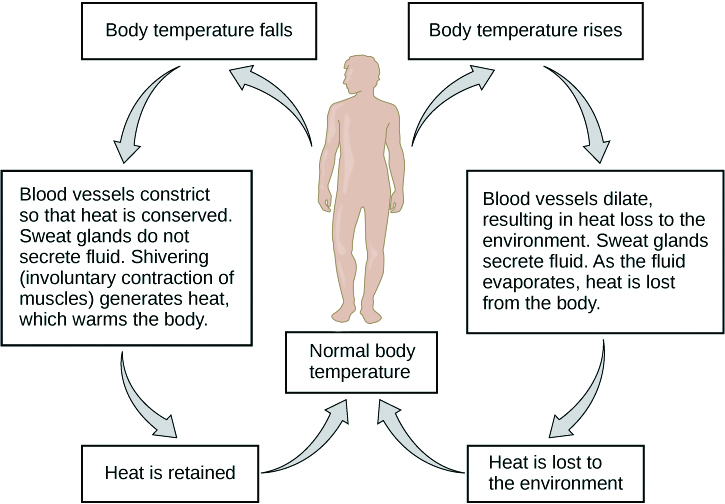
When bacteria are destroyed by leuckocytes, pyrogens are released into the blood. Pyrogens reset the body’s thermostat to a higher temperature, resulting in fever. How might pyrogens cause the body temperature to rise?
The hypothalamus maintains the set point for body temperature through reflexes that cause
vasodilation and sweating when the body is too warm, or vasoconstriction and shivering when the body is too cold. It responds to chemicals from the body. When a bacterium is destroyed by phagocytic leukocytes, chemicals called endogenous pyrogens are released into the blood. These pyrogens circulate to the hypothalamus and reset the thermostat. This allows the body’s temperature to increase in what is commonly called a fever. An increase in body temperature causes iron to be conserved, which reduces a nutrient needed by bacteria. An increase in body heat also increases the activity of the animal’s enzymes and protective cells while inhibiting the enzymes and activity of the invading microorganisms. Finally, heat itself may also kill the pathogen. A fever that was once thought to be a complication of an infection is now understood to be a normal defense mechanism.
Homeostasis is a dynamic equilibrium that is maintained in body tissues and organs. It is dynamic because it is constantly adjusting to the changes that the systems encounter. It is in equilibrium because body functions are kept within a normal range, with some fluctuations around a set point for the processes.
Exercises
Visual Connection Questions
Figure 10.21: State whether each of the following processes are regulated by a positive feedback loop or a negative feedback loop.
Figure 10.23: When bacteria are destroyed by leuckocytes, pyrogens are released into the blood. Pyrogens reset the body’s thermostat to a higher temperature, resulting in fever. How might pyrogens cause the body temperature to rise?
Review Questions
When faced with a sudden drop in environmental temperature, an endothermic animal will:
Which is an example of negative feedback?
Which method of heat exchange occurs during direct contact between the source and animal?
The body’s thermostat is located in the ________.
Which of the following is not true about acclimatization?
Which of the following is not a way that ectotherms can change their body temperatures?
Critical Thinking Questions
Glossary
Chapter 33 in OpenStax Concepts of Biology 2E

The daily intake recommendation for human water consumption is eight to ten glasses of water. In order to achieve a healthy balance, the human body should excrete the eight to ten glasses of water every day. This occurs via the processes of urination, defecation, sweating and, to a small extent, respiration. The organs and tissues of the human body are soaked in fluids that are maintained at constant temperature, pH, and solute concentration, all crucial elements of homeostasis. The solutes in body fluids are mainly mineral salts and sugars, and osmotic regulation is the process by which the mineral salts and water are kept in balance. Osmotic homeostasis is maintained despite the influence of external factors like temperature, diet, and weather conditions.
Chapter 41 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Osmosis is the diffusion of water across a membrane in response to osmotic pressure caused by an imbalance of molecules on either side of the membrane. Osmoregulation is the process of maintenance of salt and water balance (osmotic balance) across membranes within the body’s fluids, which are composed of water, plus electrolytes and non-electrolytes. An electrolyte is a solute that dissociates into ions when dissolved in water. A non-electrolyte, in contrast, doesn’t dissociate into ions during water dissolution. Both electrolytes and non-electrolytes contribute to the osmotic balance. The body’s fluids include blood plasma, the cytosol within cells, and interstitial fluid, the fluid that exists in the spaces between cells and tissues of the body. The membranes of the body (such as the pleural, serous, and cell membranes) are semi-permeable membranes. Semi-permeable membranes are permeable (or permissive) to certain types of solutes and water. Solutions on two sides of a semi-permeable membrane tend to equalize in solute concentration by movement of solutes and/or water across the membrane. As seen in Figure 11.2, a cell placed in water tends to swell due to gain of water from the hypotonic or “low salt” environment. A cell placed in a solution with higher salt concentration, on the other hand, tends to make the membrane shrivel up due to loss of water into the hypertonic or “high salt” environment. Isotonic cells have an equal concentration of solutes inside and outside the cell; this equalizes the osmotic pressure on either side of the cell membrane which is a semi-permeable membrane.
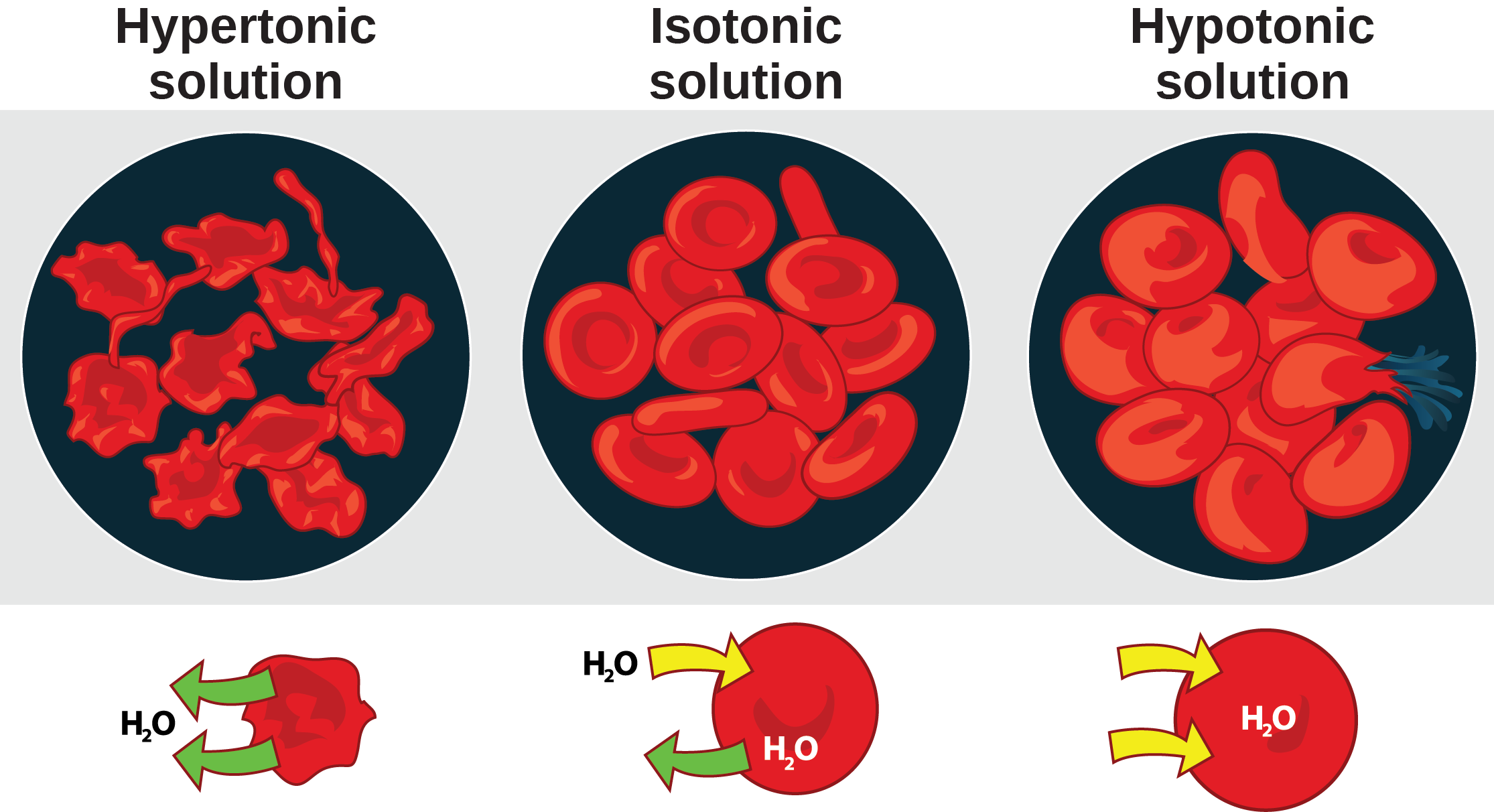
The body does not exist in isolation. There is a constant input of water and electrolytes into the system. While osmoregulation is achieved across membranes within the body, excess electrolytes and wastes are transported to the kidneys and excreted, helping to maintain osmotic balance.
Biological systems constantly interact and exchange water and nutrients with the environment by way of consumption of food and water and through excretion in the form of sweat, urine, and feces. Without a mechanism to regulate osmotic pressure, or when a disease damages this mechanism, there is a tendency to accumulate toxic waste and water, which can have dire consequences.
Mammalian systems have evolved to regulate not only the overall osmotic pressure across membranes, but also specific concentrations of important electrolytes in the three major fluid compartments: blood plasma, extracellular fluid, and intracellular fluid. Since osmotic pressure is regulated by the movement of water across membranes, the volume of the fluid compartments can also change temporarily. Because blood plasma is one of the fluid components, osmotic pressures have a direct bearing on blood pressure.
Electrolytes, such as sodium chloride, ionize in water, meaning that they dissociate into their component ions. In water, sodium chloride (NaCl), dissociates into the sodium ion (Na+) and the chloride ion (Cl–). The most important ions, whose concentrations are
very closely regulated in body fluids, are the cations sodium (Na+), potassium (K+), calcium (Ca+2),
magnesium (Mg+2), and the anions chloride (Cl–), carbonate (CO3-2), bicarbonate (HCO3–), and phosphate(PO3–). Electrolytes are lost from the body during urination and perspiration. For this
reason, athletes are encouraged to replace electrolytes and fluids during periods of increased activity and perspiration.
Osmotic pressure is influenced by the concentration of solutes in a solution. It is directly proportional to
the number of solute atoms or molecules and not dependent on the size of the solute molecules. Because electrolytes dissociate into their component ions, they, in essence, add more solute particles into the solution and have a greater effect on osmotic pressure, per mass than compounds that do not dissociate in water, such as glucose.
Water can pass through membranes by passive diffusion. If electrolyte ions could passively diffuse across membranes, it would be impossible to maintain specific concentrations of ions in each fluid compartment therefore they require special mechanisms to cross the semi-permeable membranes in the body. This movement can be accomplished by facilitated diffusion and active transport. Facilitated diffusion requires protein-based channels for moving the solute. Active transport requires energy in the form of ATP conversion, carrier proteins, or pumps in order to move ions against the concentration gradient.
In order to calculate osmotic pressure, it is necessary to understand how solute concentrations are measured. The unit for measuring solutes is the mole. One mole is defined as the gram molecular weight of the solute. For example, the molecular weight of sodium chloride is 58.44. Thus, one mole of sodium chloride weighs 58.44 grams. The molarity of a solution is the number of moles of solute per liter of solution. The molality of a solution is the number of moles of solute per kilogram of solvent. If the solvent is water, one kilogram of water is equal to one liter of water. While molarity and molality are used to express the concentration of solutions, electrolyte concentrations are usually expressed in terms of milliequivalents per liter (mEq/L): the mEq/L is equal to the ion concentration (in millimoles) multiplied by the number of electrical charges on the ion. The unit of milliequivalent takes into consideration the ions present in the solution (since electrolytes form ions in aqueous solutions) and the charge on the ions.
Thus, for ions that have a charge of one, one milliequivalent is equal to one millimole. For ions that have a charge of two (like calcium), one milliequivalent is equal to 0.5 millimoles. Another unit for the expression of electrolyte concentration is the milliosmole (mOsm), which is the number of milliequivalents of solute per kilogram of solvent. Body fluids are usually maintained within the range of 280 to 300 mOsm.
Persons lost at sea without any freshwater to drink are at risk of severe dehydration because the human body cannot adapt to drinking seawater, which is hypertonic in comparison to body fluids. Organisms such as goldfish that can tolerate only a relatively narrow range of salinity are referred to as stenohaline. About 90 percent of all bony fish are restricted to either freshwater or seawater. They are incapable of osmotic regulation in the opposite environment. It is possible, however, for a few fishes like salmon to spend part of their life in freshwater and part in seawater. Organisms like the salmon and molly that can tolerate a relatively wide range of salinity are referred to as euryhaline organisms. This is possible because some fish have evolved osmoregulatory mechanisms to survive in all kinds of aquatic environments. When they live in freshwater, their bodies tend to take up water because the environment is relatively hypotonic, as illustrated in Figure 11.3 a. In such hypotonic environments, these fish do not drink much water. Instead, they pass a lot of very dilute urine, and they achieve electrolyte balance by active transport of salts through the gills. When they move to a hypertonic marine environment, these fish start drinking seawater; they excrete the excess salts through their gills and their urine, as illustrated in b. Most marine invertebrates, on the other hand, may be isotonic with seawater (osmoconformers). Their body fluid concentrations conform to changes in seawater concentration. Cartilaginous fishes’ salt composition of the blood is similar to bony fishes; however, the blood of sharks contains the organic compounds urea and trimethylamine oxide (TMAO). This does not mean that their electrolyte composition is similar to that of seawater. They achieve isotonicity with the sea by storing large concentrations of urea. These animals that secrete urea are called ureotelic animals. TMAO stabilizes proteins in the presence of high urea levels, preventing the disruption of peptide bonds that would occur in other animals exposed to similar levels of urea. Sharks are cartilaginous fish with a rectal gland to secrete salt and assist in osmoregulation.
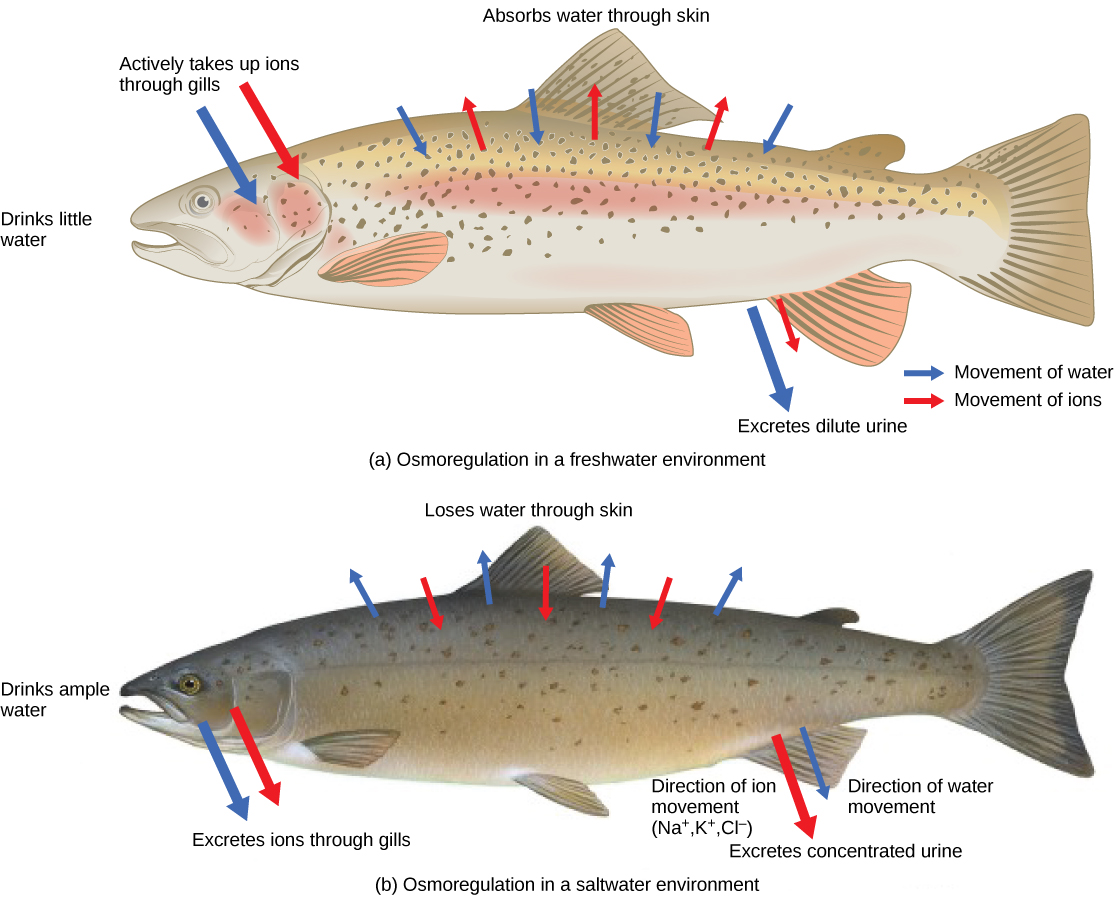
Dialysis is a medical process of removing wastes and excess water from the blood by diffusion and ultrafiltration. When kidney function fails, dialysis must be done to artificially rid the body of wastes. This is a vital process to keep patients alive. In some cases, the patients undergo artificial dialysis until they are eligible for a kidney transplant. In others who are not candidates for kidney transplants, dialysis is a life-long necessity.
Dialysis technicians typically work in hospitals and clinics. While some roles in this field include equipment development and maintenance, most dialysis technicians work in direct patient care. Their on-the-job duties, which typically occur under the direct supervision of a registered nurse, focus on providing dialysis treatments. This can include reviewing patient history and current condition, assessing and responding to patient needs before and during treatment, and monitoring the dialysis process. Treatment may include taking and reporting a patient’s vital signs and preparing solutions and equipment to ensure accurate and sterile procedures.
Solute concentrations across semi-permeable membranes influence the movement of water and solutes across the membrane. It is the number of solute molecules and not the molecular size that is important in osmosis. Osmoregulation and osmotic balance are important bodily functions, resulting in water and salt balance. Not all solutes can pass through a semi-permeable membrane. Osmosis is the movement of water across the membrane. Osmosis occurs to equalize the number of solute molecules across a semi-permeable membrane by the movement of water to the side of higher solute concentration. Facilitated diffusion utilizes protein channels to move solute molecules from areas of higher to lower concentration while active transport mechanisms are required to move solutes against concentration gradients. Osmolarity is measured in units of milliequivalents or milliosmoles, both of which take into consideration the number of solute particles and the charge on them. Fish that live in freshwater or saltwater adapt by being osmoregulators or osmoconformers.
Exercises
Review Questions
When a dehydrated human patient needs to be given fluids intravenously, he or she is given:
The sodium ion is at the highest concentration in:
Cells in a hypertonic solution tend to:
Critical Thinking Questions
Glossary
Chapter 41 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Although the kidneys are the major osmoregulatory organ, the skin and lungs also play a role in the process. Water and electrolytes are lost through sweat glands in the skin, which helps moisturize and cool the skin surface, while the lungs expel a small amount of water in the form of mucous secretions and via evaporation of water vapor.
The kidneys, illustrated in Figure 11.4, are a pair of bean-shaped structures that are located just below and posterior to the liver in the peritoneal cavity. The adrenal glands sit on top of each kidney and are also called the suprarenal glands. Kidneys filter blood and purify it. All the blood in the human body is filtered many times a day by the kidneys; these organs use up almost 25 percent of the oxygen absorbed through the lungs to perform this function. Oxygen allows the kidney cells to efficiently manufacture chemical energy in the form of ATP through aerobic respiration. The filtrate coming out of the kidneys is called urine.
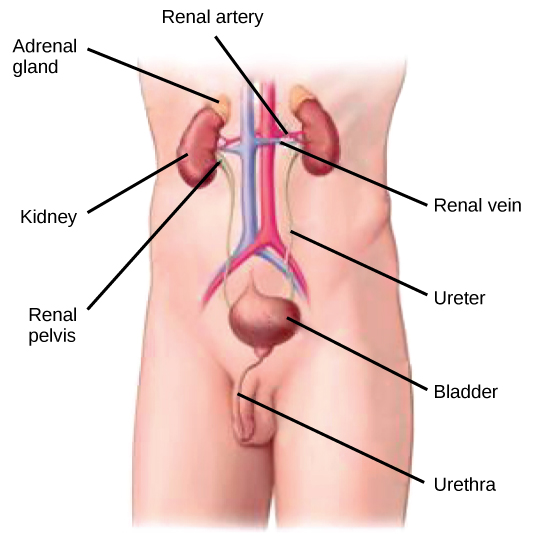
Externally, the kidneys are surrounded by three layers, illustrated in Figure 11.5. The outermost layer is a tough connective tissue layer called the renal fascia. The second layer is called the perirenal fat capsule, which helps anchor the kidneys in place. The third and innermost layer is the renal capsule. Internally, the kidney has three regions—an outer cortex, a medulla in the middle, and the renal pelvis in the region called the hilum of the kidney. The hilum is the concave part of the bean-shape where blood vessels and nerves enter and exit the kidney; it is also the point of exit for the ureters. The renal cortex is granular due to the presence of nephrons—the functional unit of the kidney. The medulla consists of multiple pyramidal tissue masses, called the renal pyramids. In between the pyramids are spaces called renal columns through which the blood vessels pass. The tips of the pyramids, called renal papillae, point toward the renal pelvis. There are, on average, eight renal pyramids in each kidney. The renal pyramids along with the adjoining cortical region are called the lobes of the kidney. The renal pelvis leads to the ureter on the outside of the kidney. On the inside of the kidney, the renal pelvis branches out into two or three extensions called the major calyces, which further branch into the minor calyces. The ureters are urine-bearing tubes that exit the kidney and empty into the urinary bladder.
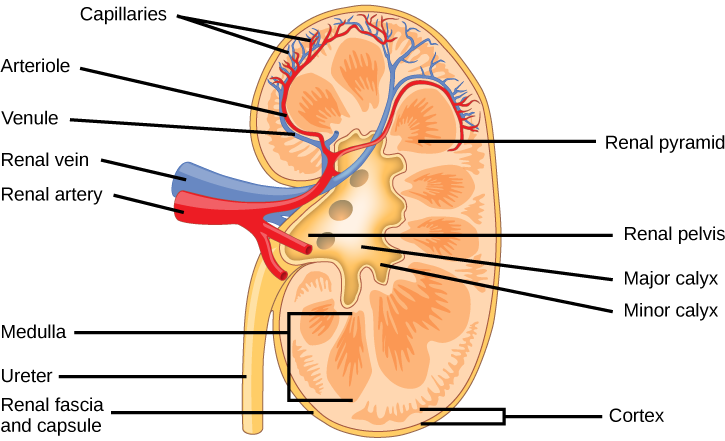
Which of the following statements about the kidney is false?
Because the kidney filters blood, its network of blood vessels is an important component of its structure and function. The arteries, veins, and nerves that supply the kidney enter and exit at the renal hilum. Renal blood supply starts with the branching of the aorta into the renal arteries (which are each named based on the region of the kidney they pass through) and ends with the exiting of the renal veins to join the inferior vena cava. The renal arteries split into several segmental arteries upon entering the kidneys. Each segmental artery splits further into several interlobar arteries and enters the renal columns, which supply the renal lobes. The interlobar arteries split at the junction of the renal cortex and medulla to form the arcuate arteries. The arcuate “bow shaped” arteries form arcs along the base of the medullary pyramids. Cortical radiate arteries, as the name suggests, radiate out from the arcuate arteries. The cortical radiate arteries branch into numerous afferent arterioles, and then enter the capillaries supplying the nephrons. Veins trace the path of the arteries and have similar names, except there are no segmental veins.
As mentioned previously, the functional unit of the kidney is the nephron, illustrated in Figure 11.6. Each kidney is made up of over one million nephrons that dot the renal cortex, giving it a granular appearance when sectioned sagittally. There are two types of nephrons—cortical nephrons (85 percent), which are deep in the renal cortex, and juxtamedullary nephrons (15 percent), which lie in the renal cortex close to the renal medulla. A nephron consists of three parts—a renal corpuscle, a renal tubule, and the associated capillary network, which originates from the cortical radiate arteries.
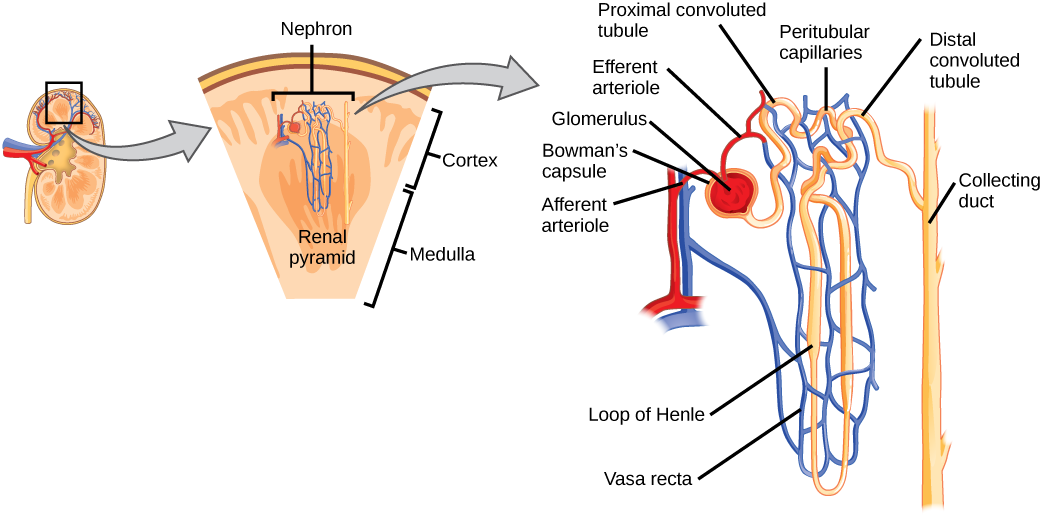
Which of the following statements about the nephron is false?
The renal corpuscle, located in the renal cortex, is made up of a network of capillaries known as the glomerulus and the capsule, a cup-shaped chamber that surrounds it, called the glomerular or Bowman’s capsule.
The renal tubule is a long and convoluted structure that emerges from the glomerulus and can be divided into three parts based on function. The first part is called the proximal convoluted tubule (PCT) due to its proximity to the glomerulus; it stays in the renal cortex. The second part is called the loop of Henle, or nephritic loop, because it forms a loop (with descending and ascending limbs) that goes through the renal medulla. The third part of the renal tubule is called the distal convoluted tubule (DCT) and this part is also restricted to the renal cortex. The DCT, which is the last part of the nephron, connects and empties its contents into collecting ducts that line the medullary pyramids. The collecting ducts amass contents from multiple nephrons and fuse together as they enter the papillae of the renal medulla.
The capillary network that originates from the renal arteries supplies the nephron with blood that needs to be filtered. The branch that enters the glomerulus is called the afferent arteriole. The branch that exits the glomerulus is called the efferent arteriole. Within the glomerulus, the network of capillaries is called the glomerular capillary bed. Once the efferent arteriole exits the glomerulus, it forms the peritubular capillary network, which surrounds and interacts with parts of the renal tubule. In cortical nephrons, the peritubular capillary network surrounds the PCT and DCT. In juxtamedullary nephrons, the peritubular capillary network forms a network around the loop of Henle and is called the vasa recta.
Go to the website Interactive Human to see another coronal section of the kidney and to explore an animation of the workings of nephrons.
Kidneys filter blood in a three-step process. First, the nephrons filter blood that runs through the capillary network in the glomerulus. Almost all solutes, except for proteins, are filtered out into the glomerulus by a process called glomerular filtration. Second, the filtrate is collected in the renal tubules. Most of the solutes get reabsorbed in the PCT by a process called tubular reabsorption. In the loop of Henle, the filtrate continues to exchange solutes and water with the renal medulla and the peritubular capillary network. Water is also reabsorbed during this step. Then, additional solutes and wastes are secreted into the kidney tubules during tubular secretion, which is, in essence, the opposite process to tubular reabsorption. The collecting ducts collect filtrate coming from the nephrons and fuse in the medullary papillae. From here, the papillae deliver the filtrate, now called urine, into the minor calyces that eventually connect to the ureters through the renal pelvis. This entire process is illustrated in Figure 11.7.
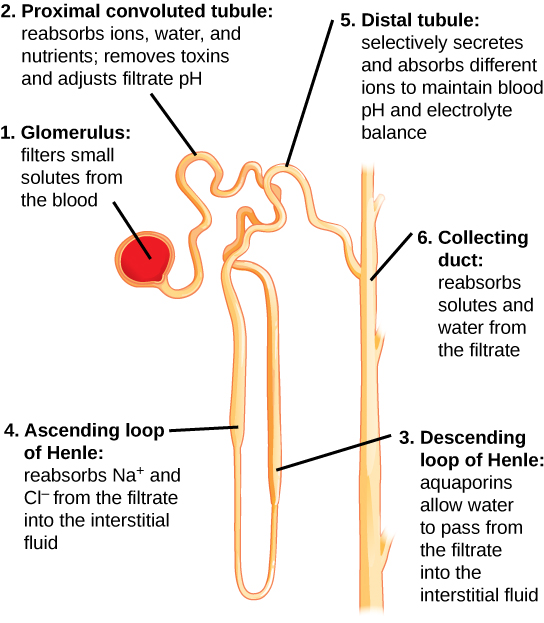
Glomerular filtration filters out most of the solutes due to high blood pressure and specialized membranes in the afferent arteriole. The blood pressure in the glomerulus is maintained independent of factors that affect systemic blood pressure. The “leaky” connections between the endothelial cells of the glomerular capillary network allow solutes to pass through easily. All solutes in the glomerular capillaries, except for macromolecules like proteins, pass through by passive diffusion. There is no energy requirement at this stage of the filtration process. Glomerular filtration rate (GFR) is the volume of glomerular filtrate formed per minute by the kidneys. GFR is regulated by multiple mechanisms and is an important indicator of kidney function.
To learn more watch the interactive review The Vascular System of the Kidneys By Becky Polk-Pohlman.
Tubular reabsorption occurs in the PCT part of the renal tubule. Almost all nutrients are reabsorbed, and this occurs either by passive or active transport. Reabsorption of water and some key electrolytes are regulated and can be influenced by hormones. Sodium (Na+) is the most abundant ion and most of it is reabsorbed by active transport and then transported to the peritubular capillaries. Because Na+ is actively transported out of the tubule, water follows it to even out the osmotic pressure. Water is also independently reabsorbed into the peritubular capillaries due to the presence of aquaporins, or water channels, in the PCT. This occurs due to the low blood pressure and high osmotic pressure in the peritubular capillaries. However, every solute has a transport maximum and the excess is not reabsorbed.
In the loop of Henle, the permeability of the membrane changes. The descending limb is permeable to water, not solutes; the opposite is true for the ascending limb. Additionally, the loop of Henle invades the renal medulla, which is naturally high in salt concentration and tends to absorb water from the renal tubule and concentrate the filtrate. The osmotic gradient increases as it moves deeper into the medulla. Because two sides of the loop of Henle perform opposing functions, as illustrated in Figure 11.8, it acts as a countercurrent multiplier. The vasa recta around it acts as the countercurrent exchanger.
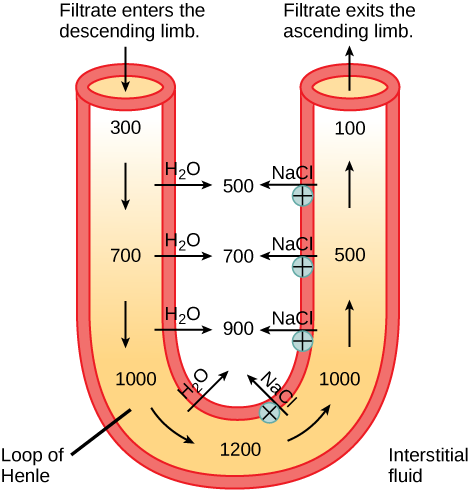
Loop diuretics are drugs sometimes used to treat hypertension. These drugs inhibit the reabsorption of Na+ and Cl– ions by the ascending limb of the loop of Henle. A side effect is that they increase urination. Why do you think this is the case?
By the time the filtrate reaches the DCT, most of the urine and solutes have been reabsorbed. If the body requires additional water, all of it can be reabsorbed at this point. Further reabsorption is controlled by hormones, which will be discussed in a later section. Excretion of wastes occurs due to lack of reabsorption combined with tubular secretion. Undesirable products like metabolic wastes, urea, uric acid, and certain drugs, are excreted by tubular secretion. Most of the tubular secretion happens in the DCT, but some occurs in the early part of the collecting duct. Kidneys also maintain an acid-base balance by secreting excess H+ ions.
Although parts of the renal tubules are named proximal and distal, in a cross-section of the kidney, the tubules are placed close together and in contact with each other and the glomerulus. This allows for exchange of chemical messengers between the different cell types. For example, the DCT ascending limb of the loop of Henle has masses of cells called macula densa, which are in contact with cells of the afferent arterioles called juxtaglomerular cells. Together, the macula densa and juxtaglomerular cells form the juxtaglomerular complex (JGC). The JGC is an endocrine structure that secretes the enzyme renin and the hormone erythropoietin. When hormones trigger the macula densa cells in the DCT due to variations in blood volume, blood pressure, or electrolyte balance, these cells can immediately communicate the problem to the capillaries in the afferent and efferent arterioles, which can constrict or relax to change the glomerular filtration rate of the kidneys.
A nephrologist studies and deals with diseases of the kidneys—both those that cause kidney failure (such as diabetes) and the conditions that are produced by kidney disease (such as hypertension). Blood pressure, blood volume, and changes in electrolyte balance come under the purview of a nephrologist.
Nephrologists usually work with other physicians who refer patients to them or consult with them about specific diagnoses and treatment plans. Patients are usually referred to a nephrologist for symptoms such as blood or protein in the urine, very high blood pressure, kidney stones, or renal failure.
Nephrology is a subspecialty of internal medicine. To become a nephrologist, medical school is followed by additional training to become certified in internal medicine. An additional two or more years is spent specifically studying kidney disorders and their accompanying effects on the body.
The kidneys are the main osmoregulatory organs in mammalian systems; they function to filter blood and maintain the osmolarity of body fluids at 300 mOsm. They are surrounded by three layers and are made up internally of three distinct regions—the cortex, medulla, and pelvis.
The blood vessels that transport blood into and out of the kidneys arise from and merge with the aorta and inferior vena cava, respectively. The renal arteries branch out from the aorta and enter the kidney where they further divide into segmental, interlobar, arcuate, and cortical radiate arteries.
The nephron is the functional unit of the kidney, which actively filters blood and generates urine. The nephron is made up of the renal corpuscle and renal tubule. Cortical nephrons are found in the renal cortex, while juxtamedullary nephrons are found in the renal cortex close to the renal medulla. The nephron filters and exchanges water and solutes with two sets of blood vessels and the tissue fluid in the kidneys.
There are three steps in the formation of urine: glomerular filtration, which occurs in the glomerulus; tubular reabsorption, which occurs in the renal tubules; and tubular secretion, which also occurs in the renal tubules.
Exercises
Visual Connection Questions
Figure 11.5 : Which of the following statements about the kidney is false?
Figure 11.6 : Which of the following statements about the nephron is false?
Figure 11.8 : Loop diuretics are drugs sometimes used to treat hypertension. These drugs inhibit the reabsorption of Na+ and Cl– ions by the ascending limb of the loop of Henle. A side effect is that they increase urination. Why do you think this is the case?
Review Questions
The macula densa is/are:
The osmolarity of body fluids is maintained at ________.
The gland located at the top of the kidney is the ________ gland.
Critical Thinking Questions
Glossary
Chapter 33 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Microorganisms and invertebrate animals use more primitive and simple mechanisms to get rid of their metabolic wastes than the mammalian system of kidney and urinary function. Three excretory systems evolved in organisms before complex kidneys: vacuoles, flame cells, and Malpighian tubules.
The most fundamental feature of life is the presence of a cell. In other words, a cell is the simplest functional unit of a life. Bacteria are unicellular, prokaryotic organisms that have some of the least complex life processes in place; however, prokaryotes such as bacteria do not contain membrane-bound vacuoles. The cells of microorganisms like bacteria, protozoa, and fungi are bound by cell membranes and use them to interact with the environment. Some cells, including some leucocytes in humans, are able to engulf food by endocytosis—the formation of vesicles by involution of the cell membrane within the cells. The same vesicles are able to interact and exchange metabolites with the intracellular environment. In some unicellular eukaryotic organisms such as the amoeba, shown in Figure 11.9, cellular wastes and excess water are excreted by exocytosis, when the contractile vacuoles merge with the cell membrane and expel wastes into the environment. Contractile vacuoles (CV) should not be confused with vacuoles, which store food or water.
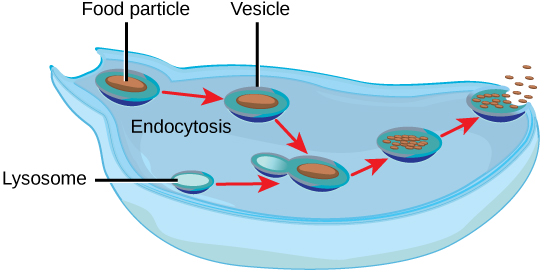
As multicellular systems evolved to have organ systems that divided the metabolic needs of the body, individual organs evolved to perform the excretory function. Planaria are flatworms that live in freshwater. Their excretory system consists of two tubules connected to a highly branched duct system. The cells in the tubules are called flame cells (or protonephridia) because they have a cluster of cilia that looks like a flickering flame when viewed under the microscope, as illustrated in Figure 11.10a. The cilia propel waste matter down the tubules and out of the body through excretory pores that open on the body surface; cilia also draw water from the interstitial fluid, allowing for filtration. Any valuable metabolites are recovered by reabsorption. Flame cells are found in flatworms, including parasitic tapeworms and free-living planaria. They also maintain the organism’s osmotic balance.
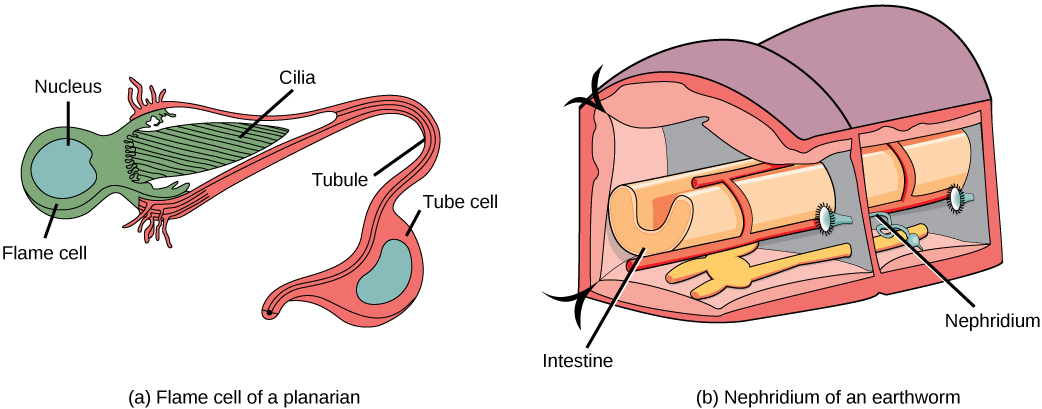
Earthworms (annelids) have slightly more evolved excretory structures called nephridia, illustrated in Figure 11.10b. A pair of nephridia is present on each segment of the earthworm. They are similar to flame cells in that they have a tubule with cilia. Excretion occurs through a pore called the nephridiopore. They are more evolved than the flame cells in that they have a system for tubular reabsorption by a capillary network before excretion.
Malpighian tubules are found lining the gut of some species of arthropods, such as the bee illustrated in Figure 11.11. They are usually found in pairs and the number of tubules varies with the species of insect. Malpighian tubules are convoluted, which increases their surface area, and they are lined with microvilli for reabsorption and maintenance of osmotic balance. Malpighian tubules work cooperatively with specialized glands in the wall of the rectum. Body fluids are not filtered as in the case of nephridia; urine is produced by tubular secretion mechanisms by the cells lining the Malpighian tubules that are bathed in hemolymph (a mixture of blood and interstitial fluid that is found in insects and other arthropods as well as most mollusks). Metabolic wastes like uric acid freely diffuse into the tubules. There are exchange pumps lining the tubules, which actively transport H+ ions into the cell and K+ or Na+ ions out; water passively follows to form urine. The secretion of ions alters the osmotic pressure which draws water, electrolytes, and nitrogenous waste (uric acid) into the tubules. Water and electrolytes are reabsorbed when these organisms are faced with low-water environments, and uric acid is excreted as a thick paste or powder. Not dissolving wastes in water helps these organisms to conserve water; this is especially important for life in dry environments.
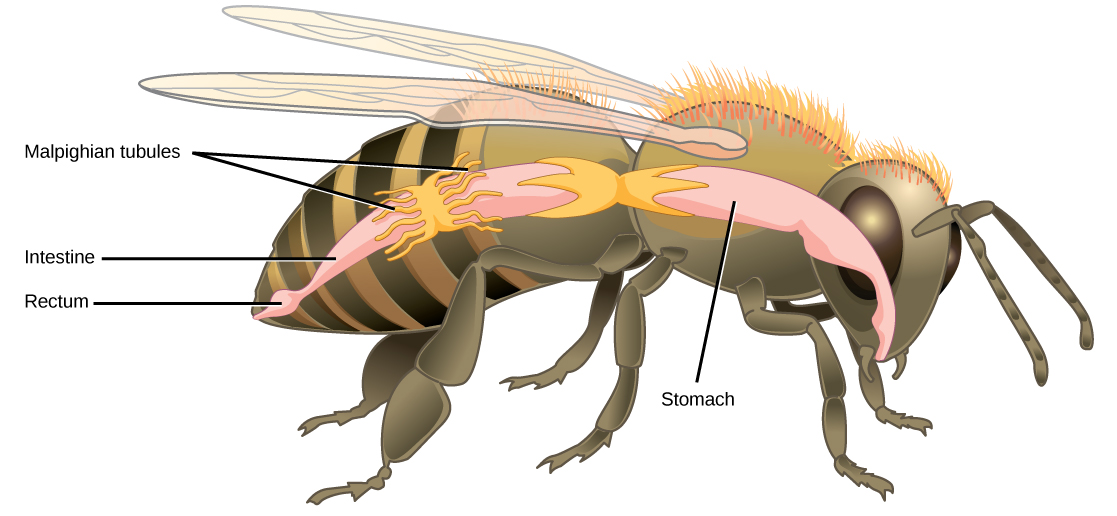
See a dissected cockroach, including a close-up look at its Malpighian tubules, in this video.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=656
Many systems have evolved for excreting wastes that are simpler than the kidney and urinary systems of vertebrate animals. The simplest system is that of contractile vacuoles present in microorganisms. Flame cells and nephridia in worms perform excretory functions and maintain osmotic balance. Some insects have evolved Malpighian tubules to excrete wastes and maintain osmotic balance.
Exercises
Review Questions
Active transport of K+ in Malpighian tubules ensures that:
Contractile vacuoles in microorganisms:
Flame cells are primitive excretory organs found in ________.
Critical Thinking Questions
Glossary
Chapter 33 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Of the four major macromolecules in biological systems, both proteins and nucleic acids contain nitrogen. During the catabolism, or breakdown, of nitrogen-containing macromolecules, carbon, hydrogen, and oxygen are extracted and stored in the form of carbohydrates and fats. Excess nitrogen is excreted from the body. Nitrogenous wastes tend to form toxic ammonia, which raises the pH of body fluids. The formation of ammonia itself requires energy in the form of ATP and large quantities of water to dilute it out of a biological system. Animals that live in aquatic environments tend to release ammonia into the water. Animals that excrete ammonia are said to be ammonotelic. Terrestrial organisms have evolved other mechanisms to excrete nitrogenous wastes. The animals must detoxify ammonia by converting it into a relatively nontoxic form such as urea or uric acid. Mammals, including humans, produce urea, whereas reptiles and many terrestrial invertebrates produce uric acid. Animals that secrete urea as the primary nitrogenous waste material are called ureotelic animals.
The urea cycle is the primary mechanism by which mammals convert ammonia to urea. Urea is made in the liver and excreted in urine. The overall chemical reaction by which ammonia is converted to urea is 2 NH3 (ammonia) + CO2 + 3 ATP + H2O → H2N-CO-NH2 (urea) + 2 ADP + 4 Pi + AMP.
The urea cycle utilizes five intermediate steps, catalyzed by five different enzymes, to convert ammonia to urea, as shown in Figure 11.12. The amino acid L-ornithine gets converted into different intermediates before being regenerated at the end of the urea cycle. Hence, the urea cycle is also referred to as the ornithine cycle. The enzyme ornithine transcarbamylase catalyzes a key step in the urea cycle and its deficiency can lead to accumulation of toxic levels of ammonia in the body. The first two reactions occur in the mitochondria and the last three reactions occur in the cytosol. Urea concentration in the blood, called blood urea nitrogen or BUN, is used as an indicator of kidney function.
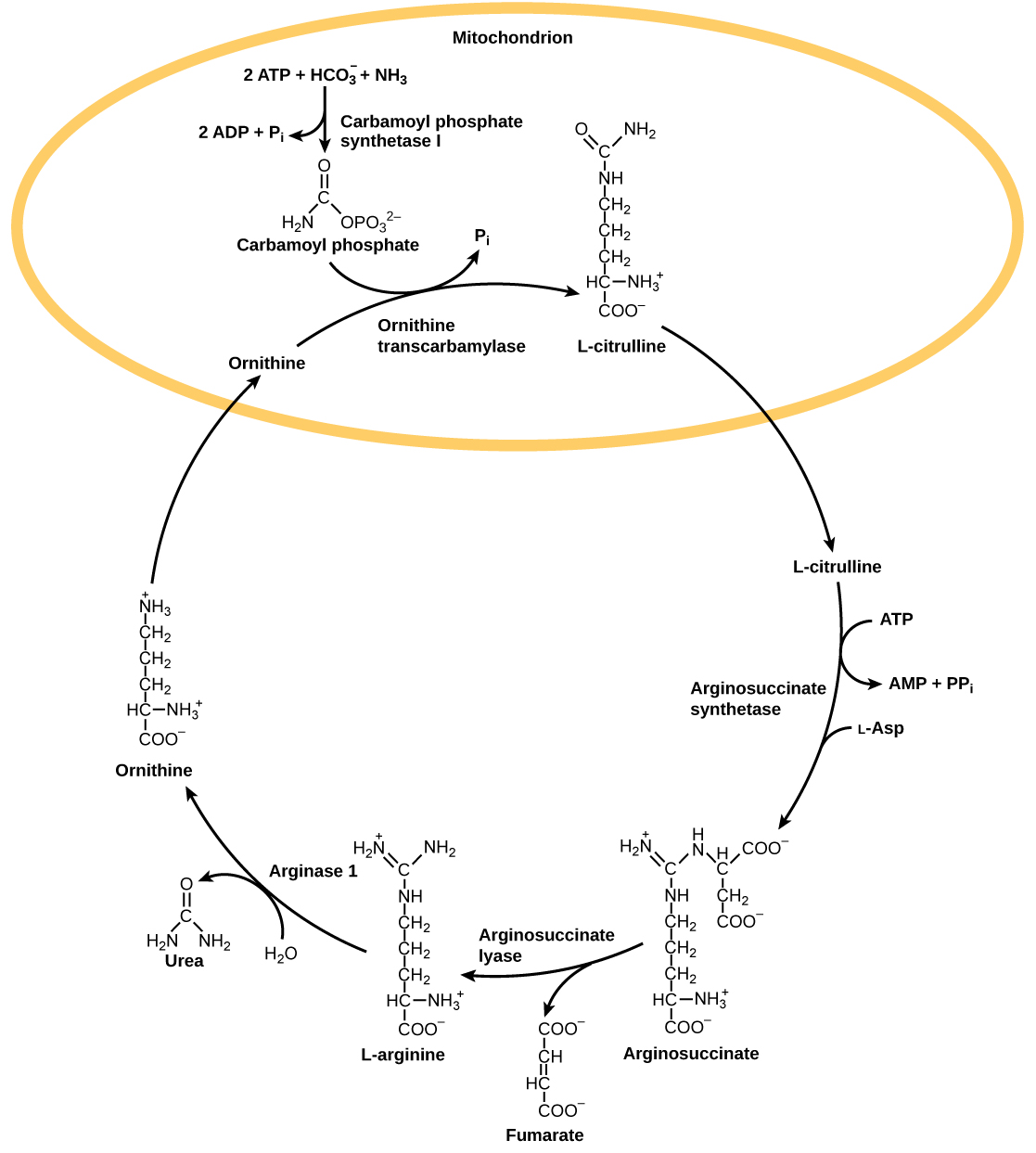
The theory of evolution proposes that life started in an aquatic environment. It is not surprising to see that biochemical pathways like the urea cycle evolved to adapt to a changing environment when terrestrial life forms evolved. Arid conditions probably led to the evolution of the uric acid pathway as a means of conserving water.
Birds, reptiles, and most terrestrial arthropods convert toxic ammonia to uric acid or the closely related compound guanine (guano) instead of urea. Mammals also form some uric acid during breakdown of nucleic acids. Uric acid is a compound similar to purines found in nucleic acids. It is water insoluble and tends to form a white paste or powder; it is excreted by birds, insects, and reptiles. Conversion of ammonia to uric acid requires more energy and is much more complex than conversion of ammonia to urea Figure 11.13.
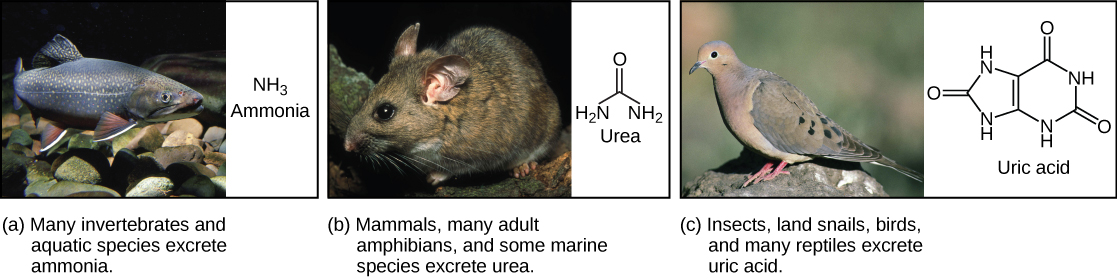
Mammals use uric acid crystals as an antioxidant in their cells. However, too much uric acid tends to form kidney stones and may also cause a painful condition called gout, where uric acid crystals accumulate in the joints, as illustrated in Figure 11.14. Food choices that reduce the amount of nitrogenous bases in the diet help reduce the risk of gout. For example, tea, coffee, and chocolate have purine-like compounds, called xanthines, and should be avoided by people with gout and kidney stones.
Ammonia is the waste produced by metabolism of nitrogen-containing compounds like proteins and nucleic acids. While aquatic animals can easily excrete ammonia into their watery surroundings, terrestrial animals have evolved special mechanisms to eliminate the toxic ammonia from their systems. Urea is the major byproduct of ammonia metabolism in vertebrate animals. Uric acid is the major byproduct of ammonia metabolism in birds, terrestrial arthropods, and reptiles.
Exercises
Review Questions
BUN is ________.
Human beings accumulate ________ before excreting nitrogenous waste.
Critical Thinking Questions
Glossary
Chapter 33 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
While the kidneys operate to maintain osmotic balance and blood pressure in the body, they also act in concert with hormones. Hormones are small molecules that act as messengers within the body. Hormones are typically secreted from one cell and travel in the bloodstream to affect a target cell in another portion of the body. Different regions of the nephron bear specialized cells that have receptors to respond to chemical messengers and hormones. Table 11.1 summarizes the hormones that control the osmoregulatory functions.
| Table 11.1 Hormones That Affect Osmoregulation | ||
|---|---|---|
| Hormone | Where produced | Function |
| Epinephrine and Norepinephrine | Adrenal medulla | Can decrease kidney function temporarily by vasoconstriction |
| Renin | Kidney nephrons | Increases blood pressure by acting on angiotensinogen |
| Angiotensin | Liver | Angiotensin II affects multiple processes and increases blood pressure |
| Aldosterone | Adrenal cortex | Prevents loss of sodium and water |
| Anti-diuretic hormone (vasopressin) | Hypothalamus (stored in the posterior pituitary) | Prevents water loss |
| Atrial natriuretic peptide | Heart atrium | Decreases blood pressure by acting as a vasodilator and increasing glomerular filtration rate; decreases sodium reabsorption in kidneys |
Epinephrine and norepinephrine are released by the adrenal medulla and nervous system respectively. They are the flight/fight hormones that are released when the body is under extreme stress. During stress, much of the body’s energy is used to combat imminent danger. Kidney function is halted temporarily by epinephrine and norepinephrine. These hormones function by acting directly on the smooth muscles of blood vessels to constrict them. Once the afferent arterioles are constricted, blood flow into the nephrons stops. These hormones go one step further and trigger the renin-angiotensin-aldosterone system.
The renin-angiotensin-aldosterone system, illustrated in Figure 11.15 proceeds through several steps to produce angiotensin II, which acts to stabilize blood pressure and volume. Renin (secreted by a part of the juxtaglomerular complex) is produced by the granular cells of the afferent and efferent arterioles. Thus, the kidneys control blood pressure and volume directly. Renin acts on angiotensinogen, which is made in the liver and converts it to angiotensin I. Angiotensin converting enzyme (ACE) converts angiotensin I to angiotensin II. Angiotensin II raises blood pressure by constricting blood vessels. It also triggers the release of the mineralocorticoid aldosterone from the adrenal cortex, which in turn stimulates the renal tubules to reabsorb more sodium. Angiotensin II also triggers the release of anti-diuretic hormone (ADH) from the hypothalamus, leading to water retention in the kidneys. It acts directly on the nephrons and decreases glomerular filtration rate. Medically, blood pressure can be controlled by drugs that inhibit ACE (called ACE inhibitors).
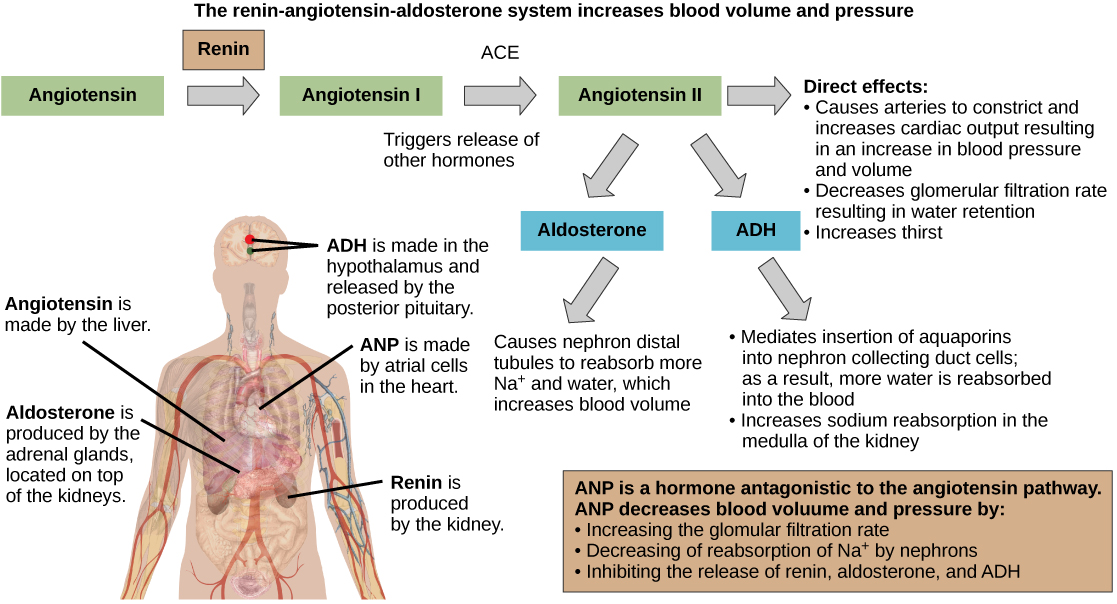
Mineralocorticoids are hormones synthesized by the adrenal cortex that affect osmotic balance. Aldosterone is a mineralocorticoid that regulates sodium levels in the blood. Almost all of the sodium in the blood is reclaimed by the renal tubules under the influence of aldosterone. Because sodium is always reabsorbed by active transport and water follows sodium to maintain osmotic balance, aldosterone manages not only sodium levels but also the water levels in body fluids. In contrast, the aldosterone also stimulates potassium secretion concurrently with sodium reabsorption. In contrast, absence of aldosterone means that no sodium gets reabsorbed in the renal tubules and all of it gets excreted in the urine. In addition, the daily dietary potassium load is not secreted and the retention of K+ can cause a dangerous increase in plasma K+ concentration. Patients who have Addison’s disease have a failing adrenal cortex and cannot produce aldosterone. They lose sodium in their urine constantly, and if the supply is not replenished, the consequences can be fatal.
As previously discussed, antidiuretic hormone or ADH (also called vasopressin), as the name suggests, helps the body conserve water when body fluid volume, especially that of blood, is low. It is formed by the hypothalamus and is stored and released from the posterior pituitary. It acts by inserting aquaporins in the collecting ducts and promotes reabsorption of water. ADH also acts as a vasoconstrictor and increases blood pressure during hemorrhaging.
The atrial natriuretic peptide (ANP) lowers blood pressure by acting as a vasodilator. It is released by cells in the atrium of the heart in response to high blood pressure and in patients with sleep apnea. ANP affects salt release, and because water passively follows salt to maintain osmotic balance, it also has a diuretic effect. ANP also prevents sodium reabsorption by the renal tubules, decreasing water reabsorption (thus acting as a diuretic) and lowering blood pressure. Its actions suppress the actions of aldosterone, ADH, and renin.
Hormonal cues help the kidneys synchronize the osmotic needs of the body. Hormones like epinephrine, norepinephrine, renin-angiotensin, aldosterone, anti-diuretic hormone, and atrial natriuretic peptide help regulate the needs of the body as well as the communication between the different organ systems.
Exercises
Review Questions
Renin is made by ________.
Patients with Addison’s disease ________.
Which hormone elicits the “fight or flight” response?
Critical Thinking Questions
Glossary
Chapter 33 in OpenStax Concepts of Biology 2E

All living organisms need nutrients to survive. While plants can obtain the molecules required for cellular function through the process of photosynthesis, most animals obtain their nutrients by the consumption of other organisms. At the cellular level, the biological molecules necessary for animal function are amino acids, lipid molecules, nucleotides, and simple sugars. However, the food consumed consists of protein, fat, and complex carbohydrates. Animals must convert these macromolecules into the simple molecules required for maintaining cellular functions, such as assembling new molecules, cells, and tissues. The conversion of the food consumed to the nutrients required is a multistep process involving digestion and absorption. During digestion, food particles are broken down to smaller components, and later, they are absorbed by the body.
One of the challenges in human nutrition is maintaining a balance between food intake, storage, and energy expenditure. Imbalances can have serious health consequences. For example, eating too much food while not expending much energy leads to obesity, which in turn will increase the risk of developing illnesses such as type-2 diabetes and cardiovascular disease. The recent rise in obesity and related diseases makes understanding the role of diet and nutrition in maintaining good health all the more important.
Chapter 34 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Animals obtain their nutrition from the consumption of other organisms. Depending on their diet, animals can be classified into the following categories: plant eaters (herbivores), meat eaters (carnivores), and those that eat both plants and animals (omnivores). The nutrients and macromolecules present in food are not immediately accessible to the cells. There are a number of processes that modify food within the animal body in order to make the nutrients and organic molecules accessible for cellular function. As animals evolved in complexity of form and function, their digestive systems have also evolved to accommodate their various dietary needs.
Herbivores are animals whose primary food source is plant-based. Examples of herbivores, as shown in Figure 12.2 include vertebrates like deer, koalas, and some bird species, as well as invertebrates such as crickets and caterpillars. These animals have evolved digestive systems capable of handling large amounts of plant material. Herbivores can be further classified into frugivores (fruit-eaters), granivores (seed eaters), nectivores (nectar feeders), and folivores (leaf eaters).

Carnivores are animals that eat other animals. The word carnivore is derived from Latin and literally means “meat eater.” Wild cats such as lions, shown in Figure 12.3 a and tigers are examples of vertebrate carnivores, as are snakes and sharks, while invertebrate carnivores include sea stars, spiders, and ladybugs, shown in Figure 12.3b. Obligate carnivores are those that rely entirely on animal flesh to obtain their nutrients; examples of obligate carnivores are members of the cat family, such as lions and cheetahs. Facultative carnivores are those that also eat non-animal food in addition to animal food. Note that there is no clear line that differentiates facultative carnivores from omnivores; dogs would be considered facultative carnivores.

Omnivores are animals that eat both plant- and animal-derived food. In Latin, omnivore means to eat everything. Humans, bears (shown in Figure 12.4a), and chickens are example of vertebrate omnivores; invertebrate omnivores include cockroaches and crayfish (shown in Figure 12.4b).

Animals have evolved different types of digestive systems to aid in the digestion of the different foods they consume. The simplest example is that of a gastrovascular cavity and is found in organisms with only one opening for digestion. Platyhelminthes (flatworms), Ctenophora (comb jellies), and Cnidaria (coral, jelly fish, and sea anemones) use this type of digestion. Gastrovascular cavities, as shown in Figure12.4a, are typically a blind tube or cavity with only one opening, the “mouth”, which also serves as an “anus”. Ingested material enters the mouth and passes through a hollow, tubular cavity. Cells within the cavity secrete digestive enzymes that breakdown the food. The food particles are engulfed by the cells lining the gastrovascular cavity.
The alimentary canal, shown in Figure12.4b, is a more advanced system: it consists of one tube with a mouth at one end and an anus at the other. Earthworms are an example of an animal with an alimentary canal. Once the food is ingested through the mouth, it passes through the esophagus and is stored in an organ called the crop; then it passes into the gizzard where it is churned and digested. From the gizzard, the food passes through the intestine, the nutrients are absorbed, and the waste is eliminated as feces, called castings, through the anus.
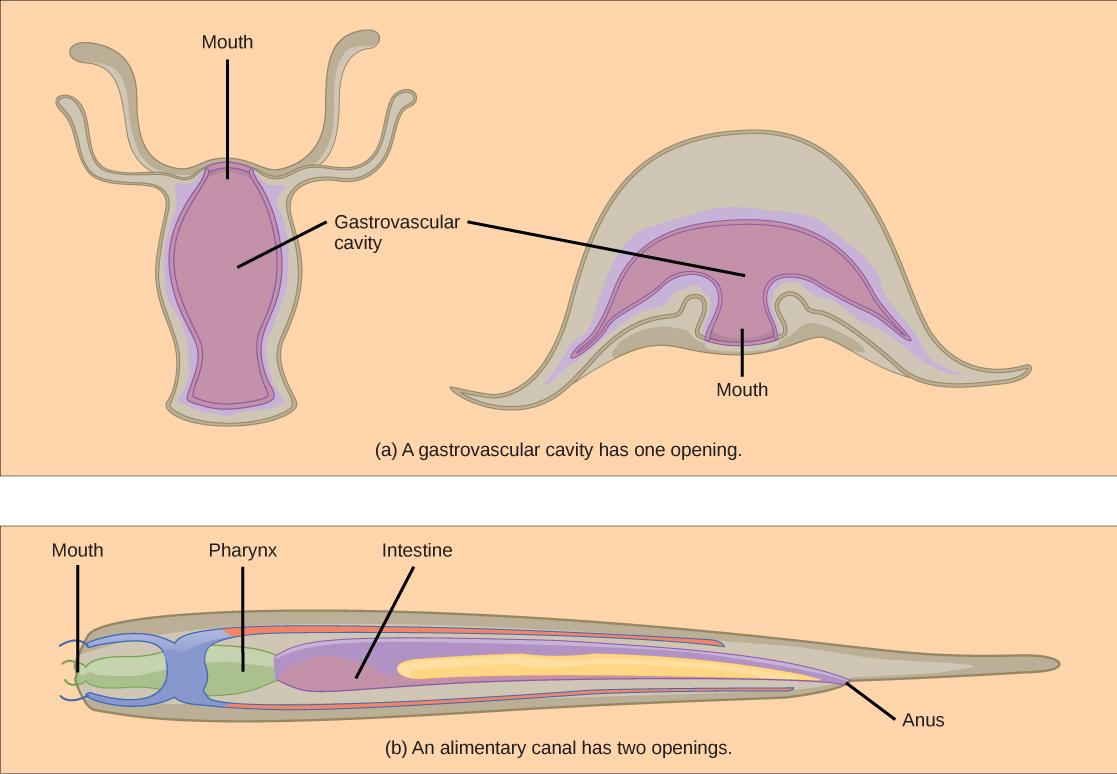
Vertebrates have evolved more complex digestive systems to adapt to their dietary needs. Some animals have a single stomach, while others have multi-chambered stomachs. Birds have developed a digestive system adapted to eating unmasticated food.
As the word monogastric suggests, this type of digestive system consists of one (“mono”) stomach chamber (“gastric”). Humans and many animals have a monogastric digestive system as illustrated in Figure12.6ab. The process of digestion begins with the mouth and the intake of food. The teeth play an important role in masticating (chewing) or physically breaking down food into smaller particles. The enzymes present in saliva also begin to chemically breakdown food. The esophagus is a long tube that connects the mouth to the stomach. Using peristalsis, or wave-like smooth muscle contractions, the muscles of the esophagus push the food towards the stomach. In order to speed up the actions of enzymes in the stomach, the stomach is an extremely acidic environment, with a pH between 1.5 and 2.5. The gastric juices, which include enzymes in the stomach, act on the food particles and continue the process of digestion. Further breakdown of food takes place in the small intestine where enzymes produced by the liver, the small intestine, and the pancreas continue the process of digestion. The nutrients are absorbed into the bloodstream across the epithelial cells lining the walls of the small intestines. The waste material travels on to the large intestine where water is absorbed and the drier waste material is compacted into feces; it is stored until it is excreted through the rectum.
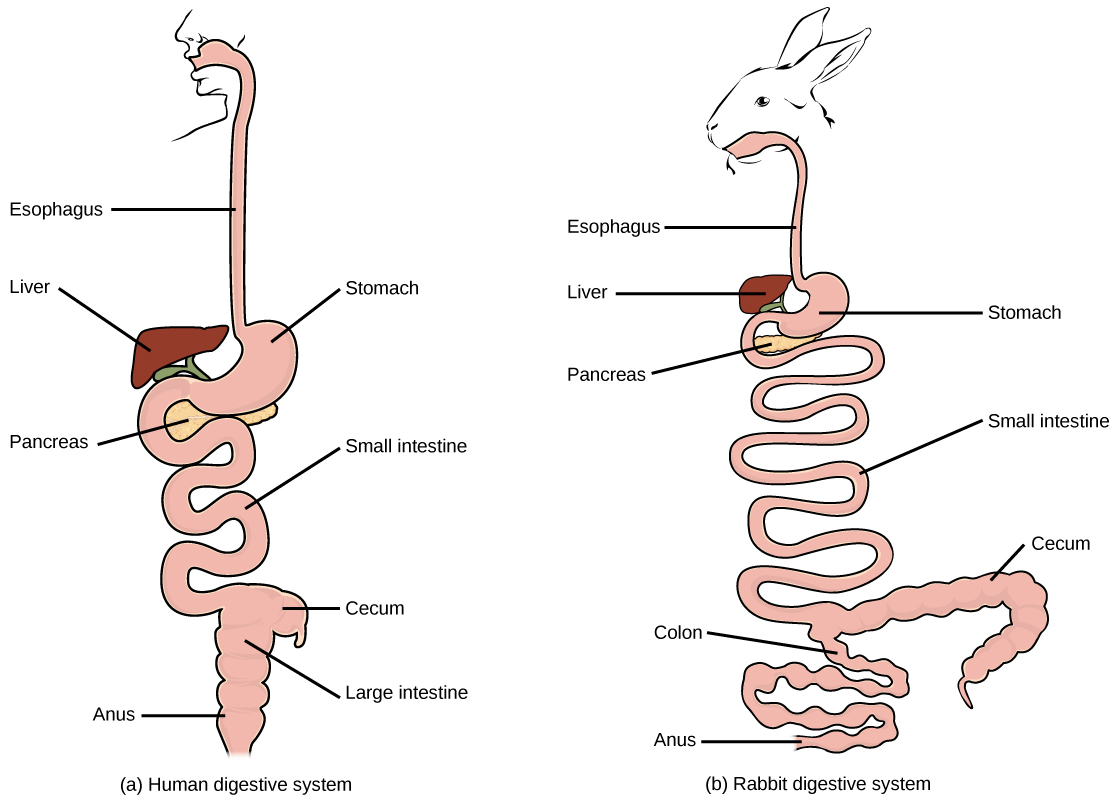
Birds face special challenges when it comes to obtaining nutrition from food. They do not have teeth and so their digestive system, shown in Figure 12.7, must be able to process un-masticated food. Birds have evolved a variety of beak types that reflect the vast variety in their diet, ranging from seeds and insects to fruits and nuts. Because most birds fly, their metabolic rates are high in order to efficiently process food and keep their body weight low. The stomach of birds has two chambers: the proventriculus, where gastric juices are produced to digest the food before it enters the stomach, and the gizzard, where the food is stored, soaked, and mechanically ground. The undigested material forms food pellets that are sometimes regurgitated. Most of the chemical digestion and absorption happens in the intestine and the waste is excreted through the cloaca.
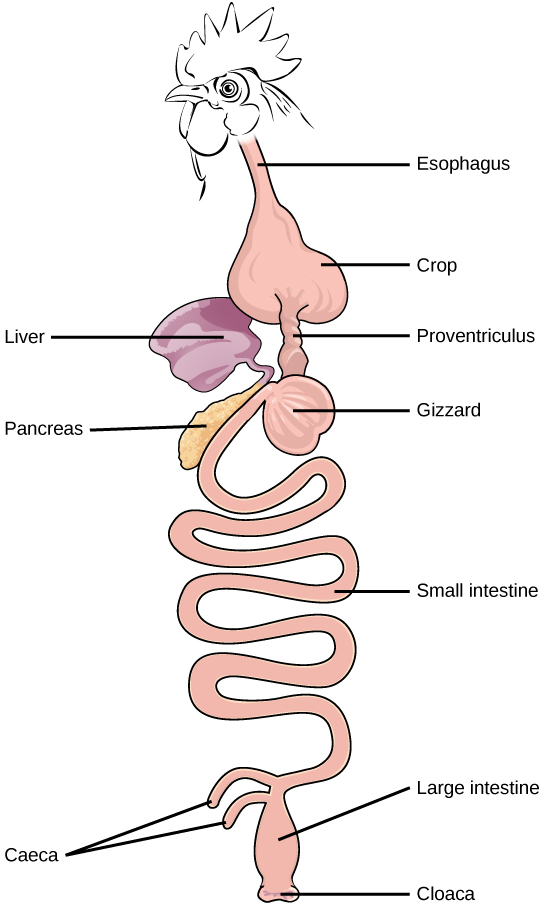
Birds have a highly efficient, simplified digestive system. Recent fossil evidence has shown that the evolutionary divergence of birds from other land animals was characterized by streamlining and simplifying the digestive system. Unlike many other animals, birds do not have teeth to chew their food. In place of lips, they have sharp pointy beaks. The horny beak, lack of jaws, and the smaller tongue of the birds can be traced back to their dinosaur ancestors. The emergence of these changes seems to coincide with the inclusion of seeds in the bird diet. Seed-eating birds have beaks that are shaped for grabbing seeds and the two-compartment stomach allows for delegation of tasks. Since birds need to remain light in order to fly, their metabolic rates are very high, which means they digest their food very quickly and need to eat often. Contrast this with the ruminants, where the digestion of plant matter takes a very long time.
Ruminants are mainly herbivores like cows, sheep, and goats, whose entire diet consists of eating large amounts of roughage or fiber. They have evolved digestive systems that help them digest vast amounts of cellulose. An interesting feature of the ruminants’ mouth is that they do not have upper incisor teeth. They use their lower teeth, tongue and lips to tear and chew their food. From the mouth, the food travels to the esophagus and on to the stomach.
To help digest the large amount of plant material, the stomach of the ruminants is a multi-chambered organ, as illustrated in Figure12.8. The four compartments of the stomach are called the rumen, reticulum, omasum, and abomasum. These chambers contain many microbes that breakdown cellulose and ferment ingested food. The abomasum is the “true” stomach and is the equivalent of the monogastric stomach chamber where gastric juices are secreted. The four-compartment gastric chamber provides larger space and the microbial support necessary to digest plant material in ruminants. The fermentation process produces large amounts of gas in the stomach chamber, which must be eliminated. As in other animals, the small intestine plays an important role in nutrient absorption, and the large intestine helps in the elimination of waste.
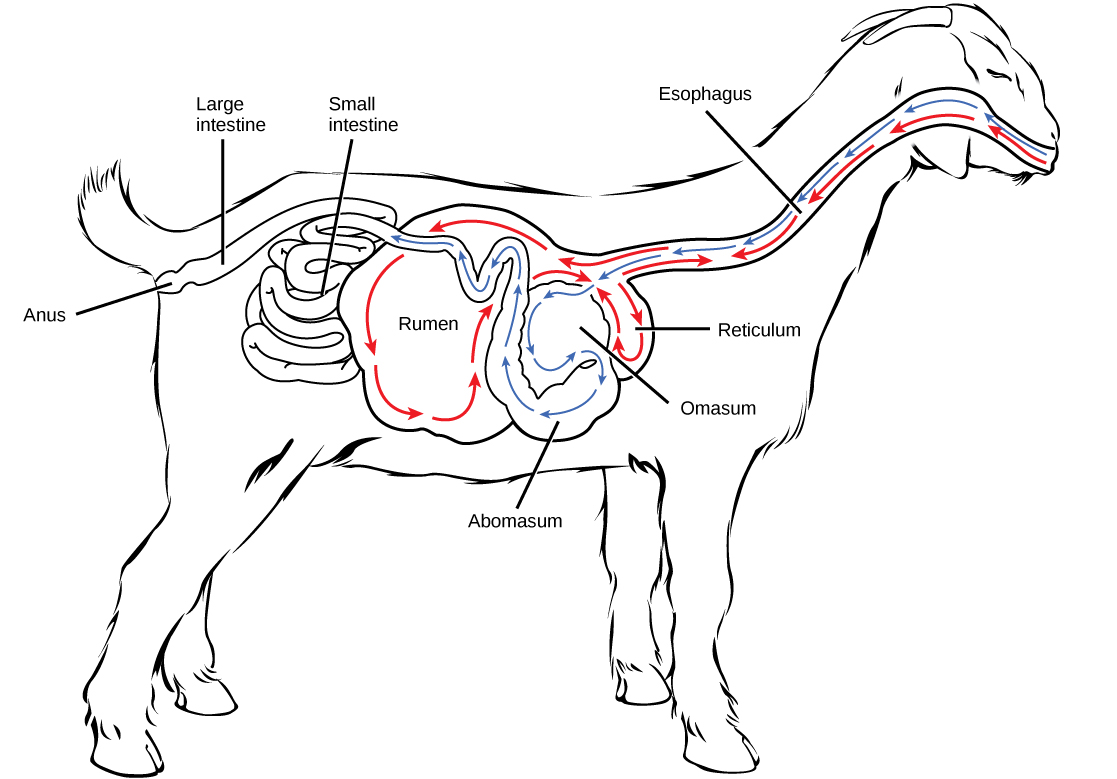
Some animals, such as camels and alpacas, are pseudo-ruminants. They eat a lot of plant material and roughage. Digesting plant material is not easy because plant cell walls contain the polymeric sugar molecule cellulose. The digestive enzymes of these animals cannot breakdown cellulose, but microorganisms present in the digestive system can. Therefore, the digestive system must be able to handle large amounts of roughage and breakdown the cellulose. Pseudo-ruminants have a three-chamber stomach in the digestive system. However, their cecum—a pouched organ at the beginning of the large intestine containing many microorganisms that are necessary for the digestion of plant materials—is large and is the site where the roughage is fermented and digested. These animals do not have a rumen but have an omasum, abomasum, and reticulum.
The vertebrate digestive system is designed to facilitate the transformation of food matter into the nutrient components that sustain organisms.
The oral cavity, or mouth, is the point of entry of food into the digestive system, illustrated in Figure12.9. The food consumed is broken into smaller particles by mastication, the chewing action of the teeth. All mammals have teeth and can chew their food.
The extensive chemical process of digestion begins in the mouth. As food is being chewed, saliva, produced by the salivary glands, mixes with the food. Saliva is a watery substance produced in the mouths of many animals. There are three major glands that secrete saliva—the parotid, the submandibular, and the sublingual. Saliva contains mucus that moistens food and buffers the pH of the food. Saliva also contains immunoglobulins and lysozymes, which have antibacterial action to reduce tooth decay by inhibiting growth of some bacteria. Saliva also contains an enzyme called salivary amylase that begins the process of converting starches in the food into a disaccharide called maltose. Another enzyme called lipase is produced by the cells in the tongue. Lipases are a class of enzymes that can breakdown triglycerides. The lingual lipase begins the breakdown of fat components in the food. The chewing and wetting action provided by the teeth and saliva prepare the food into a mass called the bolus for swallowing. The tongue helps in swallowing—moving the bolus from the mouth into the pharynx. The pharynx opens to two passageways: the trachea, which leads to the lungs, and the esophagus, which leads to the stomach. The trachea has an opening called the glottis, which is covered by a cartilaginous flap called the epiglottis. When swallowing, the epiglottis closes the glottis and food passes into the esophagus and not the trachea. This arrangement allows food to be kept out of the trachea.
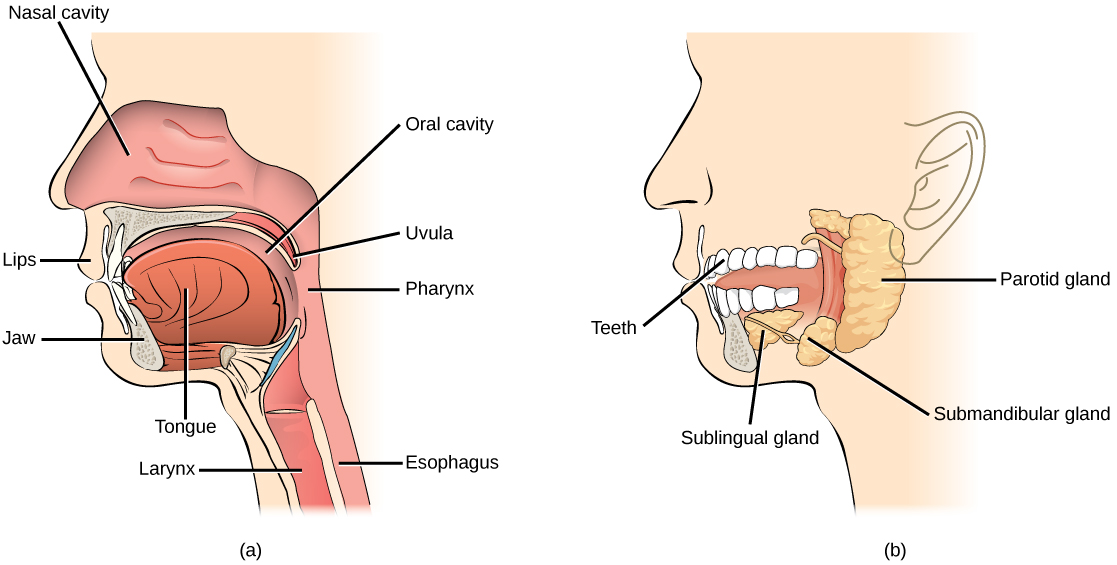
The esophagus is a tubular organ that connects the mouth to the stomach. The chewed and softened food passes through the esophagus after being swallowed. The smooth muscles of the esophagus undergo a series of wave like movements called peristalsis that push the food toward the stomach, as illustrated in Figure 12.10. The peristalsis wave is unidirectional—it moves food from the mouth to the stomach, and reverse movement is not possible. The peristaltic movement of the esophagus is an involuntary reflex; it takes place in response to the act of swallowing.
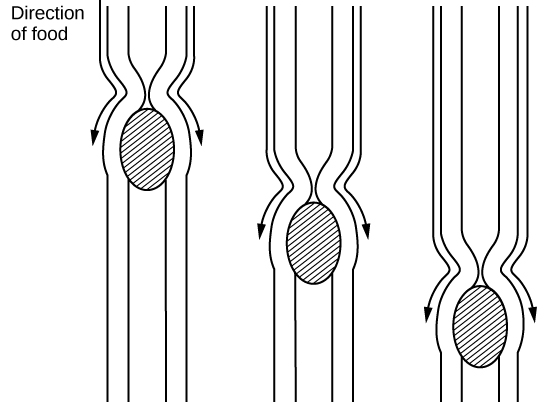
A ring-like muscle called a sphincter forms valves in the digestive system. The gastro-esophageal sphincter is located at the stomach end of the esophagus. In response to swallowing and the pressure exerted by the bolus of food, this sphincter opens, and the bolus enters the stomach. When there is no swallowing action, this sphincter is shut and prevents the contents of the stomach from traveling up the esophagus. Many animals have a true sphincter; however, in humans, there is no true sphincter, but the esophagus remains closed when there is no swallowing action. Acid reflux or “heartburn” occurs when the acidic digestive juices escape into the esophagus.
A large part of digestion occurs in the stomach, shown in Figure 12.11. The stomach is a saclike organ that secretes gastric digestive juices. The pH in the stomach is between 1.5 and 2.5. This highly acidic environment is required for the chemical breakdown of food and the extraction of nutrients. When empty, the stomach is a rather small organ; however, it can expand to up to 20 times its resting size when filled with food. This characteristic is particularly useful for animals that need to eat when food is available.
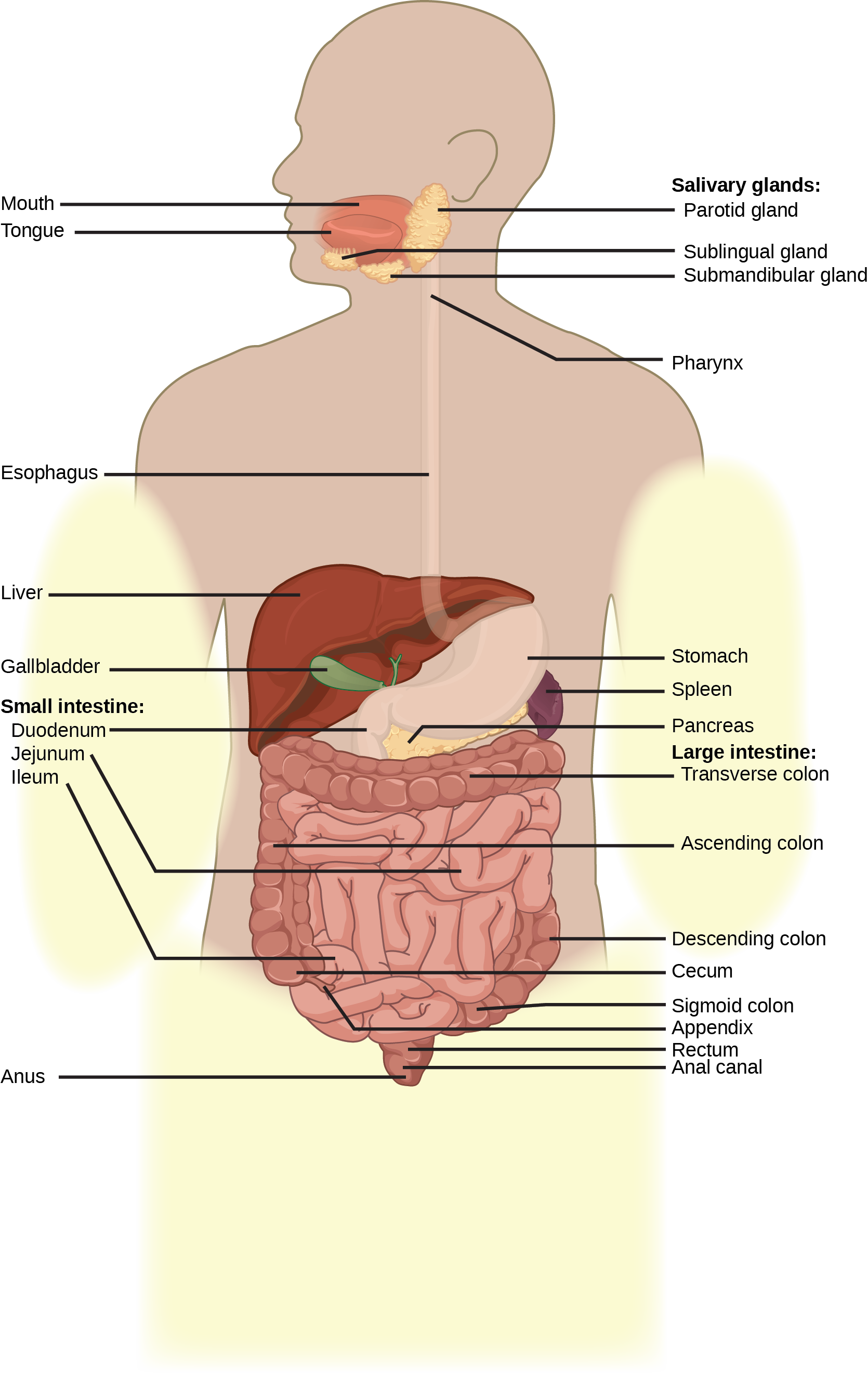
Which of the following statements about the digestive system is false?
The stomach is also the major site for protein digestion in animals other than ruminants. Protein digestion is mediated by an enzyme called pepsin in the stomach chamber. Pepsin is secreted by the chief cells in the stomach in an inactive form called pepsinogen. Pepsin breaks peptide bonds and cleaves proteins into smaller polypeptides; it also helps activate more pepsinogen, starting a positive feedback mechanism that generates more pepsin. Another cell type—parietal cells—secrete hydrogen and chloride ions, which combine in the lumen to form hydrochloric acid, the primary acidic component of the stomach juices. Hydrochloric acid helps to convert the inactive pepsinogen to pepsin. The highly acidic environment also kills many microorganisms in the food and, combined with the action of the enzyme pepsin, results in the hydrolysis of protein in the food. Chemical digestion is facilitated by the churning action of the stomach. Contraction and relaxation of smooth muscles mixes the stomach contents about every 20 minutes. The partially digested food and gastric juice mixture is called chyme. Chyme passes from the stomach to the small intestine. Further protein digestion takes place in the small intestine. Gastric emptying occurs within two to six hours after a meal. Only a small amount of chyme is released into the small intestine at a time. The movement of chyme from the stomach into the small intestine is regulated by the pyloric sphincter.
When digesting protein and some fats, the stomach lining must be protected from getting digested by pepsin. There are two points to consider when describing how the stomach lining is protected. First, as previously mentioned, the enzyme pepsin is synthesized in the inactive form. This protects the chief cells, because pepsinogen does not have the same enzyme functionality of pepsin. Second, the stomach has a thick mucus lining that protects the underlying tissue from the action of the digestive juices. When this mucus lining is ruptured, ulcers can form in the stomach. Ulcers are open wounds in or on an organ caused by bacteria (Helicobacter pylori) when the mucus lining is ruptured and fails to reform.
Chyme moves from the stomach to the small intestine. The small intestine is the organ where the digestion of protein, fats, and carbohydrates is completed. The small intestine is a long tube-like organ with a highly folded surface containing finger-like projections called the villi. The apical surface of each villus has many microscopic projections called microvilli. These structures, illustrated in Figure 12.12, are lined with epithelial cells on the luminal side and allow for the nutrients to be absorbed from the digested food and absorbed into the bloodstream on the other side. The villi and microvilli, with their many folds, increase the surface area of the intestine and increase absorption efficiency of the nutrients. Absorbed nutrients in the blood are carried into the hepatic portal vein, which leads to the liver. There, the liver regulates the distribution of nutrients to the rest of the body and removes toxic substances, including drugs, alcohol, and some pathogens.
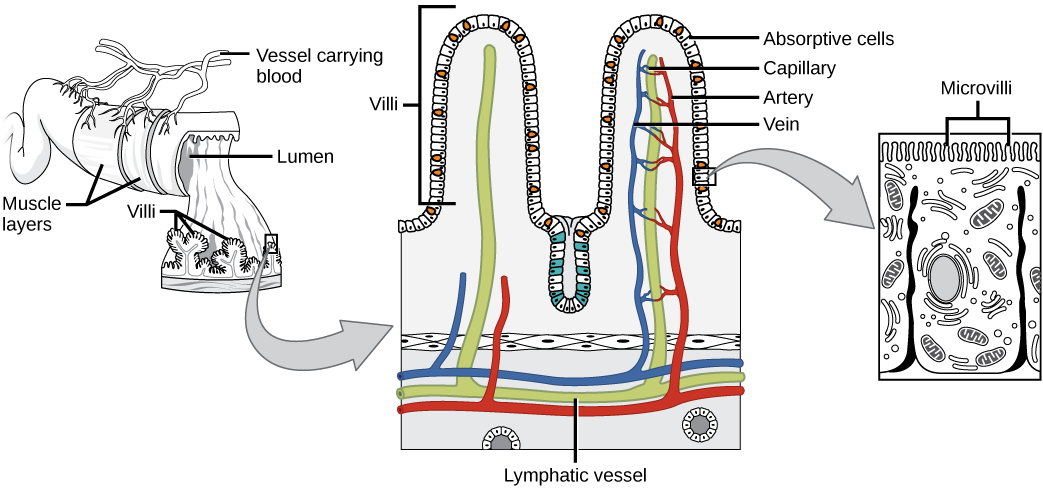
Which of the following statements about the small intestine is false?
The human small intestine is over 6m long and is divided into three parts: the duodenum, the jejunum, and the ileum. The “C-shaped,” fixed part of the small intestine is called the duodenum and is shown in Figure 12.11. The duodenum is separated from the stomach by the pyloric sphincter which opens to allow chyme to move from the stomach to the duodenum. In the duodenum, chyme is mixed with pancreatic juices in an alkaline solution rich in bicarbonate that neutralizes the acidity of chyme and acts as a buffer. Pancreatic juices also contain several digestive enzymes. Digestive juices from the pancreas, liver, and gallbladder, as well as from gland cells of the intestinal wall itself, enter the duodenum. Bile is produced in the liver and stored and concentrated in the gallbladder. Bile contains bile salts which emulsify lipids while the pancreas produces enzymes that catabolize starches, disaccharides, proteins, and fats. These digestive juices breakdown the food particles in the chyme into glucose, triglycerides, and amino acids. Some chemical digestion of food takes place in the duodenum. Absorption of fatty acids also takes place in the duodenum.
The second part of the small intestine is called the jejunum, shown in Figure 12.11. Here, hydrolysis of nutrients is continued while most of the carbohydrates and amino acids are absorbed through the intestinal lining. The bulk of chemical digestion and nutrient absorption occurs in the jejunum.
The ileum, also illustrated in Figure 12.11 is the last part of the small intestine and here the bile salts and vitamins are absorbed into the bloodstream. The undigested food is sent to the colon from the ileum via peristaltic movements of the muscle. The ileum ends and the large intestine begins at the ileocecal valve. The vermiform, “worm-like,” appendix is located at the ileocecal valve. The appendix of humans secretes no enzymes and has an insignificant role in immunity.
The large intestine, illustrated in Figure 12.13, reabsorbs the water from the undigested food material and processes the waste material. The human large intestine is much smaller in length compared to the small intestine but larger in diameter. It has three parts: the cecum, the colon, and the rectum. The cecum joins the ileum to the colon and is the receiving pouch for the waste matter. The colon is home to many bacteria or “intestinal flora” that aid in the digestive processes. The colon can be divided into four regions, the ascending colon, the transverse colon, the descending colon, and the sigmoid colon. The main functions of the colon are to extract the water and mineral salts from undigested food, and to store waste material. Carnivorous mammals have a shorter large intestine compared to herbivorous mammals due to their diet.
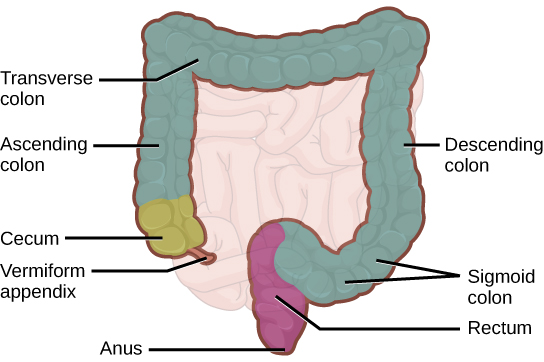
The rectum is the terminal end of the large intestine, as shown in Figure 12.13. The primary role of the rectum is to store the feces until defecation. The feces are propelled using peristaltic movements during elimination. The anus is an opening at the far-end of the digestive tract and is the exit point for the waste material. Two sphincters between the rectum and anus control elimination: the inner sphincter is involuntary and the outer sphincter is voluntary.
The organs discussed above are the organs of the digestive tract through which food passes. Accessory organs are organs that add secretions (enzymes) that catabolize food into nutrients. Accessory organs include salivary glands, the liver, the pancreas, and the gallbladder. The liver, pancreas, and gallbladder are regulated by hormones in response to the food consumed.
The liver is the largest internal organ in humans and it plays a very important role in digestion of fats and detoxifying blood. The liver produces bile, a digestive juice that is required for the breakdown of fatty components of the food in the duodenum. The liver also processes the vitamins and fats and synthesizes many plasma proteins.
The pancreas is another important gland that secretes digestive juices. The chyme produced from the stomach is highly acidic in nature; the pancreatic juices contain high levels of bicarbonate, an alkali that neutralizes the acidic chyme. Additionally, the pancreatic juices contain a large variety of enzymes that are required for the digestion of protein and carbohydrates.
The gallbladder is a small organ that aids the liver by storing bile and concentrating bile salts. When chyme containing fatty acids enters the duodenum, the bile is secreted from the gallbladder into the duodenum.
Different animals have evolved different types of digestive systems specialized to meet their dietary needs. Humans and many other animals have monogastric digestive systems with a single-chambered stomach. Birds have evolved a digestive system that includes a gizzard where the food is crushed into smaller pieces. This compensates for their inability to masticate. Ruminants that consume large amounts of plant material have a multi-chambered stomach that digests roughage. Pseudo-ruminants have similar digestive processes as ruminants but do not have the four-compartment stomach. Processing food involves ingestion (eating), digestion (mechanical and enzymatic breakdown of large molecules), absorption (cellular uptake of nutrients), and elimination (removal of undigested waste as feces).
Many organs work together to digest food and absorb nutrients. The mouth is the point of ingestion and the location where both mechanical and chemical breakdown of food begins. Saliva contains an enzyme called amylase that breaks down carbohydrates. The food bolus travels through the esophagus by peristaltic movements to the stomach. The stomach has an extremely acidic environment. An enzyme called pepsin digests protein in the stomach. Further digestion and absorption take place in the small intestine. The large intestine reabsorbs water from the undigested food and stores waste until elimination.
Exercises
Visual Connection Questions
Figure 12.11 : Which of the following statements about the digestive system is false?
Figure 12.12: Which of the following statements about the small intestine is false?
Review Questions
Which of the following is a pseudo-ruminant?
Which of the following statements is untrue?
The acidic nature of chyme is neutralized by ________.
The digestive juices from the liver are delivered to the ________.
A scientist dissects a new species of animal. If the animal’s digestive system has a single stomach with an extended small intestine, to which animal could the dissected specimen be closely related?
Critical Thinking Questions
Glossary
Chapter 34 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Given the diversity of animal life on our planet, it is not surprising that the animal diet would also vary substantially. The animal diet is the source of materials needed for building DNA and other complex molecules needed for growth, maintenance, and reproduction; collectively these processes are called biosynthesis. The diet is also the source of materials for ATP production in the cells. The diet must be balanced to provide the minerals and vitamins that are required for cellular function.
What are the fundamental requirements of the animal diet? The animal diet should be well balanced and provide nutrients required for bodily function and the minerals and vitamins required for maintaining structure and regulation necessary for good health and reproductive capability. These requirements for a human are illustrated graphically in Figure 12.14.

The first step in ensuring that you are meeting the food requirements of your body is an awareness of the food groups and the nutrients they provide. To learn more about each food group and the recommended daily amounts, explore the What’s on Your Plate? interactive site by the United States Department of Agriculture.
ParticipACTION emerged from Sport Participation Canada, a non-profit organization formed on July 12, 1971 in response to a 1969 study commissioned by the National Advisory Council for Fitness and Amateur Sport that found that the future of Canadian health was at risk from poor physical fitness and apathy on the part of Canadians. It was formed to promote healthy living and physical fitness.
It was shut down due to financial cutbacks in 2001, but was revived on February 19, 2007 with a grant of $5 million from the Canadian federal government.
The organic molecules required for building cellular material and tissues must come from food. Carbohydrates or sugars are the primary source of organic carbons in the animal body. During digestion, digestible carbohydrates are ultimately broken down into glucose and used to provide energy through metabolic pathways. Complex carbohydrates, including polysaccharides, can be broken down into glucose through biochemical modification; however, humans do not produce the enzyme cellulase and lack the ability to derive glucose from the polysaccharide cellulose. In humans, these molecules provide the fiber required for moving waste through the large intestine and a healthy colon. The intestinal flora in the human gut are able to extract some nutrition from these plant fibers. The excess sugars in the body are converted into glycogen and stored in the liver and muscles for later use. Glycogen stores are used to fuel prolonged exertions, such as long-distance running, and to provide energy during food shortage. Excess glycogen can be converted to fats, which are stored in the lower layer of the skin of mammals for insulation and energy storage. Excess digestible carbohydrates are stored by mammals in order to survive famine and aid in mobility.
Another important requirement is that of nitrogen. Protein catabolism provides a source of organic nitrogen. Amino acids are the building blocks of proteins and protein breakdown provides amino acids that are used for cellular function. The carbon and nitrogen derived from these become the building block for nucleotides, nucleic acids, proteins, cells, and tissues. Excess nitrogen must be excreted as it is toxic. Fats add flavor to food and promote a sense of satiety or fullness. Fatty foods are also significant sources of energy because one gram of fat contains nine calories. Fats are required in the diet to aid the absorption of fat-soluble vitamins and the production of fat-soluble hormones.
While the animal body can synthesize many of the molecules required for function from the organic precursors, there are some nutrients that need to be consumed from food. These nutrients are termed essential nutrients, meaning they must be eaten, and the body cannot produce them.
The omega-3 alpha-linolenic acid and the omega-6 linoleic acid are essential fatty acids needed to make some membrane phospholipids. Vitamins are another class of essential organic molecules that are required in small quantities for many enzymes to function and, for this reason, are considered to be coenzymes. Absence or low levels of vitamins can have a dramatic effect on health, as outlined in Table 12.1 and Table 12.2. Both fat-soluble and water-soluble vitamins must be obtained from food. Minerals, listed in Table12.3, are inorganic essential nutrients that must be obtained from food. Among their many functions, minerals help in structure and regulation and are considered cofactors. Certain amino acids also must be procured from food and cannot be synthesized by the body. These amino acids are the “essential” amino acids. The human body can synthesize only 11 of the 20 required amino acids; the rest must be obtained from food. The essential amino acids are listed in Table 12.4.
| Table 12.1 Water-soluble Essential Vitamins | |||
|---|---|---|---|
| Vitamin | Function | Deficiencies Can Lead To | Sources |
| Vitamin B1 (Thiamine) | Needed by the body to process lipids, proteins, and carbohydrates; coenzyme removes CO2 from organic compounds | Muscle weakness, Beriberi: reduced heart function, CNS problems | Milk, meat, dried beans, whole grains |
| Vitamin B2 (Riboflavin) | Takes an active role in metabolism, aiding in the conversion of food to energy (FAD and FMN) | Cracks or sores on the outer surface of the lips (cheliosis); inflammation and redness of the tongue; moist, scaly skin inflammation (seborrheic dermatitis) | Meat, eggs, enriched grains, vegetables |
| Vitamin B3 (Niacin) | Used by the body to release energy from carbohydrates and to process alcohol; required for the synthesis of sex hormones; component of coenzyme NAD+ and NADP+ | Pellagra, which can result in dermatitis, diarrhea, dementia, and death | Meat, eggs, grains, nuts, potatoes |
| Vitamin B5 (Pantothenic acid) | Assists in producing energy from foods (lipids, in particular); component of coenzyme A | Fatigue, poor coordination, retarded growth, numbness, tingling of hands and feet | Meat, whole grains, milk, fruits, vegetables |
| Vitamin B6 (Pyridoxine) | The principal vitamin for processing amino acids and lipids; also helps convert nutrients into energy | Irritability, depression, confusion, mouth sores or ulcers, anemia, muscular twitching | Meat, dairy products, whole grains, orange juice |
| Vitamin B7 (Biotin) | Used in energy and amino acid metabolism, fat synthesis, and fat breakdown; helps the body use blood sugar | Hair loss, dermatitis, depression, numbness and tingling in the extremities; neuromuscular disorders | Meat, eggs, legumes and other vegetables |
| Vitamin B9 (Folic acid) | Assists the normal development of cells, especially during fetal development; helps metabolize nucleic and amino acids | Deficiency during pregnancy is associated with birth defects, such as neural tube defects and anemia | Leafy green vegetables, whole wheat, fruits, nuts, legumes |
| Vitamin B12 (Cobalamin) | Maintains healthy nervous system and assists with blood cell formation; coenzyme in nucleic acid metabolism | Anemia, neurological disorders, numbness, loss of balance | Meat, eggs, animal products |
| Vitamin C (Ascorbic acid) | Helps maintain connective tissue: bone, cartilage, and dentin; boosts the immune system | Scurvy, which results in bleeding, hair and tooth loss; joint pain and swelling; delayed wound healing | Citrus fruits, broccoli, tomatoes, red sweet bell peppers |
| Table 12.2 Fat-soluble Essential Vitamins | |||
|---|---|---|---|
| Vitamin | Function | Deficiencies Can Lead To | Sources |
| Vitamin A (Retinol) | Critical to the development of bones, teeth, and skin; helps maintain eyesight, enhances the immune system, fetal development, gene expression | Night-blindness, skin disorders, impaired immunity | Dark green leafy vegetables, yellow-orange vegetables, fruits, milk, butter |
| Vitamin D | Critical for calcium absorption for bone development and strength; maintains a stable nervous system; maintains a normal and strong heartbeat; helps in blood clotting | Rickets, osteomalacia, immunity | Cod liver oil, milk, egg yolk |
| Vitamin E (Tocopherol) | Lessens oxidative damage of cells and prevents lung damage from pollutants; vital to the immune system | Deficiency is rare; anemia, nervous system degeneration | Wheat germ oil, unrefined vegetable oils, nuts, seeds, grains |
| Vitamin K (Phylloquinone) | Essential to blood clotting | Bleeding and easy bruising | Leafy green vegetables, tea |

| Table 12.3 Minerals and Their Function in the Human Body | |||
|---|---|---|---|
| Mineral | Function | Deficiencies Can Lead To | Sources |
| *Calcium | Needed for muscle and neuron function; heart health; builds bone and supports synthesis and function of blood cells; nerve function | Osteoporosis, rickets, muscle spasms, impaired growth | Milk, yogurt, fish, green leafy vegetables, legumes |
| *Chlorine | Needed for production of hydrochloric acid (HCl) in the stomach and nerve function; osmotic balance | Muscle cramps, mood disturbances, reduced appetite | Table salt |
| Copper (trace amounts) | Required component of many redox enzymes, including cytochrome c oxidase; cofactor for hemoglobin synthesis | Copper deficiency is rare | Liver, oysters, cocoa, chocolate, sesame, nuts |
| Iodine | Required for the synthesis of thyroid hormones | Goiter | Seafood, iodized salt, dairy products |
| Iron | Required for many proteins and enzymes, notably hemoglobin, to prevent anemia | Anemia, which causes poor concentration, fatigue, and poor immune function | Red meat, leafy green vegetables, fish (tuna, salmon), eggs, dried fruits, beans, whole grains |
| *Magnesium | Required cofactor for ATP formation; bone formation; normal membrane functions; muscle function | Mood disturbances, muscle spasms | Whole grains, leafy green vegetables |
| Manganese (trace amounts) | A cofactor in enzyme functions; trace amounts are required | Manganese deficiency is rare | Common in most foods |
| Molybdenum (trace amounts) | Acts as a cofactor for three essential enzymes in humans: sulfite oxidase, xanthine oxidase, and aldehyde oxidase | Molybdenum deficiency is rare | |
| *Phosphorus | A component of bones and teeth; helps regulate acid-base balance; nucleotide synthesis | Weakness, bone abnormalities, calcium loss | Milk, hard cheese, whole grains, meats |
| *Potassium | Vital for muscles, heart, and nerve function | Cardiac rhythm disturbance, muscle weakness | Legumes, potato skin, tomatoes, bananas |
| Selenium (trace amounts) | A cofactor essential to activity of antioxidant enzymes like glutathione peroxidase; trace amounts are required | Selenium deficiency is rare | Common in most foods |
| *Sodium | Systemic electrolyte required for many functions; acid-base balance; water balance; nerve function | Muscle cramps, fatigue, reduced appetite | Table salt |
| Zinc (trace amounts) | Required for several enzymes such as carboxypeptidase, liver alcohol dehydrogenase, and carbonic anhydrase | Anemia, poor wound healing, can lead to short stature | Common in most foods |
| *Greater than 200mg/day required | |||
| Table 12.4 Essential Amino Acids | |
|---|---|
| Amino acids that must be consumed | Amino acids anabolized by the body |
| isoleucine | alanine |
| leucine | selenocysteine |
| lysine | aspartate |
| methionine | cysteine |
| phenylalanine | glutamate |
| tryptophan | glycine |
| valine | proline |
| histidine* | serine |
| threonine | tyrosine |
| arginine* | asparagine |
| *The human body can synthesize histidine and arginine, but not in the quantities required, especially for growing children. | |
Animals need food to obtain energy and maintain homeostasis. Homeostasis is the ability of a system to maintain a stable internal environment even in the face of external changes to the environment. For example, the normal body temperature of humans is 37°C (98.6°F). Humans maintain this temperature even when the external temperature is hot or cold. It takes energy to maintain this body temperature, and animals obtain this energy from food.
The primary source of energy for animals is carbohydrates, mainly glucose. Glucose is called the body’s fuel. The digestible carbohydrates in an animal’s diet are converted to glucose molecules through a series of catabolic chemical reactions.
Adenosine triphosphate, or ATP, is the primary energy currency in cells; ATP stores energy in phosphate ester bonds. ATP releases energy when the phosphodiester bonds are broken and ATP is converted to ADP and a phosphate group. ATP is produced by the oxidative reactions in the cytoplasm and mitochondrion of the cell, where carbohydrates, proteins, and fats undergo a series of metabolic reactions collectively called cellular respiration. For example, glycolysis is a series of reactions in which glucose is converted to pyruvic acid and some of its chemical potential energy is transferred to NADH and ATP.
ATP is required for all cellular functions. It is used to build the organic molecules that are required for cells and tissues; it provides energy for muscle contraction and for the transmission of electrical signals in the nervous system. When the amount of ATP is available in excess of the body’s requirements, the liver uses the excess ATP and excess glucose to produce molecules called glycogen. Glycogen is a polymeric form of glucose and is stored in the liver and skeletal muscle cells. When blood sugar drops, the liver releases glucose from stores of glycogen. Skeletal muscle converts glycogen to glucose during intense exercise. The process of converting glucose and excess ATP to glycogen and the storage of excess energy is an evolutionarily important step in helping animals deal with mobility, food shortages, and famine.
Obesity is a major health concern in the United States, and there is a growing focus on reducing obesity and the diseases it may lead to, such as type-2 diabetes, cancers of the colon and breast, and cardiovascular disease. How does the food consumed contribute to obesity?
Fatty foods are calorie-dense, meaning that they have more calories per unit mass than carbohydrates or proteins. One gram of carbohydrates has four calories, one gram of protein has four calories, and one gram of fat has nine calories. Animals tend to seek lipid-rich food for their higher energy content.
The signals of hunger (“time to eat”) and satiety (“time to stop eating”) are controlled in the hypothalamus region of the brain. Foods that are rich in fatty acids tend to promote satiety more than foods that are rich only in carbohydrates.
Excess carbohydrate and ATP are used by the liver to synthesize glycogen. The pyruvate produced during glycolysis is used to synthesize fatty acids. When there is more glucose in the body than required, the resulting excess pyruvate is converted into molecules that eventually result in the synthesis of fatty acids within the body. These fatty acids are stored in adipose cells—the fat cells in the mammalian body whose primary role is to store fat for later use.
It is important to note that some animals benefit from obesity. Polar bears and seals need body fat for insulation and to keep them from losing body heat during Arctic winters. When food is scarce, stored body fat provides energy for maintaining homeostasis. Fats prevent famine in mammals, allowing them to access energy when food is not available on a daily basis; fats are stored when a large kill is made or lots of food is available.
Animal diet should be balanced and meet the needs of the body. Carbohydrates, proteins, and fats are the primary components of food. Some essential nutrients are required for cellular function but cannot be produced by the animal body. These include vitamins, minerals, some fatty acids, and some amino acids. Food intake in more than necessary amounts is stored as glycogen in the liver and muscle cells, and in fat cells. Excess adipose storage can lead to obesity and serious health problems. ATP is the energy currency of the cell and is obtained from the metabolic pathways. Excess carbohydrates and energy are stored as glycogen in the body.
Exercises
Review Questions
Which of the following statements is not true?
Which of the following is a water-soluble vitamin?
What is the primary fuel for the body?
Excess glucose is stored as ________.
Many distance runners “carb load” the day before a big race. How does this eating strategy provide an advantage to the runner?
Critical Thinking Questions
Glossary
Chapter 34 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
Obtaining nutrition and energy from food is a multistep process. For true animals, the first step is ingestion, the act of taking in food. This is followed by digestion, absorption, and elimination. In the following sections, each of these steps will be discussed in detail.
The large molecules found in intact food cannot pass through the cell membranes. Food needs to be broken into smaller particles so that animals can harness the nutrients and organic molecules. The first step in this process is ingestion. Ingestion is the process of taking in food through the mouth. In vertebrates, the teeth, saliva, and tongue play important roles in mastication (preparing the food into bolus). While the food is being mechanically broken down, the enzymes in saliva begin to chemically process the food as well. The combined action of these processes modifies the food from large particles to a soft mass that can be swallowed and can travel the length of the esophagus.
Digestion is the mechanical and chemical breakdown of food into small organic fragments. It is important to breakdown macromolecules into smaller fragments that are of suitable size for absorption across the digestive epithelium. Large, complex molecules of proteins, polysaccharides, and lipids must be reduced to simpler particles such as simple sugar before they can be absorbed by the digestive epithelial cells. Different organs play specific roles in the digestive process. The animal diet needs carbohydrates, protein, and fat, as well as vitamins and inorganic components for nutritional balance. How each of these components is digested is discussed in the following sections.
The digestion of carbohydrates begins in the mouth. The salivary enzyme amylase begins the breakdown of food starches into maltose, a disaccharide. As the bolus of food travels through the esophagus to the stomach, no significant digestion of carbohydrates takes place. The esophagus produces no digestive enzymes but does produce mucous for lubrication. The acidic environment in the stomach stops the action of the amylase enzyme.
The next step of carbohydrate digestion takes place in the duodenum. Recall that the chyme from the stomach enters the duodenum and mixes with the digestive secretion from the pancreas, liver, and gallbladder. Pancreatic juices also contain amylase, which continues the breakdown of starch and glycogen into maltose, a disaccharide. The disaccharides are broken down into monosaccharides by enzymes called maltases, sucrases, and lactases, which are also present in the brush border of the small intestinal wall. Maltase breaks down maltose into glucose. Other disaccharides, such as sucrose and lactose are broken down by sucrase and lactase, respectively. Sucrase breaks down sucrose (or “table sugar”) into glucose and fructose, and lactase breaks down lactose (or “milk sugar”) into glucose and galactose. The monosaccharides (glucose) thus produced are absorbed and then can be used in metabolic pathways to harness energy. The monosaccharides are transported across the intestinal epithelium into the bloodstream to be transported to the different cells in the body. The steps in carbohydrate digestion are summarized in Figure 12.16 and Table 12.5.
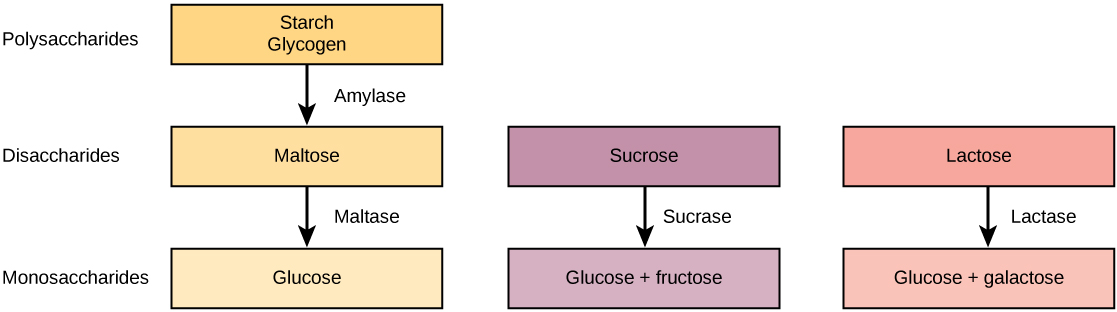
| Table 12. 5 Digestion of Carbohydrates | ||||
|---|---|---|---|---|
| Enzyme | Produced By | Site of Action | Substrate Acting On | End Products |
| Salivary amylase | Salivary glands | Mouth | Polysaccharides (Starch) | Disaccharides (maltose), oligosaccharides |
| Pancreatic amylase | Pancreas | Small intestine | Polysaccharides (starch) | Disaccharides (maltose), monosaccharides |
| Oligosaccharidases | Lining of the intestine; brush border membrane | Small intestine | Disaccharides | Monosaccharides (e.g., glucose, fructose, galactose) |
A large part of protein digestion takes place in the stomach. The enzyme pepsin plays an important role in the digestion of proteins by breaking down the intact protein to peptides, which are short chains of four to nine amino acids. In the duodenum, other enzymes—trypsin, elastase, and chymotrypsin—act on the peptides reducing them to smaller peptides. Trypsin elastase, carboxypeptidase, and chymotrypsin are produced by the pancreas and released into the duodenum where they act on the chyme. Further breakdown of peptides to single amino acids is aided by enzymes called peptidases (those that breakdown peptides). Specifically, carboxypeptidase, dipeptidase, and aminopeptidase play important roles in reducing the peptides to free amino acids. The amino acids are absorbed into the bloodstream through the small intestines. The steps in protein digestion are summarized in Figure 12.7 and Table 12.6.
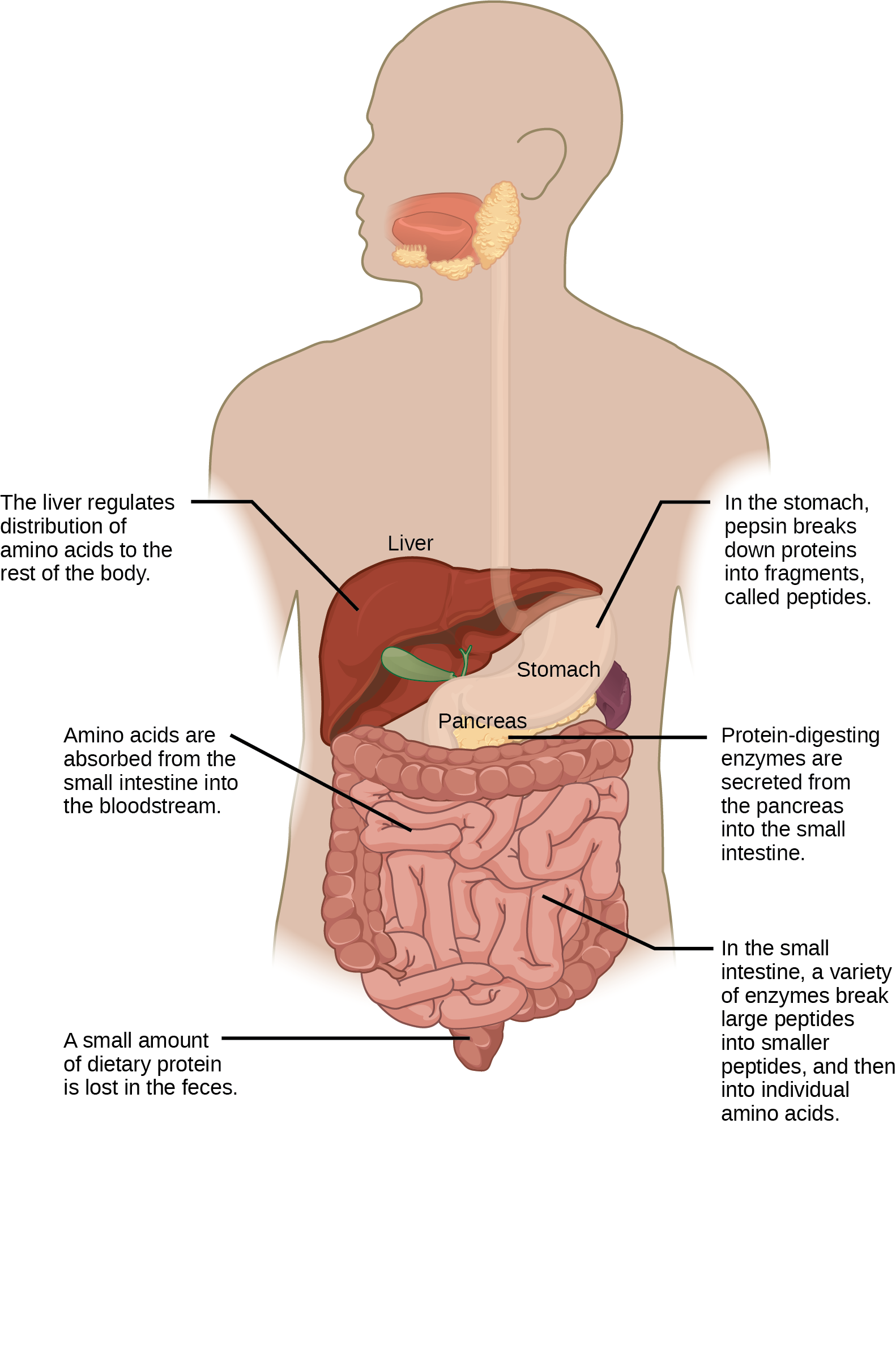
| Table 12.6 Digestion of Protein | ||||
|---|---|---|---|---|
| Enzyme | Produced By | Site of Action | Substrate Acting On | End Products |
| Pepsin | Stomach chief cells | Stomach | Proteins | Peptides |
| Pancreas | Small intestine | Proteins | Peptides |
| Carboxypeptidase | Pancreas | Small intestine | Peptides | Amino acids and peptides |
| Lining of intestine | Small intestine | Peptides | Amino acids |
Lipid digestion begins in the stomach with the aid of lingual lipase and gastric lipase. However, the bulk of lipid digestion occurs in the small intestine due to pancreatic lipase. When chyme enters the duodenum, the hormonal responses trigger the release of bile, which is produced in the liver and stored in the gallbladder. Bile aids in the digestion of lipids, primarily triglycerides by emulsification. Emulsification is a process in which large lipid globules are broken down into several small lipid globules. These small globules are more widely distributed in the chyme rather than forming large aggregates. Lipids are hydrophobic substances: in the presence of water, they will aggregate to form globules to minimize exposure to water. Bile contains bile salts, which are amphipathic, meaning they contain hydrophobic and hydrophilic parts. Thus, the bile salts hydrophilic side can interface with water on one side and the hydrophobic side interfaces with lipids on the other. By doing so, bile salts emulsify large lipid globules into small lipid globules.
Why is emulsification important for digestion of lipids? Pancreatic juices contain enzymes called lipases (enzymes that breakdown lipids). If the lipid in the chyme aggregates into large globules, very little surface area of the lipids is available for the lipases to act on, leaving lipid digestion incomplete. By forming an emulsion, bile salts increase the available surface area of the lipids many fold. The pancreatic lipases can then act on the lipids more efficiently and digest them, as detailed in Figure 12.18. Lipases breakdown the lipids into fatty acids and glycerides. These molecules can pass through the plasma membrane of the cell and enter the epithelial cells of the intestinal lining. The bile salts surround long-chain fatty acids and monoglycerides forming tiny spheres called micelles. The micelles move into the brush border of the small intestine absorptive cells where the long-chain fatty acids and monoglycerides diffuse out of the micelles into the absorptive cells leaving the micelles behind in the chyme. The long-chain fatty acids and monoglycerides recombine in the absorptive cells to form triglycerides, which aggregate into globules and become coated with proteins. These large spheres are called chylomicrons. Chylomicrons contain triglycerides, cholesterol, and other lipids and have proteins on their surface. The surface is also composed of the hydrophilic phosphate “heads” of phospholipids. Together, they enable the chylomicron to move in an aqueous environment without exposing the lipids to water. Chylomicrons leave the absorptive cells via exocytosis. Chylomicrons enter the lymphatic vessels, and then enter the blood in the subclavian vein.
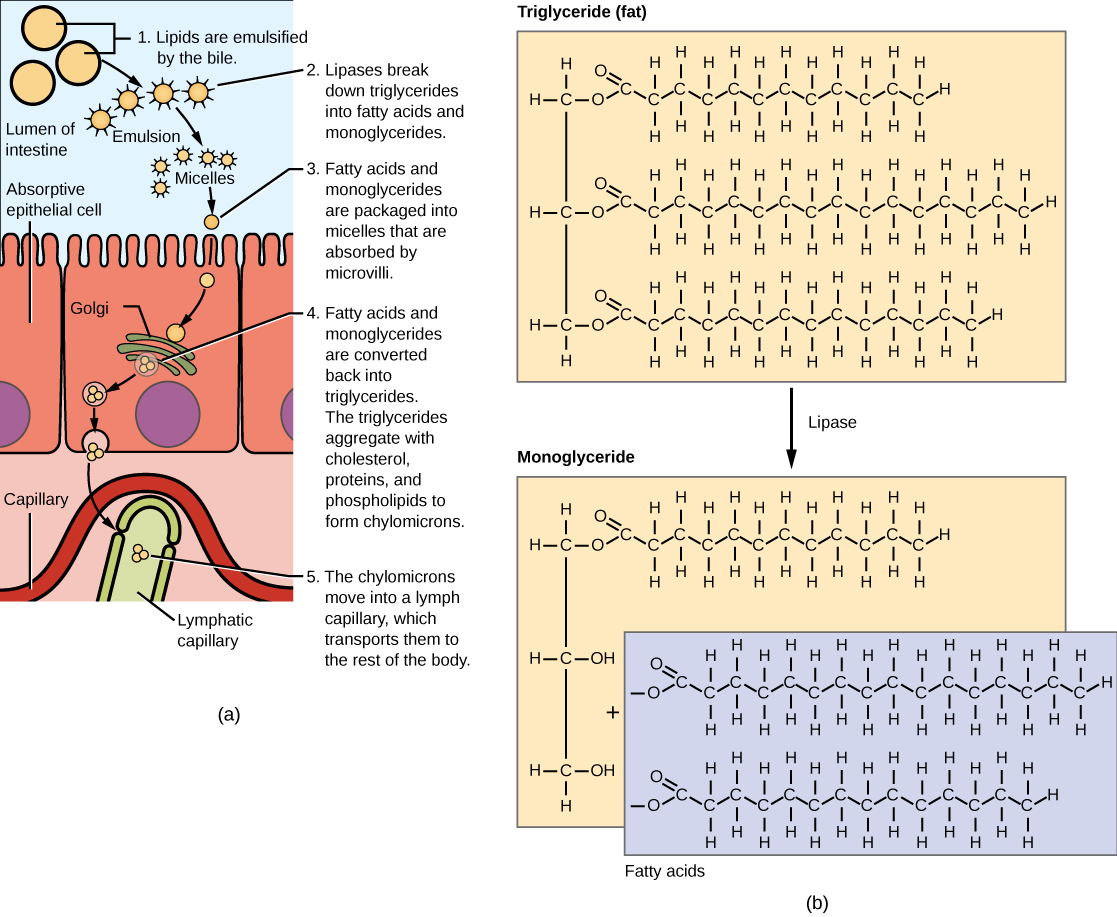
Vitamins can be either water-soluble or lipid-soluble. Fat soluble vitamins are absorbed in the same manner as lipids. It is important to consume some amount of dietary lipid to aid the absorption of lipid-soluble vitamins. Water-soluble vitamins can be directly absorbed into the bloodstream from the intestine.
This website has an overview of the digestion of protein, fat, and carbohydrates.
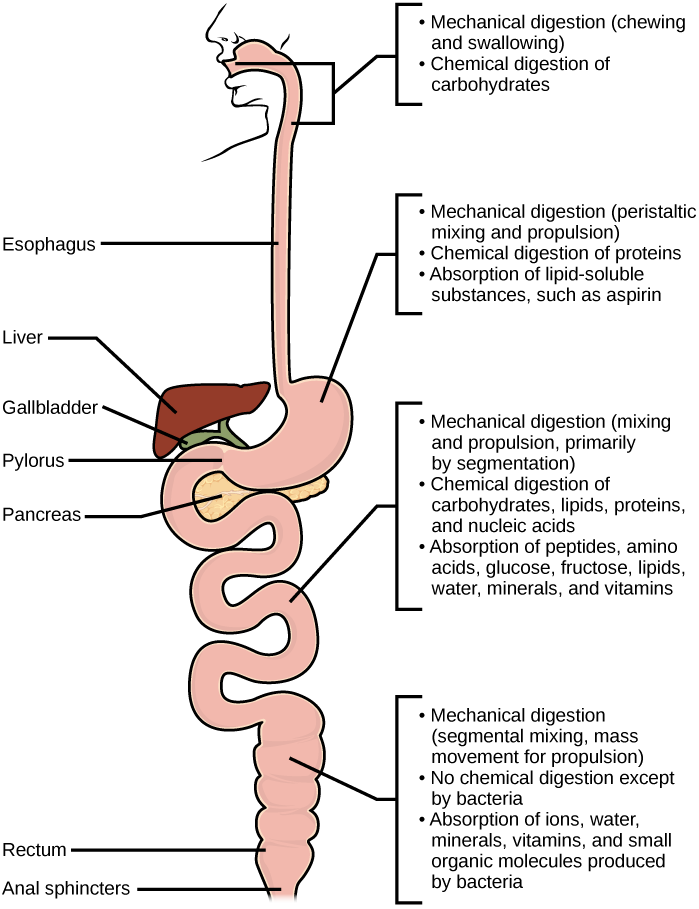
Which of the following statements about digestive processes is true?
The final step in digestion is the elimination of undigested food content and waste products. The undigested food material enters the colon, where most of the water is reabsorbed. Recall that the colon is also home to the microflora called “intestinal flora” that aid in the digestion process. The semi-solid waste is moved through the colon by peristaltic movements of the muscle and is stored in the rectum. As the rectum expands in response to storage of fecal matter, it triggers the neural signals required to set up the urge to eliminate. The solid waste is eliminated through the anus using peristaltic movements of the rectum.
Diarrhea and constipation are some of the most common health concerns that affect digestion. Constipation is a condition where the feces are hardened because of excess water removal in the colon. In contrast, if enough water is not removed from the feces, it results in diarrhea. Many bacteria, including the ones that cause cholera, affect the proteins involved in water reabsorption in the colon and result in excessive diarrhea.
Emesis, or vomiting, is elimination of food by forceful expulsion through the mouth. It is often in response to an irritant that affects the digestive tract, including but not limited to viruses, bacteria, emotions, sights, and food poisoning. This forceful expulsion of the food is due to the strong contractions produced by the stomach muscles. The process of emesis is regulated by the medulla.
Digestion begins with ingestion, where the food is taken in the mouth. Digestion and absorption take place in a series of steps with special enzymes playing important roles in digesting carbohydrates, proteins, and lipids. Elimination describes removal of undigested food contents and waste products from the body. While most absorption occurs in the small intestines, the large intestine is responsible for the final removal of water that remains after the absorptive process of the small intestines. The cells that line the large intestine absorb some vitamins as well as any leftover salts and water. The large intestine (colon) is also where feces is formed.
Exercises
Exercises
Where does the majority of protein digestion take place?
A
Lipases are enzymes that breakdown ________.
B
Which of the following conditions is most likely to cause constipation?
B
Explain why some dietary lipid is a necessary part of a balanced diet.
Lipids add flavor to food and promote a sense of satiety or fullness. Fatty foods are sources of high energy; one gram of lipid contains nine calories. Lipids are also required in the diet to aid the absorption of lipid-soluble vitamins and for the production of lipid-soluble hormones.
The gut microbiome (the bacterial colonies in the intestines) have become a popular area of study in biomedical research. How could varying gut microbiomes impact a person’s nutrition?
The gut microbiome includes all the bacteria that aid in chemical digestion in the intestines. Changing its composition can change the way that food is digested since not all bacteria have the same macromolecule-digesting enzymes. Additionally, changes in gut microbiome can lead to the establishment of pathogenic bacteria populations that cause inflammation in the gut or other disease.
Many mammals become ill if they drink milk as adults even though they could consume it as babies. What causes this digestive issue?
As mammals wean from their mothers they stop drinking milk. Since they stop consuming the sugar lactose their bodies conserve resources by no longer making the enzyme lactase. If the animals then consume lactose at some point in the future their digestive system cannot break the lactose molecules into glucose and galactose for absorption. When gut bacteria further along the digestive tract interact with the lactose molecules it causes symptoms of lactose intolerance.
Glossary
Chapter 34 in OpenStax Concepts of Biology 2E
Learning Objectives
By the end of this section, you will be able to do the following:
The brain is the control center for the sensation of hunger and satiety. The functions of the digestive system are regulated through neural and hormonal responses.
In reaction to the smell, sight, or thought of food, like that shown in Figure 12.20, the first response is that of salivation. The salivary glands secrete more saliva in response to stimulation by the autonomic nervous system triggered by food in preparation for digestion. Simultaneously, the stomach begins to produce hydrochloric acid to digest the food. Recall that the peristaltic movements of the esophagus and other organs of the digestive tract are under the control of the brain. The brain prepares these muscles for movement as well. When the stomach is full, the part of the brain that detects satiety signals fullness. There are three overlapping phases of gastric control—the cephalic phase, the gastric phase, and the intestinal phase—each requires many enzymes and is under neural control as well.

The response to food begins even before food enters the mouth. The first phase of ingestion, called the cephalic phase, is controlled by the neural response to the stimulus provided by food. All aspects—such as sight, sense, and smell—trigger the neural responses resulting in salivation and secretion of gastric juices. The gastric and salivary secretion in the cephalic phase can also take place due to the thought of food. Right now, if you think about a piece of chocolate or a crispy potato chip, the increase in salivation is a cephalic phase response to the thought. The central nervous system prepares the stomach to receive food.
The gastric phase begins once the food arrives in the stomach. It builds on the stimulation provided during the cephalic phase. Gastric acids and enzymes process the ingested materials. The gastric phase is stimulated by (1) distension of the stomach, (2) a decrease in the pH of the gastric contents, and (3) the presence of undigested material. This phase consists of local, hormonal, and neural responses. These responses stimulate secretions and powerful contractions.
The intestinal phase begins when chyme enters the small intestine triggering digestive secretions. This phase controls the rate of gastric emptying. In addition to gastrin emptying, when chyme enters the small intestine, it triggers other hormonal and neural events that coordinate the activities of the intestinal tract, pancreas, liver, and gallbladder.
The endocrine system controls the response of the various glands in the body and the release of hormones at the appropriate times.
One of the important factors under hormonal control is the stomach acid environment. During the gastric phase, the hormone gastrin is secreted by G cells in the stomach in response to the presence of proteins. Gastrin stimulates the release of stomach acid, or hydrochloric acid (HCl) which aids in the digestion of the proteins. However, when the stomach is emptied, the acidic environment need not be maintained and a hormone called somatostatin stops the release of hydrochloric acid. This is controlled by a negative feedback mechanism.
In the duodenum, digestive secretions from the liver, pancreas, and gallbladder play an important role in digesting chyme during the intestinal phase. In order to neutralize the acidic chyme, a hormone called secretin stimulates the pancreas to produce alkaline bicarbonate solution and deliver it to the duodenum. Secretin acts in tandem with another hormone called cholecystokinin (CCK). Not only does CCK stimulate the pancreas to produce the requisite pancreatic juices, it also stimulates the gallbladder to release bile into the duodenum.
Visit this website to learn more about the endocrine system. Review the text and watch the animation of how control is implemented in the endocrine system.
Another level of hormonal control occurs in response to the composition of food. Foods high in lipids take a long time to digest. A hormone called gastric inhibitory peptide is secreted by the small intestine to slow down the peristaltic movements of the intestine to allow fatty foods more time to be digested and absorbed.
Understanding the hormonal control of the digestive system is an important area of ongoing research. Scientists are exploring the role of each hormone in the digestive process and developing ways to target these hormones. Advances could lead to knowledge that may help to battle the obesity epidemic.
The brain and the endocrine system control digestive processes. The brain controls the responses of hunger and satiety. The endocrine system controls the release of hormones and enzymes required for digestion of food in the digestive tract.
Exercises
Which hormone controls the release of bile from the gallbladder
C
Which hormone stops acid secretion in the stomach?
B
In the famous conditioning experiment, Pavlov demonstrated that his dogs started drooling in response to a bell sounding. What part of the digestive process did he stimulate?
A
Describe how hormones regulate digestion.
Hormones control the different digestive enzymes that are secreted in the stomach and the intestine during the process of digestion and absorption. For example, the hormone gastrin stimulates stomach acid secretion in response to food intake. The hormone somatostatin stops the release of stomach acid.
Describe one or more scenarios where loss of hormonal regulation of digestion can lead to diseases.
There are many cases where loss of hormonal regulation can lead to illnesses. For example, the bilirubin produced by the breakdown of red blood cells is converted to bile by the liver. When there is malfunction of this process, there is excess bilirubin in the blood and bile levels are low. As a result, the body struggles with dealing with fatty food. This is why a patient suffering from jaundice is asked to eat a diet with almost zero fat.
A scientist is studying a model that has a mutation in the receptor for somatostatin that prevents hormone binding. How would this mutation affect the structure and function of the digestive system?
Somatostatin is the hormone that inhibits the release of HCl into the stomach lumen after the chyme has moved to the intestine. If the receptor for somatostatin is nonfunctional, somatostatin cannot signal to the stomach parietal cells to stop acid secretion. Thus, acid secretion will continue when there is no food present, and can cause damage to the stomach tissue. However, as long as the stomach remains intact the mutation should not slow digestion since acid will always be present in the stomach to digest any new boluses of food.
Glossary
Chapter 34 in OpenStax Concepts of Biology 2E

Most animals are complex multicellular organisms that require a mechanism for transporting nutrients throughout their bodies and removing waste products. The circulatory system has evolved over time from simple diffusion through cells in the early evolution of animals to a complex network of blood vessels that reach all parts of the human body. This extensive network supplies the cells, tissues, and organs with oxygen and nutrients, and removes carbon dioxide and waste, which are byproducts of respiration.
At the core of the human circulatory system is the heart. The size of a clenched fist, the human heart is protected beneath the rib cage. Made of specialized and unique cardiac muscle, it pumps blood throughout the body and to the heart itself. Heart contractions are driven by intrinsic electrical impulses that the brain and endocrine hormones help to regulate. Understanding the heart’s basic anatomy and function is important to understanding the body’s circulatory and respiratory systems.
Gas exchange is one essential function of the circulatory system. A circulatory system is not needed in organisms with no specialized respiratory organs because oxygen and carbon dioxide diffuse directly between their body tissues and the external environment. However, in organisms that possess lungs and gills, oxygen must be transported from these specialized respiratory organs to the body tissues via a circulatory system. Therefore, circulatory systems have had to evolve to accommodate the great diversity of body sizes and body types present among animals.
Chapter 40 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
In all animals, except a few simple types, the circulatory system is used to transport nutrients and gases through the body. Simple diffusion allows some water, nutrient, waste, and gas exchange into primitive animals that are only a few cell layers thick; however, bulk flow is the only method by which the entire body of larger more complex organisms is accessed.
The circulatory system is effectively a network of cylindrical vessels: the arteries, veins, and capillaries that emanate from a pump, the heart. In all vertebrate organisms, as well as some invertebrates, this is a closed-loop system, in which the blood is not free in a cavity. In a closed circulatory system, blood is contained inside blood vessels and circulates unidirectionally from the heart around the systemic circulatory route, then returns to the heart again, as illustrated in Figure 13.2a. As opposed to a closed system, arthropods—including insects, crustaceans, and most mollusks—have an open circulatory system, as illustrated in Figure 13.2b. In an open circulatory system, the blood is not enclosed in the blood vessels but is pumped into a cavity called a hemocoel and is called hemolymph because the blood mixes with the interstitial fluid. As the heart beats and the animal moves, the hemolymph circulates around the organs within the body cavity and then reenters the hearts through openings called ostia. This movement allows for gas and nutrient exchange. An open circulatory system does not use as much energy as a closed system to operate or to maintain; however, there is a trade-off with the amount of blood that can be moved to metabolically active organs and tissues that require high levels of oxygen. In fact, one reason that insects with wing spans of up to two feet wide (70 cm) are not around today is probably because they were outcompeted by the arrival of birds 150 million years ago. Birds, having a closed circulatory system, are thought to have moved more agilely, allowing them to get food faster and possibly to prey on the insects.
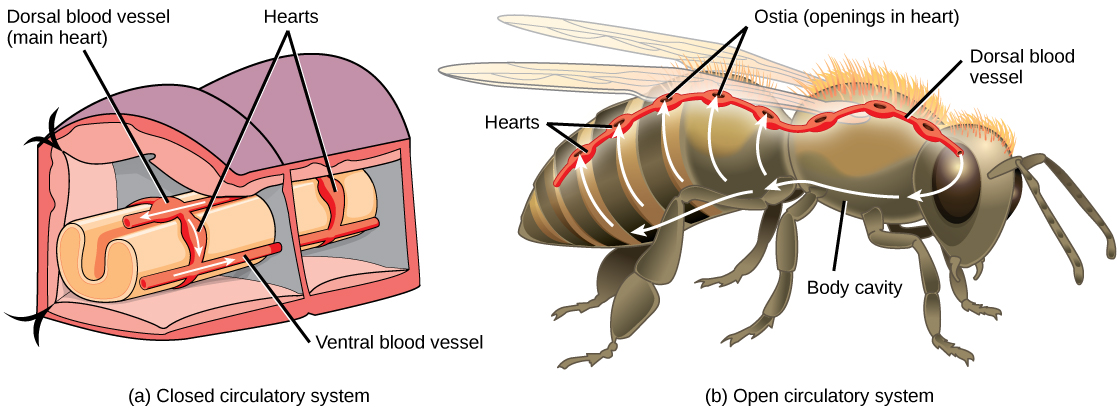
The circulatory system varies from simple systems in invertebrates to more complex systems in vertebrates. The simplest animals, such as the sponges (Porifera) and rotifers (Rotifera), do not need a circulatory system because diffusion allows adequate exchange of water, nutrients, and waste, as well as dissolved gases, as shown in Figure 13.3a. Organisms that are more complex but still only have two layers of cells in their body plan, such as jellies (Cnidaria) and comb jellies (Ctenophora) also use diffusion through their epidermis and internally through the gastrovascular compartment. Both their internal and external tissues are bathed in an aqueous environment and exchange fluids by diffusion on both sides, as illustrated in Figure 13.3b. Exchange of fluids is assisted by the pulsing of the jellyfish body.
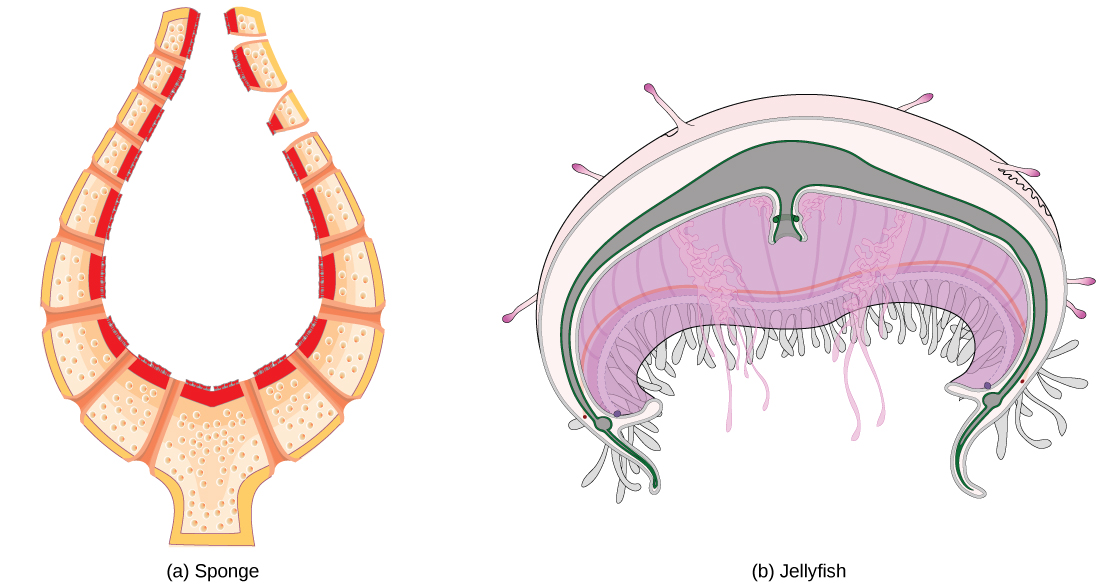
For more complex organisms, diffusion is not efficient for cycling gases, nutrients, and waste effectively through the body; therefore, more complex circulatory systems evolved. Most arthropods and many mollusks have open circulatory systems. In an open system, an elongated beating heart pushes the hemolymph through the body and muscle contractions help to move fluids. The larger more complex crustaceans, including lobsters, have developed arterial-like vessels to push blood through their bodies, and the most active mollusks, such as squids, have evolved a closed circulatory system and are able to move rapidly to catch prey. Closed circulatory systems are a characteristic of vertebrates; however, there are significant differences in the structure of the heart and the circulation of blood between the different vertebrate groups due to adaptation during evolution and associated differences in anatomy. Figure 13.4 illustrates the basic circulatory systems of some vertebrates: fish, amphibians, reptiles, and mammals.
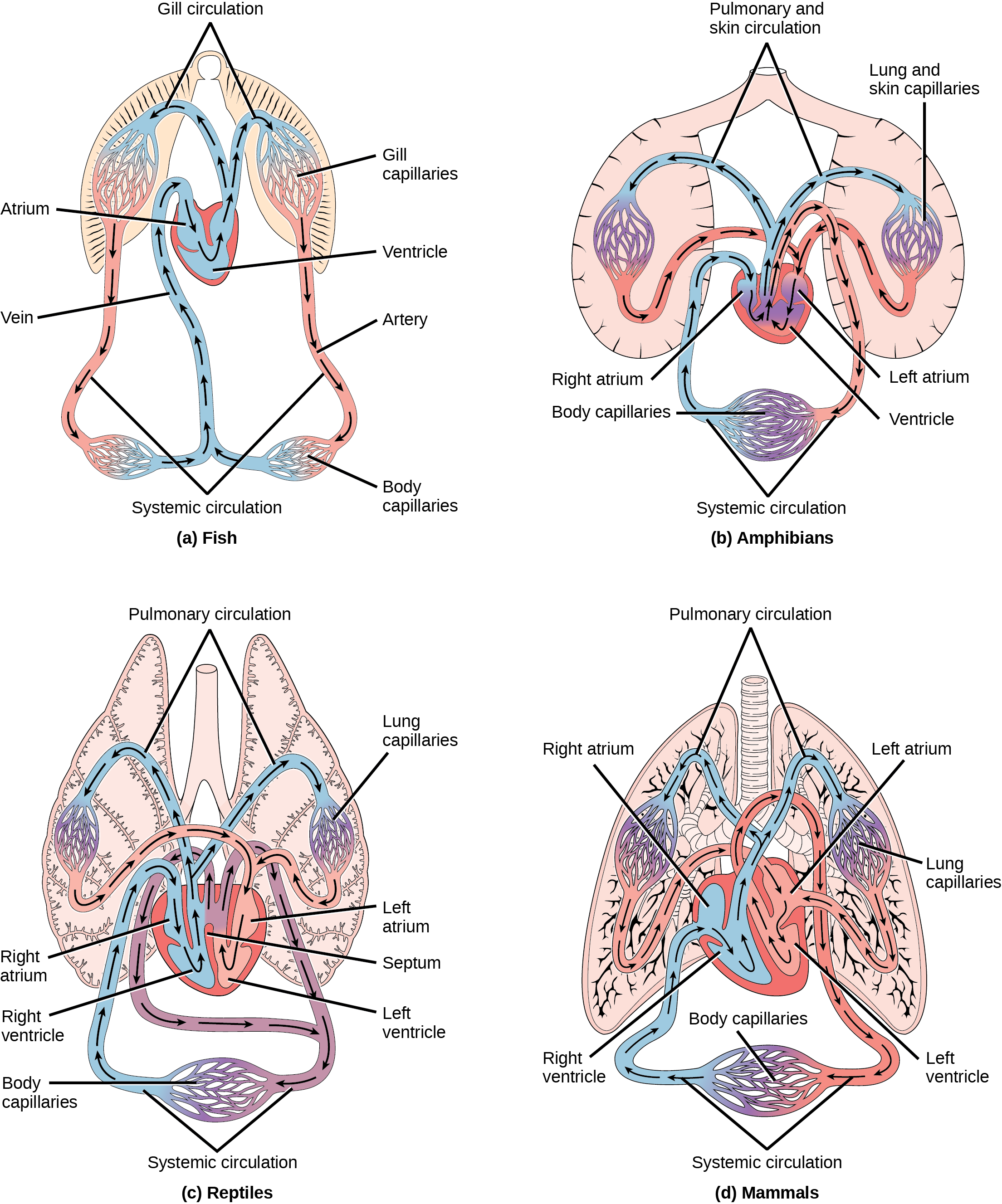
As illustrated in Figure 13.4a. Fish have a single circuit for blood flow and a two-chambered heart that has only a single atrium and a single ventricle. The atrium collects blood that has returned from the body and the ventricle pumps the blood to the gills where gas exchange occurs and the blood is re-oxygenated; this is called gill circulation. The blood then continues through the rest of the body before arriving back at the atrium; this is called systemic circulation. This unidirectional flow of blood produces a gradient of oxygenated to deoxygenated blood around the fish’s systemic circuit. The result is a limit in the amount of oxygen that can reach some of the organs and tissues of the body, reducing the overall metabolic capacity of fish.
In amphibians, reptiles, birds, and mammals, blood flow is directed in two circuits: one through the lungs and back to the heart, which is called pulmonary circulation, and the other throughout the rest of the body and its organs including the brain (systemic circulation). In amphibians, gas exchange also occurs through the skin during pulmonary circulation and is referred to as pulmocutaneous circulation.
As shown in Figure 13.4b, amphibians have a three-chambered heart that has two atria and one ventricle rather than the two-chambered heart of fish. The two atria (superior heart chambers) receive blood from the two different circuits (the lungs and the systems), and then there is some mixing of the blood in the heart’s ventricle (inferior heart chamber), which reduces the efficiency of oxygenation. The advantage to this arrangement is that high pressure in the vessels pushes blood to the lungs and body. The mixing is mitigated by a ridge within the ventricle that diverts oxygen-rich blood through the systemic circulatory system and deoxygenated blood to the pulmocutaneous circuit. For this reason, amphibians are often described as having double circulation.
Most reptiles also have a three-chambered heart similar to the amphibian heart that directs blood to the pulmonary and systemic circuits, as shown in Figure 13.4c. The ventricle is divided more effectively by a partial septum, which results in less mixing of oxygenated and deoxygenated blood. Some reptiles (alligators and crocodiles) are the most primitive animals to exhibit a four-chambered heart. Crocodilians have a unique circulatory mechanism where the heart shunts blood from the lungs toward the stomach and other organs during long periods of submergence, for instance, while the animal waits for prey or stays underwater waiting for prey to rot. One adaptation includes two main arteries that leave the same part of the heart: one takes blood to the lungs and the other provides an alternate route to the stomach and other parts of the body. Two other adaptations include a hole in the heart between the two ventricles, called the foramen of Panizza, which allows blood to move from one side of the heart to the other, and specialized connective tissue that slows the blood flow to the lungs. Together these adaptations have made crocodiles and alligators one of the most evolutionarily successful animal groups on earth.
In mammals and birds, the heart is also divided into four chambers: two atria and two ventricles, as illustrated in Figure 13.4d. The oxygenated blood is separated from the deoxygenated blood, which improves the efficiency of double circulation and is probably required for the warm-blooded lifestyle of mammals and birds. The four-chambered heart of birds and mammals evolved independently from a three-chambered heart. The independent evolution of the same or a similar biological trait is referred to as convergent evolution.
In most animals, the circulatory system is used to transport blood through the body. Some primitive animals use diffusion for the exchange of water, nutrients, and gases. However, complex organisms use the circulatory system to carry gases, nutrients, and waste through the body. Circulatory systems may be open (mixed with the interstitial fluid) or closed (separated from the interstitial fluid). Closed circulatory systems are a characteristic of vertebrates; however, there are significant differences in the structure of the heart and the circulation of blood between the different vertebrate groups due to adaptions during evolution and associated differences in anatomy. Fish have a two-chambered heart with unidirectional circulation. Amphibians have a three-chambered heart, which has some mixing of the blood, and they have double circulation. Most non-avian reptiles have a three-chambered heart, but have little mixing of the blood; they have double circulation. Mammals and birds have a four-chambered heart with no mixing of the blood and double circulation.
Exercises
Why are open circulatory systems advantageous to some animals?
A
Some animals use diffusion instead of a circulatory system. Examples include:
D
Blood flow that is directed through the lungs and back to the heart is called ________.
C
Describe a closed circulatory system.
A closed circulatory system is a closed-loop system, in which blood is not free in a cavity. Blood is separate from the bodily interstitial fluid and contained within blood vessels. In this type of system, blood circulates unidirectionally from the heart around the systemic circulatory route, and then returns to the heart.
Describe systemic circulation.
Systemic circulation flows through the systems of the body. The blood flows away from the heart to the brain, liver, kidneys, stomach, and other organs, the limbs, and the muscles of the body; it then returns to the heart.
Glossary
Chapter 40 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
Hemoglobin is responsible for distributing oxygen, and to a lesser extent, carbon dioxide, throughout the circulatory systems of humans, vertebrates, and many invertebrates. The blood is more than the proteins, though. Blood is actually a term used to describe the liquid that moves through the vessels and includes plasma (the liquid portion, which contains water, proteins, salts, lipids, and glucose) and the cells (red and white cells) and cell fragments called platelets. Blood plasma is actually the dominant component of blood and contains the water, proteins, electrolytes, lipids, and glucose. The cells are responsible for carrying the gases (red cells) and the immune response (white). The platelets are responsible for blood clotting. Interstitial fluid that surrounds cells is separate from the blood, but in hemolymph, they are combined. In humans, cellular components make up approximately 45 percent of the blood and the liquid plasma 55 percent. Blood is 20 percent of a person’s extracellular fluid and eight percent of weight.
Blood, like the human blood illustrated in Figure 13.5 is important for regulation of the body’s systems and homeostasis. Blood helps maintain homeostasis by stabilizing pH, temperature, osmotic pressure, and by eliminating excess heat. Blood supports growth by distributing nutrients and hormones, and by removing waste. Blood plays a protective role by transporting clotting factors and platelets to prevent blood loss and transporting the disease-fighting agents or white blood cells to sites of infection.
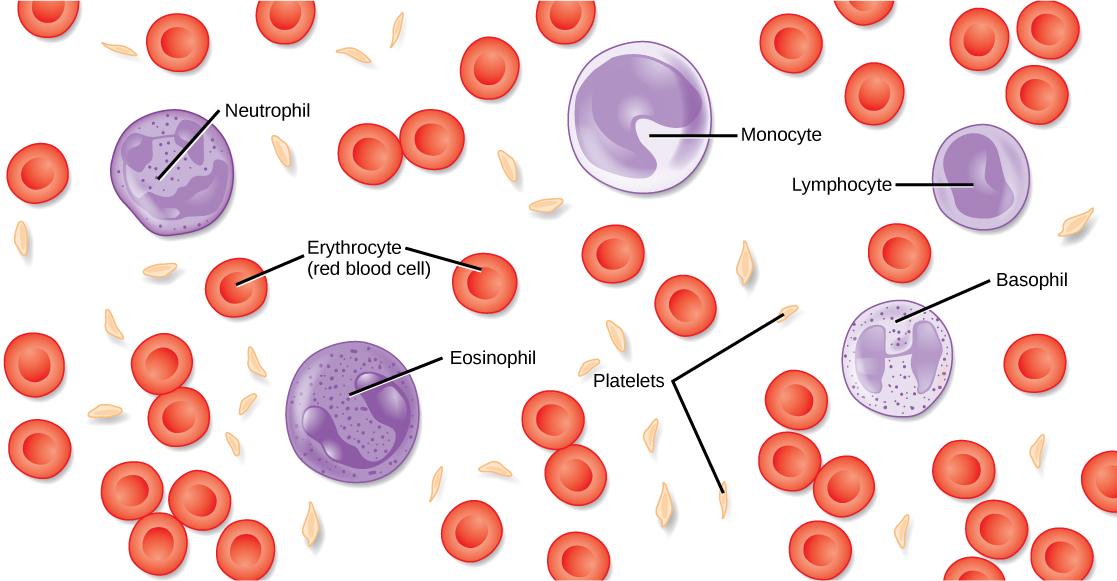
Red blood cells, or erythrocytes (erythro- = “red”; -cyte = “cell”), are specialized cells that circulate through the body delivering oxygen to cells; they are formed from stem cells in the bone marrow. In mammals, red blood cells are small biconcave cells that at maturity do not contain a nucleus or mitochondria and are only 7–8 µm in size. In birds and non-avian reptiles, a nucleus is still maintained in red blood cells.
The red coloring of blood comes from the iron-containing protein hemoglobin, illustrated in Figure 13.6a. The principle job of this protein is to carry oxygen, but it also transports carbon dioxide as well. Hemoglobin is packed into red blood cells at a rate of about 250 million molecules of hemoglobin per cell. Each hemoglobin molecule binds four oxygen molecules so that each red blood cell carries one billion molecules of oxygen. There are approximately 25 trillion red blood cells in the five liters of blood in the human body, which could carry up to 25 sextillion (25 × 1021) molecules of oxygen in the body at any time. In mammals, the lack of organelles in erythrocytes leaves more room for the hemoglobin molecules, and the lack of mitochondria also prevents use of the oxygen for metabolic respiration. Only mammals have anucleated red blood cells, and some mammals (camels, for instance) even have nucleated red blood cells. The advantage of nucleated red blood cells is that these cells can undergo mitosis. Anucleated red blood cells metabolize anaerobically (without oxygen), making use of a primitive metabolic pathway to produce ATP and increase the efficiency of oxygen transport.
Not all organisms use hemoglobin as the method of oxygen transport. Invertebrates that utilize hemolymph rather than blood use different pigments to bind to the oxygen. These pigments use copper or iron to the oxygen. Invertebrates have a variety of other respiratory pigments. Hemocyanin, a blue-green, copper-containing protein, illustrated in Figure 13.6b is found in mollusks, crustaceans, and some of the arthropods. Chlorocruorin, a green-colored, iron-containing pigment is found in four families of polychaete tubeworms. Hemerythrin, a red, iron-containing protein is found in some polychaete worms and annelids and is illustrated in Figure 13.6c. Despite the name, hemerythrin does not contain a heme group and its oxygen-carrying capacity is poor compared to hemoglobin.
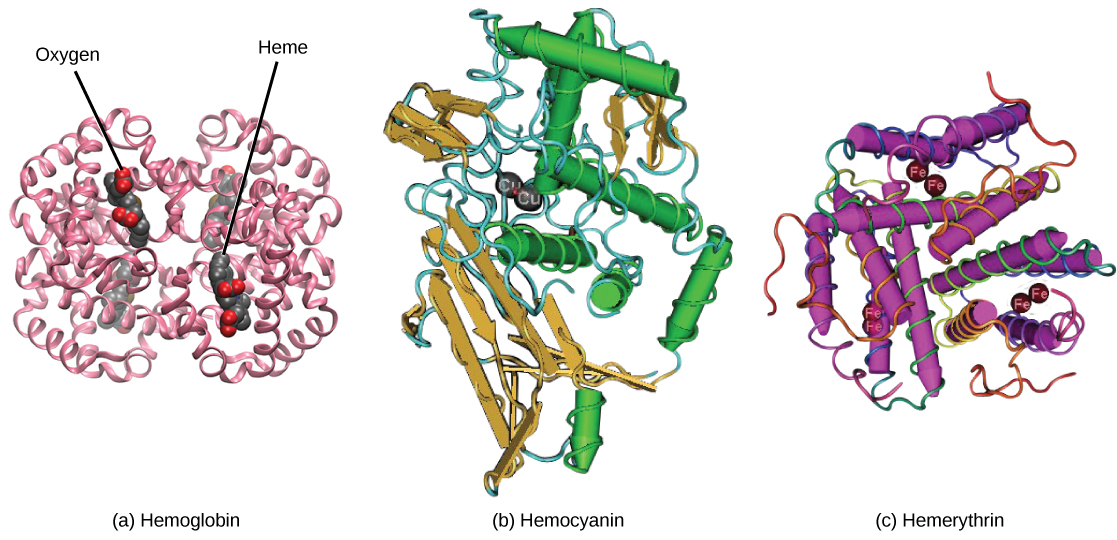
The small size and large surface area of red blood cells allows for rapid diffusion of oxygen and carbon dioxide across the plasma membrane. In the lungs, carbon dioxide is released and oxygen is taken in by the blood. In the tissues, oxygen is released from the blood and carbon dioxide is bound for transport back to the lungs. Studies have found that hemoglobin also binds nitrous oxide (NO). NO is a vasodilator that relaxes the blood vessels and capillaries and may help with gas exchange and the passage of red blood cells through narrow vessels. Nitroglycerin, a heart medication for angina and heart attacks, is converted to NO to help relax the blood vessels and increase oxygen flow through the body.
A characteristic of red blood cells is their glycolipid and glycoprotein coating; these are lipids and proteins that have carbohydrate molecules attached. In humans, the surface glycoproteins and glycolipids on red blood cells vary between individuals, producing the different blood types, such as A, B, and O. Red blood cells have an average life span of 120 days, at which time they are broken down and recycled in the liver and spleen by phagocytic macrophages, a type of white blood cell.
White blood cells, also called leukocytes (leuko = white), make up approximately one percent by volume of the cells in blood. The role of white blood cells is very different than that of red blood cells: they are primarily involved in the immune response to identify and target pathogens, such as invading bacteria, viruses, and other foreign organisms. White blood cells are formed continually; some only live for hours or days, but some live for years.
The morphology of white blood cells differs significantly from red blood cells. They have nuclei and do not contain hemoglobin. The different types of white blood cells are identified by their microscopic appearance after histologic staining, and each has a different specialized function. The two main groups, both illustrated in Figure 13.7 are the granulocytes, which include the neutrophils, eosinophils, and basophils, and the agranulocytes, which include the monocytes and lymphocytes.
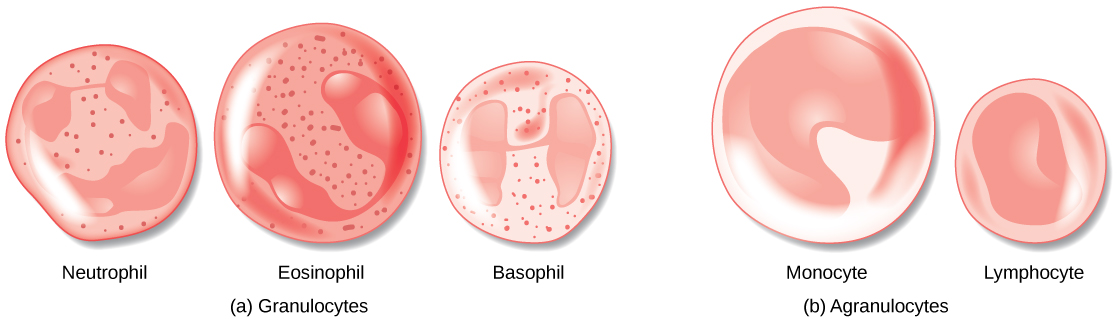
Granulocytes contain granules in their cytoplasm; the agranulocytes are so named because of the lack of granules in their cytoplasm. Some leukocytes become macrophages that either stay at the same site or move through the bloodstream and gather at sites of infection or inflammation where they are attracted by chemical signals from foreign particles and damaged cells. Lymphocytes are the primary cells of the immune system and include B cells, T cells, and natural killer cells. B cells destroy bacteria and inactivate their toxins. They also produce antibodies. T cells attack viruses, fungi, some bacteria, transplanted cells, and cancer cells. T cells attack viruses by releasing toxins that kill the viruses. Natural killer cells attack a variety of infectious microbes and certain tumor cells.
One reason that HIV poses significant management challenges is because the virus directly targets T cells by gaining entry through a receptor. Once inside the cell, HIV then multiplies using the T cell’s own genetic machinery. After the HIV virus replicates, it is transmitted directly from the infected T cell to macrophages. The presence of HIV can remain unrecognized for an extensive period of time before full disease symptoms develop.
Blood must clot to heal wounds and prevent excess blood loss. Small cell fragments called platelets (thrombocytes) are attracted to the wound site where they adhere by extending many projections and releasing their contents. These contents activate other platelets and also interact with other coagulation factors, which convert fibrinogen, a water-soluble protein present in blood serum into fibrin (a non-water soluble protein), causing the blood to clot. Many of the clotting factors require vitamin K to work, and vitamin K deficiency can lead to problems with blood clotting. Many platelets converge and stick together at the wound site forming a platelet plug (also called a fibrin clot), as illustrated in Figure 13.8b. The plug or clot lasts for a number of days and stops the loss of blood. Platelets are formed from the disintegration of larger cells called megakaryocytes, like that shown in Figure 13.8a. For each megakaryocyte, 2000–3000 platelets are formed with 150,000 to 400,000 platelets present in each cubic millimeter of blood. Each platelet is disc shaped and 2–4 μm in diameter. They contain many small vesicles but do not contain a nucleus.
(
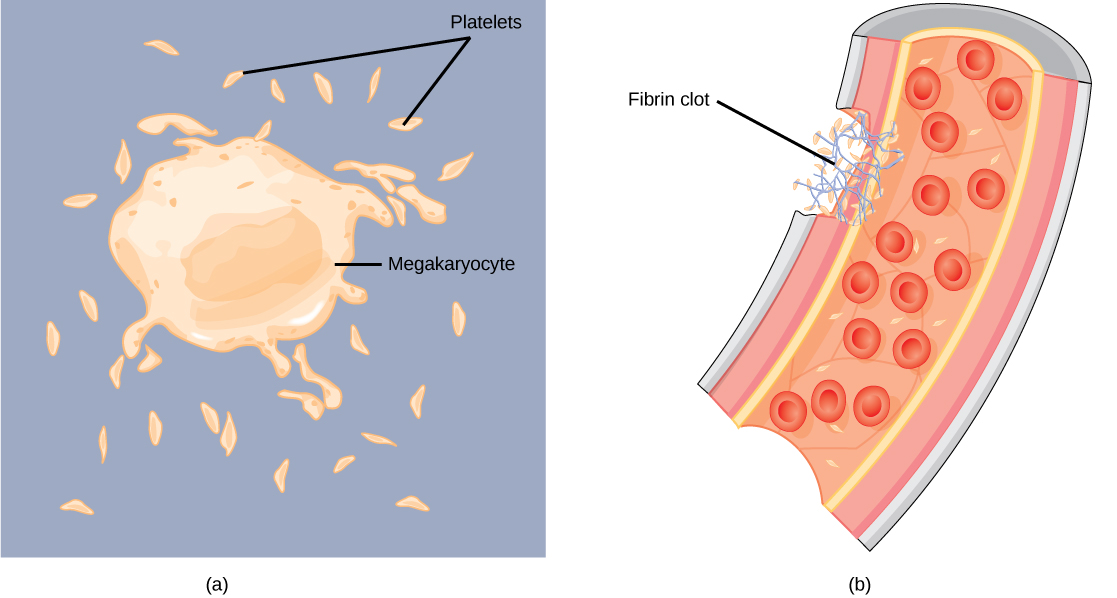
The liquid component of blood is called plasma, and it is separated by spinning or centrifuging the blood at high rotations (3000 rpm or higher). The blood cells and platelets are separated by centrifugal forces to the bottom of a specimen tube. The upper liquid layer, the plasma, consists of 90 percent water along with various substances required for maintaining the body’s pH, osmotic load, and for protecting the body. The plasma also contains the coagulation factors and antibodies.
The plasma component of blood without the coagulation factors is called the serum. Serum is similar to interstitial fluid in which the correct composition of key ions acting as electrolytes is essential for normal functioning of muscles and nerves. Other components in the serum include proteins that assist with maintaining pH and osmotic balance while giving viscosity to the blood. The serum also contains antibodies, specialized proteins that are important for defense against viruses and bacteria. Lipids, including cholesterol, are also transported in the serum, along with various other substances including nutrients, hormones, metabolic waste, plus external substances, such as, drugs, viruses, and bacteria.
Human serum albumin is the most abundant protein in human blood plasma and is synthesized in the liver. Albumin, which constitutes about half of the blood serum protein, transports hormones and fatty acids, buffers pH, and maintains osmotic pressures. Immunoglobin is a protein antibody produced in the mucosal lining and plays an important role in antibody mediated immunity.
Red blood cells are coated in antigens made of glycolipids and glycoproteins. The composition of these molecules is determined by genetics, which have evolved over time. In humans, the different surface antigens are grouped into 24 different blood groups with more than 100 different antigens on each red blood cell. The two most well known blood groups are the ABO, shown in Figure 13.9, and Rh systems. The surface antigens in the ABO blood group are glycolipids, called antigen A and antigen B. People with blood type A have antigen A, those with blood type B have antigen B, those with blood type AB have both antigens, and people with blood type O have neither antigen. Antibodies called agglutinougens are found in the blood plasma and react with the A or B antigens, if the two are mixed. When type A and type B blood are combined, agglutination (clumping) of the blood occurs because of antibodies in the plasma that bind with the opposing antigen; this causes clots that coagulate in the kidney causing kidney failure. Type O blood has neither A or B antigens, and therefore, type O blood can be given to all blood types. Type O negative blood is the universal donor. Type AB positive blood is the universal acceptor because it has both A and B antigen. The ABO blood groups were discovered in 1900 and 1901 by Karl Landsteiner at the University of Vienna.
The Rh blood group was first discovered in Rhesus monkeys. Most people have the Rh antigen (Rh+) and do not have anti-Rh antibodies in their blood. The few people who do not have the Rh antigen and are Rh– can develop anti-Rh antibodies if exposed to Rh+ blood. This can happen after a blood transfusion or after an Rh– woman has an Rh+ baby. The first exposure does not usually cause a reaction; however, at the second exposure, enough antibodies have built up in the blood to produce a reaction that causes agglutination and breakdown of red blood cells. An injection can prevent this reaction.
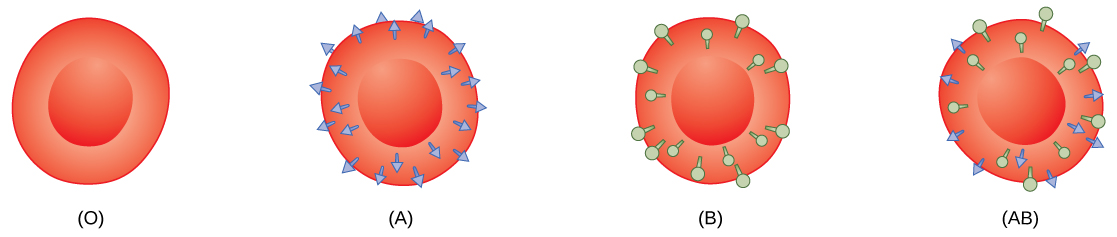
Play a blood typing game on the Nobel Prize website to solidify your understanding of blood types.
Specific components of the blood include red blood cells, white blood cells, platelets, and the plasma, which contains coagulation factors and serum. Blood is important for regulation of the body’s pH, temperature, osmotic pressure, the circulation of nutrients and removal of waste, the distribution of hormones from endocrine glands, and the elimination of excess heat; it also contains components for blood clotting. Red blood cells are specialized cells that contain hemoglobin and circulate through the body delivering oxygen to cells. White blood cells are involved in the immune response to identify and target invading bacteria, viruses, and other foreign organisms; they also recycle waste components, such as old red blood cells. Platelets and blood clotting factors cause the change of the soluble protein fibrinogen to the insoluble protein fibrin at a wound site forming a plug. Plasma consists of 90 percent water along with various substances, such as coagulation factors and antibodies. The serum is the plasma component of the blood without the coagulation factors.
Exercises
White blood cells:
D
Platelet plug formation occurs at which point?
C
In humans, the plasma comprises what percentage of the blood?
B
The red blood cells of birds differ from mammalian red blood cells because:
C
Describe the cause of different blood type groups.
Red blood cells are coated with proteins called antigens made of glycolipids and glycoproteins. When type A and type B blood are mixed, the blood agglutinates because of antibodies in the plasma that bind with the opposing antigen. Type O blood has no antigens. The Rh blood group has either the Rh antigen (Rh+) or no Rh antigen (Rh–).
List some of the functions of blood in the body.
Blood is important for regulation of the body’s pH, temperature, and osmotic pressure, the circulation of nutrients and removal of wastes, the distribution of hormones from endocrine glands, the elimination of excess heat; it also contains components for the clotting of blood to prevent blood loss. Blood also transports clotting factors and disease-fighting agents.
How does the lymphatic system work with blood flow?
Lymph capillaries take fluid from the blood to the lymph nodes. The lymph nodes filter the lymph by percolation through connective tissue filled with white blood cells. The white blood cells remove infectious agents, such as bacteria and viruses, to clean the lymph before it returns to the bloodstream.
Glossary
Chapter 40 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
The heart is a complex muscle that pumps blood through the three divisions of the circulatory system: the coronary (vessels that serve the heart), pulmonary (heart and lungs), and systemic (systems of the body), as shown in (Figure). Coronary circulation intrinsic to the heart takes blood directly from the main artery (aorta) coming from the heart. For pulmonary and systemic circulation, the heart has to pump blood to the lungs or the rest of the body, respectively. In vertebrates, the lungs are relatively close to the heart in the thoracic cavity. The shorter distance to pump means that the muscle wall on the right side of the heart is not as thick as the left side which must have enough pressure to pump blood all the way to your big toe.
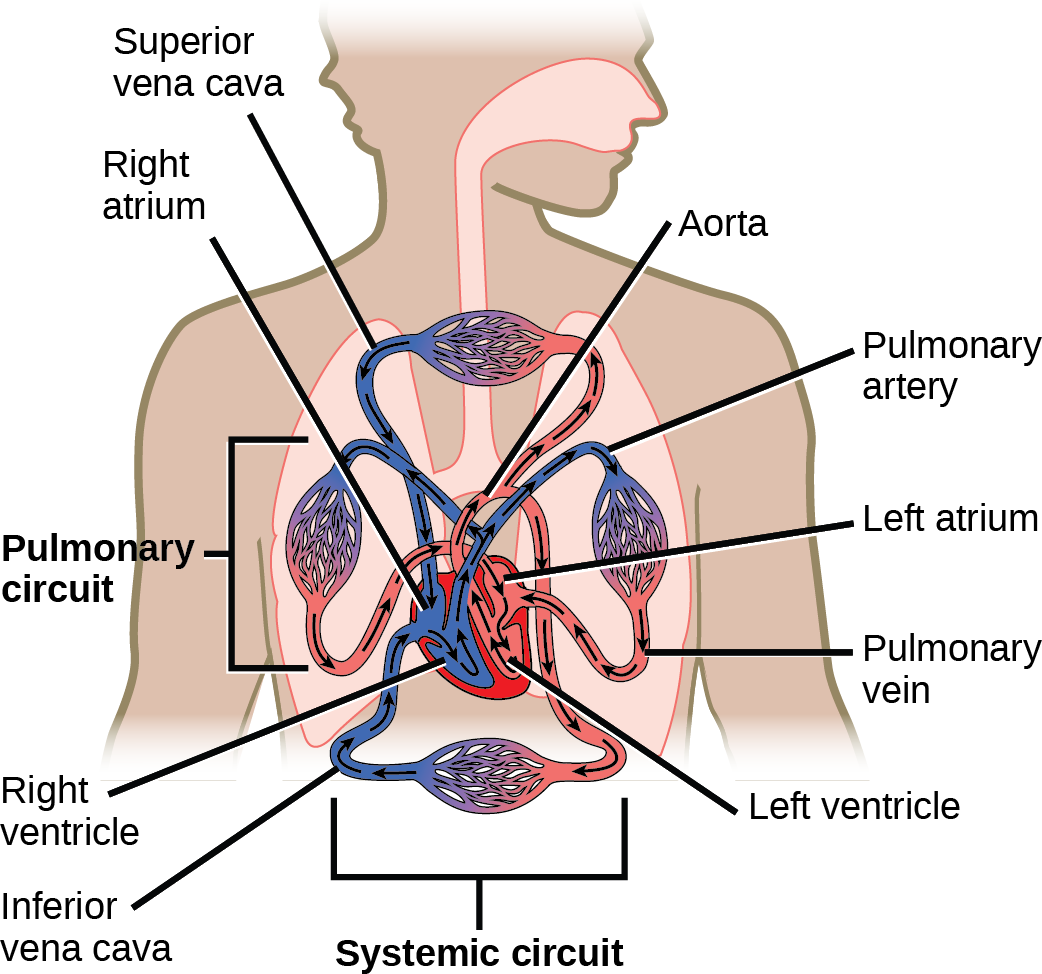
Which of the following statements about the circulatory system is false?
The heart muscle is asymmetrical as a result of the distance blood must travel in the pulmonary and systemic circuits. Since the right side of the heart sends blood to the pulmonary circuit it is smaller than the left side which must send blood out to the whole body in the systemic circuit, as shown in Figure 13.11. In humans, the heart is about the size of a clenched fist; it is divided into four chambers: two atria and two ventricles. There is one atrium and one ventricle on the right side and one atrium and one ventricle on the left side. The atria are the chambers that receive blood, and the ventricles are the chambers that pump blood. The right atrium receives deoxygenated blood from the superior vena cava, which drains blood from the jugular vein that comes from the brain and from the veins that come from the arms, as well as from the inferior vena cava which drains blood from the veins that come from the lower organs and the legs. In addition, the right atrium receives blood from the coronary sinus which drains deoxygenated blood from the heart itself. This deoxygenated blood then passes to the right ventricle through the atrioventricular valve or the tricuspid valve, a flap of connective tissue that opens in only one direction to prevent the backflow of blood. The valve separating the chambers on the left side of the heart valve is called the biscuspid or mitral valve. After it is filled, the right ventricle pumps the blood through the pulmonary arteries, bypassing the semilunar valve (or pulmonic valve) to the lungs for re-oxygenation. After blood passes through the pulmonary arteries, the right semilunar valves close preventing the blood from flowing backwards into the right ventricle. The left atrium then receives the oxygen-rich blood from the lungs via the pulmonary veins. This blood passes through the bicuspid valve or mitral valve (the atrioventricular valve on the left side of the heart) to the left ventricle where the blood is pumped out through the aorta, the major artery of the body, taking oxygenated blood to the organs and muscles of the body. Once blood is pumped out of the left ventricle and into the aorta, the aortic semilunar valve (or aortic valve) closes preventing blood from flowing backward into the left ventricle. This pattern of pumping is referred to as double circulation and is found in all mammals.
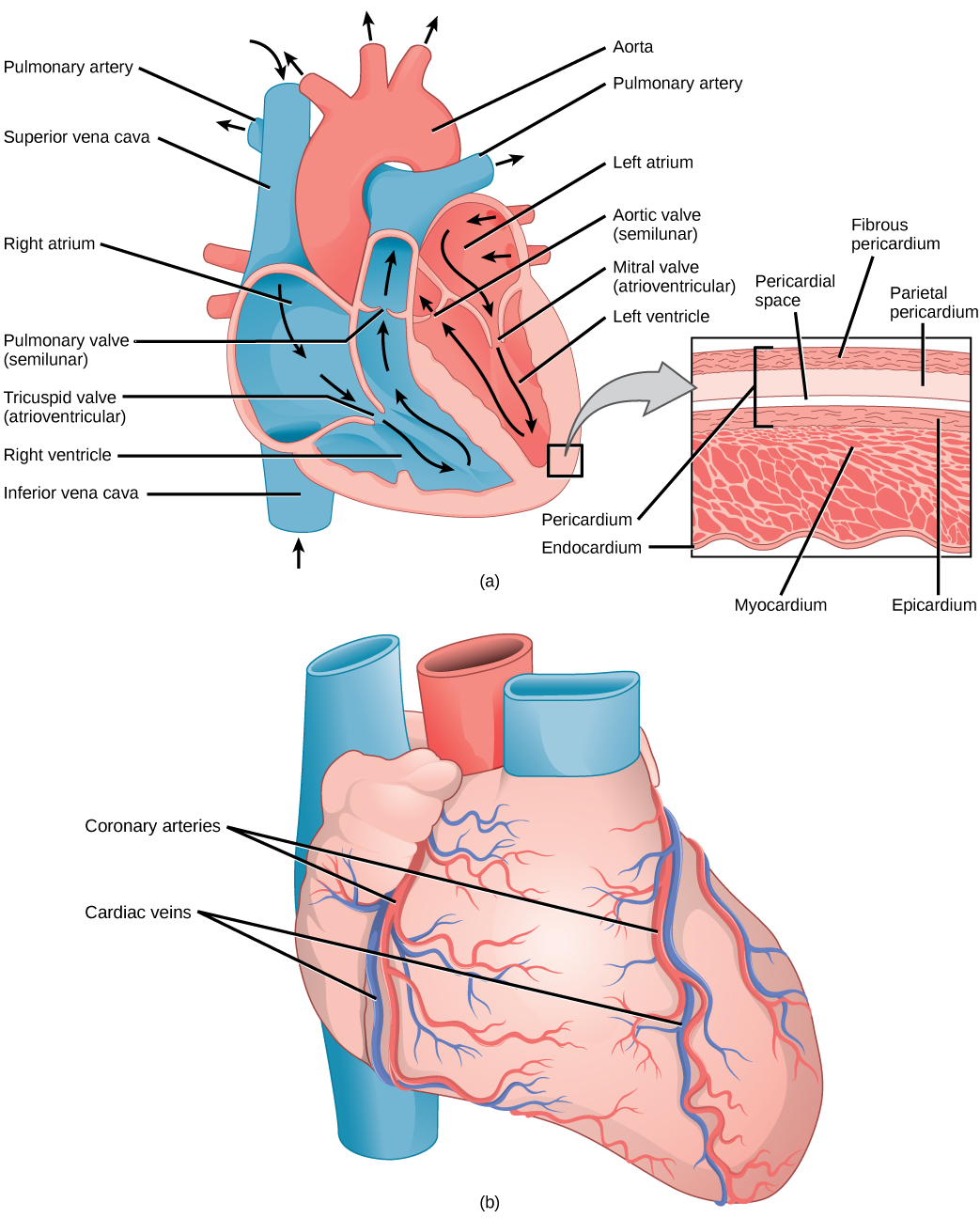
Which of the following statements about the heart is false?
The heart is composed of three layers; the epicardium, the myocardium, and the endocardium, illustrated in Figure 13.11. The inner wall of the heart has a lining called the endocardium. The myocardium consists of the heart muscle cells that make up the middle layer and the bulk of the heart wall. The outer layer of cells is called the epicardium, of which the second layer is a membranous layered structure called the pericardium that surrounds and protects the heart; it allows enough room for vigorous pumping but also keeps the heart in place to reduce friction between the heart and other structures.
The heart has its own blood vessels that supply the heart muscle with blood. The coronary arteries branch from the aorta and surround the outer surface of the heart like a crown. They diverge into capillaries where the heart muscle is supplied with oxygen before converging again into the coronary veins to take the deoxygenated blood back to the right atrium where the blood will be re-oxygenated through the pulmonary circuit. The heart muscle will die without a steady supply of blood. Atherosclerosis is the blockage of an artery by the buildup of fatty plaques. Because of the size (narrow) of the coronary arteries and their function in serving the heart itself, atherosclerosis can be deadly in these arteries. The slowdown of blood flow and subsequent oxygen deprivation that results from atherosclerosis causes severe pain, known as angina, and complete blockage of the arteries will cause myocardial infarction: the death of cardiac muscle tissue, commonly known as a heart attack.
The main purpose of the heart is to pump blood through the body; it does so in a repeating sequence called the cardiac cycle. The cardiac cycle is the coordination of the filling and emptying of the heart of blood by electrical signals that cause the heart muscles to contract and relax. The human heart beats over 100,000 times per day. In each cardiac cycle, the heart contracts (systole), pushing out the blood and pumping it through the body; this is followed by a relaxation phase (diastole), where the heart fills with blood, as illustrated in Figure 13.12. The atria contract at the same time, forcing blood through the atrioventricular valves into the ventricles. Closing of the atrioventricular valves produces a monosyllabic “lup” sound. Following a brief delay, the ventricles contract at the same time forcing blood through the semilunar valves into the aorta and the artery transporting blood to the lungs (via the pulmonary artery). Closing of the semilunar valves produces a monosyllabic “dup” sound.
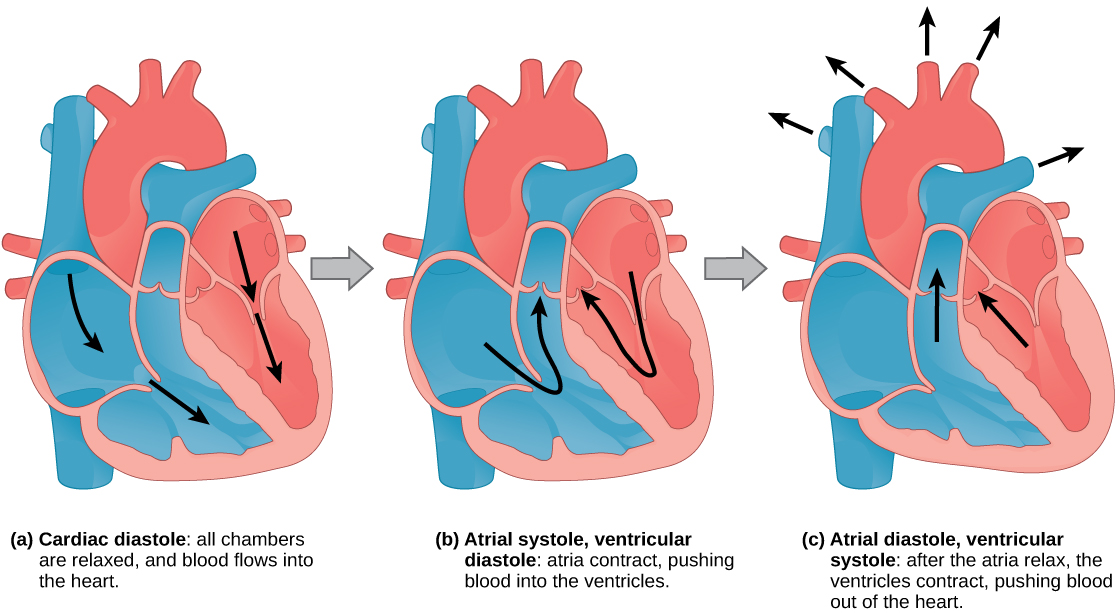
The pumping of the heart is a function of the cardiac muscle cells, or cardiomyocytes, that make up the heart muscle. Cardiomyocytes, shown in Figure 13.13, are distinctive muscle cells that are striated like skeletal muscle but pump rhythmically and involuntarily like smooth muscle; they are connected by intercalated disks exclusive to cardiac muscle. They are self-stimulated for a period of time and isolated cardiomyocytes will beat if given the correct balance of nutrients and electrolytes.

The autonomous beating of cardiac muscle cells is regulated by the heart’s internal pacemaker that uses electrical signals to time the beating of the heart. The electrical signals and mechanical actions, illustrated in Figure 13.14, are intimately intertwined. The internal pacemaker starts at the sinoatrial (SA) node, which is located near the wall of the right atrium. Electrical charges spontaneously pulse from the SA node causing the two atria to contract in unison. The pulse reaches a second node, called the atrioventricular (AV) node, between the right atrium and right ventricle where it pauses for approximately 0.1 second before spreading to the walls of the ventricles. From the AV node, the electrical impulse enters the bundle of His, then to the left and right bundle branches extending through the interventricular septum. Finally, the Purkinje fibers conduct the impulse from the apex of the heart up the ventricular myocardium, and then the ventricles contract. This pause allows the atria to empty completely into the ventricles before the ventricles pump out the blood. The electrical impulses in the heart produce electrical currents that flow through the body and can be measured on the skin using electrodes. This information can be observed as an electrocardiogram (ECG)—a recording of the electrical impulses of the cardiac muscle.
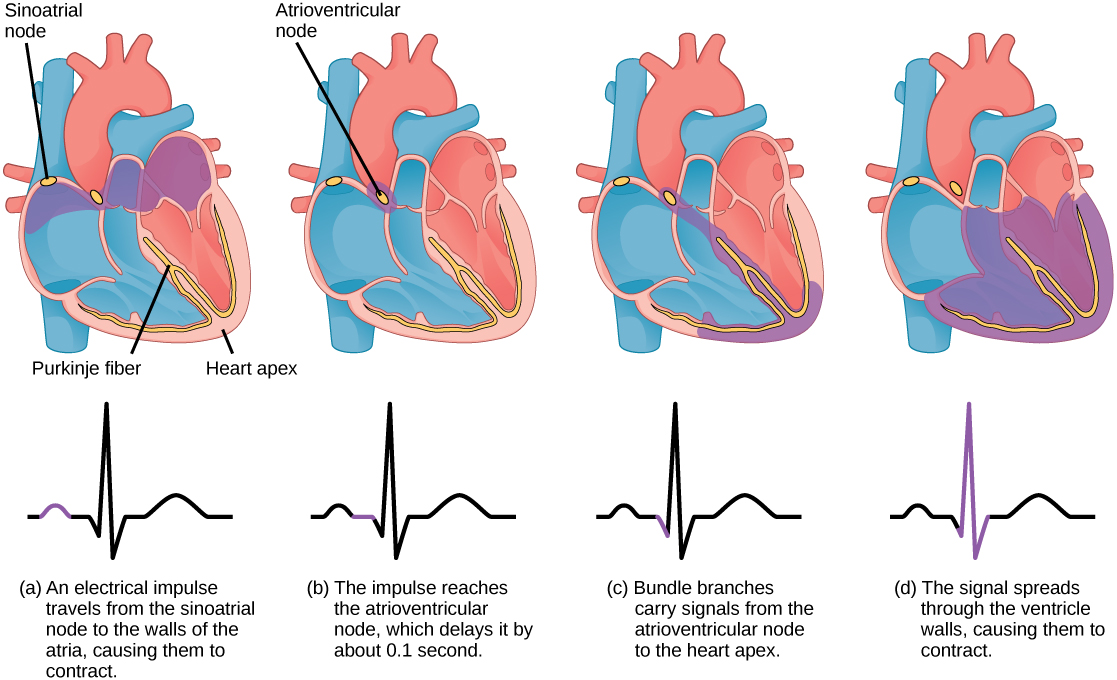
Visit this site to see the heart’s “pacemaker” in action.
The blood from the heart is carried through the body by a complex network of blood vessels (Figure13.15). Arteries take blood away from the heart. The main artery is the aorta that branches into major arteries that take blood to different limbs and organs. These major arteries include the carotid artery that takes blood to the brain, the brachial arteries that take blood to the arms, and the thoracic artery that takes blood to the thorax and then into the hepatic, renal, and gastric arteries for the liver, kidney, and stomach, respectively. The iliac artery takes blood to the lower limbs. The major arteries diverge into minor arteries, and then smaller vessels called arterioles, to reach more deeply into the muscles and organs of the body.
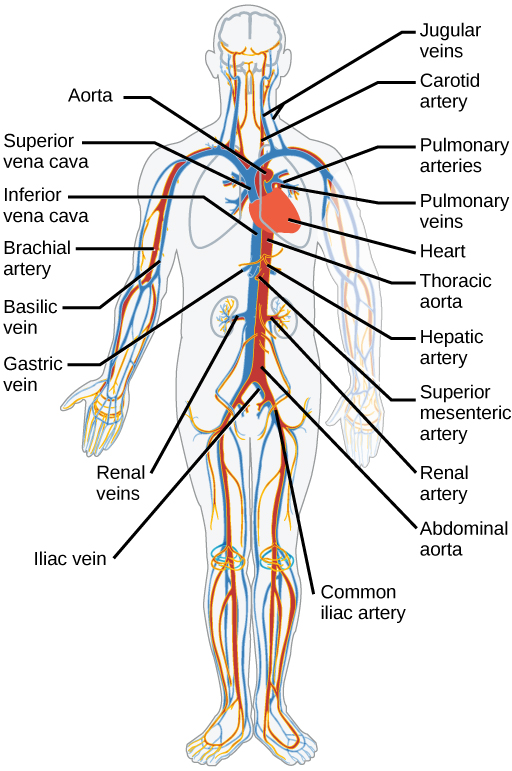
Arterioles diverge into capillary beds. Capillary beds contain a large number (10 to 100) of capillaries that branch among the cells and tissues of the body. Capillaries are narrow-diameter tubes that can fit red blood cells through in single file and are the sites for the exchange of nutrients, waste, and oxygen with tissues at the cellular level. Fluid also crosses into the interstitial space from the capillaries. The capillaries converge again into venules that connect to minor veins that finally connect to major veins that take blood high in carbon dioxide back to the heart. Veins are blood vessels that bring blood back to the heart. The major veins drain blood from the same organs and limbs that the major arteries supply. Fluid is also brought back to the heart via the lymphatic system.
The structure of the different types of blood vessels reflects their function or layers. There are three distinct layers, or tunics, that form the walls of blood vessels (Figure 13.16). The first tunic is a smooth, inner lining of endothelial cells that are in contact with the red blood cells. The endothelial tunic is continuous with the endocardium of the heart. In capillaries, this single layer of cells is the location of diffusion of oxygen and carbon dioxide between the endothelial cells and red blood cells, as well as the exchange site via endocytosis and exocytosis. The movement of materials at the site of capillaries is regulated by vasoconstriction, narrowing of the blood vessels, and vasodilation, widening of the blood vessels; this is important in the overall regulation of blood pressure.
Veins and arteries both have two further tunics that surround the endothelium: the middle tunic is composed of smooth muscle and the outermost layer is connective tissue (collagen and elastic fibers). The elastic connective tissue stretches and supports the blood vessels, and the smooth muscle layer helps regulate blood flow by altering vascular resistance through vasoconstriction and vasodilation. The arteries have thicker smooth muscle and connective tissue than the veins to accommodate the higher pressure and speed of freshly pumped blood. The veins are thinner walled as the pressure and rate of flow are much lower. In addition, veins are structurally different than arteries in that veins have valves to prevent the backflow of blood. Because veins have to work against gravity to get blood back to the heart, contraction of skeletal muscle assists with the flow of blood back to the heart.
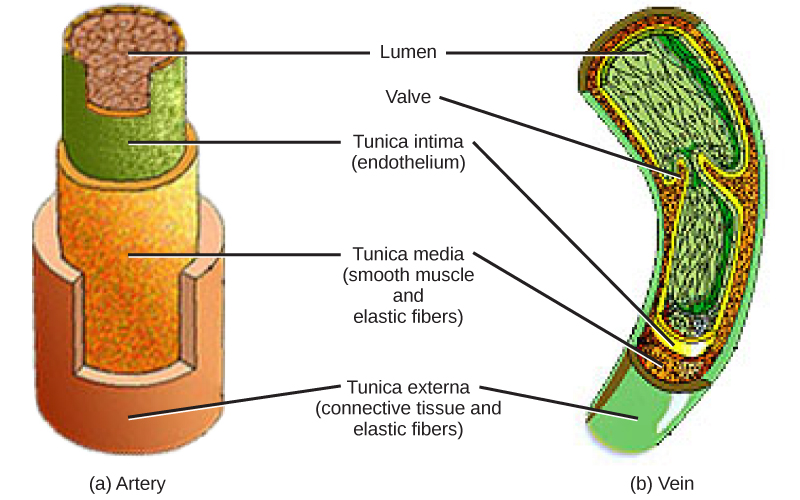
The heart muscle pumps blood through three divisions of the circulatory system: coronary, pulmonary, and systemic. There is one atrium and one ventricle on the right side and one atrium and one ventricle on the left side. The pumping of the heart is a function of cardiomyocytes, distinctive muscle cells that are striated like skeletal muscle but pump rhythmically and involuntarily like smooth muscle. The internal pacemaker starts at the sinoatrial node, which is located near the wall of the right atrium. Electrical charges pulse from the SA node causing the two atria to contract in unison; then the pulse reaches the atrioventricular node between the right atrium and right ventricle. A pause in the electric signal allows the atria to empty completely into the ventricles before the ventricles pump out the blood. The blood from the heart is carried through the body by a complex network of blood vessels; arteries take blood away from the heart, and veins bring blood back to the heart.
Exercises
(Figure) Which of the following statements about the circulatory system is false?
(Figure) C
(Figure) Which of the following statements about the heart is false?
(Figure) B
The heart’s internal pacemaker beats by:
B
During the systolic phase of the cardiac cycle, the heart is ________.
A
Cardiomyocytes are similar to skeletal muscle because:
D
How do arteries differ from veins?
A
Describe the cardiac cycle.
The heart receives an electrical signal from the sinoatrial node triggering the cardiac muscle cells in the atria to contract. The signal pauses at the atrioventricular node before spreading to the walls of the ventricles so the blood is pumped through the body. This is the systolic phase. The heart then relaxes in the diastole and fills again with blood.
What happens in capillaries?
The capillaries basically exchange materials with their surroundings. Their walls are very thin and are made of one or two layers of cells, where gases, nutrients, and waste are diffused. They are distributed as beds, complex networks that link arteries as well as veins.
Glossary
Chapter 40 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
Blood pressure (BP) is the pressure exerted by blood on the walls of a blood vessel that helps to push blood through the body. Systolic blood pressure measures the amount of pressure that blood exerts on vessels while the heart is beating. The optimal systolic blood pressure is 120 mmHg. Diastolic blood pressure measures the pressure in the vessels between heartbeats. The optimal diastolic blood pressure is 80 mmHg. Many factors can affect blood pressure, such as hormones, stress, exercise, eating, sitting, and standing. Blood flow through the body is regulated by the size of blood vessels, by the action of smooth muscle, by one-way valves, and by the fluid pressure of the blood itself.
Blood is pushed through the body by the action of the pumping heart. With each rhythmic pump, blood is pushed under high pressure and velocity away from the heart, initially along the main artery, the aorta. In the aorta, the blood travels at 30 cm/sec. As blood moves into the arteries, arterioles, and ultimately to the capillary beds, the rate of movement slows dramatically to about 0.026 cm/sec, one-thousand times slower than the rate of movement in the aorta. While the diameter of each individual arteriole and capillary is far narrower than the diameter of the aorta, and according to the law of continuity, fluid should travel faster through a narrower diameter tube, the rate is actually slower due to the overall diameter of all the combined capillaries being far greater than the diameter of the individual aorta.
The slow rate of travel through the capillary beds, which reach almost every cell in the body, assists with gas and nutrient exchange and also promotes the diffusion of fluid into the interstitial space. After the blood has passed through the capillary beds to the venules, veins, and finally to the main venae cavae, the rate of flow increases again but is still much slower than the initial rate in the aorta. Blood primarily moves in the veins by the rhythmic movement of smooth muscle in the vessel wall and by the action of the skeletal muscle as the body moves. Because most veins must move blood against the pull of gravity, blood is prevented from flowing backward in the veins by one-way valves. Because skeletal muscle contraction aids in venous blood flow, it is important to get up and move frequently after long periods of sitting so that blood will not pool in the extremities.
Blood flow through the capillary beds is regulated depending on the body’s needs and is directed by nerve and hormone signals. For example, after a large meal, most of the blood is diverted to the stomach by vasodilation of vessels of the digestive system and vasoconstriction of other vessels. During exercise, blood is diverted to the skeletal muscles through vasodilation while blood to the digestive system would be lessened through vasoconstriction. The blood entering some capillary beds is controlled by small muscles, called precapillary sphincters, illustrated in Figure 13.17. If the sphincters are open, the blood will flow into the associated branches of the capillary blood. If all of the sphincters are closed, then the blood will flow directly from the arteriole to the venule through the thoroughfare channel (see Figure 13.17). These muscles allow the body to precisely control when capillary beds receive blood flow. At any given moment only about 5–10% of our capillary beds actually have blood flowing through them.
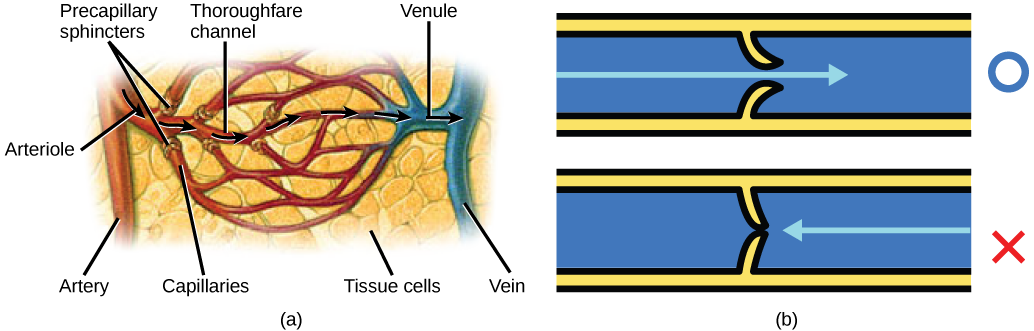
Varicose veins are veins that become enlarged because the valves no longer close properly, allowing blood to flow backward. Varicose veins are often most prominent on the legs. Why do you think this is the case?
Watch the video Circulation to learn about the circulatory system’s blood flow.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=635
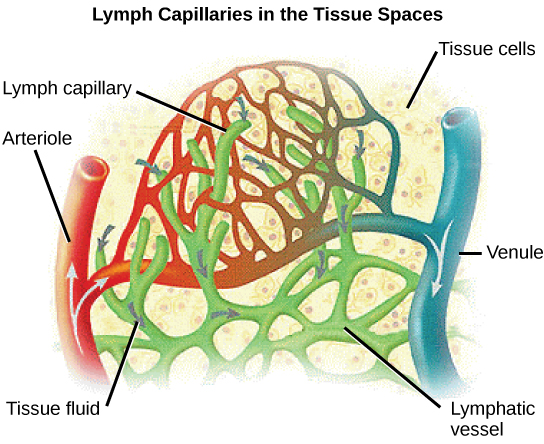
Blood circulation has evolved differently in vertebrates and may show variation in different animals for the required amount of pressure, organ and vessel location, and organ size. Animals with longs necks and those that live in cold environments have distinct blood pressure adaptations.
Long necked animals, such as giraffes, need to pump blood upward from the heart against gravity. The blood pressure required from the pumping of the left ventricle would be equivalent to 250 mm Hg (mm Hg = millimeters of mercury, a unit of pressure) to reach the height of a giraffe’s head, which is 2.5 meters higher than the heart. However, if checks and balances were not in place, this blood pressure would damage the giraffe’s brain, particularly if it was bending down to drink. These checks and balances include valves and feedback mechanisms that reduce the rate of cardiac output. Long-necked dinosaurs such as the sauropods had to pump blood even higher, up to ten meters above the heart. This would have required a blood pressure of more than 600 mm Hg, which could only have been achieved by an enormous heart. Evidence for such an enormous heart does not exist and mechanisms to reduce the blood pressure required include the slowing of metabolism as these animals grew larger. It is likely that they did not routinely feed on tree tops but grazed on the ground.
Living in cold water, whales need to maintain the temperature in their blood. This is achieved by the veins and arteries being close together so that heat exchange can occur. This mechanism is called a countercurrent heat exchanger. The blood vessels and the whole body are also protected by thick layers of blubber to prevent heat loss. In land animals that live in cold environments, thick fur and hibernation are used to retain heat and slow metabolism.
The pressure of the blood flow in the body is produced by the hydrostatic pressure of the fluid (blood) against the walls of the blood vessels. Fluid will move from areas of high to low hydrostatic pressures. In the arteries, the hydrostatic pressure near the heart is very high and blood flows to the arterioles where the rate of flow is slowed by the narrow openings of the arterioles. During systole, when new blood is entering the arteries, the artery walls stretch to accommodate the increase of pressure of the extra blood; during diastole, the walls return to normal because of their elastic properties. The blood pressure of the systole phase and the diastole phase, graphed in Figure 13.19, gives the two pressure readings for blood pressure. For example, 120/80 indicates a reading of 120 mm Hg during the systole and 80 mm Hg during diastole. Throughout the cardiac cycle, the blood continues to empty into the arterioles at a relatively even rate. This resistance to blood flow is called peripheral resistance.
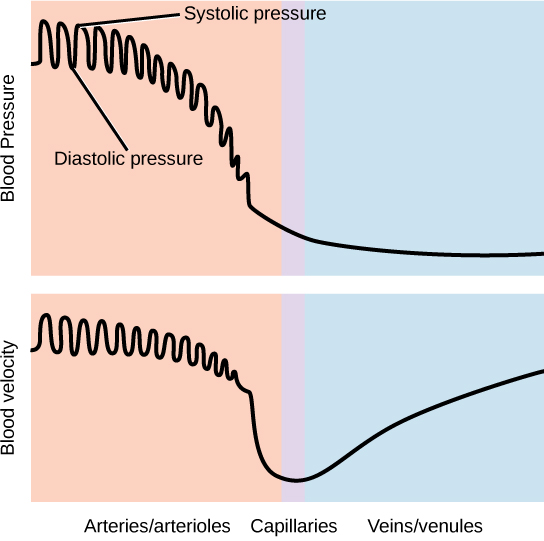
Cardiac output is the volume of blood pumped by the heart in one minute. It is calculated by multiplying the number of heart contractions that occur per minute (heart rate) times the stroke volume (the volume of blood pumped into the aorta per contraction of the left ventricle). Therefore, cardiac output can be increased by increasing heart rate, as when exercising. However, cardiac output can also be increased by increasing stroke volume, such as if the heart contracts with greater strength. Stroke volume can also be increased by speeding blood circulation through the body so that more blood enters the heart between contractions. During heavy exertion, the blood vessels relax and increase in diameter, offsetting the increased heart rate and ensuring adequate oxygenated blood gets to the muscles. Stress triggers a decrease in the diameter of the blood vessels, consequently increasing blood pressure. These changes can also be caused by nerve signals or hormones, and even standing up or lying down can have a great effect on blood pressure.
Blood primarily moves through the body by the rhythmic movement of smooth muscle in the vessel wall and by the action of the skeletal muscle as the body moves. Blood is prevented from flowing backward in the veins by one-way valves. Blood flow through the capillary beds is controlled by precapillary sphincters to increase and decrease flow depending on the body’s needs and is directed by nerve and hormone signals. Lymph vessels take fluid that has leaked out of the blood to the lymph nodes where it is cleaned before returning to the heart. During systole, blood enters the arteries, and the artery walls stretch to accommodate the extra blood. During diastole, the artery walls return to normal. The blood pressure of the systole phase and the diastole phase gives the two pressure readings for blood pressure.
Exercises
(Figure) Varicose veins are veins that become enlarged because the valves no longer close properly, allowing blood to flow backward. Varicose veins are often most prominent on the legs. Why do you think this is the case?
(Figure) Blood in the legs is farthest away from the heart and has to flow up to reach it.
High blood pressure would be a result of ________.
A
How does blood pressure change during heavy exercise?
The heart rate increases, which increases the hydrostatic pressure against the artery walls. At the same time, the arterioles dilate in response to the increased exercise, which reduces peripheral resistance.
Glossary
Chapter 40 in OpenStax Concepts of Biology 2e

Breathing is an involuntary event. How often a breath is taken and how much air is inhaled or exhaled are tightly regulated by the respiratory center in the brain. Humans, when they aren’t exerting themselves, breathe approximately 15 times per minute on average. Canines, like the dog in Figure 14.1, have a respiratory rate of about 15–30 breaths per minute. With every inhalation, air fills the lungs, and with every exhalation, air rushes back out. That air is doing more than just inflating and deflating the lungs in the chest cavity. The air contains oxygen that crosses the lung tissue, enters the bloodstream, and travels to organs and tissues. Oxygen (O2) enters the cells where it is used for metabolic reactions that produce ATP, a high-energy compound. At the same time, these reactions release carbon dioxide (CO2) as a by-product. CO2 is toxic and must be eliminated. Carbon dioxide exits the cells, enters the bloodstream, travels back to the lungs, and is expired out of the body during exhalation.
Chapter 39 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
The primary function of the respiratory system is to deliver oxygen to the cells of the body’s tissues and remove carbon dioxide, a cell waste product. The main structures of the human respiratory system are the nasal cavity, the trachea, and lungs.
All aerobic organisms require oxygen to carry out their metabolic functions. Along the evolutionary tree, different organisms have devised different means of obtaining oxygen from the surrounding atmosphere. The environment in which the animal lives greatly determines how an animal respires. The complexity of the respiratory system is correlated with the size of the organism. As animal size increases, diffusion distances increase and the ratio of surface area to volume drops. In unicellular organisms, diffusion across the cell membrane is sufficient for supplying oxygen to the cell (Figure 14.2). Diffusion is a slow, passive transport process. In order for diffusion to be a feasible means of providing oxygen to the cell, the rate of oxygen uptake must match the rate of diffusion across the membrane. In other words, if the cell were very large or thick, diffusion would not be able to provide oxygen quickly enough to the inside of the cell. Therefore, dependence on diffusion as a means of obtaining oxygen and removing carbon dioxide remains feasible only for small organisms or those with highly-flattened bodies, such as many flatworms (Platyhelminthes). Larger organisms had to evolve specialized respiratory tissues, such as gills, lungs, and respiratory passages accompanied by complex circulatory systems, to transport oxygen throughout their entire body.

For small multicellular organisms, diffusion across the outer membrane is sufficient to meet their oxygen needs. Gas exchange by direct diffusion across surface membranes is efficient for organisms less than 1 mm in diameter. In simple organisms, such as cnidarians and flatworms, every cell in the body is close to the external environment. Their cells are kept moist and gases diffuse quickly via direct diffusion. Flatworms are small, literally flat worms, which ‘breathe’ through diffusion across the outer membrane (Figure 14.3). The flat shape of these organisms increases the surface area for diffusion, ensuring that each cell within the body is close to the outer membrane surface and has access to oxygen. If the flatworm had a cylindrical body, then the cells in the center would not be able to get oxygen.

Earthworms and amphibians use their skin (integument) as a respiratory organ. A dense network of capillaries lies just below the skin and facilitates gas exchange between the external environment and the circulatory system. The respiratory surface must be kept moist in order for the gases to dissolve and diffuse across cell membranes.
Organisms that live in water need to obtain oxygen from the water. Oxygen dissolves in water but at a lower concentration than in the atmosphere. The atmosphere has roughly 21 percent oxygen. In water, the oxygen concentration is much lower than that. Fish and many other aquatic organisms have evolved gills to take up the dissolved oxygen from water (Figure 14.4). Gills are thin tissue filaments that are highly branched and folded. When water passes over the gills, the dissolved oxygen in water rapidly diffuses across the gills into the bloodstream. The circulatory system can then carry the oxygenated blood to the other parts of the body. In animals that contain coelomic fluid instead of blood, oxygen diffuses across the gill surfaces into the coelomic fluid. Gills are found in mollusks, annelids, and crustaceans.

The folded surfaces of the gills provide a large surface area to ensure that the fish gets sufficient oxygen. Diffusion is a process in which material travels from regions of high concentration to low concentration until equilibrium is reached. In this case, blood with a low concentration of oxygen molecules circulates through the gills. The concentration of oxygen molecules in water is higher than the concentration of oxygen molecules in gills. As a result, oxygen molecules diffuse from water (high concentration) to blood (low concentration), as shown in (Figure). Similarly, carbon dioxide molecules in the blood diffuse from the blood (high concentration) to water (low concentration).
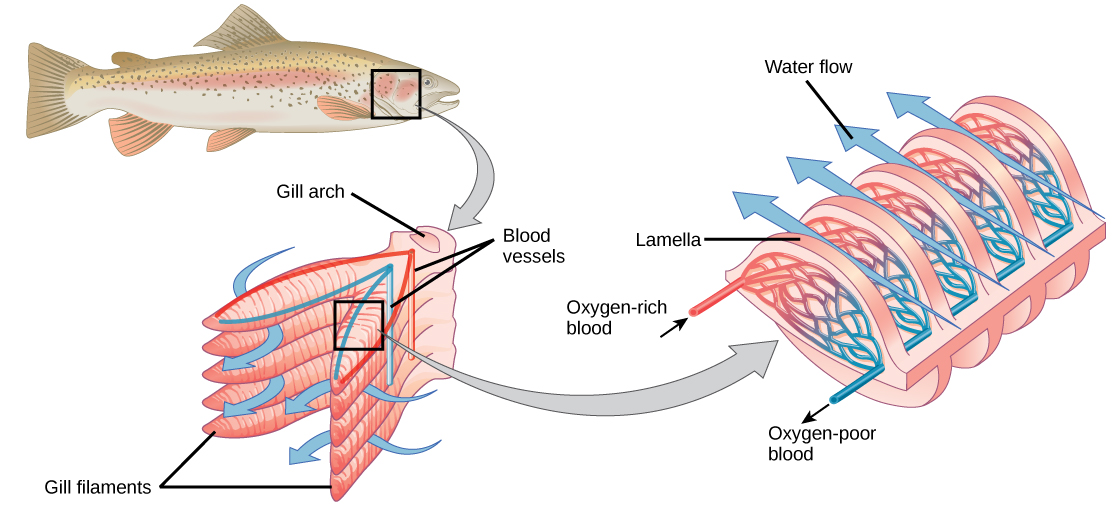
Insect respiration is independent of its circulatory system; therefore, the blood does not play a direct role in oxygen transport. Insects have a highly specialized type of respiratory system called the tracheal system, which consists of a network of small tubes that carries oxygen to the entire body. The tracheal system is the most direct and efficient respiratory system in active animals. The tubes in the tracheal system are made of a polymeric material called chitin.
Insect bodies have openings, called spiracles, along the thorax and abdomen. These openings connect to the tubular network, allowing oxygen to pass into the body (Figure 14.6) and regulating the diffusion of CO2 and water vapor. Air enters and leaves the tracheal system through the spiracles. Some insects can ventilate the tracheal system with body movements.
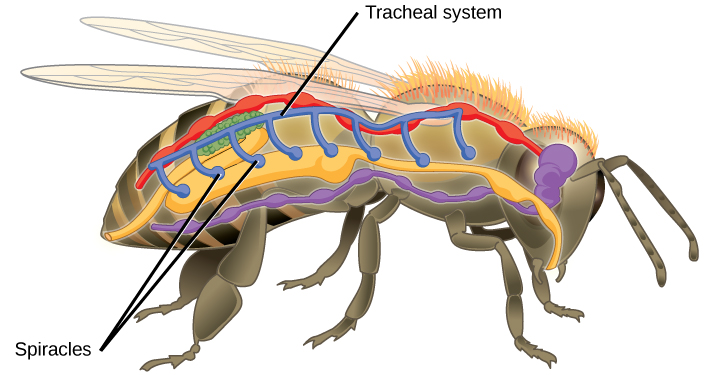
In mammals, pulmonary ventilation occurs via inhalation (breathing). During inhalation, air enters the body through the nasal cavity located just inside the nose (Figure 14.7). As air passes through the nasal cavity, the air is warmed to body temperature and humidified. The respiratory tract is coated with mucus to seal the tissues from direct contact with air. Mucus is high in water. As air crosses these surfaces of the mucous membranes, it picks up water. These processes help equilibrate the air to the body conditions, reducing any damage that cold, dry air can cause. Particulate matter that is floating in the air is removed in the nasal passages via mucus and cilia. The processes of warming, humidifying, and removing particles are important protective mechanisms that prevent damage to the trachea and lungs. Thus, inhalation serves several purposes in addition to bringing oxygen into the respiratory system.
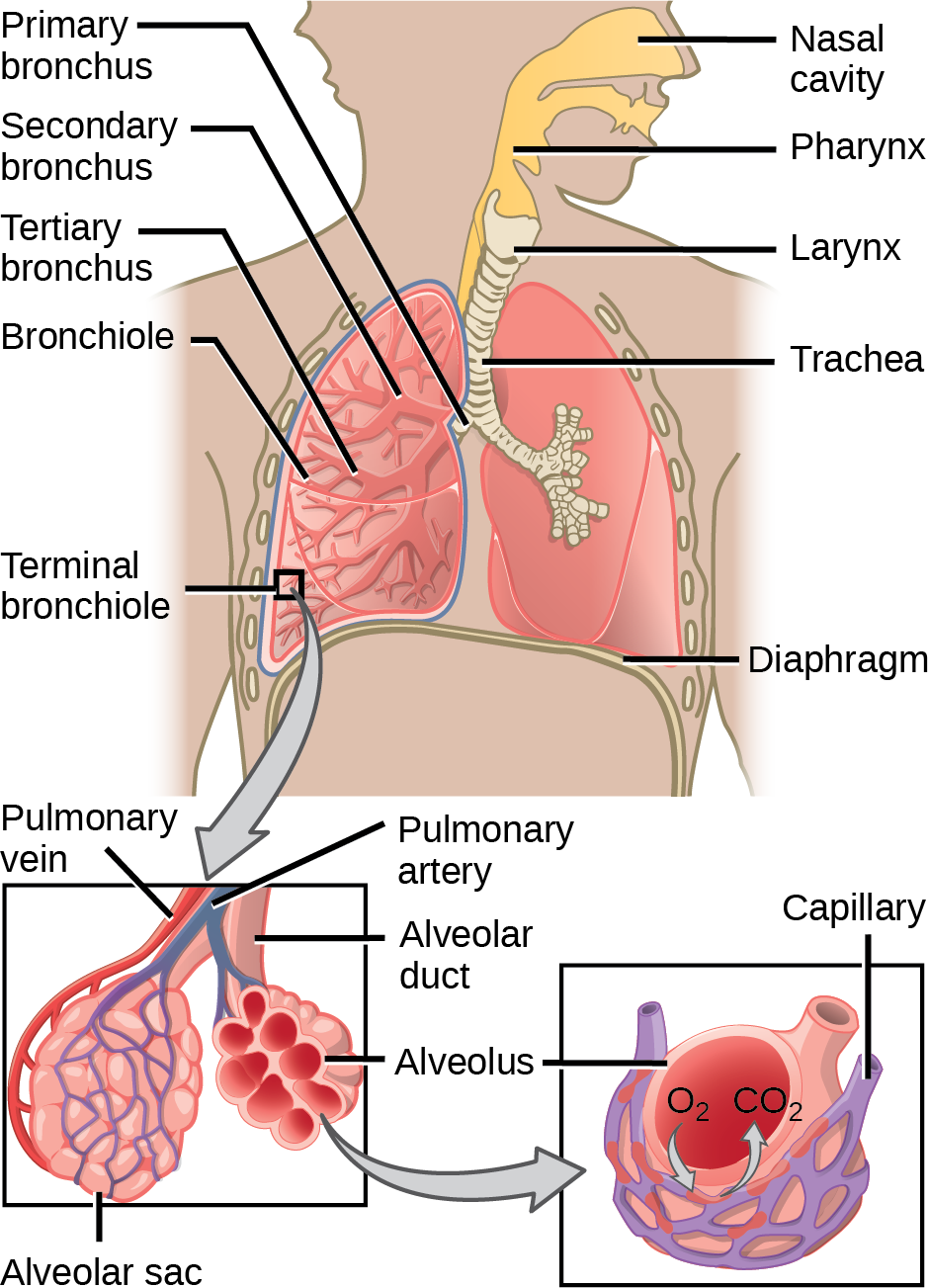
Which of the following statements about the mammalian respiratory system is false?
From the nasal cavity, air passes through the pharynx (throat) and the larynx (voice box), as it makes its way to the trachea (Figure 14.7). The main function of the trachea is to funnel the inhaled air to the lungs and the exhaled air back out of the body. The human trachea is a cylinder about 10 to 12 cm long and 2 cm in diameter that sits in front of the esophagus and extends from the larynx into the chest cavity where it divides into the two primary bronchi at the midthorax. It is made of incomplete rings of hyaline cartilage and smooth muscle (Figure 14.8). The trachea is lined with mucus-producing goblet cells and ciliated epithelia. The cilia propel foreign particles trapped in the mucus toward the pharynx. The cartilage provides strength and support to the trachea to keep the passage open. The smooth muscle can contract, decreasing the trachea’s diameter, which causes expired air to rush upwards from the lungs at a great force. The forced exhalation helps expel mucus when we cough. Smooth muscle can contract or relax, depending on stimuli from the external environment or the body’s nervous system.
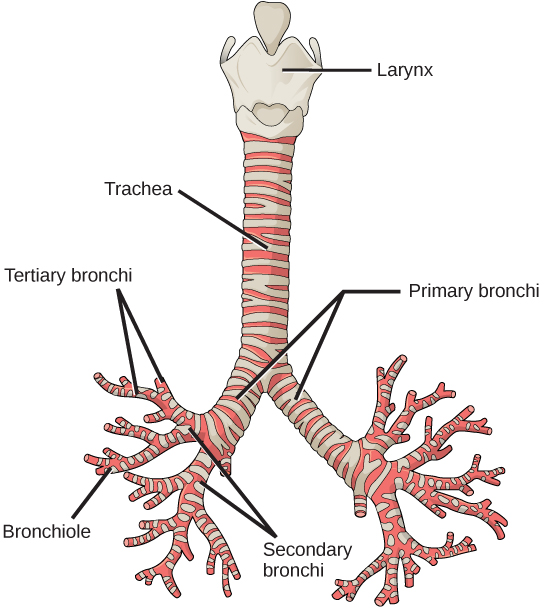
The end of the trachea bifurcates (divides) to the right and left lungs. The lungs are not identical. The right lung is larger and contains three lobes, whereas the smaller left lung contains two lobes (Figure 14.9). The muscular diaphragm, which facilitates breathing, is inferior to (below) the lungs and marks the end of the thoracic cavity.
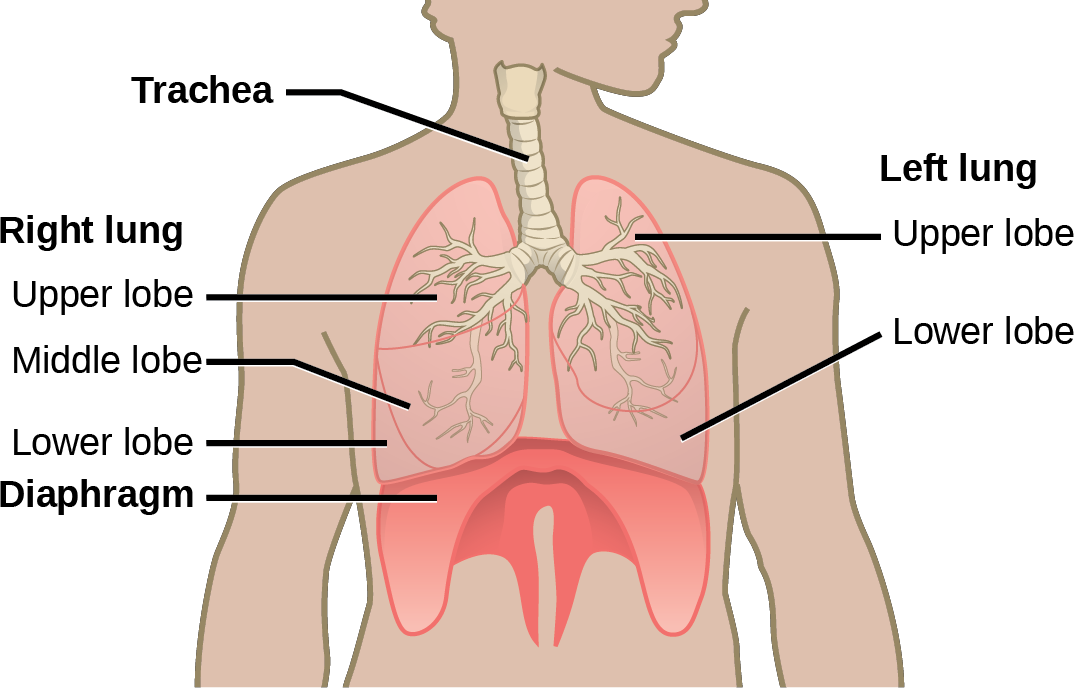
In the lungs, air is diverted into smaller and smaller passages, or bronchi. Air enters the lungs through the two primary (main) bronchi (singular: bronchus). Each bronchus divides into secondary bronchi, then into tertiary bronchi, which in turn divide, creating smaller and smaller diameter bronchioles as they split and spread through the lung. Like the trachea, the bronchi are made of cartilage and smooth muscle. At the bronchioles, the cartilage is replaced with elastic fibers. Bronchi are innervated by nerves of both the parasympathetic and sympathetic nervous systems that control muscle contraction (parasympathetic) or relaxation (sympathetic) in the bronchi and bronchioles, depending on the nervous system’s cues. In humans, bronchioles with a diameter smaller than 0.5 mm are the respiratory bronchioles. They lack cartilage and therefore rely on inhaled air to support their shape. As the passageways decrease in diameter, the relative amount of smooth muscle increases.
The terminal bronchioles subdivide into microscopic branches called respiratory bronchioles. The respiratory bronchioles subdivide into several alveolar ducts. Numerous alveoli and alveolar sacs surround the alveolar ducts. The alveolar sacs resemble bunches of grapes tethered to the end of the bronchioles ((Figure)). In the acinar region, the alveolar ducts are attached to the end of each bronchiole. At the end of each duct are approximately 100 alveolar sacs, each containing 20 to 30 alveoli that are 200 to 300 microns in diameter. Gas exchange occurs only in alveoli. Alveoli are made of thin-walled parenchymal cells, typically one-cell thick, that look like tiny bubbles within the sacs. Alveoli are in direct contact with capillaries (one-cell thick) of the circulatory system. Such intimate contact ensures that oxygen will diffuse from alveoli into the blood and be distributed to the cells of the body. In addition, the carbon dioxide that was produced by cells as a waste product will diffuse from the blood into alveoli to be exhaled. The anatomical arrangement of capillaries and alveoli emphasizes the structural and functional relationship of the respiratory and circulatory systems. Because there are so many alveoli (~300 million per lung) within each alveolar sac and so many sacs at the end of each alveolar duct, the lungs have a sponge-like consistency. This organization produces a very large surface area that is available for gas exchange. The surface area of alveoli in the lungs is approximately 75 m2. This large surface area, combined with the thin-walled nature of the alveolar parenchymal cells, allows gases to easily diffuse across the cells.
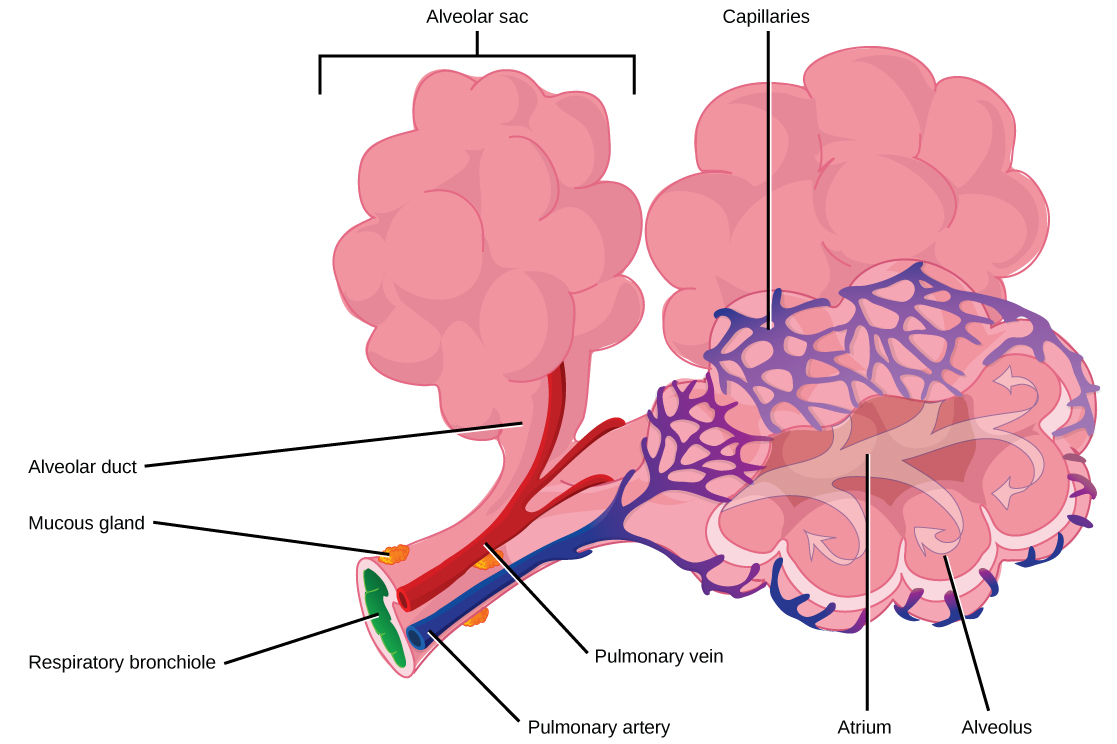
Watch the following video to review the respiratory system.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=588
The air that organisms breathe contains particulate matter such as dust, dirt, viral particles, and bacteria that can damage the lungs or trigger allergic immune responses. The respiratory system contains several protective mechanisms to avoid problems or tissue damage. In the nasal cavity, hairs and mucus trap small particles, viruses, bacteria, dust, and dirt to prevent their entry.
If particulates do make it beyond the nose, or enter through the mouth, the bronchi and bronchioles of the lungs also contain several protective devices. The lungs produce mucus—a sticky substance made of mucin, a complex glycoprotein, as well as salts and water—that traps particulates. The bronchi and bronchioles contain cilia, small hair-like projections that line the walls of the bronchi and bronchioles (Figure 14.11). These cilia beat in unison and move mucus and particles out of the bronchi and bronchioles back up to the throat where it is swallowed and eliminated via the esophagus.
In humans, for example, tar and other substances in cigarette smoke destroy or paralyze the cilia, making the removal of particles more difficult. In addition, smoking causes the lungs to produce more mucus, which the damaged cilia are not able to move. This causes a persistent cough, as the lungs try to rid themselves of particulate matter, and makes smokers more susceptible to respiratory ailments.

Animal respiratory systems are designed to facilitate gas exchange. In mammals, air is warmed and humidified in the nasal cavity. Air then travels down the pharynx, through the trachea, and into the lungs. In the lungs, air passes through the branching bronchi, reaching the respiratory bronchioles, which house the first site of gas exchange. The respiratory bronchioles open into the alveolar ducts, alveolar sacs, and alveoli. Because there are so many alveoli and alveolar sacs in the lung, the surface area for gas exchange is very large. Several protective mechanisms are in place to prevent damage or infection. These include the hair and mucus in the nasal cavity that trap dust, dirt, and other particulate matter before they can enter the system. In the lungs, particles are trapped in a mucus layer and transported via cilia up to the esophageal opening at the top of the trachea to be swallowed.
Exercises
Figure 14.7 Which of the following statements about the mammalian respiratory system is false?
The respiratory system ________.
Air is warmed and humidified in the nasal passages. This helps to ________.
Which is the order of airflow during inhalation?
Describe the function of these terms and describe where they are located: main bronchus, trachea, alveoli, and acinus.
The main bronchus is the conduit in the lung that funnels air to the airways where gas exchange occurs. The main bronchus attaches the lungs to the very end of the trachea where it bifurcates. The trachea is the cartilaginous structure that extends from the pharynx to the primary bronchi. It serves to funnel air to the lungs. The alveoli are the sites of gas exchange; they are located at the terminal regions of the lung and are attached to the respiratory bronchioles. The acinus is the structure in the lung where gas exchange occurs.
How does the structure of alveoli maximize gas exchange?
The sac-like structure of the alveoli increases their surface area. In addition, the alveoli are made of thin-walled parenchymal cells. These features allow gases to easily diffuse across the cells.
Glossary
Chapter 39 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
The structure of the lung maximizes its surface area to increase gas diffusion. Because of the enormous number of alveoli (approximately 300 million in each human lung), the surface area of the lung is very large (75 m2). Having such a large surface area increases the amount of gas that can diffuse into and out of the lungs.
Gas exchange during respiration occurs primarily through diffusion. Diffusion is a process in which transport is driven by a concentration gradient. Gas molecules move from a region of high concentration to a region of low concentration. Blood that is low in oxygen concentration and high in carbon dioxide concentration undergoes gas exchange with air in the lungs. The air in the lungs has a higher concentration of oxygen than that of oxygen-depleted blood and a lower concentration of carbon dioxide. This concentration gradient allows for gas exchange during respiration.
Partial pressure is a measure of the concentration of the individual components in a mixture of gases. The total pressure exerted by the mixture is the sum of the partial pressures of the components in the mixture. The rate of diffusion of a gas is proportional to its partial pressure within the total gas mixture. This concept is discussed further in detail below.
Different animals have different lung capacities based on their activities. Cheetahs have evolved a much higher lung capacity than humans; it helps provide oxygen to all the muscles in the body and allows them to run very fast. Elephants also have a high lung capacity. In this case, it is not because they run fast but because they have a large body and must be able to take up oxygen in accordance with their body size.
Human lung size is determined by genetics, sex, and height. At maximal capacity, an average lung can hold almost six liters of air, but lungs do not usually operate at maximal capacity. Air in the lungs is measured in terms of lung volumes and lung capacities (Figure 14.12) and (Figure 14.1). Volume measures the amount of air for one function (such as inhalation or exhalation). Capacity is any two or more volumes (for example, how much can be inhaled from the end of a maximal exhalation).
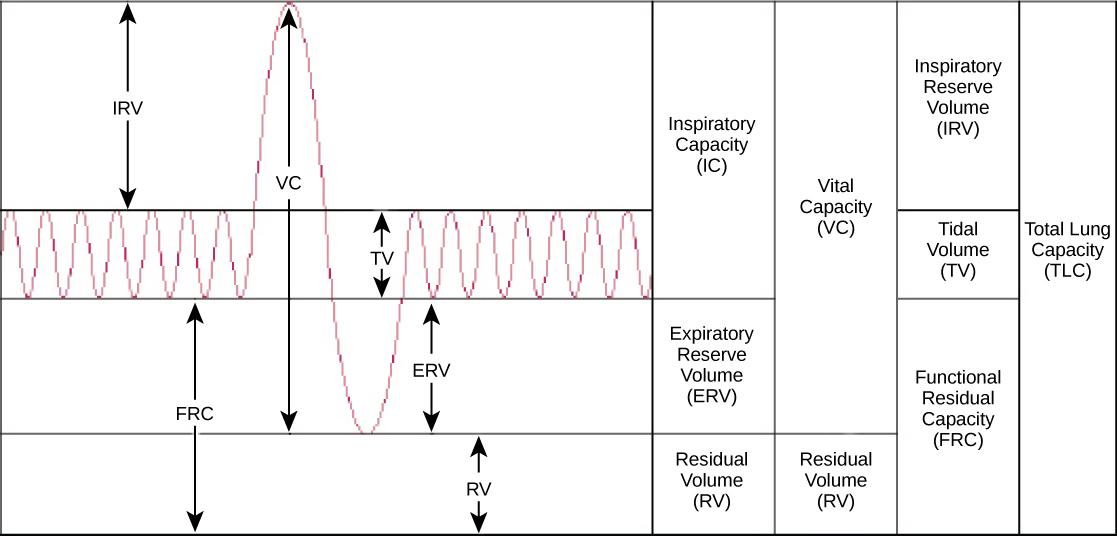
| Table 14.1 Lung Volumes and Capacities (Avg Adult Male) | |||
|---|---|---|---|
| Volume/Capacity | Definition | Volume (liters) | Equations |
| Tidal volume (TV) | Amount of air inhaled during a normal breath | 0.5 | – |
| Expiratory reserve volume (ERV) | Amount of air that can be exhaled after a normal exhalation | 1.2 | – |
| Inspiratory reserve volume (IRV) | Amount of air that can be further inhaled after a normal inhalation | 3.1 | – |
| Residual volume (RV) | Air left in the lungs after a forced exhalation | 1.2 | – |
| Vital capacity (VC) | Maximum amount of air that can be moved in or out of the lungs in a single respiratory cycle | 4.8 | ERV+TV+IRV |
| Inspiratory capacity (IC) | Volume of air that can be inhaled in addition to a normal exhalation | 3.6 | TV+IRV |
| Functional residual capacity (FRC) | Volume of air remaining after a normal exhalation | 2.4 | ERV+RV |
| Total lung capacity (TLC) | Total volume of air in the lungs after a maximal inspiration | 6.0 | RV+ERV+TV+IRV |
| Forced expiratory volume (FEV1) | How much air can be forced out of the lungs over a specific time period, usually one second | ~4.1 to 5.5 | – |
The volume in the lung can be divided into four units: tidal volume, expiratory reserve volume, inspiratory reserve volume, and residual volume. Tidal volume (TV) measures the amount of air that is inspired and expired during a normal breath. On average, this volume is around one-half liter, which is a little less than the capacity of a 20-ounce drink bottle. The expiratory reserve volume (ERV) is the additional amount of air that can be exhaled after a normal exhalation. It is the reserve amount that can be exhaled beyond what is normal. Conversely, the inspiratory reserve volume (IRV) is the additional amount of air that can be inhaled after a normal inhalation. The residual volume (RV) is the amount of air that is left after expiratory reserve volume is exhaled. The lungs are never completely empty: There is always some air left in the lungs after a maximal exhalation. If this residual volume did not exist and the lungs emptied completely, the lung tissues would stick together and the energy necessary to reinflate the lung could be too great to overcome. Therefore, there is always some air remaining in the lungs. Residual volume is also important for preventing large fluctuations in respiratory gases (O2 and CO2). The residual volume is the only lung volume that cannot be measured directly because it is impossible to completely empty the lung of air. This volume can only be calculated rather than measured.
Capacities are measurements of two or more volumes. The vital capacity (VC) measures the maximum amount of air that can be inhaled or exhaled during a respiratory cycle. It is the sum of the expiratory reserve volume, tidal volume, and inspiratory reserve volume. The inspiratory capacity (IC) is the amount of air that can be inhaled after the end of a normal expiration. It is, therefore, the sum of the tidal volume and inspiratory reserve volume. The functional residual capacity (FRC) includes the expiratory reserve volume and the residual volume. The FRC measures the amount of additional air that can be exhaled after a normal exhalation. Lastly, the total lung capacity (TLC) is a measurement of the total amount of air that the lung can hold. It is the sum of the residual volume, expiratory reserve volume, tidal volume, and inspiratory reserve volume.
Lung volumes are measured by a technique called spirometry. An important measurement taken during spirometry is the forced expiratory volume (FEV), which measures how much air can be forced out of the lung over a specific period, usually one second (FEV1). In addition, the forced vital capacity (FVC), which is the total amount of air that can be forcibly exhaled, is measured. The ratio of these values (FEV1/FVC ratio) is used to diagnose lung diseases including asthma, emphysema, and fibrosis. If the FEV1/FVC ratio is high, the lungs are not compliant (meaning they are stiff and unable to bend properly), and the patient most likely has lung fibrosis. Patients exhale most of the lung volume very quickly. Conversely, when the FEV1/FVC ratio is low, there is resistance in the lung that is characteristic of asthma. In this instance, it is hard for the patient to get the air out of his or her lungs, and it takes a long time to reach the maximal exhalation volume. In either case, breathing is difficult and complications arise.
Respiratory therapists or respiratory practitioners evaluate and treat patients with lung and cardiovascular diseases. They work as part of a medical team to develop treatment plans for patients. Respiratory therapists may treat premature babies with underdeveloped lungs, patients with chronic conditions such as asthma, or older patients suffering from lung disease such as emphysema and chronic obstructive pulmonary disease (COPD). They may operate advanced equipment such as compressed gas delivery systems, ventilators, blood gas analyzers, and resuscitators. Specialized programs to become a respiratory therapist generally lead to a bachelor’s degree with a respiratory therapist specialty. Because of a growing aging population, career opportunities as a respiratory therapist are expected to remain strong.
The respiratory process can be better understood by examining the properties of gases. Gases move freely, but gas particles are constantly hitting the walls of their vessel, thereby producing gas pressure.
Air is a mixture of gases, primarily nitrogen (N2; 78.6 percent), oxygen (O2; 20.9 percent), water vapor (H2O; 0.5 percent), and carbon dioxide (CO2; 0.04 percent). Each gas component of that mixture exerts a pressure. The pressure for an individual gas in the mixture is the partial pressure of that gas. Approximately 21 percent of atmospheric gas is oxygen. Carbon dioxide, however, is found in relatively small amounts, 0.04 percent. The partial pressure for oxygen is much greater than that of carbon dioxide. The partial pressure of any gas can be calculated by:

Patm, the atmospheric pressure, is the sum of all of the partial pressures of the atmospheric gases added together,

× (percent content in mixture).
The pressure of the atmosphere at sea level is 760 mm Hg. Therefore, the partial pressure of oxygen is:

and for carbon dioxide:

At high altitudes, Patm decreases but concentration does not change; the partial pressure decrease is due to the reduction in Patm.
When the air mixture reaches the lung, it has been humidified. The pressure of the water vapor in the lung does not change the pressure of the air, but it must be included in the partial pressure equation. For this calculation, the water pressure (47 mm Hg) is subtracted from the atmospheric pressure:

and the partial pressure of oxygen is:

These pressures determine the gas exchange, or the flow of gas, in the system. Oxygen and carbon dioxide will flow according to their pressure gradient from high to low. Therefore, understanding the partial pressure of each gas will aid in understanding how gases move in the respiratory system.
In the body, oxygen is used by cells of the body’s tissues and carbon dioxide is produced as a waste product. The ratio of carbon dioxide production to oxygen consumption is the respiratory quotient (RQ). RQ varies between 0.7 and 1.0. If just glucose were used to fuel the body, the RQ would equal one. One mole of carbon dioxide would be produced for every mole of oxygen consumed. Glucose, however, is not the only fuel for the body. Protein and fat are also used as fuels for the body. Because of this, less carbon dioxide is produced than oxygen is consumed and the RQ is, on average, about 0.7 for fat and about 0.8 for protein.
The RQ is used to calculate the partial pressure of oxygen in the alveolar spaces within the lung, the alveolar 
. Above, the partial pressure of oxygen in the lungs was calculated to be 150 mm Hg. However, lungs never fully deflate with an exhalation; therefore, the inspired air mixes with this residual air and lowers the partial pressure of oxygen within the alveoli. This means that there is a lower concentration of oxygen in the lungs than is found in the air outside the body. Knowing the RQ, the partial pressure of oxygen in the alveoli can be calculated:

With an RQ of 0.8 and a 
in the alveoli of 40 mm Hg, the alveolar
is equal to:

Notice that this pressure is less than the external air. Therefore, the oxygen will flow from the inspired air in the lung ( = 150 mm Hg) into the bloodstream ( = 100 mm Hg)
In the lungs, oxygen diffuses out of the alveoli and into the capillaries surrounding the alveoli. Oxygen (about 98 percent) binds reversibly to the respiratory pigment hemoglobin found in red blood cells (RBCs). RBCs carry oxygen to the tissues where oxygen dissociates from the hemoglobin and diffuses into the cells of the tissues. More specifically, alveolar
is higher in the alveoli ( = 100 mm Hg)
= 100 mm Hg)
than blood (40 mm Hg) in the capillaries. Because this pressure gradient exists, oxygen diffuses down its pressure gradient, moving out of the alveoli and entering the blood of the capillaries where O2 binds to hemoglobin. At the same time, alveolar
is lower = 40 mm Hg
than blood = (45 mm Hg). CO2 diffuses down its pressure gradient, moving out of the capillaries and entering the alveoli.
Oxygen and carbon dioxide move independently of each other; they diffuse down their own pressure gradients. As blood leaves the lungs through the pulmonary veins, the venous = 100 mm Hg, whereas the venous = 40 mm Hg. As blood enters the systemic capillaries, the blood will lose oxygen and gain carbon dioxide because of the pressure difference of the tissues and blood. In systemic capillaries, = 100 mm Hg, but in the tissue cells, = 40 mm Hg. This pressure gradient drives the diffusion of oxygen out of the capillaries and into the tissue cells. At the same time, blood = 40 mm Hg and systemic tissue = 45 mm Hg. The pressure gradient drives CO2 out of tissue cells and into the capillaries. The blood returning to the lungs through the pulmonary arteries has a venous = 40 mm Hg and a = 45 mm Hg. The blood enters the lung capillaries where the process of exchanging gases between the capillaries and alveoli begins again ((Figure)).
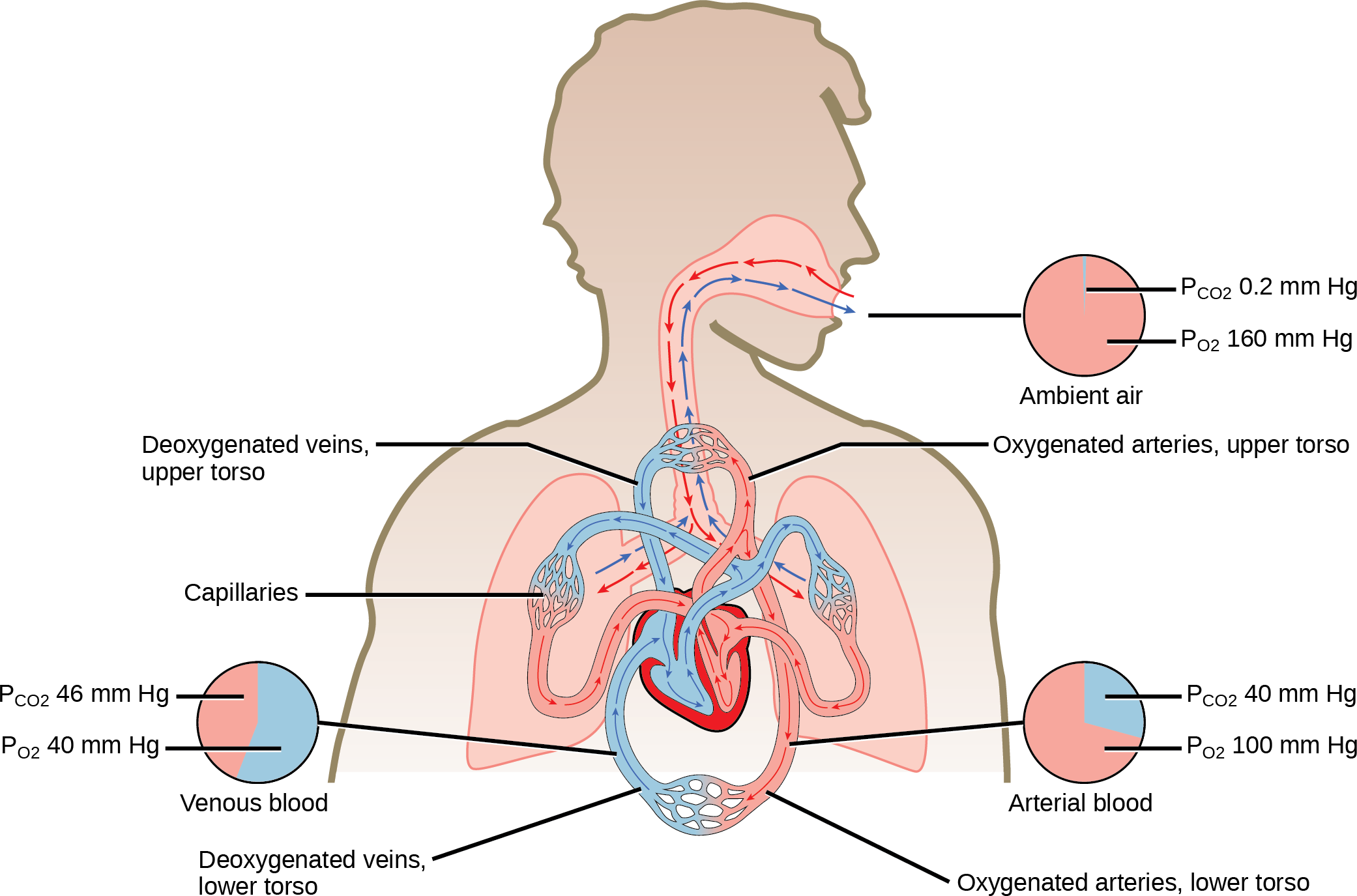
Which of the following statements is false?
drops as blood passes from the arteries to the veins, while increases. is higher in air than in the lungs.In short, the change in partial pressure from the alveoli to the capillaries drives the oxygen into the tissues and the carbon dioxide into the blood from the tissues. The blood is then transported to the lungs where differences in pressure in the alveoli result in the movement of carbon dioxide out of the blood into the lungs, and oxygen into the blood.
Watch this video to learn how to carry out spirometry.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=592
The lungs can hold a large volume of air, but they are not usually filled to maximal capacity. Lung volume measurements include tidal volume, expiratory reserve volume, inspiratory reserve volume, and residual volume. The sum of these equals the total lung capacity. Gas movement into or out of the lungs is dependent on the pressure of the gas. Air is a mixture of gases; therefore, the partial pressure of each gas can be calculated to determine how the gas will flow in the lung. The difference between the partial pressure of the gas in the air drives oxygen into the tissues and carbon dioxide out of the body.
Exercises
Visual Connection Questions
Figure 14.13: Which of the following statements is false?
drops as blood passes from the arteries to the veins, while increases. is higher in air than in the lungs.Review Questions
The inspiratory reserve volume measures the ________.
Of the following, which does not explain why the partial pressure of oxygen is lower in the lung than in the external air?
The total lung capacity is calculated using which of the following formulas?
Critical Thinking Questions
How can a decrease in the percent of oxygen in the air affect the movement of oxygen in the body?
If a patient has increased resistance in his or her lungs, how can this be detected by a doctor? What does this mean?
Glossary
Chapter 39 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
Mammalian lungs are located in the thoracic cavity where they are surrounded and protected by the rib cage, intercostal muscles, and bound by the chest wall. The bottom of the lungs is contained by the diaphragm, a skeletal muscle that facilitates breathing. Breathing requires the coordination of the lungs, the chest wall, and most importantly, the diaphragm.
Amphibians have evolved multiple ways of breathing. Young amphibians, like tadpoles, use gills to breathe, and they don’t leave the water. Some amphibians retain gills for life. As the tadpole grows, the gills disappear and lungs grow. These lungs are primitive and not as evolved as mammalian lungs. Adult amphibians are lacking or have a reduced diaphragm, so breathing via lungs is forced. The other means of breathing for amphibians is diffusion across the skin. To aid this diffusion, amphibian skin must remain moist.
Birds face a unique challenge with respect to breathing: They fly. Flying consumes a great amount of energy; therefore, birds require a lot of oxygen to aid their metabolic processes. Birds have evolved a respiratory system that supplies them with the oxygen needed to enable flying. Similar to mammals, birds have lungs, which are organs specialized for gas exchange. Oxygenated air, taken in during inhalation, diffuses across the surface of the lungs into the bloodstream, and carbon dioxide diffuses from the blood into the lungs and expelled during exhalation. The details of breathing between birds and mammals differ substantially.
In addition to lungs, birds have air sacs inside their body. Air flows in one direction from the posterior air sacs to the lungs and out of the anterior air sacs. The flow of air is in the opposite direction from blood flow, and gas exchange takes place much more efficiently. This type of breathing enables birds to obtain the requisite oxygen, even at higher altitudes where the oxygen concentration is low. This directionality of airflow requires two cycles of air intake and exhalation to completely get the air out of the lungs.
Birds have evolved a respiratory system that enables them to fly. Flying is a high-energy process and requires a lot of oxygen. Furthermore, many birds fly in high altitudes where the concentration of oxygen is low. How did birds evolve a respiratory system that is so unique?
Decades of research by paleontologists have shown that birds evolved from therapods, meat-eating dinosaurs ((Figure 14.14). In fact, fossil evidence shows that meat-eating dinosaurs that lived more than 100 million years ago had a similar flow-through respiratory system with lungs and air sacs. Archaeopteryx and Xiaotingia, for example, were flying dinosaurs and are believed to be early precursors of birds.
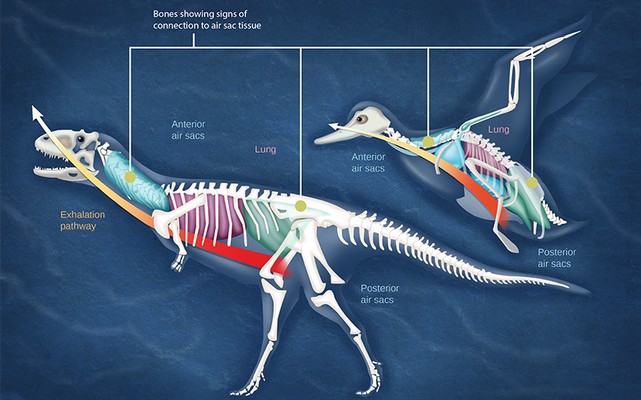
Most of us consider that dinosaurs are extinct. However, modern birds are descendants of avian dinosaurs. The respiratory system of modern birds has been evolving for hundreds of millions of years.
All mammals have lungs that are the main organs for breathing. Lung capacity has evolved to support the animal’s activities. During inhalation, the lungs expand with air, and oxygen diffuses across the lung’s surface and enters the bloodstream. During exhalation, the lungs expel air and lung volume decreases. In the next few sections, the process of human breathing will be explained.
Boyle’s Law is the gas law that states that in a closed space, pressure and volume are inversely related. As volume decreases, pressure increases and vice versa (Figure 14.15). The relationship between gas pressure and volume helps to explain the mechanics of breathing.
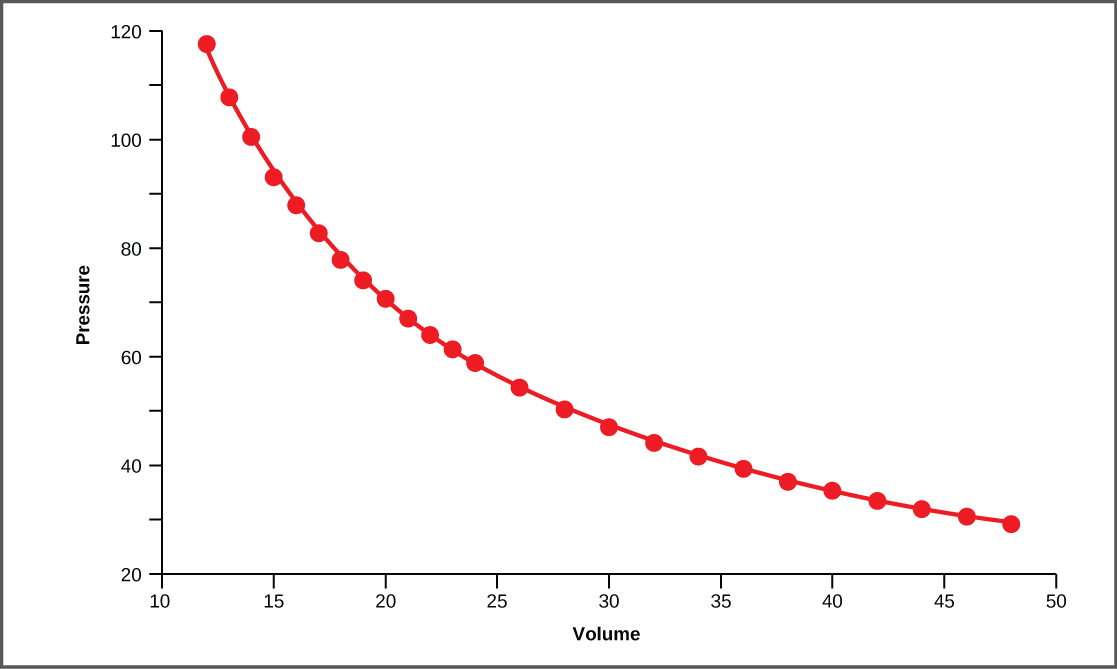
There is always a slightly negative pressure within the thoracic cavity, which aids in keeping the airways of the lungs open. During inhalation, volume increases as a result of contraction of the diaphragm, and pressure decreases (according to Boyle’s Law). This decrease of pressure in the thoracic cavity relative to the environment makes the cavity less than the atmosphere (Figure 14.16a). Because of this drop in pressure, air rushes into the respiratory passages. To increase the volume of the lungs, the chest wall expands. This results from the contraction of the intercostal muscles, the muscles that are connected to the rib cage. Lung volume expands because the diaphragm contracts and the intercostal muscles contract, thus expanding the thoracic cavity. This increase in the volume of the thoracic cavity lowers pressure compared to the atmosphere, so air rushes into the lungs, thus increasing its volume. The resulting increase in volume is largely attributed to an increase in alveolar space, because the bronchioles and bronchi are stiff structures that do not change in size.
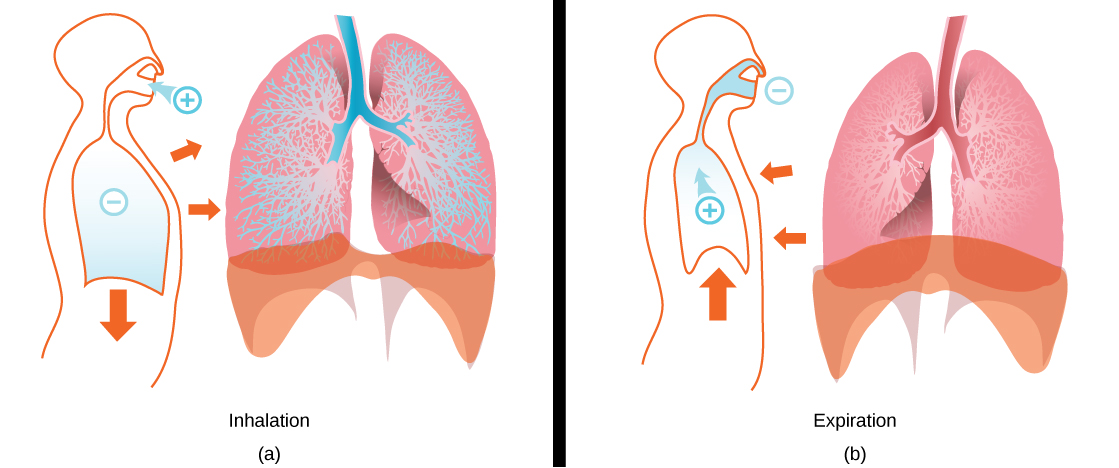
The chest wall expands out and away from the lungs. The lungs are elastic; therefore, when air fills the lungs, the elastic recoil within the tissues of the lung exerts pressure back toward the interior of the lungs. These outward and inward forces compete to inflate and deflate the lung with every breath. Upon exhalation, the lungs recoil to force the air out of the lungs, and the intercostal muscles relax, returning the chest wall back to its original position (Figure 14.16b). The diaphragm also relaxes and moves higher into the thoracic cavity. This increases the pressure within the thoracic cavity relative to the environment, and air rushes out of the lungs. The movement of air out of the lungs is a passive event. No muscles are contracting to expel the air.
Each lung is surrounded by an invaginated sac. The layer of tissue that covers the lung and dips into spaces is called the visceral pleura. A second layer of parietal pleura lines the interior of the thorax (Figure 14.17). The space between these layers, the intrapleural space, contains a small amount of fluid that protects the tissue and reduces the friction generated from rubbing the tissue layers together as the lungs contract and relax. Pleurisy results when these layers of tissue become inflamed; it is painful because the inflammation increases the pressure within the thoracic cavity and reduces the volume of the lung.
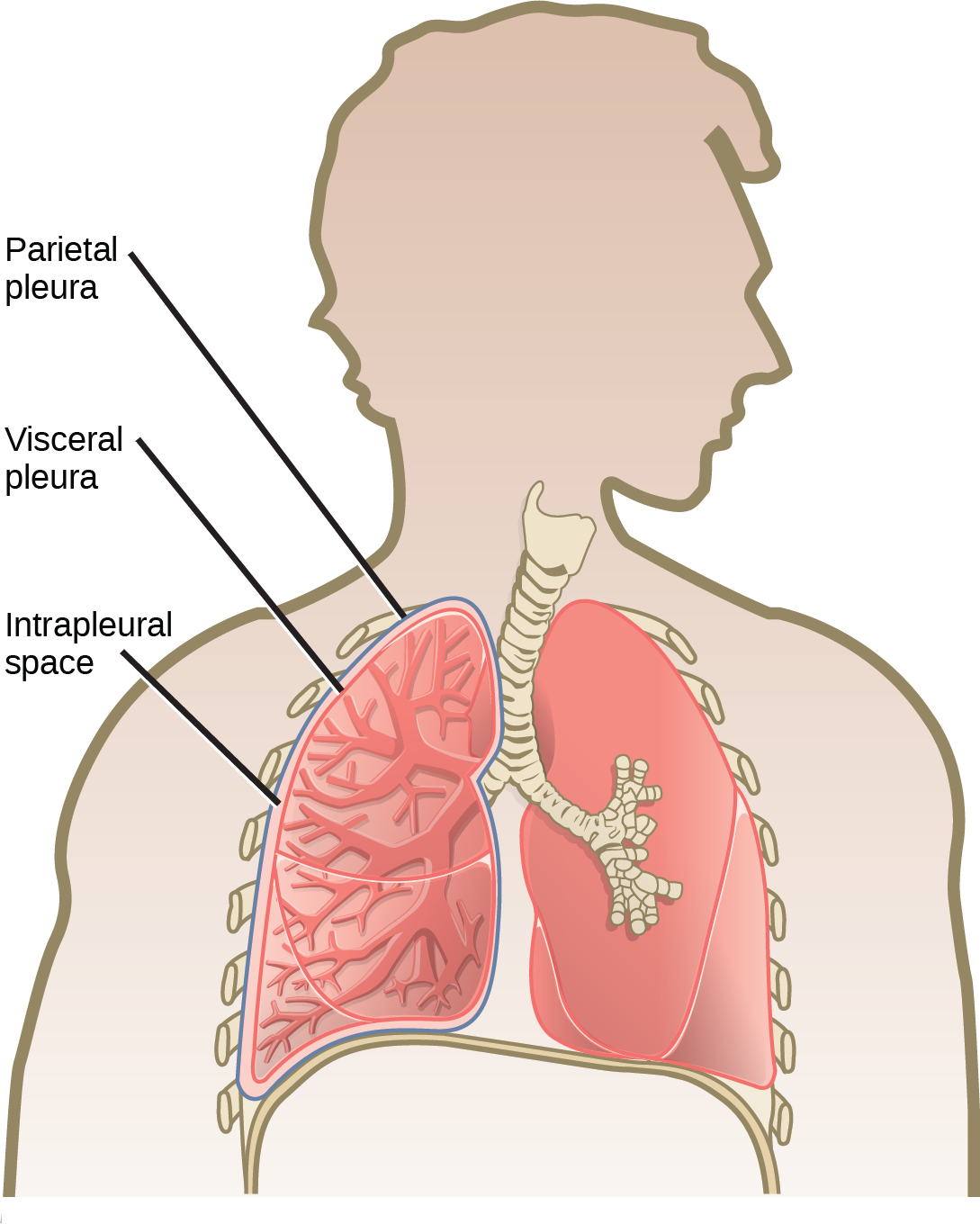
View how Boyle’s Law is related to breathing. Watch the video on Boyle’s Law.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=598
The number of breaths per minute is the respiratory rate. On average, under non-exertion conditions, the human respiratory rate is 12–15 breaths/minute. The respiratory rate contributes to the alveolar ventilation, or how much air moves into and out of the alveoli. Alveolar ventilation prevents carbon dioxide buildup in the alveoli. There are two ways to keep the alveolar ventilation constant: increase the respiratory rate while decreasing the tidal volume of air per breath (shallow breathing), or decrease the respiratory rate while increasing the tidal volume per breath. In either case, the ventilation remains the same, but the work done and type of work needed are quite different. Both tidal volume and respiratory rate are closely regulated when oxygen demand increases.
There are two types of work conducted during respiration, flow-resistive and elastic work. Flow-resistive refers to the work of the alveoli and tissues in the lung, whereas elastic work refers to the work of the intercostal muscles, chest wall, and diaphragm. Increasing the respiration rate increases the flow-resistive work of the airways and decreases the elastic work of the muscles. Decreasing the respiratory rate reverses the type of work required.
The air-tissue/water interface of the alveoli has a high surface tension. This surface tension is similar to the surface tension of water at the liquid-air interface of a water droplet that results in the bonding of the water molecules together. Surfactant is a complex mixture of phospholipids and lipoproteins that works to reduce the surface tension that exists between the alveoli tissue and the air found within the alveoli. By lowering the surface tension of the alveolar fluid, it reduces the tendency of alveoli to collapse.
Surfactant works like a detergent to reduce the surface tension and allows for easier inflation of the airways. When a balloon is first inflated, it takes a large amount of effort to stretch the plastic and start to inflate the balloon. If a little bit of detergent was applied to the interior of the balloon, then the amount of effort or work needed to begin to inflate the balloon would decrease, and it would become much easier to start blowing up the balloon. This same principle applies to the airways. A small amount of surfactant to the airway tissues reduces the effort or work needed to inflate those airways. Babies born prematurely sometimes do not produce enough surfactant. As a result, they suffer from respiratory distress syndrome, because it requires more effort to inflate their lungs. Surfactant is also important for preventing collapse of small alveoli relative to large alveoli.
Pulmonary diseases reduce the rate of gas exchange into and out of the lungs. Two main causes of decreased gas exchange are compliance (how elastic the lung is) and resistance (how much obstruction exists in the airways). A change in either can dramatically alter breathing and the ability to take in oxygen and release carbon dioxide.
Examples of restrictive diseases are respiratory distress syndrome and pulmonary fibrosis. In both diseases, the airways are less compliant and they are stiff or fibrotic. There is a decrease in compliance because the lung tissue cannot bend and move. In these types of restrictive diseases, the intrapleural pressure is more positive and the airways collapse upon exhalation, which traps air in the lungs. Forced or functional vital capacity (FVC), which is the amount of air that can be forcibly exhaled after taking the deepest breath possible, is much lower than in normal patients, and the time it takes to exhale most of the air is greatly prolonged (Figure 14.18). A patient suffering from these diseases cannot exhale the normal amount of air.
Obstructive diseases and conditions include emphysema, asthma, and pulmonary edema. In emphysema, which mostly arises from smoking tobacco, the walls of the alveoli are destroyed, decreasing the surface area for gas exchange. The overall compliance of the lungs is increased, because as the alveolar walls are damaged, lung elastic recoil decreases due to a loss of elastic fibers, and more air is trapped in the lungs at the end of exhalation. Asthma is a disease in which inflammation is triggered by environmental factors. Inflammation obstructs the airways. The obstruction may be due to edema (fluid accumulation), smooth muscle spasms in the walls of the bronchioles, increased mucus secretion, damage to the epithelia of the airways, or a combination of these events. Those with asthma or edema experience increased occlusion from increased inflammation of the airways. This tends to block the airways, preventing the proper movement of gases (Figure 14.18). Those with obstructive diseases have large volumes of air trapped after exhalation and breathe at a very high lung volume to compensate for the lack of airway recruitment.
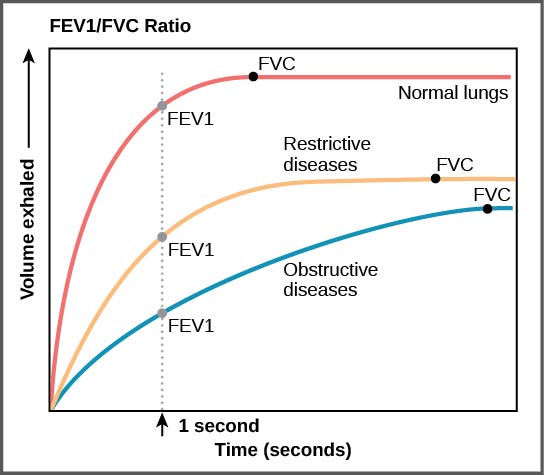
Pulmonary circulation pressure is very low compared to that of the systemic circulation. It is also independent of cardiac output. This is because of a phenomenon called recruitment, which is the process of opening airways that normally remain closed when cardiac output increases. As cardiac output increases, the number of capillaries and arteries that are perfused (filled with blood) increases. These capillaries and arteries are not always in use but are ready if needed. At times, however, there is a mismatch between the amount of air (ventilation, V) and the amount of blood (perfusion, Q) in the lungs. This is referred to as ventilation/perfusion (V/Q) mismatch.
There are two types of V/Q mismatch. Both produce dead space, regions of broken down or blocked lung tissue. Dead spaces can severely impact breathing, because they reduce the surface area available for gas diffusion. As a result, the amount of oxygen in the blood decreases, whereas the carbon dioxide level increases. Dead space is created when no ventilation and/or perfusion takes place. Anatomical dead space or anatomical shunt, arises from an anatomical failure, while physiological dead space or physiological shunt, arises from a functional impairment of the lung or arteries.
An example of an anatomical shunt is the effect of gravity on the lungs. The lung is particularly susceptible to changes in the magnitude and direction of gravitational forces. When someone is standing or sitting upright, the pleural pressure gradient leads to increased ventilation further down in the lung. As a result, the intrapleural pressure is more negative at the base of the lung than at the top, and more air fills the bottom of the lung than the top. Likewise, it takes less energy to pump blood to the bottom of the lung than to the top when in a prone position. Perfusion of the lung is not uniform while standing or sitting. This is a result of hydrostatic forces combined with the effect of airway pressure. An anatomical shunt develops because the ventilation of the airways does not match the perfusion of the arteries surrounding those airways. As a result, the rate of gas exchange is reduced. Note that this does not occur when lying down, because in this position, gravity does not preferentially pull the bottom of the lung down.
A physiological shunt can develop if there is infection or edema in the lung that obstructs an area. This will decrease ventilation but not affect perfusion; therefore, the V/Q ratio changes and gas exchange is affected.
The lung can compensate for these mismatches in ventilation and perfusion. If ventilation is greater than perfusion, the arterioles dilate and the bronchioles constrict. This increases perfusion and reduces ventilation. Likewise, if ventilation is less than perfusion, the arterioles constrict and the bronchioles dilate to correct the imbalance.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=598
The structure of the lungs and thoracic cavity control the mechanics of breathing. Upon inspiration, the diaphragm contracts and lowers. The intercostal muscles contract and expand the chest wall outward. The intrapleural pressure drops, the lungs expand, and air is drawn into the airways. When exhaling, the intercostal muscles and diaphragm relax, returning the intrapleural pressure back to the resting state. The lungs recoil and airways close. The air passively exits the lung. There is high surface tension at the air-airway interface in the lung. Surfactant, a mixture of phospholipids and lipoproteins, acts like a detergent in the airways to reduce surface tension and allow for opening of the alveoli.
Breathing and gas exchange are both altered by changes in the compliance and resistance of the lung. If the compliance of the lung decreases, as occurs in restrictive diseases like fibrosis, the airways stiffen and collapse upon exhalation. Air becomes trapped in the lungs, making breathing more difficult. If resistance increases, as happens with asthma or emphysema, the airways become obstructed, trapping air in the lungs and causing breathing to become difficult. Alterations in the ventilation of the airways or perfusion of the arteries can affect gas exchange. These changes in ventilation and perfusion, called V/Q mismatch, can arise from anatomical or physiological changes.
Exercises
Review Questions
How would paralysis of the diaphragm alter inspiration?
Restrictive airway diseases ________.
Alveolar ventilation remains constant when ________.
Critical Thinking Questions
Glossary
Chapter 39 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
Once the oxygen diffuses across the alveoli, it enters the bloodstream and is transported to the tissues where it is unloaded, and carbon dioxide diffuses out of the blood and into the alveoli to be expelled from the body. Although gas exchange is a continuous process, the oxygen and carbon dioxide are transported by different mechanisms.
Although oxygen dissolves in blood, only a small amount of oxygen is transported this way. Only 1.5 percent of oxygen in the blood is dissolved directly into the blood itself. Most oxygen—98.5 percent—is bound to a protein called hemoglobin and carried to the tissues.
Hemoglobin, or Hb, is a protein molecule found in red blood cells (erythrocytes) made of four subunits: two alpha subunits and two beta subunits (Figure 14.19). Each subunit surrounds a central heme group that contains iron and binds one oxygen molecule, allowing each hemoglobin molecule to bind four oxygen molecules. Molecules with more oxygen bound to the heme groups are brighter red. As a result, oxygenated arterial blood where the Hb is carrying four oxygen molecules is bright red, while venous blood that is deoxygenated is darker red.
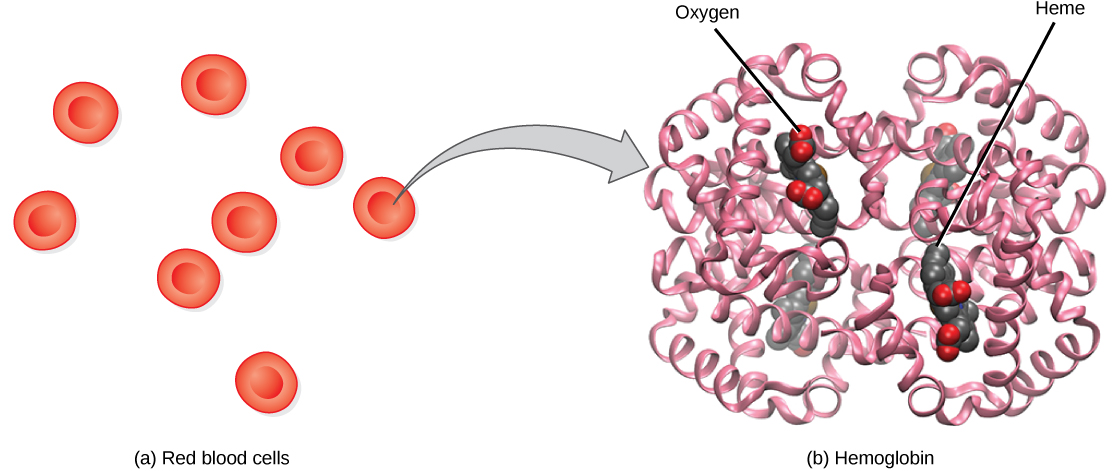
It is easier to bind a second and third oxygen molecule to Hb than the first molecule. This is because the hemoglobin molecule changes its shape, or conformation, as oxygen binds. The fourth oxygen is then more difficult to bind. The binding of oxygen to hemoglobin can be plotted as a function of the partial pressure of oxygen in the blood (x-axis) versus the relative Hb-oxygen saturation (y-axis). The resulting graph—an oxygen dissociation curve—is sigmoidal, or S-shaped (Figure 14.20). As the partial pressure of oxygen increases, the hemoglobin becomes increasingly saturated with oxygen.
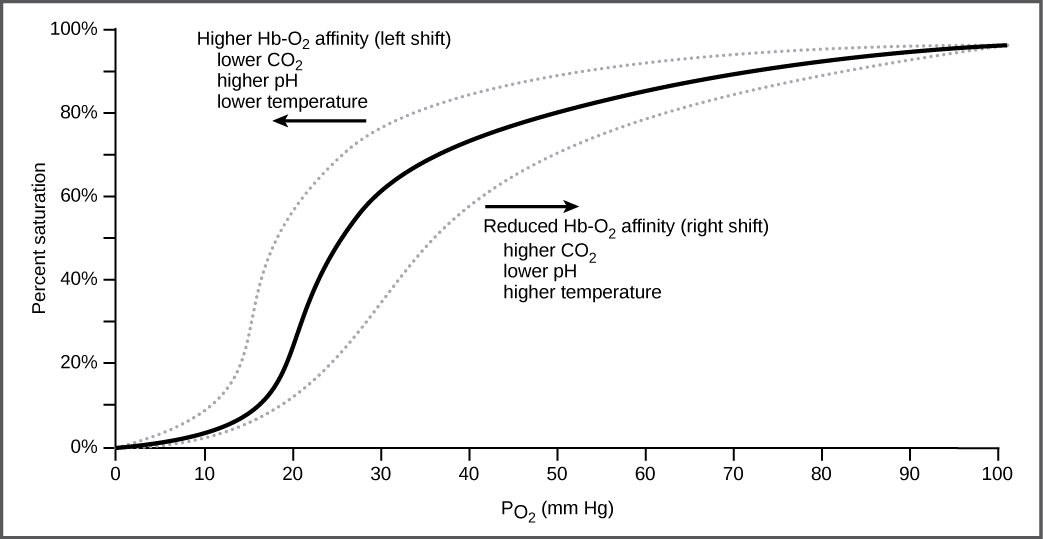
The kidneys are responsible for removing excess H+ ions from the blood. If the kidneys fail, what would happen to blood pH and to hemoglobin affinity for oxygen?
The oxygen-carrying capacity of hemoglobin determines how much oxygen is carried in the blood. In addition to , other environmental factors and diseases can affect oxygen carrying capacity and delivery.
Carbon dioxide levels, blood pH, and body temperature affect oxygen-carrying capacity (Figure 14.20). When carbon dioxide is in the blood, it reacts with water to form bicarbonate 
and hydrogen ions (H+). As the level of carbon dioxide in the blood increases, more H+ is produced and the pH decreases. This increase in carbon dioxide and subsequent decrease in pH reduce the affinity of hemoglobin for oxygen. The oxygen dissociates from the Hb molecule, shifting the oxygen dissociation curve to the right. Therefore, more oxygen is needed to reach the same hemoglobin saturation level as when the pH was higher. A similar shift in the curve also results from an increase in body temperature. Increased temperature, such as from increased activity of skeletal muscle, causes the affinity of hemoglobin for oxygen to be reduced.
Diseases like sickle cell anemia and thalassemia decrease the blood’s ability to deliver oxygen to tissues and its oxygen-carrying capacity. In sickle cell anemia, the shape of the red blood cell is crescent-shaped, elongated, and stiffened, reducing its ability to deliver oxygen (Figure 14.21). In this form, red blood cells cannot pass through the capillaries. This is painful when it occurs. Thalassemia is a rare genetic disease caused by a defect in either the alpha or the beta subunit of Hb. Patients with thalassemia produce a high number of red blood cells, but these cells have lower-than-normal levels of hemoglobin. Therefore, the oxygen-carrying capacity is diminished.
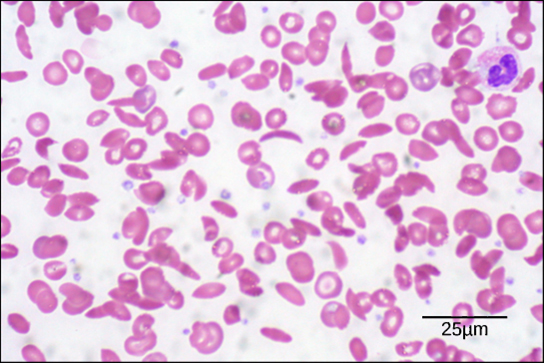
Carbon dioxide molecules are transported in the blood from body tissues to the lungs by one of three methods: dissolution directly into the blood, binding to hemoglobin, or carried as a bicarbonate ion. Several properties of carbon dioxide in the blood affect its transport. First, carbon dioxide is more soluble in blood than oxygen. About 5 to 7 percent of all carbon dioxide is dissolved in the plasma. Second, carbon dioxide can bind to plasma proteins or can enter red blood cells and bind to hemoglobin. This form transports about 10 percent of the carbon dioxide. When carbon dioxide binds to hemoglobin, a molecule called carbaminohemoglobin is formed. Binding of carbon dioxide to hemoglobin is reversible. Therefore, when it reaches the lungs, the carbon dioxide can freely dissociate from the hemoglobin and be expelled from the body.
Third, the majority of carbon dioxide molecules (85 percent) are carried as part of the bicarbonate buffer system. In this system, carbon dioxide diffuses into the red blood cells. Carbonic anhydrase (CA) within the red blood cells quickly converts the carbon dioxide into carbonic acid (H2CO3). Carbonic acid is an unstable intermediate molecule that immediately dissociates into bicarbonate ions and hydrogen (H+) ions. Since carbon dioxide is quickly converted into bicarbonate ions, this reaction allows for the continued uptake of carbon dioxide into the blood down its concentration gradient. It also results in the production of H+ ions. If too much H+ is produced, it can alter blood pH. However, hemoglobin binds to the free H+ ions and thus limits shifts in pH. The newly synthesized bicarbonate ion is transported out of the red blood cell into the liquid component of the blood in exchange for a chloride ion (Cl–); this is called the chloride shift. When the blood reaches the lungs, the bicarbonate ion is transported back into the red blood cell in exchange for the chloride ion. The H+ ion dissociates from the hemoglobin and binds to the bicarbonate ion. This produces the carbonic acid intermediate, which is converted back into carbon dioxide through the enzymatic action of CA. The carbon dioxide produced is expelled through the lungs during exhalation.

The benefit of the bicarbonate buffer system is that carbon dioxide is “soaked up” into the blood with little change to the pH of the system. This is important because it takes only a small change in the overall pH of the body for severe injury or death to result. The presence of this bicarbonate buffer system also allows for people to travel and live at high altitudes: When the partial pressure of oxygen and carbon dioxide change at high altitudes, the bicarbonate buffer system adjusts to regulate carbon dioxide while maintaining the correct pH in the body.
While carbon dioxide can readily associate and dissociate from hemoglobin, other molecules such as carbon monoxide (CO) cannot. Carbon monoxide has a greater affinity for hemoglobin than oxygen. Therefore, when carbon monoxide is present, it binds to hemoglobin preferentially over oxygen. As a result, oxygen cannot bind to hemoglobin, so very little oxygen is transported through the body (Figure 14.22). Carbon monoxide is a colorless, odorless gas and is therefore difficult to detect. It is produced by gas-powered vehicles and tools. Carbon monoxide can cause headaches, confusion, and nausea; long-term exposure can cause brain damage or death. Administering 100 percent (pure) oxygen is the usual treatment for carbon monoxide poisoning. Administration of pure oxygen speeds up the separation of carbon monoxide from hemoglobin.
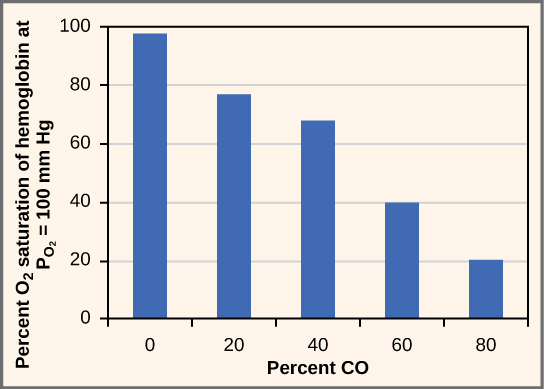
Hemoglobin is a protein found in red blood cells that is comprised of two alpha and two beta subunits that surround an iron-containing heme group. Oxygen readily binds this heme group. The ability of oxygen to bind increases as more oxygen molecules are bound to heme. Disease states and altered conditions in the body can affect the binding ability of oxygen, and increase or decrease its ability to dissociate from hemoglobin.
Carbon dioxide can be transported through the blood via three methods. It is dissolved directly in the blood, bound to plasma proteins or hemoglobin, or converted into bicarbonate. The majority of carbon dioxide is transported as part of the bicarbonate system. Carbon dioxide diffuses into red blood cells. Inside, carbonic anhydrase converts carbon dioxide into carbonic acid (H2CO3), which is subsequently hydrolyzed into bicarbonate and H+. The H+ ion binds to hemoglobin in red blood cells, and bicarbonate is transported out of the red blood cells in exchange for a chloride ion. This is called the chloride shift. Bicarbonate leaves the red blood cells and enters the blood plasma. In the lungs, bicarbonate is transported back into the red blood cells in exchange for chloride. The H+ dissociates from hemoglobin and combines with bicarbonate to form carbonic acid with the help of carbonic anhydrase, which further catalyzes the reaction to convert carbonic acid back into carbon dioxide and water. The carbon dioxide is then expelled from the lungs.
Exercises
Visual Connection Questions
Figure 39.20: The kidneys are responsible for removing excess H+ ions from the blood. If the kidneys fail, what would happen to blood pH and to hemoglobin affinity for oxygen?
Review Questions
Which of the following will NOT facilitate the transfer of oxygen to tissues?
The majority of carbon dioxide in the blood is transported by ________.
The majority of oxygen in the blood is transported by ________.
Critical Thinking Questions
Glossary
ionChapter 39 in OpenStax Concepts of Biology 2e
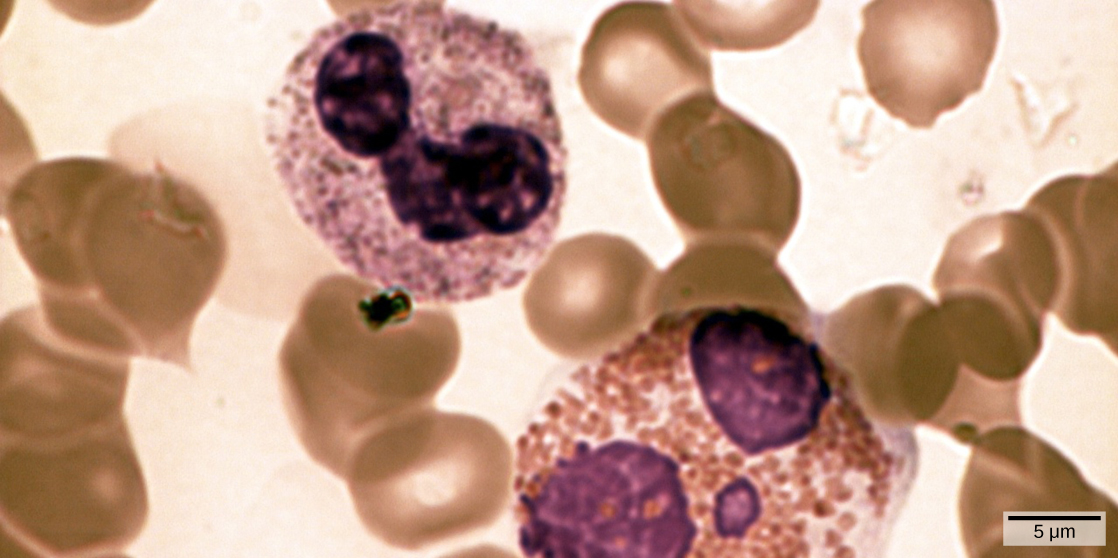
The environment consists of numerous pathogens, which are agents, usually microorganisms, that cause diseases in their hosts. A host is the organism that is invaded and often harmed by a pathogen. Pathogens include bacteria, protists, fungi and other infectious organisms. We are constantly exposed to pathogens in food and water, on surfaces, and in the air. Mammalian immune systems evolved for protection from such pathogens; they are composed of an extremely diverse array of specialized cells and soluble molecules that coordinate a rapid and flexible defense system capable of providing protection from a majority of these disease agents.
Components of the immune system constantly search the body for signs of pathogens. When pathogens are found, immune factors are mobilized to the site of an infection. The immune factors identify the nature of the pathogen, strengthen the corresponding cells and molecules to combat it efficiently, and then halt the immune response after the infection is cleared to avoid unnecessary host cell damage. The immune system can remember pathogens to which it has been exposed to create a more efficient response upon reexposure. This memory can last several decades. Features of the immune system, such as pathogen identification, specific response, amplification, retreat, and remembrance are essential for survival against pathogens. The immune response can be classified as either innate or active. The innate immune response is always present and attempts to defend against all pathogens rather than focusing on specific ones. Conversely, the adaptive immune response stores information about past infections and mounts pathogen-specific defenses.
Glossary
Chapter 42 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
The immune system comprises both innate and adaptive immune responses. Innate immunity occurs naturally because of genetic factors or physiology; it is not induced by infection or vaccination but works to reduce the workload for the adaptive immune response. Both the innate and adaptive levels of the immune response involve secreted proteins, receptor-mediated signaling, and intricate cell-to-cell communication. The innate immune system developed early in animal evolution, roughly a billion years ago, as an essential response to infection. Innate immunity has a limited number of specific targets: any pathogenic threat triggers a consistent sequence of events that can identify the type of pathogen and either clear the infection independently or mobilize a highly specialized adaptive immune response. For example, tears and mucus secretions contain microbicidal factors.
Before any immune factors are triggered, the skin functions as a continuous, impassable barrier to potentially infectious pathogens. Pathogens are killed or inactivated on the skin by desiccation (drying out) and by the skin’s acidity. In addition, beneficial microorganisms that coexist on the skin compete with invading pathogens, preventing infection. Regions of the body that are not protected by skin (such as the eyes and mucus membranes) have alternative methods of defense, such as tears and mucus secretions that trap and rinse away pathogens, and cilia in the nasal passages and respiratory tract that push the mucus with the pathogens out of the body. Throughout the body are other defenses, such as the low pH of the stomach (which inhibits the growth of pathogens), blood proteins that bind and disrupt bacterial cell membranes, and the process of urination (which flushes pathogens from the urinary tract).
Despite these barriers, pathogens may enter the body through skin abrasions or punctures, or by collecting on mucosal surfaces in large numbers that overcome the mucus or cilia. Some pathogens have evolved specific mechanisms that allow them to overcome physical and chemical barriers. When pathogens do enter the body, the innate immune system responds with inflammation, pathogen engulfment, and secretion of immune factors and proteins.
An infection may be intracellular or extracellular, depending on the pathogen. All viruses infect cells and replicate within those cells (intracellularly), whereas bacteria and other parasites may replicate intracellularly or extracellularly, depending on the species. The innate immune system must respond accordingly: by identifying the extracellular pathogen and/or by identifying host cells that have already been infected. When a pathogen enters the body, cells in the blood and lymph detect the specific pathogen-associated molecular patterns (PAMPs) on the pathogen’s surface. PAMPs are carbohydrate, polypeptide, and nucleic acid “signatures” that are expressed by viruses, bacteria, and parasites but which differ from molecules on host cells. The immune system has specific cells, described in Figure 15.2 and shown in Figure 15.3, with receptors that recognize these PAMPs. A macrophage is a large phagocytic cell that engulfs foreign particles and pathogens. Macrophages recognize PAMPs via complementary pattern recognition receptors (PRRs). PRRs are molecules on macrophages and dendritic cells which are in contact with the external environment. A monocyte is a type of white blood cell that circulates in the blood and lymph and differentiates into macrophages after it moves into infected tissue. Dendritic cells bind molecular signatures of pathogens and promote pathogen engulfment and destruction. Toll-like receptors (TLRs) are a type of PRR that recognizes molecules that are shared by pathogens but distinguishable from host molecules. TLRs are present in invertebrates as well as vertebrates, and appear to be one of the most ancient components of the immune system. TLRs have also been identified in the mammalian nervous system.
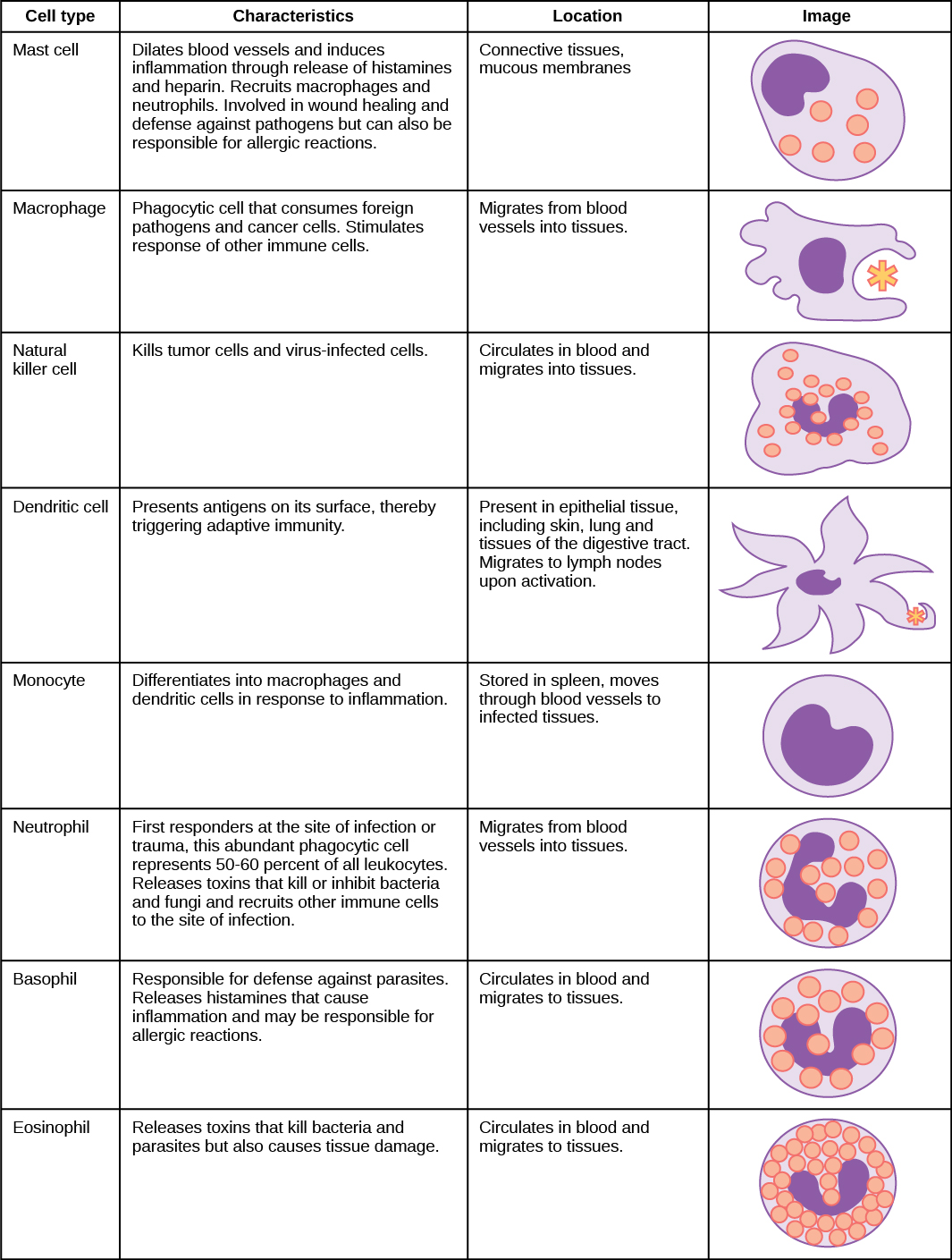
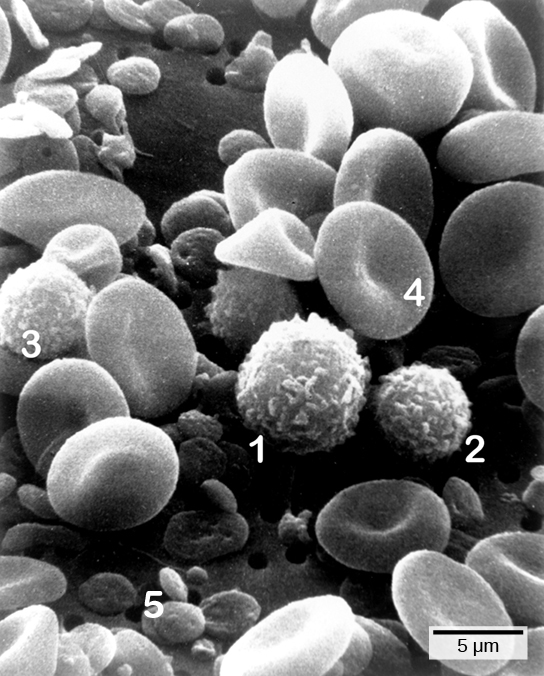
The binding of PRRs with PAMPs triggers the release of cytokines, which signal that a pathogen is present and needs to be destroyed along with any infected cells. A cytokine is a chemical messenger that regulates cell differentiation (form and function), proliferation (production), and gene expression to affect immune responses. At least 40 types of cytokines exist in humans that differ in terms of the cell type that produces them, the cell type that responds to them, and the changes they produce. One type of cytokine, interferon, is illustrated in Figure 15.2.
One subclass of cytokines is the interleukin (IL), so named because they mediate interactions between leukocytes (white blood cells). Interleukins are involved in bridging the innate and adaptive immune responses. In addition to being released from cells after PAMP recognition, cytokines are released by the infected cells which bind to nearby uninfected cells and induce those cells to release cytokines, which results in a cytokine burst.
A second class of early-acting cytokines is interferons, which are released by infected cells as a warning to nearby uninfected cells. One of the functions of an interferon is to inhibit viral replication. They also have other important functions, such as tumor surveillance. Interferons work by signaling neighboring uninfected cells to destroy RNA and reduce protein synthesis, signaling neighboring infected cells to undergo apoptosis (programmed cell death), and activating immune cells.
In response to interferons, uninfected cells alter their gene expression, which increases the cells’ resistance to infection. One effect of interferon-induced gene expression is a sharply reduced cellular protein synthesis. Virally infected cells produce more viruses by synthesizing large quantities of viral proteins. Thus, by reducing protein synthesis, a cell becomes resistant to viral infection.
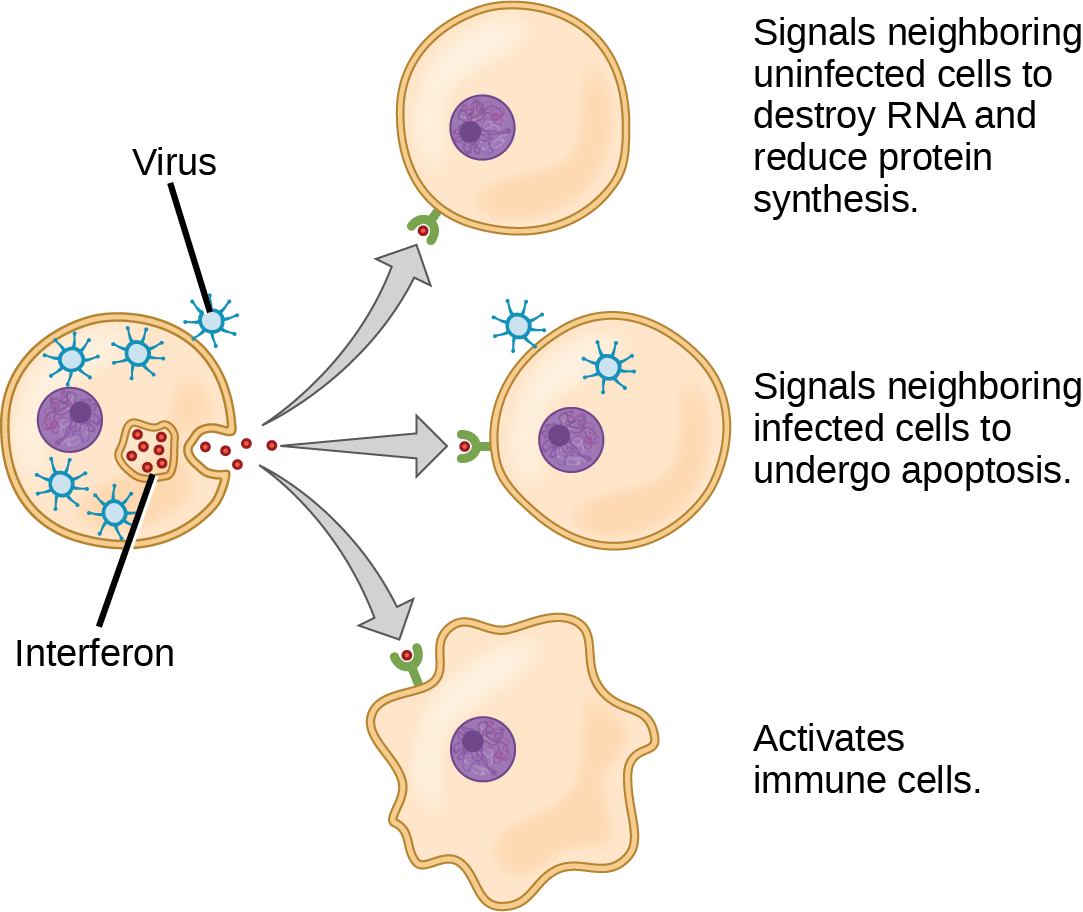
The first cytokines to be produced are pro-inflammatory; that is, they encourage inflammation, the localized redness, swelling, heat, and pain that result from the movement of leukocytes and fluid through increasingly permeable capillaries to a site of infection. The population of leukocytes that arrives at an infection site depends on the nature of the infecting pathogen. Both macrophages and dendritic cells engulf pathogens and cellular debris through phagocytosis. A neutrophil is also a phagocytic leukocyte that engulfs and digests pathogens. Neutrophils, shown in Figure 15.3, are the most abundant leukocytes of the immune system. Neutrophils have a nucleus with two to five lobes, and they contain organelles, called lysosomes, that digest engulfed pathogens. An eosinophil is a leukocyte that works with other eosinophils to surround a parasite; it is involved in the allergic response and in protection against helminthes (parasitic worms).
Neutrophils and eosinophils are particularly important leukocytes that engulf large pathogens, such as bacteria and fungi. A mast cell is a leukocyte that produces inflammatory molecules, such as histamine, in response to large pathogens. A basophil is a leukocyte that, like a neutrophil, releases chemicals to stimulate the inflammatory response as illustrated in Figure 15.5. Basophils are also involved in allergy and hypersensitivity responses and induce specific types of inflammatory responses. Eosinophils and basophils produce additional inflammatory mediators to recruit more leukocytes. A hypersensitive immune response to harmless antigens, such as in pollen, often involves the release of histamine by basophils and mast cells.
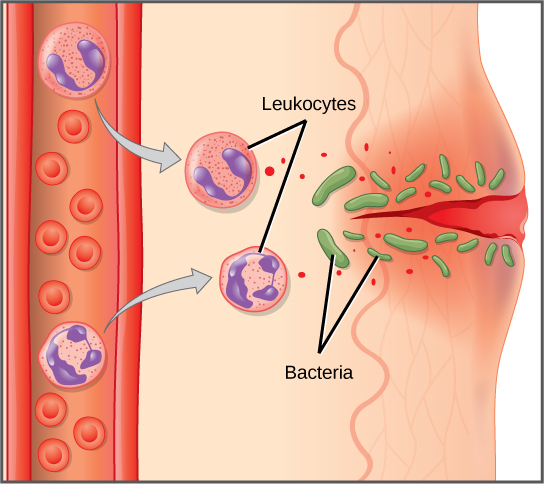
Cytokines also send feedback to cells of the nervous system to bring about the overall symptoms of feeling sick, which include lethargy, muscle pain, and nausea. These effects may have evolved because the symptoms encourage the individual to rest and prevent the spreading of the infection to others. Cytokines also increase the core body temperature, causing a fever, which causes the liver to withhold iron from the blood. Without iron, certain pathogens, such as some bacteria, are unable to replicate; this is called nutritional immunity.
Watch this 23-second stop-motion video showing a neutrophil that searches for and engulfs fungus spores during an elapsed time of about 79 minutes.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=677
Lymphocytes are leukocytes that are histologically identifiable by their large, darkly staining nuclei; they are small cells with very little cytoplasm, as shown in Figure 15.6. Infected cells are identified and destroyed by natural killer (NK) cells, lymphocytes that can kill cells infected with viruses or tumor cells (abnormal cells that uncontrollably divide and invade other tissue). T cells and B cells of the adaptive immune system also are classified as lymphocytes. T cells are lymphocytes that mature in the thymus gland, and B cells are lymphocytes that mature in the bone marrow. NK cells identify intracellular infections, especially from viruses, by the altered expression of major histocompatibility class (MHC) I molecules on the surface of infected cells. MHC I molecules are proteins on the surfaces of all nucleated cells, thus they are scarce on red blood cells and platelets which are non-nucleated. The function of MHC I molecules is to display fragments of proteins from the infectious agents within the cell to T cells; healthy cells will be ignored, while “non-self” or foreign proteins will be attacked by the immune system. MHC II molecules are found mainly on cells containing antigens (“non-self proteins”) and on lymphocytes. MHC II molecules interact with helper T cells to trigger the appropriate immune response, which may include the inflammatory response.
An infected cell (or a tumor cell) is usually incapable of synthesizing and displaying MHC I molecules appropriately. The metabolic resources of cells infected by some viruses produce proteins that interfere with MHC I processing and/or trafficking to the cell surface. The reduced MHC I on host cells varies from virus to virus and results from active inhibitors being produced by the viruses. This process can deplete host MHC I molecules on the cell surface, which NK cells detect as “unhealthy” or “abnormal” while searching for cellular MHC I molecules. Similarly, the dramatically altered gene expression of tumor cells leads to expression of extremely deformed or absent MHC I molecules that also signal “unhealthy” or “abnormal.”
NK cells are always active; an interaction with normal, intact MHC I molecules on a healthy cell disables the killing sequence, and the NK cell moves on. After the NK cell detects an infected or tumor cell, its cytoplasm secretes granules comprised of perforin, a destructive protein that creates a pore in the target cell. Granzymes are released along with the perforin in the immunological synapse. A granzyme is a protease that digests cellular proteins and induces the target cell to undergo programmed cell death, or apoptosis. Phagocytic cells then digest the cell debris left behind. NK cells are constantly patrolling the body and are an effective mechanism for controlling potential infections and preventing cancer progression.
An array of approximately 20 types of soluble proteins, called a complement system, functions to destroy extracellular pathogens. Cells of the liver and macrophages synthesize complement proteins continuously; these proteins are abundant in the blood serum and are capable of responding immediately to infecting microorganisms. The complement system is so named because it is complementary to the antibody response of the adaptive immune system. Complement proteins bind to the surfaces of microorganisms and are particularly attracted to pathogens that are already bound by antibodies. Binding of complement proteins occurs in a specific and highly regulated sequence, with each successive protein being activated by cleavage and/or structural changes induced upon binding of the preceding protein(s). After the first few complement proteins bind, a cascade of sequential binding events follows in which the pathogen rapidly becomes coated in complement proteins.
Complement proteins perform several functions. The proteins serve as a marker to indicate the presence of a pathogen to phagocytic cells, such as macrophages and B cells, and enhance engulfment; this process is called opsonization. Certain complement proteins can combine to form attack complexes that open pores in microbial cell membranes. These structures destroy pathogens by causing their contents to leak, as illustrated in Figure 15.7.
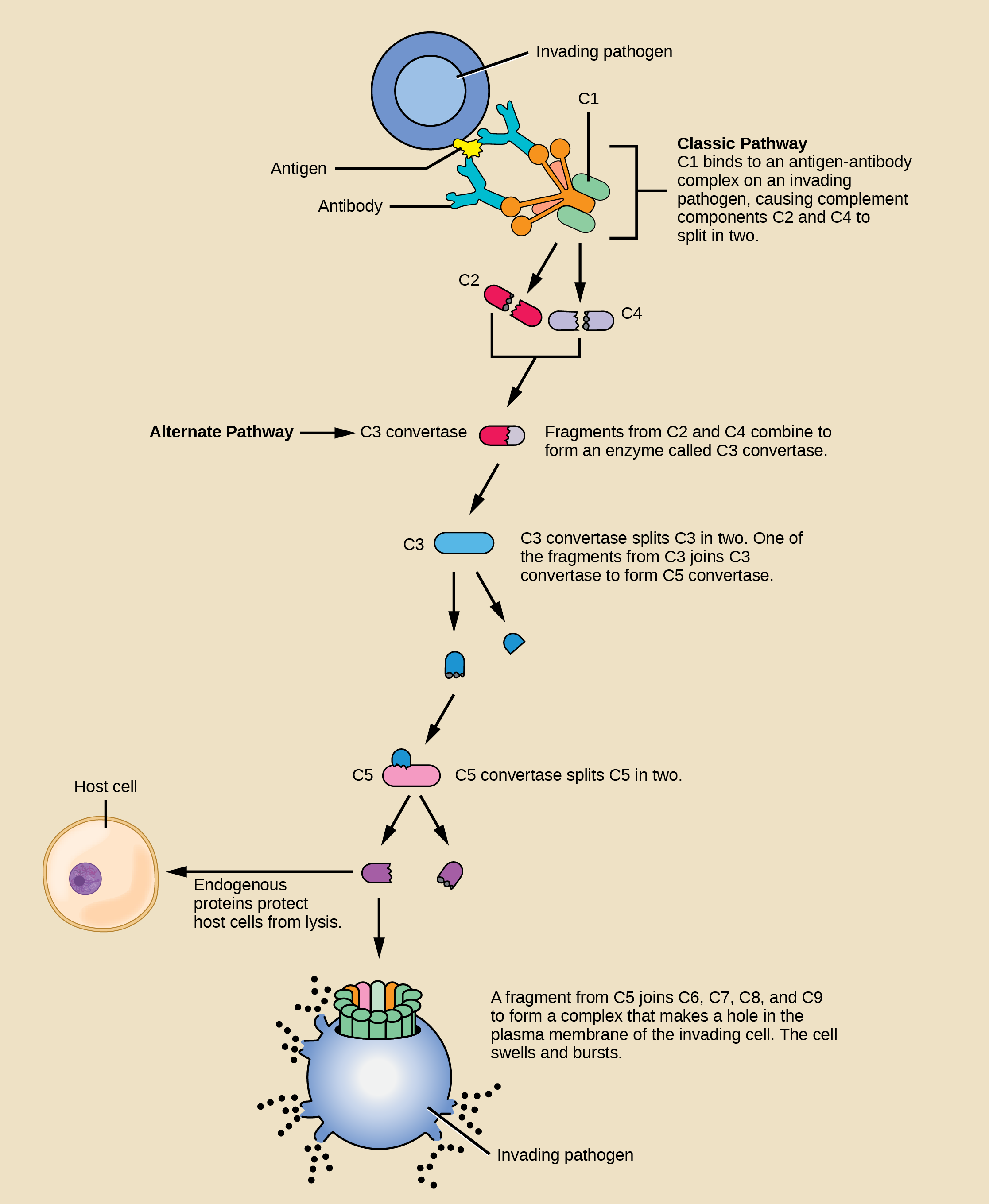
The innate immune system serves as a first responder to pathogenic threats that bypass natural physical and chemical barriers of the body. Using a combination of cellular and molecular attacks, the innate immune system identifies the nature of a pathogen and responds with inflammation, phagocytosis, cytokine release, destruction by NK cells, and/or a complement system. When innate mechanisms are insufficient to clear an infection, the adaptive immune response is informed and mobilized.
Exercises
Review Questions
Which of the following is a barrier against pathogens provided by the skin?
Although interferons have several effects, they are particularly useful against infections with which type of pathogen?
Which organelle do phagocytes use to digest engulfed particles?
Which innate immune system component uses MHC I molecules directly in its defense strategy?
Critical Thinking Questions
Glossary
Chapter 42 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
The adaptive, or acquired, immune response takes days or even weeks to become established—much longer than the innate response; however, adaptive immunity is more specific to pathogens and has memory. Adaptive immunity is an immunity that occurs after exposure to an antigen either from a pathogen or a vaccination. This part of the immune system is activated when the innate immune response is insufficient to control an infection. In fact, without information from the innate immune system, the adaptive response could not be mobilized. There are two types of adaptive responses: the cell-mediated immune response, which is carried out by T cells, and the humoral immune response, which is controlled by activated B cells and antibodies. Activated T cells and B cells that are specific to molecular structures on the pathogen proliferate and attack the invading pathogen. Their attack can kill pathogens directly or secrete antibodies that enhance the phagocytosis of pathogens and disrupt the infection. Adaptive immunity also involves a memory to provide the host with long-term protection from reinfection with the same type of pathogen; on reexposure, this memory will facilitate an efficient and quick response.
Unlike NK cells of the innate immune system, B cells (B lymphocytes) are a type of white blood cell that gives rise to antibodies, whereas T cells (T lymphocytes) are a type of white blood cell that plays an important role in the immune response. T cells are a key component in the cell-mediated response—the specific immune response that utilizes T cells to neutralize cells that have been infected with viruses and certain bacteria. There are three types of T cells: cytotoxic, helper, and suppressor T cells. Cytotoxic T cells destroy virus-infected cells in the cell-mediated immune response, and helper T cells play a part in activating both the antibody and the cell-mediated immune responses. Suppressor T cells deactivate T cells and B cells when needed, and thus prevent the immune response from becoming too intense.
An antigen is a foreign or “non-self” macromolecule that reacts with cells of the immune system. Not all antigens will provoke a response. For instance, individuals produce innumerable “self” antigens and are constantly exposed to harmless foreign antigens, such as food proteins, pollen, or dust components. The suppression of immune responses to harmless macromolecules is highly regulated and typically prevents processes that could be damaging to the host, known as tolerance.
The innate immune system contains cells that detect potentially harmful antigens, and then inform the adaptive immune response about the presence of these antigens. An antigen-presenting cell (APC) is an immune cell that detects, engulfs, and informs the adaptive immune response about an infection. When a pathogen is detected, these APCs will phagocytose the pathogen and digest it to form many different fragments of the antigen. Antigen fragments will then be transported to the surface of the APC, where they will serve as an indicator to other immune cells. Dendritic cells are immune cells that process antigen material; they are present in the skin (Langerhans cells) and the lining of the nose, lungs, stomach, and intestines. Sometimes a dendritic cell presents on the surface of other cells to induce an immune response, thus functioning as an antigen-presenting cell. Macrophages also function as APCs. Before activation and differentiation, B cells can also function as APCs.
After phagocytosis by APCs, the phagocytic vesicle fuses with an intracellular lysosome forming phagolysosome. Within the phagolysosome, the components are broken down into fragments; the fragments are then loaded onto MHC class I or MHC class II molecules and are transported to the cell surface for antigen presentation, as illustrated in Figure 15.8. Note that T lymphocytes cannot properly respond to the antigen unless it is processed and embedded in an MHC II molecule. APCs express MHC on their surfaces, and when combined with a foreign antigen, these complexes signal a “non-self” invader. Once the fragment of antigen is embedded in the MHC II molecule, the immune cell can respond. Helper T cells are one of the main lymphocytes that respond to antigen-presenting cells. Recall that all other nucleated cells of the body expressed MHC I molecules, which signal “healthy” or “normal.”
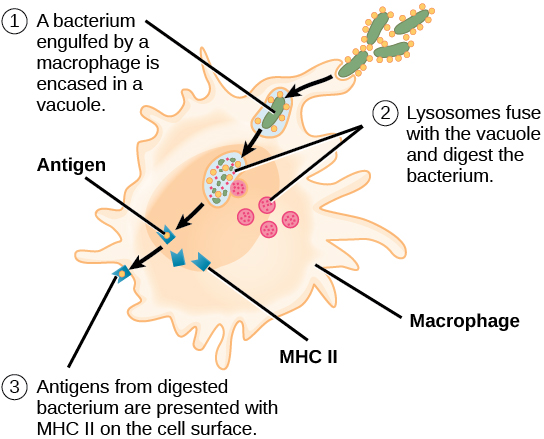
This animation from Rockefeller University shows how dendritic cells act as sentinels in the body’s immune system.
Lymphocytes in human circulating blood are approximately 80 to 90 percent T cells, shown in Figure 15.9, and 10 to 20 percent B cells. Recall that the T cells are involved in the cell-mediated immune response, whereas B cells are part of the humoral immune response.
T cells encompass a heterogeneous population of cells with extremely diverse functions. Some T cells respond to APCs of the innate immune system, and indirectly induce immune responses by releasing cytokines. Other T cells stimulate B cells to prepare their own response. Another population of T cells detects APC signals and directly kills the infected cells. Other T cells are involved in suppressing inappropriate immune reactions to harmless or “self” antigens.

T and B cells exhibit a common theme of recognition/binding of specific antigens via a complementary receptor, followed by activation and self-amplification/maturation to specifically bind to the particular antigen of the infecting pathogen. T and B lymphocytes are also similar in that each cell only expresses one type of antigen receptor. Any individual may possess a population of T and B cells that together express a near limitless variety of antigen receptors that are capable of recognizing virtually any infecting pathogen. T and B cells are activated when they recognize small components of antigens, called epitopes, presented by APCs, illustrated in Figure 15.10. Note that recognition occurs at a specific epitope rather than on the entire antigen; for this reason, epitopes are known as “antigenic determinants.” In the absence of information from APCs, T and B cells remain inactive, or naïve, and are unable to prepare an immune response. The requirement for information from the APCs of innate immunity to trigger B cell or T cell activation illustrates the essential nature of the innate immune response to the functioning of the entire immune system.

Naïve T cells can express one of two different molecules, CD4 or CD8, on their surface, as shown in Figure 15.11, and are accordingly classified as CD4+ or CD8+ cells. These molecules are important because they regulate how a T cell will interact with and respond to an APC. Naïve CD4+ cells bind APCs via their antigen-embedded MHC II molecules and are stimulated to become helper T (TH) lymphocytes, cells that go on to stimulate B cells (or cytotoxic T cells) directly or secrete cytokines to inform more and various target cells about the pathogenic threat. In contrast, CD8+ cells engage antigen-embedded MHC I molecules on APCs and are stimulated to become cytotoxic T lymphocytes (CTLs), which directly kill infected cells by apoptosis and emit cytokines to amplify the immune response. The two populations of T cells have different mechanisms of immune protection, but both bind MHC molecules via their antigen receptors called T cell receptors (TCRs). The CD4 or CD8 surface molecules differentiate whether the TCR will engage an MHC II or an MHC I molecule. Because they assist in binding specificity, the CD4 and CD8 molecules are described as coreceptors.
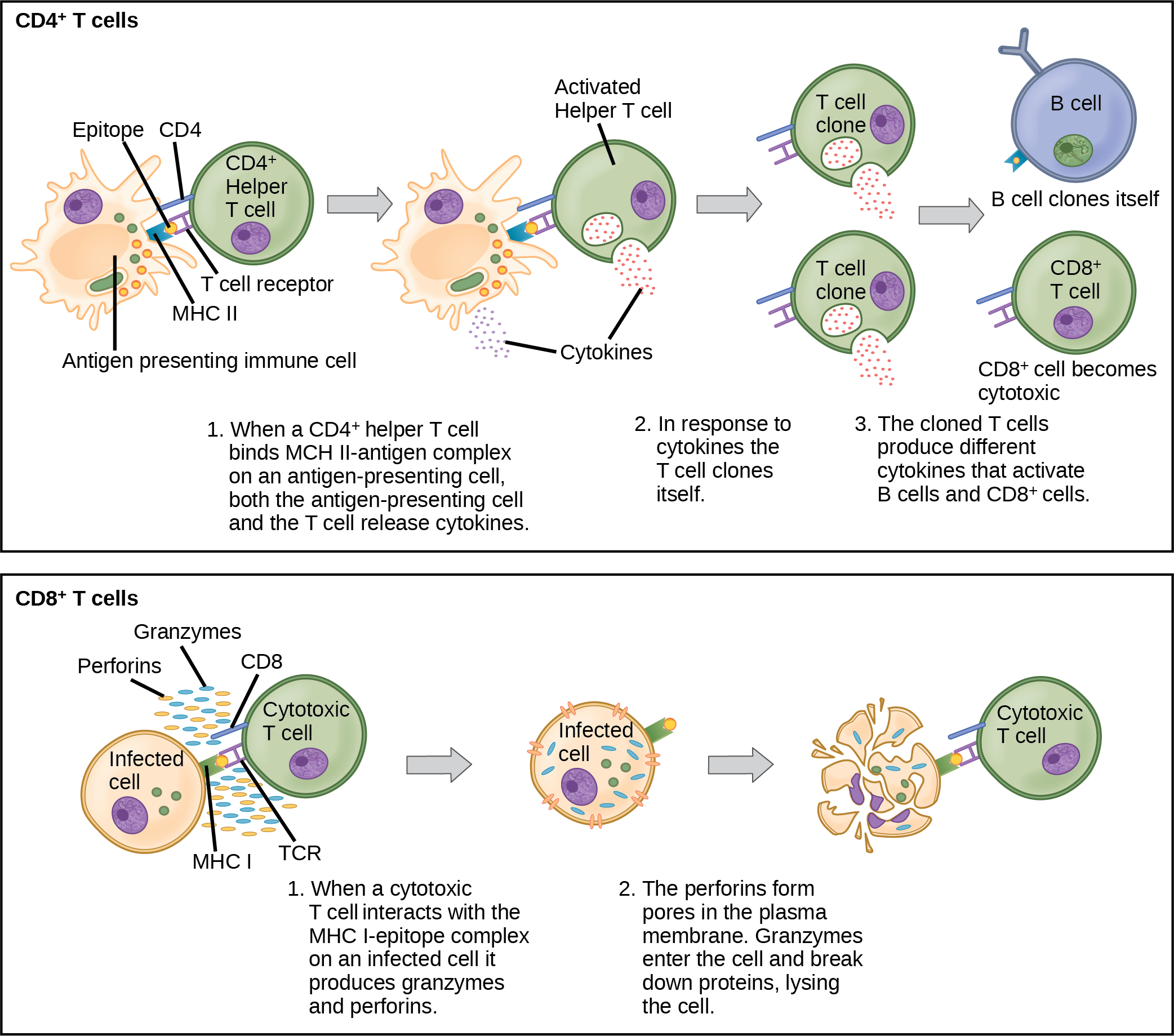
Which of the following statements about T cells is false?
Consider the innumerable possible antigens that an individual will be exposed to during a lifetime. The mammalian adaptive immune system is adept in responding appropriately to each antigen. Mammals have an enormous diversity of T cell populations, resulting from the diversity of TCRs. Each TCR consists of two polypeptide chains that span the T cell membrane, as illustrated in Figure 15.12; the chains are linked by a disulfide bridge. Each polypeptide chain is comprised of a constant domain and a variable domain: a domain, in this sense, is a specific region of a protein that may be regulatory or structural. The intracellular domain is involved in intracellular signaling. A single T cell will express thousands of identical copies of one specific TCR variant on its cell surface. The specificity of the adaptive immune system occurs because it synthesizes millions of different T cell populations, each expressing a TCR that differs in its variable domain. This TCR diversity is achieved by the mutation and recombination of genes that encode these receptors in stem cell precursors of T cells. The binding between an antigen-displaying MHC molecule and a complementary TCR “match” indicates that the adaptive immune system needs to activate and produce that specific T cell because its structure is appropriate to recognize and destroy the invading pathogen.
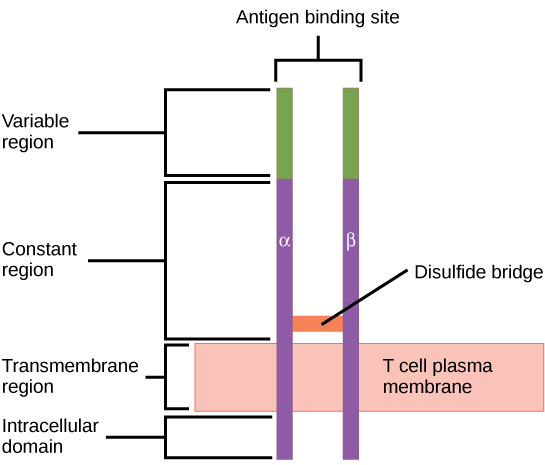
The TH lymphocytes function indirectly to identify potential pathogens for other cells of the immune system. These cells are important for extracellular infections, such as those caused by certain bacteria, helminths, and protozoa. TH lymphocytes recognize specific antigens displayed in the MHC II complexes of APCs. There are two major populations of TH cells: TH1 and TH2. TH1 cells secrete cytokines to enhance the activities of macrophages and other T cells. TH1 cells activate the action of cyotoxic T cells, as well as macrophages. TH2 cells stimulate naïve B cells to destroy foreign invaders via antibody secretion. Whether a TH1 or a TH2 immune response develops depends on the specific types of cytokines secreted by cells of the innate immune system, which in turn depends on the nature of the invading pathogen.
The TH1-mediated response involves macrophages and is associated with inflammation. Recall the frontline defenses of macrophages involved in the innate immune response. Some intracellular bacteria, such as Mycobacterium tuberculosis, have evolved to multiply in macrophages after they have been engulfed. These pathogens evade attempts by macrophages to destroy and digest the pathogen. When M. tuberculosis infection occurs, macrophages can stimulate naïve T cells to become TH1 cells. These stimulated T cells secrete specific cytokines that send feedback to the macrophage to stimulate its digestive capabilities and allow it to destroy the colonizing M. tuberculosis. In the same manner, TH1-activated macrophages also become better suited to ingest and kill tumor cells. In summary; TH1 responses are directed toward intracellular invaders while TH2 responses are aimed at those that are extracellular.
When stimulated by the TH2 pathway, naïve B cells differentiate into antibody-secreting plasma cells. A plasma cell is an immune cell that secrets antibodies; these cells arise from B cells that were stimulated by antigens. Similar to T cells, naïve B cells initially are coated in thousands of B cell receptors (BCRs), which are membrane-bound forms of Ig (immunoglobulin, or an antibody). The B cell receptor has two heavy chains and two light chains connected by disulfide linkages. Each chain has a constant and a variable region; the latter is involved in antigen binding. Two other membrane proteins, Ig alpha and Ig beta, are involved in signaling. The receptors of any particular B cell, as shown in Figure 15.13 are all the same, but the hundreds of millions of different B cells in an individual have distinct recognition domains that contribute to extensive diversity in the types of molecular structures to which they can bind. In this state, B cells function as APCs. They bind and engulf foreign antigens via their BCRs and then display processed antigens in the context of MHC II molecules to TH2 cells. When a TH2 cell detects that a B cell is bound to a relevant antigen, it secretes specific cytokines that induce the B cell to proliferate rapidly, which makes thousands of identical (clonal) copies of it, and then it synthesizes and secretes antibodies with the same antigen recognition pattern as the BCRs. The activation of B cells corresponding to one specific BCR variant and the dramatic proliferation of that variant is known as clonal selection. This phenomenon drastically, but briefly, changes the proportions of BCR variants expressed by the immune system, and shifts the balance toward BCRs specific to the infecting pathogen.
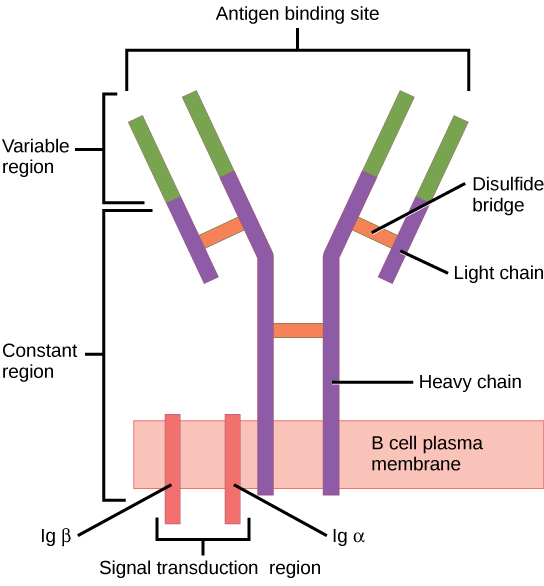
T and B cells differ in one fundamental way: whereas T cells bind antigens that have been digested and embedded in MHC molecules by APCs, B cells function as APCs that bind intact antigens that have not been processed. Although T and B cells both react with molecules that are termed “antigens,” these lymphocytes actually respond to very different types of molecules. B cells must be able to bind intact antigens because they secrete antibodies that must recognize the pathogen directly, rather than digested remnants of the pathogen. Bacterial carbohydrate and lipid molecules can activate B cells independently from the T cells.
CTLs, a subclass of T cells, function to clear infections directly. The cell-mediated part of the adaptive immune system consists of CTLs that attack and destroy infected cells. CTLs are particularly important in protecting against viral infections; this is because viruses replicate within cells where they are shielded from extracellular contact with circulating antibodies. When APCs phagocytize pathogens and present MHC I-embedded antigens to naïve CD8+ T cells that express complementary TCRs, the CD8+ T cells become activated to proliferate according to clonal selection. These resulting CTLs then identify non-APCs displaying the same MHC I-embedded antigens (for example, viral proteins)—for example, the CTLs identify infected host cells.
Intracellularly, infected cells typically die after the infecting pathogen replicates to a sufficient concentration and lyses the cell, as many viruses do. CTLs attempt to identify and destroy infected cells before the pathogen can replicate and escape, thereby halting the progression of intracellular infections. CTLs also support NK lymphocytes to destroy early cancers. Cytokines secreted by the TH1 response that stimulates macrophages also stimulate CTLs and enhance their ability to identify and destroy infected cells and tumors.
CTLs sense MHC I-embedded antigens by directly interacting with infected cells via their TCRs. Binding of TCRs with antigens activates CTLs to release perforin and granzyme, degradative enzymes that will induce apoptosis of the infected cell. Recall that this is a similar destruction mechanism to that used by NK cells. In this process, the CTL does not become infected and is not harmed by the secretion of perforin and granzymes. In fact, the functions of NK cells and CTLs are complementary and maximize the removal of infected cells, as illustrated in Figure 15.14. If the NK cell cannot identify the “missing self” pattern of down-regulated MHC I molecules, then the CTL can identify it by the complex of MHC I with foreign antigens, which signals “altered self.” Similarly, if the CTL cannot detect antigen-embedded MHC I because the receptors are depleted from the cell surface, NK cells will destroy the cell instead. CTLs also emit cytokines, such as interferons, that alter surface protein expression in other infected cells, such that the infected cells can be easily identified and destroyed. Moreover, these interferons can also prevent virally infected cells from releasing virus particles.
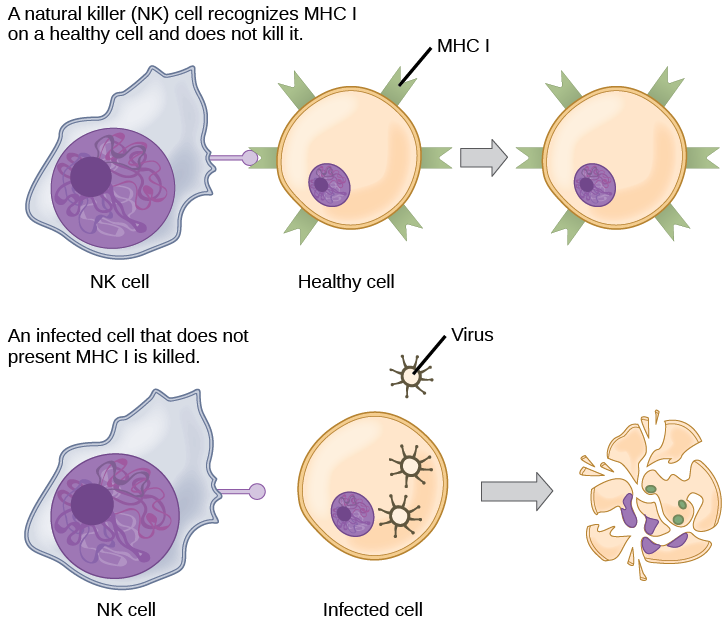
Based on what you know about MHC receptors, why do you think an organ transplanted from an incompatible donor to a recipient will be rejected?
Plasma cells and CTLs are collectively called effector cells: they represent differentiated versions of their naïve counterparts, and they are involved in bringing about the immune defense of killing pathogens and infected host cells.
The innate and adaptive immune responses discussed thus far comprise the systemic immune system (affecting the whole body), which is distinct from the mucosal immune system. Mucosal immunity is formed by mucosa-associated lymphoid tissue, which functions independently of the systemic immune system, and which has its own innate and adaptive components. Mucosa-associated lymphoid tissue (MALT), illustrated in Figure 15.15, is a collection of lymphatic tissue that combines with epithelial tissue lining the mucosa throughout the body. This tissue functions as the immune barrier and response in areas of the body with direct contact to the external environment. The systemic and mucosal immune systems use many of the same cell types. Foreign particles that make their way to MALT are taken up by absorptive epithelial cells called M cells and delivered to APCs located directly below the mucosal tissue. M cells function in the transport described, and are located in the Peyer’s patch, a lymphoid nodule. APCs of the mucosal immune system are primarily dendritic cells, with B cells and macrophages having minor roles. Processed antigens displayed on APCs are detected by T cells in the MALT and at various mucosal induction sites, such as the tonsils, adenoids, appendix, or the mesenteric lymph nodes of the intestine. Activated T cells then migrate through the lymphatic system and into the circulatory system to mucosal sites of infection.
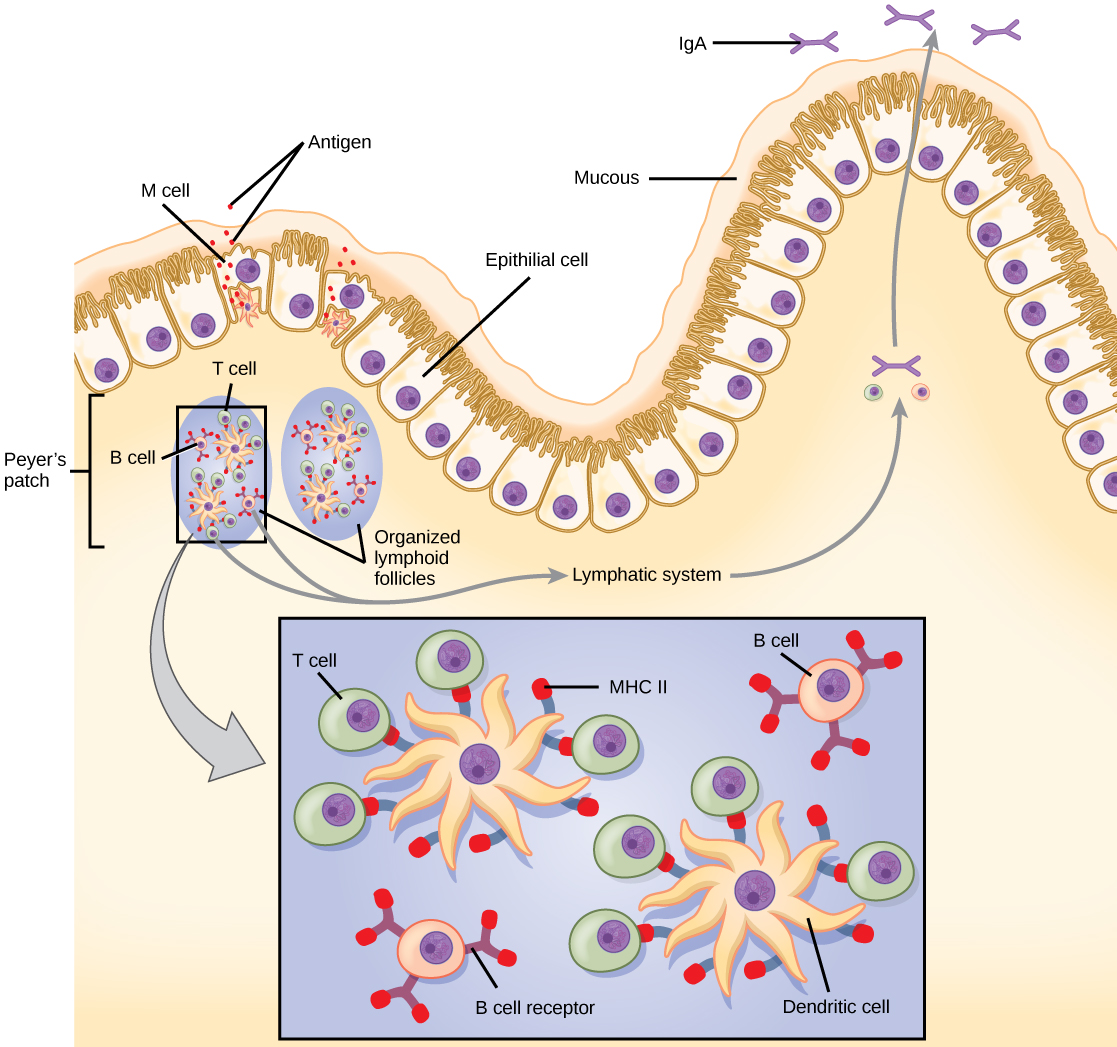
MALT is a crucial component of a functional immune system because mucosal surfaces, such as the nasal passages, are the first tissues onto which inhaled or ingested pathogens are deposited. The mucosal tissue includes the mouth, pharynx, and esophagus, and the gastrointestinal, respiratory, and urogenital tracts.
The immune system has to be regulated to prevent wasteful, unnecessary responses to harmless substances, and more importantly so that it does not attack “self.” The acquired ability to prevent an unnecessary or harmful immune response to a detected foreign substance known not to cause disease is described as immune tolerance. Immune tolerance is crucial for maintaining mucosal homeostasis given the tremendous number of foreign substances (such as food proteins) that APCs of the oral cavity, pharynx, and gastrointestinal mucosa encounter. Immune tolerance is brought about by specialized APCs in the liver, lymph nodes, small intestine, and lung that present harmless antigens to an exceptionally diverse population of regulatory T (Treg) cells, specialized lymphocytes that suppress local inflammation and inhibit the secretion of stimulatory immune factors. The combined result of Treg cells is to prevent immunologic activation and inflammation in undesired tissue compartments and to allow the immune system to focus on pathogens instead. In addition to promoting immune tolerance of harmless antigens, other subsets of Treg cells are involved in the prevention of the autoimmune response, which is an inappropriate immune response to host cells or self-antigens. Another Treg class suppresses immune responses to harmful pathogens after the infection has cleared to minimize host cell damage induced by inflammation and cell lysis.
The adaptive immune system possesses a memory component that allows for an efficient and dramatic response upon reinvasion of the same pathogen. Memory is handled by the adaptive immune system with little reliance on cues from the innate response. During the adaptive immune response to a pathogen that has not been encountered before, called a primary response, plasma cells secreting antibodies and differentiated T cells increase, then plateau over time. As B and T cells mature into effector cells, a subset of the naïve populations differentiates into B and T memory cells with the same antigen specificities, as illustrated in Figure 15.16.
A memory cell is an antigen-specific B or T lymphocyte that does not differentiate into effector cells during the primary immune response, but that can immediately become effector cells upon reexposure to the same pathogen. During the primary immune response, memory cells do not respond to antigens and do not contribute to host defenses. As the infection is cleared and pathogenic stimuli subside, the effectors are no longer needed, and they undergo apoptosis. In contrast, the memory cells persist in the circulation.
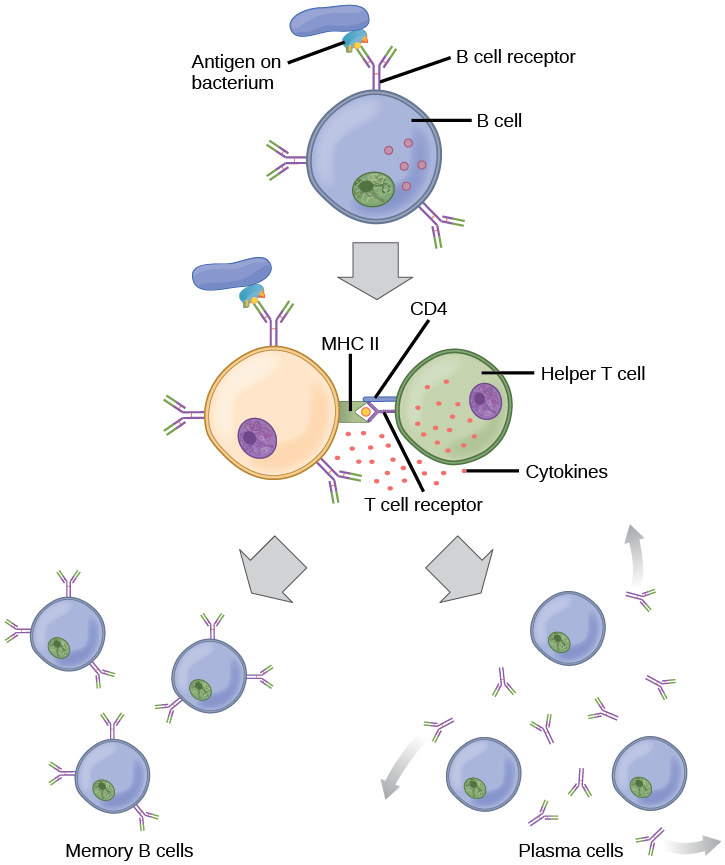
The Rh antigen is found on Rh-positive red blood cells. An Rh-negative female can usually carry an Rh-positive fetus to term without difficulty. However, if she has a second Rh-positive fetus, her body may launch an immune attack that causes hemolytic disease of the newborn. Why do you think hemolytic disease is only a problem during the second or subsequent pregnancies?
If the pathogen is never encountered again during the individual’s lifetime, B and T memory cells will circulate for a few years or even several decades and will gradually die off, having never functioned as effector cells. However, if the host is reexposed to the same pathogen type, circulating memory cells will immediately differentiate into plasma cells and CTLs without input from APCs or TH cells. One reason the adaptive immune response is delayed is because it takes time for naïve B and T cells with the appropriate antigen specificities to be identified and activated. Upon reinfection, this step is skipped, and the result is a more rapid production of immune defenses. Memory B cells that differentiate into plasma cells output tens to hundreds-fold greater antibody amounts than were secreted during the primary response, as the graph in Figure 15.17 illustrates. This rapid and dramatic antibody response may stop the infection before it can even become established, and the individual may not realize he or she had been exposed.
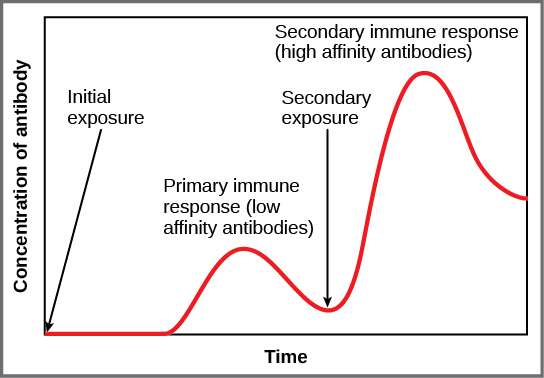
Vaccination is based on the knowledge that exposure to noninfectious antigens, derived from known pathogens, generates a mild primary immune response. The immune response to vaccination may not be perceived by the host as illness but still confers immune memory. When exposed to the corresponding pathogen to which an individual was vaccinated, the reaction is similar to a secondary exposure. Because each reinfection generates more memory cells and increased resistance to the pathogen, and because some memory cells die, certain vaccine courses involve one or more booster vaccinations to mimic repeat exposures: for instance, tetanus boosters are necessary every ten years because the memory cells only live that long.
A subset of T and B cells of the mucosal immune system differentiates into memory cells just as in the systemic immune system. Upon reinvasion of the same pathogen type, a pronounced immune response occurs at the mucosal site where the original pathogen deposited, but a collective defense is also organized within interconnected or adjacent mucosal tissue. For instance, the immune memory of an infection in the oral cavity would also elicit a response in the pharynx if the oral cavity was exposed to the same pathogen.
Vaccination (or immunization) involves the delivery, usually by injection as shown in Figure 15.18, of noninfectious antigen(s) derived from known pathogens. Other components, called adjuvants, are delivered in parallel to help stimulate the immune response. Immunological memory is the reason vaccines work. Ideally, the effect of vaccination is to elicit immunological memory, and thus resistance to specific pathogens without the individual having to experience an infection.
Vaccinologists are involved in the process of vaccine development from the initial idea to the availability of the completed vaccine. This process can take decades, can cost millions of dollars, and can involve many obstacles along the way. For instance, injected vaccines stimulate the systemic immune system, eliciting humoral and cell-mediated immunity, but have little effect on the mucosal response, which presents a challenge because many pathogens are deposited and replicate in mucosal compartments, and the injection does not provide the most efficient immune memory for these disease agents. For this reason, vaccinologists are actively involved in developing new vaccines that are applied via intranasal, aerosol, oral, or transcutaneous (absorbed through the skin) delivery methods. Importantly, mucosal-administered vaccines elicit both mucosal and systemic immunity and produce the same level of disease resistance as injected vaccines.
Currently, a version of intranasal influenza vaccine is available, and the polio and typhoid vaccines can be administered orally, as shown in Figure 15.19. Similarly, the measles and rubella vaccines are being adapted to aerosol delivery using inhalation devices. Eventually, transgenic plants may be engineered to produce vaccine antigens that can be eaten to confer disease resistance. Other vaccines may be adapted to rectal or vaginal application to elicit immune responses in rectal, genitourinary, or reproductive mucosa. Finally, vaccine antigens may be adapted to transdermal application in which the skin is lightly scraped and microneedles are used to pierce the outermost layer. In addition to mobilizing the mucosal immune response, this new generation of vaccines may end the anxiety associated with injections and, in turn, improve patient participation.
Although the immune system is characterized by circulating cells throughout the body, the regulation, maturation, and intercommunication of immune factors occur at specific sites. The blood circulates immune cells, proteins, and other factors through the body. Approximately 0.1 percent of all cells in the blood are leukocytes, which encompass monocytes (the precursor of macrophages) and lymphocytes. The majority of cells in the blood are erythrocytes (red blood cells). Lymph is a watery fluid that bathes tissues and organs with protective white blood cells and does not contain erythrocytes. Cells of the immune system can travel between the distinct lymphatic and blood circulatory systems, which are separated by interstitial space, by a process called extravasation (passing through to surrounding tissue).
The cells of the immune system originate from hematopoietic stem cells in the bone marrow. Cytokines stimulate these stem cells to differentiate into immune cells. B cell maturation occurs in the bone marrow, whereas naïve T cells transit from the bone marrow to the thymus for maturation. In the thymus, immature T cells that express TCRs complementary to self-antigens are destroyed. This process helps prevent autoimmune responses.
On maturation, T and B lymphocytes circulate to various destinations. Lymph nodes scattered throughout the body, as illustrated in Figure 15.20, house large populations of T and B cells, dendritic cells, and macrophages. Lymph gathers antigens as it drains from tissues. These antigens then are filtered through lymph nodes before the lymph is returned to circulation. APCs in the lymph nodes capture and process antigens and inform nearby lymphocytes about potential pathogens.
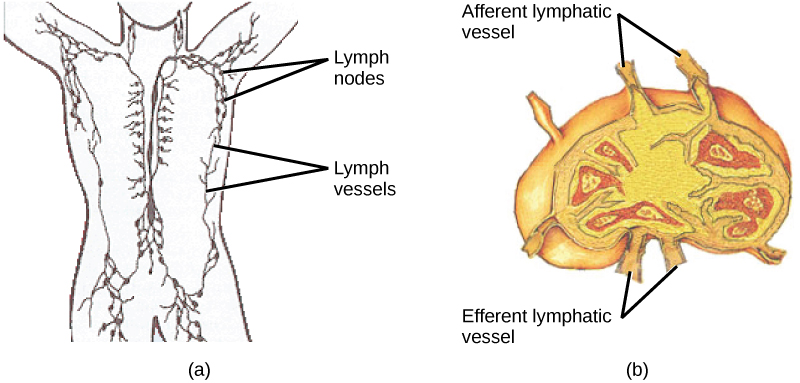
The spleen houses B and T cells, macrophages, dendritic cells, and NK cells. The spleen, shown in Figure 15.21, is the site where APCs that have trapped foreign particles in the blood can communicate with lymphocytes. Antibodies are synthesized and secreted by activated plasma cells in the spleen, and the spleen filters foreign substances and antibody-complexed pathogens from the blood. Functionally, the spleen is to the blood as lymph nodes are to the lymph.
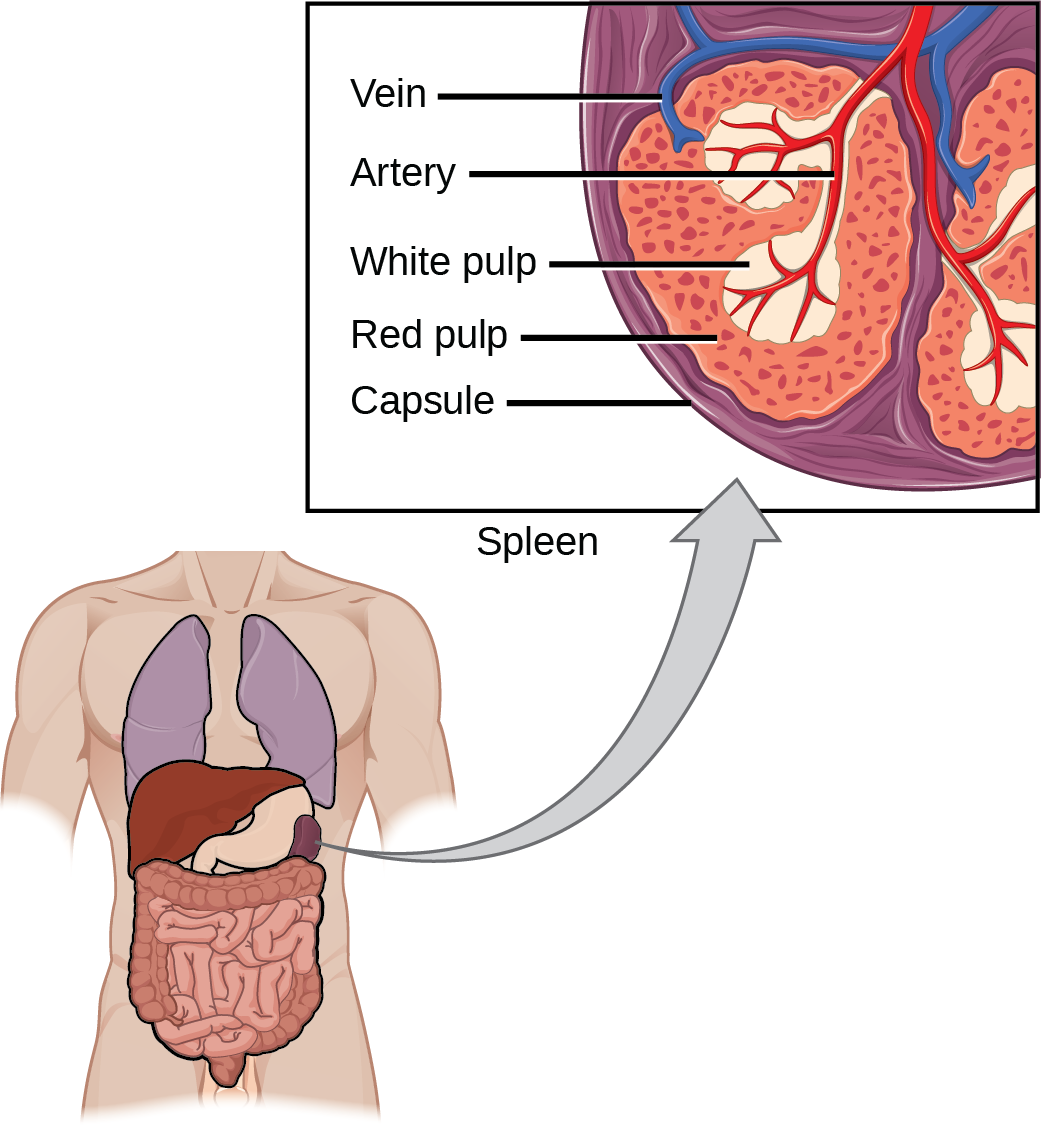
The adaptive immune response is a slower-acting, longer-lasting, and more specific response than the innate response. However, the adaptive response requires information from the innate immune system to function. APCs display antigens via MHC molecules to complementary naïve T cells. In response, the T cells differentiate and proliferate, becoming TH cells or CTLs. TH cells stimulate B cells that have engulfed and presented pathogen-derived antigens. B cells differentiate into plasma cells that secrete antibodies, whereas CTLs induce apoptosis in intracellularly infected or cancerous cells. Memory cells persist after a primary exposure to a pathogen. If reexposure occurs, memory cells differentiate into effector cells without input from the innate immune system. The mucosal immune system is largely independent from the systemic immune system but functions in a parallel fashion to protect the extensive mucosal surfaces of the body.
Exercises
Visual Connection Questions
Figure 15.11: Which of the following statements about T cells is false?
Figure 15.14: Based on what you know about MHC receptors, why do you think an organ transplanted from an incompatible donor to a recipient will be rejected?
Figure 15.16: The Rh antigen is found on Rh-positive red blood cells. An Rh-negative female can usually carry an Rh-positive fetus to term without difficulty. However, if she has a second Rh-positive fetus, her body may launch an immune attack that causes hemolytic disease of the newborn. Why do you think hemolytic disease is only a problem during the second or subsequent pregnancies?
Review Questions
Which of the following is both a phagocyte and an antigen-presenting cell?
Which immune cells bind MHC molecules on APCs via CD8 coreceptors on their cell surfaces?
What “self” pattern is identified by NK cells?
The acquired ability to prevent an unnecessary or destructive immune reaction to a harmless foreign particle, such as a food protein, is called ________.
A memory B cell can differentiate upon reexposure to a pathogen of which cell type?
Foreign particles circulating in the blood are filtered by the ________.
Critical Thinking Questions
Glossary
Chapter 42 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
An antibody, also known as an immunoglobulin (Ig), is a protein that is produced by plasma cells after stimulation by an antigen. Antibodies are the functional basis of humoral immunity. Antibodies occur in the blood, in gastric and mucus secretions, and in breast milk. Antibodies in these bodily fluids can bind pathogens and mark them for destruction by phagocytes before they can infect cells.
An antibody molecule is comprised of four polypeptides: two identical heavy chains (large peptide units) that are partially bound to each other in a “Y” formation, which are flanked by two identical light chains (small peptide units), as illustrated in Figure 15.22. Bonds between the cysteine amino acids in the antibody molecule attach the polypeptides to each other. The areas where the antigen is recognized on the antibody are variable domains and the antibody base is composed of constant domains.
In germ-line B cells, the variable region of the light chain gene has 40 variable (V) and five joining (J) segments. An enzyme called DNA recombinase randomly excises most of these segments out of the gene, and splices one V segment to one J segment. During RNA processing, all but one V and J segment are spliced out. Recombination and splicing may result in over 106 possible VJ combinations. As a result, each differentiated B cell in the human body typically has a unique variable chain. The constant domain, which does not bind antibody, is the same for all antibodies.
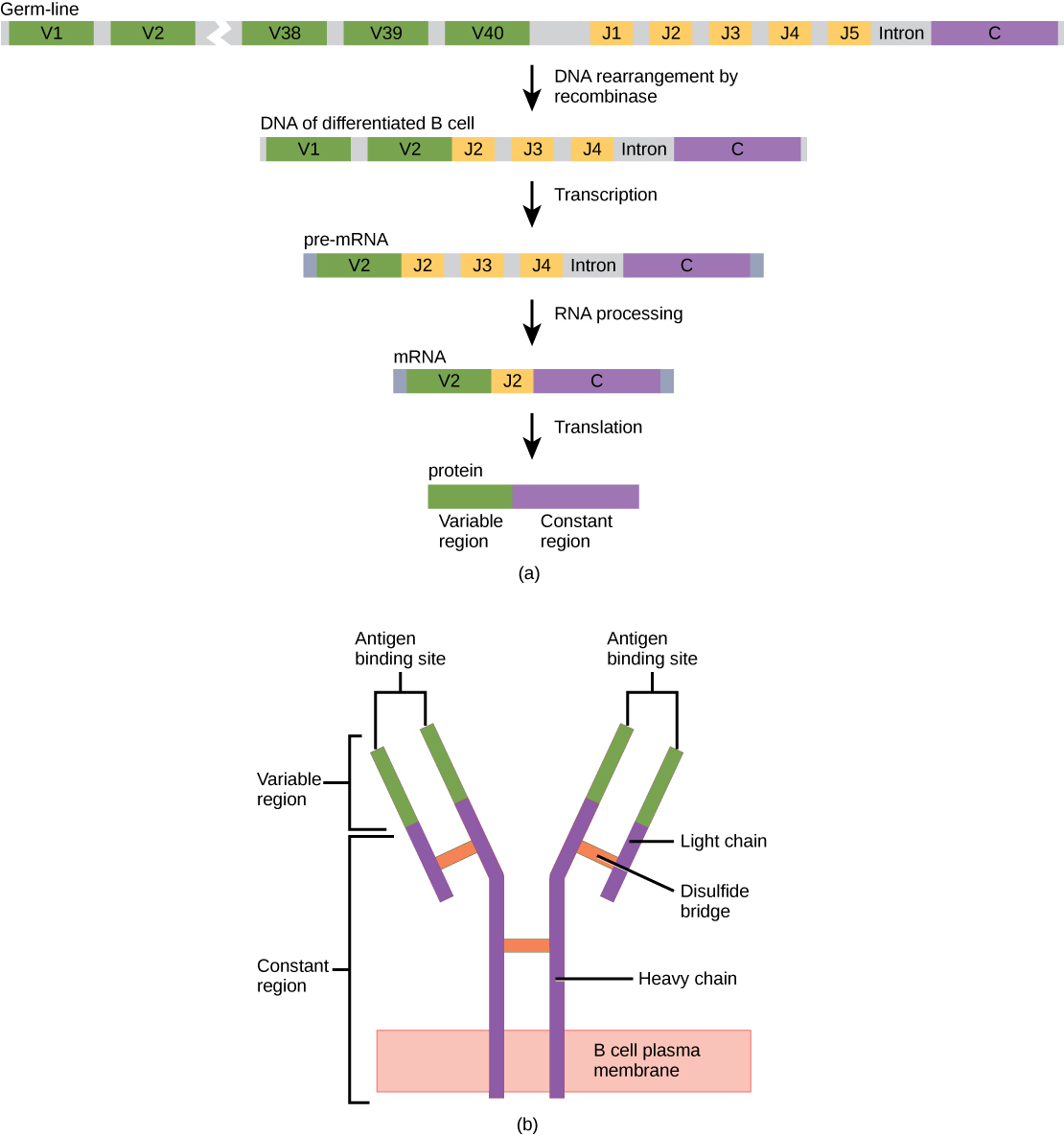
Similar to TCRs and BCRs, antibody diversity is produced by the mutation and recombination of approximately 300 different gene segments encoding the light and heavy chain variable domains in precursor cells that are destined to become B cells. The variable domains from the heavy and light chains interact to form the binding site through which an antibody can bind a specific epitope on an antigen. The numbers of repeated constant domains in Ig classes are the same for all antibodies corresponding to a specific class. Antibodies are structurally similar to the extracellular component of the BCRs, and B cell maturation to plasma cells can be visualized in simple terms as the cell acquires the ability to secrete the extracellular portion of its BCR in large quantities.
Antibodies can be divided into five classes—IgM, IgG, IgA, IgD, IgE—based on their physiochemical, structural, and immunological properties. IgGs, which make up about 80 percent of all antibodies, have heavy chains that consist of one variable domain and three identical constant domains. IgA and IgD also have three constant domains per heavy chain, whereas IgM and IgE each have four constant domains per heavy chain. The variable domain determines binding specificity and the constant domain of the heavy chain determines the immunological mechanism of action of the corresponding antibody class. It is possible for two antibodies to have the same binding specificities but be in different classes and, therefore, to be involved in different functions.
After an adaptive defense is produced against a pathogen, typically plasma cells first secrete IgM into the blood. BCRs on naïve B cells are of the IgM class and occasionally IgD class. IgM molecules make up approximately ten percent of all antibodies. Prior to antibody secretion, plasma cells assemble IgM molecules into pentamers (five individual antibodies) linked by a joining (J) chain, as shown in Figure 15.23. The pentamer arrangement means that these macromolecules can bind ten identical antigens. However, IgM molecules released early in the adaptive immune response do not bind to antigens as stably as IgGs, which are one of the possible types of antibodies secreted in large quantities upon reexposure to the same pathogen. Figure 15.23 summarizes the properties of immunoglobulins and illustrates their basic structures.
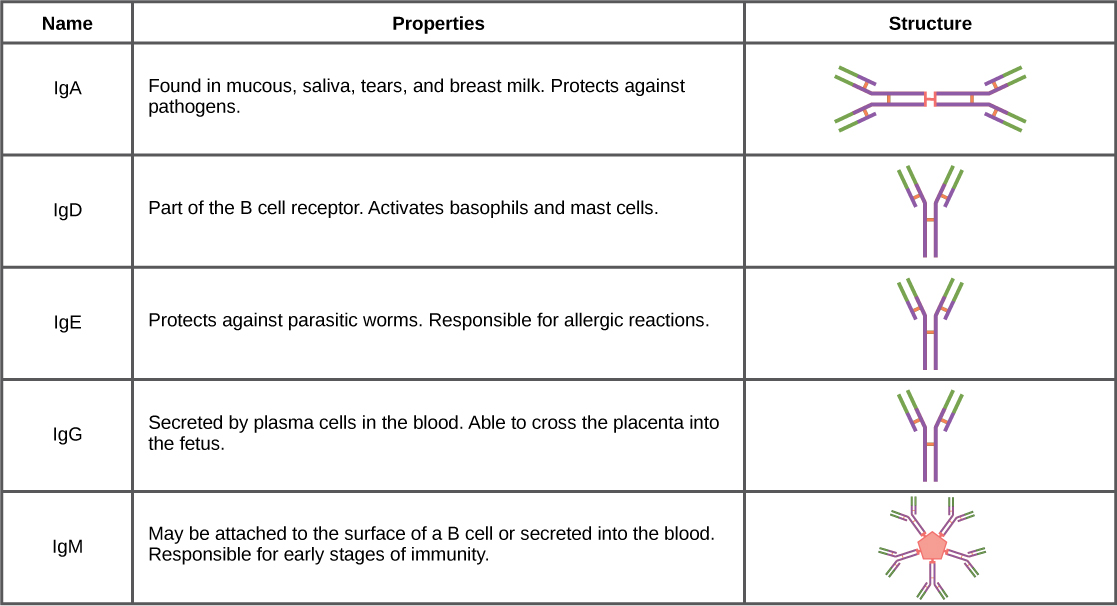
IgAs populate the saliva, tears, breast milk, and mucus secretions of the gastrointestinal, respiratory, and genitourinary tracts. Collectively, these bodily fluids coat and protect the extensive mucosa (4000 square feet in humans). The total number of IgA molecules in these bodily secretions is greater than the number of IgG molecules in the blood serum. A small amount of IgA is also secreted into the serum in monomeric form. Conversely, some IgM is secreted into bodily fluids of the mucosa. Similar to IgM, IgA molecules are secreted as polymeric structures linked with a J chain. However, IgAs are secreted mostly as dimeric molecules, not pentamers.
IgE is present in the serum in small quantities and is best characterized in its role as an allergy mediator. IgD is also present in small quantities. Similar to IgM, BCRs of the IgD class are found on the surface of naïve B cells. This class supports antigen recognition and maturation of B cells to plasma cells.
Differentiated plasma cells are crucial players in the humoral response, and the antibodies they secrete are particularly significant against extracellular pathogens and toxins. Antibodies circulate freely and act independently of plasma cells. Antibodies can be transferred from one individual to another to temporarily protect against infectious disease. For instance, a person who has recently produced a successful immune response against a particular disease agent can donate blood to a nonimmune recipient and confer temporary immunity through antibodies in the donor’s blood serum. This phenomenon is called passive immunity; it also occurs naturally during breastfeeding, which makes breastfed infants highly resistant to infections during the first few months of life.
Antibodies coat extracellular pathogens and neutralize them, as illustrated in Figure 15.24, by blocking key sites on the pathogen that enhance their infectivity (such as receptors that “dock” pathogens on host cells). Antibody neutralization can prevent pathogens from entering and infecting host cells, as opposed to the CTL-mediated approach of killing cells that are already infected to prevent progression of an established infection. The neutralized antibody-coated pathogens can then be filtered by the spleen and eliminated in urine or feces.
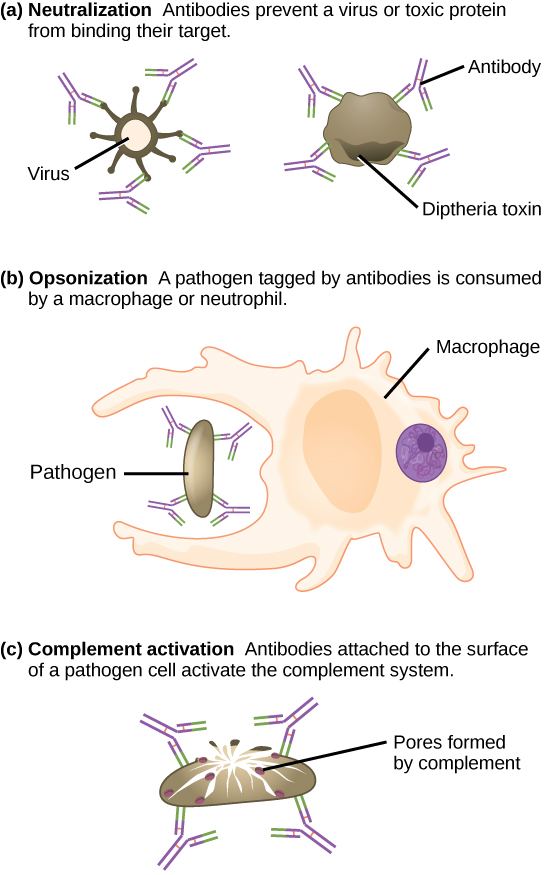
Antibodies also mark pathogens for destruction by phagocytic cells, such as macrophages or neutrophils, because phagocytic cells are highly attracted to macromolecules complexed with antibodies. Phagocytic enhancement by antibodies is called opsonization. In a process called complement fixation, IgM and IgG in serum bind to antigens and provide docking sites onto which sequential complement proteins can bind. The combination of antibodies and complement enhances opsonization even further and promotes rapid clearing of pathogens.
Not all antibodies bind with the same strength, specificity, and stability. In fact, antibodies exhibit different affinities (attraction) depending on the molecular complementarity between antigen and antibody molecules, as illustrated in Figure 15.25. An antibody with a higher affinity for a particular antigen would bind more strongly and stably, and thus would be expected to present a more challenging defense against the pathogen corresponding to the specific antigen.
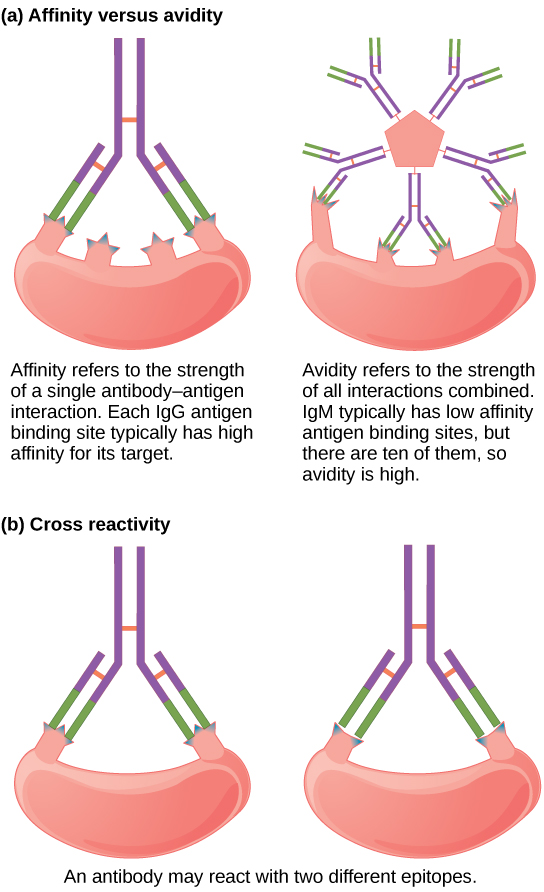
The term avidity describes binding by antibody classes that are secreted as joined, multivalent structures (such as IgM and IgA). Although avidity measures the strength of binding, just as affinity does, the avidity is not simply the sum of the affinities of the antibodies in a multimeric structure. The avidity depends on the number of identical binding sites on the antigen being detected, as well as other physical and chemical factors. Typically, multimeric antibodies, such as pentameric IgM, are classified as having lower affinity than monomeric antibodies, but high avidity. Essentially, the fact that multimeric antibodies can bind many antigens simultaneously balances their slightly lower binding strength for each antibody/antigen interaction.
Antibodies secreted after binding to one epitope on an antigen may exhibit cross reactivity for the same or similar epitopes on different antigens. Because an epitope corresponds to such a small region (the surface area of about four to six amino acids), it is possible for different macromolecules to exhibit the same molecular identities and orientations over short regions. Cross reactivity describes when an antibody binds not to the antigen that elicited its synthesis and secretion, but to a different antigen.
Cross reactivity can be beneficial if an individual develops immunity to several related pathogens despite having only been exposed to or vaccinated against one of them. For instance, antibody cross reactivity may occur against the similar surface structures of various Gram-negative bacteria. Conversely, antibodies raised against pathogenic molecular components that resemble self molecules may incorrectly mark host cells for destruction and cause autoimmune damage. Patients who develop systemic lupus erythematosus (SLE) commonly exhibit antibodies that react with their own DNA. These antibodies may have been initially raised against the nucleic acid of microorganisms but later cross-reacted with self-antigens. This phenomenon is also called molecular mimicry.
Antibodies synthesized by the mucosal immune system include IgA and IgM. Activated B cells differentiate into mucosal plasma cells that synthesize and secrete dimeric IgA, and to a lesser extent, pentameric IgM. Secreted IgA is abundant in tears, saliva, breast milk, and in secretions of the gastrointestinal and respiratory tracts. Antibody secretion results in a local humoral response at epithelial surfaces and prevents infection of the mucosa by binding and neutralizing pathogens.
Antibodies (immunoglobulins) are the molecules secreted from plasma cells that mediate the humoral immune response. There are five antibody classes; an antibody’s class determines its mechanism of action and production site but does not control its binding specificity. Antibodies bind antigens via variable domains and can either neutralize pathogens or mark them for phagocytosis or activate the complement cascade.
Exercises
Review Questions
The structure of an antibody is similar to the extracellular component of which receptor?
The first antibody class to appear in the serum in response to a newly encountered pathogen is ________.
What is the most abundant antibody class detected in the serum upon reexposure to a pathogen or in reaction to a vaccine?
Breastfed infants typically are resistant to disease because of ________.
Critical Thinking Questions
Glossary
Chapter 42 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
A functioning immune system is essential for survival, but even the sophisticated cellular and molecular defenses of the mammalian immune response can be defeated by pathogens at virtually every step. In the competition between immune protection and pathogen evasion, pathogens have the advantage of more rapid evolution because of their shorter generation time and other characteristics. For instance, Streptococcus pneumoniae (bacterium that cause pneumonia and meningitis) surrounds itself with a capsule that inhibits phagocytes from engulfing it and displaying antigens to the adaptive immune system. Staphylococcus aureus (bacterium that can cause skin infections, abscesses, and meningitis) synthesizes a toxin called leukocidin that kills phagocytes after they engulf the bacterium. Other pathogens can also hinder the adaptive immune system. HIV infects TH cells via their CD4 surface molecules, gradually depleting the number of TH cells in the body; this inhibits the adaptive immune system’s capacity to generate sufficient responses to infection or tumors. As a result, HIV-infected individuals often suffer from infections that would not cause illness in people with healthy immune systems but which can cause devastating illness to immune-compromised individuals. Maladaptive responses of immune cells and molecules themselves can also disrupt the proper functioning of the entire system, leading to host cell damage that could become fatal.
Failures, insufficiencies, or delays at any level of the immune response can allow pathogens or tumor cells to gain a foothold and replicate or proliferate to high enough levels that the immune system becomes overwhelmed. Immunodeficiency is the failure, insufficiency, or delay in the response of the immune system, which may be acquired or inherited. Immunodeficiency can be acquired as a result of infection with certain pathogens (such as HIV), chemical exposure (including certain medical treatments), malnutrition, or possibly by extreme stress. For instance, radiation exposure can destroy populations of lymphocytes and elevate an individual’s susceptibility to infections and cancer. Dozens of genetic disorders result in immunodeficiencies, including Severe Combined Immunodeficiency (SCID), Bare lymphocyte syndrome, and MHC II deficiencies. Rarely, primary immunodeficiencies that are present from birth may occur. Neutropenia is one form in which the immune system produces a below-average number of neutrophils, the body’s most abundant phagocytes. As a result, bacterial infections may go unrestricted in the blood, causing serious complications.
Maladaptive immune responses toward harmless foreign substances or self antigens that occur after tissue sensitization are termed hypersensitivities. The types of hypersensitivities include immediate, delayed, and autoimmunity. A large proportion of the population is affected by one or more types of hypersensitivity.
The immune reaction that results from immediate hypersensitivities in which an antibody-mediated immune response occurs within minutes of exposure to a harmless antigen is called an allergy. In the United States, 20 percent of the population exhibits symptoms of allergy or asthma, whereas 55 percent test positive against one or more allergens. Upon initial exposure to a potential allergen, an allergic individual synthesizes antibodies of the IgE class via the typical process of APCs presenting processed antigen to TH cells that stimulate B cells to produce IgE. This class of antibodies also mediates the immune response to parasitic worms. The constant domain of the IgE molecules interact with mast cells embedded in connective tissues. This process primes, or sensitizes, the tissue. Upon subsequent exposure to the same allergen, IgE molecules on mast cells bind the antigen via their variable domains and stimulate the mast cell to release the modified amino acids histamine and serotonin; these chemical mediators then recruit eosinophils which mediate allergic responses. Figure 15.26 shows an example of an allergic response to ragweed pollen. The effects of an allergic reaction range from mild symptoms like sneezing and itchy, watery eyes to more severe or even life-threatening reactions involving intensely itchy welts or hives, airway contraction with severe respiratory distress, and plummeting blood pressure. This extreme reaction is known as anaphylactic shock. If not treated with epinephrine to counter the blood pressure and breathing effects, this condition can be fatal.
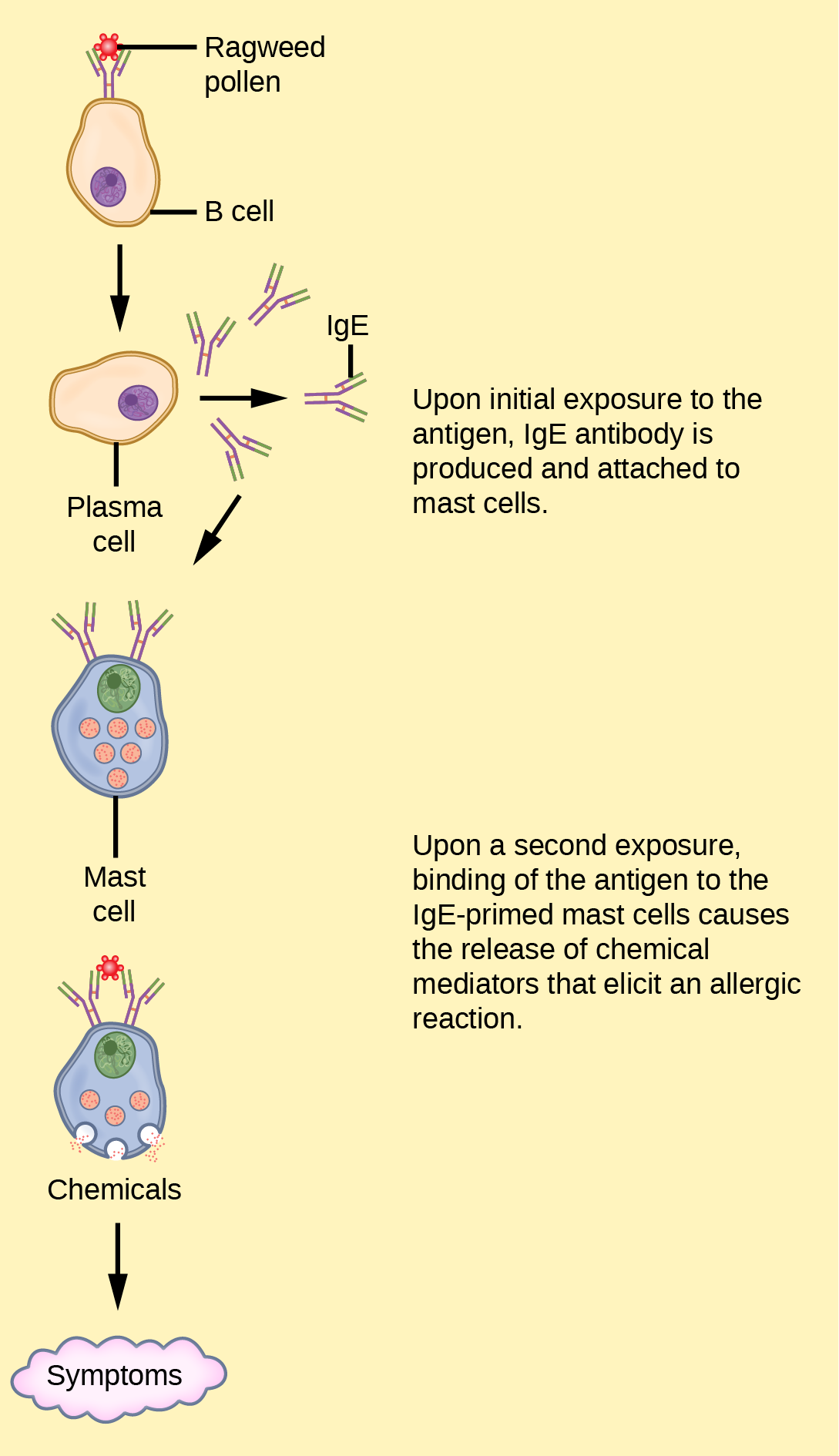
Delayed hypersensitivity is a cell-mediated immune response that takes approximately one to two days after secondary exposure for a maximal reaction to be observed. This type of hypersensitivity involves the TH1 cytokine-mediated inflammatory response and may manifest as local tissue lesions or contact dermatitis (rash or skin irritation). Delayed hypersensitivity occurs in some individuals in response to contact with certain types of jewelry or cosmetics. Delayed hypersensitivity facilitates the immune response to poison ivy and is also the reason why the skin test for tuberculosis results in a small region of inflammation on individuals who were previously exposed to Mycobacterium tuberculosis. That is also why cortisone is used to treat such responses: it will inhibit cytokine production.
Autoimmunity is a type of hypersensitivity to self antigens that affects approximately five percent of the population. Most types of autoimmunity involve the humoral immune response. Antibodies that inappropriately mark self components as foreign are termed autoantibodies. In patients with the autoimmune disease myasthenia gravis, muscle cell receptors that induce contraction in response to acetylcholine are targeted by antibodies. The result is muscle weakness that may include marked difficultly with fine and/or gross motor functions. In systemic lupus erythematosus, a diffuse autoantibody response to the individual’s own DNA and proteins results in various systemic diseases. As illustrated in Figure 15.27, systemic lupus erythematosus may affect the heart, joints, lungs, skin, kidneys, central nervous system, or other tissues, causing tissue damage via antibody binding, complement recruitment, lysis, and inflammation.
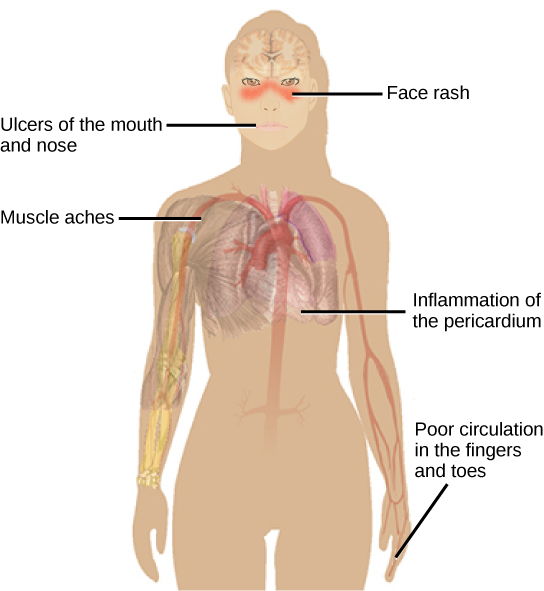
Autoimmunity can develop with time, and its causes may be rooted in molecular mimicry. Antibodies and TCRs may bind self antigens that are structurally similar to pathogen antigens, which the immune receptors first raised. As an example, infection with Streptococcus pyogenes (bacterium that causes strep throat) may generate antibodies or T cells that react with heart muscle, which has a similar structure to the surface of S. pyogenes. These antibodies can damage heart muscle with autoimmune attacks, leading to rheumatic fever. Insulin-dependent (Type 1) diabetes mellitus arises from a destructive inflammatory TH1 response against insulin-producing cells of the pancreas. Patients with this autoimmunity must be injected with insulin that originates from other sources.
Immune disruptions may involve insufficient immune responses or inappropriate immune targets. Immunodeficiency increases an individual’s susceptibility to infections and cancers. Hypersensitivities are misdirected responses either to harmless foreign particles, as in the case of allergies, or to host factors, as in the case of autoimmunity. Reactions to self components may be the result of molecular mimicry.
Exercises
Review Questions
Allergy to pollen is classified as:
A potential cause of acquired autoimmunity is ________.
Autoantibodies are probably involved in:
Which of the following diseases is not due to autoimmunity?
Glossary
Chapter 42 in OpenStax Concepts of Biology 2e

When you’re reading this book, your nervous system is performing several functions simultaneously. The visual system is processing what is seen on the page; the motor system controls the turn of the pages (or click of the mouse); the prefrontal cortex maintains attention. Even fundamental functions, like breathing and regulation of body temperature, are controlled by the nervous system. A nervous system is an organism’s control center: it processes sensory information from outside (and inside) the body and controls all behaviors—from eating to sleeping to finding a mate.
Chapter 35 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
Nervous systems throughout the animal kingdom vary in structure and complexity, as illustrated by the variety of animals shown in Figure 16.2. Some organisms, like sea sponges, lack a true nervous system. Others, like jellyfish, lack a true brain and instead have a system of separate but connected nerve cells (neurons) called a “nerve net.” Echinoderms such as sea stars have nerve cells that are bundled into fibers called nerves. Flatworms of the phylum Platyhelminthes have both a central nervous system (CNS), made up of a small “brain” and two nerve cords, and a peripheral nervous system (PNS) containing a system of nerves that extend throughout the body. The insect nervous system is more complex but also fairly decentralized. It contains a brain, ventral nerve cord, and ganglia (clusters of connected neurons). These ganglia can control movements and behaviors without input from the brain. Octopi may have the most complicated of invertebrate nervous systems—they have neurons that are organized in specialized lobes and eyes that are structurally similar to vertebrate species.
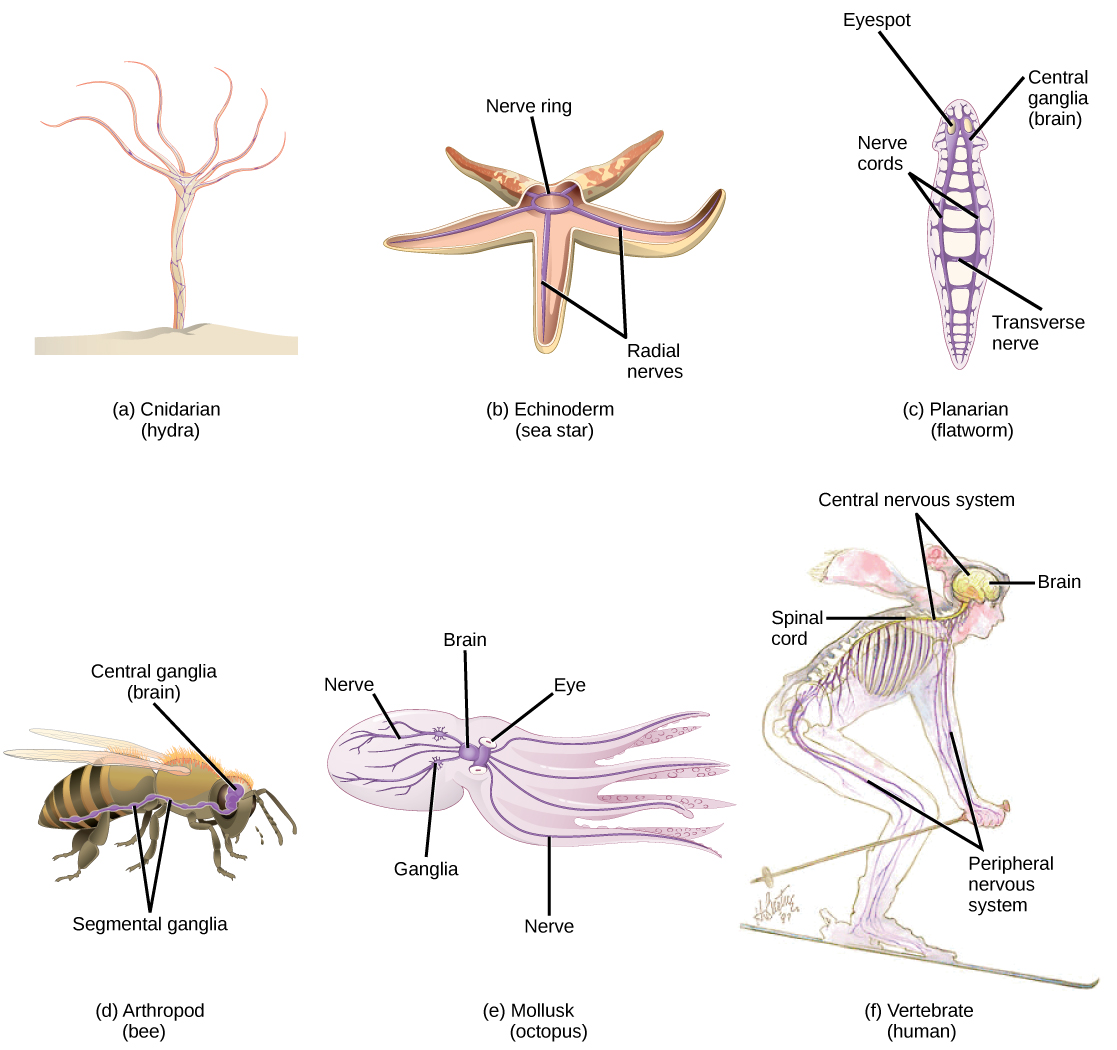
Compared to invertebrates, vertebrate nervous systems are more complex, centralized, and specialized. While there is great diversity among different vertebrate nervous systems, they all share a basic structure: a CNS that contains a brain and spinal cord and a PNS made up of peripheral sensory and motor nerves. One interesting difference between the nervous systems of invertebrates and vertebrates is that the nerve cords of many invertebrates are located ventrally whereas the vertebrate spinal cords are located dorsally. There is debate among evolutionary biologists as to whether these different nervous system plans evolved separately or whether the invertebrate body plan arrangement somehow “flipped” during the evolution of vertebrates.
Watch this video of biologist Mark Kirschner discussing the “flipping” phenomenon of vertebrate evolution.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=418
The nervous system is made up of neurons, specialized cells that can receive and transmit chemical or electrical signals, and glia, cells that provide support functions for the neurons by playing an information processing role that is complementary to neurons. A neuron can be compared to an electrical wire—it transmits a signal from one place to another. Glia can be compared to the workers at the electric company who make sure wires go to the right places, maintain the wires, and take down wires that are broken. Although glia have been compared to workers, recent evidence suggests that they also usurp some of the signaling functions of neurons.
There is great diversity in the types of neurons and glia that are present in different parts of the nervous system. There are four major types of neurons, and they share several important cellular components.
The nervous system of the common laboratory fly, Drosophila melanogaster, contains around 100,000 neurons, the same number as a lobster. This number compares to 75 million in the mouse and 300 million in the octopus. A human brain contains around 86 billion neurons. Despite these very different numbers, the nervous systems of these animals control many of the same behaviors—from basic reflexes to more complicated behaviors like finding food and courting mates. The ability of neurons to communicate with each other as well as with other types of cells underlies all of these behaviors.
Most neurons share the same cellular components. But neurons are also highly specialized—different types of neurons have different sizes and shapes that relate to their functional roles.
Like other cells, each neuron has a cell body (or soma) that contains a nucleus, smooth and rough endoplasmic reticulum, Golgi apparatus, mitochondria, and other cellular components. Neurons also contain unique structures, illustrated in Figure 16.3 for receiving and sending the electrical signals that make neuronal communication possible. Dendrites are tree-like structures that extend away from the cell body to receive messages from other neurons at specialized junctions called synapses. Although some neurons do not have any dendrites, some types of neurons have multiple dendrites. Dendrites can have small protrusions called dendritic spines, which further increase surface area for possible synaptic connections.
Once a signal is received by the dendrite, it then travels passively to the cell body. The cell body contains a specialized structure, the axon hillock that integrates signals from multiple synapses and serves as a junction between the cell body and an axon. An axon is a tube-like structure that propagates the integrated signal to specialized endings called axon terminals. These terminals in turn synapse on other neurons, muscle, or target organs. Chemicals released at axon terminals allow signals to be communicated to these other cells. Neurons usually have one or two axons, but some neurons, like amacrine cells in the retina, do not contain any axons. Some axons are covered with myelin, which acts as an insulator to minimize dissipation of the electrical signal as it travels down the axon, greatly increasing the speed of conduction. This insulation is important as the axon from a human motor neuron can be as long as a meter—from the base of the spine to the toes. The myelin sheath is not actually part of the neuron. Myelin is produced by glial cells. Along the axon there are periodic gaps in the myelin sheath. These gaps are called nodes of Ranvier and are sites where the signal is “recharged” as it travels along the axon.
It is important to note that a single neuron does not act alone—neuronal communication depends on the connections that neurons make with one another (as well as with other cells, like muscle cells). Dendrites from a single neuron may receive synaptic contact from many other neurons. For example, dendrites from a Purkinje cell in the cerebellum are thought to receive contact from as many as 200,000 other neurons.
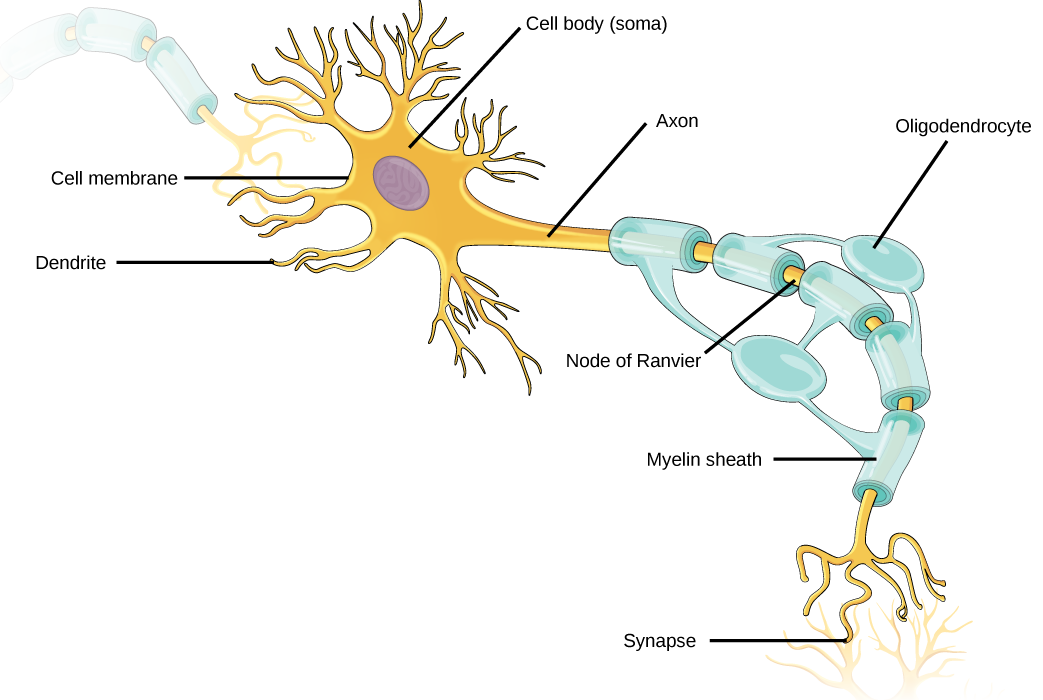
Which of the following statements is false?
There are different types of neurons, and the functional role of a given neuron is intimately dependent on its structure. There is an amazing diversity of neuron shapes and sizes found in different parts of the nervous system (and across species), as illustrated by the neurons shown in Figure 16.4.

While there are many defined neuron cell subtypes, neurons are broadly divided into four basic types: unipolar, bipolar, multipolar, and pseudounipolar. Figure 16.5 illustrates these four basic neuron types. Unipolar neurons have only one structure that extends away from the soma. These neurons are not found in vertebrates but are found in insects where they stimulate muscles or glands. A bipolar neuron has one axon and one dendrite extending from the soma. An example of a bipolar neuron is a retinal bipolar cell, which receives signals from photoreceptor cells that are sensitive to light and transmits these signals to ganglion cells that carry the signal to the brain. Multipolar neurons are the most common type of neuron. Each multipolar neuron contains one axon and multiple dendrites. Multipolar neurons can be found in the central nervous system (brain and spinal cord). An example of a multipolar neuron is a Purkinje cell in the cerebellum, which has many branching dendrites but only one axon. Pseudounipolar cells share characteristics with both unipolar and bipolar cells. A pseudounipolar cell has a single process that extends from the soma, like a unipolar cell, but this process later branches into two distinct structures, like a bipolar cell. Most sensory neurons are pseudounipolar and have an axon that branches into two extensions: one connected to dendrites that receive sensory information and another that transmits this information to the spinal cord.
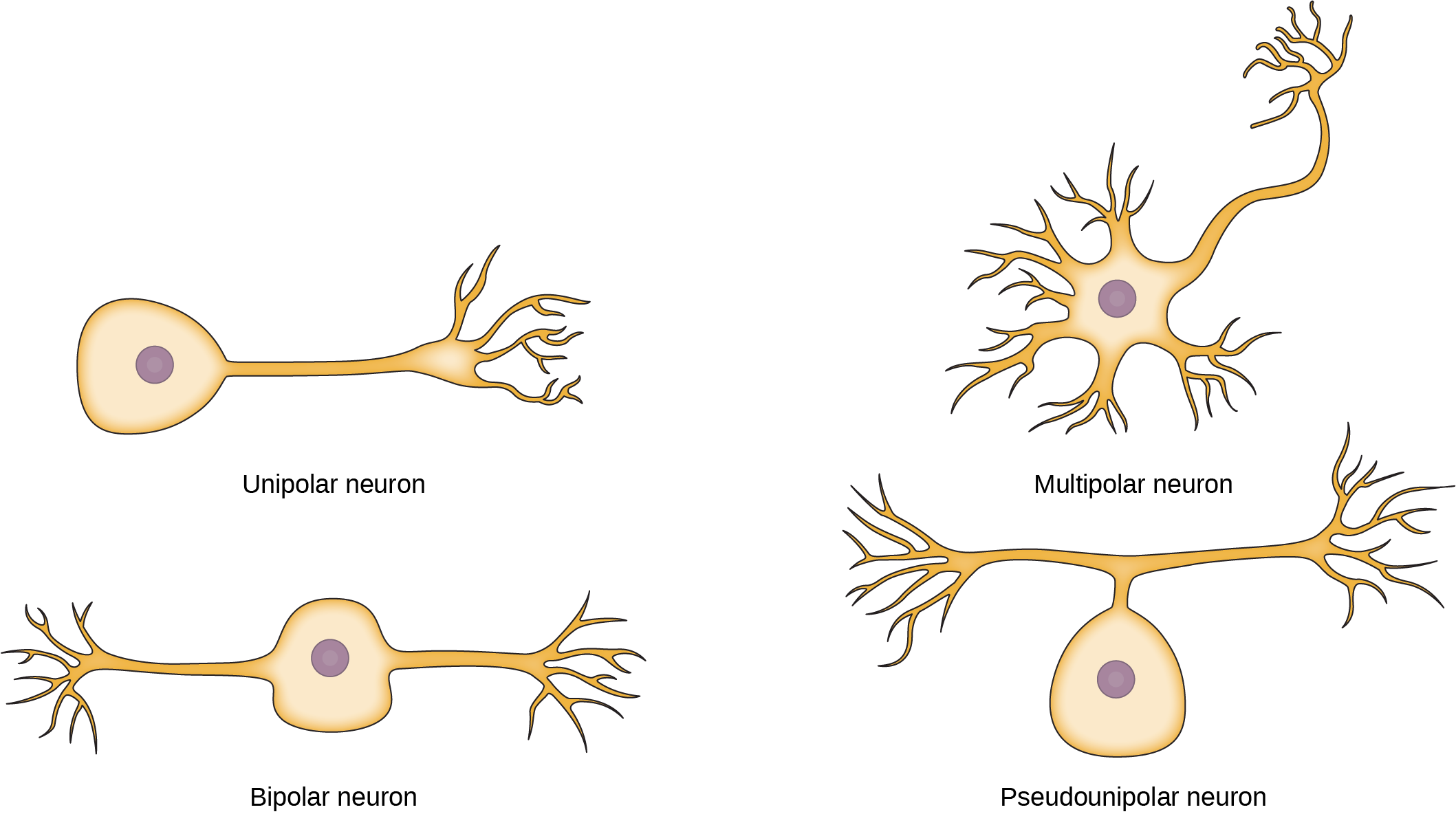
At one time, scientists believed that people were born with all the neurons they would ever have. Research performed during the last few decades indicates that neurogenesis, the birth of new neurons, continues into adulthood. Neurogenesis was first discovered in songbirds that produce new neurons while learning songs. For mammals, new neurons also play an important role in learning: about 1000 new neurons develop in the hippocampus (a brain structure involved in learning and memory) each day. While most of the new neurons will die, researchers found that an increase in the number of surviving new neurons in the hippocampus correlated with how well rats learned a new task. Interestingly, both exercise and some antidepressant medications also promote neurogenesis in the hippocampus. Stress has the opposite effect. While neurogenesis is quite limited compared to regeneration in other tissues, research in this area may lead to new treatments for disorders such as Alzheimer’s, stroke, and epilepsy.
How do scientists identify new neurons? A researcher can inject a compound called bromodeoxyuridine (BrdU) into the brain of an animal. While all cells will be exposed to BrdU, BrdU will only be incorporated into the DNA of newly generated cells that are in S phase. A technique called immunohistochemistry can be used to attach a fluorescent label to the incorporated BrdU, and a researcher can use fluorescent microscopy to visualize the presence of BrdU, and thus new neurons, in brain tissue. Figure 16.6 is a micrograph which shows fluorescently labeled neurons in the hippocampus of a rat.
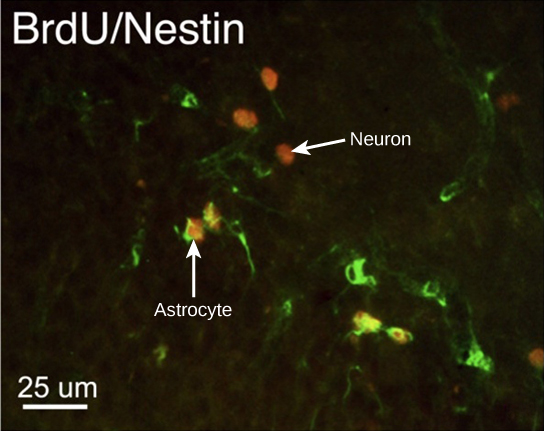
The Wellesley College Biology website contains more information about neurogenesis, including an interactive laboratory simulation and a video that explains how BrdU labels new cells.
While glia are often thought of as the supporting cast of the nervous system, the number of glial cells in the brain actually outnumbers the number of neurons by a factor of ten. Neurons would be unable to function without the vital roles that are fulfilled by these glial cells. Glia guide developing neurons to their destinations, buffer ions and chemicals that would otherwise harm neurons, and provide myelin sheaths around axons. Scientists have recently discovered that they also play a role in responding to nerve activity and modulating communication between nerve cells. When glia do not function properly, the result can be disastrous—most brain tumors are caused by mutations in glia.
There are several different types of glia with different functions, two of which are shown in Figure 16.7. Astrocytes, shown in (Figure)16.8a make contact with both capillaries and neurons in the CNS. They provide nutrients and other substances to neurons, regulate the concentrations of ions and chemicals in the extracellular fluid, and provide structural support for synapses. Astrocytes also form the blood-brain barrier—a structure that blocks entrance of toxic substances into the brain. Astrocytes, in particular, have been shown through calcium imaging experiments to become active in response to nerve activity, transmit calcium waves between astrocytes, and modulate the activity of surrounding synapses. Satellite glia provide nutrients and structural support for neurons in the PNS. Microglia scavenge and degrade dead cells and protect the brain from invading microorganisms. Oligodendrocytes, shown in Figure 16.8b form myelin sheaths around axons in the CNS. One axon can be myelinated by several oligodendrocytes, and one oligodendrocyte can provide myelin for multiple neurons. This is distinctive from the PNS where a single Schwann cell provides myelin for only one axon as the entire Schwann cell surrounds the axon. Radial glia serve as scaffolds for developing neurons as they migrate to their end destinations. Ependymal cells line fluid-filled ventricles of the brain and the central canal of the spinal cord. They are involved in the production of cerebrospinal fluid, which serves as a cushion for the brain, moves the fluid between the spinal cord and the brain, and is a component for the choroid plexus.
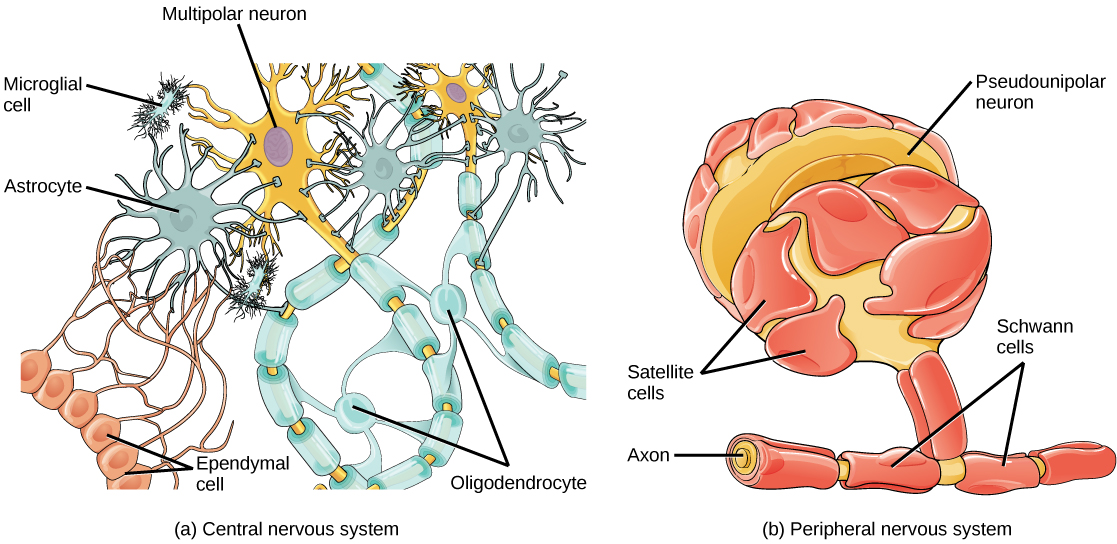
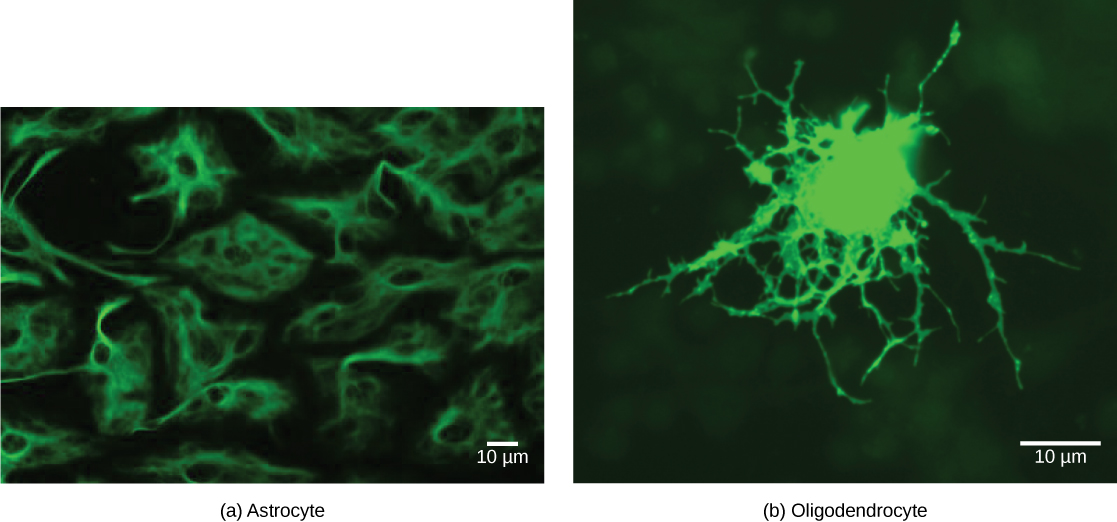
The nervous system is made up of neurons and glia. Neurons are specialized cells that are capable of sending electrical as well as chemical signals. Most neurons contain dendrites, which receive these signals, and axons that send signals to other neurons or tissues. There are four main types of neurons: unipolar, bipolar, multipolar, and pseudounipolar neurons. Glia are non-neuronal cells in the nervous system that support neuronal development and signaling. There are several types of glia that serve different functions.
Exercises
Visual Connection Questions
Figure 16.3: Which of the following statements is false?
Review Questions
Neurons contain ________, which can receive signals from other neurons.
A(n) ________ neuron has one axon and one dendrite extending directly from the cell body.
Glia that provide myelin for neurons in the brain are called ________.
Meningitis is a viral or bacterial infection of the brain. Which cell type is the first to have its function disrupted during meningitis?
Critical Thinking Questions
Glossary
Chapter 35 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
All functions performed by the nervous system—from a simple motor reflex to more advanced functions like making a memory or a decision—require neurons to communicate with one another. While humans use words and body language to communicate, neurons use electrical and chemical signals. Just like a person in a committee, one neuron usually receives and synthesizes messages from multiple other neurons before “making the decision” to send the message on to other neurons.
For the nervous system to function, neurons must be able to send and receive signals. These signals are possible because each neuron has a charged cellular membrane (a voltage difference between the inside and the outside), and the charge of this membrane can change in response to neurotransmitter molecules released from other neurons and environmental stimuli. To understand how neurons communicate, one must first understand the basis of the baseline or ‘resting’ membrane charge.
The lipid bilayer membrane that surrounds a neuron is impermeable to charged molecules or ions. To enter or exit the neuron, ions must pass through special proteins called ion channels that span the membrane. Ion channels have different configurations: open, closed, and inactive, as illustrated in Figure 16.9. Some ion channels need to be activated in order to open and allow ions to pass into or out of the cell. These ion channels are sensitive to the environment and can change their shape accordingly. Ion channels that change their structure in response to voltage changes are called voltage-gated ion channels. Voltage-gated ion channels regulate the relative concentrations of different ions inside and outside the cell. The difference in total charge between the inside and outside of the cell is called the membrane potential.
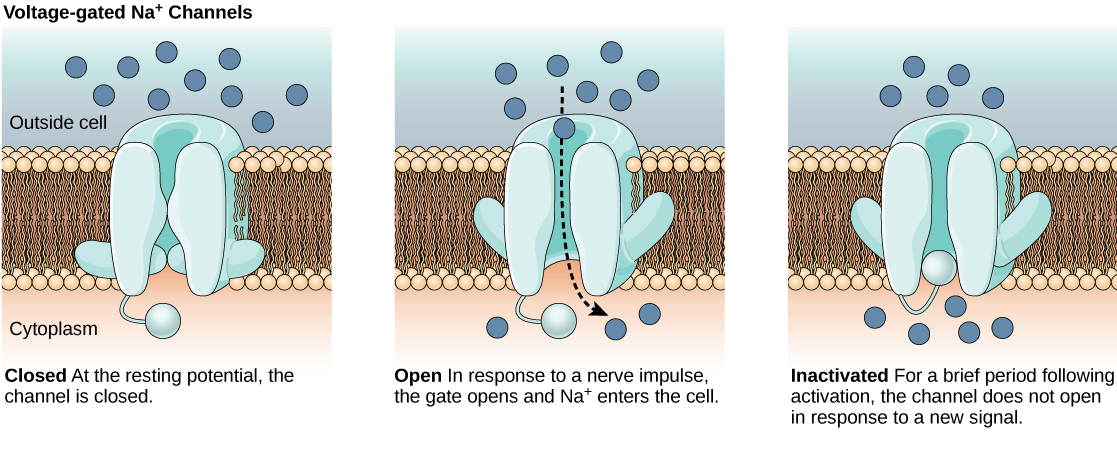
This video discusses the basis of the resting membrane potential.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=430
A neuron at rest is negatively charged: the inside of a cell is approximately 70 millivolts more negative than the outside (−70 mV, note that this number varies by neuron type and by species). This voltage is called the resting membrane potential; it is caused by differences in the concentrations of ions inside and outside the cell. If the membrane were equally permeable to all ions, each type of ion would flow across the membrane and the system would reach equilibrium. Because ions cannot simply cross the membrane at will, there are different concentrations of several ions inside and outside the cell, as shown in Table 16.1. The difference in the number of positively charged potassium ions (K+) inside and outside the cell dominates the resting membrane potential (Figure 16.10). When the membrane is at rest, K+ ions accumulate inside the cell due to a net movement with the concentration gradient. The negative resting membrane potential is created and maintained by increasing the concentration of cations outside the cell (in the extracellular fluid) relative to inside the cell (in the cytoplasm). The negative charge within the cell is created by the cell membrane being more permeable to potassium ion movement than sodium ion movement. In neurons, potassium ions are maintained at high concentrations within the cell while sodium ions are maintained at high concentrations outside of the cell. The cell possesses potassium and sodium leakage channels that allow the two cations to diffuse down their concentration gradient. However, the neurons have far more potassium leakage channels than sodium leakage channels. Therefore, potassium diffuses out of the cell at a much faster rate than sodium leaks in. Because more cations are leaving the cell than are entering, this causes the interior of the cell to be negatively charged relative to the outside of the cell. The actions of the sodium potassium pump help to maintain the resting potential, once established. Recall that sodium potassium pumps brings two K+ ions into the cell while removing three Na+ ions per ATP consumed. As more cations are expelled from the cell than taken in, the inside of the cell remains negatively charged relative to the extracellular fluid. It should be noted that chloride ions (Cl–) tend to accumulate outside of the cell because they are repelled by negatively-charged proteins within the cytoplasm.
| Ion Concentration Inside and Outside Neurons | |||
|---|---|---|---|
| Ion | Extracellular concentration (mM) | Intracellular concentration (mM) | Ratio outside/inside |
| Na+ | 145 | 12 | 12 |
| K+ | 4 | 155 | 0.026 |
| Cl− | 120 | 4 | 30 |
| Organic anions (A−) | — | 100 | |
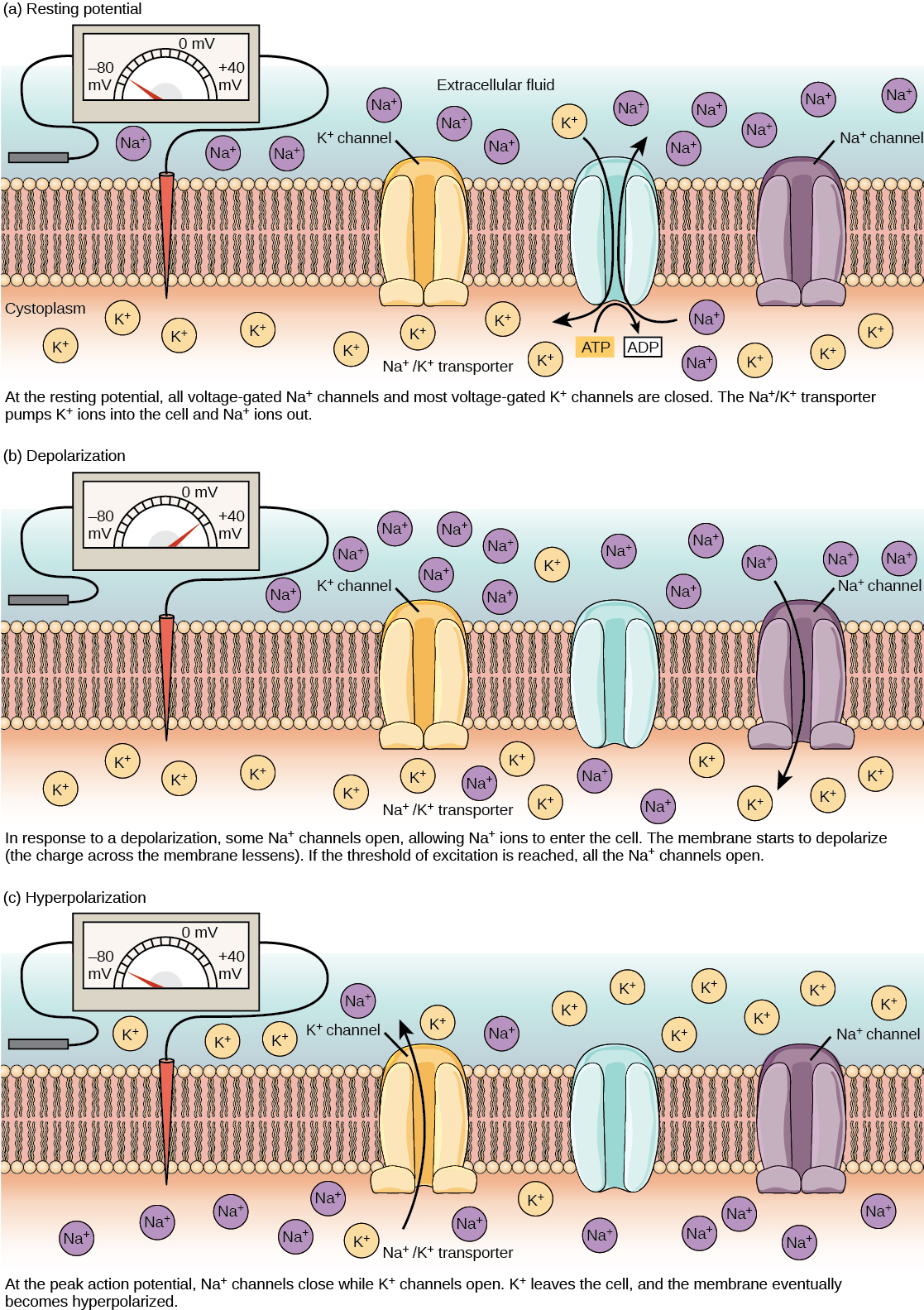
A neuron can receive input from other neurons and, if this input is strong enough, send the signal to downstream neurons. Transmission of a signal between neurons is generally carried by a chemical called a neurotransmitter. Transmission of a signal within a neuron (from dendrite to axon terminal) is carried by a brief reversal of the resting membrane potential called an action potential. When neurotransmitter molecules bind to receptors located on a neuron’s dendrites, ion channels open. At excitatory synapses, this opening allows positive ions to enter the neuron and results in depolarization of the membrane—a decrease in the difference in voltage between the inside and outside of the neuron. A stimulus from a sensory cell or another neuron depolarizes the target neuron to its threshold potential (-55 mV). Na+ channels in the axon hillock open, allowing positive ions to enter the cell (Figure 16.10 and Figure 16.11). Once the sodium channels open, the neuron completely depolarizes to a membrane potential of about +40 mV. Action potentials are considered an “all-or nothing” event, in that, once the threshold potential is reached, the neuron always completely depolarizes. Once depolarization is complete, the cell must now “reset” its membrane voltage back to the resting potential. To accomplish this, the Na+ channels close and cannot be opened. This begins the neuron’s refractory period, in which it cannot produce another action potential because its sodium channels will not open. At the same time, voltage-gated K+ channels open, allowing K+ to leave the cell. As K+ ions leave the cell, the membrane potential once again becomes negative. The diffusion of K+ out of the cell actually hyperpolarizes the cell, in that the membrane potential becomes more negative than the cell’s normal resting potential. At this point, the sodium channels will return to their resting state, meaning they are ready to open again if the membrane potential again exceeds the threshold potential. Eventually the extra K+ ions diffuse out of the cell through the potassium leakage channels, bringing the cell from its hyperpolarized state, back to its resting membrane potential.
Visual Connection
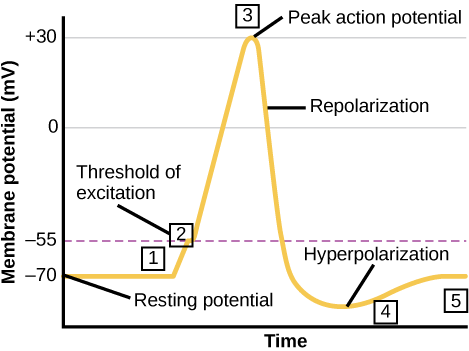
Potassium channel blockers, such as amiodarone and procainamide, which are used to treat abnormal electrical activity in the heart, called cardiac dysrhythmia, impede the movement of K+ through voltage-gated K+ channels. Which part of the action potential would you expect potassium channels to affect?
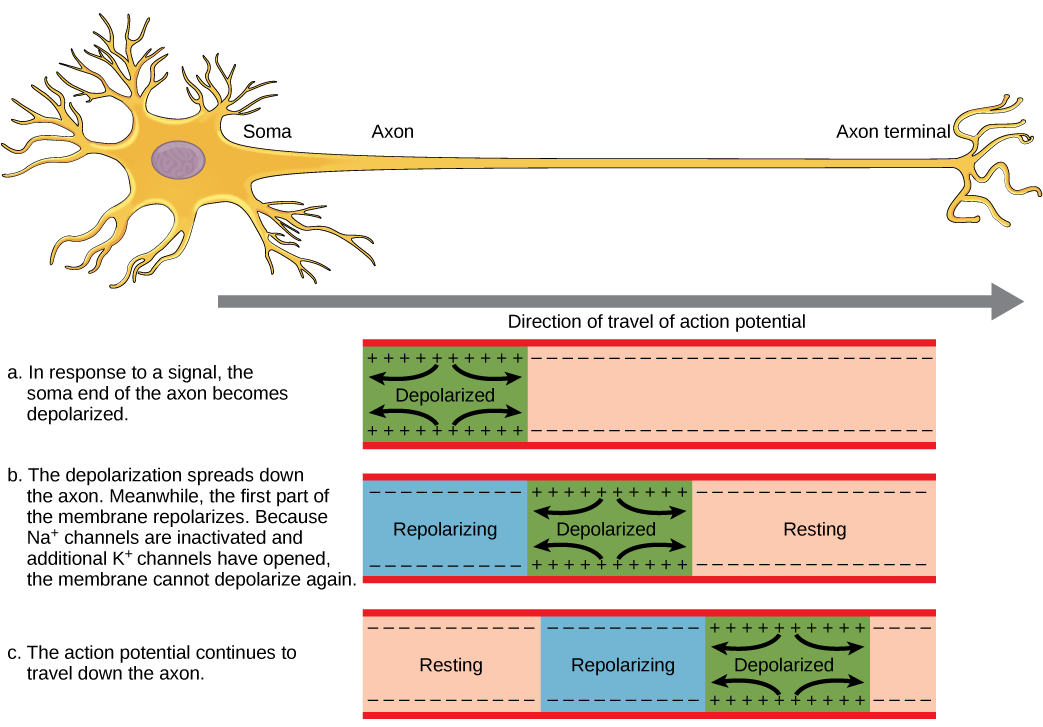
For an action potential to communicate information to another neuron, it must travel along the axon and reach the axon terminals where it can initiate neurotransmitter release. The speed of conduction of an action potential along an axon is influenced by both the diameter of the axon and the axon’s resistance to current leak. Myelin acts as an insulator that prevents current from leaving the axon; this increases the speed of action potential conduction. In demyelinating diseases like multiple sclerosis, action potential conduction slows because current leaks from previously insulated axon areas. The nodes of Ranvier, illustrated in Figure 16.13 are gaps in the myelin sheath along the axon. These unmyelinated spaces are about one micrometer long and contain voltage-gated Na+ and K+ channels. Flow of ions through these channels, particularly the Na+ channels, regenerates the action potential over and over again along the axon. This ‘jumping’ of the action potential from one node to the next is called saltatory conduction. If nodes of Ranvier were not present along an axon, the action potential would propagate very slowly since Na+ and K+ channels would have to continuously regenerate action potentials at every point along the axon instead of at specific points. Nodes of Ranvier also save energy for the neuron since the channels only need to be present at the nodes and not along the entire axon.
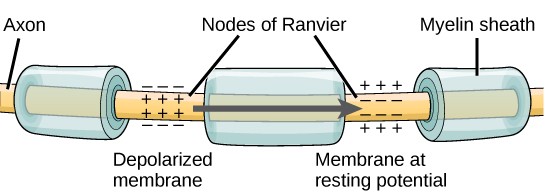
The synapse or “gap” is the place where information is transmitted from one neuron to another. Synapses usually form between axon terminals and dendritic spines, but this is not universally true. There are also axon-to-axon, dendrite-to-dendrite, and axon-to-cell body synapses. The neuron transmitting the signal is called the presynaptic neuron, and the neuron receiving the signal is called the postsynaptic neuron. Note that these designations are relative to a particular synapse—most neurons are both presynaptic and postsynaptic. There are two types of synapses: chemical and electrical.
When an action potential reaches the axon terminal it depolarizes the membrane and opens voltage-gated Na+ channels. Na+ ions enter the cell, further depolarizing the presynaptic membrane. This depolarization causes voltage-gated Ca2+ channels to open. Calcium ions entering the cell initiate a signaling cascade that causes small membrane-bound vesicles, called synaptic vesicles, containing neurotransmitter molecules to fuse with the presynaptic membrane. Synaptic vesicles are shown in Figure 16.14, which is an image from a scanning electron microscope.
Fusion of a vesicle with the presynaptic membrane causes neurotransmitter to be released into the synaptic cleft, the extracellular space between the presynaptic and postsynaptic membranes, as illustrated in Figure 16.15. The neurotransmitter diffuses across the synaptic cleft and binds to receptor proteins on the postsynaptic membrane.
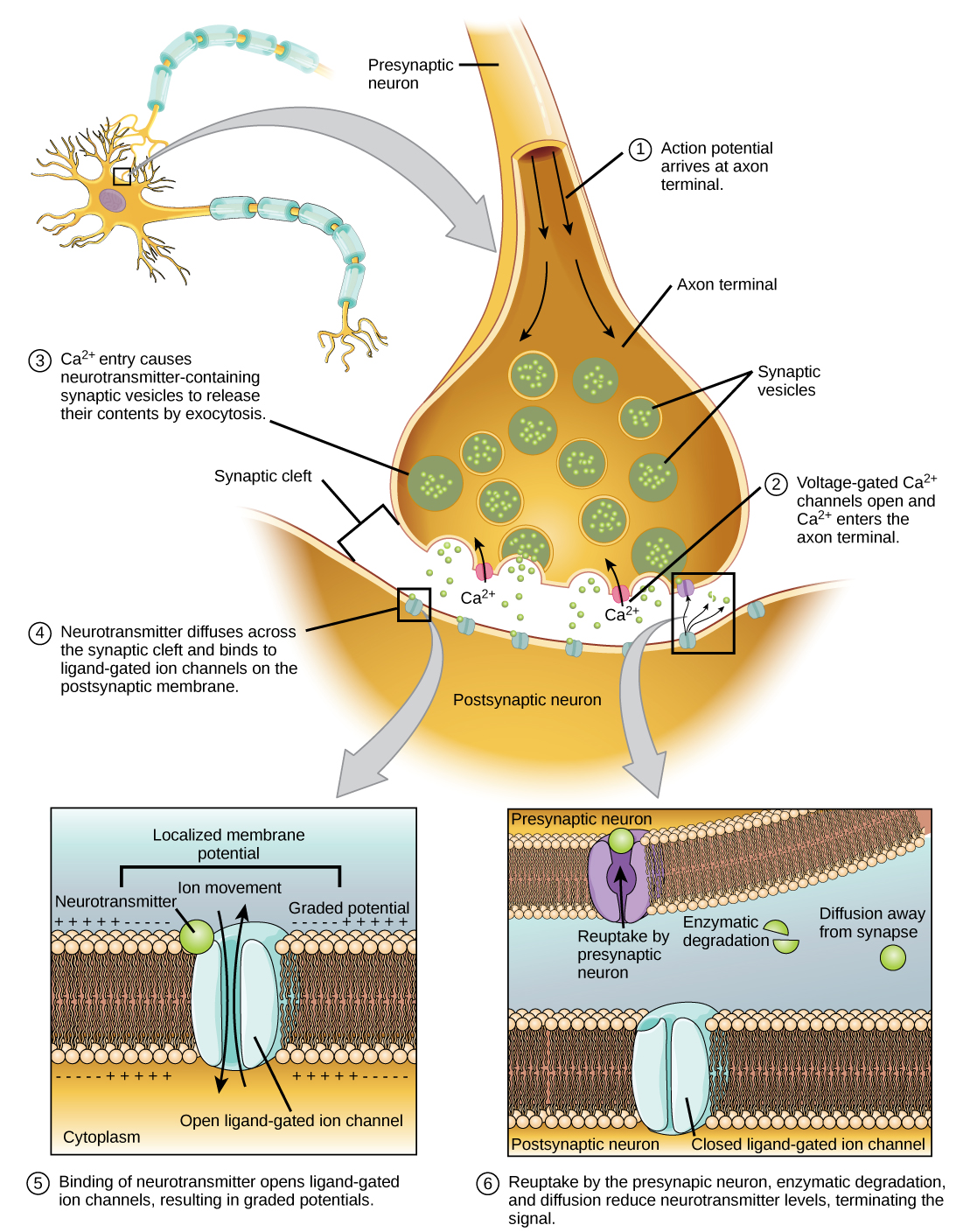
The binding of a specific neurotransmitter causes particular ion channels, in this case ligand-gated channels, on the postsynaptic membrane to open. Neurotransmitters can either have excitatory or inhibitory effects on the postsynaptic membrane. For example, when acetylcholine is released at the synapse between a nerve and muscle (called the neuromuscular junction) by a presynaptic neuron, it causes postsynaptic Na+ channels to open. Na+ enters the postsynaptic cell and causes the postsynaptic membrane to depolarize. This depolarization is called an excitatory postsynaptic potential (EPSP) and makes the postsynaptic neuron more likely to fire an action potential. Release of neurotransmitter at inhibitory synapses causes inhibitory postsynaptic potentials (IPSPs), a hyperpolarization of the presynaptic membrane. For example, when the neurotransmitter GABA (gamma-aminobutyric acid) is released from a presynaptic neuron, it binds to and opens Cl– channels. Cl– ions enter the cell and hyperpolarizes the membrane, making the neuron less likely to fire an action potential.
Once neurotransmission has occurred, the neurotransmitter must be removed from the synaptic cleft so the postsynaptic membrane can “reset” and be ready to receive another signal. This can be accomplished in three ways: the neurotransmitter can diffuse away from the synaptic cleft, it can be degraded by enzymes in the synaptic cleft, or it can be recycled (sometimes called reuptake) by the presynaptic neuron. Several drugs act at this step of neurotransmission. For example, some drugs that are given to Alzheimer’s patients work by inhibiting acetylcholinesterase, the enzyme that degrades acetylcholine. This inhibition of the enzyme essentially increases neurotransmission at synapses that release acetylcholine. Once released, the acetylcholine stays in the cleft and can continually bind and unbind to postsynaptic receptors.
| Table 16.2 Neurotransmitter Function and Location | ||
|---|---|---|
| Neurotransmitter | Example | Location |
| Acetylcholine | — | CNS and/or PNS |
| Biogenic amine | Dopamine, serotonin, norepinephrine | CNS and/or PNS |
| Amino acid | Glycine, glutamate, aspartate, gamma aminobutyric acid | CNS |
| Neuropeptide | Substance P, endorphins | CNS and/or PNS |
While electrical synapses are fewer in number than chemical synapses, they are found in all nervous systems and play important and unique roles. The mode of neurotransmission in electrical synapses is quite different from that in chemical synapses. In an electrical synapse, the presynaptic and postsynaptic membranes are very close together and are actually physically connected by channel proteins forming gap junctions. Gap junctions allow current to pass directly from one cell to the next. In addition to the ions that carry this current, other molecules, such as ATP, can diffuse through the large gap junction pores.
There are key differences between chemical and electrical synapses. Because chemical synapses depend on the release of neurotransmitter molecules from synaptic vesicles to pass on their signal, there is an approximately one millisecond delay between when the axon potential reaches the presynaptic terminal and when the neurotransmitter leads to opening of postsynaptic ion channels. Additionally, this signaling is unidirectional. Signaling in electrical synapses, in contrast, is virtually instantaneous (which is important for synapses involved in key reflexes), and some electrical synapses are bidirectional. Electrical synapses are also more reliable as they are less likely to be blocked, and they are important for synchronizing the electrical activity of a group of neurons. For example, electrical synapses in the thalamus are thought to regulate slow-wave sleep, and disruption of these synapses can cause seizures.
Sometimes a single EPSP is strong enough to induce an action potential in the postsynaptic neuron, but often multiple presynaptic inputs must create EPSPs around the same time for the postsynaptic neuron to be sufficiently depolarized to fire an action potential. This process is called summation and occurs at the axon hillock, as illustrated in Figure 16.16. Additionally, one neuron often has inputs from many presynaptic neurons—some excitatory and some inhibitory—so IPSPs can cancel out EPSPs and vice versa. It is the net change in postsynaptic membrane voltage that determines whether the postsynaptic cell has reached its threshold of excitation needed to fire an action potential. Together, synaptic summation and the threshold for excitation act as a filter so that random “noise” in the system is not transmitted as important information.
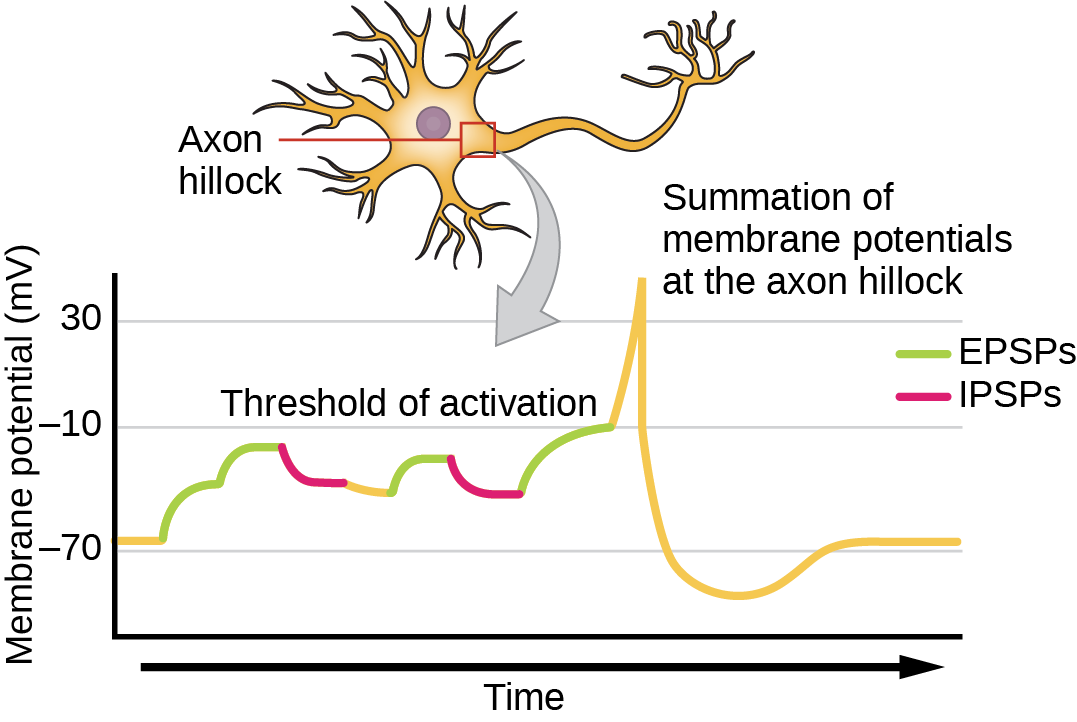
Amyotrophic lateral sclerosis (ALS, also called Lou Gehrig’s Disease) is a neurological disease characterized by the degeneration of the motor neurons that control voluntary movements. The disease begins with muscle weakening and lack of coordination and eventually destroys the neurons that control speech, breathing, and swallowing; in the end, the disease can lead to paralysis. At that point, patients require assistance from machines to be able to breathe and to communicate. Several special technologies have been developed to allow “locked-in” patients to communicate with the rest of the world. One technology, for example, allows patients to type out sentences by twitching their cheek. These sentences can then be read aloud by a computer.
A relatively new line of research for helping paralyzed patients, including those with ALS, to communicate and retain a degree of self-sufficiency is called brain-computer interface (BCI) technology and is illustrated in Figure 16.17. This technology sounds like something out of science fiction: it allows paralyzed patients to control a computer using only their thoughts. There are several forms of BCI. Some forms use EEG recordings from electrodes taped onto the skull. These recordings contain information from large populations of neurons that can be decoded by a computer. Other forms of BCI require the implantation of an array of electrodes smaller than a postage stamp in the arm and hand area of the motor cortex. This form of BCI, while more invasive, is very powerful as each electrode can record actual action potentials from one or more neurons. These signals are then sent to a computer, which has been trained to decode the signal and feed it to a tool—such as a cursor on a computer screen. This means that a patient with ALS can use e-mail, read the Internet, and communicate with others by thinking of moving his or her hand or arm (even though the paralyzed patient cannot make that bodily movement). Recent advances have allowed a paralyzed locked-in patient who suffered a stroke 15 years ago to control a robotic arm and even to feed herself coffee using BCI technology.
Despite the amazing advancements in BCI technology, it also has limitations. The technology can require many hours of training and long periods of intense concentration for the patient; it can also require brain surgery to implant the devices.
Watch this Nature video in which a paralyzed woman uses a brain-controlled robotic arm to bring a drink to her mouth, among other images of brain-computer interface technology in action.
An interactive or media element has been excluded from this version of the text. You can view it online here: https://pressbooks.nscc.ca/conceptsofbiologynscc/?p=430
Long-term potentiation (LTP) is a persistent strengthening of a synaptic connection. LTP is based on the Hebbian principle: cells that fire together wire together. There are various mechanisms, none fully understood, behind the synaptic strengthening seen with LTP. One known mechanism involves a type of postsynaptic glutamate receptor, called NMDA (N-Methyl-D-aspartate) receptors, shown in Figure 16.18. These receptors are normally blocked by magnesium ions; however, when the postsynaptic neuron is depolarized by multiple presynaptic inputs in quick succession (either from one neuron or multiple neurons), the magnesium ions are forced out allowing Ca ions to pass into the postsynaptic cell. Next, Ca2+ ions entering the cell initiate a signaling cascade that causes a different type of glutamate receptor, called AMPA (α-amino-3-hydroxy-5-methyl-4-isoxazolepropionic acid) receptors, to be inserted into the postsynaptic membrane, since activated AMPA receptors allow positive ions to enter the cell. So, the next time glutamate is released from the presynaptic membrane, it will have a larger excitatory effect (EPSP) on the postsynaptic cell because the binding of glutamate to these AMPA receptors will allow more positive ions into the cell. The insertion of additional AMPA receptors strengthens the synapse and means that the postsynaptic neuron is more likely to fire in response to presynaptic neurotransmitter release. Some drugs of abuse co-opt the LTP pathway, and this synaptic strengthening can lead to addiction.
Long-term depression (LTD) is essentially the reverse of LTP: it is a long-term weakening of a synaptic connection. One mechanism known to cause LTD also involves AMPA receptors. In this situation, calcium that enters through NMDA receptors initiates a different signaling cascade, which results in the removal of AMPA receptors from the postsynaptic membrane, as illustrated in Figure 16.18. The decrease in AMPA receptors in the membrane makes the postsynaptic neuron less responsive to glutamate released from the presynaptic neuron. While it may seem counterintuitive, LTD may be just as important for learning and memory as LTP. The weakening and pruning of unused synapses allows for unimportant connections to be lost and makes the synapses that have undergone LTP that much stronger by comparison.
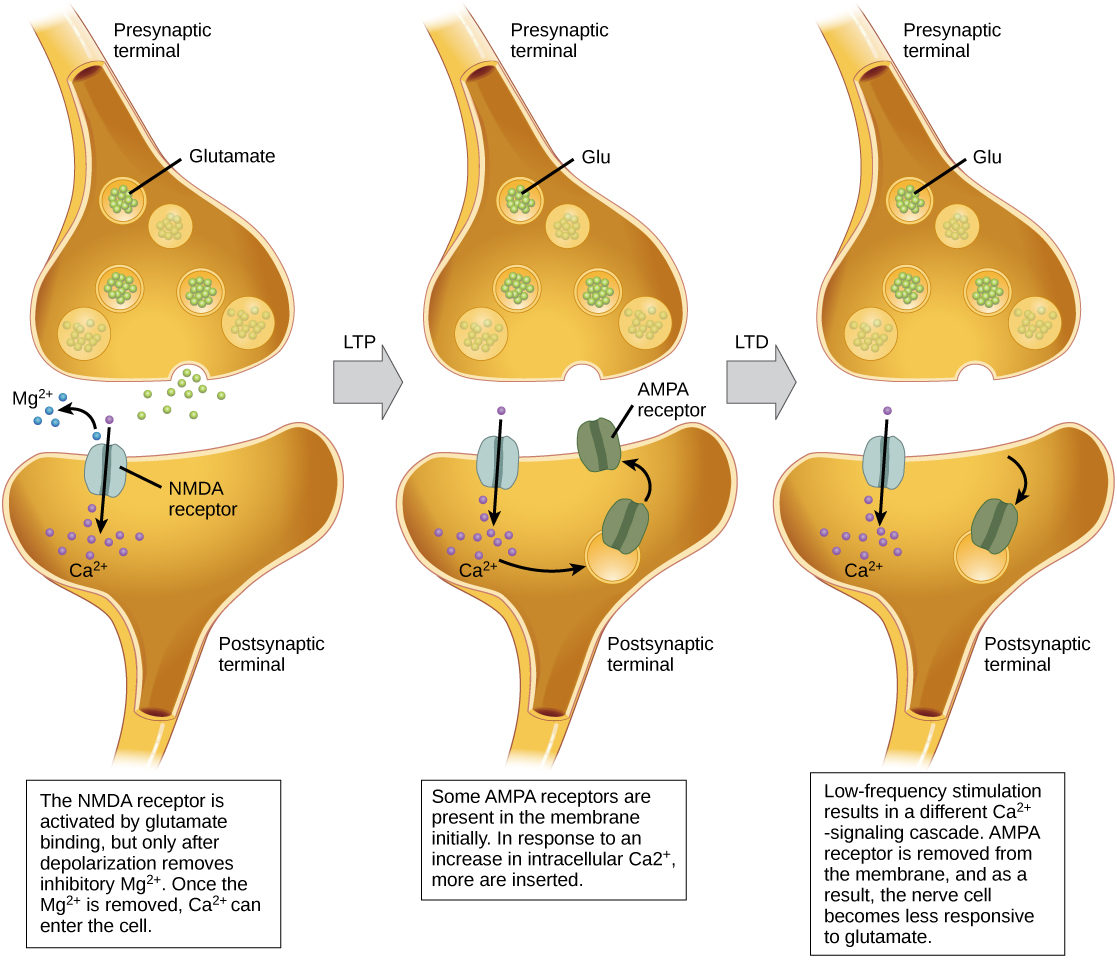
Neurons have charged membranes because there are different concentrations of ions inside and outside of the cell. Voltage-gated ion channels control the movement of ions into and out of a neuron. When a neuronal membrane is depolarized to at least the threshold of excitation, an action potential is fired. The action potential is then propagated along a myelinated axon to the axon terminals. In a chemical synapse, the action potential causes release of neurotransmitter molecules into the synaptic cleft. Through binding to postsynaptic receptors, the neurotransmitter can cause excitatory or inhibitory postsynaptic potentials by depolarizing or hyperpolarizing, respectively, the postsynaptic membrane. In electrical synapses, the action potential is directly communicated to the postsynaptic cell through gap junctions—large channel proteins that connect the pre-and postsynaptic membranes. Synapses are not static structures and can be strengthened and weakened. Two mechanisms of synaptic plasticity are long-term potentiation and long-term depression.
Exercises
Visual Connection Questions
Figure 16.x: Potassium channel blockers, such as amiodarone and procainamide, which are used to treat abnormal electrical activity in the heart, called cardiac dysrhythmia, impede the movement of K+ through voltage-gated K+ channels. Which part of the action potential would you expect potassium channels to affect?
Review Questions
For a neuron to fire an action potential, its membrane must reach ________.
After an action potential, the opening of additional voltage-gated ________ channels and the inactivation of sodium channels, cause the membrane to return to its resting membrane potential.
What is the term for protein channels that connect two neurons at an electrical synapse?
Which of the following molecules is not involved in the maintenance of the resting membrane potential?
Critical Thinking Questions
Glossary
Chapter 35 in OpenStax Concepts of Biology 2e.
Learning Objectives
By the end of this section, you will be able to do the following:
The central nervous system (CNS) is made up of the brain, a part of which is shown in Figure 16.19 and spinal cord and is covered with three layers of protective coverings called meninges (from the Greek word for membrane). The outermost layer is the dura mater (Latin for “hard mother”). As the Latin suggests, the primary function for this thick layer is to protect the brain and spinal cord. The dura mater also contains vein-like structures that carry blood from the brain back to the heart. The middle layer is the web-like arachnoid mater. The last layer is the pia mater (Latin for “soft mother”), which directly contacts and covers the brain and spinal cord like plastic wrap. The space between the arachnoid and pia maters is filled with cerebrospinal fluid (CSF). CSF is produced by a tissue called choroid plexus in fluid-filled compartments in the CNS called ventricles. The brain floats in CSF, which acts as a cushion and shock absorber and makes the brain neutrally buoyant. CSF also functions to circulate chemical substances throughout the brain and into the spinal cord.
The entire brain contains only about 8.5 tablespoons of CSF, but CSF is constantly produced in the ventricles. This creates a problem when a ventricle is blocked—the CSF builds up and creates swelling and the brain is pushed against the skull. This swelling condition is called hydrocephalus (“water head”) and can cause seizures, cognitive problems, and even death if a shunt is not inserted to remove the fluid and pressure.
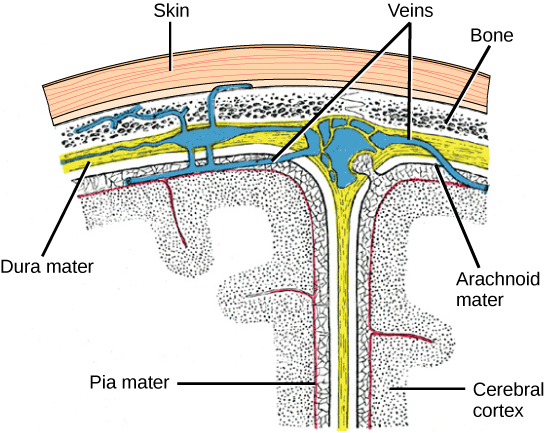
The brain is the part of the central nervous system that is contained in the cranial cavity of the skull. It includes the cerebral cortex, limbic system, basal ganglia, thalamus, hypothalamus, and cerebellum. There are three different ways that a brain can be sectioned in order to view internal structures: a sagittal section cuts the brain left to right, as shown in Figure 16.20b, a coronal section cuts the brain front to back, as shown in Figure 16.21a, and a horizontal section cuts the brain top to bottom.
The outermost part of the brain is a thick piece of nervous system tissue called the cerebral cortex, which is folded into hills called gyri (singular: gyrus) and valleys called sulci (singular: sulcus). The cortex is made up of two hemispheres—right and left—which are separated by a large sulcus. A thick fiber bundle called the corpus callosum (Latin: “tough body”) connects the two hemispheres and allows information to be passed from one side to the other. Although there are some brain functions that are localized more to one hemisphere than the other, the functions of the two hemispheres are largely redundant. In fact, sometimes (very rarely) an entire hemisphere is removed to treat severe epilepsy. While patients do suffer some deficits following the surgery, they can have surprisingly few problems, especially when the surgery is performed on children who have very immature nervous systems.
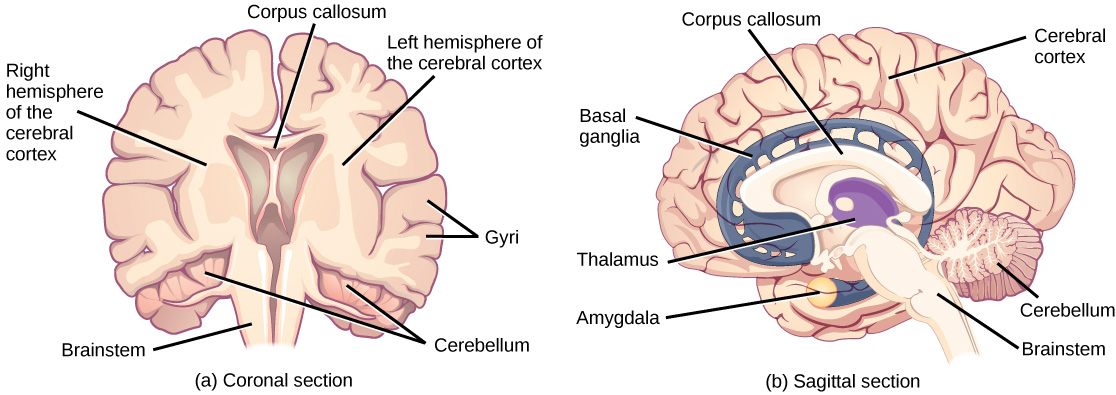
In other surgeries to treat severe epilepsy, the corpus callosum is cut instead of removing an entire hemisphere. This causes a condition called split-brain, which gives insights into unique functions of the two hemispheres. For example, when an object is presented to patients’ left visual field, they may be unable to verbally name the object (and may claim to not have seen an object at all). This is because the visual input from the left visual field crosses and enters the right hemisphere and cannot then signal to the speech center, which generally is found in the left side of the brain. Remarkably, if a split-brain patient is asked to pick up a specific object out of a group of objects with the left hand, the patient will be able to do so but will still be unable to vocally identify it.
See this website to learn more about split-brain patients and to play a game where you can model the split-brain experiments yourself.
Each cortical hemisphere contains regions called lobes that are involved in different functions. Scientists use various techniques to determine what brain areas are involved in different functions: they examine patients who have had injuries or diseases that affect specific areas and see how those areas are related to functional deficits. They also conduct animal studies where they stimulate brain areas and see if there are any behavioral changes. They use a technique called transmagnetic stimulation (TMS) to temporarily deactivate specific parts of the cortex using strong magnets placed outside the head; and they use functional magnetic resonance imaging (fMRI) to look at changes in oxygenated blood flow in particular brain regions that correlate with specific behavioral tasks. These techniques, and others, have given great insight into the functions of different brain regions but have also showed that any given brain area can be involved in more than one behavior or process, and any given behavior or process generally involves neurons in multiple brain areas. That being said, each hemisphere of the mammalian cerebral cortex can be broken down into four functionally and spatially defined lobes: frontal, parietal, temporal, and occipital. Figure 16.21 illustrates these four lobes of the human cerebral cortex.
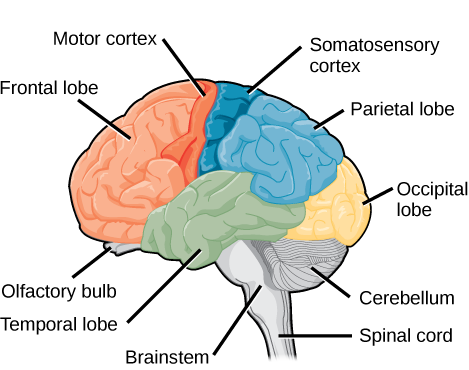
The frontal lobe is located at the front of the brain, over the eyes. This lobe contains the olfactory bulb, which processes smells. The frontal lobe also contains the motor cortex, which is important for planning and implementing movement. Areas within the motor cortex map to different muscle groups, and there is some organization to this map, as shown in Figure 16.22. For example, the neurons that control movement of the fingers are next to the neurons that control movement of the hand. Neurons in the frontal lobe also control cognitive functions like maintaining attention, speech, and decision-making. Studies of humans who have damaged their frontal lobes show that parts of this area are involved in personality, socialization, and assessing risk.
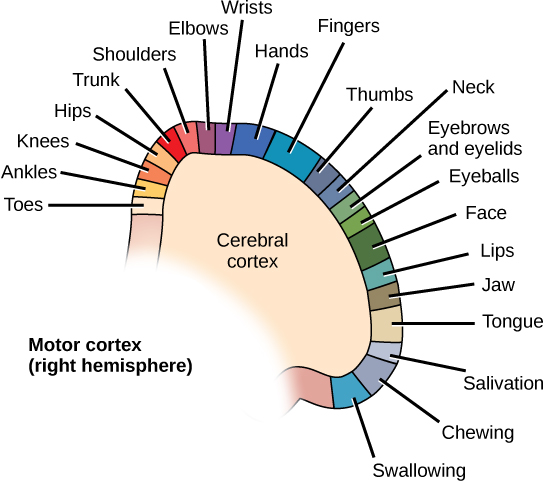
The parietal lobe is located at the top of the brain. Neurons in the parietal lobe are involved in speech and also reading. Two of the parietal lobe’s main functions are processing somatosensation—touch sensations like pressure, pain, heat, cold—and processing proprioception—the sense of how parts of the body are oriented in space. The parietal lobe contains a somatosensory map of the body similar to the motor cortex.
The occipital lobe is located at the back of the brain. It is primarily involved in vision—seeing, recognizing, and identifying the visual world.
The temporal lobe is located at the base of the brain by your ears and is primarily involved in processing and interpreting sounds. It also contains the hippocampus (Greek for “seahorse”)—a structure that processes memory formation. The hippocampus is illustrated in (Figure). The role of the hippocampus in memory was partially determined by studying one famous epileptic patient, HM, who had both sides of his hippocampus removed in an attempt to cure his epilepsy. His seizures went away, but he could no longer form new memories (although he could remember some facts from before his surgery and could learn new motor tasks).
Compared to other vertebrates, mammals have exceptionally large brains for their body size. An entire alligator’s brain, for example, would fill about one and a half teaspoons. This increase in brain to body size ratio is especially pronounced in apes, whales, and dolphins. While this increase in overall brain size doubtlessly played a role in the evolution of complex behaviors unique to mammals, it does not tell the whole story. Scientists have found a relationship between the relatively high surface area of the cortex and the intelligence and complex social behaviors exhibited by some mammals. This increased surface area is due, in part, to increased folding of the cortical sheet (more sulci and gyri). For example, a rat cortex is very smooth with very few sulci and gyri. Cat and sheep cortices have more sulci and gyri. Chimps, humans, and dolphins have even more.
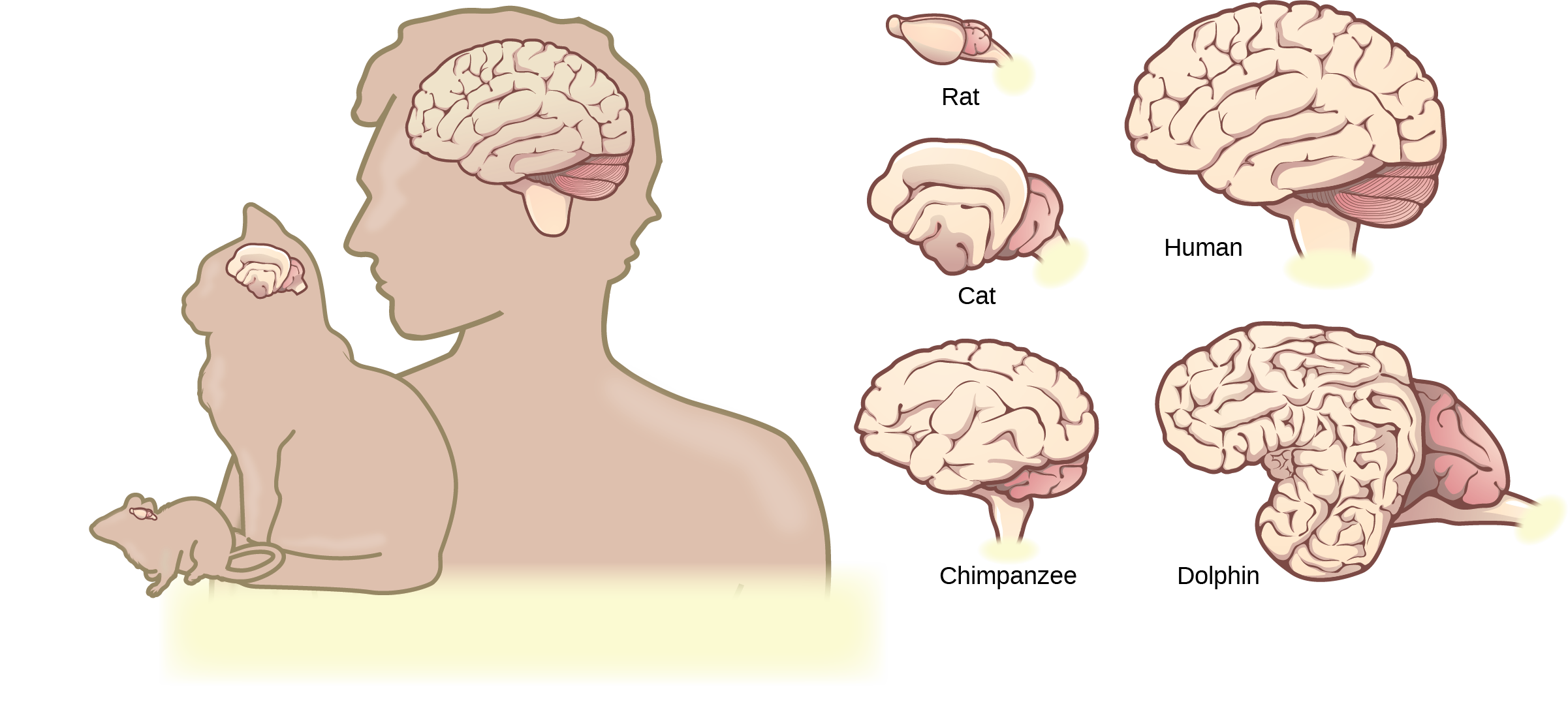
Interconnected brain areas called the basal ganglia (or basal nuclei), shown in (igure 16.20b, play important roles in movement control and posture. Damage to the basal ganglia, as in Parkinson’s disease, leads to motor impairments like a shuffling gait when walking. The basal ganglia also regulate motivation. For example, when a wasp sting led to bilateral basal ganglia damage in a 25-year-old businessman, he began to spend all his days in bed and showed no interest in anything or anybody. But when he was externally stimulated—as when someone asked to play a card game with him—he was able to function normally. Interestingly, he and other similar patients do not report feeling bored or frustrated by their state.
The thalamus (Greek for “inner chamber”), illustrated in Figure 16.24, acts as a gateway to and from the cortex. It receives sensory and motor inputs from the body and also receives feedback from the cortex. This feedback mechanism can modulate conscious awareness of sensory and motor inputs depending on the attention and arousal state of the animal. The thalamus helps regulate consciousness, arousal, and sleep states. A rare genetic disorder called fatal familial insomnia causes the degeneration of thalamic neurons and glia. This disorder prevents affected patients from being able to sleep, among other symptoms, and is eventually fatal.
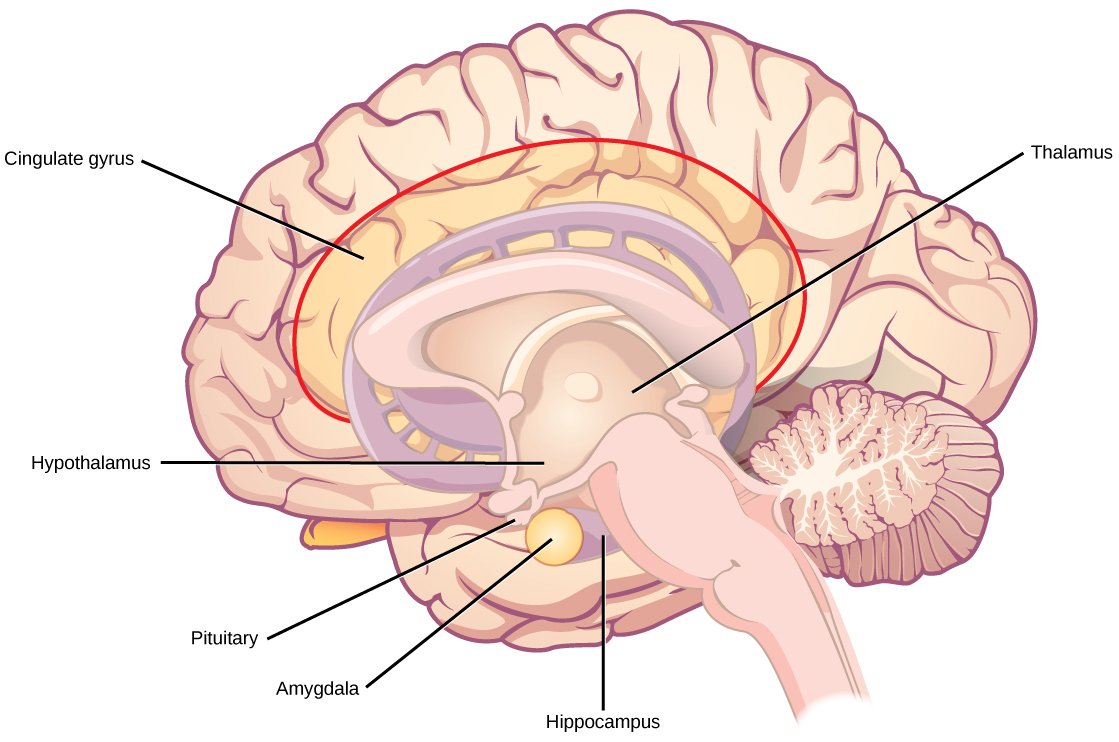
Below the thalamus is the hypothalamus, shown in Figure 16.24. The hypothalamus controls the endocrine system by sending signals to the pituitary gland, a pea-sized endocrine gland that releases several different hormones that affect other glands as well as other cells. This relationship means that the hypothalamus regulates important behaviors that are controlled by these hormones. The hypothalamus is the body’s thermostat—it makes sure key functions like food and water intake, energy expenditure, and body temperature are kept at appropriate levels. Neurons within the hypothalamus also regulate circadian rhythms, sometimes called sleep cycles.
The limbic system is a connected set of structures that regulates emotion, as well as behaviors related to fear and motivation. It plays a role in memory formation and includes parts of the thalamus and hypothalamus as well as the hippocampus. One important structure within the limbic system is a temporal lobe structure called the amygdala (Greek for “almond”), illustrated in Figure 16.24. The two amygdala are important both for the sensation of fear and for recognizing fearful faces. The cingulate gyrus helps regulate emotions and pain.
The cerebellum (Latin for “little brain”), shown in Figure 16.21, sits at the base of the brain on top of the brainstem. The cerebellum controls balance and aids in coordinating movement and learning new motor tasks.
The brainstem, illustrated in Figure 16.21, connects the rest of the brain with the spinal cord. It consists of the midbrain, medulla oblongata, and the pons. Motor and sensory neurons extend through the brainstem allowing for the relay of signals between the brain and spinal cord. Ascending neural pathways cross in this section of the brain allowing the left hemisphere of the cerebrum to control the right side of the body and vice versa. The brainstem coordinates motor control signals sent from the brain to the body. The brainstem controls several important functions of the body including alertness, arousal, breathing, blood pressure, digestion, heart rate, swallowing, walking, and sensory and motor information integration.
Connecting to the brainstem and extending down the body through the spinal column is the spinal cord, shown in Figure 16.21. The spinal cord is a thick bundle of nerve tissue that carries information about the body to the brain and from the brain to the body. The spinal cord is contained within the bones of the vertebrate column but is able to communicate signals to and from the body through its connections with spinal nerves (part of the peripheral nervous system). A cross-section of the spinal cord looks like a white oval containing a gray butterfly-shape, as illustrated in Figure 16.25. Myelinated axons make up the “white matter” and neuron and glial cell bodies make up the “gray matter.” Gray matter is also composed of interneurons, which connect two neurons each located in different parts of the body. Axons and cell bodies in the dorsal (facing the back of the animal) spinal cord convey mostly sensory information from the body to the brain. Axons and cell bodies in the ventral (facing the front of the animal) spinal cord primarily transmit signals controlling movement from the brain to the body.
The spinal cord also controls motor reflexes. These reflexes are quick, unconscious movements—like automatically removing a hand from a hot object. Reflexes are so fast because they involve local synaptic connections. For example, the knee reflex that a doctor tests during a routine physical is controlled by a single synapse between a sensory neuron and a motor neuron. While a reflex may only require the involvement of one or two synapses, synapses with interneurons in the spinal column transmit information to the brain to convey what happened (the knee jerked, or the hand was hot).
In the United States, there around 10,000 spinal cord injuries each year. Because the spinal cord is the information superhighway connecting the brain with the body, damage to the spinal cord can lead to paralysis. The extent of the paralysis depends on the location of the injury along the spinal cord and whether the spinal cord was completely severed. For example, if the spinal cord is damaged at the level of the neck, it can cause paralysis from the neck down, whereas damage to the spinal column further down may limit paralysis to the legs. Spinal cord injuries are notoriously difficult to treat because spinal nerves do not regenerate, although ongoing research suggests that stem cell transplants may be able to act as a bridge to reconnect severed nerves. Researchers are also looking at ways to prevent the inflammation that worsens nerve damage after injury. One such treatment is to pump the body with cold saline to induce hypothermia. This cooling can prevent swelling and other processes that are thought to worsen spinal cord injuries.
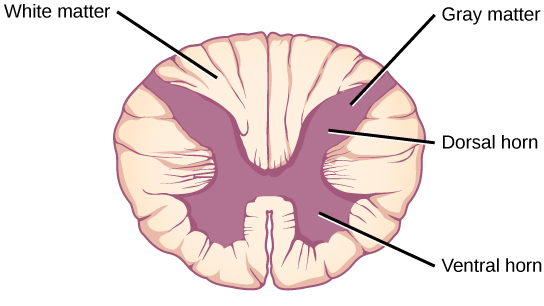
The vertebrate central nervous system contains the brain and the spinal cord, which are covered and protected by three meninges. The brain contains structurally and functionally defined regions. In mammals, these include the cortex (which can be broken down into four primary functional lobes: frontal, temporal, occipital, and parietal), basal ganglia, thalamus, hypothalamus, limbic system, cerebellum, and brainstem—although structures in some of these designations overlap. While functions may be primarily localized to one structure in the brain, most complex functions, like language and sleep, involve neurons in multiple brain regions. The spinal cord is the information superhighway that connects the brain with the rest of the body through its connections with peripheral nerves. It transmits sensory and motor input and also controls motor reflexes.
Exercises
Review Questions
The ________ lobe contains the visual cortex.
The ________ connects the two cerebral hemispheres.
Neurons in the ________ control motor reflexes.
Phineas Gage was a 19th century railroad worker who survived an accident that drove a large iron rod through his head. If the injury resulted in him becoming temperamental and capricious what part of his brain was damaged?
Critical Thinking Questions
Glossary
Chapter 35 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
The peripheral nervous system (PNS) is the connection between the central nervous system and the rest of the body. The CNS is like the power plant of the nervous system. It creates the signals that control the functions of the body. The PNS is like the wires that go to individual houses. Without those “wires,” the signals produced by the CNS could not control the body (and the CNS would not be able to receive sensory information from the body either).
The PNS can be broken down into the autonomic nervous system, which controls bodily functions without conscious control, and the sensory-somatic nervous system, which transmits sensory information from the skin, muscles, and sensory organs to the CNS and sends motor commands from the CNS to the muscles.
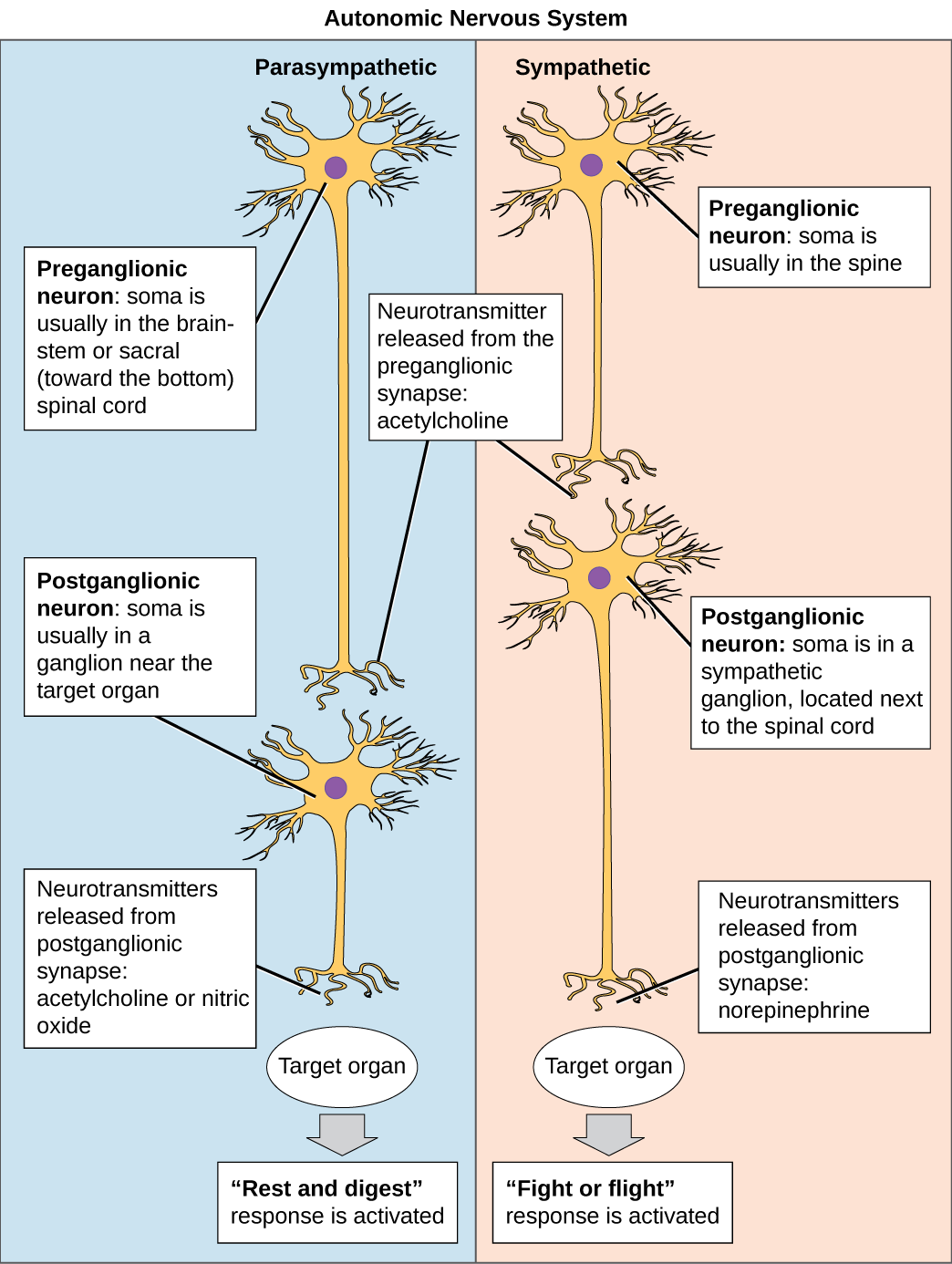
Which of the following statements is false?
The autonomic nervous system serves as the relay between the CNS and the internal organs. It controls the lungs, the heart, smooth muscle, and exocrine and endocrine glands. The autonomic nervous system controls these organs largely without conscious control; it can continuously monitor the conditions of these different systems and implement changes as needed. Signaling to the target tissue usually involves two synapses: a preganglionic neuron (originating in the CNS) synapses to a neuron in a ganglion that, in turn, synapses on the target organ, as illustrated in Figure 16.26. There are two divisions of the autonomic nervous system that often have opposing effects: the sympathetic nervous system and the parasympathetic nervous system.
The sympathetic nervous system is responsible for the “fight or flight” response that occurs when an animal encounters a dangerous situation. One way to remember this is to think of the surprise a person feels when encountering a snake (“snake” and “sympathetic” both begin with “s”). Examples of functions controlled by the sympathetic nervous system include an accelerated heart rate and inhibited digestion. These functions help prepare an organism’s body for the physical strain required to escape a potentially dangerous situation or to fend off a predator.
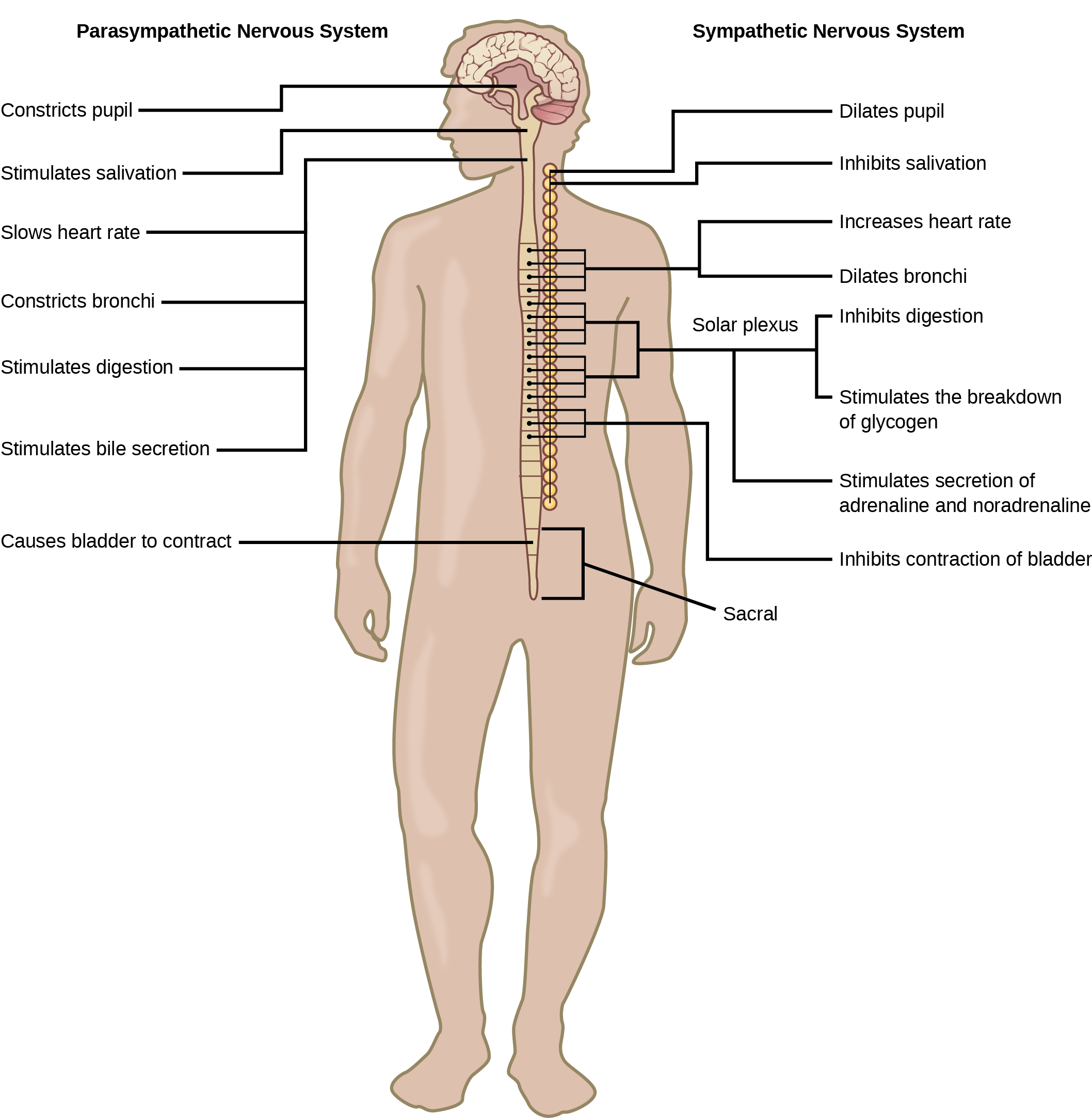
Most preganglionic neurons in the sympathetic nervous system originate in the spinal cord, as illustrated in Figure 16.27. The axons of these neurons release acetylcholine on postganglionic neurons within sympathetic ganglia (the sympathetic ganglia form a chain that extends alongside the spinal cord). The acetylcholine activates the postganglionic neurons. Postganglionic neurons then release norepinephrine onto target organs. As anyone who has ever felt a rush before a big test, speech, or athletic event can attest, the effects of the sympathetic nervous system are quite pervasive. This is both because one preganglionic neuron synapses on multiple postganglionic neurons, amplifying the effect of the original synapse, and because the adrenal gland also releases norepinephrine (and the closely related hormone epinephrine) into the bloodstream. The physiological effects of this norepinephrine release include dilating the trachea and bronchi (making it easier for the animal to breathe), increasing heart rate, and moving blood from the skin to the heart, muscles, and brain (so the animal can think and run). The strength and speed of the sympathetic response helps an organism avoid danger, and scientists have found evidence that it may also increase LTP—allowing the animal to remember the dangerous situation and avoid it in the future.
While the sympathetic nervous system is activated in stressful situations, the parasympathetic nervous system allows an animal to “rest and digest.” One way to remember this is to think that during a restful situation like a picnic, the parasympathetic nervous system is in control (“picnic” and “parasympathetic” both start with “p”). Parasympathetic preganglionic neurons have cell bodies located in the brainstem and in the sacral (toward the bottom) spinal cord, as shown in Figure 16.27. The axons of the preganglionic neurons release acetylcholine on the postganglionic neurons, which are generally located very near the target organs. Most postganglionic neurons release acetylcholine onto target organs, although some release nitric oxide.
The parasympathetic nervous system resets organ function after the sympathetic nervous system is activated (the common adrenaline dump you feel after a ‘fight-or-flight’ event). Effects of acetylcholine release on target organs include slowing of heart rate, lowered blood pressure, and stimulation of digestion.
The sensory-somatic nervous system is made up of cranial and spinal nerves and contains both sensory and motor neurons. Sensory neurons transmit sensory information from the skin, skeletal muscle, and sensory organs to the CNS. Motor neurons transmit messages about desired movement from the CNS to the muscles to make them contract. Without its sensory-somatic nervous system, an animal would be unable to process any information about its environment (what it sees, feels, hears, and so on) and could not control motor movements. Unlike the autonomic nervous system, which has two synapses between the CNS and the target organ, sensory and motor neurons have only one synapse—one ending of the neuron is at the organ and the other directly contacts a CNS neuron. Acetylcholine is the main neurotransmitter released at these synapses.
Humans have 12 cranial nerves, nerves that emerge from or enter the skull (cranium), as opposed to the spinal nerves, which emerge from the vertebral column. Each cranial nerve is accorded a name, which are detailed in Figure 16.28. Some cranial nerves transmit only sensory information. For example, the olfactory nerve transmits information about smells from the nose to the brainstem. Other cranial nerves transmit almost solely motor information. For example, the oculomotor nerve controls the opening and closing of the eyelid and some eye movements. Other cranial nerves contain a mix of sensory and motor fibers. For example, the glossopharyngeal nerve has a role in both taste (sensory) and swallowing (motor).
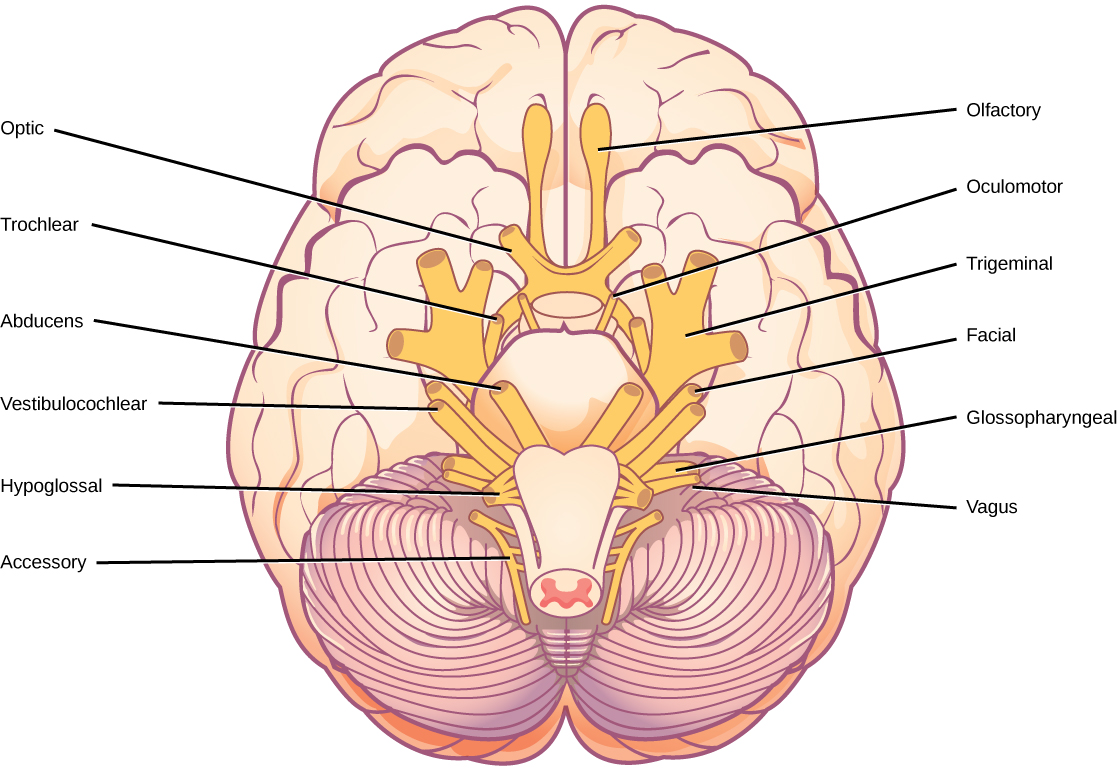
Spinal nerves transmit sensory and motor information between the spinal cord and the rest of the body. Each of the 31 spinal nerves (in humans) contains both sensory and motor axons. The sensory neuron cell bodies are grouped in structures called dorsal root ganglia and are shown in Figure 16.29. Each sensory neuron has one projection—with a sensory receptor ending in skin, muscle, or sensory organs—and another that synapses with a neuron in the dorsal spinal cord. Motor neurons have cell bodies in the ventral gray matter of the spinal cord that project to muscle through the ventral root. These neurons are usually stimulated by interneurons within the spinal cord but are sometimes directly stimulated by sensory neurons.
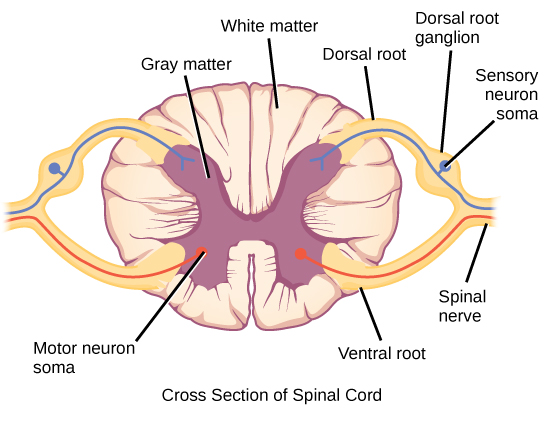
The peripheral nervous system contains both the autonomic and sensory-somatic nervous systems. The autonomic nervous system provides unconscious control over visceral functions and has two divisions: the sympathetic and parasympathetic nervous systems. The sympathetic nervous system is activated in stressful situations to prepare the animal for a “fight or flight” response. The parasympathetic nervous system is active during restful periods. The sensory-somatic nervous system is made of cranial and spinal nerves that transmit sensory information from skin and muscle to the CNS and motor commands from the CNS to the muscles.
Exercises
Visual Connection Questions
Figure 16. : Which of the following statements is false?
Review Questions
Activation of the sympathetic nervous system causes:
Where are parasympathetic preganglionic cell bodies located?
________ is released by motor nerve endings onto muscle.
Critical Thinking Questions
What are the main functions of the sensory-somatic nervous system?
Describe how the sensory-somatic nervous system reacts by reflex to a person touching something hot. How does this allow for rapid responses in potentially dangerous situations
Scientists have suggested that the autonomic nervous system is not well-adapted to modern human life. How is the sympathetic nervous system an ineffective response to the everyday challenges faced by modern humans?
Glossary
Chapter 35 in OpenStax Concepts of Biology 2e
Learning Objectives
By the end of this section, you will be able to do the following:
A nervous system that functions correctly is a fantastically complex, well-oiled machine—synapses fire appropriately, muscles move when needed, memories are formed and stored, and emotions are well regulated. Unfortunately, each year millions of people in the United States deal with some sort of nervous system disorder. While scientists have discovered potential causes of many of these diseases, and viable treatments for some, ongoing research seeks to find ways to better prevent and treat all of these disorders.
Neurodegenerative disorders are illnesses characterized by a loss of nervous system functioning that are usually caused by neuronal death. These diseases generally worsen over time as more and more neurons die. The symptoms of a particular neurodegenerative disease are related to where in the nervous system the death of neurons occurs. Spinocerebellar ataxia, for example, leads to neuronal death in the cerebellum. The death of these neurons causes problems in balance and walking. Neurodegenerative disorders include Huntington’s disease, amyotrophic lateral sclerosis, Alzheimer’s disease and other types of dementia disorders, and Parkinson’s disease. Here, Alzheimer’s and Parkinson’s disease will be discussed in more depth.
Alzheimer’s disease is the most common cause of dementia in the elderly. In 2012, an estimated 5.4 million Americans suffered from Alzheimer’s disease, and payments for their care are estimated at $200 billion. Roughly one in every eight people age 65 or older has the disease. Due to the aging of the baby-boomer generation, there are projected to be as many as 13 million Alzheimer’s patients in the United States in the year 2050.
Symptoms of Alzheimer’s disease include disruptive memory loss, confusion about time or place, difficulty planning or executing tasks, poor judgment, and personality changes. Problems smelling certain scents can also be indicative of Alzheimer’s disease and may serve as an early warning sign. Many of these symptoms are also common in people who are aging normally, so it is the severity and longevity of the symptoms that determine whether a person is suffering from Alzheimer’s.
Alzheimer’s disease was named for Alois Alzheimer, a German psychiatrist who published a report in 1911 about a woman who showed severe dementia symptoms. Along with his colleagues, he examined the woman’s brain following her death and reported the presence of abnormal clumps, which are now called amyloid plaques, along with tangled brain fibers called neurofibrillary tangles. Amyloid plaques, neurofibrillary tangles, and an overall shrinking of brain volume are commonly seen in the brains of Alzheimer’s patients. Loss of neurons in the hippocampus is especially severe in advanced Alzheimer’s patients. Figure 16.30 compares a normal brain to the brain of an Alzheimer’s patient. Many research groups are examining the causes of these hallmarks of the disease.
One form of the disease is usually caused by mutations in one of three known genes. This rare form of early onset Alzheimer’s disease affects fewer than five percent of patients with the disease and causes dementia beginning between the ages of 30 and 60. The more prevalent, late-onset form of the disease likely also has a genetic component. One particular gene, apolipoprotein E (APOE) has a variant (E4) that increases a carrier’s likelihood of getting the disease. Many other genes have been identified that might be involved in the pathology.
Visit the Canadian Alzheimer Society website for links discussing genetics and Alzheimer’s disease.
Unfortunately, there is no cure for Alzheimer’s disease. Current treatments focus on managing the symptoms of the disease. Because decrease in the activity of cholinergic neurons (neurons that use the neurotransmitter acetylcholine) is common in Alzheimer’s disease, several drugs used to treat the disease work by increasing acetylcholine neurotransmission, often by inhibiting the enzyme that breaks down acetylcholine in the synaptic cleft. Other clinical interventions focus on behavioral therapies like psychotherapy, sensory therapy, and cognitive exercises. Since Alzheimer’s disease appears to hijack the normal aging process, research into prevention is prevalent. Smoking, obesity, and cardiovascular problems may be risk factors for the disease, so treatments for those may also help to prevent Alzheimer’s disease. Some studies have shown that people who remain intellectually active by playing games, reading, playing musical instruments, and being socially active in later life have a reduced risk of developing the disease.
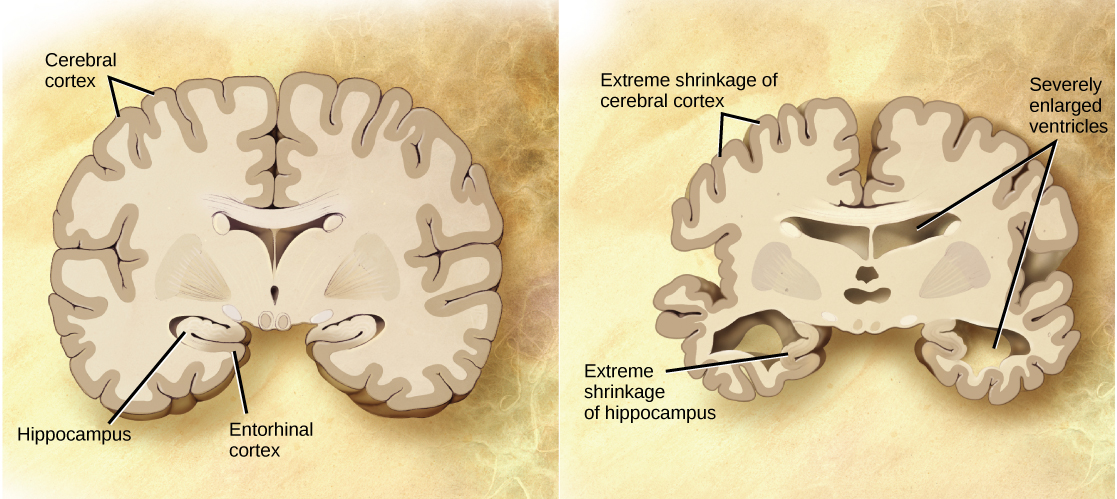
Like Alzheimer’s disease, Parkinson’s disease is a neurodegenerative disease. It was first characterized by James Parkinson in 1817. Each year, 50,000-60,000 people in the United States are diagnosed with the disease. Parkinson’s disease causes the loss of dopamine neurons in the substantia nigra, a midbrain structure that regulates movement. Loss of these neurons causes many symptoms including tremor (shaking of fingers or a limb), slowed movement, speech changes, balance and posture problems, and rigid muscles. The combination of these symptoms often causes a characteristic slow hunched shuffling walk, illustrated in Figure 16.31. Patients with Parkinson’s disease can also exhibit psychological symptoms, such as dementia or emotional problems.
Although some patients have a form of the disease known to be caused by a single mutation, for most patients the exact causes of Parkinson’s disease remain unknown: the disease likely results from a combination of genetic and environmental factors (similar to Alzheimer’s disease). Post-mortem analysis of brains from Parkinson’s patients shows the presence of Lewy bodies—abnormal protein clumps—in dopaminergic neurons. The prevalence of these Lewy bodies often correlates with the severity of the disease.
There is no cure for Parkinson’s disease, and treatment is focused on easing symptoms. One of the most commonly prescribed drugs for Parkinson’s is L-DOPA, which is a chemical that is converted into dopamine by neurons in the brain. This conversion increases the overall level of dopamine neurotransmission and can help compensate for the loss of dopaminergic neurons in the substantia nigra. Other drugs work by inhibiting the enzyme that breaks down dopamine.
Neurodevelopmental disorders occur when the development of the nervous system is disturbed. There are several different classes of neurodevelopmental disorders. Some, like Down Syndrome, cause intellectual deficits. Others specifically affect communication, learning, or the motor system. Some disorders like autism spectrum disorder and attention deficit/hyperactivity disorder have complex symptoms.
Autism spectrum disorder (ASD) is a neurodevelopmental disorder. Its severity differs from person to person. Estimates for the prevalence of the disorder have changed rapidly in the past few decades. Current estimates suggest that one in 88 children will develop the disorder. ASD is four times more prevalent in males than females.
This video discusses possible reasons why there has been a recent increase in the number of people diagnosed with autism.
A characteristic symptom of ASD is impaired social skills. Children with autism may have difficulty making and maintaining eye contact and reading social cues. They also may have problems feeling empathy for others. Other symptoms of ASD include repetitive motor behaviors (such as rocking back and forth), preoccupation with specific subjects, strict adherence to certain rituals, and unusual language use. Up to 30 percent of patients with ASD develop epilepsy, and patients with some forms of the disorder (like Fragile X) also have intellectual disability. Because it is a spectrum disorder, other ASD patients are very functional and have good-to-excellent language skills. Many of these patients do not feel that they suffer from a disorder and instead think that their brains just process information differently.
Except for some well-characterized, clearly genetic forms of autism (like Fragile X and Rett’s Syndrome), the causes of ASD are largely unknown. Variants of several genes correlate with the presence of ASD, but for any given patient, many different mutations in different genes may be required for the disease to develop. At a general level, ASD is thought to be a disease of “incorrect” wiring. Accordingly, brains of some ASD patients lack the same level of synaptic pruning that occurs in non-affected people. In the 1990s, a research paper linked autism to a common vaccine given to children. This paper was retracted when it was discovered that the author falsified data, and follow-up studies showed no connection between vaccines and autism.
Treatment for autism usually combines behavioral therapies and interventions, along with medications to treat other disorders common to people with autism (depression, anxiety, obsessive compulsive disorder). Although early interventions can help mitigate the effects of the disease, there is currently no cure for ASD.
Approximately three to five percent of children and adults are affected by attention deficit/hyperactivity disorder (ADHD). Like ASD, ADHD is more prevalent in males than females. Symptoms of the disorder include inattention (lack of focus), executive functioning difficulties, impulsivity, and hyperactivity beyond what is characteristic of the normal developmental stage. Some patients do not have the hyperactive component of symptoms and are diagnosed with a subtype of ADHD: attention deficit disorder (ADD). Many people with ADHD also show comorbitity, in that they develop secondary disorders in addition to ADHD. Examples include depression or obsessive compulsive disorder (OCD). Figure 16.32 provides some statistics concerning comorbidity with ADHD.
The cause of ADHD is unknown, although research points to a delay and dysfunction in the development of the prefrontal cortex and disturbances in neurotransmission. According to studies of twins, the disorder has a strong genetic component. There are several candidate genes that may contribute to the disorder, but no definitive links have been discovered. Environmental factors, including exposure to certain pesticides, may also contribute to the development of ADHD in some patients. Treatment for ADHD often involves behavioral therapies and the prescription of stimulant medications, which paradoxically cause a calming effect in these patients.
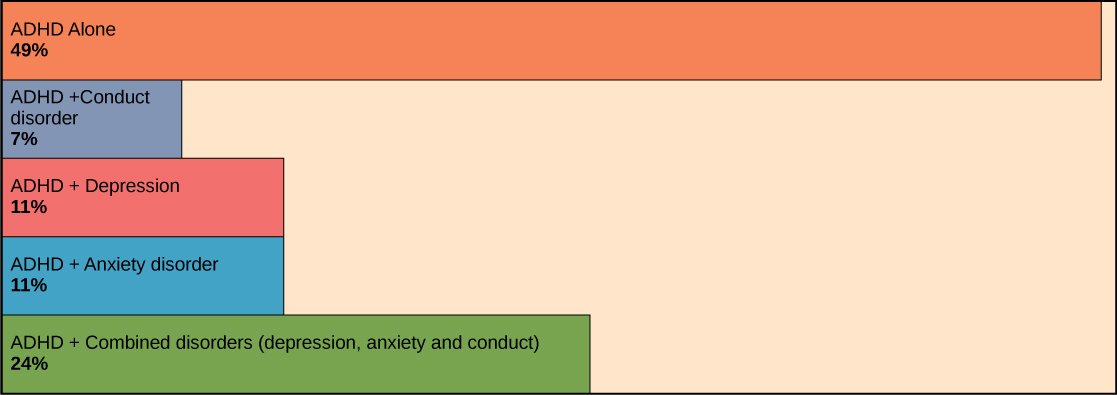
Neurologists are physicians who specialize in disorders of the nervous system. They diagnose and treat disorders such as epilepsy, stroke, dementia, nervous system injuries, Parkinson’s disease, sleep disorders, and multiple sclerosis. Neurologists are medical doctors who have attended college, medical school, and completed three to four years of neurology residency.
When examining a new patient, a neurologist takes a full medical history and performs a complete physical exam. The physical exam contains specific tasks that are used to determine what areas of the brain, spinal cord, or peripheral nervous system may be damaged. For example, to check whether the hypoglossal nerve is functioning correctly, the neurologist will ask the patient to move his or her tongue in different ways. If the patient does not have full control over tongue movements, then the hypoglossal nerve may be damaged or there may be a lesion in the brainstem where the cell bodies of these neurons reside (or there could be damage to the tongue muscle itself).
Neurologists have other tools besides a physical exam they can use to diagnose particular problems in the nervous system. If the patient has had a seizure, for example, the neurologist can use electroencephalography (EEG), which involves taping electrodes to the scalp to record brain activity, to try to determine which brain regions are involved in the seizure. In suspected stroke patients, a neurologist can use a computerized tomography (CT) scan, which is a type of X-ray, to look for bleeding in the brain or a possible brain tumor. To treat patients with neurological problems, neurologists can prescribe medications or refer the patient to a neurosurgeon for surgery.
The Neurological Exam: An Anatomical Approach website allows you to see the different tests a neurologist might use to see what regions of the nervous system may be damaged in a patient.
Mental illnesses are nervous system disorders that result in problems with thinking, mood, or relating with other people. These disorders are severe enough to affect a person’s quality of life and often make it difficult for people to perform the routine tasks of daily living. Debilitating mental disorders plague approximately 12.5 million Americans (about 1 in 17 people) at an annual cost of more than $300 billion. There are several types of mental disorders including schizophrenia, major depression, bipolar disorder, anxiety disorders and phobias, post-traumatic stress disorders, and obsessive-compulsive disorder (OCD), among others. The American Psychiatric Association publishes the Diagnostic and Statistical Manual of Mental Disorders (or DSM), which describes the symptoms required for a patient to be diagnosed with a particular mental disorder. Each newly released version of the DSM contains different symptoms and classifications as scientists learn more about these disorders, their causes, and how they relate to each other. A more detailed discussion of two mental illnesses—schizophrenia and major depression—is given below.
Schizophrenia is a serious and often debilitating mental illness affecting one percent of people in the United States. Symptoms of the disease include the inability to differentiate between reality and imagination, inappropriate and unregulated emotional responses, difficulty thinking, and problems with social situations. People with schizophrenia can suffer from hallucinations and hear voices; they may also suffer from delusions. Patients also have so-called “negative” symptoms like a flattened emotional state, loss of pleasure, and loss of basic drives. Many schizophrenic patients are diagnosed in their late adolescence or early 20s. The development of schizophrenia is thought to involve malfunctioning dopaminergic neurons and may also involve problems with glutamate signaling. Treatment for the disease usually requires antipsychotic medications that work by blocking dopamine receptors and decreasing dopamine neurotransmission in the brain. This decrease in dopamine can cause Parkinson’s disease-like symptoms in some patients. While some classes of antipsychotics can be quite effective at treating the disease, they are not a cure, and most patients must remain medicated for the rest of their lives.
Major depression affects approximately 6.7 percent of the adults in the United States each year and is one of the most common mental disorders. To be diagnosed with major depressive disorder, a person must have experienced a severely depressed mood lasting longer than two weeks along with other symptoms including a loss of enjoyment in activities that were previously enjoyed, changes in appetite and sleep schedules, difficulty concentrating, feelings of worthlessness, and suicidal thoughts. The exact causes of major depression are unknown and likely include both genetic and environmental risk factors. Some research supports the “classic monoamine hypothesis,” which suggests that depression is caused by a decrease in norepinephrine and serotonin neurotransmission. One argument against this hypothesis is the fact that some antidepressant medications cause an increase in norepinephrine and serotonin release within a few hours of beginning treatment—but clinical results of these medications are not seen until weeks later. This has led to alternative hypotheses: for example, dopamine may also be decreased in depressed patients, or it may actually be an increase in norepinephrine and serotonin that causes the disease, and antidepressants force a feedback loop that decreases this release. Treatments for depression include psychotherapy, electroconvulsive therapy, deep-brain stimulation, and prescription medications. There are several classes of antidepressant medications that work through different mechanisms. For example, monoamine oxidase inhibitors (MAO inhibitors) block the enzyme that degrades many neurotransmitters (including dopamine, serotonin, norepinephrine), resulting in increased neurotransmitter in the synaptic cleft. Selective serotonin reuptake inhibitors (SSRIs) block the reuptake of serotonin into the presynaptic neuron. This blockage results in an increase in serotonin in the synaptic cleft. Other types of drugs such as norepinephrine-dopamine reuptake inhibitors and norepinephrine-serotonin reuptake inhibitors are also used to treat depression.
There are several other neurological disorders that cannot be easily placed in the above categories. These include chronic pain conditions, cancers of the nervous system, epilepsy disorders, and stroke. Epilepsy and stroke are discussed below.
Estimates suggest that up to three percent of people in the United States will be diagnosed with epilepsy in their lifetime. While there are several different types of epilepsy, all are characterized by recurrent seizures. Epilepsy itself can be a symptom of a brain injury, disease, or other illness. For example, people who have intellectual disability or ASD can experience seizures, presumably because the developmental wiring malfunctions that caused their disorders also put them at risk for epilepsy. For many patients, however, the cause of their epilepsy is never identified and is likely to be a combination of genetic and environmental factors. Often, seizures can be controlled with anticonvulsant medications. However, for very severe cases, patients may undergo brain surgery to remove the brain area where seizures originate.
A stroke results when blood fails to reach a portion of the brain for a long enough time to cause damage. Without the oxygen supplied by blood flow, neurons in this brain region die. This neuronal death can cause many different symptoms—depending on the brain area affected— including headache, muscle weakness or paralysis, speech disturbances, sensory problems, memory loss, and confusion. Stroke is often caused by blood clots and can also be caused by the bursting of a weak blood vessel. Strokes are extremely common and are the third most common cause of death in the United States. On average one person experiences a stroke every 40 seconds in the United States. Approximately 75 percent of strokes occur in people older than 65. Risk factors for stroke include high blood pressure, diabetes, high cholesterol, and a family history of stroke. Smoking doubles the risk of stroke. Because a stroke is a medical emergency, patients with symptoms of a stroke should immediately go to the emergency room, where they can receive drugs that will dissolve any clot that may have formed. These drugs will not work if the stroke was caused by a burst blood vessel or if the stroke occurred more than three hours before arriving at the hospital. Treatment following a stroke can include blood pressure medication (to prevent future strokes) and (sometimes intense) physical therapy.
Some general themes emerge from the sampling of nervous system disorders presented above. The causes for most disorders are not fully understood—at least not for all patients—and likely involve a combination of nature (genetic mutations that become risk factors) and nurture (emotional trauma, stress, hazardous chemical exposure). Because the causes have yet to be fully determined, treatment options are often lacking and only address symptoms.
Exercises
Review Questions
Parkinson’s disease is a caused by the degeneration of neurons that release ________.
________ medications are often used to treat patients with ADHD.
Strokes are often caused by ________.
Why is it difficult to identify the cause of many nervous system disorders?
Why do many patients with neurodevelopmental disorders develop secondary disorders?
Critical Thinking Questions
Glossary
Chapter 35 in OpenStax Concepts of Biology 2e

In more advanced animals, the senses are constantly at work, making the animal aware of stimuli—such as light, or sound, or the presence of a chemical substance in the external environment—and monitoring information about the organism’s internal environment. All bilaterally symmetric animals have a sensory system, and the development of any species’ sensory system has been driven by natural selection; thus, sensory systems differ among species according to the demands of their environments. The shark, unlike most fish predators, is electrosensitive—that is, sensitive to electrical fields produced by other animals in its environment. While it is helpful to this underwater predator, electrosensitivity is a sense not found in most land animals.
Chapter 36 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Senses provide information about the body and its environment. Humans have five special senses: olfaction (smell), gustation (taste), equilibrium (balance and body position), vision, and hearing. Additionally, we possess general senses, also called somatosensation, which respond to stimuli like temperature, pain, pressure, and vibration. Vestibular sensation, which is an organism’s sense of spatial orientation and balance, proprioception (position of bones, joints, and muscles), and the sense of limb position that is used to track kinesthesia (limb movement) are part of somatosensation. Although the sensory systems associated with these senses are very different, all share a common function: to convert a stimulus (such as light, or sound, or the position of the body) into an electrical signal in the nervous system. This process is called sensory transduction.
There are two broad types of cellular systems that perform sensory transduction. In one, a neuron works with a sensory receptor, a cell, or cell process that is specialized to engage with and detect a specific stimulus. Stimulation of the sensory receptor activates the associated afferent neuron, which carries information about the stimulus to the central nervous system. In the second type of sensory transduction, a sensory nerve ending responds to a stimulus in the internal or external environment: this neuron constitutes the sensory receptor. Free nerve endings can be stimulated by several different stimuli, thus showing little receptor specificity. For example, pain receptors in your gums and teeth may be stimulated by temperature changes, chemical stimulation, or pressure.
The first step in sensation is reception, which is the activation of sensory receptors by stimuli such as mechanical stimuli (being bent or squished, for example), chemicals, or temperature. The receptor can then respond to the stimuli. The region in space in which a given sensory receptor can respond to a stimulus, be it far away or in contact with the body, is that receptor’s receptive field. Think for a moment about the differences in receptive fields for the different senses. For the sense of touch, a stimulus must come into contact with the body. For the sense of hearing, a stimulus can be a moderate distance away (some baleen whale sounds can propagate for many kilometers). For vision, a stimulus can be very far away; for example, the visual system perceives light from stars at enormous distances.
The most fundamental function of a sensory system is the translation of a sensory signal to an electrical signal in the nervous system. This takes place at the sensory receptor, and the change in electrical potential that is produced is called the receptor potential. How is sensory input, such as pressure on the skin, changed to a receptor potential? In this example, a type of receptor called a mechanoreceptor (as shown in (Figure)) possesses specialized membranes that respond to pressure. Disturbance of these dendrites by compressing them or bending them opens gated ion channels in the plasma membrane of the sensory neuron, changing its electrical potential. Recall that in the nervous system, a positive change of a neuron’s electrical potential (also called the membrane potential), depolarizes the neuron. Receptor potentials are graded potentials: the magnitude of these graded (receptor) potentials varies with the strength of the stimulus. If the magnitude of depolarization is sufficient (that is, if membrane potential reaches a threshold), the neuron will fire an action potential. In most cases, the correct stimulus impinging on a sensory receptor will drive membrane potential in a positive direction, although for some receptors, such as those in the visual system, this is not always the case.
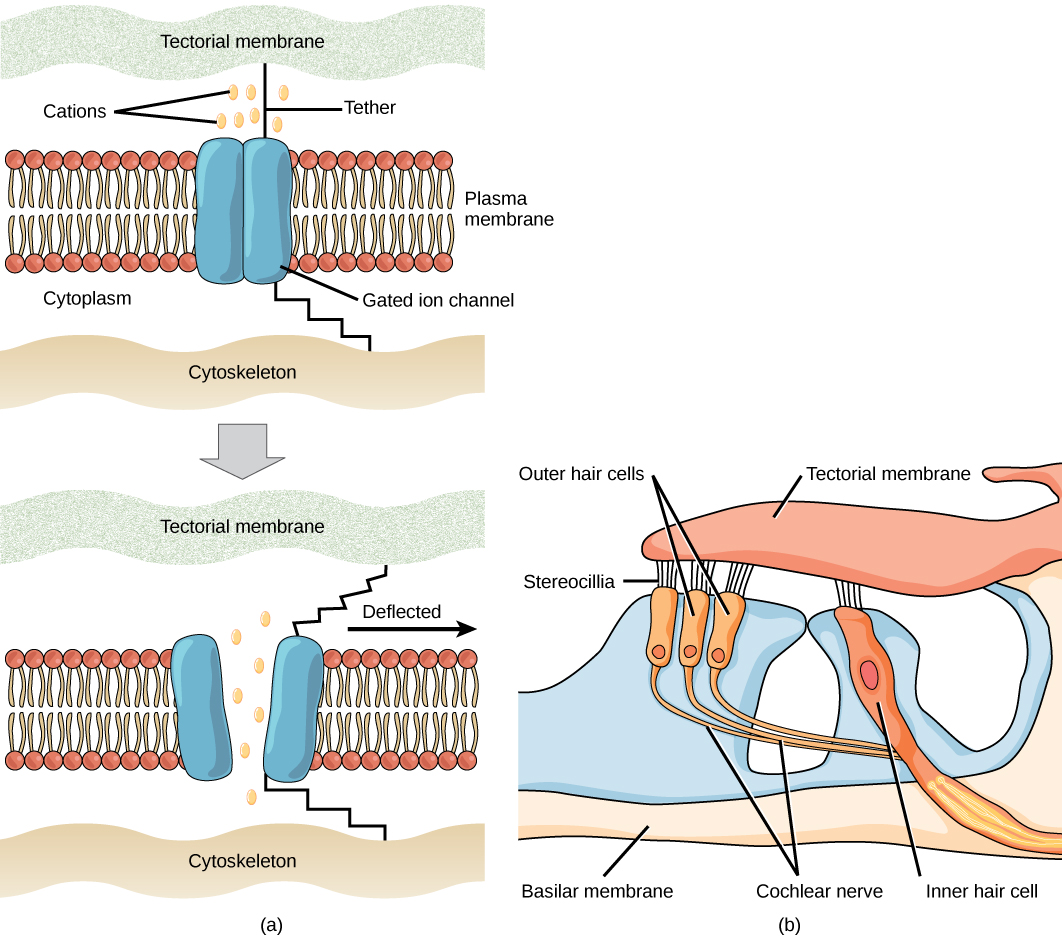
Sensory receptors for different senses are very different from each other, and they are specialized according to the type of stimulus they sense: they have receptor specificity. For example, touch receptors, light receptors, and sound receptors are each activated by different stimuli. Touch receptors are not sensitive to light or sound; they are sensitive only to touch or pressure. However, stimuli may be combined at higher levels in the brain, as happens with olfaction, contributing to our sense of taste.
Four aspects of sensory information are encoded by sensory systems: the type of stimulus, the location of the stimulus in the receptive field, the duration of the stimulus, and the relative intensity of the stimulus. Thus, action potentials transmitted over a sensory receptor’s afferent axons encode one type of stimulus, and this segregation of the senses is preserved in other sensory circuits. For example, auditory receptors transmit signals over their own dedicated system, and electrical activity in the axons of the auditory receptors will be interpreted by the brain as an auditory stimulus—a sound.
The intensity of a stimulus is often encoded in the rate of action potentials produced by the sensory receptor. Thus, an intense stimulus will produce a more rapid train of action potentials, and reducing the stimulus will likewise slow the rate of production of action potentials. A second way in which intensity is encoded is by the number of receptors activated. An intense stimulus might initiate action potentials in a large number of adjacent receptors, while a less intense stimulus might stimulate fewer receptors. Integration of sensory information begins as soon as the information is received in the CNS, and the brain will further process incoming signals.
Perception is an individual’s interpretation of a sensation. Although perception relies on the activation of sensory receptors, perception happens not at the level of the sensory receptor, but at higher levels in the nervous system, in the brain. The brain distinguishes sensory stimuli through a sensory pathway: action potentials from sensory receptors travel along neurons that are dedicated to a particular stimulus. These neurons are dedicated to that particular stimulus and synapse with particular neurons in the brain or spinal cord.
All sensory signals, except those from the olfactory system, are transmitted though the central nervous system and are routed to the thalamus and to the appropriate region of the cortex. Recall that the thalamus is a structure in the forebrain that serves as a clearinghouse and relay station for sensory (as well as motor) signals. When the sensory signal exits the thalamus, it is conducted to the specific area of the cortex ((Figure)) dedicated to processing that particular sense.
How are neural signals interpreted? Interpretation of sensory signals between individuals of the same species is largely similar, owing to the inherited similarity of their nervous systems; however, there are some individual differences. A good example of this is individual tolerances to a painful stimulus, such as dental pain, which certainly differ.
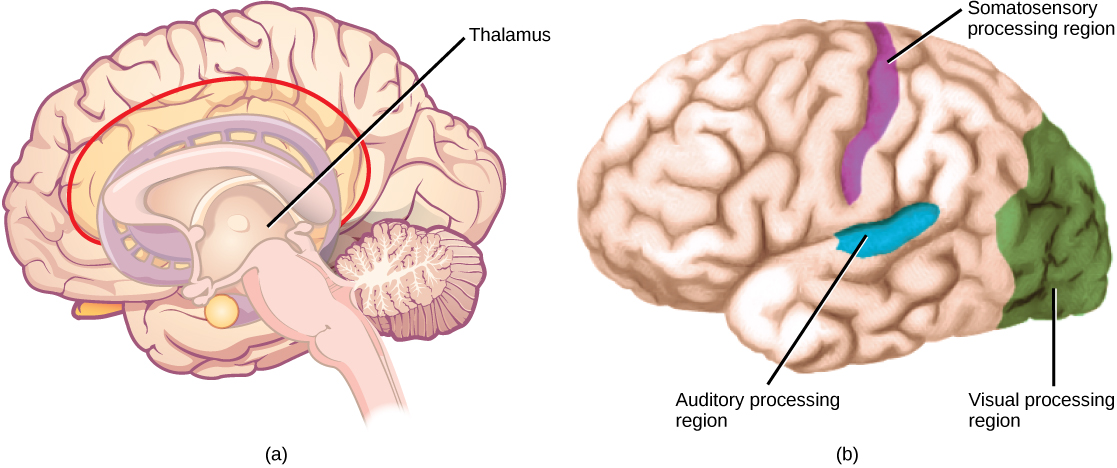
Just-Noticeable DifferenceIt is easy to differentiate between a one-pound bag of rice and a two-pound bag of rice. There is a one-pound difference, and one bag is twice as heavy as the other. However, would it be as easy to differentiate between a 20- and a 21-pound bag?
Question: What is the smallest detectible weight difference between a one-pound bag of rice and a larger bag? What is the smallest detectible difference between a 20-pound bag and a larger bag? In both cases, at what weights are the differences detected? This smallest detectible difference in stimuli is known as the just-noticeable difference (JND).
Background: Research background literature on JND and on Weber’s Law, a description of a proposed mathematical relationship between the overall magnitude of the stimulus and the JND. You will be testing JND of different weights of rice in bags. Choose a convenient increment that is to be stepped through while testing. For example, you could choose 10 percent increments between one and two pounds (1.1, 1.2, 1.3, 1.4, and so on) or 20 percent increments (1.2, 1.4, 1.6, and 1.8).
Hypothesis: Develop a hypothesis about JND in terms of percentage of the whole weight being tested (such as “the JND between the two small bags and between the two large bags is proportionally the same,” or “. . . is not proportionally the same.”) So, for the first hypothesis, if the JND between the one-pound bag and a larger bag is 0.2 pounds (that is, 20 percent; 1.0 pound feels the same as 1.1 pounds, but 1.0 pound feels less than 1.2 pounds), then the JND between the 20-pound bag and a larger bag will also be 20 percent. (So, 20 pounds feels the same as 22 pounds or 23 pounds, but 20 pounds feels less than 24 pounds.)
Test the hypothesis: Enlist 24 participants, and split them into two groups of 12. To set up the demonstration, assuming a 10 percent increment was selected, have the first group be the one-pound group. As a counter-balancing measure against a systematic error, however, six of the first group will compare one pound to two pounds, and step down in weight (1.0 to 2.0, 1.0 to 1.9, and so on), while the other six will step up (1.0 to 1.1, 1.0 to 1.2, and so on). Apply the same principle to the 20-pound group (20 to 40, 20 to 38, and so on, and 20 to 22, 20 to 24, and so on). Given the large difference between 20 and 40 pounds, you may wish to use 30 pounds as your larger weight. In any case, use two weights that are easily detectable as different.
Record the observations: Record the data in a table similar to the table below. For the one-pound and 20-pound groups (base weights) record a plus sign (+) for each participant that detects a difference between the base weight and the step weight. Record a minus sign (-) for each participant that finds no difference. If one-tenth steps were not used, then replace the steps in the “Step Weight” columns with the step you are using.
| Results of JND Testing (+ = difference; – = no difference) | |||
|---|---|---|---|
| Step Weight | One pound | 20 pounds | Step Weight |
| 1.1 | 22 | ||
| 1.2 | 24 | ||
| 1.3 | 26 | ||
| 1.4 | 28 | ||
| 1.5 | 30 | ||
| 1.6 | 32 | ||
| 1.7 | 34 | ||
| 1.8 | 36 | ||
| 1.9 | 38 | ||
| 2.0 | 40 | ||
Analyze the data/report the results: What step weight did all participants find to be equal with one-pound base weight? What about the 20-pound group?
Draw a conclusion: Did the data support the hypothesis? Are the final weights proportionally the same? If not, why not? Do the findings adhere to Weber’s Law? Weber’s Law states that the concept that a just-noticeable difference in a stimulus is proportional to the magnitude of the original stimulus.
A sensory activation occurs when a physical or chemical stimulus is processed into a neural signal (sensory transduction) by a sensory receptor. Perception is an individual interpretation of a sensation and is a brain function. Humans have special senses: olfaction, gustation, equilibrium, and hearing, plus the general senses of somatosensation.
Sensory receptors are either specialized cells associated with sensory neurons or the specialized ends of sensory neurons that are a part of the peripheral nervous system, and they are used to receive information about the environment (internal or external). Each sensory receptor is modified for the type of stimulus it detects. For example, neither gustatory receptors nor auditory receptors are sensitive to light. Each sensory receptor is responsive to stimuli within a specific region in space, which is known as that receptor’s receptive field. The most fundamental function of a sensory system is the translation of a sensory signal to an electrical signal in the nervous system.
All sensory signals, except those from the olfactory system, enter the central nervous system and are routed to the thalamus. When the sensory signal exits the thalamus, it is conducted to the specific area of the cortex dedicated to processing that particular sense.
Where does perception occur?
B
If a person’s cold receptors no longer convert cold stimuli into sensory signals, that person has a problem with the process of ________.
D
After somatosensory transduction, the sensory signal travels through the brain as a(n) _____ signal.
A
Many people experience motion sickness while traveling in a car. This sensation results from contradictory inputs arising from which senses?
D
If a person sustains damage to axons leading from sensory receptors to the central nervous system, which step or steps of sensory perception will be affected?
Transmission of sensory information from the receptor to the central nervous system will be impaired, and thus, perception of stimuli, which occurs in the brain, will be halted.
In what way does the overall magnitude of a stimulus affect the just-noticeable difference in the perception of that stimulus?
The just-noticeable difference is a fraction of the overall magnitude of the stimulus and seems to be a relatively fixed proportion (such as 10 percent) whether the stimulus is large (such as a very heavy object) or small (such as a very light object).
Describe the difference in the localization of the sensory receptors for general and special senses in humans.
General sensory receptors are located throughout the body in the skin and internal organs. Conversely, special senses are all located in the head region, and require specialized organs.
Chapter 36 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Somatosensation is a mixed sensory category and includes all sensation received from the skin and mucous membranes, as well from as the limbs and joints. Somatosensation is also known as tactile sense, or more familiarly, as the sense of touch. Somatosensation occurs all over the exterior of the body and at some interior locations as well. A variety of receptor types—embedded in the skin, mucous membranes, muscles, joints, internal organs, and cardiovascular system—play a role.
Recall that the epidermis is the outermost layer of skin in mammals. It is relatively thin, is composed of keratin-filled cells, and has no blood supply. The epidermis serves as a barrier to water and to invasion by pathogens. Below this, the much thicker dermis contains blood vessels, sweat glands, hair follicles, lymph vessels, and lipid-secreting sebaceous glands ((Figure)). Below the epidermis and dermis is the subcutaneous tissue, or hypodermis, the fatty layer that contains blood vessels, connective tissue, and the axons of sensory neurons. The hypodermis, which holds about 50 percent of the body’s fat, attaches the dermis to the bone and muscle, and supplies nerves and blood vessels to the dermis.
Sensory receptors are classified into five categories: mechanoreceptors, thermoreceptors, proprioceptors, pain receptors, and chemoreceptors. These categories are based on the nature of stimuli each receptor class transduces. What is commonly referred to as “touch” involves more than one kind of stimulus and more than one kind of receptor. Mechanoreceptors in the skin are described as encapsulated (that is, surrounded by a capsule) or unencapsulated (a group that includes free nerve endings). A free nerve ending, as its name implies, is an unencapsulated dendrite of a sensory neuron. Free nerve endings are the most common nerve endings in skin, and they extend into the middle of the epidermis. Free nerve endings are sensitive to painful stimuli, to hot and cold, and to light touch. They are slow to adjust to a stimulus and so are less sensitive to abrupt changes in stimulation.
There are three classes of mechanoreceptors: tactile, proprioceptors, and baroreceptors. Mechanoreceptors sense stimuli due to physical deformation of their plasma membranes. They contain mechanically gated ion channels whose gates open or close in response to pressure, touch, stretching, and sound.” There are four primary tactile mechanoreceptors in human skin: Merkel’s disks, Meissner’s corpuscles, Ruffini endings, and Pacinian corpuscles; two are located toward the surface of the skin and two are located deeper. A fifth type of mechanoreceptor, Krause end bulbs, are found only in specialized regions. Merkel’s disks (shown in (Figure)) are found in the upper layers of skin near the base of the epidermis, both in skin that has hair and on glabrous skin, that is, the hairless skin found on the palms and fingers, the soles of the feet, and the lips of humans and other primates. Merkel’s disks are densely distributed in the fingertips and lips. They are slow-adapting, encapsulated nerve endings, and they respond to light touch. Light touch, also known as discriminative touch, is a light pressure that allows the location of a stimulus to be pinpointed. The receptive fields of Merkel’s disks are small with well-defined borders. That makes them finely sensitive to edges and they come into use in tasks such as typing on a keyboard.
Which of the following statements about mechanoreceptors is false?
<!–<para>D–>
Meissner’s corpuscles, (shown in (Figure)) also known as tactile corpuscles, are found in the upper dermis, but they project into the epidermis. They, too, are found primarily in the glabrous skin on the fingertips and eyelids. They respond to fine touch and pressure, but they also respond to low-frequency vibration or flutter. They are rapidly adapting, fluid-filled, encapsulated neurons with small, well-defined borders and are responsive to fine details. Like Merkel’s disks, Meissner’s corpuscles are not as plentiful in the palms as they are in the fingertips.
Deeper in the epidermis, near the base, are Ruffini endings, which are also known as bulbous corpuscles. They are found in both glabrous and hairy skin. These are slow-adapting, encapsulated mechanoreceptors that detect skin stretch and deformations within joints, so they provide valuable feedback for gripping objects and controlling finger position and movement. Thus, they also contribute to proprioception and kinesthesia. Ruffini endings also detect warmth. Note that these warmth detectors are situated deeper in the skin than are the cold detectors. It is not surprising, then, that humans detect cold stimuli before they detect warm stimuli.
Pacinian corpuscles (seen in (Figure)) are located deep in the dermis of both glabrous and hairy skin and are structurally similar to Meissner’s corpuscles; they are found in the bone periosteum, joint capsules, pancreas and other viscera, breast, and genitals. They are rapidly adapting mechanoreceptors that sense deep transient (but not prolonged) pressure and high-frequency vibration. Pacinian receptors detect pressure and vibration by being compressed, stimulating their internal dendrites. There are fewer Pacinian corpuscles and Ruffini endings in skin than there are Merkel’s disks and Meissner’s corpuscles.
In proprioception, proprioceptive and kinesthetic signals travel through myelinated afferent neurons running from the spinal cord to the medulla. Neurons are not physically connected, but communicate via neurotransmitters secreted into synapses or “gaps” between communicating neurons. Once in the medulla, the neurons continue carrying the signals to the thalamus.
Muscle spindles are stretch receptors that detect the amount of stretch, or lengthening of muscles. Related to these are Golgi tendon organs, which are tension receptors that detect the force of muscle contraction. Proprioceptive and kinesthetic signals come from limbs. Unconscious proprioceptive signals run from the spinal cord to the cerebellum, the brain region that coordinates muscle contraction, rather than to the thalamus, like most other sensory information.
Baroreceptors detect pressure changes in an organ. They are found in the walls of the carotid artery and the aorta where they monitor blood pressure, and in the lungs where they detect the degree of lung expansion. Stretch receptors are found at various sites in the digestive and urinary systems.
In addition to these two types of deeper receptors, there are also rapidly adapting hair receptors, which are found on nerve endings that wrap around the base of hair follicles. There are a few types of hair receptors that detect slow and rapid hair movement, and they differ in their sensitivity to movement. Some hair receptors also detect skin deflection, and certain rapidly adapting hair receptors allow detection of stimuli that have not yet touched the skin.
The configuration of the different types of receptors working in concert in human skin results in a very refined sense of touch. The nociceptive receptors—those that detect pain—are located near the surface. Small, finely calibrated mechanoreceptors—Merkel’s disks and Meissner’s corpuscles—are located in the upper layers and can precisely localize even gentle touch. The large mechanoreceptors—Pacinian corpuscles and Ruffini endings—are located in the lower layers and respond to deeper touch. (Consider that the deep pressure that reaches those deeper receptors would not need to be finely localized.) Both the upper and lower layers of the skin hold rapidly and slowly adapting receptors. Both primary somatosensory cortex and secondary cortical areas are responsible for processing the complex picture of stimuli transmitted from the interplay of mechanoreceptors.
The distribution of touch receptors in human skin is not consistent over the body. In humans, touch receptors are less dense in skin covered with any type of hair, such as the arms, legs, torso, and face. Touch receptors are denser in glabrous skin (the type found on human fingertips and lips, for example), which is typically more sensitive and is thicker than hairy skin (4 to 5 mm versus 2 to 3 mm).
How is receptor density estimated in a human subject? The relative density of pressure receptors in different locations on the body can be demonstrated experimentally using a two-point discrimination test. In this demonstration, two sharp points, such as two thumbtacks, are brought into contact with the subject’s skin (though not hard enough to cause pain or break the skin). The subject reports if he or she feels one point or two points. If the two points are felt as one point, it can be inferred that the two points are both in the receptive field of a single sensory receptor. If two points are felt as two separate points, each is in the receptive field of two separate sensory receptors. The points could then be moved closer and retested until the subject reports feeling only one point, and the size of the receptive field of a single receptor could be estimated from that distance.
In addition to Krause end bulbs that detect cold and Ruffini endings that detect warmth, there are different types of cold receptors on some free nerve endings: thermoreceptors, located in the dermis, skeletal muscles, liver, and hypothalamus, that are activated by different temperatures. Their pathways into the brain run from the spinal cord through the thalamus to the primary somatosensory cortex. Warmth and cold information from the face travels through one of the cranial nerves to the brain. You know from experience that a tolerably cold or hot stimulus can quickly progress to a much more intense stimulus that is no longer tolerable. Any stimulus that is too intense can be perceived as pain because temperature sensations are conducted along the same pathways that carry pain sensations.
Pain is the name given to nociception, which is the neural processing of injurious stimuli in response to tissue damage. Pain is caused by true sources of injury, such as contact with a heat source that causes a thermal burn or contact with a corrosive chemical. But pain also can be caused by harmless stimuli that mimic the action of damaging stimuli, such as contact with capsaicins, the compounds that cause peppers to taste hot and which are used in self-defense pepper sprays and certain topical medications. Peppers taste “hot” because the protein receptors that bind capsaicin open the same calcium channels that are activated by warm receptors.
Nociception starts at the sensory receptors, but pain, inasmuch as it is the perception of nociception, does not start until it is communicated to the brain. There are several nociceptive pathways to and through the brain. Most axons carrying nociceptive information into the brain from the spinal cord project to the thalamus (as do other sensory neurons) and the neural signal undergoes final processing in the primary somatosensory cortex. Interestingly, one nociceptive pathway projects not to the thalamus but directly to the hypothalamus in the forebrain, which modulates the cardiovascular and neuroendocrine functions of the autonomic nervous system. Recall that threatening—or painful—stimuli stimulate the sympathetic branch of the visceral sensory system, readying a fight-or-flight response.
View this video that animates the five phases of nociceptive pain.
Somatosensation includes all sensation received from the skin and mucous membranes, as well as from the limbs and joints. Somatosensation occurs all over the exterior of the body and at some interior locations as well, and a variety of receptor types, embedded in the skin and mucous membranes, play a role.
There are several types of specialized sensory receptors. Rapidly adapting free nerve endings detect nociception, hot and cold, and light touch. Slowly adapting, encapsulated Merkel’s disks are found in fingertips and lips, and respond to light touch. Meissner’s corpuscles, found in glabrous skin, are rapidly adapting, encapsulated receptors that detect touch, low-frequency vibration, and flutter. Ruffini endings are slowly adapting, encapsulated receptors that detect skin stretch, joint activity, and warmth. Hair receptors are rapidly adapting nerve endings wrapped around the base of hair follicles that detect hair movement and skin deflection. Finally, Pacinian corpuscles are encapsulated, rapidly adapting receptors that detect transient pressure and high-frequency vibration.
(Figure) Which of the following statements about mechanoreceptors is false?
(Figure) D
_____ are found only in _____ skin, and detect skin deflection.
B
If you were to burn your epidermis, what receptor type would you most likely burn?
A
Many diabetic patients are warned by their doctors to test their glucose levels by pricking the sides of their fingers rather than the pads. Pricking the sides avoids stimulating which receptor?
B
What can be inferred about the relative sizes of the areas of cortex that process signals from skin not densely innervated with sensory receptors and skin that is densely innervated with sensory receptors?
The cortical areas serving skin that is densely innervated likely are larger than those serving skin that is less densely innervated.
Many studies have demonstrated that women are able to tolerate the same painful stimuli for longer than men. Why don’t all people experience pain the same way?
Pain is a subjective sensation that relies on the brain interpreting the nociception signals received by the sensory receptors (perception). Therefore, even though two people experience identical stimuli, their brains can perceive them as very different sensory experiences.
Chapter 36 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Taste, also called gustation, and smell, also called olfaction, are the most interconnected senses in that both involve molecules of the stimulus entering the body and bonding to receptors. Smell lets an animal sense the presence of food or other animals—whether potential mates, predators, or prey—or other chemicals in the environment that can impact their survival. Similarly, the sense of taste allows animals to discriminate between types of foods. While the value of a sense of smell is obvious, what is the value of a sense of taste? Different tasting foods have different attributes, both helpful and harmful. For example, sweet-tasting substances tend to be highly caloric, which could be necessary for survival in lean times. Bitterness is associated with toxicity, and sourness is associated with spoiled food. Salty foods are valuable in maintaining homeostasis by helping the body retain water and by providing ions necessary for cells to function.
Both taste and odor stimuli are molecules taken in from the environment. The primary tastes detected by humans are sweet, sour, bitter, salty, and umami. The first four tastes need little explanation. The identification of umami as a fundamental taste occurred fairly recently—it was identified in 1908 by Japanese scientist Kikunae Ikeda while he worked with seaweed broth, but it was not widely accepted as a taste that could be physiologically distinguished until many years later. The taste of umami, also known as savoriness, is attributable to the taste of the amino acid L-glutamate. In fact, monosodium glutamate, or MSG, is often used in cooking to enhance the savory taste of certain foods. What is the adaptive value of being able to distinguish umami? Savory substances tend to be high in protein.
All odors that we perceive are molecules in the air we breathe. If a substance does not release molecules into the air from its surface, it has no smell. And if a human or other animal does not have a receptor that recognizes a specific molecule, then that molecule has no smell. Humans have about 350 olfactory receptor subtypes that work in various combinations to allow us to sense about 10,000 different odors. Compare that to mice, for example, which have about 1,300 olfactory receptor types, and therefore probably sense more odors. Both odors and tastes involve molecules that stimulate specific chemoreceptors. Although humans commonly distinguish taste as one sense and smell as another, they work together to create the perception of flavor. A person’s perception of flavor is reduced if he or she has congested nasal passages.
Odorants (odor molecules) enter the nose and dissolve in the olfactory epithelium, the mucosa at the back of the nasal cavity (as illustrated in (Figure)). The olfactory epithelium is a collection of specialized olfactory receptors in the back of the nasal cavity that spans an area about 5 cm2 in humans. Recall that sensory cells are neurons. An olfactory receptor, which is a dendrite of a specialized neuron, responds when it binds certain molecules inhaled from the environment by sending impulses directly to the olfactory bulb of the brain. Humans have about 12 million olfactory receptors, distributed among hundreds of different receptor types that respond to different odors. Twelve million seems like a large number of receptors, but compare that to other animals: rabbits have about 100 million, most dogs have about 1 billion, and bloodhounds—dogs selectively bred for their sense of smell—have about 4 billion. The overall size of the olfactory epithelium also differs between species, with that of bloodhounds, for example, being many times larger than that of humans.
Olfactory neurons are bipolar neurons (neurons with two processes from the cell body). Each neuron has a single dendrite buried in the olfactory epithelium, and extending from this dendrite are 5 to 20 receptor-laden, hair-like cilia that trap odorant molecules. The sensory receptors on the cilia are proteins, and it is the variations in their amino acid chains that make the receptors sensitive to different odorants. Each olfactory sensory neuron has only one type of receptor on its cilia, and the receptors are specialized to detect specific odorants, so the bipolar neurons themselves are specialized. When an odorant binds with a receptor that recognizes it, the sensory neuron associated with the receptor is stimulated. Olfactory stimulation is the only sensory information that directly reaches the cerebral cortex, whereas other sensations are relayed through the thalamus.
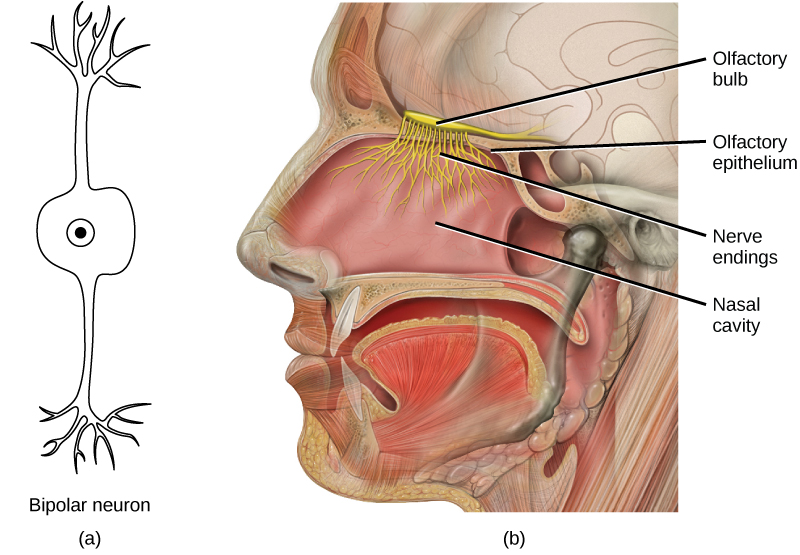
PheromonesA pheromone is a chemical released by an animal that affects the behavior or physiology of animals of the same species. Pheromonal signals can have profound effects on animals that inhale them, but pheromones apparently are not consciously perceived in the same way as other odors. There are several different types of pheromones, which are released in urine or as glandular secretions. Certain pheromones are attractants to potential mates, others are repellants to potential competitors of the same sex, and still others play roles in mother-infant attachment. Some pheromones can also influence the timing of puberty, modify reproductive cycles, and even prevent embryonic implantation. While the roles of pheromones in many nonhuman species are important, pheromones have become less important in human behavior over evolutionary time compared to their importance to organisms with more limited behavioral repertoires.
The vomeronasal organ (VNO, or Jacobson’s organ) is a tubular, fluid-filled, olfactory organ present in many vertebrate animals that sits adjacent to the nasal cavity. It is very sensitive to pheromones and is connected to the nasal cavity by a duct. When molecules dissolve in the mucosa of the nasal cavity, they then enter the VNO where the pheromone molecules among them bind with specialized pheromone receptors. Upon exposure to pheromones from their own species or others, many animals, including cats, may display the flehmen response (shown in (Figure)), a curling of the upper lip that helps pheromone molecules enter the VNO.
Pheromonal signals are sent, not to the main olfactory bulb, but to a different neural structure that projects directly to the amygdala (recall that the amygdala is a brain center important in emotional reactions, such as fear). The pheromonal signal then continues to areas of the hypothalamus that are key to reproductive physiology and behavior. While some scientists assert that the VNO is apparently functionally vestigial in humans, even though there is a similar structure located near human nasal cavities, others are researching it as a possible functional system that may, for example, contribute to synchronization of menstrual cycles in women living in close proximity.

Detecting a taste (gustation) is fairly similar to detecting an odor (olfaction), given that both taste and smell rely on chemical receptors being stimulated by certain molecules. The primary organ of taste is the taste bud. A taste bud is a cluster of gustatory receptors (taste cells) that are located within the bumps on the tongue called papillae (singular: papilla) (illustrated in (Figure)). There are several structurally distinct papillae. Filiform papillae, which are located across the tongue, are tactile, providing friction that helps the tongue move substances, and contain no taste cells. In contrast, fungiform papillae, which are located mainly on the anterior two-thirds of the tongue, each contain one to eight taste buds and also have receptors for pressure and temperature. The large circumvallate papillae contain up to 100 taste buds and form a V near the posterior margin of the tongue.
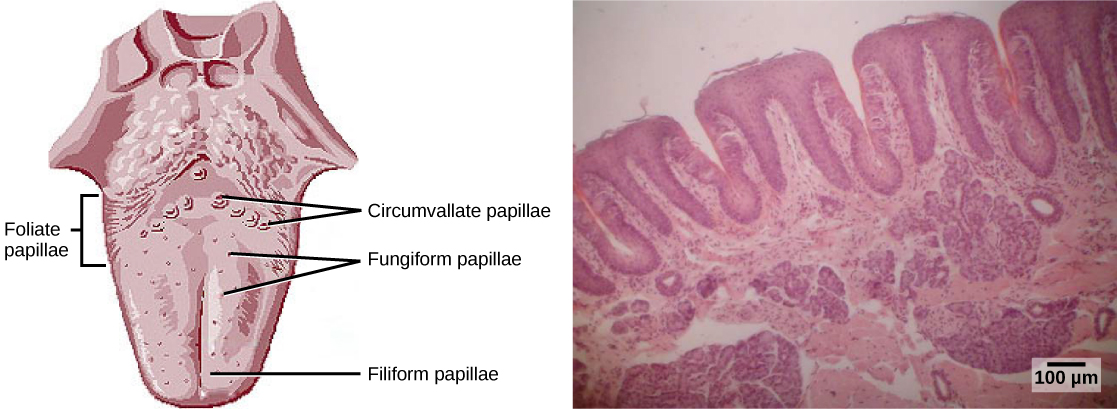
In addition to those two types of chemically and mechanically sensitive papillae are foliate papillae—leaf-like papillae located in parallel folds along the edges and toward the back of the tongue, as seen in the (Figure) micrograph. Foliate papillae contain about 1,300 taste buds within their folds. Finally, there are circumvallate papillae, which are wall-like papillae in the shape of an inverted “V” at the back of the tongue. Each of these papillae is surrounded by a groove and contains about 250 taste buds.
Each taste bud’s taste cells are replaced every 10 to 14 days. These are elongated cells with hair-like processes called microvilli at the tips that extend into the taste bud pore (illustrated in (Figure)). Food molecules (tastants) are dissolved in saliva, and they bind with and stimulate the receptors on the microvilli. The receptors for tastants are located across the outer portion and front of the tongue, outside of the middle area where the filiform papillae are most prominent.
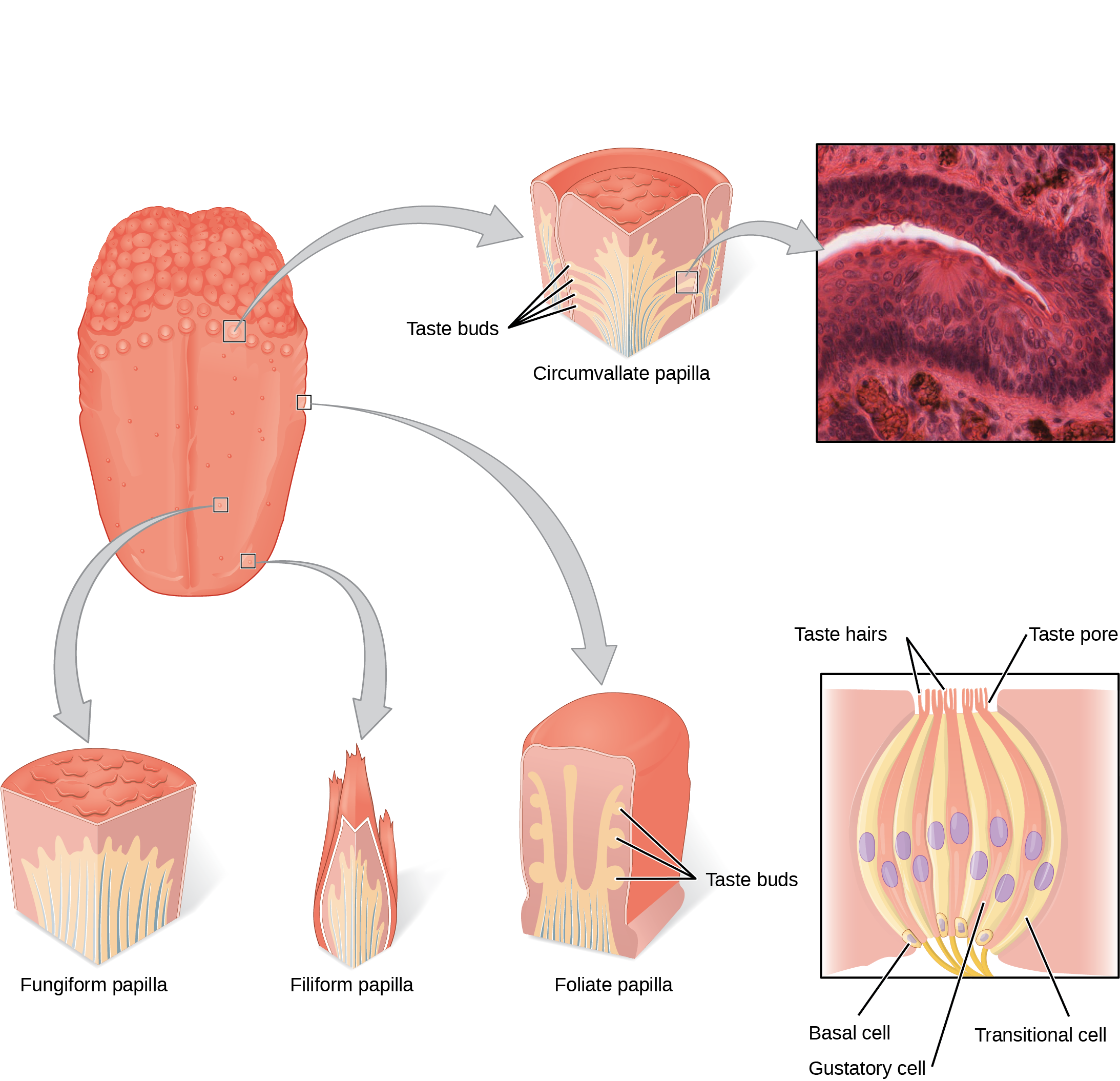
In humans, there are five primary tastes, and each taste has only one corresponding type of receptor. Thus, like olfaction, each receptor is specific to its stimulus (tastant). Transduction of the five tastes happens through different mechanisms that reflect the molecular composition of the tastant. A salty tastant (containing NaCl) provides the sodium ions (Na+) that enter the taste neurons and excite them directly. Sour tastants are acids and belong to the thermoreceptor protein family. Binding of an acid or other sour-tasting molecule triggers a change in the ion channel and these increase hydrogen ion (H+) concentrations in the taste neurons, thus depolarizing them. Sweet, bitter, and umami tastants require a G-protein coupled receptor. These tastants bind to their respective receptors, thereby exciting the specialized neurons associated with them.
Both tasting abilities and sense of smell change with age. In humans, the senses decline dramatically by age 50 and continue to decline. A child may find a food to be too spicy, whereas an elderly person may find the same food to be bland and unappetizing.
View this animation that shows how the sense of taste works.
Olfactory neurons project from the olfactory epithelium to the olfactory bulb as thin, unmyelinated axons. The olfactory bulb is composed of neural clusters called glomeruli, and each glomerulus receives signals from one type of olfactory receptor, so each glomerulus is specific to one odorant. From glomeruli, olfactory signals travel directly to the olfactory cortex and then to the frontal cortex and the thalamus. Recall that this is a different path from most other sensory information, which is sent directly to the thalamus before ending up in the cortex. Olfactory signals also travel directly to the amygdala, thereafter reaching the hypothalamus, thalamus, and frontal cortex. The last structure that olfactory signals directly travel to is a cortical center in the temporal lobe structure important in spatial, autobiographical, declarative, and episodic memories. Olfaction is finally processed by areas of the brain that deal with memory, emotions, reproduction, and thought.
Taste neurons project from taste cells in the tongue, esophagus, and palate to the medulla, in the brainstem. From the medulla, taste signals travel to the thalamus and then to the primary gustatory cortex. Information from different regions of the tongue is segregated in the medulla, thalamus, and cortex.
There are five primary tastes in humans: sweet, sour, bitter, salty, and umami. Each taste has its own receptor type that responds only to that taste. Tastants enter the body and are dissolved in saliva. Taste cells are located within taste buds, which are found on three of the four types of papillae in the mouth.
Regarding olfaction, there are many thousands of odorants, but humans detect only about 10,000. Like taste receptors, olfactory receptors are each responsive to only one odorant. Odorants dissolve in nasal mucosa, where they excite their corresponding olfactory sensory cells. When these cells detect an odorant, they send their signals to the main olfactory bulb and then to other locations in the brain, including the olfactory cortex.
Which of the following has the fewest taste receptors?
D
How many different taste molecules do taste cells each detect?
A
Salty foods activate the taste cells by _____.
A
All sensory signals except _____ travel to the _____ in the brain before the cerebral cortex.
B
How is the ability to recognize the umami taste an evolutionary advantage?
C
From the perspective of the recipient of the signal, in what ways do pheromones differ from other odorants?
Pheromones may not be consciously perceived, and pheromones can have direct physiological and behavioral effects on their recipients.
What might be the effect on an animal of not being able to perceive taste?
The animal might not be able to recognize the differences in food sources and thus might not be able to discriminate between spoiled food and safe food or between foods that contain necessary nutrients, such as proteins, and foods that do not.
A few recent cancer detection studies have used trained dogs to detect lung cancer in urine samples. What is the hypothesis behind this study? Why are dogs a better choice of detectors in this study than humans?
These studies rely on the dogs’ olfactory senses. The hypothesis behind the study is that the dogs are capable of detecting volatile compounds (evaporating scent molecules) that are only produced in people with cancer. The dogs are a better choice because their sense of smell is more sensitive due to the increased number of olfactory receptors.
Chapter 36 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Audition, or hearing, is important to humans and to other animals for many different interactions. It enables an organism to detect and receive information about danger, such as an approaching predator, and to participate in communal exchanges like those concerning territories or mating. On the other hand, although it is physically linked to the auditory system, the vestibular system is not involved in hearing. Instead, an animal’s vestibular system detects its own movement, both linear and angular acceleration and deceleration, and balance.
Auditory stimuli are sound waves, which are mechanical, pressure waves that move through a medium, such as air or water. There are no sound waves in a vacuum since there are no air molecules to move in waves. The speed of sound waves differs, based on altitude, temperature, and medium, but at sea level and a temperature of 20º C (68º F), sound waves travel in the air at about 343 meters per second.
As is true for all waves, there are four main characteristics of a sound wave: frequency, wavelength, period, and amplitude. Frequency is the number of waves per unit of time, and in sound is heard as pitch. High-frequency (≥15.000Hz) sounds are higher-pitched (short wavelength) than low-frequency (long wavelengths; ≤100Hz) sounds. Frequency is measured in cycles per second, and for sound, the most commonly used unit is hertz (Hz), or cycles per second. Most humans can perceive sounds with frequencies between 30 and 20,000 Hz. Women are typically better at hearing high frequencies, but everyone’s ability to hear high frequencies decreases with age. Dogs detect up to about 40,000 Hz; cats, 60,000 Hz; bats, 100,000 Hz; and dolphins 150,000 Hz, and American shad (Alosa sapidissima), a fish, can hear 180,000 Hz. Those frequencies above the human range are called ultrasound.
Amplitude, or the dimension of a wave from peak to trough, in sound is heard as volume and is illustrated in (Figure). The sound waves of louder sounds have greater amplitude than those of softer sounds. For sound, volume is measured in decibels (dB). The softest sound that a human can hear is the zero point. Humans speak normally at 60 decibels.
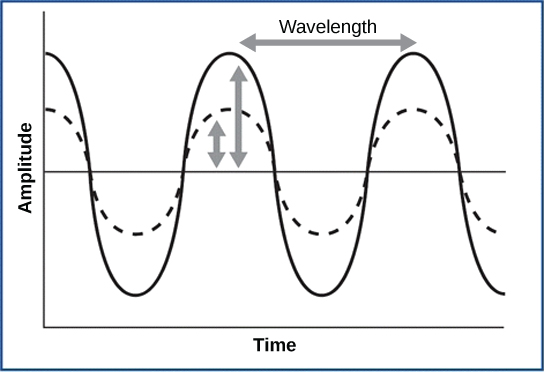
In mammals, sound waves are collected by the external, cartilaginous part of the ear called the pinna, then travel through the auditory canal and cause vibration of the thin diaphragm called the tympanum or ear drum, the innermost part of the outer ear (illustrated in (Figure)). Interior to the tympanum is the middle ear. The middle ear holds three small bones called the ossicles, which transfer energy from the moving tympanum to the inner ear. The three ossicles are the malleus (also known as the hammer), the incus (the anvil), and stapes (the stirrup). The aptly named stapes looks very much like a stirrup. The three ossicles are unique to mammals, and each plays a role in hearing. The malleus attaches at three points to the interior surface of the tympanic membrane. The incus attaches the malleus to the stapes. In humans, the stapes is not long enough to reach the tympanum. If we did not have the malleus and the incus, then the vibrations of the tympanum would never reach the inner ear. These bones also function to collect force and amplify sounds. The ear ossicles are homologous to bones in a fish mouth: the bones that support gills in fish are thought to be adapted for use in the vertebrate ear over evolutionary time. Many animals (frogs, reptiles, and birds, for example) use the stapes of the middle ear to transmit vibrations to the middle ear.
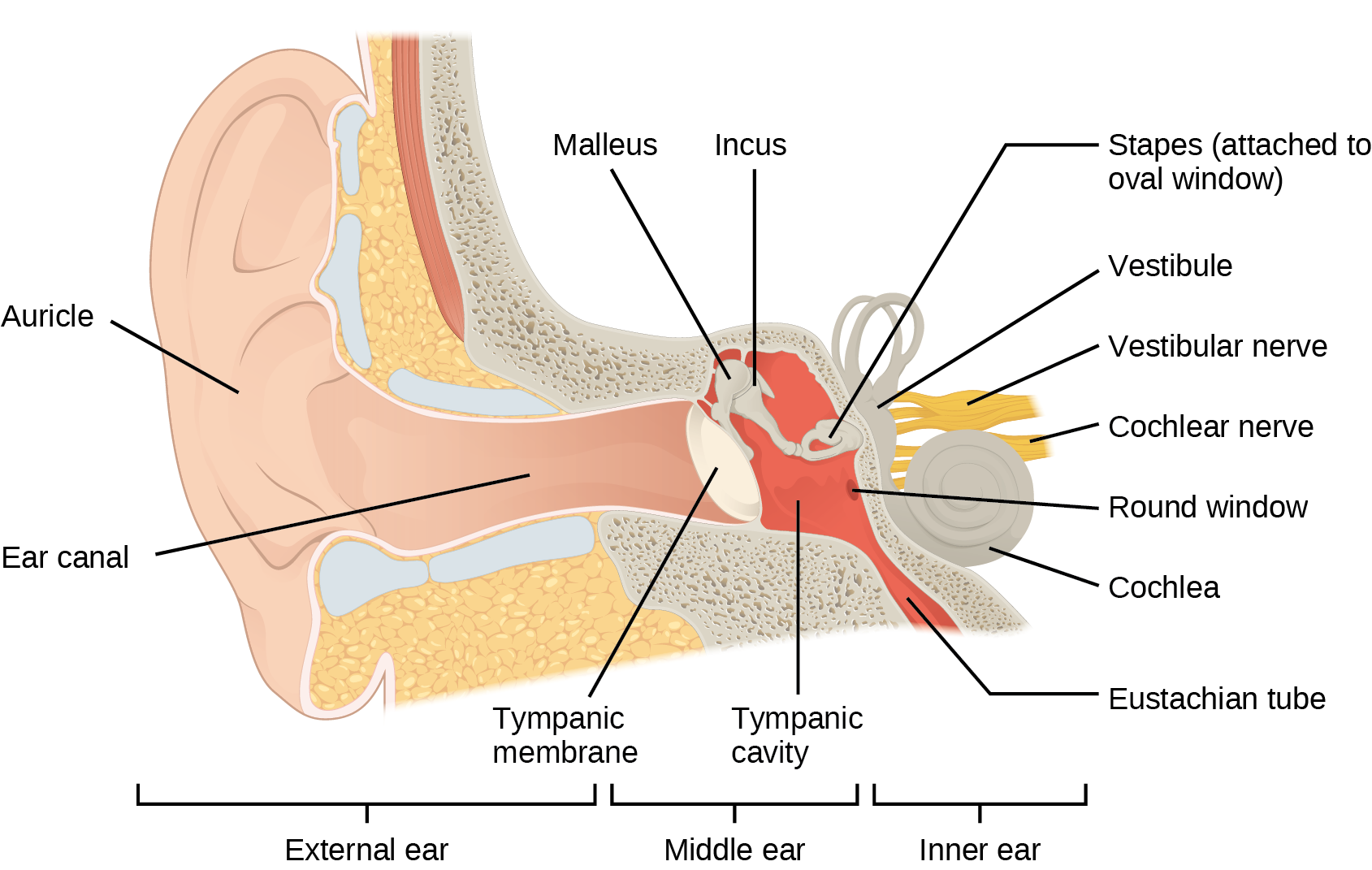
Vibrating objects, such as vocal cords, create sound waves or pressure waves in the air. When these pressure waves reach the ear, the ear transduces this mechanical stimulus (pressure wave) into a nerve impulse (electrical signal) that the brain perceives as sound. The pressure waves strike the tympanum, causing it to vibrate. The mechanical energy from the moving tympanum transmits the vibrations to the three bones of the middle ear. The stapes transmits the vibrations to a thin diaphragm called the oval window, which is the outermost structure of the inner ear. The structures of the inner ear are found in the labyrinth, a bony, hollow structure that is the most interior portion of the ear. Here, the energy from the sound wave is transferred from the stapes through the flexible oval window and to the fluid of the cochlea. The vibrations of the oval window create pressure waves in the fluid (perilymph) inside the cochlea. The cochlea is a whorled structure, like the shell of a snail, and it contains receptors for transduction of the mechanical wave into an electrical signal (as illustrated in (Figure)). Inside the cochlea, the basilar membrane is a mechanical analyzer that runs the length of the cochlea, curling toward the cochlea’s center.
The mechanical properties of the basilar membrane change along its length, such that it is thicker, tauter, and narrower at the outside of the whorl (where the cochlea is largest), and thinner, floppier, and broader toward the apex, or center, of the whorl (where the cochlea is smallest). Different regions of the basilar membrane vibrate according to the frequency of the sound wave conducted through the fluid in the cochlea. For these reasons, the fluid-filled cochlea detects different wave frequencies (pitches) at different regions of the membrane. When the sound waves in the cochlear fluid contact the basilar membrane, it flexes back and forth in a wave-like fashion. Above the basilar membrane is the tectorial membrane.
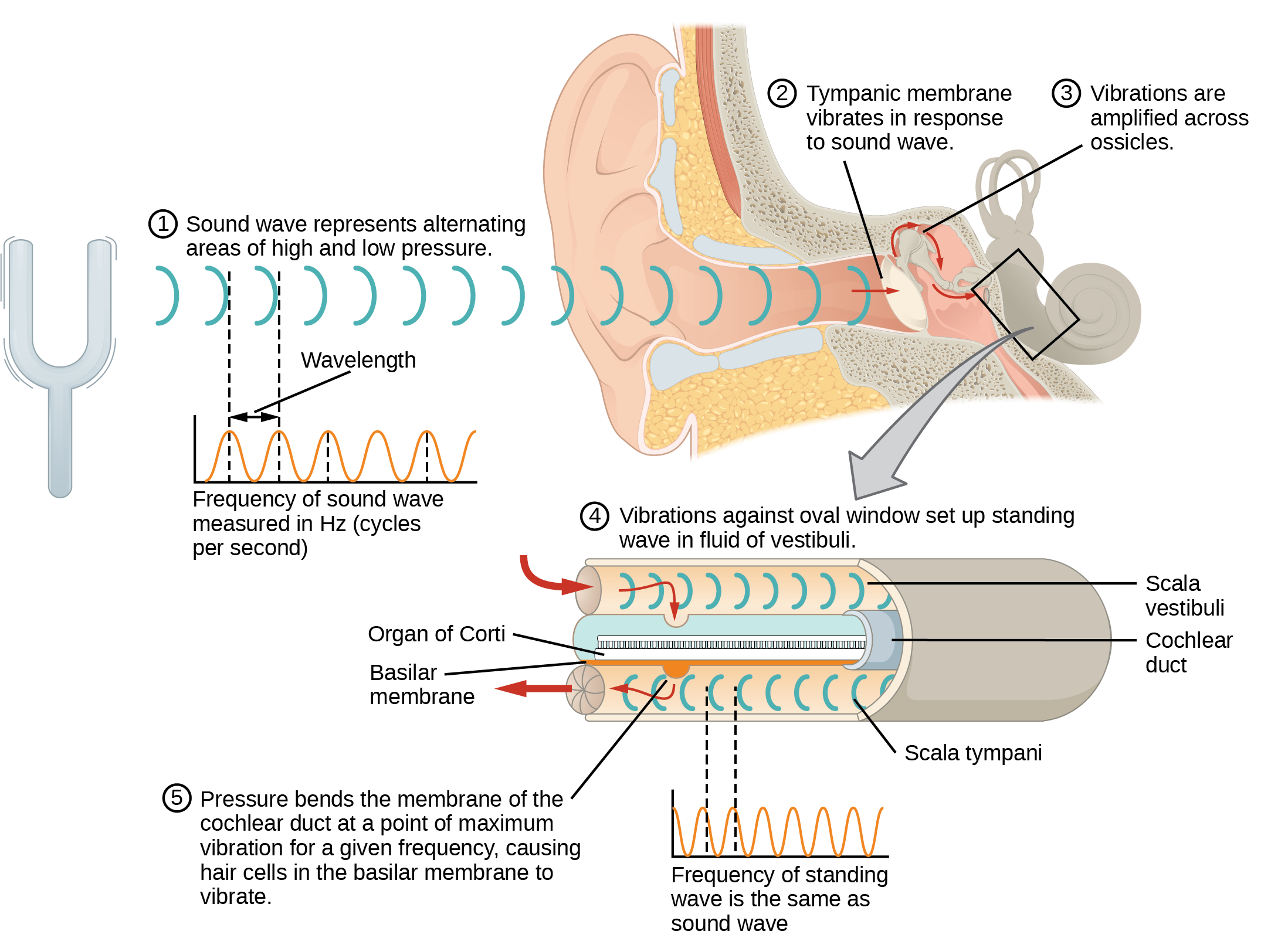
Cochlear implants can restore hearing in people who have a nonfunctional cochlea. The implant consists of a microphone that picks up sound. A speech processor selects sounds in the range of human speech, and a transmitter converts these sounds to electrical impulses, which are then sent to the auditory nerve. Which of the following types of hearing loss would not be restored by a cochlear implant?
<!–<para>abcB–>
The site of transduction is in the organ of Corti (spiral organ). It is composed of hair cells held in place above the basilar membrane like flowers projecting up from soil, with their exposed short, hair-like stereocilia contacting or embedded in the tectorial membrane above them. The inner hair cells are the primary auditory receptors and exist in a single row, numbering approximately 3,500. The stereocilia from inner hair cells extend into small dimples on the tectorial membrane’s lower surface. The outer hair cells are arranged in three or four rows. They number approximately 12,000, and they function to fine tune incoming sound waves. The longer stereocilia that project from the outer hair cells actually attach to the tectorial membrane. All of the stereocilia are mechanoreceptors, and when bent by vibrations they respond by opening a gated ion channel (refer to (Figure)). As a result, the hair cell membrane is depolarized, and a signal is transmitted to the chochlear nerve. Intensity (volume) of sound is determined by how many hair cells at a particular location are stimulated.
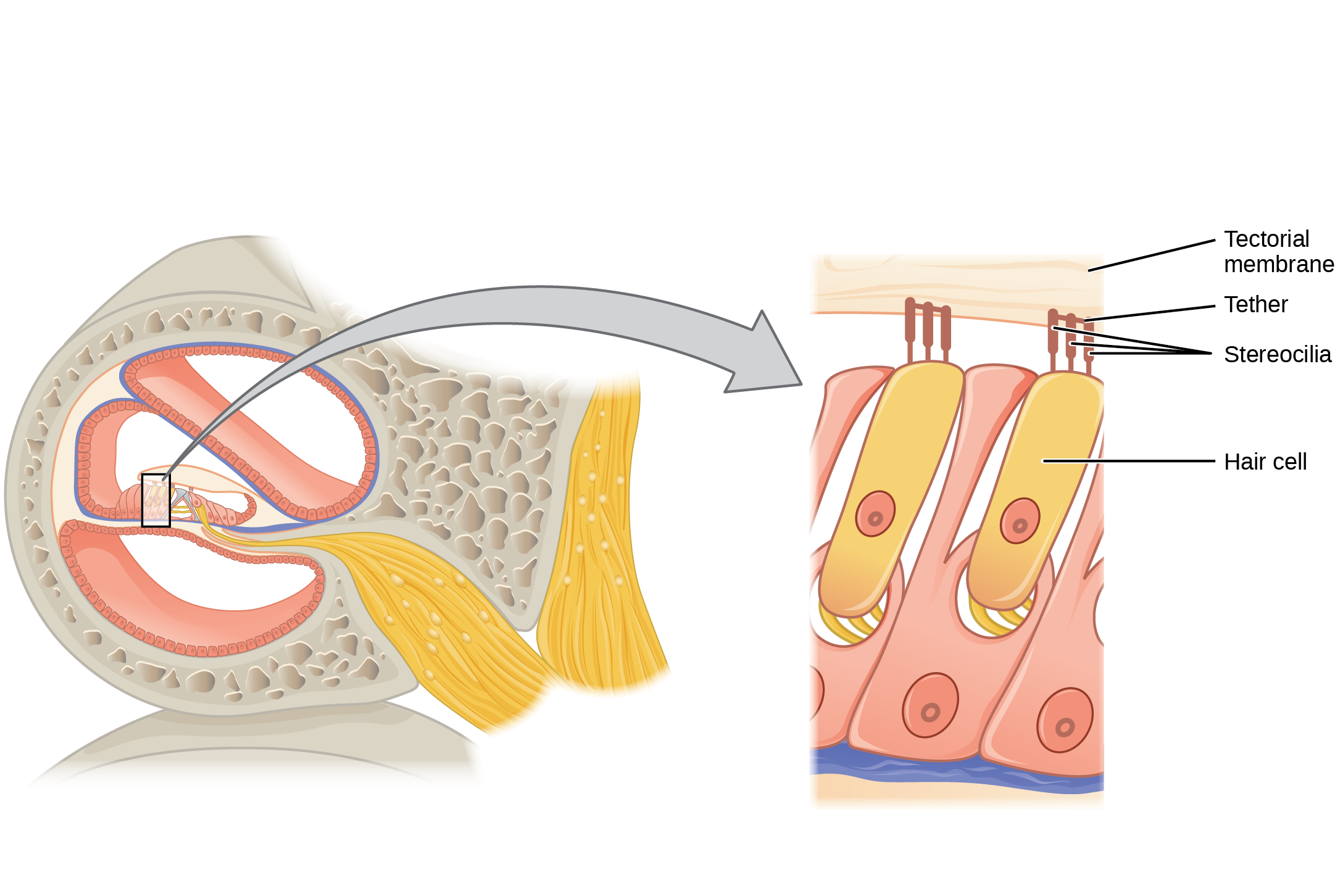
The hair cells are arranged on the basilar membrane in an orderly way. The basilar membrane vibrates in different regions, according to the frequency of the sound waves impinging on it. Likewise, the hair cells that lay above it are most sensitive to a specific frequency of sound waves. Hair cells can respond to a small range of similar frequencies, but they require stimulation of greater intensity to fire at frequencies outside of their optimal range. The difference in response frequency between adjacent inner hair cells is about 0.2 percent. Compare that to adjacent piano strings, which are about six percent different. Place theory, which is the model for how biologists think pitch detection works in the human ear, states that high frequency sounds selectively vibrate the basilar membrane of the inner ear near the entrance port (the oval window). Lower frequencies travel farther along the membrane before causing appreciable excitation of the membrane. The basic pitch-determining mechanism is based on the location along the membrane where the hair cells are stimulated. The place theory is the first step toward an understanding of pitch perception. Considering the extreme pitch sensitivity of the human ear, it is thought that there must be some auditory “sharpening” mechanism to enhance the pitch resolution.
When sound waves produce fluid waves inside the cochlea, the basilar membrane flexes, bending the stereocilia that attach to the tectorial membrane. Their bending results in action potentials in the hair cells, and auditory information travels along the neural endings of the bipolar neurons of the hair cells (collectively, the auditory nerve) to the brain. When the hairs bend, they release an excitatory neurotransmitter at a synapse with a sensory neuron, which then conducts action potentials to the central nervous system. The cochlear branch of the vestibulocochlear cranial nerve sends information on hearing. The auditory system is very refined, and there is some modulation or “sharpening” built in. The brain can send signals back to the cochlea, resulting in a change of length in the outer hair cells, sharpening or dampening the hair cells’ response to certain frequencies.
Watch an animation of sound entering the outer ear, moving through the ear structure, stimulating cochlear nerve impulses, and eventually sending signals to the temporal lobe.
The inner hair cells are most important for conveying auditory information to the brain. About 90 percent of the afferent neurons carry information from inner hair cells, with each hair cell synapsing with 10 or so neurons. Outer hair cells connect to only 10 percent of the afferent neurons, and each afferent neuron innervates many hair cells. The afferent, bipolar neurons that convey auditory information travel from the cochlea to the medulla, through the pons and midbrain in the brainstem, finally reaching the primary auditory cortex in the temporal lobe.
The stimuli associated with the vestibular system are linear acceleration (gravity) and angular acceleration and deceleration. Gravity, acceleration, and deceleration are detected by evaluating the inertia on receptive cells in the vestibular system. Gravity is detected through head position. Angular acceleration and deceleration are expressed through turning or tilting of the head.
The vestibular system has some similarities with the auditory system. It utilizes hair cells just like the auditory system, but it excites them in different ways. There are five vestibular receptor organs in the inner ear: the utricle, the saccule, and three semicircular canals. Together, they make up what’s known as the vestibular labyrinth that is shown in (Figure). The utricle and saccule respond to acceleration in a straight line, such as gravity. The roughly 30,000 hair cells in the utricle and 16,000 hair cells in the saccule lie below a gelatinous layer, with their stereocilia projecting into the gelatin. Embedded in this gelatin are calcium carbonate crystals—like tiny rocks. When the head is tilted, the crystals continue to be pulled straight down by gravity, but the new angle of the head causes the gelatin to shift, thereby bending the stereocilia. The bending of the stereocilia stimulates the neurons, and they signal to the brain that the head is tilted, allowing the maintenance of balance. It is the vestibular branch of the vestibulocochlear cranial nerve that deals with balance.
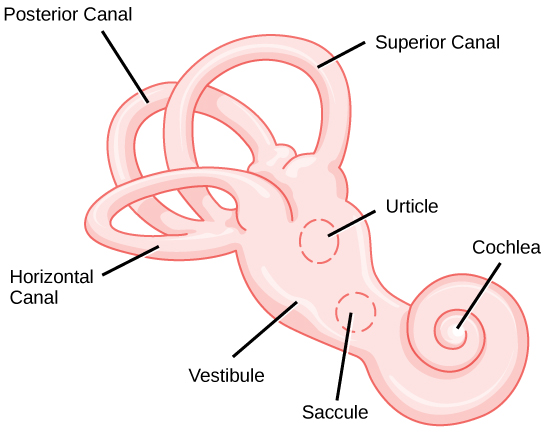
The fluid-filled semicircular canals are tubular loops set at oblique angles. They are arranged in three spatial planes. The base of each canal has a swelling that contains a cluster of hair cells. The hairs project into a gelatinous cap called the cupula and monitor angular acceleration and deceleration from rotation. They would be stimulated by driving your car around a corner, turning your head, or falling forward. One canal lies horizontally, while the other two lie at about 45 degree angles to the horizontal axis, as illustrated in (Figure). When the brain processes input from all three canals together, it can detect angular acceleration or deceleration in three dimensions. When the head turns, the fluid in the canals shifts, thereby bending stereocilia and sending signals to the brain. Upon cessation accelerating or decelerating—or just moving—the movement of the fluid within the canals slows or stops. For example, imagine holding a glass of water. When moving forward, water may splash backwards onto the hand, and when motion has stopped, water may splash forward onto the fingers. While in motion, the water settles in the glass and does not splash. Note that the canals are not sensitive to velocity itself, but to changes in velocity, so moving forward at 60mph with your eyes closed would not give the sensation of movement, but suddenly accelerating or braking would stimulate the receptors.
Hair cells from the utricle, saccule, and semicircular canals also communicate through bipolar neurons to the cochlear nucleus in the medulla. Cochlear neurons send descending projections to the spinal cord and ascending projections to the pons, thalamus, and cerebellum. Connections to the cerebellum are important for coordinated movements. There are also projections to the temporal cortex, which account for feelings of dizziness; projections to autonomic nervous system areas in the brainstem, which account for motion sickness; and projections to the primary somatosensory cortex, which monitors subjective measurements of the external world and self-movement. People with lesions in the vestibular area of the somatosensory cortex see vertical objects in the world as being tilted. Finally, the vestibular signals project to certain optic muscles to coordinate eye and head movements.
Click through this interactive tutorial to review the parts of the ear and how they function to process sound.
Audition is important for territory defense, predation, predator defense, and communal exchanges. The vestibular system, which is not auditory, detects linear acceleration and angular acceleration and deceleration. Both the auditory system and vestibular system use hair cells as their receptors.
Auditory stimuli are sound waves. The sound wave energy reaches the outer ear (pinna, canal, tympanum), and vibrations of the tympanum send the energy to the middle ear. The middle ear bones shift and the stapes transfers mechanical energy to the oval window of the fluid-filled inner ear cochlea. Once in the cochlea, the energy causes the basilar membrane to flex, thereby bending the stereocilia on receptor hair cells. This activates the receptors, which send their auditory neural signals to the brain.
The vestibular system has five parts that work together to provide the sense of direction, thus helping to maintain balance. The utricle and saccule measure head orientation: their calcium carbonate crystals shift when the head is tilted, thereby activating hair cells. The semicircular canals work similarly, such that when the head is turned, the fluid in the canals bends stereocilia on hair cells. The vestibular hair cells also send signals to the thalamus and to the somatosensory cortex, but also to the cerebellum, the structure above the brainstem that plays a large role in timing and coordination of movement.
(Figure) Cochlear implants can restore hearing in people who have a nonfunctional cochlea. The implant consists of a microphone that picks up sound. A speech processor selects sounds in the range of human speech, and a transmitter converts these sounds to electrical impulses, which are then sent to the auditory nerve. Which of the following types of hearing loss would not be restored by a cochlear implant?
(Figure) B
In sound, pitch is measured in _____, and volume is measured in _____.
D
Auditory hair cells are indirectly anchored to the _____.
A
Which of the following are found both in the auditory system and the vestibular system?
B
Benign Paroxysmal Positional Vertigo is a disorder where some of the calcium carbonate crystals in the utricle migrate into the semicircular canals. Why does this condition cause periods of dizziness?
B
How would a rise in altitude likely affect the speed of a sound transmitted through air? Why?
The sound would slow down, because it is transmitted through the particles (gas) and there are fewer particles (lower density) at higher altitudes.
How might being in a place with less gravity than Earth has (such as Earth’s moon) affect vestibular sensation, and why?
Because vestibular sensation relies on gravity’s effects on tiny crystals in the inner ear, a situation of reduced gravity would likely impair vestibular sensation.
How does the structure of the ear allow a person to determine where a sound originates?
The first step in processing a sound in humans is the collection of sound by the pinna. When a person encounters a sound, the pinna on both sides of the head will collect the vibrations. Since the waves originate from a single site, the two pinnae will not collect the sound at the exact same time. When the sound is processed by the auditory system, the brain is able to use this slight difference in timing to determine the location of the sound.
Chapter 36 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Vision is the ability to detect light patterns from the outside environment and interpret them into images. Animals are bombarded with sensory information, and the sheer volume of visual information can be problematic. Fortunately, the visual systems of species have evolved to attend to the most-important stimuli. The importance of vision to humans is further substantiated by the fact that about one-third of the human cerebral cortex is dedicated to analyzing and perceiving visual information.
As with auditory stimuli, light travels in waves. The compression waves that compose sound must travel in a medium—a gas, a liquid, or a solid. In contrast, light is composed of electromagnetic waves and needs no medium; light can travel in a vacuum ((Figure)). The behavior of light can be discussed in terms of the behavior of waves and also in terms of the behavior of the fundamental unit of light—a packet of electromagnetic radiation called a photon. A glance at the electromagnetic spectrum shows that visible light for humans is just a small slice of the entire spectrum, which includes radiation that we cannot see as light because it is below the frequency of visible red light and above the frequency of visible violet light.
Certain variables are important when discussing perception of light. Wavelength (which varies inversely with frequency) manifests itself as hue. Light at the red end of the visible spectrum has longer wavelengths (and is lower frequency), while light at the violet end has shorter wavelengths (and is higher frequency). The wavelength of light is expressed in nanometers (nm); one nanometer is one billionth of a meter. Humans perceive light that ranges between approximately 380 nm and 740 nm. Some other animals, though, can detect wavelengths outside of the human range. For example, bees see near-ultraviolet light in order to locate nectar guides on flowers, and some non-avian reptiles sense infrared light (heat that prey gives off).
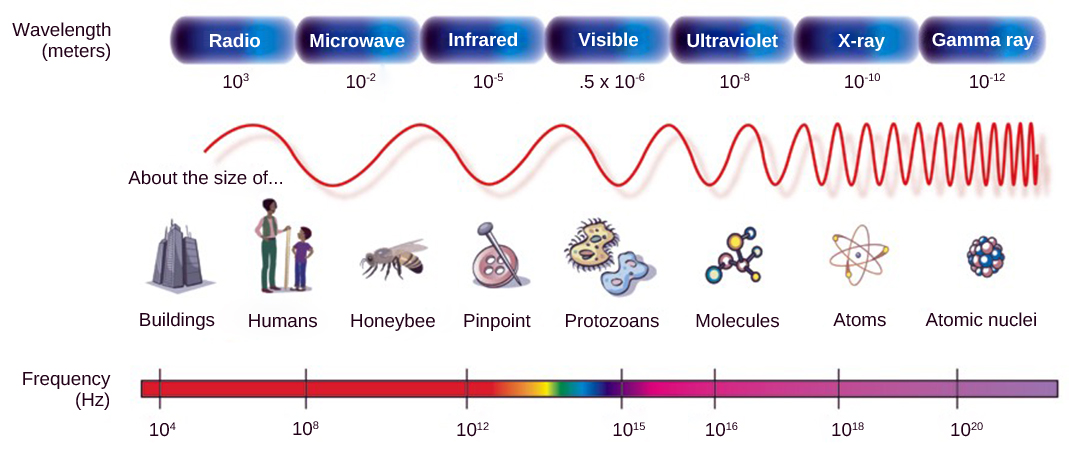
Wave amplitude is perceived as luminous intensity, or brightness. The standard unit of intensity of light is the candela, which is approximately the luminous intensity of one common candle.
Light waves travel 299,792 km per second in a vacuum, (and somewhat slower in various media such as air and water), and those waves arrive at the eye as long (red), medium (green), and short (blue) waves. What is termed “white light” is light that is perceived as white by the human eye. This effect is produced by light that stimulates equally the color receptors in the human eye. The apparent color of an object is the color (or colors) that the object reflects. Thus a red object reflects the red wavelengths in mixed (white) light and absorbs all other wavelengths of light.
The photoreceptive cells of the eye, where transduction of light to nervous impulses occurs, are located in the retina (shown in (Figure)) on the inner surface of the back of the eye. But light does not impinge on the retina unaltered. It passes through other layers that process it so that it can be interpreted by the retina ((Figure)b). The cornea, the front transparent layer of the eye, and the crystalline lens, a transparent convex structure behind the cornea, both refract (bend) light to focus the image on the retina. The iris, which is conspicuous as the colored part of the eye, is a circular muscular ring lying between the lens and cornea that regulates the amount of light entering the eye. In conditions of high ambient light, the iris contracts, reducing the size of the pupil at its center. In conditions of low light, the iris relaxes and the pupil enlarges.
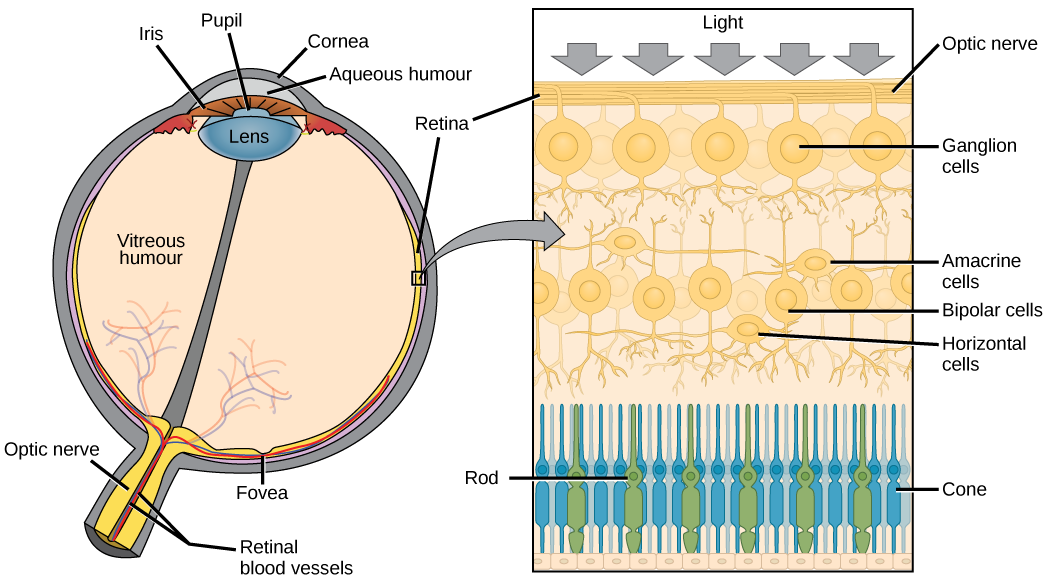
Which of the following statements about the human eye is false?
<!–<para id=”fs-idp172440208″>A–>
The main function of the lens is to focus light on the retina and fovea centralis. The lens is dynamic, focusing and re-focusing light as the eye rests on near and far objects in the visual field. The lens is operated by muscles that stretch it flat or allow it to thicken, changing the focal length of light coming through it to focus it sharply on the retina. With age comes the loss of the flexibility of the lens, and a form of farsightedness called presbyopia results. Presbyopia occurs because the image focuses behind the retina. Presbyopia is a deficit similar to a different type of farsightedness called hyperopia caused by an eyeball that is too short. For both defects, images in the distance are clear but images nearby are blurry. Myopia (nearsightedness) occurs when an eyeball is elongated and the image focus falls in front of the retina. In this case, images in the distance are blurry but images nearby are clear.
There are two types of photoreceptors in the retina: rods and cones, named for their general appearance as illustrated in (Figure). Rods are strongly photosensitive and are located in the outer edges of the retina. They detect dim light and are used primarily for peripheral and nighttime vision. Cones are weakly photosensitive and are located near the center of the retina. They respond to bright light, and their primary role is in daytime, color vision.
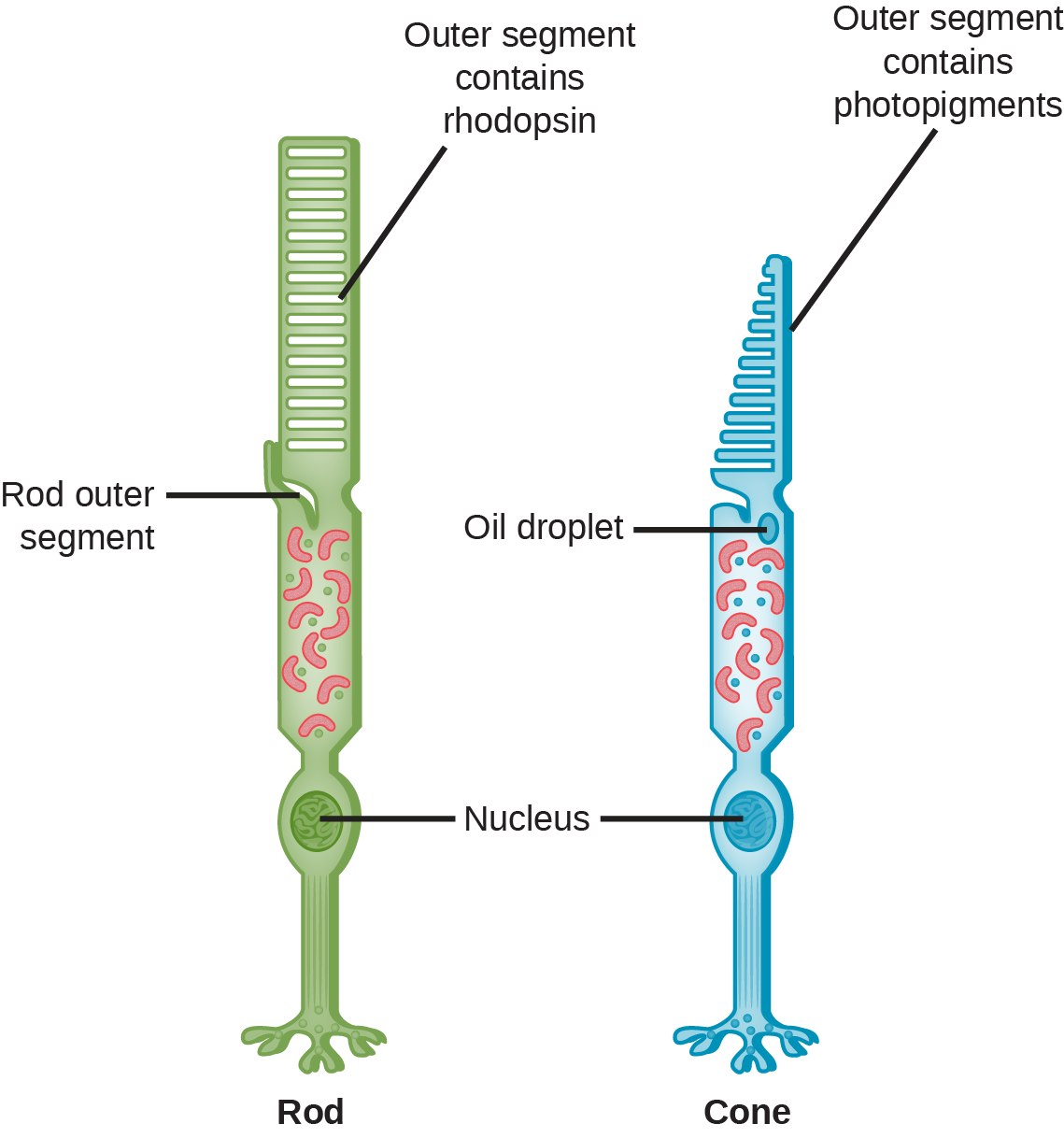
The fovea is the region in the center back of the eye that is responsible for acute vision. The fovea has a high density of cones. When you bring your gaze to an object to examine it intently in bright light, the eyes orient so that the object’s image falls on the fovea. However, when looking at a star in the night sky or other object in dim light, the object can be better viewed by the peripheral vision because it is the rods at the edges of the retina, rather than the cones at the center, that operate better in low light. In humans, cones far outnumber rods in the fovea.
Review the anatomical structure of the eye, clicking on each part to practice identification.
The rods and cones are the site of transduction of light to a neural signal. Both rods and cones contain photopigments. In vertebrates, the main photopigment, rhodopsin, has two main parts ((Figure)): an opsin, which is a membrane protein (in the form of a cluster of α-helices that span the membrane), and retinal—a molecule that absorbs light. When light hits a photoreceptor, it causes a shape change in the retinal, altering its structure from a bent (cis) form of the molecule to its linear (trans) isomer. This isomerization of retinal activates the rhodopsin, starting a cascade of events that ends with the closing of Na+ channels in the membrane of the photoreceptor. Thus, unlike most other sensory neurons (which become depolarized by exposure to a stimulus) visual receptors become hyperpolarized and thus driven away from threshold ((Figure)).
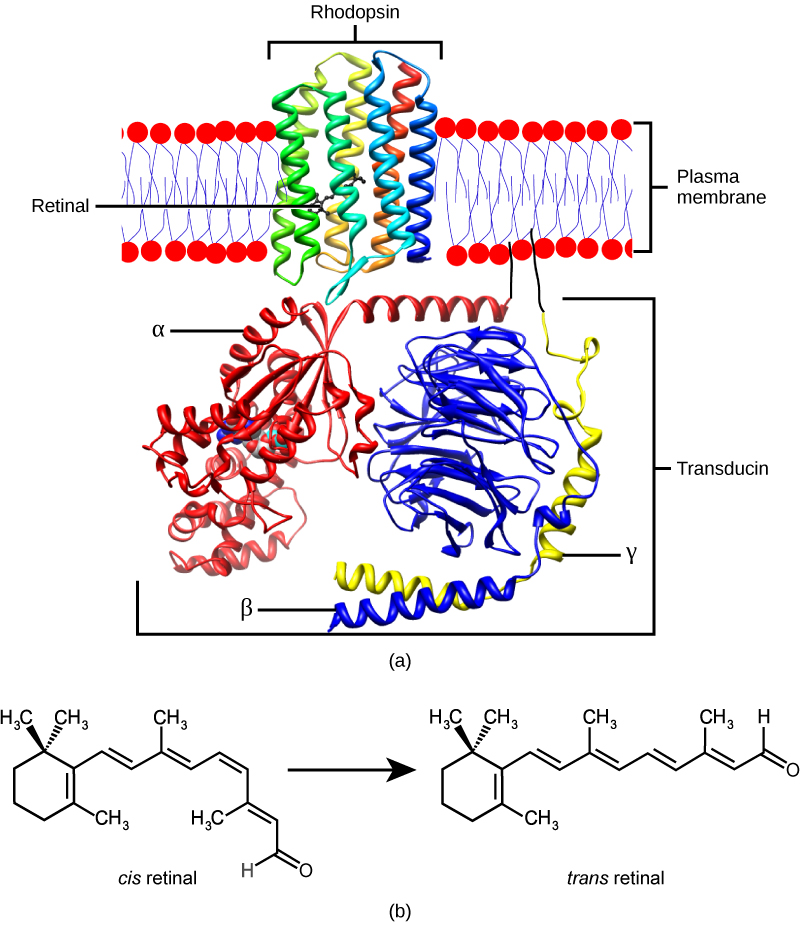
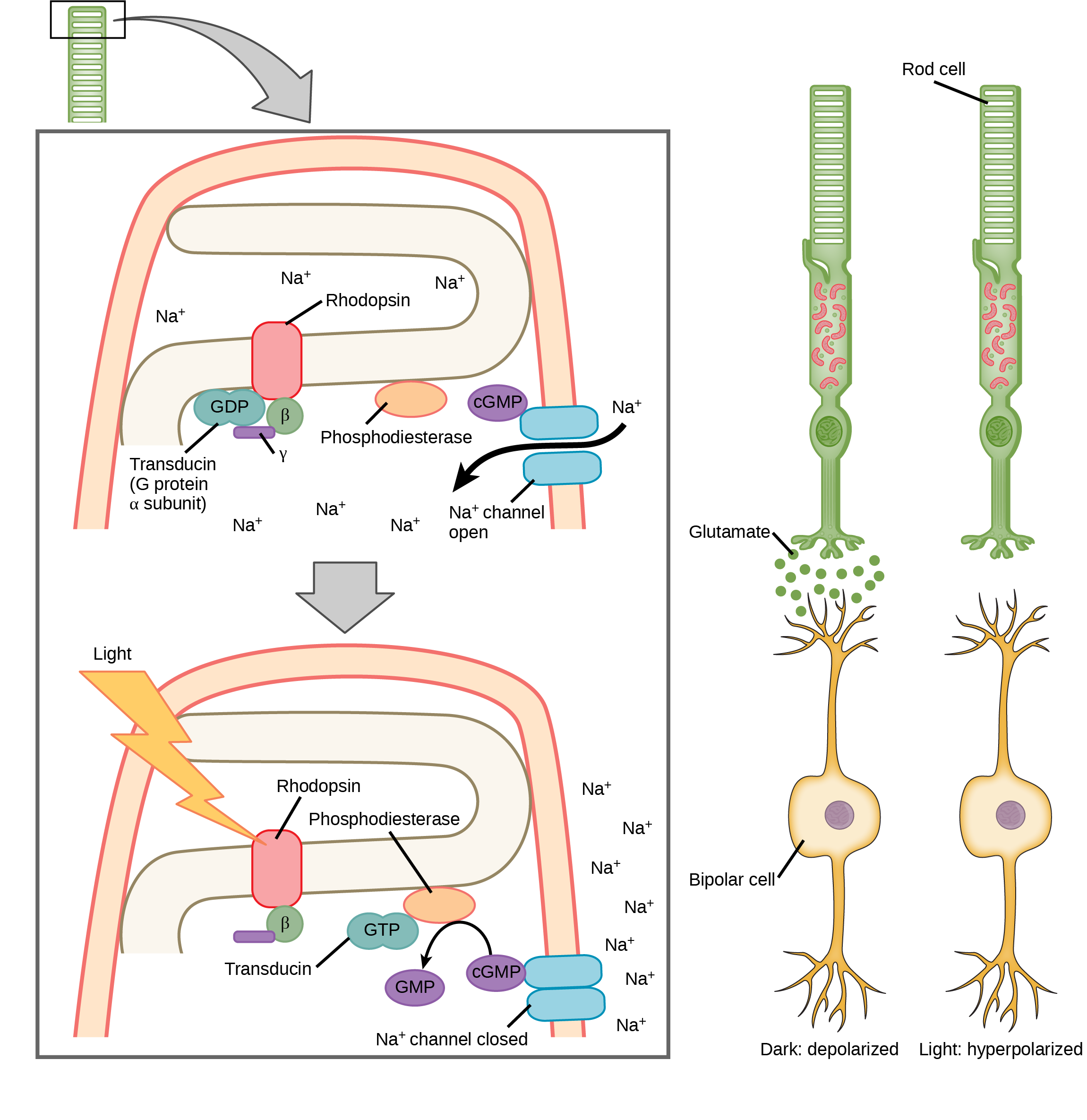
There are three types of cones (with different photopsins), and they differ in the wavelength to which they are most responsive, as shown in (Figure). Some cones are maximally responsive to short light waves of 420 nm, so they are called S cones (“S” for “short”); others respond maximally to waves of 530 nm (M cones, for “medium”); a third group responds maximally to light of longer wavelengths, at 560 nm (L, or “long” cones). With only one type of cone, color vision would not be possible, and a two-cone (dichromatic) system has limitations. Primates use a three-cone (trichromatic) system, resulting in full color vision.
The color we perceive is a result of the ratio of activity of our three types of cones. The colors of the visual spectrum, running from long-wavelength light to short, are red (700 nm), orange (600 nm), yellow (565 nm), green (497 nm), blue (470 nm), indigo (450 nm), and violet (425 nm). Humans have very sensitive perception of color and can distinguish about 500 levels of brightness, 200 different hues, and 20 steps of saturation, or about 2 million distinct colors.
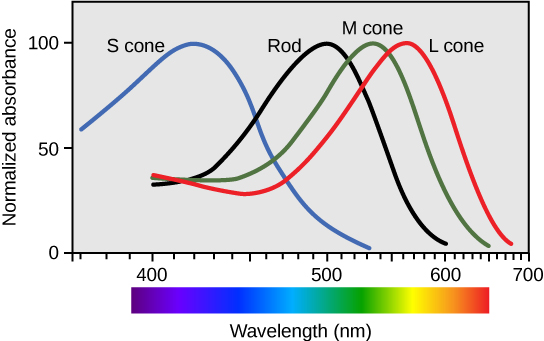
Visual signals leave the cones and rods, travel to the bipolar cells, and then to ganglion cells. A large degree of processing of visual information occurs in the retina itself, before visual information is sent to the brain.
Photoreceptors in the retina continuously undergo tonic activity. That is, they are always slightly active even when not stimulated by light. In neurons that exhibit tonic activity, the absence of stimuli maintains a firing rate at a baseline; while some stimuli increase firing rate from the baseline, and other stimuli decrease firing rate. In the absence of light, the bipolar neurons that connect rods and cones to ganglion cells are continuously and actively inhibited by the rods and cones. Exposure of the retina to light hyperpolarizes the rods and cones and removes their inhibition of bipolar cells. The now active bipolar cells in turn stimulate the ganglion cells, which send action potentials along their axons (which leave the eye as the optic nerve). Thus, the visual system relies on change in retinal activity, rather than the absence or presence of activity, to encode visual signals for the brain. Sometimes horizontal cells carry signals from one rod or cone to other photoreceptors and to several bipolar cells. When a rod or cone stimulates a horizontal cell, the horizontal cell inhibits more distant photoreceptors and bipolar cells, creating lateral inhibition. This inhibition sharpens edges and enhances contrast in the images by making regions receiving light appear lighter and dark surroundings appear darker. Amacrine cells can distribute information from one bipolar cell to many ganglion cells.
You can demonstrate this using an easy demonstration to “trick” your retina and brain about the colors you are observing in your visual field. Look fixedly at (Figure) for about 45 seconds. Then quickly shift your gaze to a sheet of blank white paper or a white wall. You should see an afterimage of the Norwegian flag in its correct colors. At this point, close your eyes for a moment, then reopen them, looking again at the white paper or wall; the afterimage of the flag should continue to appear as red, white, and blue. What causes this? According to an explanation called opponent process theory, as you gazed fixedly at the green, black, and yellow flag, your retinal ganglion cells that respond positively to green, black, and yellow increased their firing dramatically. When you shifted your gaze to the neutral white ground, these ganglion cells abruptly decreased their activity and the brain interpreted this abrupt downshift as if the ganglion cells were responding now to their “opponent” colors: red, white, and blue, respectively, in the visual field. Once the ganglion cells return to their baseline activity state, the false perception of color will disappear.

The myelinated axons of ganglion cells make up the optic nerves. Within the nerves, different axons carry different qualities of the visual signal. Some axons constitute the magnocellular (big cell) pathway, which carries information about form, movement, depth, and differences in brightness. Other axons constitute the parvocellular (small cell) pathway, which carries information on color and fine detail. Some visual information projects directly back into the brain, while other information crosses to the opposite side of the brain. This crossing of optical pathways produces the distinctive optic chiasma (Greek, for “crossing”) found at the base of the brain and allows us to coordinate information from both eyes.
Once in the brain, visual information is processed in several places, and its routes reflect the complexity and importance of visual information to humans and other animals. One route takes the signals to the thalamus, which serves as the routing station for all incoming sensory impulses except olfaction. In the thalamus, the magnocellular and parvocellular distinctions remain intact, and there are different layers of the thalamus dedicated to each. When visual signals leave the thalamus, they travel to the primary visual cortex at the rear of the brain. From the visual cortex, the visual signals travel in two directions. One stream that projects to the parietal lobe, in the side of the brain, carries magnocellular (“where”) information. A second stream projects to the temporal lobe and carries both magnocellular (“where”) and parvocellular (“what”) information.
Another important visual route is a pathway from the retina to the superior colliculus in the midbrain, where eye movements are coordinated and integrated with auditory information. Finally, there is the pathway from the retina to the suprachiasmatic nucleus (SCN) of the hypothalamus. The SCN is a cluster of cells that is considered to be the body’s internal clock, which controls our circadian (day-long) cycle. The SCN sends information to the pineal gland, which is important in sleep/wake patterns and annual cycles.
View this interactive presentation to review what you have learned about how vision functions.
Vision is the only photo responsive sense. Visible light travels in waves and is a very small slice of the electromagnetic radiation spectrum. Light waves differ based on their frequency (wavelength = hue) and amplitude (intensity = brightness).
In the vertebrate retina, there are two types of light receptors (photoreceptors): cones and rods. Cones, which are the source of color vision, exist in three forms—L, M, and S—and they are differentially sensitive to different wavelengths. Cones are located in the retina, along with the dim-light, achromatic receptors (rods). Cones are found in the fovea, the central region of the retina, whereas rods are found in the peripheral regions of the retina.
Visual signals travel from the eye over the axons of retinal ganglion cells, which make up the optic nerves. Ganglion cells come in several versions. Some ganglion cell axons carry information on form, movement, depth, and brightness, while other axons carry information on color and fine detail. Visual information is sent to the superior colliculi in the midbrain, where coordination of eye movements and integration of auditory information takes place. Visual information is also sent to the suprachiasmatic nucleus (SCN) of the hypothalamus, which plays a role in the circadian cycle.
(Figure) Which of the following statements about the human eye is false?
(Figure) A
Why do people over 55 often need reading glasses?
B
Why is it easier to see images at night using peripheral, rather than the central, vision?
C
A person catching a ball must coordinate her head and eyes. What part of the brain is helping to do this?
D
A satellite is launched into space, but explodes after exiting the Earth’s atmosphere. Which statement accurately reflects the observations made by an astronaut on a space walk outside the International Space Station during the explosion?
A
How could the pineal gland, the brain structure that plays a role in annual cycles, use visual information from the suprachiasmatic nucleus of the hypothalamus?
The pineal gland could use length-of-day information to determine the time of year, for example. Day length is shorter in the winter than it is in the summer. For many animals and plants, photoperiod cues them to reproduce at a certain time of year.
How is the relationship between photoreceptors and bipolar cells different from other sensory receptors and adjacent cells?
The photoreceptors tonically inhibit the bipolar cells, and stimulation of the receptors turns this inhibition off, activating the bipolar cells.
Cataracts, the medical condition where the lens of the eye becomes cloudy, are a leading cause of blindness. Describe how developing a cataract would change the path of light through the eye.
The purpose of the lens in the eye is to focus the light beams on the retina so that the image seen by the eye can be transmitted to the optic nerve and interpreted. When the lens becomes cloudy instead of clear, it scatters the light over the back of the retina. The vision system cannot interpret the image then.
Chapter 36 in OpenStax Concepts of Biology 2e

The muscular and skeletal systems provide support to the body and allow for a wide range of movement. The bones of the skeletal system protect the body’s internal organs and support the weight of the body. The muscles of the muscular system contract and pull on the bones, allowing for movements as diverse as standing, walking, running, and grasping items.
Injury or disease affecting the musculoskeletal system can be very debilitating. In humans, the most common musculoskeletal diseases worldwide are caused by malnutrition. Ailments that affect the joints are also widespread, such as arthritis, which can make movement difficult and—in advanced cases—completely impair mobility. In severe cases in which the joint has suffered extensive damage, joint replacement surgery may be needed.
Progress in the science of prosthesis design has resulted in the development of artificial joints, with joint replacement surgery in the hips and knees being the most common. Replacement joints for shoulders, elbows, and fingers are also available. Even with this progress, there is still room for improvement in the design of prostheses. The state-of-the-art prostheses have limited durability and therefore wear out quickly, particularly in young or active individuals. Current research is focused on the use of new materials, such as carbon fiber, that may make prostheses more durable.
Chapter 38 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
A skeletal system is necessary to support the body, protect internal organs, and allow for the movement of an organism. There are three different skeleton designs that fulfill these functions: hydrostatic skeleton, exoskeleton, and endoskeleton.
A hydrostatic skeleton is a skeleton formed by a fluid-filled compartment within the body, called the coelom. The organs of the coelom are supported by the aqueous fluid, which also resists external compression. This compartment is under hydrostatic pressure because of the fluid and supports the other organs of the organism. This type of skeletal system is found in soft-bodied animals such as sea anemones, earthworms, Cnidaria, and other invertebrates ((Figure)).

Movement in a hydrostatic skeleton is provided by muscles that surround the coelom. The muscles in a hydrostatic skeleton contract to change the shape of the coelom; the pressure of the fluid in the coelom produces movement. For example, earthworms move by waves of muscular contractions of the skeletal muscle of the body wall hydrostatic skeleton, called peristalsis, which alternately shorten and lengthen the body. Lengthening the body extends the anterior end of the organism. Most organisms have a mechanism to fix themselves in the substrate. Shortening the muscles then draws the posterior portion of the body forward. Although a hydrostatic skeleton is well-suited to invertebrate organisms such as earthworms and some aquatic organisms, it is not an efficient skeleton for terrestrial animals.
An exoskeleton is an external skeleton that consists of a hard encasement on the surface of an organism. For example, the shells of crabs and insects are exoskeletons ((Figure)). This skeleton type provides defence against predators, supports the body, and allows for movement through the contraction of attached muscles. As with vertebrates, muscles must cross a joint inside the exoskeleton. Shortening of the muscle changes the relationship of the two segments of the exoskeleton. Arthropods such as crabs and lobsters have exoskeletons that consist of 30–50 percent chitin, a polysaccharide derivative of glucose that is a strong but flexible material. Chitin is secreted by the epidermal cells. The exoskeleton is further strengthened by the addition of calcium carbonate in organisms such as the lobster. Because the exoskeleton is acellular, arthropods must periodically shed their exoskeletons because the exoskeleton does not grow as the organism grows.

An endoskeleton is a skeleton that consists of hard, mineralized structures located within the soft tissue of organisms. An example of a primitive endoskeletal structure is the spicules of sponges. The bones of vertebrates are composed of tissues, whereas sponges have no true tissues ((Figure)). Endoskeletons provide support for the body, protect internal organs, and allow for movement through contraction of muscles attached to the skeleton.

The human skeleton is an endoskeleton that consists of 206 bones in the adult. It has five main functions: providing support to the body, storing minerals and lipids, producing blood cells, protecting internal organs, and allowing for movement. The skeletal system in vertebrates is divided into the axial skeleton (which consists of the skull, vertebral column, and rib cage), and the appendicular skeleton (which consists of the shoulders, limb bones, the pectoral girdle, and the pelvic girdle).
Visit the interactive body site to build a virtual skeleton: select “skeleton” and click through the activity to place each bone.
The axial skeleton forms the central axis of the body and includes the bones of the skull, ossicles of the middle ear, hyoid bone of the throat, vertebral column, and the thoracic cage (ribcage) ((Figure)). The function of the axial skeleton is to provide support and protection for the brain, the spinal cord, and the organs in the ventral body cavity. It provides a surface for the attachment of muscles that move the head, neck, and trunk, performs respiratory movements, and stabilizes parts of the appendicular skeleton.
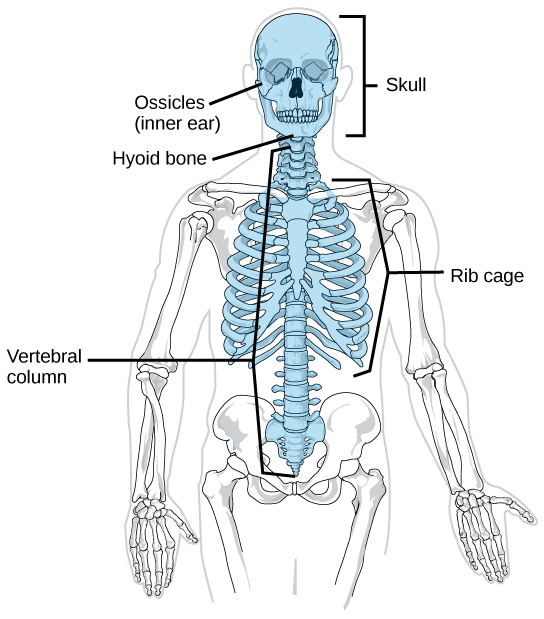
The bones of the skull support the structures of the face and protect the brain. The skull consists of 22 bones, which are divided into two categories: cranial bones and facial bones. The cranial bones are eight bones that form the cranial cavity, which encloses the brain and serves as an attachment site for the muscles of the head and neck. The eight cranial bones are the frontal bone, two parietal bones, two temporal bones, occipital bone, sphenoid bone, and the ethmoid bone. Although the bones developed separately in the embryo and fetus, in the adult, they are tightly fused with connective tissue and adjoining bones do not move ((Figure)).
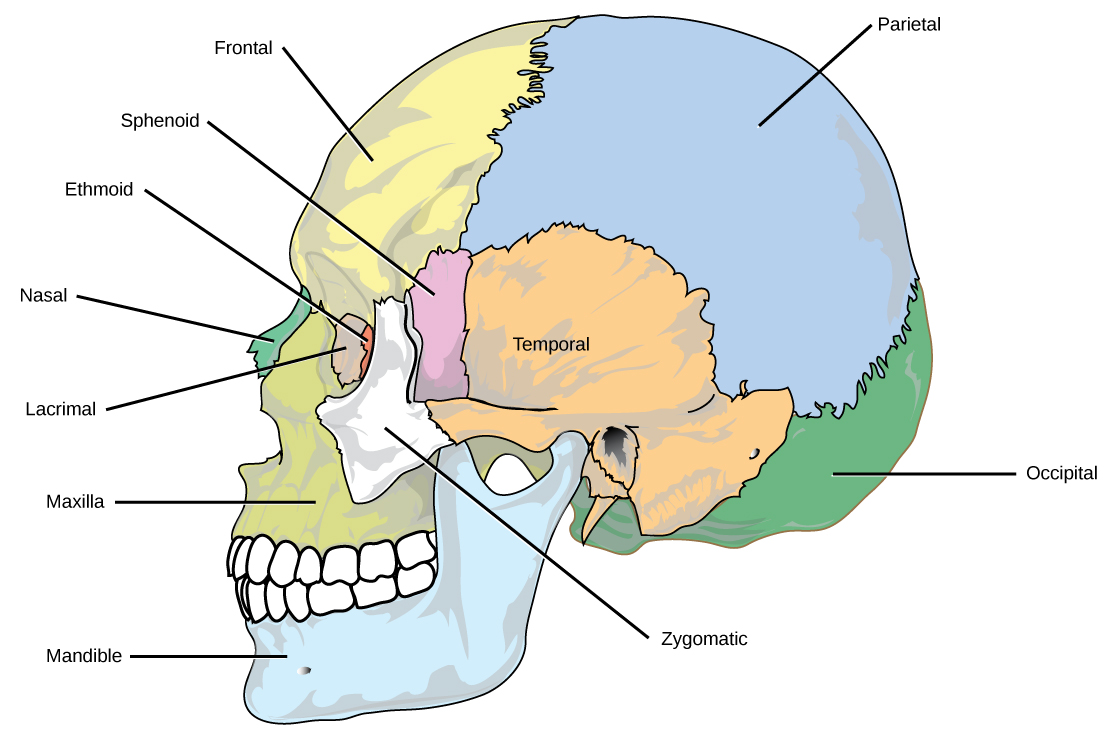
The auditory ossicles of the middle ear transmit sounds from the air as vibrations to the fluid-filled cochlea. The auditory ossicles consist of three bones each: the malleus, incus, and stapes. These are the smallest bones in the body and are unique to mammals.
Fourteen facial bones form the face, provide cavities for the sense organs (eyes, mouth, and nose), protect the entrances to the digestive and respiratory tracts, and serve as attachment points for facial muscles. The 14 facial bones are the nasal bones, the maxillary bones, zygomatic bones, palatine, vomer, lacrimal bones, the inferior nasal conchae, and the mandible. All of these bones occur in pairs except for the mandible and the vomer ((Figure)).
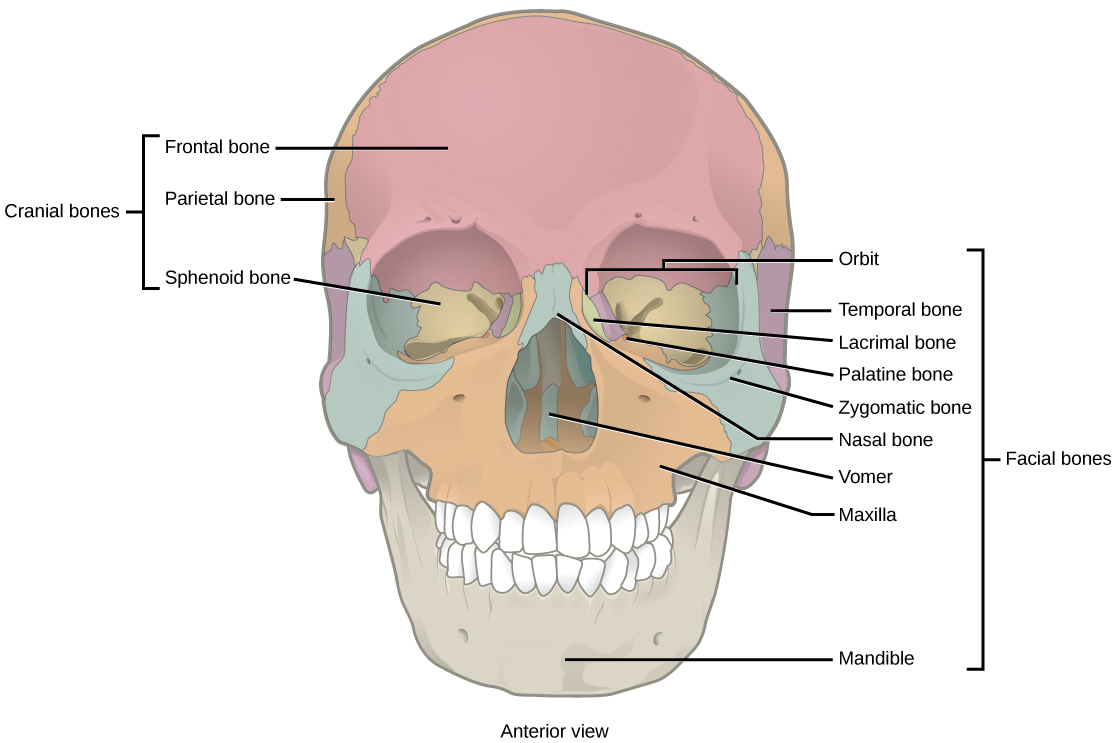
Although it is not found in the skull, the hyoid bone is considered a component of the axial skeleton. The hyoid bone lies below the mandible in the front of the neck. It acts as a movable base for the tongue and is connected to muscles of the jaw, larynx, and tongue. The mandible articulates with the base of the skull. The mandible controls the opening to the airway and gut. In animals with teeth, the mandible brings the surfaces of the teeth in contact with the maxillary teeth.
The vertebral column, or spinal column, surrounds and protects the spinal cord, supports the head, and acts as an attachment point for the ribs and muscles of the back and neck. The adult vertebral column comprises 26 bones: the 24 vertebrae, the sacrum, and the coccyx bones. In the adult, the sacrum is typically composed of five vertebrae that fuse into one. The coccyx is typically 3–4 vertebrae that fuse into one. Around the age of 70, the sacrum and the coccyx may fuse together. We begin life with approximately 33 vertebrae, but as we grow, several vertebrae fuse together. The adult vertebrae are further divided into the 7 cervical vertebrae, 12 thoracic vertebrae, and 5 lumbar vertebrae ((Figure)).
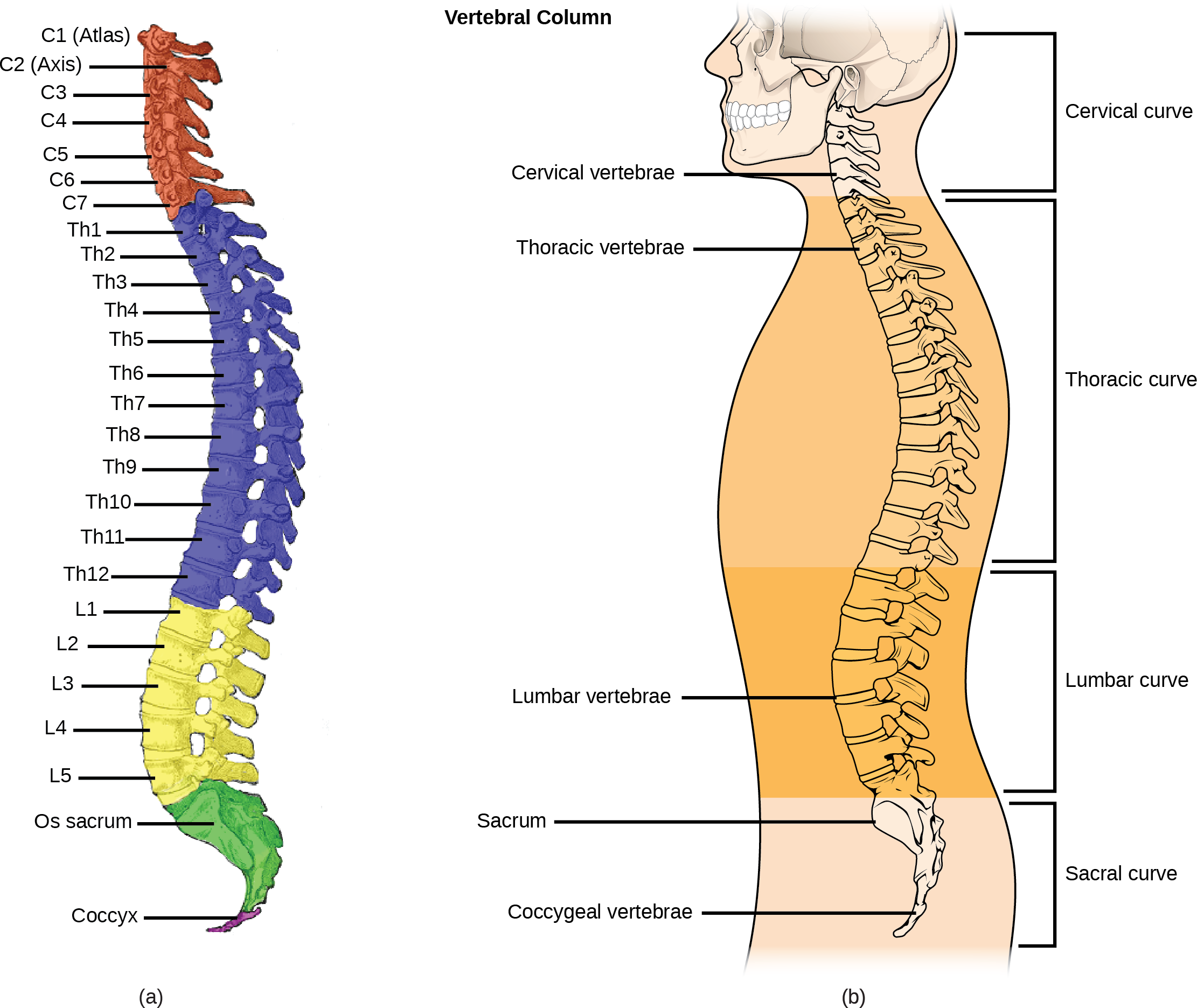
Each vertebral body has a large hole in the center through which the nerves of the spinal cord pass. There is also a notch on each side through which the spinal nerves, which serve the body at that level, can exit from the spinal cord. The vertebral column is approximately 71 cm (28 inches) in adult male humans and is curved, which can be seen from a side view. The names of the spinal curves correspond to the region of the spine in which they occur. The thoracic and sacral curves are concave (curve inwards relative to the front of the body) and the cervical and lumbar curves are convex (curve outwards relative to the front of the body). The arched curvature of the vertebral column increases its strength and flexibility, allowing it to absorb shocks like a spring ((Figure)).
Intervertebral discs composed of fibrous cartilage lie between adjacent vertebral bodies from the second cervical vertebra to the sacrum. Each disc is part of a joint that allows for some movement of the spine and acts as a cushion to absorb shocks from movements such as walking and running. Intervertebral discs also act as ligaments to bind vertebrae together. The inner part of discs, the nucleus pulposus, hardens as people age and becomes less elastic. This loss of elasticity diminishes its ability to absorb shocks.
The thoracic cage, also known as the ribcage, is the skeleton of the chest, and consists of the ribs, sternum, thoracic vertebrae, and costal cartilages ((Figure)). The thoracic cage encloses and protects the organs of the thoracic cavity, including the heart and lungs. It also provides support for the shoulder girdles and upper limbs, and serves as the attachment point for the diaphragm, muscles of the back, chest, neck, and shoulders. Changes in the volume of the thorax enable breathing.
The sternum, or breastbone, is a long, flat bone located at the anterior of the chest. It is formed from three bones that fuse in the adult. The ribs are 12 pairs of long, curved bones that attach to the thoracic vertebrae and curve toward the front of the body, forming the ribcage. Costal cartilages connect the anterior ends of the ribs to the sternum, with the exception of rib pairs 11 and 12, which are free-floating ribs.
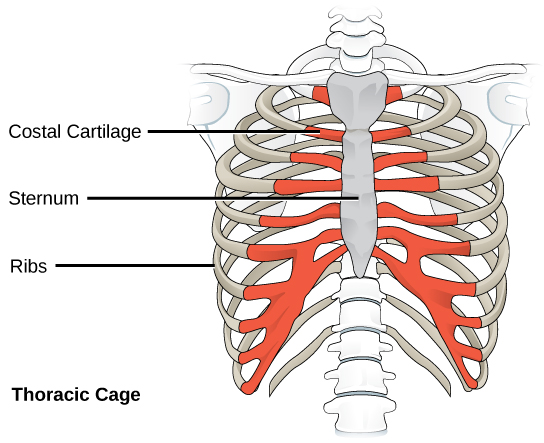
The appendicular skeleton is composed of the bones of the upper limbs (which function to grasp and manipulate objects) and the lower limbs (which permit locomotion). It also includes the pectoral girdle, or shoulder girdle, that attaches the upper limbs to the body, and the pelvic girdle that attaches the lower limbs to the body ((Figure)).
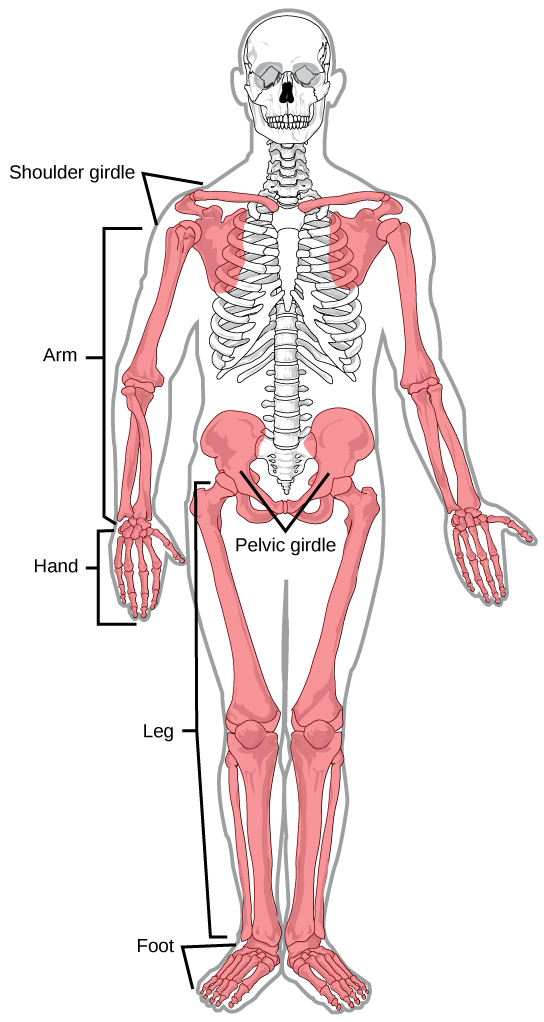
The pectoral girdle bones provide the points of attachment of the upper limbs to the axial skeleton. The human pectoral girdle consists of the clavicle (or collarbone) in the anterior, and the scapula (or shoulder blades) in the posterior ((Figure)).
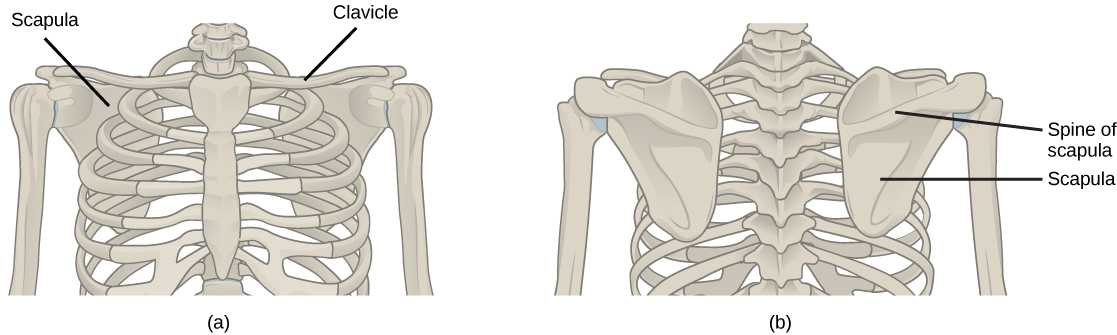
The clavicles are S-shaped bones that position the arms on the body. The clavicles lie horizontally across the front of the thorax (chest) just above the first rib. These bones are fairly fragile and are susceptible to fractures. For example, a fall with the arms outstretched causes the force to be transmitted to the clavicles, which can break if the force is excessive. The clavicle articulates with the sternum and the scapula.
The scapulae are flat, triangular bones that are located at the back of the pectoral girdle. They support the muscles crossing the shoulder joint. A ridge, called the spine, runs across the back of the scapula and can easily be felt through the skin ((Figure)). The spine of the scapula is a good example of a bony protrusion that facilitates a broad area of attachment for muscles to bone.
The upper limb contains 30 bones in three regions: the arm (shoulder to elbow), the forearm (ulna and radius), and the wrist and hand ((Figure)).
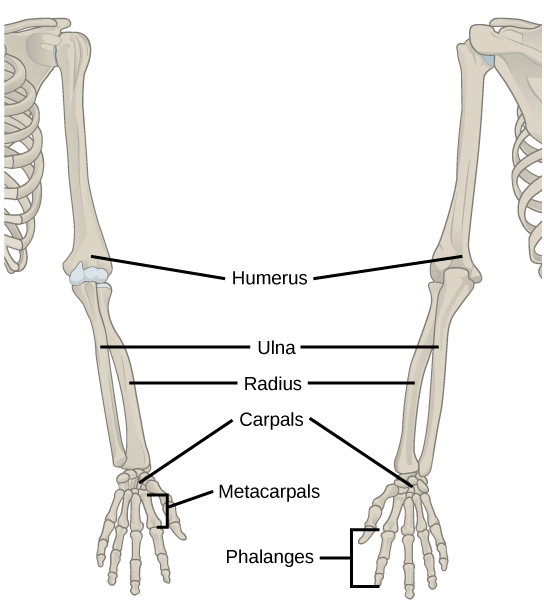
An articulation is any place at which two bones are joined. The humerus is the largest and longest bone of the upper limb and the only bone of the arm. It articulates with the scapula at the shoulder and with the forearm at the elbow. The forearm extends from the elbow to the wrist and consists of two bones: the ulna and the radius. The radius is located along the lateral (thumb) side of the forearm and articulates with the humerus at the elbow. The ulna is located on the medial aspect (pinky-finger side) of the forearm. It is longer than the radius. The ulna articulates with the humerus at the elbow. The radius and ulna also articulate with the carpal bones and with each other, which in vertebrates enables a variable degree of rotation of the carpus with respect to the long axis of the limb. The hand includes the eight bones of the carpus (wrist), the five bones of the metacarpus (palm), and the 14 bones of the phalanges (digits). Each digit consists of three phalanges, except for the thumb, when present, which has only two.
The pelvic girdle attaches to the lower limbs of the axial skeleton. Because it is responsible for bearing the weight of the body and for locomotion, the pelvic girdle is securely attached to the axial skeleton by strong ligaments. It also has deep sockets with robust ligaments to securely attach the femur to the body. The pelvic girdle is further strengthened by two large hip bones. In adults, the hip bones, or coxal bones, are formed by the fusion of three pairs of bones: the ilium, ischium, and pubis. The pelvis joins together in the anterior of the body at a joint called the pubic symphysis and with the bones of the sacrum at the posterior of the body.
The female pelvis is slightly different from the male pelvis. Over generations of evolution, females with a wider pubic angle and larger diameter pelvic canal reproduced more successfully. Therefore, their offspring also had pelvic anatomy that enabled successful childbirth ((Figure)).
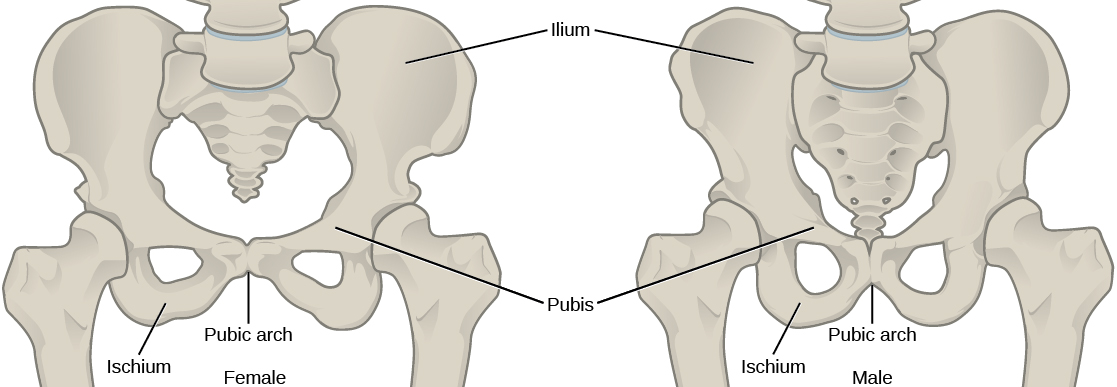
The lower limb consists of the thigh, the leg, and the foot. The bones of the lower limb are the femur (thigh bone), patella (kneecap), tibia and fibula (bones of the leg), tarsals (bones of the ankle), and metatarsals and phalanges (bones of the foot) ((Figure)). The bones of the lower limbs are thicker and stronger than the bones of the upper limbs because of the need to support the entire weight of the body and the resulting forces from locomotion. In addition to evolutionary fitness, the bones of an individual will respond to forces exerted upon them.
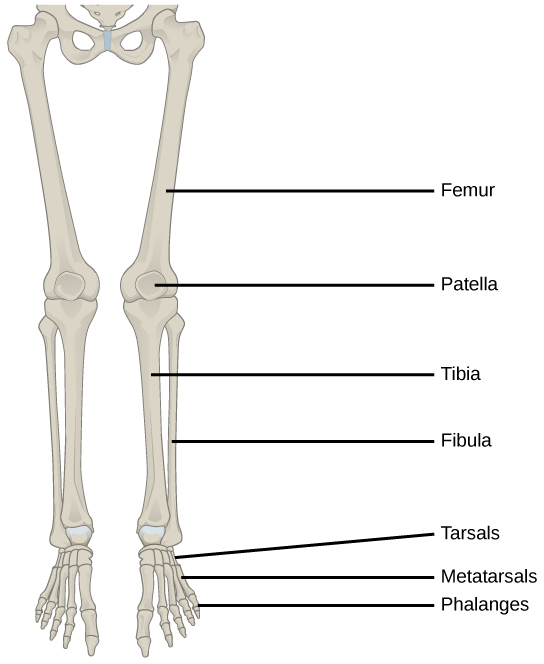
The femur, or thighbone, is the longest, heaviest, and strongest bone in the body. The femur and pelvis form the hip joint at the proximal end. At the distal end, the femur, tibia, and patella form the knee joint. The patella, or kneecap, is a triangular bone that lies anterior to the knee joint. The patella is embedded in the tendon of the femoral extensors (quadriceps). It improves knee extension by reducing friction. The tibia, or shinbone, is a large bone of the leg that is located directly below the knee. The tibia articulates with the femur at its proximal end, with the fibula and the tarsal bones at its distal end. It is the second largest bone in the human body and is responsible for transmitting the weight of the body from the femur to the foot. The fibula, or calf bone, parallels and articulates with the tibia. It does not articulate with the femur and does not bear weight. The fibula acts as a site for muscle attachment and forms the lateral part of the ankle joint.
The tarsals are the seven bones of the ankle. The ankle transmits the weight of the body from the tibia and the fibula to the foot. The metatarsals are the five bones of the foot. The phalanges are the 14 bones of the toes. Each toe consists of three phalanges, except for the big toe that has only two ((Figure)). Variations exist in other species; for example, the horse’s metacarpals and metatarsals are oriented vertically and do not make contact with the substrate.
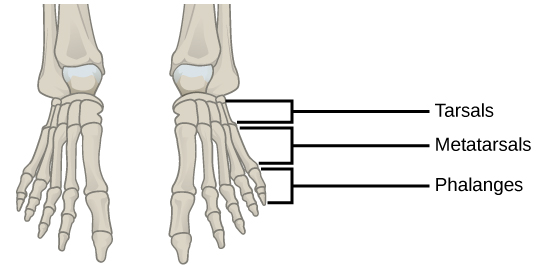
Evolution of Body Design for Locomotion on Land
The transition of vertebrates onto land required a number of changes in body design, as movement on land presents a number of challenges for animals that are adapted to movement in water. The buoyancy of water provides a certain amount of lift, and a common form of movement by fish is lateral undulations of the entire body. This back and forth movement pushes the body against the water, creating forward movement. In most fish, the muscles of paired fins attach to girdles within the body, allowing for some control of locomotion. As certain fish began moving onto land, they retained their lateral undulation form of locomotion (anguilliform). However, instead of pushing against water, their fins or flippers became points of contact with the ground, around which they rotated their bodies.
The effect of gravity and the lack of buoyancy on land meant that body weight was suspended on the limbs, leading to increased strengthening and ossification of the limbs. The effect of gravity also required changes to the axial skeleton. Lateral undulations of land animal vertebral columns cause torsional strain. A firmer, more ossified vertebral column became common in terrestrial tetrapods because it reduces strain while providing the strength needed to support the body’s weight. In later tetrapods, the vertebrae began allowing for vertical motion rather than lateral flexion. Another change in the axial skeleton was the loss of a direct attachment between the pectoral girdle and the head. This reduced the jarring to the head caused by the impact of the limbs on the ground. The vertebrae of the neck also evolved to allow movement of the head independently of the body.
The appendicular skeleton of land animals is also different from aquatic animals. The shoulders attach to the pectoral girdle through muscles and connective tissue, thus reducing the jarring of the skull. Because of a lateral undulating vertebral column, in early tetrapods, the limbs were splayed out to the side and movement occurred by performing “push-ups.” The vertebrae of these animals had to move side-to-side in a similar manner to fish and reptiles. This type of motion requires large muscles to move the limbs toward the midline; it was almost like walking while doing push-ups, and it is not an efficient use of energy. Later tetrapods have their limbs placed under their bodies, so that each stride requires less force to move forward. This resulted in decreased adductor muscle size and an increased range of motion of the scapulae. This also restricts movement primarily to one plane, creating forward motion rather than moving the limbs upward as well as forward. The femur and humerus were also rotated, so that the ends of the limbs and digits were pointed forward, in the direction of motion, rather than out to the side. By placement underneath the body, limbs can swing forward like a pendulum to produce a stride that is more efficient for moving over land.
The three types of skeleton designs are hydrostatic skeletons, exoskeletons, and endoskeletons. A hydrostatic skeleton is formed by a fluid-filled compartment held under hydrostatic pressure; movement is created by the muscles producing pressure on the fluid. An exoskeleton is a hard external skeleton that protects the outer surface of an organism and enables movement through muscles attached on the inside. An endoskeleton is an internal skeleton composed of hard, mineralized tissue that also enables movement by attachment to muscles. The human skeleton is an endoskeleton that is composed of the axial and appendicular skeleton. The axial skeleton is composed of the bones of the skull, ossicles of the ear, hyoid bone, vertebral column, and ribcage. The skull consists of eight cranial bones and 14 facial bones. Six bones make up the ossicles of the middle ear, while the hyoid bone is located in the neck under the mandible. The vertebral column contains 26 bones, and it surrounds and protects the spinal cord. The thoracic cage consists of the sternum, ribs, thoracic vertebrae, and costal cartilages. The appendicular skeleton is made up of the limbs of the upper and lower limbs. The pectoral girdle is composed of the clavicles and the scapulae. The upper limb contains 30 bones in the arm, the forearm, and the hand. The pelvic girdle attaches the lower limbs to the axial skeleton. The lower limb includes the bones of the thigh, the leg, and the foot.
The forearm consists of the:
A
The pectoral girdle consists of the:
C
All of the following are groups of vertebrae except ________, which is a curvature.
D
Which of these is a facial bone?
C
Which of the following is not a true statement comparing exoskeletons and endoskeletons?
D
What are the major differences between the male pelvis and female pelvis that permit childbirth in females?
The female pelvis is tilted forward and is wider, lighter, and shallower than the male pelvis. It also has a pubic angle that is broader than the male pelvis.
What are the major differences between the pelvic girdle and the pectoral girdle that allow the pelvic girdle to bear the weight of the body?
The pelvic girdle is securely attached to the body by strong ligaments, unlike the pectoral girdle, which is sparingly attached to the ribcage. The sockets of the pelvic girdle are deep, allowing the femur to be more stable than the pectoral girdle, which has shallow sockets for the scapula. Most tetrapods have 75 percent of their weight on the front legs because the head and neck are so heavy; the advantage of the shoulder joint is more degrees of freedom in movement.
Both hydrostatic and exoskeletons can protect internal organs from harm. Contrast the ways the skeletons perform these functions.
Hydrostatic skeletons protect internal organs from harm by cushioning them from external shock. However, these skeletons do not provide protection from external trauma. Exoskeletons are hard structures that protect the organs from damage caused by their environment. However, since they are rigid, they provide little shock absorption, so the animal will need to have other ways of cushioning its internal organs.
Scoliosis is a medical condition where the spine develops a sideways curvature. How would this change interfere with the normal function of the spine?
Normal vertebral columns are stacked in a vertical line. If the spine were to curve to the side instead this would disrupt the support and cushioning functions of the vertebrae. When the spine is out of alignment, it cannot absorb shock as well so normal activities can become painful and cause back problems later in life. The curvature also disrupts posture and structure, even disrupting lung expansion in severe cases due to changes to rib location.
Chapter 38 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Bone, or osseous tissue, is a connective tissue that constitutes the endoskeleton. It contains specialized cells and a matrix of mineral salts and collagen fibers.
The mineral salts primarily include hydroxyapatite, a mineral formed from calcium phosphate. Calcification is the process of deposition of mineral salts on the collagen fiber matrix that crystallizes and hardens the tissue. The process of calcification only occurs in the presence of collagen fibers.
The bones of the human skeleton are classified by their shape: long bones, short bones, flat bones, sutural bones, sesamoid bones, and irregular bones ((Figure)).
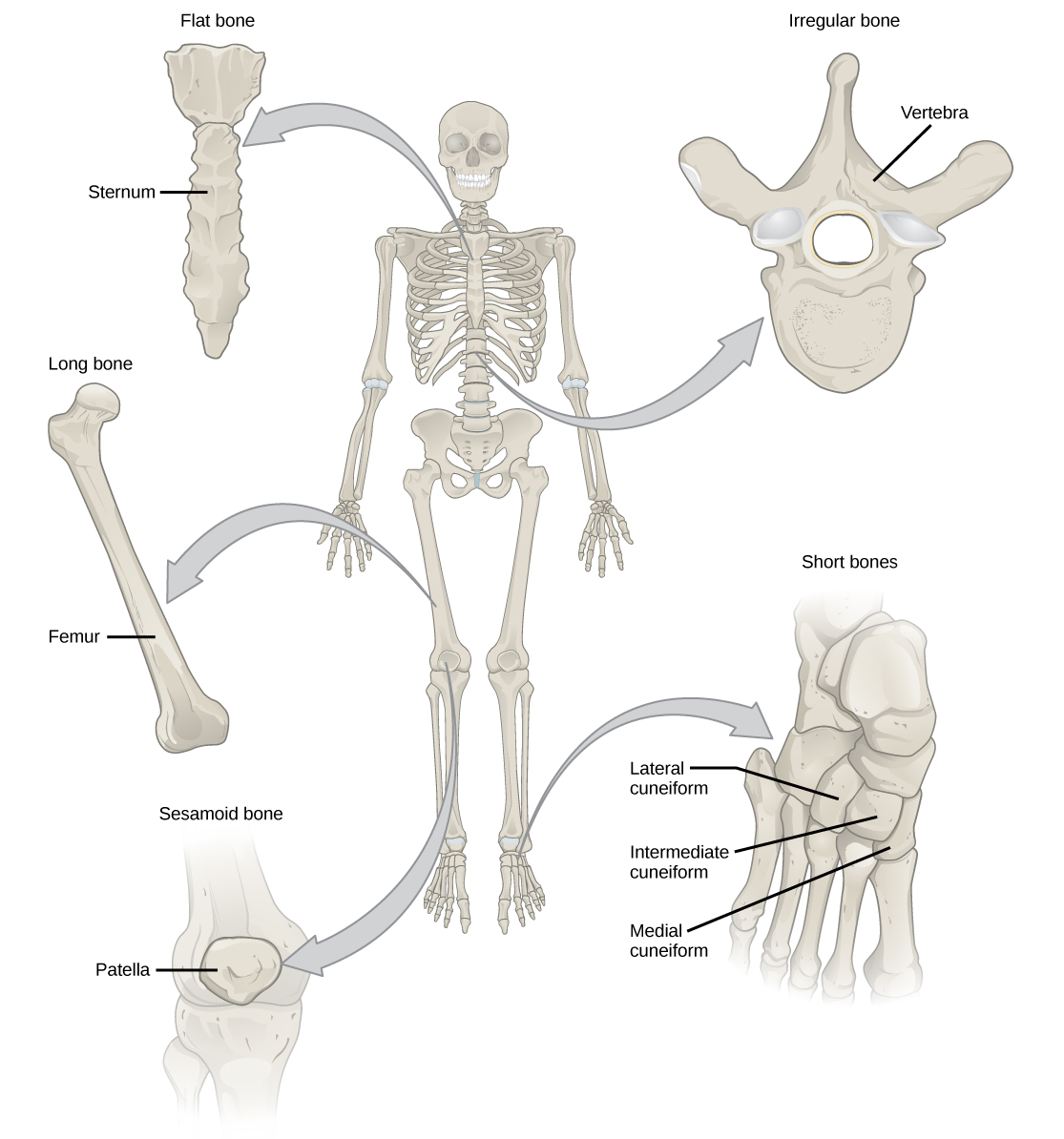
Long bones are longer than they are wide and have a shaft and two ends. The diaphysis, or central shaft, contains bone marrow in a marrow cavity. The rounded ends, the epiphyses, are covered with articular cartilage and are filled with red bone marrow, which produces blood cells ((Figure)). Most of the limb bones are long bones—for example, the femur, tibia, ulna, and radius. Exceptions to this include the patella and the bones of the wrist and ankle.
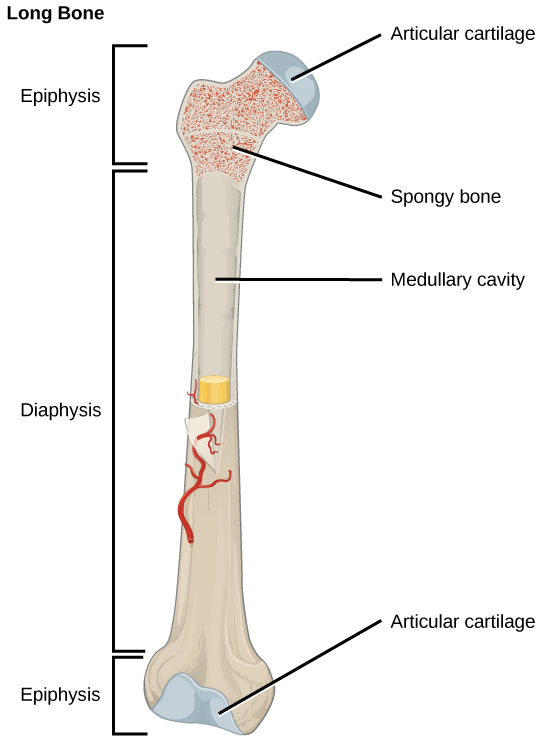
Short bones, or cuboidal bones, are bones that are the same width and length, giving them a cube-like shape. For example, the bones of the wrist (carpals) and ankle (tarsals) are short bones ((Figure)).
Flat bones are thin and relatively broad bones that are found where extensive protection of organs is required or where broad surfaces of muscle attachment are required. Examples of flat bones are the sternum (breast bone), ribs, scapulae (shoulder blades), and the roof of the skull ((Figure)).
Irregular bones are bones with complex shapes. These bones may have short, flat, notched, or ridged surfaces. Examples of irregular bones are the vertebrae, hip bones, and several skull bones.
Sesamoid bones are small, flat bones and are shaped similarly to a sesame seed. The patellae are sesamoid bones ((Figure)). Sesamoid bones develop inside tendons and may be found near joints at the knees, hands, and feet.
Sutural bones are small, flat, irregularly shaped bones. They may be found between the flat bones of the skull. They vary in number, shape, size, and position.
Bones are considered organs because they contain various types of tissue, such as blood, connective tissue, nerves, and bone tissue. Osteocytes, the living cells of bone tissue, form the mineral matrix of bones. There are two types of bone tissue: compact and spongy.
Compact bone (or cortical bone) forms the hard external layer of all bones and surrounds the medullary cavity, or bone marrow. It provides protection and strength to bones. Compact bone tissue consists of units called osteons or Haversian systems. Osteons are cylindrical structures that contain a mineral matrix and living osteocytes connected by canaliculi, which transport blood. They are aligned parallel to the long axis of the bone. Each osteon consists of lamellae, which are layers of compact matrix that surround a central canal called the Haversian canal. The Haversian canal (osteonic canal) contains the bone’s blood vessels and nerve fibers ((Figure)). Osteons in compact bone tissue are aligned in the same direction along lines of stress and help the bone resist bending or fracturing. Therefore, compact bone tissue is prominent in areas of bone at which stresses are applied in only a few directions.
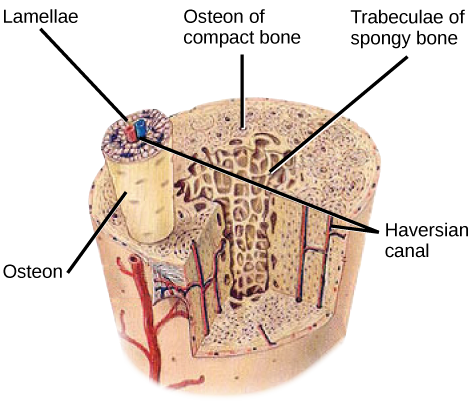
Which of the following statements about bone tissue is false?
<!–<para>B–>
Whereas compact bone tissue forms the outer layer of all bones, spongy bone or cancellous bone forms the inner layer of all bones. Spongy bone tissue does not contain osteons that constitute compact bone tissue. Instead, it consists of trabeculae, which are lamellae that are arranged as rods or plates. Red bone marrow is found between the trabuculae. Blood vessels within this tissue deliver nutrients to osteocytes and remove waste. The red bone marrow of the femur and the interior of other large bones, such as the ileum, forms blood cells.
Spongy bone reduces the density of bone and allows the ends of long bones to compress as the result of stresses applied to the bone. Spongy bone is prominent in areas of bones that are not heavily stressed or where stresses arrive from many directions. The epiphyses of bones, such as the neck of the femur, are subject to stress from many directions. Imagine laying a heavy framed picture flat on the floor. You could hold up one side of the picture with a toothpick if the toothpick was perpendicular to the floor and the picture. Now drill a hole and stick the toothpick into the wall to hang up the picture. In this case, the function of the toothpick is to transmit the downward pressure of the picture to the wall. The force on the picture is straight down to the floor, but the force on the toothpick is both the picture wire pulling down and the bottom of the hole in the wall pushing up. The toothpick will break off right at the wall.
The neck of the femur is horizontal like the toothpick in the wall. The weight of the body pushes it down near the joint, but the vertical diaphysis of the femur pushes it up at the other end. The neck of the femur must be strong enough to transfer the downward force of the body weight horizontally to the vertical shaft of the femur ((Figure)).
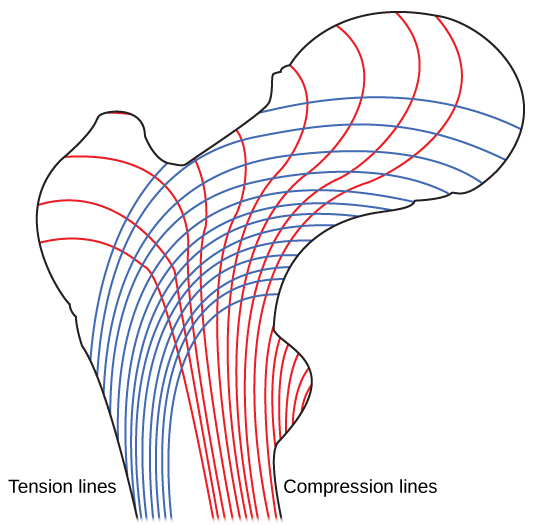
View micrographs of musculoskeletal tissues as you review the anatomy.
Bone consists of four types of cells: osteoblasts, osteoclasts, osteocytes, and osteoprogenitor cells. Osteoblasts are bone cells that are responsible for bone formation. Osteoblasts synthesize and secrete the organic part and inorganic part of the extracellular matrix of bone tissue, and collagen fibers. Osteoblasts become trapped in these secretions and differentiate into less active osteocytes. Osteoclasts are large bone cells with up to 50 nuclei. They remove bone structure by releasing lysosomal enzymes and acids that dissolve the bony matrix. These minerals, released from bones into the blood, help regulate calcium concentrations in body fluids. Bone may also be resorbed for remodeling, if the applied stresses have changed. Osteocytes are mature bone cells and are the main cells in bony connective tissue; these cells cannot divide. Osteocytes maintain normal bone structure by recycling the mineral salts in the bony matrix. Osteoprogenitor cells are squamous stem cells that divide to produce daughter cells that differentiate into osteoblasts. Osteoprogenitor cells are important in the repair of fractures.
Ossification, or osteogenesis, is the process of bone formation by osteoblasts. Ossification is distinct from the process of calcification; whereas calcification takes place during the ossification of bones, it can also occur in other tissues. Ossification begins approximately six weeks after fertilization in an embryo. Before this time, the embryonic skeleton consists entirely of fibrous membranes and hyaline cartilage. The development of bone from fibrous membranes is called intramembranous ossification; development from hyaline cartilage is called endochondral ossification. Bone growth continues until approximately age 25. Bones can grow in thickness throughout life, but after age 25, ossification functions primarily in bone remodeling and repair.
Intramembranous ossification is the process of bone development from fibrous membranes. It is involved in the formation of the flat bones of the skull, the mandible, and the clavicles. Ossification begins as mesenchymal cells form a template of the future bone. They then differentiate into osteoblasts at the ossification center. Osteoblasts secrete the extracellular matrix and deposit calcium, which hardens the matrix. The non-mineralized portion of the bone or osteoid continues to form around blood vessels, forming spongy bone. Connective tissue in the matrix differentiates into red bone marrow in the fetus. The spongy bone is remodeled into a thin layer of compact bone on the surface of the spongy bone.
Endochondral ossification is the process of bone development from hyaline cartilage. All of the bones of the body, except for the flat bones of the skull, mandible, and clavicles, are formed through endochondral ossification.
In long bones, chondrocytes form a template of the hyaline cartilage diaphysis. Responding to complex developmental signals, the matrix begins to calcify. This calcification prevents diffusion of nutrients into the matrix, resulting in chondrocytes dying and the opening up of cavities in the diaphysis cartilage. Blood vessels invade the cavities, and osteoblasts and osteoclasts modify the calcified cartilage matrix into spongy bone. Osteoclasts then break down some of the spongy bone to create a marrow, or medullary, cavity in the center of the diaphysis. Dense, irregular connective tissue forms a sheath (periosteum) around the bones. The periosteum assists in attaching the bone to surrounding tissues, tendons, and ligaments. The bone continues to grow and elongate as the cartilage cells at the epiphyses divide.
In the last stage of prenatal bone development, the centers of the epiphyses begin to calcify. Secondary ossification centers form in the epiphyses as blood vessels and osteoblasts enter these areas and convert hyaline cartilage into spongy bone. Until adolescence, hyaline cartilage persists at the epiphyseal plate (growth plate), which is the region between the diaphysis and epiphysis that is responsible for the lengthwise growth of long bones ((Figure)).
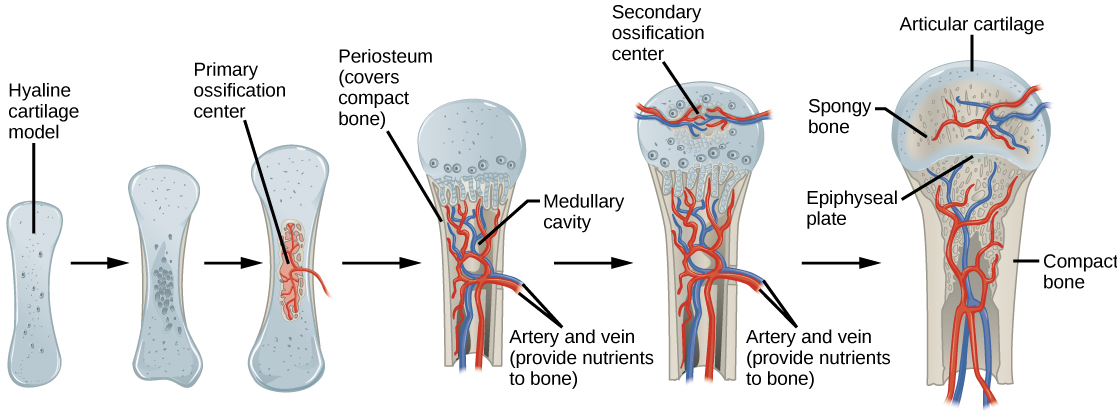
Long bones continue to lengthen, potentially until adolescence, through the addition of bone tissue at the epiphyseal plate. They also increase in width through appositional growth.
Chondrocytes on the epiphyseal side of the epiphyseal plate divide; one cell remains undifferentiated near the epiphysis, and one cell moves toward the diaphysis. The cells, which are pushed from the epiphysis, mature and are destroyed by calcification. This process replaces cartilage with bone on the diaphyseal side of the plate, resulting in a lengthening of the bone.
Long bones stop growing at around the age of 18 in females and the age of 21 in males in a process called epiphyseal plate closure. During this process, cartilage cells stop dividing and all of the cartilage is replaced by bone. The epiphyseal plate fades, leaving a structure called the epiphyseal line or epiphyseal remnant, and the epiphysis and diaphysis fuse.
Appositional growth is the increase in the diameter of bones by the addition of bony tissue at the surface of bones. Osteoblasts at the bone surface secrete bone matrix, and osteoclasts on the inner surface break down bone. The osteoblasts differentiate into osteocytes. A balance between these two processes allows the bone to thicken without becoming too heavy.
Bone renewal continues after birth into adulthood. Bone remodeling is the replacement of old bone tissue by new bone tissue. It involves the processes of bone deposition by osteoblasts and bone resorption by osteoclasts. Normal bone growth requires vitamins D, C, and A, plus minerals such as calcium, phosphorous, and magnesium. Hormones such as parathyroid hormone, growth hormone, and calcitonin are also required for proper bone growth and maintenance.
Bone turnover rates are quite high, with five to seven percent of bone mass being recycled every week. Differences in turnover rate exist in different areas of the skeleton and in different areas of a bone. For example, the bone in the head of the femur may be fully replaced every six months, whereas the bone along the shaft is altered much more slowly.
Bone remodeling allows bones to adapt to stresses by becoming thicker and stronger when subjected to stress. Bones that are not subject to normal stress, for example when a limb is in a cast, will begin to lose mass. A fractured or broken bone undergoes repair through four stages:
Decalcification of Bones
Question: What effect does the removal of calcium and collagen have on bone structure?
Background: Conduct a literature search on the role of calcium and collagen in maintaining bone structure. Conduct a literature search on diseases in which bone structure is compromised.
Hypothesis: Develop a hypothesis that states predictions of the flexibility, strength, and mass of bones that have had the calcium and collagen components removed. Develop a hypothesis regarding the attempt to add calcium back to decalcified bones.
Test the hypothesis: Test the prediction by removing calcium from chicken bones by placing them in a jar of vinegar for seven days. Test the hypothesis regarding adding calcium back to decalcified bone by placing the decalcified chicken bones into a jar of water with calcium supplements added. Test the prediction by denaturing the collagen from the bones by baking them at 250°C for three hours.
Analyze the data: Create a table showing the changes in bone flexibility, strength, and mass in the three different environments.
Report the results: Under which conditions was the bone most flexible? Under which conditions was the bone the strongest?
Draw a conclusion: Did the results support or refute the hypothesis? How do the results observed in this experiment correspond to diseases that destroy bone tissue?
Bone, or osseous tissue, is connective tissue that includes specialized cells, mineral salts, and collagen fibers. The human skeleton can be divided into long bones, short bones, flat bones, and irregular bones. Compact bone tissue is composed of osteons and forms the external layer of all bones. Spongy bone tissue is composed of trabeculae and forms the inner part of all bones. Four types of cells compose bony tissue: osteocytes, osteoclasts, osteoprogenitor cells, and osteoblasts. Ossification is the process of bone formation by osteoblasts. Intramembranous ossification is the process of bone development from fibrous membranes. Endochondral ossification is the process of bone development from hyaline cartilage. Long bones lengthen as chondrocytes divide and secrete hyaline cartilage. Osteoblasts replace cartilage with bone. Appositional growth is the increase in the diameter of bones by the addition of bone tissue at the surface of bones. Bone remodeling involves the processes of bone deposition by osteoblasts and bone resorption by osteoclasts. Bone repair occurs in four stages and can take several months.
(Figure) Which of the following statements about bone tissue is false?
The Haversian canal:
B
The epiphyseal plate:
C
The cells responsible for bone resorption are ________.
A
Compact bone is composed of ________.
C
Osteoporosis is a condition where bones become weak and brittle. It is caused by an imbalance in the activity of which cells?
A
While assembling a skeleton of a new species, a scientist points to one of the bones and observes that it looks like the most likely site of leg muscle attachment. What kind of bone did she indicate?
D
What are the major differences between spongy bone and compact bone?
Compact bone tissue forms the hard external layer of all bones and consists of osteons. Compact bone tissue is prominent in areas of bone at which stresses are applied in only a few directions. Spongy bone tissue forms the inner layer of all bones and consists of trabeculae. Spongy bone is prominent in areas of bones that are not heavily stressed or at which stresses arrive from many directions.
What are the roles of osteoblasts, osteocytes, and osteoclasts?
Osteocytes function in the exchange of nutrients and wastes with the blood. They also maintain normal bone structure by recycling the mineral salts in the bony matrix. Osteoclasts remove bone tissue by releasing lysosomal enzymes and acids that dissolve the bony matrix. Osteoblasts are bone cells that are responsible for bone formation.
Thalidomide was a morning sickness drug given to women that caused babies to be born without arm bones. If recent studies have shown that thalidomide prevents the formation of new blood vessels, describe the type of bone development inhibited by the drug and what stage of ossification was affected.
Thalidomide effected the development of the long bones of the arms, disrupting endochondral ossification. The bones would have been able to develop into a template made of the calcified cartilage matrix, but new blood vessels could not be created. Since no vessels invade the template, the structure is not converted into trabecular bone.
Chapter 38 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
The point at which two or more bones meet is called a joint, or articulation. Joints are responsible for movement, such as the movement of limbs, and stability, such as the stability found in the bones of the skull.
There are two ways to classify joints: on the basis of their structure or on the basis of their function. The structural classification divides joints into bony, fibrous, cartilaginous, and synovial joints depending on the material composing the joint and the presence or absence of a cavity in the joint.
The bones of fibrous joints are held together by fibrous connective tissue. There is no cavity, or space, present between the bones and so most fibrous joints do not move at all, or are only capable of minor movements. There are three types of fibrous joints: sutures, syndesmoses, and gomphoses. Sutures are found only in the skull and possess short fibers of connective tissue that hold the skull bones tightly in place ((Figure)).
Syndesmoses are joints in which the bones are connected by a band of connective tissue, allowing for more movement than in a suture. An example of a syndesmosis is the joint of the tibia and fibula in the ankle. The amount of movement in these types of joints is determined by the length of the connective tissue fibers. Gomphoses occur between teeth and their sockets; the term refers to the way the tooth fits into the socket like a peg ((Figure)). The tooth is connected to the socket by a connective tissue referred to as the periodontal ligament.
Cartilaginous joints are joints in which the bones are connected by cartilage. There are two types of cartilaginous joints: synchondroses and symphyses. In a synchondrosis, the bones are joined by hyaline cartilage. Synchondroses are found in the epiphyseal plates of growing bones in children. In symphyses, hyaline cartilage covers the end of the bone but the connection between bones occurs through fibrocartilage. Symphyses are found at the joints between vertebrae. Either type of cartilaginous joint allows for very little movement.
Synovial joints are the only joints that have a space between the adjoining bones ((Figure)). This space is referred to as the synovial (or joint) cavity and is filled with synovial fluid. Synovial fluid lubricates the joint, reducing friction between the bones and allowing for greater movement. The ends of the bones are covered with articular cartilage, a hyaline cartilage, and the entire joint is surrounded by an articular capsule composed of connective tissue that allows movement of the joint while resisting dislocation. Articular capsules may also possess ligaments that hold the bones together. Synovial joints are capable of the greatest movement of the three structural joint types; however, the more mobile a joint, the weaker the joint. Knees, elbows, and shoulders are examples of synovial joints.
The functional classification divides joints into three categories: synarthroses, amphiarthroses, and diarthroses. A synarthrosis is a joint that is immovable. This includes sutures, gomphoses, and synchondroses. Amphiarthroses are joints that allow slight movement, including syndesmoses and symphyses. Diarthroses are joints that allow for free movement of the joint, as in synovial joints.
The wide range of movement allowed by synovial joints produces different types of movements. The movement of synovial joints can be classified as one of four different types: gliding, angular, rotational, or special movement.
Gliding movements occur as relatively flat bone surfaces move past each other. Gliding movements produce very little rotation or angular movement of the bones. The joints of the carpal and tarsal bones are examples of joints that produce gliding movements.
Angular movements are produced when the angle between the bones of a joint changes. There are several different types of angular movements, including flexion, extension, hyperextension, abduction, adduction, and circumduction. Flexion, or bending, occurs when the angle between the bones decreases. Moving the forearm upward at the elbow or moving the wrist to move the hand toward the forearm are examples of flexion. Extension is the opposite of flexion in that the angle between the bones of a joint increases. Straightening a limb after flexion is an example of extension. Extension past the regular anatomical position is referred to as hyperextension. This includes moving the neck back to look upward, or bending the wrist so that the hand moves away from the forearm.
Abduction occurs when a bone moves away from the midline of the body. Examples of abduction are moving the arms or legs laterally to lift them straight out to the side. Adduction is the movement of a bone toward the midline of the body. Movement of the limbs inward after abduction is an example of adduction. Circumduction is the movement of a limb in a circular motion, as in moving the arm in a circular motion.
Rotational movement is the movement of a bone as it rotates around its longitudinal axis. Rotation can be toward the midline of the body, which is referred to as medial rotation, or away from the midline of the body, which is referred to as lateral rotation. Movement of the head from side to side is an example of rotation.
Some movements that cannot be classified as gliding, angular, or rotational are called special movements. Inversion involves the soles of the feet moving inward, toward the midline of the body. Eversion is the opposite of inversion, movement of the sole of the foot outward, away from the midline of the body. Protraction is the anterior movement of a bone in the horizontal plane. Retraction occurs as a joint moves back into position after protraction. Protraction and retraction can be seen in the movement of the mandible as the jaw is thrust outwards and then back inwards. Elevation is the movement of a bone upward, such as when the shoulders are shrugged, lifting the scapulae. Depression is the opposite of elevation—movement downward of a bone, such as after the shoulders are shrugged and the scapulae return to their normal position from an elevated position. Dorsiflexion is a bending at the ankle such that the toes are lifted toward the knee. Plantar flexion is a bending at the ankle when the heel is lifted, such as when standing on the toes. Supination is the movement of the radius and ulna bones of the forearm so that the palm faces forward. Pronation is the opposite movement, in which the palm faces backward. Opposition is the movement of the thumb toward the fingers of the same hand, making it possible to grasp and hold objects.
Synovial joints are further classified into six different categories on the basis of the shape and structure of the joint. The shape of the joint affects the type of movement permitted by the joint ((Figure)). These joints can be described as planar, hinge, pivot, condyloid, saddle, or ball-and-socket joints.
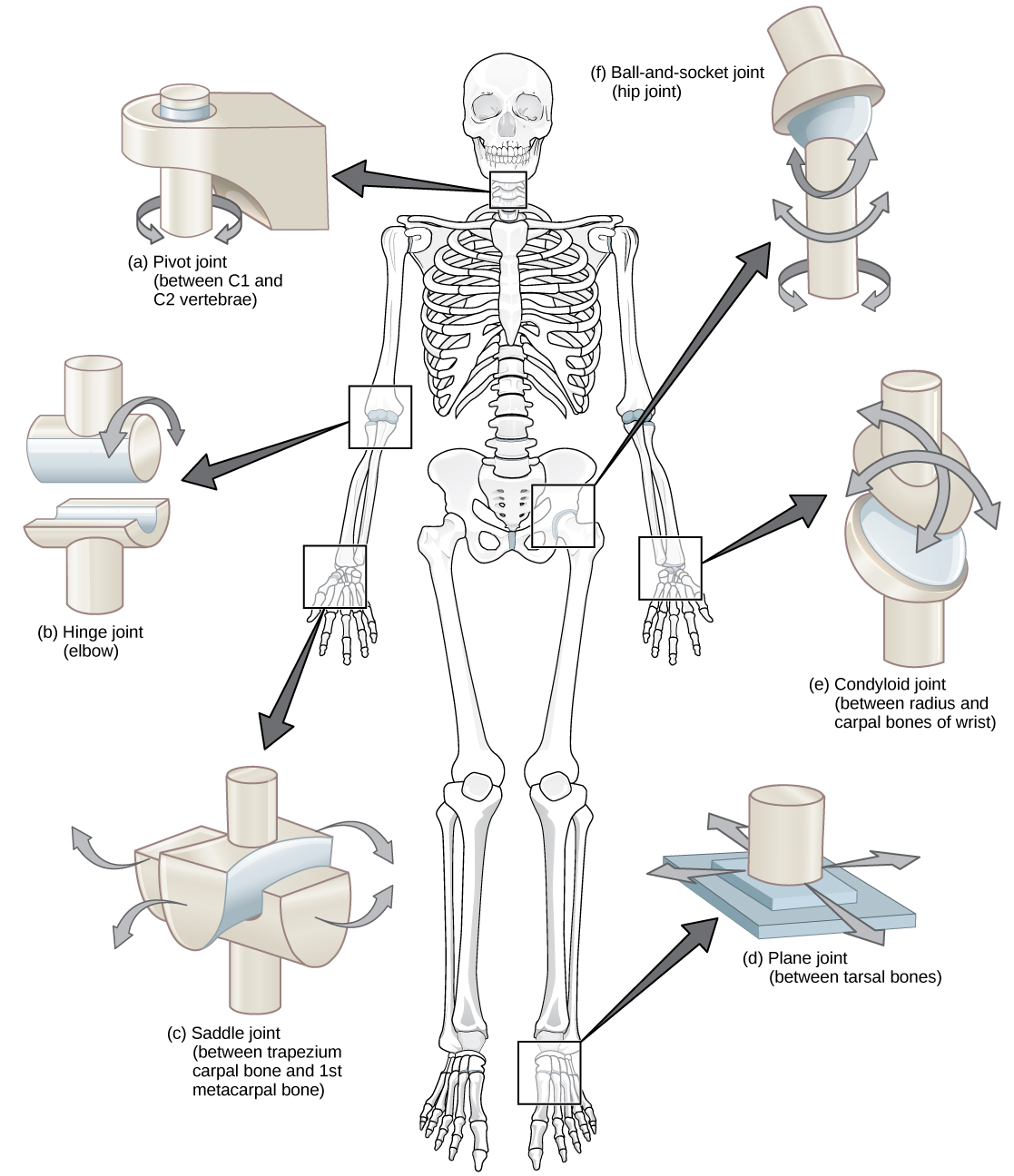
Planar joints have bones with articulating surfaces that are flat or slightly curved faces. These joints allow for gliding movements, and so the joints are sometimes referred to as gliding joints. The range of motion is limited in these joints and does not involve rotation. Planar joints are found in the carpal bones in the hand and the tarsal bones of the foot, as well as between vertebrae ((Figure)).
In hinge joints, the slightly rounded end of one bone fits into the slightly hollow end of the other bone. In this way, one bone moves while the other remains stationary, like the hinge of a door. The elbow is an example of a hinge joint. The knee is sometimes classified as a modified hinge joint ((Figure)).

Pivot joints consist of the rounded end of one bone fitting into a ring formed by the other bone. This structure allows rotational movement, as the rounded bone moves around its own axis. An example of a pivot joint is the joint of the first and second vertebrae of the neck that allows the head to move back and forth ((Figure)). The joint of the wrist that allows the palm of the hand to be turned up and down is also a pivot joint.
Condyloid joints consist of an oval-shaped end of one bone fitting into a similarly oval-shaped hollow of another bone ((Figure)). This is also sometimes called an ellipsoidal joint. This type of joint allows angular movement along two axes, as seen in the joints of the wrist and fingers, which can move both side to side and up and down.
Saddle joints are so named because the ends of each bone resemble a saddle, with concave and convex portions that fit together. Saddle joints allow angular movements similar to condyloid joints but with a greater range of motion. An example of a saddle joint is the thumb joint, which can move back and forth and up and down, but more freely than the wrist or fingers ((Figure)).
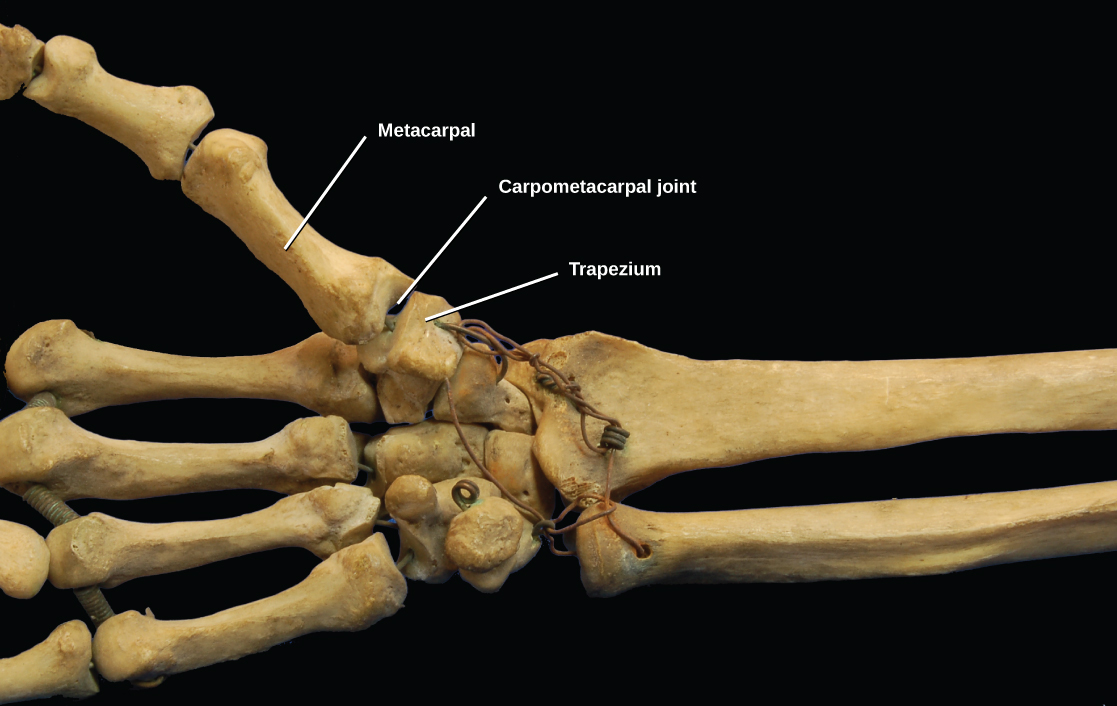
Ball-and-socket joints possess a rounded, ball-like end of one bone fitting into a cuplike socket of another bone. This organization allows the greatest range of motion, as all movement types are possible in all directions. Examples of ball-and-socket joints are the shoulder and hip joints ((Figure)).
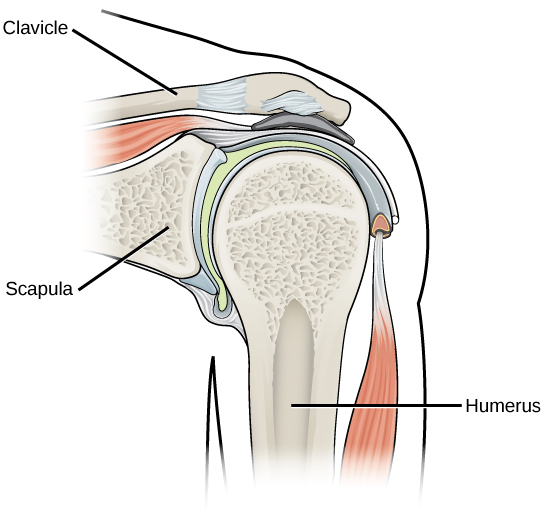
Watch this animation showing the six types of synovial joints.
Rheumatologist
Rheumatologists are medical doctors who specialize in the diagnosis and treatment of disorders of the joints, muscles, and bones. They diagnose and treat diseases such as arthritis, musculoskeletal disorders, osteoporosis, and autoimmune diseases such as ankylosing spondylitis and rheumatoid arthritis.
Rheumatoid arthritis (RA) is an inflammatory disorder that primarily affects the synovial joints of the hands, feet, and cervical spine. Affected joints become swollen, stiff, and painful. Although it is known that RA is an autoimmune disease in which the body’s immune system mistakenly attacks healthy tissue, the cause of RA remains unknown. Immune cells from the blood enter joints and the synovium causing cartilage breakdown, swelling, and inflammation of the joint lining. Breakdown of cartilage causes bones to rub against each other causing pain. RA is more common in women than men and the age of onset is usually 40–50 years of age.
Rheumatologists can diagnose RA on the basis of symptoms such as joint inflammation and pain, X-ray and MRI imaging, and blood tests. Arthrography is a type of medical imaging of joints that uses a contrast agent, such as a dye, that is opaque to X-rays. This allows the soft tissue structures of joints—such as cartilage, tendons, and ligaments—to be visualized. An arthrogram differs from a regular X-ray by showing the surface of soft tissues lining the joint in addition to joint bones. An arthrogram allows early degenerative changes in joint cartilage to be detected before bones become affected.
There is currently no cure for RA; however, rheumatologists have a number of treatment options available. Early stages can be treated with rest of the affected joints by using a cane or by using joint splints that minimize inflammation. When inflammation has decreased, exercise can be used to strengthen the muscles that surround the joint and to maintain joint flexibility. If joint damage is more extensive, medications can be used to relieve pain and decrease inflammation. Anti-inflammatory drugs such as aspirin, topical pain relievers, and corticosteroid injections may be used. Surgery may be required in cases in which joint damage is severe.
The structural classification of joints divides them into bony, fibrous, cartilaginous, and synovial joints. The bones of fibrous joints are held together by fibrous connective tissue; the three types of fibrous joints are sutures, syndesomes, and gomphoses. Cartilaginous joints are joints in which the bones are connected by cartilage; the two types of cartilaginous joints are synchondroses and symphyses. Synovial joints are joints that have a space between the adjoining bones. The functional classification divides joints into three categories: synarthroses, amphiarthroses, and diarthroses. The movement of synovial joints can be classified as one of four different types: gliding, angular, rotational, or special movement. Gliding movements occur as relatively flat bone surfaces move past each other. Angular movements are produced when the angle between the bones of a joint changes. Rotational movement is the movement of a bone as it rotates around its own longitudinal axis. Special movements include inversion, eversion, protraction, retraction, elevation, depression, dorsiflexion, plantar flexion, supination, pronation, and opposition. Synovial joints are also classified into six different categories on the basis of the shape and structure of the joint: planar, hinge, pivot, condyloid, saddle, and ball-and-socket.
Synchondroses and symphyses are:
B
The movement of bone away from the midline of the body is called ________.
D
Which of the following is not a characteristic of the synovial fluid?
C
The elbow is an example of which type of joint?
A
A high ankle sprain is an injury caused by over-stretching the ligaments connecting the tibia and fibula. What type of joint is involved in this sprain?
C
What movements occur at the hip joint and knees as you bend down to touch your toes?
The hip joint is flexed and the knees are extended.
What movement(s) occur(s) at the scapulae when you shrug your shoulders?
Elevation is the movement of a bone upward, such as when the shoulders are shrugged, lifting the scapulae. Depression is the downward movement of a bone, such as after the shoulders are shrugged and the scapulae return to their normal position from an elevated position.
Describe the joints and motions involved in taking a step forward if a person is initially standing still. Assume the person holds his foot at the same angle throughout the motion.
Taking a step would require bending the knee (modified hinge joint) and moving the leg in the hip (ball and socket joint) since the motion of the foot is excluded. As the foot comes off the ground in the step, the hip joint is going to move the femur in a protracted motion and the knee will flex the shin toward the thigh. As the foot lands, the knee extends the leg and the hip retracts the femur.
Chapter 38 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Muscle cells are specialized for contraction. Muscles allow for motions such as walking, and they also facilitate bodily processes such as respiration and digestion. The body contains three types of muscle tissue: skeletal muscle, cardiac muscle, and smooth muscle ((Figure)).
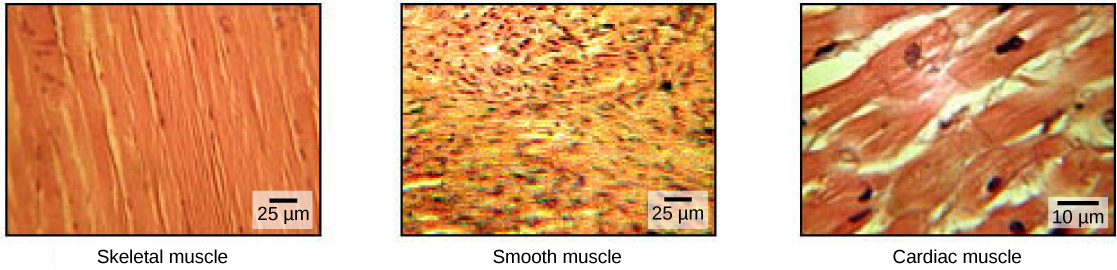
Skeletal muscle tissue forms skeletal muscles, which attach to bones or skin and control locomotion and any movement that can be consciously controlled. Because it can be controlled by thought, skeletal muscle is also called voluntary muscle. Skeletal muscles are long and cylindrical in appearance; when viewed under a microscope, skeletal muscle tissue has a striped or striated appearance. The striations are caused by the regular arrangement of contractile proteins (actin and myosin). Actin is a globular contractile protein that interacts with myosin for muscle contraction. Skeletal muscle also has multiple nuclei present in a single cell.
Smooth muscle tissue occurs in the walls of hollow organs such as the intestines, stomach, and urinary bladder, and around passages such as the respiratory tract and blood vessels. Smooth muscle has no striations, is not under voluntary control, has only one nucleus per cell, is tapered at both ends, and is called involuntary muscle.
Cardiac muscle tissue is only found in the heart, and cardiac contractions pump blood throughout the body and maintain blood pressure. Like skeletal muscle, cardiac muscle is striated, but unlike skeletal muscle, cardiac muscle cannot be consciously controlled and is called involuntary muscle. It has one nucleus per cell, is branched, and is distinguished by the presence of intercalated disks.
Each skeletal muscle fiber is a skeletal muscle cell. These cells are incredibly large, with diameters of up to 100 µm and lengths of up to 30 cm. The plasma membrane of a skeletal muscle fiber is called the sarcolemma. The sarcolemma is the site of action potential conduction, which triggers muscle contraction. Within each muscle fiber are myofibrils—long cylindrical structures that lie parallel to the muscle fiber. Myofibrils run the entire length of the muscle fiber, and because they are only approximately 1.2 µm in diameter, hundreds to thousands can be found inside one muscle fiber. They attach to the sarcolemma at their ends, so that as myofibrils shorten, the entire muscle cell contracts ((Figure)).
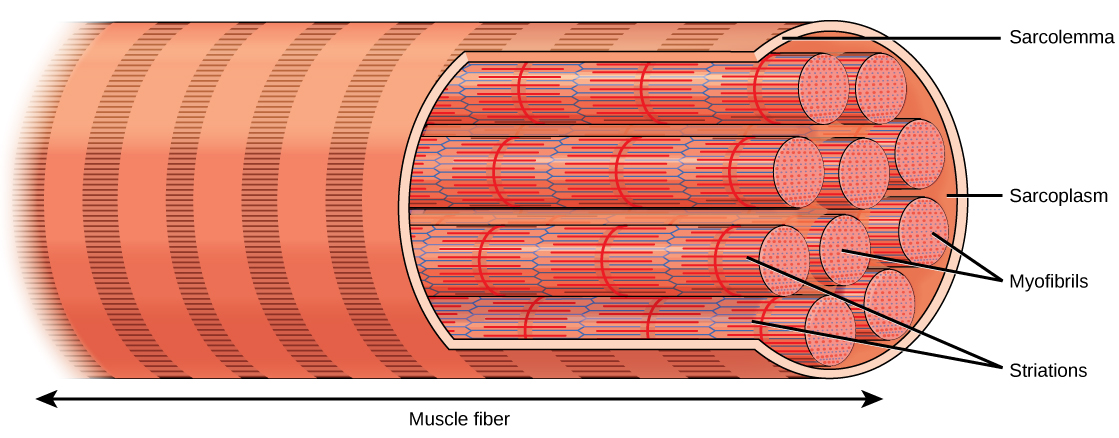
The striated appearance of skeletal muscle tissue is a result of repeating bands of the proteins actin and myosin that are present along the length of myofibrils. Dark A bands and light I bands repeat along myofibrils, and the alignment of myofibrils in the cell causes the entire cell to appear striated or banded.
Each I band has a dense line running vertically through the middle called a Z disc or Z line. The Z discs mark the border of units called sarcomeres, which are the functional units of skeletal muscle. One sarcomere is the space between two consecutive Z discs and contains one entire A band and two halves of an I band, one on either side of the A band. A myofibril is composed of many sarcomeres running along its length, and as the sarcomeres individually contract, the myofibrils and muscle cells shorten ((Figure)).
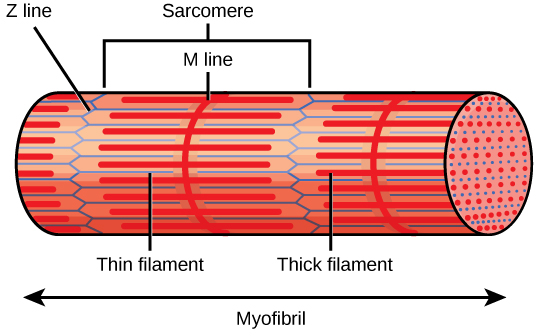
Myofibrils are composed of smaller structures called myofilaments. There are two main types of filaments: thick filaments and thin filaments; each has different compositions and locations. Thick filaments occur only in the A band of a myofibril. Thin filaments attach to a protein in the Z disc called alpha-actinin and occur across the entire length of the I band and partway into the A band. The region at which thick and thin filaments overlap has a dense appearance, as there is little space between the filaments. Thin filaments do not extend all the way into the A bands, leaving a central region of the A band that only contains thick filaments. This central region of the A band looks slightly lighter than the rest of the A band and is called the H zone. The middle of the H zone has a vertical line called the M line, at which accessory proteins hold together thick filaments. Both the Z disc and the M line hold myofilaments in place to maintain the structural arrangement and layering of the myofibril. Myofibrils are connected to each other by intermediate, or desmin, filaments that attach to the Z disc.
Thick and thin filaments are themselves composed of proteins. Thick filaments are composed of the protein myosin. The tail of a myosin molecule connects with other myosin molecules to form the central region of a thick filament near the M line, whereas the heads align on either side of the thick filament where the thin filaments overlap. The primary component of thin filaments is the actin protein. Two other components of the thin filament are tropomyosin and troponin. Actin has binding sites for myosin attachment. Strands of tropomyosin block the binding sites and prevent actin–myosin interactions when the muscles are at rest. Troponin consists of three globular subunits. One subunit binds to tropomyosin, one subunit binds to actin, and one subunit binds Ca2+ ions.
View this animation showing the organization of muscle fibers.
For a muscle cell to contract, the sarcomere must shorten. However, thick and thin filaments—the components of sarcomeres—do not shorten. Instead, they slide by one another, causing the sarcomere to shorten while the filaments remain the same length. The sliding filament theory of muscle contraction was developed to fit the differences observed in the named bands on the sarcomere at different degrees of muscle contraction and relaxation. The mechanism of contraction is the binding of myosin to actin, forming cross-bridges that generate filament movement ((Figure)).
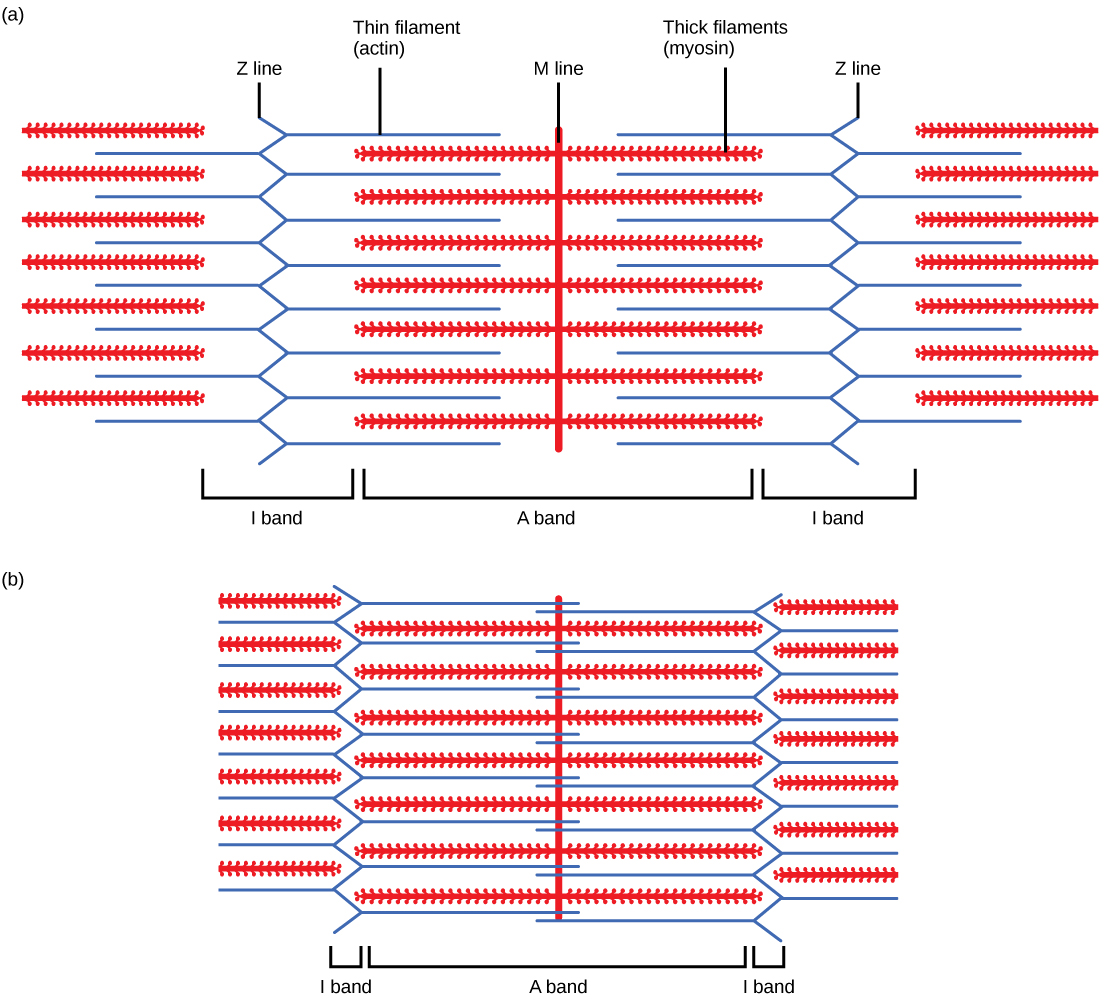
When a sarcomere shortens, some regions shorten whereas others stay the same length. A sarcomere is defined as the distance between two consecutive Z discs or Z lines; when a muscle contracts, the distance between the Z discs is reduced. The H zone—the central region of the A zone—contains only thick filaments and is shortened during contraction. The I band contains only thin filaments and also shortens. The A band does not shorten—it remains the same length—but A bands of different sarcomeres move closer together during contraction, eventually disappearing. Thin filaments are pulled by the thick filaments toward the center of the sarcomere until the Z discs approach the thick filaments. The zone of overlap, in which thin filaments and thick filaments occupy the same area, increases as the thin filaments move inward.
The motion of muscle shortening occurs as myosin heads bind to actin and pull the actin inwards. This action requires energy, which is provided by ATP. Myosin binds to actin at a binding site on the globular actin protein. Myosin has another binding site for ATP at which enzymatic activity hydrolyzes ATP to ADP, releasing an inorganic phosphate molecule and energy.
ATP binding causes myosin to release actin, allowing actin and myosin to detach from each other. After this happens, the newly bound ATP is converted to ADP and inorganic phosphate, Pi. The enzyme at the binding site on myosin is called ATPase. The energy released during ATP hydrolysis changes the angle of the myosin head into a “cocked” position. The myosin head is then in a position for further movement, possessing potential energy, but ADP and Pi are still attached. If actin binding sites are covered and unavailable, the myosin will remain in the high energy configuration with ATP hydrolyzed, but still attached.
If the actin binding sites are uncovered, a cross-bridge will form; that is, the myosin head spans the distance between the actin and myosin molecules. Pi is then released, allowing myosin to expend the stored energy as a conformational change. The myosin head moves toward the M line, pulling the actin along with it. As the actin is pulled, the filaments move approximately 10 nm toward the M line. This movement is called the power stroke, as it is the step at which force is produced. As the actin is pulled toward the M line, the sarcomere shortens and the muscle contracts.
When the myosin head is “cocked,” it contains energy and is in a high-energy configuration. This energy is expended as the myosin head moves through the power stroke; at the end of the power stroke, the myosin head is in a low-energy position. After the power stroke, ADP is released; however, the cross-bridge formed is still in place, and actin and myosin are bound together. ATP can then attach to myosin, which allows the cross-bridge cycle to start again and further muscle contraction can occur ((Figure)).
Watch this video explaining how a muscle contraction is signaled.
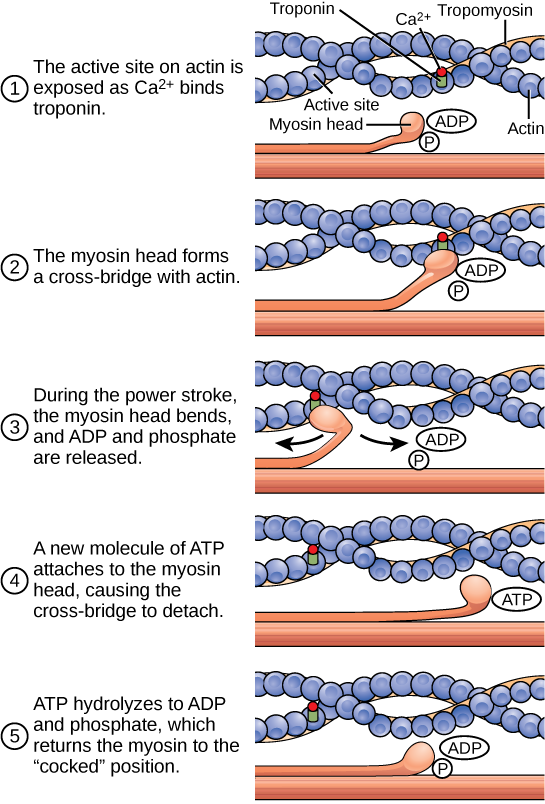
Which of the following statements about muscle contraction is true?
<!–<para>B–>
View this animation of the cross-bridge muscle contraction.
When a muscle is in a resting state, actin and myosin are separated. To keep actin from binding to the active site on myosin, regulatory proteins block the molecular binding sites. Tropomyosin blocks myosin binding sites on actin molecules, preventing cross-bridge formation and preventing contraction in a muscle without nervous input. Troponin binds to tropomyosin and helps to position it on the actin molecule; it also binds calcium ions.
To enable a muscle contraction, tropomyosin must change conformation, uncovering the myosin-binding site on an actin molecule and allowing cross-bridge formation. This can only happen in the presence of calcium, which is kept at extremely low concentrations in the sarcoplasm. If present, calcium ions bind to troponin, causing conformational changes in troponin that allow tropomyosin to move away from the myosin binding sites on actin. Once the tropomyosin is removed, a cross-bridge can form between actin and myosin, triggering contraction. Cross-bridge cycling continues until Ca2+ ions and ATP are no longer available and tropomyosin again covers the binding sites on actin.
Excitation–contraction coupling is the link (transduction) between the action potential generated in the sarcolemma and the start of a muscle contraction. The trigger for calcium release from the sarcoplasmic reticulum into the sarcoplasm is a neural signal. Each skeletal muscle fiber is controlled by a motor neuron, which conducts signals from the brain or spinal cord to the muscle. The area of the sarcolemma on the muscle fiber that interacts with the neuron is called the motor end plate. The end of the neuron’s axon is called the synaptic terminal, and it does not actually contact the motor end plate. A small space called the synaptic cleft separates the synaptic terminal from the motor end plate. Electrical signals travel along the neuron’s axon, which branches through the muscle and connects to individual muscle fibers at a neuromuscular junction.
The ability of cells to communicate electrically requires that the cells expend energy to create an electrical gradient across their cell membranes. This charge gradient is carried by ions, which are differentially distributed across the membrane. Each ion exerts an electrical influence and a concentration influence. Just as milk will eventually mix with coffee without the need to stir, ions also distribute themselves evenly, if they are permitted to do so. In this case, they are not permitted to return to an evenly mixed state.
The sodium–potassium ATPase uses cellular energy to move K+ ions inside the cell and Na+ ions outside. This alone accumulates a small electrical charge, but a big concentration gradient. There is lots of K+ in the cell and lots of Na+ outside the cell. Potassium is able to leave the cell through K+ channels that are open 90% of the time, and it does. However, Na+ channels are rarely open, so Na+ remains outside the cell. When K+ leaves the cell, obeying its concentration gradient, that effectively leaves a negative charge behind. So at rest, there is a large concentration gradient for Na+ to enter the cell, and there is an accumulation of negative charges left behind in the cell. This is the resting membrane potential. Potential in this context means a separation of electrical charge that is capable of doing work. It is measured in volts, just like a battery. However, the transmembrane potential is considerably smaller (0.07 V); therefore, the small value is expressed as millivolts (mV) or 70 mV. Because the inside of a cell is negative compared with the outside, a minus sign signifies the excess of negative charges inside the cell, −70 mV.
If an event changes the permeability of the membrane to Na+ ions, they will enter the cell. That will change the voltage. This is an electrical event, called an action potential, that can be used as a cellular signal. Communication occurs between nerves and muscles through neurotransmitters. Neuron action potentials cause the release of neurotransmitters from the synaptic terminal into the synaptic cleft, where they can then diffuse across the synaptic cleft and bind to a receptor molecule on the motor end plate. The motor end plate possesses junctional folds—folds in the sarcolemma that create a large surface area for the neurotransmitter to bind to receptors. The receptors are actually sodium channels that open to allow the passage of Na+ into the cell when they receive a neurotransmitter signal.
Acetylcholine (ACh) is a neurotransmitter released by motor neurons that binds to receptors in the motor end plate. Neurotransmitter release occurs when an action potential travels down the motor neuron’s axon, resulting in altered permeability of the synaptic terminal membrane and an influx of calcium. The Ca2+ ions allow synaptic vesicles to move to and bind with the presynaptic membrane (on the neuron), and release neurotransmitter from the vesicles into the synaptic cleft. Once released by the synaptic terminal, ACh diffuses across the synaptic cleft to the motor end plate, where it binds with ACh receptors. As a neurotransmitter binds, these ion channels open, and Na+ ions cross the membrane into the muscle cell. This reduces the voltage difference between the inside and outside of the cell, which is called depolarization. As ACh binds at the motor end plate, this depolarization is called an end-plate potential. The depolarization then spreads along the sarcolemma, creating an action potential as sodium channels adjacent to the initial depolarization site sense the change in voltage and open. The action potential moves across the entire cell, creating a wave of depolarization.
ACh is broken down by the enzyme acetylcholinesterase (AChE) into acetyl and choline. AChE resides in the synaptic cleft, breaking down ACh so that it does not remain bound to ACh receptors, which would cause unwanted extended muscle contraction ((Figure)).
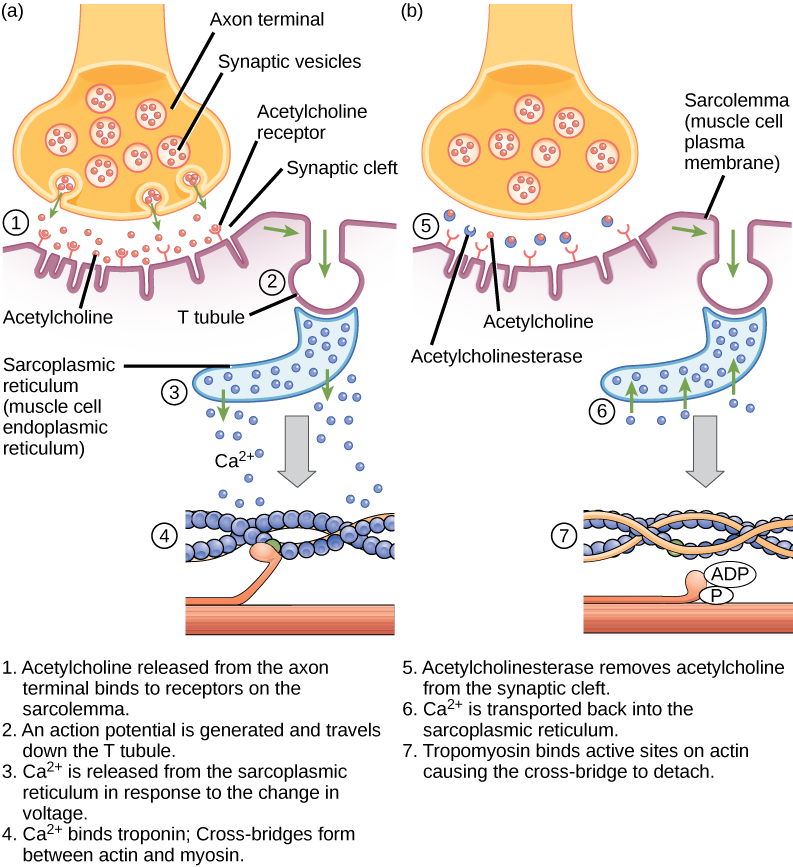
The deadly nerve gas Sarin irreversibly inhibits Acetylcholinesterase. What effect would Sarin have on muscle contraction?
<!–<para> In the presence of Sarin, acetycholine is not removed from the synapse, resulting in continuous stimulation of the muscle plasma membrane. At first, muscle activity is intense and uncontrolled, but the ion gradients dissipate, so electrical signals in the T-tubules are no longer possible. The result is paralysis, leading to death by asphyxiation.–>
After depolarization, the membrane returns to its resting state. This is called repolarization, during which voltage-gated sodium channels close. Potassium channels continue at 90% conductance. Because the plasma membrane sodium–potassium ATPase always transports ions, the resting state (negatively charged inside relative to the outside) is restored. The period immediately following the transmission of an impulse in a nerve or muscle, in which a neuron or muscle cell regains its ability to transmit another impulse, is called the refractory period. During the refractory period, the membrane cannot generate another action potential. The refractory period allows the voltage-sensitive ion channels to return to their resting configurations. The sodium potassium ATPase continually moves Na+ back out of the cell and K+ back into the cell, and the K+ leaks out leaving negative charge behind. Very quickly, the membrane repolarizes, so that it can again be depolarized.
Neural control initiates the formation of actin–myosin cross-bridges, leading to the sarcomere shortening involved in muscle contraction. These contractions extend from the muscle fiber through connective tissue to pull on bones, causing skeletal movement. The pull exerted by a muscle is called tension, and the amount of force created by this tension can vary. This enables the same muscles to move very light objects and very heavy objects. In individual muscle fibers, the amount of tension produced depends on the cross-sectional area of the muscle fiber and the frequency of neural stimulation.
The number of cross-bridges formed between actin and myosin determine the amount of tension that a muscle fiber can produce. Cross-bridges can only form where thick and thin filaments overlap, allowing myosin to bind to actin. If more cross-bridges are formed, more myosin will pull on actin, and more tension will be produced.
The ideal length of a sarcomere during production of maximal tension occurs when thick and thin filaments overlap to the greatest degree. If a sarcomere at rest is stretched past an ideal resting length, thick and thin filaments do not overlap to the greatest degree, and fewer cross-bridges can form. This results in fewer myosin heads pulling on actin, and less tension is produced. As a sarcomere is shortened, the zone of overlap is reduced as the thin filaments reach the H zone, which is composed of myosin tails. Because it is myosin heads that form cross-bridges, actin will not bind to myosin in this zone, reducing the tension produced by this myofiber. If the sarcomere is shortened even more, thin filaments begin to overlap with each other—reducing cross-bridge formation even further, and producing even less tension. Conversely, if the sarcomere is stretched to the point at which thick and thin filaments do not overlap at all, no cross-bridges are formed and no tension is produced. This amount of stretching does not usually occur because accessory proteins, internal sensory nerves, and connective tissue oppose extreme stretching.
The primary variable determining force production is the number of myofibers within the muscle that receive an action potential from the neuron that controls that fiber. When using the biceps to pick up a pencil, the motor cortex of the brain only signals a few neurons of the biceps, and only a few myofibers respond. In vertebrates, each myofiber responds fully if stimulated. When picking up a piano, the motor cortex signals all of the neurons in the biceps and every myofiber participates. This is close to the maximum force the muscle can produce. As mentioned above, increasing the frequency of action potentials (the number of signals per second) can increase the force a bit more, because the tropomyosin is flooded with calcium.
The body contains three types of muscle tissue: skeletal muscle, cardiac muscle, and smooth muscle. Skeleton muscle tissue is composed of sarcomeres, the functional units of muscle tissue. Muscle contraction occurs when sarcomeres shorten, as thick and thin filaments slide past each other, which is called the sliding filament model of muscle contraction. ATP provides the energy for cross-bridge formation and filament sliding. Regulatory proteins, such as troponin and tropomyosin, control cross-bridge formation. Excitation–contraction coupling transduces the electrical signal of the neuron, via acetylcholine, to an electrical signal on the muscle membrane, which initiates force production. The number of muscle fibers contracting determines how much force the whole muscle produces.
(Figure) Which of the following statements about muscle contraction is true?
(Figure) B
(Figure) The deadly nerve gas Sarin irreversibly inhibits Acetylcholinesterase. What effect would Sarin have on muscle contraction?
(Figure) In the presence of Sarin, acetycholine is not removed from the synapse, resulting in continuous stimulation of the muscle plasma membrane. At first, muscle activity is intense and uncontrolled, but the ion gradients dissipate, so electrical signals in the T-tubules are no longer possible. The result is paralysis, leading to death by asphyxiation.
In relaxed muscle, the myosin-binding site on actin is blocked by ________.
D
The cell membrane of a muscle fiber is called a ________.
B
The muscle relaxes if no new nerve signal arrives. However the neurotransmitter from the previous stimulation is still present in the synapse. The activity of ________ helps to remove this neurotransmitter.
D
The ability of a muscle to generate tension immediately after stimulation is dependent on:
D
Botulinum toxin causes flaccid paralysis of the muscles, and is used for cosmetic purposes under the name Botox. Which of the following is the most likely mechanism of action of Botox?
D
How would muscle contractions be affected if ATP was completely depleted in a muscle fiber?
Because ATP is required for myosin to release from actin, muscles would remain rigidly contracted until more ATP was available for the myosin cross-bridge release. This is why dead vertebrates undergo rigor mortis.
What factors contribute to the amount of tension produced in an individual muscle fiber?
The cross-sectional area, the length of the muscle fiber at rest, and the frequency of neural stimulation.
What effect will low blood calcium have on neurons? What effect will low blood calcium have on skeletal muscles?
Neurons will not be able to release neurotransmitter without calcium. Skeletal muscles have calcium stored and don’t need any from the outside.
Skeletal muscles can only produce a mechanical force as they are contracted, but a leg flexes and extends while walking. How can muscles perform this task?
Muscles are able to drive locomotion (and other tasks involving opposing motions) because they are paired. When walking, the hamstring muscle contracts first, causing the leg to flex around the knee joint. The quadriceps muscle then contracts (while the hamstring relaxes and extends) to straighten the leg as the foot returns to the ground.
Chapter 38 in OpenStax Concepts of Biology 2e

An animal’s endocrine system controls body processes through the production, secretion, and regulation of hormones, which serve as chemical “messengers” functioning in cellular and organ activity and, ultimately, maintaining the body’s homeostasis. The endocrine system plays a role in growth, metabolism, and sexual development. In humans, common endocrine system diseases include thyroid disease and diabetes mellitus. In organisms that undergo metamorphosis, the process is controlled by the endocrine system. The transformation from tadpole to frog, for example, is complex and nuanced to adapt to specific environments and ecological circumstances.
Chapter 37 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Maintaining homeostasis within the body requires the coordination of many different systems and organs. Communication between neighboring cells, and between cells and tissues in distant parts of the body, occurs through the release of chemicals called hormones. Hormones are released into body fluids (usually blood) that carry these chemicals to their target cells. At the target cells, which are cells that have a receptor for a signal or ligand from a signal cell, the hormones elicit a response. The cells, tissues, and organs that secrete hormones make up the endocrine system. Examples of glands of the endocrine system include the adrenal glands, which produce hormones such as epinephrine and norepinephrine that regulate responses to stress, and the thyroid gland, which produces thyroid hormones that regulate metabolic rates.
Although there are many different hormones in the human body, they can be divided into three classes based on their chemical structure: lipid-derived, amino acid-derived, and peptide (peptide and proteins) hormones. One of the key distinguishing features of lipid-derived hormones is that they can diffuse across plasma membranes whereas the amino acid-derived and peptide hormones cannot.
Most lipid hormones are derived from cholesterol and thus are structurally similar to it, as illustrated in (Figure). The primary class of lipid hormones in humans is the steroid hormones. Chemically, these hormones are usually ketones or alcohols; their chemical names will end in “-ol” for alcohols or “-one” for ketones. Examples of steroid hormones include estradiol, which is an estrogen, or female sex hormone, and testosterone, which is an androgen, or male sex hormone. These two hormones are released by the female and male reproductive organs, respectively. Other steroid hormones include aldosterone and cortisol, which are released by the adrenal glands along with some other types of androgens. Steroid hormones are insoluble in water, and they are transported by transport proteins in blood. As a result, they remain in circulation longer than peptide hormones. For example, cortisol has a half-life of 60 to 90 minutes, while epinephrine, an amino acid derived-hormone, has a half-life of approximately one minute.
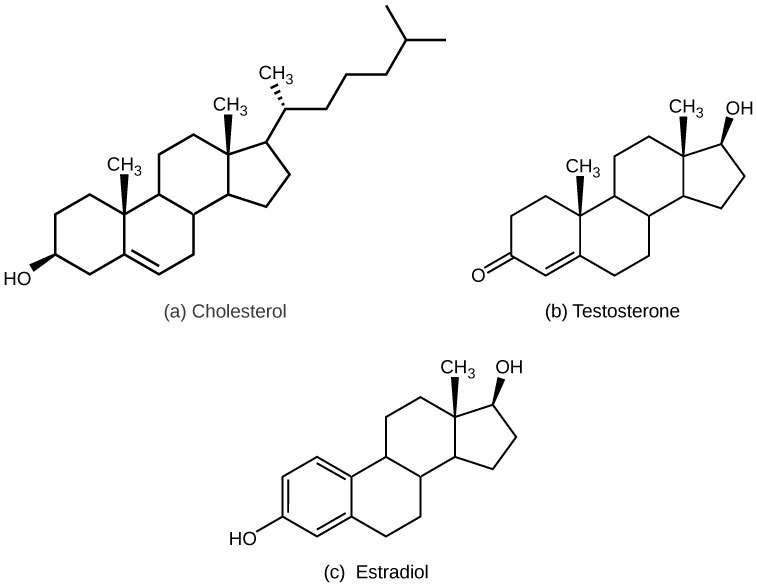
The amino acid-derived hormones are relatively small molecules that are derived from the amino acids tyrosine and tryptophan, shown in (Figure). If a hormone is amino acid-derived, its chemical name will end in “-ine”. Examples of amino acid-derived hormones include epinephrine and norepinephrine, which are synthesized in the medulla of the adrenal glands, and thyroxine, which is produced by the thyroid gland. The pineal gland in the brain makes and secretes melatonin which regulates sleep cycles.
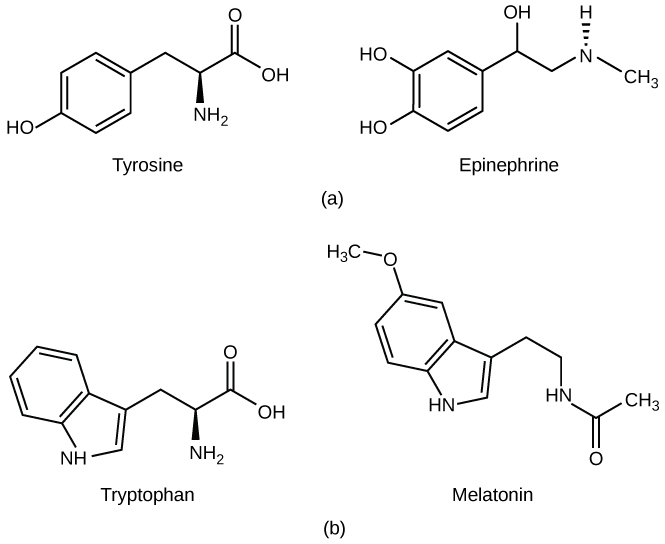
The structure of peptide hormones is that of a polypeptide chain (chain of amino acids). The peptide hormones include molecules that are short polypeptide chains, such as antidiuretic hormone and oxytocin produced in the brain and released into the blood in the posterior pituitary gland. This class also includes small proteins, like growth hormones produced by the pituitary, and large glycoproteins such as follicle-stimulating hormone produced by the pituitary. (Figure) illustrates these peptide hormones.
Secreted peptides like insulin are stored within vesicles in the cells that synthesize them. They are then released in response to stimuli such as high blood glucose levels in the case of insulin. Amino acid-derived and polypeptide hormones are water-soluble and insoluble in lipids. These hormones cannot pass through plasma membranes of cells; therefore, their receptors are found on the surface of the target cells.
EndocrinologistAn endocrinologist is a medical doctor who specializes in treating disorders of the endocrine glands, hormone systems, and glucose and lipid metabolic pathways. An endocrine surgeon specializes in the surgical treatment of endocrine diseases and glands. Some of the diseases that are managed by endocrinologists: disorders of the pancreas (diabetes mellitus), disorders of the pituitary (gigantism, acromegaly, and pituitary dwarfism), disorders of the thyroid gland (goiter and Graves’ disease), and disorders of the adrenal glands (Cushing’s disease and Addison’s disease).
Endocrinologists are required to assess patients and diagnose endocrine disorders through extensive use of laboratory tests. Many endocrine diseases are diagnosed using tests that stimulate or suppress endocrine organ functioning. Blood samples are then drawn to determine the effect of stimulating or suppressing an endocrine organ on the production of hormones. For example, to diagnose diabetes mellitus, patients are required to fast for 12 to 24 hours. They are then given a sugary drink, which stimulates the pancreas to produce insulin to decrease blood glucose levels. A blood sample is taken one to two hours after the sugar drink is consumed. If the pancreas is functioning properly, the blood glucose level will be within a normal range. Another example is the A1C test, which can be performed during blood screening. The A1C test measures average blood glucose levels over the past two to three months by examining how well the blood glucose is being managed over a long time.
Once a disease has been diagnosed, endocrinologists can prescribe lifestyle changes and/or medications to treat the disease. Some cases of diabetes mellitus can be managed by exercise, weight loss, and a healthy diet; in other cases, medications may be required to enhance insulin release. If the disease cannot be controlled by these means, the endocrinologist may prescribe insulin injections.
In addition to clinical practice, endocrinologists may also be involved in primary research and development activities. For example, ongoing islet transplant research is investigating how healthy pancreas islet cells may be transplanted into diabetic patients. Successful islet transplants may allow patients to stop taking insulin injections.
There are three basic types of hormones: lipid-derived, amino acid-derived, and peptide. Lipid-derived hormones are structurally similar to cholesterol and include steroid hormones such as estradiol and testosterone. Amino acid-derived hormones are relatively small molecules and include the adrenal hormones epinephrine and norepinephrine. Peptide hormones are polypeptide chains or proteins and include the pituitary hormones, antidiuretic hormone (vasopressin), and oxytocin.
A newly discovered hormone contains four amino acids linked together. Under which chemical class would this hormone be classified?
C
Which class of hormones can diffuse through plasma membranes?
A
Why are steroids able to diffuse across the plasma membrane?
D
Although there are many different hormones in the human body, they can be divided into three classes based on their chemical structure. What are these classes and what is one factor that distinguishes them?
Although there are many different hormones in the human body, they can be divided into three classes based on their chemical structure: lipid-derived, amino acid-derived, and peptide hormones. One of the key distinguishing features of the lipid-derived hormones is that they can diffuse across plasma membranes whereas the amino acid-derived and peptide hormones cannot.
Where is insulin stored, and why would it be released?
Secreted peptides such as insulin are stored within vesicles in the cells that synthesize them. They are then released in response to stimuli such as high blood glucose levels in the case of insulin.
Glucagon is the peptide hormone that signals for the body to release glucose into the bloodstream. How does glucagon contribute to maintaining homeostasis throughout the body? What other hormones are involved in regulating the blood glucose cycle?
Glucagon acts in opposition to insulin, the peptide hormone that stimulates cells to take up glucose from the bloodstream, to maintain blood glucose within healthy levels. When glucagon is released into the blood in response to falling blood sugar levels, the liver catabolizes its glycogen stores to release glucose. If glucagon does not function properly, the blood sugar will drop too low from insulin signaling driving cellular uptake from the blood.
Chapter 37 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Hormones mediate changes in target cells by binding to specific hormone receptors. In this way, even though hormones circulate throughout the body and come into contact with many different cell types, they only affect cells that possess the necessary receptors. Receptors for a specific hormone may be found on many different cells or may be limited to a small number of specialized cells. For example, thyroid hormones act on many different tissue types, stimulating metabolic activity throughout the body. Cells can have many receptors for the same hormone but often also possess receptors for different types of hormones. The number of receptors that respond to a hormone determines the cell’s sensitivity to that hormone, and the resulting cellular response. Additionally, the number of receptors that respond to a hormone can change over time, resulting in increased or decreased cell sensitivity. In up-regulation, the number of receptors increases in response to rising hormone levels, making the cell more sensitive to the hormone and allowing for more cellular activity. When the number of receptors decreases in response to rising hormone levels, called down-regulation, cellular activity is reduced.
Receptor binding alters cellular activity and results in an increase or decrease in normal body processes. Depending on the location of the protein receptor on the target cell and the chemical structure of the hormone, hormones can mediate changes directly by binding to intracellular hormone receptors and modulating gene transcription, or indirectly by binding to cell surface receptors and stimulating signaling pathways.
Lipid-derived (soluble) hormones such as steroid hormones diffuse across the membranes of the endocrine cell. Once outside the cell, they bind to transport proteins that keep them soluble in the bloodstream. At the target cell, the hormones are released from the carrier protein and diffuse across the lipid bilayer of the plasma membrane of cells. The steroid hormones pass through the plasma membrane of a target cell and adhere to intracellular receptors residing in the cytoplasm or in the nucleus. The cell signaling pathways induced by the steroid hormones regulate specific genes on the cell’s DNA. The hormones and receptor complex act as transcription regulators by increasing or decreasing the synthesis of mRNA molecules of specific genes. This, in turn, determines the amount of corresponding protein that is synthesized by altering gene expression. This protein can be used either to change the structure of the cell or to produce enzymes that catalyze chemical reactions. In this way, the steroid hormone regulates specific cell processes as illustrated in (Figure).
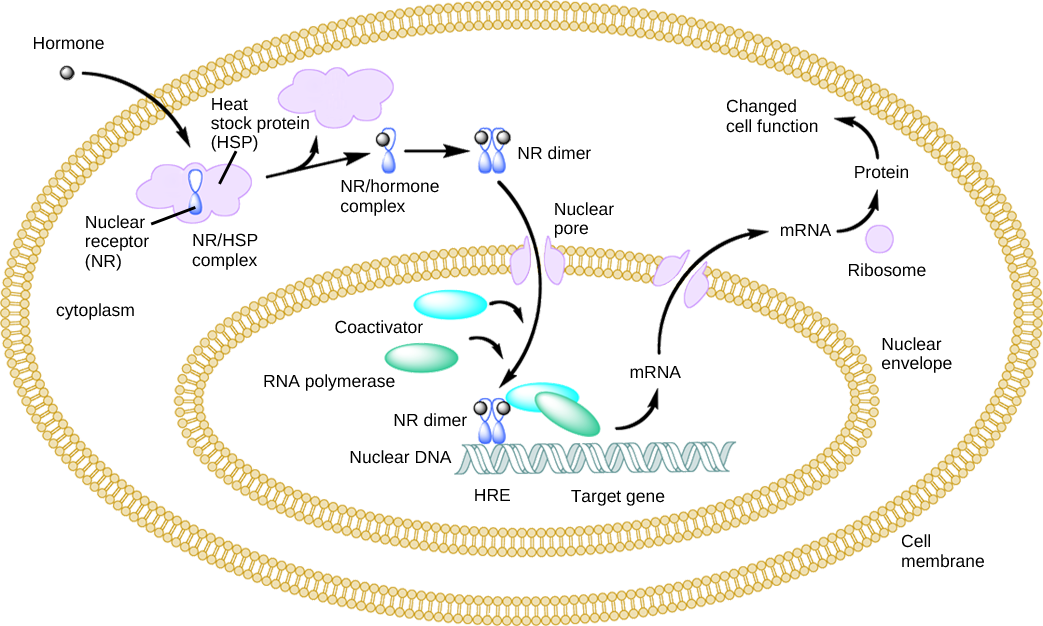
Heat shock proteins (HSP) are so named because they help refold misfolded proteins. In response to increased temperature (a “heat shock”), heat shock proteins are activated by release from the NR/HSP complex. At the same time, transcription of HSP genes is activated. Why do you think the cell responds to a heat shock by increasing the activity of proteins that help refold misfolded proteins?
<!–<para> Proteins unfold, or denature, at higher temperatures.–>
Other lipid-soluble hormones that are not steroid hormones, such as vitamin D and thyroxine, have receptors located in the nucleus. The hormones diffuse across both the plasma membrane and the nuclear envelope, then bind to receptors in the nucleus. The hormone-receptor complex stimulates transcription of specific genes.
Amino acid derived hormones and polypeptide hormones are not lipid-derived (lipid-soluble) and therefore cannot diffuse through the plasma membrane of cells. Lipid insoluble hormones bind to receptors on the outer surface of the plasma membrane, via plasma membrane hormone receptors. Unlike steroid hormones, lipid insoluble hormones do not directly affect the target cell because they cannot enter the cell and act directly on DNA. Binding of these hormones to a cell surface receptor results in activation of a signaling pathway; this triggers intracellular activity and carries out the specific effects associated with the hormone. In this way, nothing passes through the cell membrane; the hormone that binds at the surface remains at the surface of the cell while the intracellular product remains inside the cell. The hormone that initiates the signaling pathway is called a first messenger, which activates a second messenger in the cytoplasm, as illustrated in (Figure).
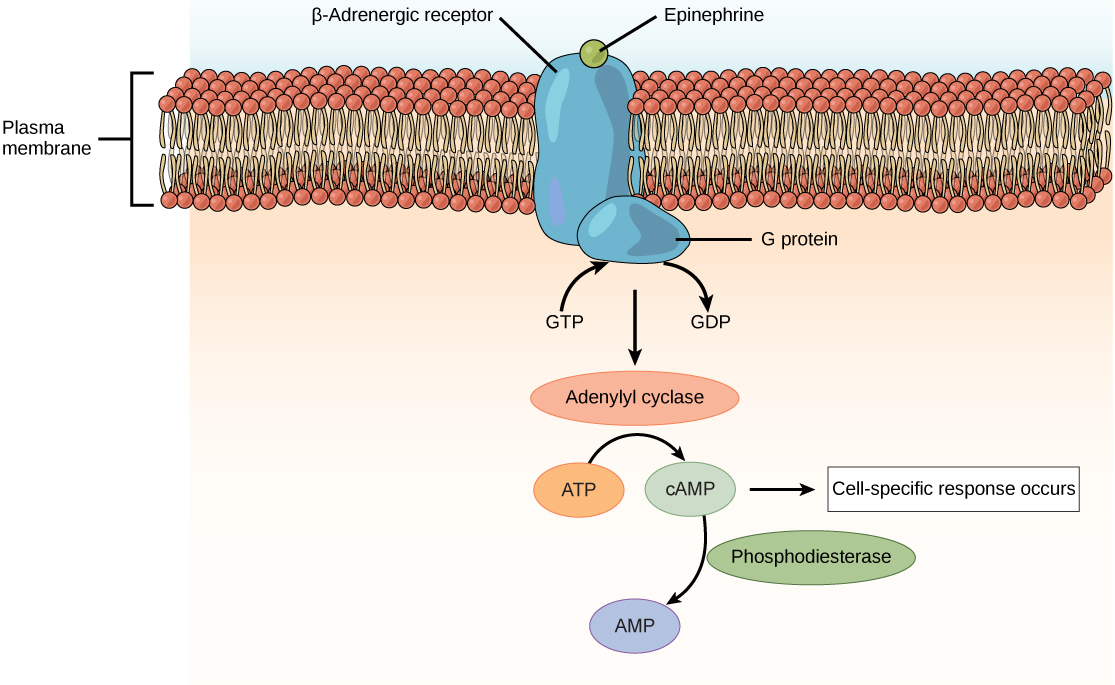
One very important second messenger is cyclic AMP (cAMP). When a hormone binds to its membrane receptor, a G-protein that is associated with the receptor is activated; G-proteins are proteins separate from receptors that are found in the cell membrane. When a hormone is not bound to the receptor, the G-protein is inactive and is bound to guanosine diphosphate, or GDP. When a hormone binds to the receptor, the G-protein is activated by binding guanosine triphosphate, or GTP, in place of GDP. After binding, GTP is hydrolysed by the G-protein into GDP and becomes inactive.
The activated G-protein in turn activates a membrane-bound enzyme called adenylyl cyclase. Adenylyl cyclase catalyzes the conversion of ATP to cAMP. cAMP, in turn, activates a group of proteins called protein kinases, which transfer a phosphate group from ATP to a substrate molecule in a process called phosphorylation. The phosphorylation of a substrate molecule changes its structural orientation, thereby activating it. These activated molecules can then mediate changes in cellular processes.
The effect of a hormone is amplified as the signaling pathway progresses. The binding of a hormone at a single receptor causes the activation of many G-proteins, which activates adenylyl cyclase. Each molecule of adenylyl cyclase then triggers the formation of many molecules of cAMP. Further amplification occurs as protein kinases, once activated by cAMP, can catalyze many reactions. In this way, a small amount of hormone can trigger the formation of a large amount of cellular product. To stop hormone activity, cAMP is deactivated by the cytoplasmic enzyme phosphodiesterase, or PDE. PDE is always present in the cell and breaks down cAMP to control hormone activity, preventing overproduction of cellular products.
The specific response of a cell to a lipid insoluble hormone depends on the type of receptors that are present on the cell membrane and the substrate molecules present in the cell cytoplasm. Cellular responses to hormone binding of a receptor include altering membrane permeability and metabolic pathways, stimulating synthesis of proteins and enzymes, and activating hormone release.
Hormones cause cellular changes by binding to receptors on target cells. The number of receptors on a target cell can increase or decrease in response to hormone activity. Hormones can affect cells directly through intracellular hormone receptors or indirectly through plasma membrane hormone receptors.
Lipid-derived (soluble) hormones can enter the cell by diffusing across the plasma membrane and binding to DNA to regulate gene transcription and to change the cell’s activities by inducing production of proteins that affect, in general, the long-term structure and function of the cell. Lipid insoluble hormones bind to receptors on the plasma membrane surface and trigger a signaling pathway to change the cell’s activities by inducing production of various cell products that affect the cell in the short-term. The hormone is called a first messenger and the cellular component is called a second messenger. G-proteins activate the second messenger (cyclic AMP), triggering the cellular response. Response to hormone binding is amplified as the signaling pathway progresses. Cellular responses to hormones include the production of proteins and enzymes and altered membrane permeability.
(Figure) Heat shock proteins (HSP) are so named because they help refold misfolded proteins. In response to increased temperature (a “heat shock”), heat shock proteins are activated by release from the NR/HSP complex. At the same time, transcription of HSP genes is activated. Why do you think the cell responds to a heat shock by increasing the activity of proteins that help refold misfolded proteins?
(Figure) Proteins unfold, or denature, at higher temperatures.
A new antagonist molecule has been discovered that binds to and blocks plasma membrane receptors. What effect will this antagonist have on testosterone, a steroid hormone?
D
What effect will a cAMP inhibitor have on a peptide hormone-mediated signaling pathway?
D
When insulin binds to its receptor, the complex is endocytosed into the cell. This is an example of ______ in response to hormone signaling.
D
Name two important functions of hormone receptors.
The number of receptors that respond to a hormone can change, resulting in increased or decreased cell sensitivity. The number of receptors can increase in response to rising hormone levels, called up-regulation, making the cell more sensitive to the hormone and allowing for more cellular activity. The number of receptors can also decrease in response to rising hormone levels, called down-regulation, leading to reduced cellular activity.
How can hormones mediate changes?
Depending on the location of the protein receptor on the target cell and the chemical structure of the hormone, hormones can mediate changes directly by binding to intracellular receptors and modulating gene transcription, or indirectly by binding to cell surface receptors and stimulating signaling pathways.
Why is cAMP-mediated signal amplification not required in steroid hormone signaling? Describe how steroid signaling is amplified instead.
In steroid hormone signaling, the steroid interacts directly with its intracellular receptor rather than signaling through a second messenger like cAMP. The steroid-receptor complex then moves into the nucleus, and directly regulates the transcription of DNA. This will cause the cell to produce multiple copies of the target gene, amplifying the signal from the hormone at the transcriptional level rather than the second messenger level.
Chapter 37 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Hormones have a wide range of effects and modulate many different body processes. The key regulatory processes that will be examined here are those affecting the excretory system, the reproductive system, metabolism, blood calcium concentrations, growth, and the stress response.
Maintaining a proper water balance in the body is important to avoid dehydration or over-hydration (hyponatremia). The water concentration of the body is monitored by osmoreceptors in the hypothalamus, which detect the concentration of electrolytes in the extracellular fluid. The concentration of electrolytes in the blood rises when there is water loss caused by excessive perspiration, inadequate water intake, or low blood volume due to blood loss. An increase in blood electrolyte levels results in a neuronal signal being sent from the osmoreceptors in hypothalamic nuclei. The pituitary gland has two components: anterior and posterior. The anterior pituitary is composed of glandular cells that secrete protein hormones. The posterior pituitary is an extension of the hypothalamus. It is composed largely of neurons that are continuous with the hypothalamus.
The hypothalamus produces a polypeptide hormone known as antidiuretic hormone (ADH), which is transported to and released from the posterior pituitary gland. The principal action of ADH is to regulate the amount of water excreted by the kidneys. As ADH (which is also known as vasopressin) causes direct water reabsorption from the kidney tubules, salts and wastes are concentrated in what will eventually be excreted as urine. The hypothalamus controls the mechanisms of ADH secretion, either by regulating blood volume or the concentration of water in the blood. Dehydration or physiological stress can cause an increase of osmolarity above 300 mOsm/L, which in turn, raises ADH secretion and water will be retained, causing an increase in blood pressure. ADH travels in the bloodstream to the kidneys. Once at the kidneys, ADH changes the kidneys to become more permeable to water by temporarily inserting water channels, aquaporins, into the kidney tubules. Water moves out of the kidney tubules through the aquaporins, reducing urine volume. The water is reabsorbed into the capillaries lowering blood osmolarity back toward normal. As blood osmolarity decreases, a negative feedback mechanism reduces osmoreceptor activity in the hypothalamus, and ADH secretion is reduced. ADH release can be reduced by certain substances, including alcohol, which can cause increased urine production and dehydration.
Chronic underproduction of ADH or a mutation in the ADH receptor results in diabetes insipidus. If the posterior pituitary does not release enough ADH, water cannot be retained by the kidneys and is lost as urine. This causes increased thirst, but water taken in is lost again and must be continually consumed. If the condition is not severe, dehydration may not occur, but severe cases can lead to electrolyte imbalances due to dehydration.
Another hormone responsible for maintaining electrolyte concentrations in extracellular fluids is aldosterone, a steroid hormone that is produced by the adrenal cortex. In contrast to ADH, which promotes the reabsorption of water to maintain proper water balance, aldosterone maintains proper water balance by enhancing Na+ reabsorption and K+ secretion from extracellular fluid of the cells in kidney tubules. Because it is produced in the cortex of the adrenal gland and affects the concentrations of minerals Na+ and K+, aldosterone is referred to as a mineralocorticoid, a corticosteroid that affects ion and water balance. Aldosterone release is stimulated by a decrease in blood sodium levels, blood volume, or blood pressure, or an increase in blood potassium levels. It also prevents the loss of Na+ from sweat, saliva, and gastric juice. The reabsorption of Na+ also results in the osmotic reabsorption of water, which alters blood volume and blood pressure.
Aldosterone production can be stimulated by low blood pressure, which triggers a sequence of chemical release, as illustrated in (Figure). When blood pressure drops, the renin-angiotensin-aldosterone system (RAAS) is activated. Cells in the juxtaglomerular apparatus, which regulates the functions of the nephrons of the kidney, detect this and release renin. Renin, an enzyme, circulates in the blood and reacts with a plasma protein produced by the liver called angiotensinogen. When angiotensinogen is cleaved by renin, it produces angiotensin I, which is then converted into angiotensin II in the lungs. Angiotensin II functions as a hormone and then causes the release of the hormone aldosterone by the adrenal cortex, resulting in increased Na+ reabsorption, water retention, and an increase in blood pressure. Angiotensin II in addition to being a potent vasoconstrictor also causes an increase in ADH and increased thirst, both of which help to raise blood pressure.
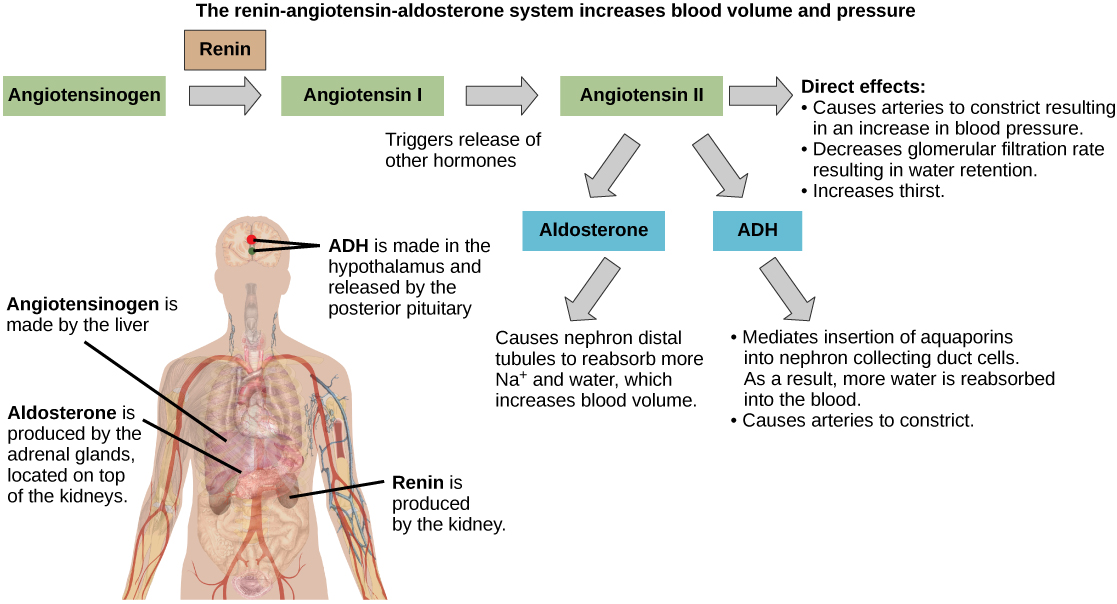
Regulation of the reproductive system is a process that requires the action of hormones from the pituitary gland, the adrenal cortex, and the gonads. During puberty in both males and females, the hypothalamus produces gonadotropin-releasing hormone (GnRH), which stimulates the production and release of follicle-stimulating hormone (FSH) and luteinizing hormone (LH) from the anterior pituitary gland. These hormones regulate the gonads (testes in males and ovaries in females) and therefore are called gonadotropins. In both males and females, FSH stimulates gamete production and LH stimulates production of hormones by the gonads. An increase in gonad hormone levels inhibits GnRH production through a negative feedback loop.
In males, FSH stimulates the maturation of sperm cells. FSH production is inhibited by the hormone inhibin, which is released by the testes. LH stimulates production of the sex hormones (androgens) by the interstitial cells of the testes and therefore is also called interstitial cell-stimulating hormone.
The most widely known androgen in males is testosterone. Testosterone promotes the production of sperm and masculine characteristics. The adrenal cortex also produces small amounts of testosterone precursor, although the role of this additional hormone production is not fully understood.
The Dangers of Synthetic Hormones

Some athletes attempt to boost their performance by using artificial hormones that enhance muscle performance. Anabolic steroids, a form of the male sex hormone testosterone, are one of the most widely known performance-enhancing drugs. Steroids are used to help build muscle mass. Other hormones that are used to enhance athletic performance include erythropoietin, which triggers the production of red blood cells, and human growth hormone, which can help in building muscle mass. Most performance enhancing drugs are illegal for nonmedical purposes. They are also banned by national and international governing bodies including the International Olympic Committee, the U.S. Olympic Committee, the National Collegiate Athletic Association, the Major League Baseball, and the National Football League.
The side effects of synthetic hormones are often significant and nonreversible, and in some cases, fatal. Androgens produce several complications such as liver dysfunctions and liver tumors, prostate gland enlargement, difficulty urinating, premature closure of epiphyseal cartilages, testicular atrophy, infertility, and immune system depression. The physiological strain caused by these substances is often greater than what the body can handle, leading to unpredictable and dangerous effects and linking their use to heart attacks, strokes, and impaired cardiac function.
In females, FSH stimulates development of egg cells, called ova, which develop in structures called follicles. Follicle cells produce the hormone inhibin, which inhibits FSH production. LH also plays a role in the development of ova, induction of ovulation, and stimulation of estradiol and progesterone production by the ovaries, as illustrated in (Figure). Estradiol and progesterone are steroid hormones that prepare the body for pregnancy. Estradiol produces secondary sex characteristics in females, while both estradiol and progesterone regulate the menstrual cycle.
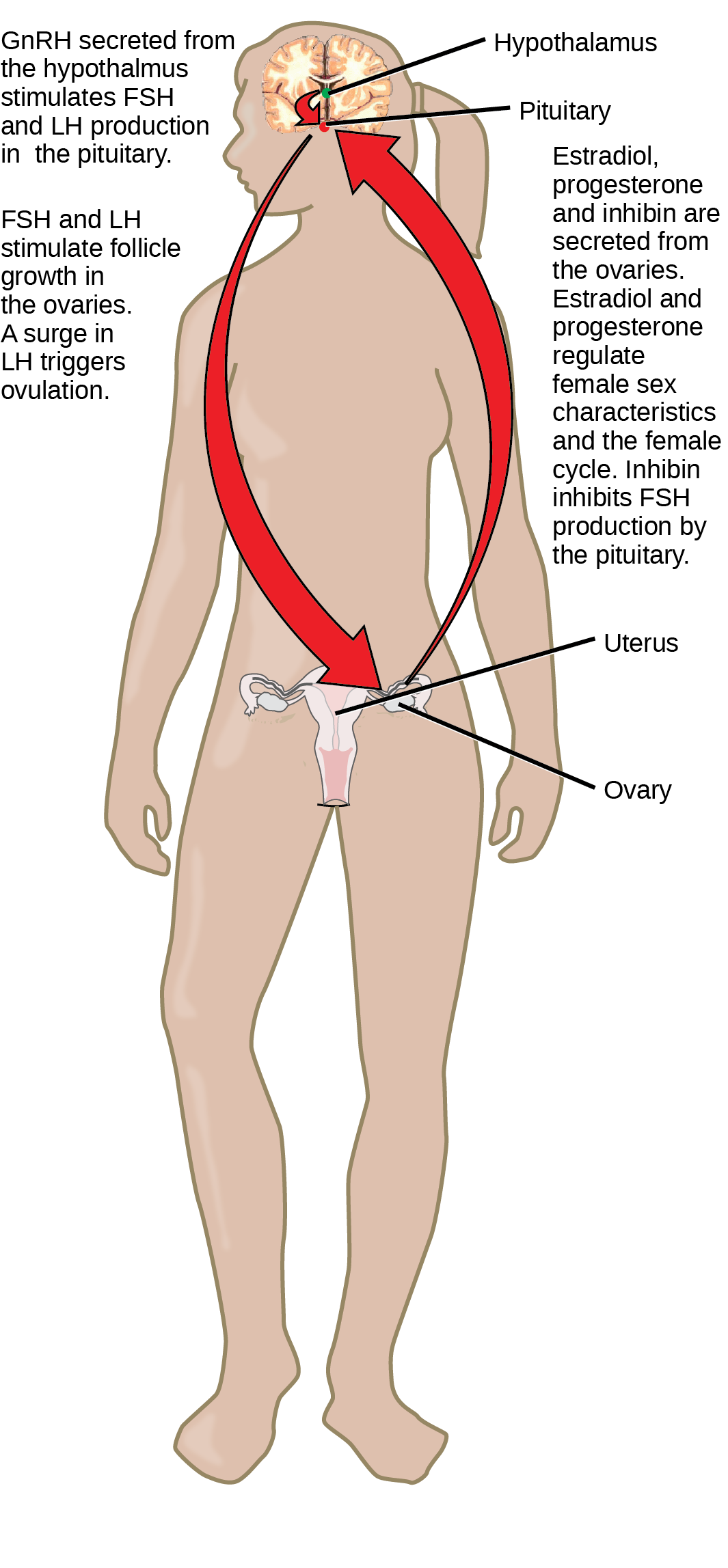
In addition to producing FSH and LH, the anterior portion of the pituitary gland also produces the hormone prolactin (PRL) in females. Prolactin stimulates the production of milk by the mammary glands following childbirth. Prolactin levels are regulated by the hypothalamic hormones prolactin-releasing hormone (PRH) and prolactin-inhibiting hormone (PIH), which is now known to be dopamine. PRH stimulates the release of prolactin and PIH inhibits it.
The posterior pituitary releases the hormone oxytocin, which stimulates uterine contractions during childbirth. The uterine smooth muscles are not very sensitive to oxytocin until late in pregnancy when the number of oxytocin receptors in the uterus peaks. Stretching of tissues in the uterus and cervix stimulates oxytocin release during childbirth. Contractions increase in intensity as blood levels of oxytocin rise via a positive feedback mechanism until the birth is complete. Oxytocin also stimulates the contraction of myoepithelial cells around the milk-producing mammary glands. As these cells contract, milk is forced from the secretory alveoli into milk ducts and is ejected from the breasts in milk ejection (“let-down”) reflex. Oxytocin release is stimulated by the suckling of an infant, which triggers the synthesis of oxytocin in the hypothalamus and its release into circulation at the posterior pituitary.
Blood glucose levels vary widely over the course of a day as periods of food consumption alternate with periods of fasting. Insulin and glucagon are the two hormones primarily responsible for maintaining homeostasis of blood glucose levels. Additional regulation is mediated by the thyroid hormones.
Cells of the body require nutrients in order to function, and these nutrients are obtained through feeding. In order to manage nutrient intake, storing excess intake and utilizing reserves when necessary, the body uses hormones to moderate energy stores. Insulin is produced by the beta cells of the pancreas, which are stimulated to release insulin as blood glucose levels rise (for example, after a meal is consumed). Insulin lowers blood glucose levels by enhancing the rate of glucose uptake and utilization by target cells, which use glucose for ATP production. It also stimulates the liver to convert glucose to glycogen, which is then stored by cells for later use. Insulin also increases glucose transport into certain cells, such as muscle cells and the liver. This results from an insulin-mediated increase in the number of glucose transporter proteins in cell membranes, which remove glucose from circulation by facilitated diffusion. As insulin binds to its target cell via insulin receptors and signal transduction, it triggers the cell to incorporate glucose transport proteins into its membrane. This allows glucose to enter the cell, where it can be used as an energy source. However, this does not occur in all cells: some cells, including those in the kidneys and brain, can access glucose without the use of insulin. Insulin also stimulates the conversion of glucose to fat in adipocytes and the synthesis of proteins. These actions mediated by insulin cause blood glucose concentrations to fall, called a hypoglycemic “low sugar” effect, which inhibits further insulin release from beta cells through a negative feedback loop.
This animation describes the role of insulin and the pancreas in diabetes.
Impaired insulin function can lead to a condition called diabetes mellitus, the main symptoms of which are illustrated in (Figure). This can be caused by low levels of insulin production by the beta cells of the pancreas, or by reduced sensitivity of tissue cells to insulin. This prevents glucose from being absorbed by cells, causing high levels of blood glucose, or hyperglycemia (high sugar). High blood glucose levels make it difficult for the kidneys to recover all the glucose from nascent urine, resulting in glucose being lost in urine. High glucose levels also result in less water being reabsorbed by the kidneys, causing high amounts of urine to be produced; this may result in dehydration. Over time, high blood glucose levels can cause nerve damage to the eyes and peripheral body tissues, as well as damage to the kidneys and cardiovascular system. Oversecretion of insulin can cause hypoglycemia, low blood glucose levels. This causes insufficient glucose availability to cells, often leading to muscle weakness, and can sometimes cause unconsciousness or death if left untreated.
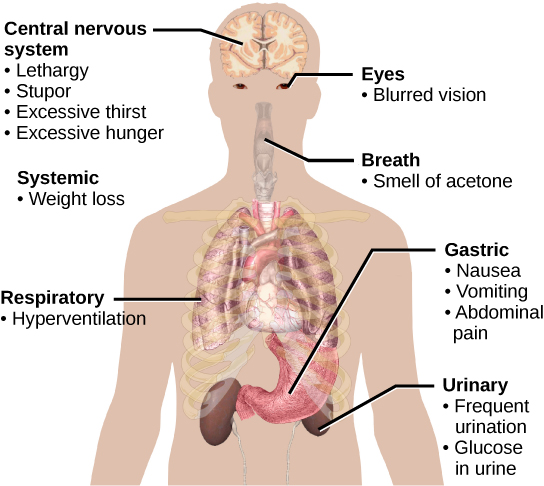
When blood glucose levels decline below normal levels, for example between meals or when glucose is utilized rapidly during exercise, the hormone glucagon is released from the alpha cells of the pancreas. Glucagon raises blood glucose levels, eliciting what is called a hyperglycemic effect, by stimulating the breakdown of glycogen to glucose in skeletal muscle cells and liver cells in a process called glycogenolysis. Glucose can then be utilized as energy by muscle cells and released into circulation by the liver cells. Glucagon also stimulates absorption of amino acids from the blood by the liver, which then converts them to glucose. This process of glucose synthesis is called gluconeogenesis. Glucagon also stimulates adipose cells to release fatty acids into the blood. These actions mediated by glucagon result in an increase in blood glucose levels to normal homeostatic levels. Rising blood glucose levels inhibit further glucagon release by the pancreas via a negative feedback mechanism. In this way, insulin and glucagon work together to maintain homeostatic glucose levels, as shown in (Figure).
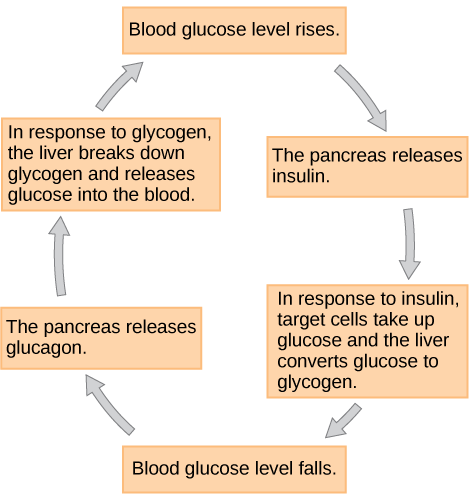
Pancreatic tumors may cause excess secretion of glucagon. Type I diabetes results from the failure of the pancreas to produce insulin. Which of the following statement about these two conditions is true?
<!–<para>B–>
The basal metabolic rate, which is the amount of calories required by the body at rest, is determined by two hormones produced by the thyroid gland: thyroxine, also known as tetraiodothyronine or T4, and triiodothyronine, also known as T3. These hormones affect nearly every cell in the body except for the adult brain, uterus, testes, blood cells, and spleen. They are transported across the plasma membrane of target cells and bind to receptors on the mitochondria resulting in increased ATP production. In the nucleus, T3 and T4 activate genes involved in energy production and glucose oxidation. This results in increased rates of metabolism and body heat production, which is known as the hormone’s calorigenic effect.
T3 and T4 release from the thyroid gland is stimulated by thyroid-stimulating hormone (TSH), which is produced by the anterior pituitary. TSH binding at the receptors of the follicle of the thyroid triggers the production of T3 and T4 from a glycoprotein called thyroglobulin. Thyroglobulin is present in the follicles of the thyroid, and is converted into thyroid hormones with the addition of iodine. Iodine is formed from iodide ions that are actively transported into the thyroid follicle from the bloodstream. A peroxidase enzyme then attaches the iodine to the tyrosine amino acid found in thyroglobulin. T3 has three iodine ions attached, while T4 has four iodine ions attached. T3 and T4 are then released into the bloodstream, with T4 being released in much greater amounts than T3. As T3 is more active than T4 and is responsible for most of the effects of thyroid hormones, tissues of the body convert T4 to T3 by the removal of an iodine ion. Most of the released T3 and T4 becomes attached to transport proteins in the bloodstream and is unable to cross the plasma membrane of cells. These protein-bound molecules are only released when blood levels of the unattached hormone begin to decline. In this way, a week’s worth of reserve hormone is maintained in the blood. Increased T3 and T4 levels in the blood inhibit the release of TSH, which results in lower T3 and T4 release from the thyroid.
The follicular cells of the thyroid require iodides (anions of iodine) in order to synthesize T3 and T4. Iodides obtained from the diet are actively transported into follicle cells resulting in a concentration that is approximately 30 times higher than in blood. The typical diet in North America provides more iodine than required due to the addition of iodide to table salt. Inadequate iodine intake, which occurs in many developing countries, results in an inability to synthesize T3 and T4 hormones. The thyroid gland enlarges in a condition called goiter, which is caused by overproduction of TSH without the formation of thyroid hormone. Thyroglobulin is contained in a fluid called colloid, and TSH stimulation results in higher levels of colloid accumulation in the thyroid. In the absence of iodine, this is not converted to thyroid hormone, and colloid begins to accumulate more and more in the thyroid gland, leading to goiter.
Disorders can arise from both the underproduction and overproduction of thyroid hormones. Hypothyroidism, underproduction of the thyroid hormones, can cause a low metabolic rate leading to weight gain, sensitivity to cold, and reduced mental activity, among other symptoms. In children, hypothyroidism can cause cretinism, which can lead to mental retardation and growth defects. Hyperthyroidism, the overproduction of thyroid hormones, can lead to an increased metabolic rate and its effects: weight loss, excess heat production, sweating, and an increased heart rate. Graves’ disease is one example of a hyperthyroid condition.
Regulation of blood calcium concentrations is important for generation of muscle contractions and nerve impulses, which are electrically stimulated. If calcium levels get too high, membrane permeability to sodium decreases and membranes become less responsive. If calcium levels get too low, membrane permeability to sodium increases and convulsions or muscle spasms can result.
Blood calcium levels are regulated by parathyroid hormone (PTH), which is produced by the parathyroid glands, as illustrated in (Figure). PTH is released in response to low blood Ca2+ levels. PTH increases Ca2+ levels by targeting the skeleton, the kidneys, and the intestine. In the skeleton, PTH stimulates osteoclasts, which causes bone to be reabsorbed, releasing Ca2+ from bone into the blood. PTH also inhibits osteoblasts, reducing Ca2+ deposition in bone. In the intestines, PTH increases dietary Ca2+ absorption, and in the kidneys, PTH stimulates reabsorption of the CA2+. While PTH acts directly on the kidneys to increase Ca2+ reabsorption, its effects on the intestine are indirect. PTH triggers the formation of calcitriol, an active form of vitamin D, which acts on the intestines to increase absorption of dietary calcium. PTH release is inhibited by rising blood calcium levels.
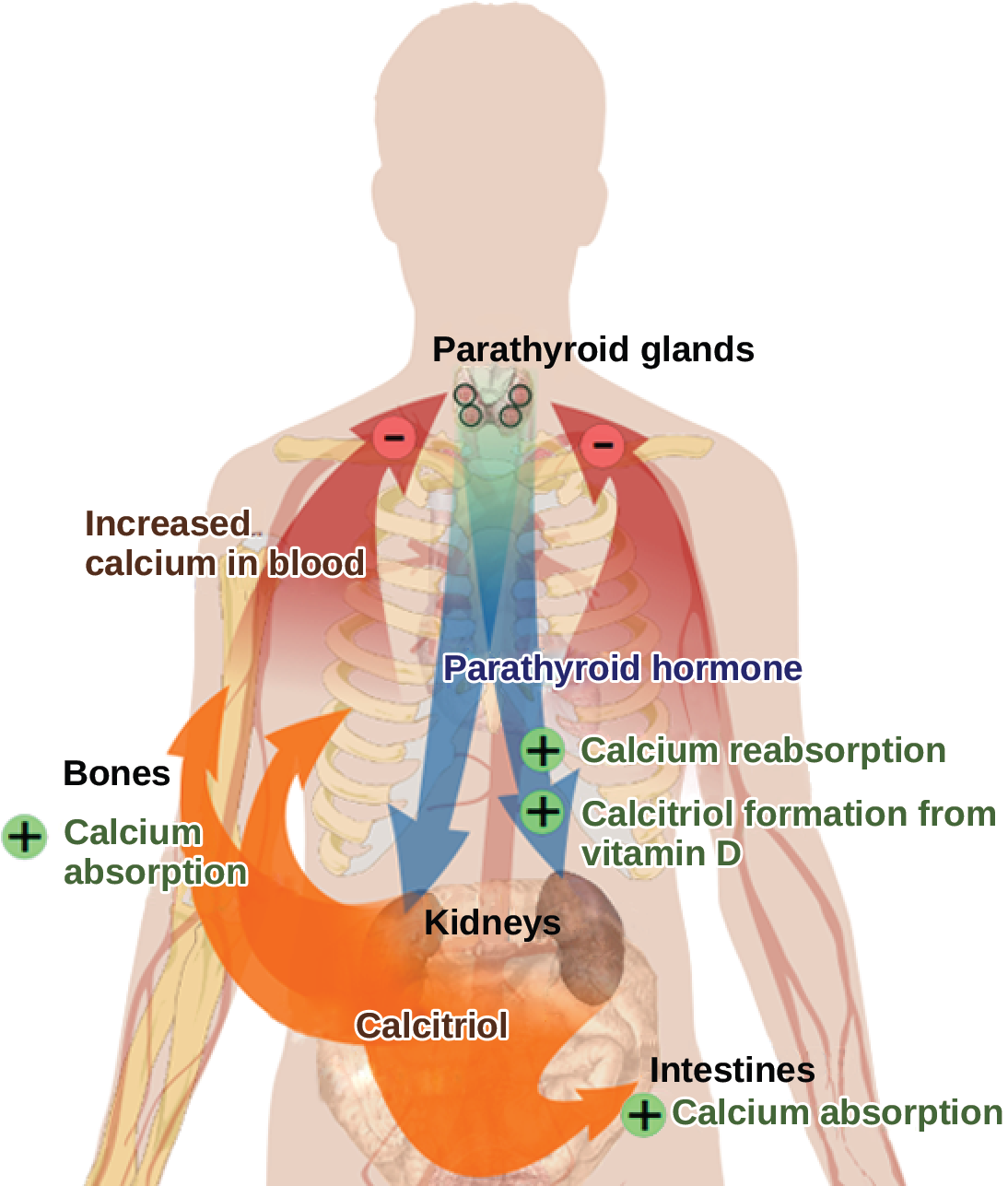
Hyperparathyroidism results from an overproduction of parathyroid hormone. This results in excessive calcium being removed from bones and introduced into blood circulation, producing structural weakness of the bones, which can lead to deformation and fractures, plus nervous system impairment due to high blood calcium levels. Hypoparathyroidism, the underproduction of PTH, results in extremely low levels of blood calcium, which causes impaired muscle function and may result in tetany (severe sustained muscle contraction).
The hormone calcitonin, which is produced by the parafollicular or C cells of the thyroid, has the opposite effect on blood calcium levels as does PTH. Calcitonin decreases blood calcium levels by inhibiting osteoclasts, stimulating osteoblasts, and stimulating calcium excretion by the kidneys. This results in calcium being added to the bones to promote structural integrity. Calcitonin is most important in children (when it stimulates bone growth), during pregnancy (when it reduces maternal bone loss), and during prolonged starvation (because it reduces bone mass loss). In healthy nonpregnant, unstarved adults, the role of calcitonin is unclear.
Hormonal regulation is required for the growth and replication of most cells in the body. Growth hormone (GH), produced by the anterior portion of the pituitary gland, accelerates the rate of protein synthesis, particularly in skeletal muscle and bones. Growth hormone has direct and indirect mechanisms of action. The first direct action of GH is stimulation of triglyceride breakdown (lipolysis) and release into the blood by adipocytes. This results in a switch by most tissues from utilizing glucose as an energy source to utilizing fatty acids. This process is called a glucose-sparing effect. In another direct mechanism, GH stimulates glycogen breakdown in the liver; the glycogen is then released into the blood as glucose. Blood glucose levels increase as most tissues are utilizing fatty acids instead of glucose for their energy needs. The GH mediated increase in blood glucose levels is called a diabetogenic effect because it is similar to the high blood glucose levels seen in diabetes mellitus.
The indirect mechanism of GH action is mediated by insulin-like growth factors (IGFs) or somatomedins, which are a family of growth-promoting proteins produced by the liver, which stimulates tissue growth. IGFs stimulate the uptake of amino acids from the blood, allowing the formation of new proteins, particularly in skeletal muscle cells, cartilage cells, and other target cells, as shown in (Figure). This is especially important after a meal, when glucose and amino acid concentration levels are high in the blood. GH levels are regulated by two hormones produced by the hypothalamus. GH release is stimulated by growth hormone-releasing hormone (GHRH) and is inhibited by growth hormone-inhibiting hormone (GHIH), also called somatostatin.
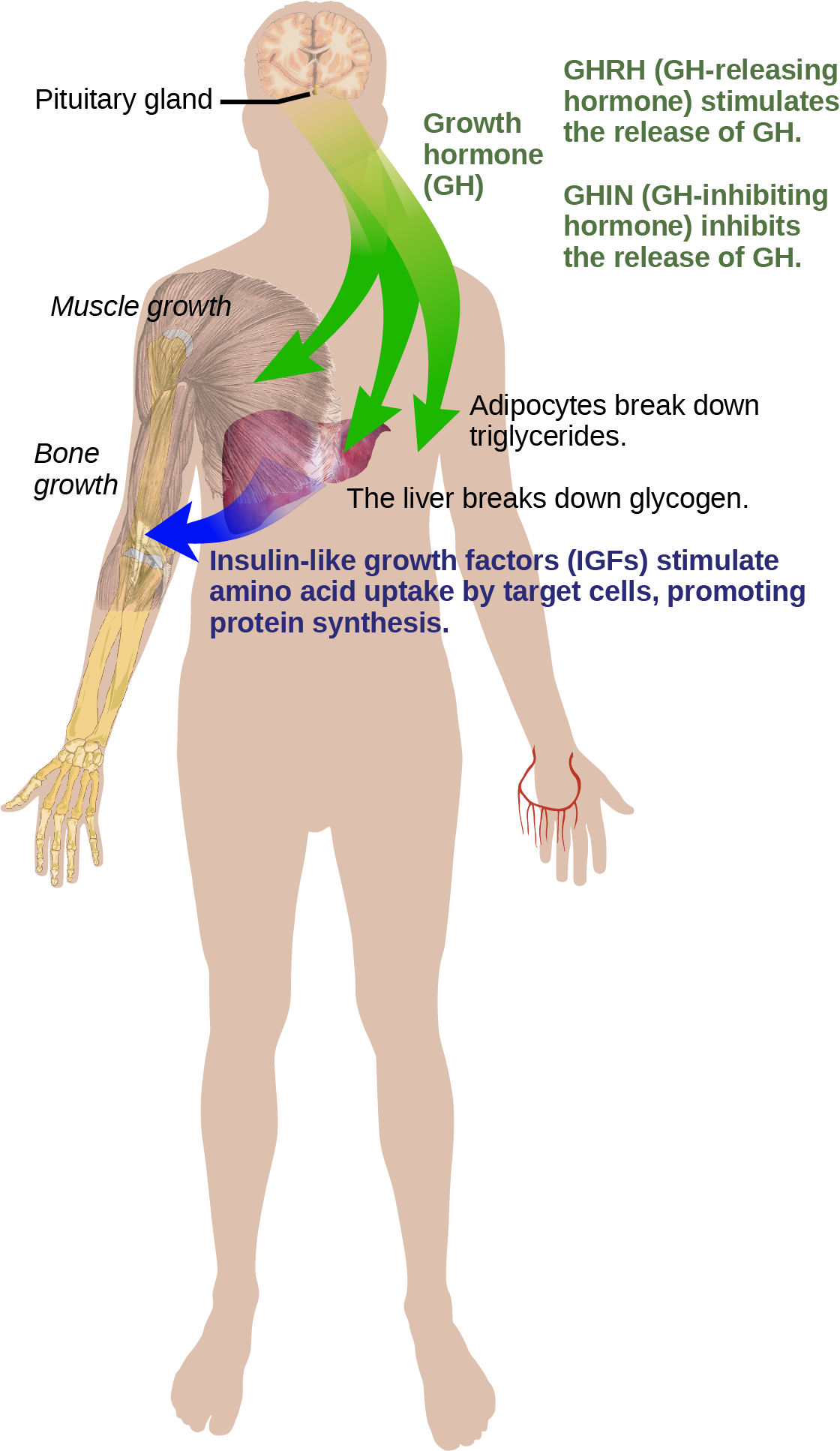
A balanced production of growth hormone is critical for proper development. Underproduction of GH in adults does not appear to cause any abnormalities, but in children it can result in pituitary dwarfism, in which growth is reduced. Pituitary dwarfism is characterized by symmetric body formation. In some cases, individuals are under 30 inches in height. Oversecretion of growth hormone can lead to gigantism in children, causing excessive growth. In some documented cases, individuals can reach heights of over eight feet. In adults, excessive GH can lead to acromegaly, a condition in which there is enlargement of bones in the face, hands, and feet that are still capable of growth.
When a threat or danger is perceived, the body responds by releasing hormones that will ready it for the “fight-or-flight” response. The effects of this response are familiar to anyone who has been in a stressful situation: increased heart rate, dry mouth, and hair standing up.
Fight-or-Flight ResponseInteractions of the endocrine hormones have evolved to ensure the body’s internal environment remains stable. Stressors are stimuli that disrupt homeostasis. The sympathetic division of the vertebrate autonomic nervous system has evolved the fight-or-flight response to counter stress-induced disruptions of homeostasis. In the initial alarm phase, the sympathetic nervous system stimulates an increase in energy levels through increased blood glucose levels. This prepares the body for physical activity that may be required to respond to stress: to either fight for survival or to flee from danger.
However, some stresses, such as illness or injury, can last for a long time. Glycogen reserves, which provide energy in the short-term response to stress, are exhausted after several hours and cannot meet long-term energy needs. If glycogen reserves were the only energy source available, neural functioning could not be maintained once the reserves became depleted due to the nervous system’s high requirement for glucose. In this situation, the body has evolved a response to counter long-term stress through the actions of the glucocorticoids, which ensure that long-term energy requirements can be met. The glucocorticoids mobilize lipid and protein reserves, stimulate gluconeogenesis, conserve glucose for use by neural tissue, and stimulate the conservation of salts and water. The mechanisms to maintain homeostasis that are described here are those observed in the human body. However, the fight-or-flight response exists in some form in all vertebrates.
The sympathetic nervous system regulates the stress response via the hypothalamus. Stressful stimuli cause the hypothalamus to signal the adrenal medulla (which mediates short-term stress responses) via nerve impulses, and the adrenal cortex, which mediates long-term stress responses, via the hormone adrenocorticotropic hormone (ACTH), which is produced by the anterior pituitary.
When presented with a stressful situation, the body responds by calling for the release of hormones that provide a burst of energy. The hormones epinephrine (also known as adrenaline) and norepinephrine (also known as noradrenaline) are released by the adrenal medulla. How do these hormones provide a burst of energy? Epinephrine and norepinephrine increase blood glucose levels by stimulating the liver and skeletal muscles to break down glycogen and by stimulating glucose release by liver cells. Additionally, these hormones increase oxygen availability to cells by increasing the heart rate and dilating the bronchioles. The hormones also prioritize body function by increasing blood supply to essential organs such as the heart, brain, and skeletal muscles, while restricting blood flow to organs not in immediate need, such as the skin, digestive system, and kidneys. Epinephrine and norepinephrine are collectively called catecholamines.
Watch this Discovery Channel animation describing the flight-or-flight response.
Long-term stress response differs from short-term stress response. The body cannot sustain the bursts of energy mediated by epinephrine and norepinephrine for long times. Instead, other hormones come into play. In a long-term stress response, the hypothalamus triggers the release of ACTH from the anterior pituitary gland. The adrenal cortex is stimulated by ACTH to release steroid hormones called corticosteroids. Corticosteroids turn on transcription of certain genes in the nuclei of target cells. They change enzyme concentrations in the cytoplasm and affect cellular metabolism. There are two main corticosteroids: glucocorticoids such as cortisol, and mineralocorticoids such as aldosterone. These hormones target the breakdown of fat into fatty acids in the adipose tissue. The fatty acids are released into the bloodstream for other tissues to use for ATP production. The glucocorticoids primarily affect glucose metabolism by stimulating glucose synthesis. Glucocorticoids also have anti-inflammatory properties through inhibition of the immune system. For example, cortisone is used as an anti-inflammatory medication; however, it cannot be used long term as it increases susceptibility to disease due to its immune-suppressing effects.
Mineralocorticoids function to regulate ion and water balance of the body. The hormone aldosterone stimulates the reabsorption of water and sodium ions in the kidney, which results in increased blood pressure and volume.
Hypersecretion of glucocorticoids can cause a condition known as Cushing’s disease, characterized by a shifting of fat storage areas of the body. This can cause the accumulation of adipose tissue in the face and neck, and excessive glucose in the blood. Hyposecretion of the corticosteroids can cause Addison’s disease, which may result in bronzing of the skin, hypoglycemia, and low electrolyte levels in the blood.
Water levels in the body are controlled by antidiuretic hormone (ADH), which is produced in the hypothalamus and triggers the reabsorption of water by the kidneys. Underproduction of ADH can cause diabetes insipidus. Aldosterone, a hormone produced by the adrenal cortex of the kidneys, enhances Na+ reabsorption from the extracellular fluids and subsequent water reabsorption by diffusion. The renin-angiotensin-aldosterone system is one way that aldosterone release is controlled.
The reproductive system is controlled by the gonadotropins follicle-stimulating hormone (FSH) and luteinizing hormone (LH), which are produced by the pituitary gland. Gonadotropin release is controlled by the hypothalamic hormone gonadotropin-releasing hormone (GnRH). FSH stimulates the maturation of sperm cells in males and is inhibited by the hormone inhibin, while LH stimulates the production of the androgen testosterone. FSH stimulates egg maturation in females, while LH stimulates the production of estrogens and progesterone. Estrogens are a group of steroid hormones produced by the ovaries that trigger the development of secondary sex characteristics in females as well as control the maturation of the ova. In females, the pituitary also produces prolactin, which stimulates milk production after childbirth, and oxytocin, which stimulates uterine contraction during childbirth and milk let-down during suckling.
Insulin is produced by the pancreas in response to rising blood glucose levels and allows cells to utilize blood glucose and store excess glucose for later use. Diabetes mellitus is caused by reduced insulin activity and causes high blood glucose levels, or hyperglycemia. Glucagon is released by the pancreas in response to low blood glucose levels and stimulates the breakdown of glycogen into glucose, which can be used by the body. The body’s basal metabolic rate is controlled by the thyroid hormones thyroxine (T4) and triiodothyronine (T3). The anterior pituitary produces thyroid stimulating hormone (TSH), which controls the release of T3 and T4 from the thyroid gland. Iodine is necessary in the production of thyroid hormone, and the lack of iodine can lead to a condition called goiter.
Parathyroid hormone (PTH) is produced by the parathyroid glands in response to low blood Ca2+ levels. The parafollicular cells of the thyroid produce calcitonin, which reduces blood Ca2+ levels. Growth hormone (GH) is produced by the anterior pituitary and controls the growth rate of muscle and bone. GH action is indirectly mediated by insulin-like growth factors (IGFs). Short-term stress causes the hypothalamus to trigger the adrenal medulla to release epinephrine and norepinephrine, which trigger the fight or flight response. Long-term stress causes the hypothalamus to trigger the anterior pituitary to release adrenocorticotropic hormone (ACTH), which causes the release of corticosteroids, glucocorticoids, and mineralocorticoids, from the adrenal cortex.
(Figure) Pancreatic tumors may cause excess secretion of glucagon. Type I diabetes results from the failure of the pancreas to produce insulin. Which of the following statement about these two conditions is true?
(Figure) B
Drinking alcoholic beverages causes an increase in urine output. This most likely occurs because alcohol:
A
FSH and LH release from the anterior pituitary is stimulated by ________.
B
What hormone is produced by beta cells of the pancreas?
C
When blood calcium levels are low, PTH stimulates:
D
How would mutations that completely ablate the function of the androgen receptor impact the phenotypic development of humans with XY chromosomes?
A
Name and describe a function of one hormone produced by the anterior pituitary and one hormone produced by the posterior pituitary.
In addition to producing FSH and LH, the anterior pituitary also produces the hormone prolactin (PRL) in females. Prolactin stimulates the production of milk by the mammary glands following childbirth. Prolactin levels are regulated by the hypothalamic hormones prolactin-releasing hormone (PRH) and prolactin-inhibiting hormone (PIH) which is now known to be dopamine. PRH stimulates the release of prolactin and PIH inhibits it. The posterior pituitary releases the hormone oxytocin, which stimulates contractions during childbirth. The uterine smooth muscles are not very sensitive to oxytocin until late in pregnancy when the number of oxytocin receptors in the uterus peaks. Stretching of tissues in the uterus and vagina stimulates oxytocin release in childbirth. Contractions increase in intensity as blood levels of oxytocin rise until the birth is complete.
Describe one direct action of growth hormone (GH).
Hormonal regulation is required for the growth and replication of most cells in the body. Growth hormone (GH), produced by the anterior pituitary, accelerates the rate of protein synthesis, particularly in skeletal muscles and bones. Growth hormone has direct and indirect mechanisms of action. The direct actions of GH include: 1) stimulation of fat breakdown (lipolysis) and release into the blood by adipocytes. This results in a switch by most tissues from utilizing glucose as an energy source to utilizing fatty acids. This process is called a glucose-sparing effect. 2) In the liver, GH stimulates glycogen breakdown, which is then released into the blood as glucose. Blood glucose levels increase as most tissues are utilizing fatty acids instead of glucose for their energy needs. The GH mediated increase in blood glucose levels is called a diabetogenic effect because it is similar to the high blood glucose levels seen in diabetes mellitus.
Researchers have recently demonstrated that stressed people are more susceptible to contracting the common cold than people who are not stressed. What kind of stress must the infected patients be experiencing, and why does it make them more susceptible to the virus?
The stressed patients that catch a cold must be chronically (long-term) stressed. Long-term stress results in the production of glucocorticoids, such as cortisol. These hormones inhibit the function of the immune system, which makes people more susceptible to infectious diseases.
Chapter 37 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Hormone production and release are primarily controlled by negative feedback. In negative feedback systems, a stimulus elicits the release of a substance; once the substance reaches a certain level, it sends a signal that stops further release of the substance. In this way, the concentration of hormones in blood is maintained within a narrow range. For example, the anterior pituitary signals the thyroid to release thyroid hormones. Increasing levels of these hormones in the blood then give feedback to the hypothalamus and anterior pituitary to inhibit further signaling to the thyroid gland, as illustrated in (Figure). There are three mechanisms by which endocrine glands are stimulated to synthesize and release hormones: humoral stimuli, hormonal stimuli, and neural stimuli.
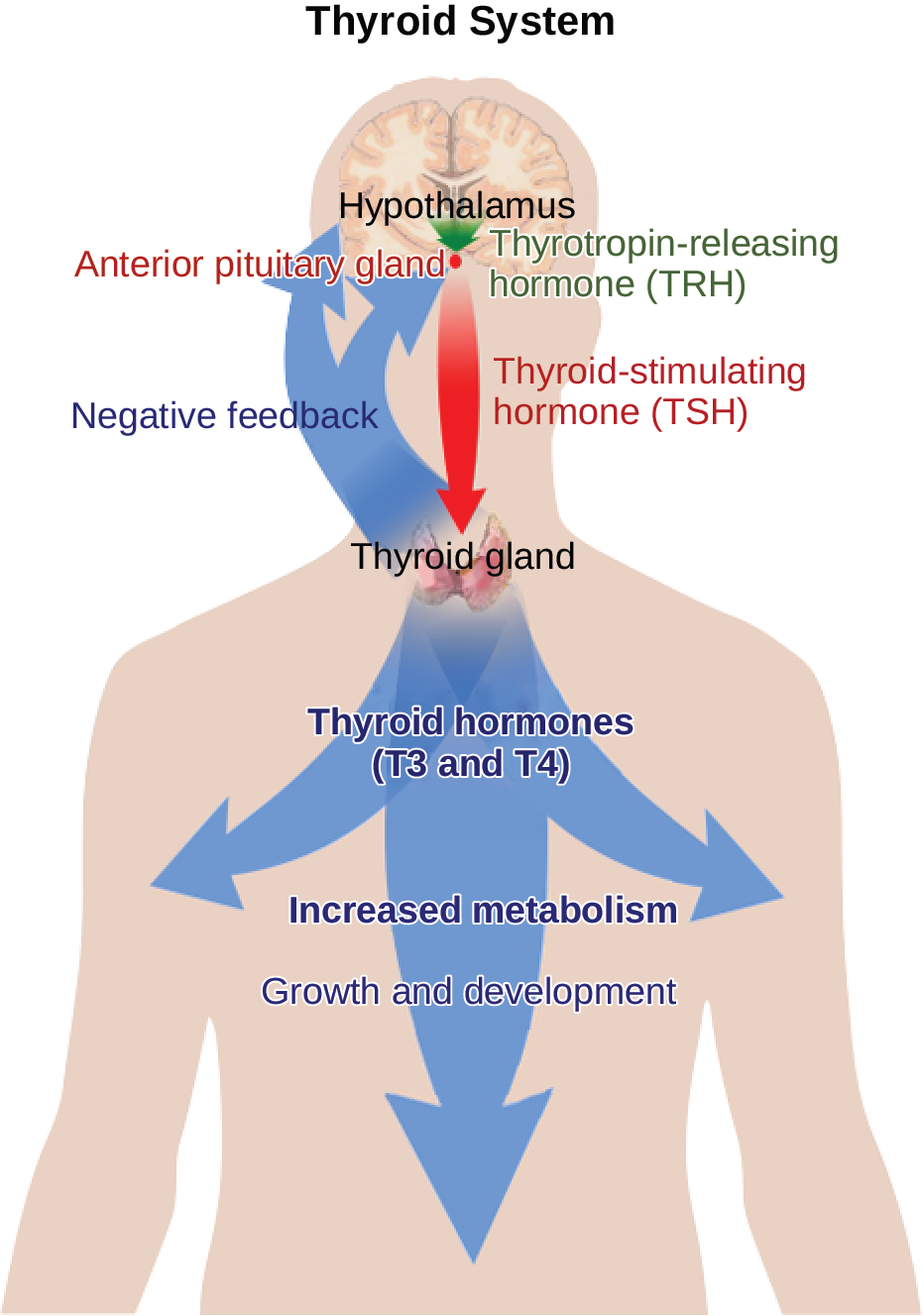
Hyperthyroidism is a condition in which the thyroid gland is overactive. Hypothyroidism is a condition in which the thyroid gland is underactive. Which of the conditions are the following two patients most likely to have?
Patient A has symptoms including weight gain, cold sensitivity, low heart rate, and fatigue.
Patient B has symptoms including weight loss, profuse sweating, increased heart rate, and difficulty sleeping.
<!–<para>Patient A has symptoms associated with decreased metabolism, and may be suffering from hypothyroidism. Patient B has symptoms associated with increased metabolism, and may be suffering from hyperthyroidism.–>
The term “humoral” is derived from the term “humor,” which refers to bodily fluids such as blood. A humoral stimulus refers to the control of hormone release in response to changes in extracellular fluids such as blood or the ion concentration in the blood. For example, a rise in blood glucose levels triggers the pancreatic release of insulin. Insulin causes blood glucose levels to drop, which signals the pancreas to stop producing insulin in a negative feedback loop.
Hormonal stimuli refers to the release of a hormone in response to another hormone. A number of endocrine glands release hormones when stimulated by hormones released by other endocrine glands. For example, the hypothalamus produces hormones that stimulate the anterior portion of the pituitary gland. The anterior pituitary in turn releases hormones that regulate hormone production by other endocrine glands. The anterior pituitary releases the thyroid-stimulating hormone, which then stimulates the thyroid gland to produce the hormones T3 and T4. As blood concentrations of T3 and T4 rise, they inhibit both the pituitary and the hypothalamus in a negative feedback loop.
In some cases, the nervous system directly stimulates endocrine glands to release hormones, which is referred to as neural stimuli. Recall that in a short-term stress response, the hormones epinephrine and norepinephrine are important for providing the bursts of energy required for the body to respond. Here, neuronal signaling from the sympathetic nervous system directly stimulates the adrenal medulla to release the hormones epinephrine and norepinephrine in response to stress.
Hormone levels are primarily controlled through negative feedback, in which rising levels of a hormone inhibit its further release. The three mechanisms of hormonal release are humoral stimuli, hormonal stimuli, and neural stimuli. Humoral stimuli refers to the control of hormonal release in response to changes in extracellular fluid levels or ion levels. Hormonal stimuli refers to the release of hormones in response to hormones released by other endocrine glands. Neural stimuli refers to the release of hormones in response to neural stimulation.
(Figure) Hyperthyroidism is a condition in which the thyroid gland is overactive. Hypothyroidism is a condition in which the thyroid gland is underactive. Which of the conditions are the following two patients most likely to have?
Patient A has symptoms including weight gain, cold sensitivity, low heart rate, and fatigue.
Patient B has symptoms including weight loss, profuse sweating, increased heart rate, and difficulty sleeping.
(Figure) Patient A has symptoms associated with decreased metabolism, and may be suffering from hypothyroidism. Patient B has symptoms associated with increased metabolism, and may be suffering from hyperthyroidism.
A rise in blood glucose levels triggers release of insulin from the pancreas. This mechanism of hormone production is stimulated by:
A
Which mechanism of hormonal stimulation would be affected if signaling and hormone release from the hypothalamus was blocked?
B
A scientist hypothesizes that the pancreas’s hormone production is controlled by neural stimuli. Which observation would support this hypothesis?
A
How is hormone production and release primarily controlled?
Hormone production and release are primarily controlled by negative feedback. In negative feedback systems, a stimulus causes the release of a substance whose effects then inhibit further release. In this way, the concentration of hormones in blood is maintained within a narrow range. For example, the anterior pituitary signals the thyroid to release thyroid hormones. Increasing levels of these hormones in the blood then feed back to the hypothalamus and anterior pituitary to inhibit further signaling to the thyroid gland.
Compare and contrast hormonal and humoral stimuli.
The term humoral is derived from the term humor, which refers to bodily fluids such as blood. Humoral stimuli refer to the control of hormone release in response to changes in extracellular fluids such as blood or the ion concentration in the blood. For example, a rise in blood glucose levels triggers the pancreatic release of insulin. Insulin causes blood glucose levels to drop, which signals the pancreas to stop producing insulin in a negative feedback loop.
Hormonal stimuli refer to the release of a hormone in response to another hormone. A number of endocrine glands release hormones when stimulated by hormones released by other endocrine organs. For example, the hypothalamus produces hormones that stimulate the anterior pituitary. The anterior pituitary in turn releases hormones that regulate hormone production by other endocrine glands. For example, the anterior pituitary releases thyroid-stimulating hormone, which stimulates the thyroid gland to produce the hormones T3 and T4. As blood concentrations of T3 and T4 rise they inhibit both the pituitary and the hypothalamus in a negative feedback loop.
Oral contraceptive pills work by delivering synthetic progestins to a woman every day. Describe why this is an effective method of birth control.
Progestins, including progesterone, are hormones that help to control the fertility cycle in women. When progesterone is released, it inhibits the production of GnRH in the hypothalamus. Without GnRH, FSH and LH are not produced in the pituitary gland, so the ovaries are not signaled to mature and release an ovum. If progesterone is delivered to the body every day, it will continuously inhibit this cycle.
Chapter 37 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Both the endocrine and nervous systems use chemical signals to communicate and regulate the body’s physiology. The endocrine system releases hormones that act on target cells to regulate development, growth, energy metabolism, reproduction, and many behaviors. The nervous system releases neurotransmitters or neurohormones that regulate neurons, muscle cells, and endocrine cells. Because the neurons can regulate the release of hormones, the nervous and endocrine systems work in a coordinated manner to regulate the body’s physiology.
The hypothalamus in vertebrates integrates the endocrine and nervous systems. The hypothalamus is an endocrine organ located in the diencephalon of the brain. It receives input from the body and other brain areas and initiates endocrine responses to environmental changes. The hypothalamus acts as an endocrine organ, synthesizing hormones and transporting them along axons to the posterior pituitary gland. It synthesizes and secretes regulatory hormones that control the endocrine cells in the anterior pituitary gland. The hypothalamus contains autonomic centers that control endocrine cells in the adrenal medulla via neuronal control.
The pituitary gland, sometimes called the hypophysis or “master gland” is located at the base of the brain in the sella turcica, a groove of the sphenoid bone of the skull, illustrated in (Figure). It is attached to the hypothalamus via a stalk called the pituitary stalk (or infundibulum). The anterior portion of the pituitary gland is regulated by releasing or release-inhibiting hormones produced by the hypothalamus, and the posterior pituitary receives signals via neurosecretory cells to release hormones produced by the hypothalamus. The pituitary has two distinct regions—the anterior pituitary and the posterior pituitary—which between them secrete nine different peptide or protein hormones. The posterior lobe of the pituitary gland contains axons of the hypothalamic neurons.
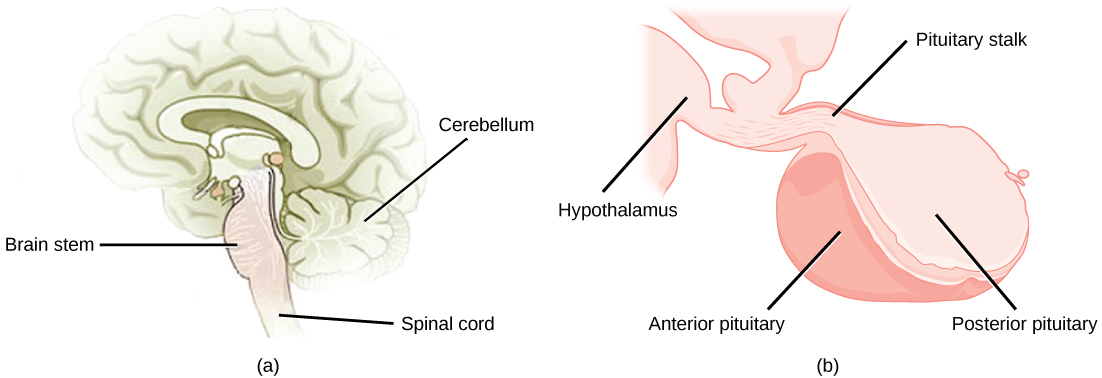
The anterior pituitary gland, or adenohypophysis, is surrounded by a capillary network that extends from the hypothalamus, down along the infundibulum, and to the anterior pituitary. This capillary network is a part of the hypophyseal portal system that carries substances from the hypothalamus to the anterior pituitary and hormones from the anterior pituitary into the circulatory system. A portal system carries blood from one capillary network to another; therefore, the hypophyseal portal system allows hormones produced by the hypothalamus to be carried directly to the anterior pituitary without first entering the circulatory system.
The anterior pituitary produces seven hormones: growth hormone (GH), prolactin (PRL), thyroid-stimulating hormone (TSH), melanin-stimulating hormone (MSH), adrenocorticotropic hormone (ACTH), follicle-stimulating hormone (FSH), and luteinizing hormone (LH). Anterior pituitary hormones are sometimes referred to as tropic hormones, because they control the functioning of other organs. While these hormones are produced by the anterior pituitary, their production is controlled by regulatory hormones produced by the hypothalamus. These regulatory hormones can be releasing hormones or inhibiting hormones, causing more or less of the anterior pituitary hormones to be secreted. These travel from the hypothalamus through the hypophyseal portal system to the anterior pituitary where they exert their effect. Negative feedback then regulates how much of these regulatory hormones are released and how much anterior pituitary hormone is secreted.
The posterior pituitary is significantly different in structure from the anterior pituitary. It is a part of the brain, extending down from the hypothalamus, and contains mostly nerve fibers and neuroglial cells, which support axons that extend from the hypothalamus to the posterior pituitary. The posterior pituitary and the infundibulum together are referred to as the neurohypophysis.
The hormones antidiuretic hormone (ADH), also known as vasopressin, and oxytocin are produced by neurons in the hypothalamus and transported within these axons along the infundibulum to the posterior pituitary. They are released into the circulatory system via neural signaling from the hypothalamus. These hormones are considered to be posterior pituitary hormones, even though they are produced by the hypothalamus, because that is where they are released into the circulatory system. The posterior pituitary itself does not produce hormones, but instead stores hormones produced by the hypothalamus and releases them into the bloodstream.
The thyroid gland is located in the neck, just below the larynx and in front of the trachea, as shown in (Figure). It is a butterfly-shaped gland with two lobes that are connected by the isthmus. It has a dark red color due to its extensive vascular system. When the thyroid swells due to dysfunction, it can be felt under the skin of the neck.
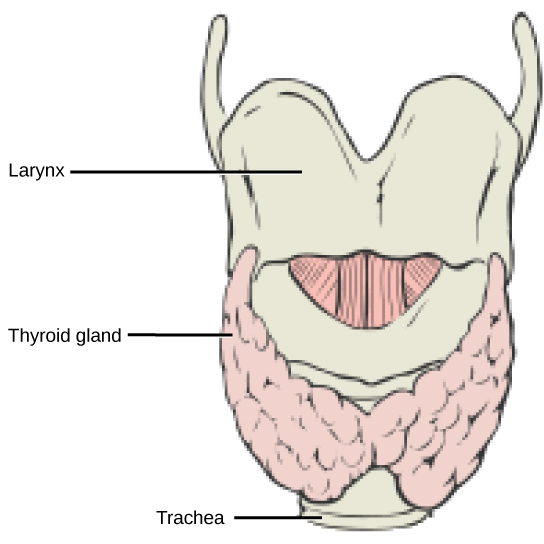
The thyroid gland is made up of many spherical thyroid follicles, which are lined with a simple cuboidal epithelium. These follicles contain a viscous fluid, called colloid, which stores the glycoprotein thyroglobulin, the precursor to the thyroid hormones. The follicles produce hormones that can be stored in the colloid or released into the surrounding capillary network for transport to the rest of the body via the circulatory system.
Thyroid follicle cells synthesize the hormone thyroxine, which is also known as T4 because it contains four atoms of iodine, and triiodothyronine, also known as T3 because it contains three atoms of iodine. Follicle cells are stimulated to release stored T3 and T4 by thyroid stimulating hormone (TSH), which is produced by the anterior pituitary. These thyroid hormones increase the rates of mitochondrial ATP production.
A third hormone, calcitonin, is produced by parafollicular cells of the thyroid either releasing hormones or inhibiting hormones. Calcitonin release is not controlled by TSH, but instead is released when calcium ion concentrations in the blood rise. Calcitonin functions to help regulate calcium concentrations in body fluids. It acts in the bones to inhibit osteoclast activity and in the kidneys to stimulate excretion of calcium. The combination of these two events lowers body fluid levels of calcium.
Most people have four parathyroid glands; however, the number can vary from two to six. These glands are located on the posterior surface of the thyroid gland, as shown in (Figure). Normally, there is a superior gland and an inferior gland associated with each of the thyroid’s two lobes. Each parathyroid gland is covered by connective tissue and contains many secretory cells that are associated with a capillary network.
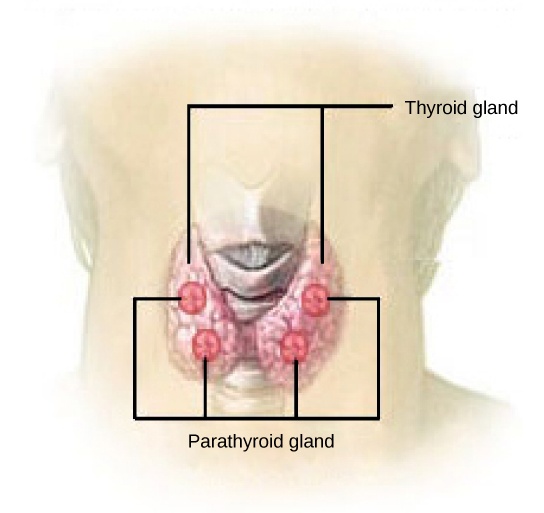
The parathyroid glands produce parathyroid hormone (PTH). PTH increases blood calcium concentrations when calcium ion levels fall below normal. PTH (1) enhances reabsorption of Ca2+ by the kidneys, (2) stimulates osteoclast activity and inhibits osteoblast activity, and (3) it stimulates synthesis and secretion of calcitriol by the kidneys, which enhances Ca2+ absorption by the digestive system. PTH is produced by chief cells of the parathyroid. PTH and calcitonin work in opposition to one another to maintain homeostatic Ca2+ levels in body fluids. Another type of cells, oxyphil cells, exist in the parathyroid but their function is not known. These hormones encourage bone growth, muscle mass, and blood cell formation in children and women.
The adrenal glands are associated with the kidneys; one gland is located on top of each kidney as illustrated in (Figure). The adrenal glands consist of an outer adrenal cortex and an inner adrenal medulla. These regions secrete different hormones.
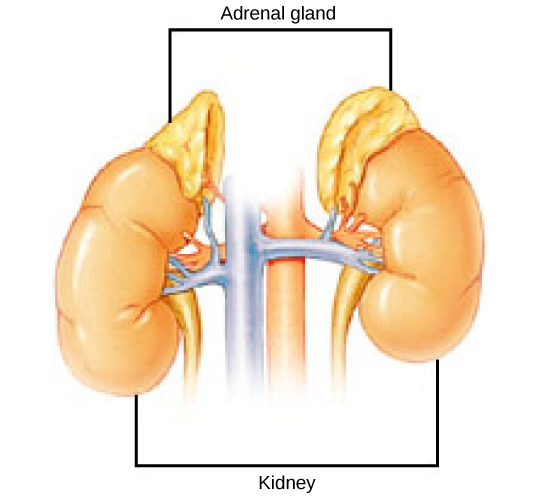
The adrenal cortex is made up of layers of epithelial cells and associated capillary networks. These layers form three distinct regions: an outer zona glomerulosa that produces mineralocorticoids, a middle zona fasciculata that produces glucocorticoids, and an inner zona reticularis that produces androgens.
The main mineralocorticoid is aldosterone, which regulates the concentration of Na+ ions in urine, sweat, pancreas, and saliva. Aldosterone release from the adrenal cortex is stimulated by a decrease in blood concentrations of sodium ions, blood volume, or blood pressure, or by an increase in blood potassium levels.
The three main glucocorticoids are cortisol, corticosterone, and cortisone. The glucocorticoids stimulate the synthesis of glucose and gluconeogenesis (converting a non-carbohydrate to glucose) by liver cells and they promote the release of fatty acids from adipose tissue. These hormones increase blood glucose levels to maintain levels within a normal range between meals. These hormones are secreted in response to ACTH and levels are regulated by negative feedback.
Androgens are sex hormones that promote masculinity. They are produced in small amounts by the adrenal cortex in both males and females. They do not affect sexual characteristics and may supplement sex hormones released from the gonads.
The adrenal medulla contains large, irregularly shaped cells that are closely associated with blood vessels. These cells are innervated by preganglionic autonomic nerve fibers from the central nervous system.
The adrenal medulla contains two types of secretory cells: one that produces epinephrine (adrenaline) and another that produces norepinephrine (noradrenaline). Epinephrine is the primary adrenal medulla hormone accounting for 75 to 80 percent of its secretions. Epinephrine and norepinephrine increase heart rate, breathing rate, cardiac muscle contractions, blood pressure, and blood glucose levels. They also accelerate the breakdown of glucose in skeletal muscles and stored fats in adipose tissue.
The release of epinephrine and norepinephrine is stimulated by neural impulses from the sympathetic nervous system. Secretion of these hormones is stimulated by acetylcholine release from preganglionic sympathetic fibers innervating the adrenal medulla. These neural impulses originate from the hypothalamus in response to stress to prepare the body for the fight-or-flight response.
The pancreas, illustrated in (Figure), is an elongated organ that is located between the stomach and the proximal portion of the small intestine. It contains both exocrine cells that excrete digestive enzymes and endocrine cells that release hormones. It is sometimes referred to as a heterocrine gland because it has both endocrine and exocrine functions.
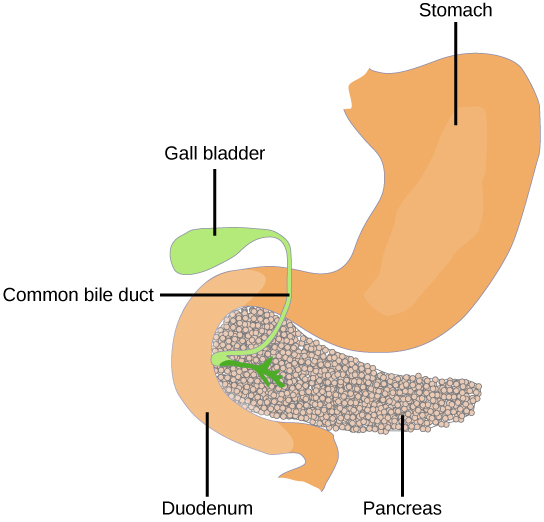
The endocrine cells of the pancreas form clusters called pancreatic islets or the islets of Langerhans, as visible in the micrograph shown in (Figure). The pancreatic islets contain two primary cell types: alpha cells, which produce the hormone glucagon, and beta cells, which produce the hormone insulin. These hormones regulate blood glucose levels. As blood glucose levels decline, alpha cells release glucagon to raise the blood glucose levels by increasing rates of glycogen breakdown and glucose release by the liver. When blood glucose levels rise, such as after a meal, beta cells release insulin to lower blood glucose levels by increasing the rate of glucose uptake in most body cells, and by increasing glycogen synthesis in skeletal muscles and the liver. Together, glucagon and insulin regulate blood glucose levels.
The pineal gland produces melatonin. The rate of melatonin production is affected by the photoperiod. Collaterals from the visual pathways innervate the pineal gland. During the day photoperiod, little melatonin is produced; however, melatonin production increases during the dark photoperiod (night). In some mammals, melatonin has an inhibitory affect on reproductive functions by decreasing production and maturation of sperm, oocytes, and reproductive organs. Melatonin is an effective antioxidant, protecting the CNS from free radicals such as nitric oxide and hydrogen peroxide. Lastly, melatonin is involved in biological rhythms, particularly circadian rhythms such as the sleep-wake cycle and eating habits.
The gonads—the male testes and female ovaries—produce steroid hormones. The testes produce androgens, testosterone being the most prominent, which allow for the development of secondary sex characteristics and the production of sperm cells. The ovaries produce estradiol and progesterone, which cause secondary sex characteristics and prepare the body for childbirth.
| Endocrine Glands and their Associated Hormones | ||
|---|---|---|
| Endocrine Gland | Associated Hormones | Effect |
| Hypothalamus | releasing and inhibiting hormones | regulate hormone release from pituitary gland; produce oxytocin; produce uterine contractions and milk secretion in females |
| antidiuretic hormone (ADH) | water reabsorption from kidneys; vasoconstriction to increase blood pressure | |
| Pituitary (Anterior) | growth hormone (GH) | promotes growth of body tissues, protein synthesis; metabolic functions |
| prolactin (PRL) | promotes milk production | |
| thyroid stimulating hormone (TSH) | stimulates thyroid hormone release | |
| adrenocorticotropic hormone (ACTH) | stimulates hormone release by adrenal cortex, glucocorticoids | |
| follicle-stimulating hormone (FSH) | stimulates gamete production (both ova and sperm); secretion of estradiol | |
| luteinizing hormone (LH) | stimulates androgen production by gonads; ovulation, secretion of progesterone | |
| melanocyte-stimulating hormone (MSH) | stimulates melanocytes of the skin increasing melanin pigment production. | |
| Pituitary (Posterior) | antidiuretic hormone (ADH) | stimulates water reabsorption by kidneys |
| oxytocin | stimulates uterine contractions during childbirth; milk ejection; stimulates ductus deferens and prostate gland contraction during emission | |
| Thyroid | thyroxine, triiodothyronine | stimulate and maintain metabolism; growth and development |
| calcitonin | reduces blood Ca2+ levels | |
| Parathyroid | parathyroid hormone (PTH) | increases blood Ca2+ levels |
| Adrenal (Cortex) | aldosterone | increases blood Na+ levels; increases K+ secretion |
| cortisol, corticosterone, cortisone | increase blood glucose levels; anti-inflammatory effects | |
| Adrenal (Medulla) | epinephrine, norepinephrine | stimulate fight-or-flight response; increase blood gluclose levels; increase metabolic activities |
| Pancreas | insulin | reduces blood glucose levels |
| glucagon | increases blood glucose levels | |
| Pineal gland | melatonin | regulates some biological rhythms and protects CNS from free radicals |
| Testes | androgens | regulate, promote, increase or maintain sperm production; male secondary sexual characteristics |
| Ovaries | estrogen | promotes uterine lining growth; female secondary sexual characteristics |
| progestins | promote and maintain uterine lining growth | |
There are several organs whose primary functions are non-endocrine but that also possess endocrine functions. These include the heart, kidneys, intestines, thymus, gonads, and adipose tissue.
The heart possesses endocrine cells in the walls of the atria that are specialized cardiac muscle cells. These cells release the hormone atrial natriuretic peptide (ANP) in response to increased blood volume. High blood volume causes the cells to be stretched, resulting in hormone release. ANP acts on the kidneys to reduce the reabsorption of Na+, causing Na+ and water to be excreted in the urine. ANP also reduces the amounts of renin released by the kidneys and aldosterone released by the adrenal cortex, further preventing the retention of water. In this way, ANP causes a reduction in blood volume and blood pressure, and reduces the concentration of Na+ in the blood.
The gastrointestinal tract produces several hormones that aid in digestion. The endocrine cells are located in the mucosa of the GI tract throughout the stomach and small intestine. Some of the hormones produced include gastrin, secretin, and cholecystokinin, which are secreted in the presence of food, and some of which act on other organs such as the pancreas, gallbladder, and liver. They trigger the release of gastric juices, which help to break down and digest food in the GI tract.
While the adrenal glands associated with the kidneys are major endocrine glands, the kidneys themselves also possess endocrine function. Renin is released in response to decreased blood volume or pressure and is part of the renin-angiotensin-aldosterone system that leads to the release of aldosterone. Aldosterone then causes the retention of Na+ and water, raising blood volume. The kidneys also release calcitriol, which aids in the absorption of Ca2+ and phosphate ions. Erythropoietin (EPO) is a protein hormone that triggers the formation of red blood cells in the bone marrow. EPO is released in response to low oxygen levels. Because red blood cells are oxygen carriers, increased production results in greater oxygen delivery throughout the body. EPO has been used by athletes to improve performance, as greater oxygen delivery to muscle cells allows for greater endurance. Because red blood cells increase the viscosity of blood, artificially high levels of EPO can cause severe health risks.
The thymus is found behind the sternum; it is most prominent in infants, becoming smaller in size through adulthood. The thymus produces hormones referred to as thymosins, which contribute to the development of the immune response.
Adipose tissue is a connective tissue found throughout the body. It produces the hormone leptin in response to food intake. Leptin increases the activity of anorexigenic neurons and decreases that of orexigenic neurons, producing a feeling of satiety after eating, thus affecting appetite and reducing the urge for further eating. Leptin is also associated with reproduction. It must be present for GnRH and gonadotropin synthesis to occur. Extremely thin females may enter puberty late; however, if adipose levels increase, more leptin will be produced, improving fertility.
The pituitary gland is located at the base of the brain and is attached to the hypothalamus by the infundibulum. The anterior pituitary receives products from the hypothalamus by the hypophyseal portal system and produces six hormones. The posterior pituitary is an extension of the brain and releases hormones (antidiuretic hormone and oxytocin) produced by the hypothalamus.
The thyroid gland is located in the neck and is composed of two lobes connected by the isthmus. The thyroid is made up of follicle cells that produce the hormones thyroxine and triiodothyronine. Parafollicular cells of the thyroid produce calcitonin. The parathyroid glands lie on the posterior surface of the thyroid gland and produce parathyroid hormone.
The adrenal glands are located on top of the kidneys and consist of the renal cortex and renal medulla. The adrenal cortex is the outer part of the adrenal gland and produces the corticosteroids, glucocorticoids, and mineralocorticoids. The adrenal medulla is the inner part of the adrenal gland and produces the catecholamines epinephrine and norepinephrine.
The pancreas lies in the abdomen between the stomach and the small intestine. Clusters of endocrine cells in the pancreas form the islets of Langerhans, which are composed of alpha cells that release glucagon and beta cells that release insulin.
Some organs possess endocrine activity as a secondary function but have another primary function. The heart produces the hormone atrial natriuretic peptide, which functions to reduce blood volume, pressure, and Na+ concentration. The gastrointestinal tract produces various hormones that aid in digestion. The kidneys produce renin, calcitriol, and erythropoietin. Adipose tissue produces leptin, which promotes satiety signals in the brain.
Which endocrine glands are associated with the kidneys?
C
Which of the following hormones is not produced by the anterior pituitary?
A
Recent studies suggest that blue light exposure can impact human circadian rhythms. This suggests that blue light disrupts the function of the _____ gland(s).
C
What does aldosterone regulate, and how is it stimulated?
The main mineralocorticoid is aldosterone, which regulates the concentration of ions in urine, sweat, and saliva. Aldosterone release from the adrenal cortex is stimulated by a decrease in blood concentrations of sodium ions, blood volume, or blood pressure, or an increase in blood potassium levels.
The adrenal medulla contains two types of secretory cells, what are they and what are their functions?
The adrenal medulla contains two types of secretory cells, one that produces epinephrine (adrenaline) and another that produces norepinephrine (noradrenaline). Epinephrine is the primary adrenal medulla hormone accounting for 75–80 percent of its secretions. Epinephrine and norepinephrine increase heart rate, breathing rate, cardiac muscle contractions, and blood glucose levels. They also accelerate the breakdown of glucose in skeletal muscles and stored fats in adipose tissue. The release of epinephrine and norepinephrine is stimulated by neural impulses from the sympathetic nervous system. These neural impulses originate from the hypothalamus in response to stress to prepare the body for the fight-or-flight response.
How would damage to the posterior pituitary gland affect the production and release of ADH and inhibiting hormones?
Damage to the posterior pituitary gland would prevent the release of ADH and oxytocin into the body. However, the hypothalamus’s ability to produce ADH would not be affected. The hypothalamus would also still be able to produce and release inhibiting hormones to regulate the anterior pituitary.
Chapter 37 in OpenStax Concepts of Biology 2e

Animal reproduction is necessary for the survival of a species. In the animal kingdom, there are innumerable ways that species reproduce. Asexual reproduction produces genetically identical organisms (clones), whereas in sexual reproduction, the genetic material of two individuals combines to produce offspring that are genetically different from their parents. During sexual reproduction the male gamete (sperm) may be placed inside the female’s body for internal fertilization, or the sperm and eggs may be released into the environment for external fertilization. Seahorses, like the one shown in (Figure), provide an example of the latter. Following a mating dance, the female lays eggs in the male seahorse’s abdominal brood pouch where they are fertilized. The eggs hatch and the offspring develop in the pouch for several weeks.
Chapter 43 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Animals produce offspring through asexual and/or sexual reproduction. Both methods have advantages and disadvantages. Asexual reproduction produces offspring that are genetically identical to the parent because the offspring are all clones of the original parent. A single individual can produce offspring asexually and large numbers of offspring can be produced quickly. In a stable or predictable environment, asexual reproduction is an effective means of reproduction because all the offspring will be adapted to that environment. In an unstable or unpredictable environment asexually-reproducing species may be at a disadvantage because all the offspring are genetically identical and may not have the genetic variation to survive in new or different conditions. On the other hand, the rapid rates of asexual reproduction may allow for a speedy response to environmental changes if individuals have mutations. An additional advantage of asexual reproduction is that colonization of new habitats may be easier when an individual does not need to find a mate to reproduce.
During sexual reproduction the genetic material of two individuals is combined to produce genetically diverse offspring that differ from their parents. The genetic diversity of sexually produced offspring is thought to give species a better chance of surviving in an unpredictable or changing environment. Species that reproduce sexually must maintain two different types of individuals, males and females, which can limit the ability to colonize new habitats as both sexes must be present.
Asexual reproduction occurs in prokaryotic microorganisms (bacteria) and in some eukaryotic single-celled and multi-celled organisms. There are a number of ways that animals reproduce asexually.
Fission, also called binary fission, occurs in prokaryotic microorganisms and in some invertebrate, multi-celled organisms. After a period of growth, an organism splits into two separate organisms. Some unicellular eukaryotic organisms undergo binary fission by mitosis. In other organisms, part of the individual separates and forms a second individual. This process occurs, for example, in many asteroid echinoderms through splitting of the central disk. Some sea anemones and some coral polyps ((Figure)) also reproduce through fission.

Budding is a form of asexual reproduction that results from the outgrowth of a part of a cell or body region leading to a separation from the original organism into two individuals. Budding occurs commonly in some invertebrate animals such as corals and hydras. In hydras, a bud forms that develops into an adult and breaks away from the main body, as illustrated in (Figure), whereas in coral budding, the bud does not detach and multiplies as part of a new colony.
Fragmentation is the breaking of the body into two parts with subsequent regeneration. If the animal is capable of fragmentation, and the part is big enough, a separate individual will regrow.
For example, in many sea stars, asexual reproduction is accomplished by fragmentation. (Figure) illustrates a sea star for which an arm of the individual is broken off and regenerates a new sea star. Fisheries workers have been known to try to kill the sea stars eating their clam or oyster beds by cutting them in half and throwing them back into the ocean. Unfortunately for the workers, the two parts can each regenerate a new half, resulting in twice as many sea stars to prey upon the oysters and clams. Fragmentation also occurs in annelid worms, turbellarians, and poriferans.

Note that in fragmentation, there is generally a noticeable difference in the size of the individuals, whereas in fission, two individuals of approximate size are formed.
Parthenogenesis is a form of asexual reproduction where an egg develops into a complete individual without being fertilized. The resulting offspring can be either haploid or diploid, depending on the process and the species. Parthenogenesis occurs in invertebrates such as water fleas, rotifers, aphids, stick insects, some ants, wasps, and bees. Bees use parthenogenesis to produce haploid males (drones). If eggs are fertilized, diploid females develop, and if the fertilized eggs are fed a special diet (so called royal jelly), a queen is produced.
Some vertebrate animals—such as certain reptiles, amphibians, and fish—also reproduce through parthenogenesis. Although more common in plants, parthenogenesis has been observed in animal species that were segregated by sex in terrestrial or marine zoos. Two female Komodo dragons, a hammerhead shark, and a blacktop shark have produced parthenogenic young when the females have been isolated from males.
Sexual reproduction is the combination of (usually haploid) reproductive cells from two individuals to form a third (usually diploid) unique offspring. Sexual reproduction produces offspring with novel combinations of genes. This can be an adaptive advantage in unstable or unpredictable environments. As humans, we are used to thinking of animals as having two separate sexes—male and female—determined at conception. However, in the animal kingdom, there are many variations on this theme.
Hermaphroditism occurs in animals where one individual has both male and female reproductive parts. Invertebrates such as earthworms, slugs, tapeworms and snails, shown in (Figure), are often hermaphroditic. Hermaphrodites may self-fertilize or may mate with another of their species, fertilizing each other and both producing offspring. Self fertilization is common in animals that have limited mobility or are not motile, such as barnacles and clams.

Mammalian sex determination is determined genetically by the presence of X and Y chromosomes. Individuals homozygous for X (XX) are female and heterozygous individuals (XY) are male. The presence of a Y chromosome causes the development of male characteristics and its absence results in female characteristics. The XY system is also found in some insects and plants.
Avian sex determination is dependent on the presence of Z and W chromosomes. Homozygous for Z (ZZ) results in a male and heterozygous (ZW) results in a female. The W appears to be essential in determining the sex of the individual, similar to the Y chromosome in mammals. Some fish, crustaceans, insects (such as butterflies and moths), and reptiles use this system.
The sex of some species is not determined by genetics but by some aspect of the environment. Sex determination in some crocodiles and turtles, for example, is often dependent on the temperature during critical periods of egg development. This is referred to as environmental sex determination, or more specifically as temperature-dependent sex determination. In many turtles, cooler temperatures during egg incubation produce males and warm temperatures produce females. In some crocodiles, moderate temperatures produce males and both warm and cool temperatures produce females. In some species, sex is both genetic- and temperature-dependent.
Individuals of some species change their sex during their lives, alternating between male and female. If the individual is female first, it is termed protogyny or “first female,” if it is male first, its termed protandry or “first male.” Oysters, for example, are born male, grow, and become female and lay eggs; some oyster species change sex multiple times.
Reproduction may be asexual when one individual produces genetically identical offspring, or sexual when the genetic material from two individuals is combined to produce genetically diverse offspring. Asexual reproduction occurs through fission, budding, and fragmentation. Sexual reproduction may mean the joining of sperm and eggs within animals’ bodies or it may mean the release of sperm and eggs into the environment. An individual may be one sex, or both; it may start out as one sex and switch during its life, or it may stay male or female.
Which form of reproduction is thought to be best in a stable environment?
A
Which form of reproduction can result from damage to the original animal?
B
Which form of reproduction is useful to an animal with little mobility that reproduces sexually?
D
Genetically unique individuals are produced through ________.
A
Why is sexual reproduction useful if only half the animals can produce offspring and two separate cells must be combined to form a third?
Sexual reproduction produces a new combination of genes in the offspring that may better enable them to survive changes in the environment and assist in the survival of the species.
What determines which sex will result in offspring of birds and mammals?
The presence of the W chromosome in birds determines femaleness and the presence of the Y chromosome in mammals determines maleness. The absence of those chromosomes and the homogeneity of the offspring (ZZ or XX) leads to the development of the other sex.
Chapter 43 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Sexual reproduction starts with the combination of a sperm and an egg in a process called fertilization. This can occur either inside (internal fertilization) or outside (external fertilization) the body of the female. Humans provide an example of the former whereas seahorse reproduction is an example of the latter.
External fertilization usually occurs in aquatic environments where both eggs and sperm are released into the water. After the sperm reaches the egg, fertilization takes place. Most external fertilization happens during the process of spawning where one or several females release their eggs and the male(s) release sperm in the same area, at the same time. The release of the reproductive material may be triggered by water temperature or the length of daylight. Nearly all fish spawn, as do crustaceans (such as crabs and shrimp), mollusks (such as oysters), squid, and echinoderms (such as sea urchins and sea cucumbers). (Figure) shows salmon spawning in a shallow stream. Frogs, like those shown in (Figure), corals, molluscs, and sea cucumbers also spawn.


Pairs of fish that are not broadcast spawners may exhibit courtship behavior. This allows the female to select a particular male. The trigger for egg and sperm release (spawning) causes the egg and sperm to be placed in a small area, enhancing the possibility of fertilization.
External fertilization in an aquatic environment protects the eggs from drying out. Broadcast spawning can result in a greater mixture of the genes within a group, leading to higher genetic diversity and a greater chance of species survival in a hostile environment. For sessile aquatic organisms like sponges, broadcast spawning is the only mechanism for fertilization and colonization of new environments. The presence of the fertilized eggs and developing young in the water provides opportunities for predation resulting in a loss of offspring. Therefore, millions of eggs must be produced by individuals, and the offspring produced through this method must mature rapidly. The survival rate of eggs produced through broadcast spawning is low.
Internal fertilization occurs most often in land-based animals, although some aquatic animals also use this method. There are three ways that offspring are produced following internal fertilization. In oviparity, fertilized eggs are laid outside the female’s body and develop there, receiving nourishment from the yolk that is a part of the egg. This occurs in most bony fish, many reptiles, some cartilaginous fish, most amphibians, two mammals, and all birds. Reptiles and insects produce leathery eggs, while birds and turtles produce eggs with high concentrations of calcium carbonate in the shell, making them hard. Chicken eggs are an example of this second type.
In ovoviparity, fertilized eggs are retained in the female, but the embryo obtains its nourishment from the egg’s yolk and the young are fully developed when they are hatched. This occurs in some bony fish (like the guppy Lebistes reticulatus), some sharks, some lizards, some snakes (such as the garter snake Thamnophis sirtalis), some vipers, and some invertebrate animals (like the Madagascar hissing cockroach Gromphadorhina portentosa).
In viviparity the young develop within the female, receiving nourishment from the mother’s blood through a placenta. The offspring develops in the female and is born alive. This occurs in most mammals, some cartilaginous fish, and a few reptiles.
Internal fertilization has the advantage of protecting the fertilized egg from dehydration on land. The embryo is isolated within the female, which limits predation on the young. Internal fertilization enhances the fertilization of eggs by a specific male. Fewer offspring are produced through this method, but their survival rate is higher than that for external fertilization.
Once multicellular organisms evolved and developed specialized cells, some also developed tissues and organs with specialized functions. An early development in reproduction occurred in the Annelids. These organisms produce sperm and eggs from undifferentiated cells in their coelom and store them in that cavity. When the coelom becomes filled, the cells are released through an excretory opening or by the body splitting open. Reproductive organs evolved with the development of gonads that produce sperm and eggs. These cells went through meiosis, an adaption of mitosis, which reduced the number of chromosomes in each reproductive cell by half, while increasing the number of cells through cell division.
Complete reproductive systems were developed in insects, with separate sexes. Sperm are made in testes and then travel through coiled tubes to the epididymis for storage. Eggs mature in the ovary. When they are released from the ovary, they travel to the uterine tubes for fertilization. Some insects have a specialized sac, called a spermatheca, which stores sperm for later use, sometimes up to a year. Fertilization can be timed with environmental or food conditions that are optimal for offspring survival.
Vertebrates have similar structures, with a few differences. Non-mammals, such as birds and reptiles, have a common body opening, called a cloaca, for the digestive, excretory and reproductive systems. Coupling between birds usually involves positioning the cloaca openings opposite each other for transfer of sperm. Mammals have separate openings for the systems in the female and a uterus for support of developing offspring. The uterus has two chambers in species that produce large numbers of offspring at a time, while species that produce one offspring, such as primates, have a single uterus.
Sperm transfer from the male to the female during reproduction ranges from releasing the sperm into the watery environment for external fertilization, to the joining of cloaca in birds, to the development of a penis for direct delivery into the female’s vagina in mammals.
Sexual reproduction starts with the combination of a sperm and an egg in a process called fertilization. This can occur either outside the bodies or inside the female. Both methods have advantages and disadvantages. Once fertilized, the eggs can develop inside the female or outside. If the egg develops outside the body, it usually has a protective covering over it. Animal anatomy evolved various ways to fertilize, hold, or expel the egg. The method of fertilization varies among animals. Some species release the egg and sperm into the environment, some species retain the egg and receive the sperm into the female body and then expel the developing embryo covered with shell, while still other species retain the developing offspring through the gestation period.
External fertilization occurs in which type of environment?
A
Which term applies to egg development within the female with nourishment derived from a yolk?
C
Which term applies to egg development outside the female with nourishment derived from a yolk?
A
What are the advantages and disadvantages of external and internal forms of fertilization?
External fertilization can create large numbers of offspring without requiring specialized delivery or reproductive support organs. Offspring develop and mature quickly compared to internally fertilizing species. A disadvantage is that the offspring are out in the environment and predation can account for large loss of offspring. The embryos are susceptible to changes in the environment, which further depletes their numbers. Internally fertilizing species control their environment and protect their offspring from predators but must have specialized organs to complete these tasks and usually produce fewer embryos.
Why would paired external fertilization be preferable to group spawning?
Paired external fertilization allows the female to select the male for mating. It also has a greater chance of fertilization taking place, whereas spawning just puts a large number of sperm and eggs together and random interactions result in the fertilization.
Chapter 43 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
As animals became more complex, specific organs and organ systems developed to support specific functions for the organism. The reproductive structures that evolved in land animals allow males and females to mate, fertilize internally, and support the growth and development of offspring.
The reproductive tissues of male and female humans develop similarly in utero until a low level of the hormone testosterone is released from male gonads. Testosterone causes the undeveloped tissues to differentiate into male sexual organs. When testosterone is absent, the tissues develop into female sexual tissues. Primitive gonads become testes or ovaries. Tissues that produce a penis in males produce a clitoris in females. The tissue that will become the scrotum in a male becomes the labia in a female; that is, they are homologous structures.
In the male reproductive system, the scrotum houses the testicles or testes (singular: testis), including providing passage for blood vessels, nerves, and muscles related to testicular function. The testes are a pair of male reproductive organs that produce sperm and some reproductive hormones. Each testis is approximately 2.5 by 3.8 cm (1.5 by 1 in.) in size and divided into wedge-shaped lobules by connective tissue called septa. Coiled in each wedge are seminiferous tubules that produce sperm.
Sperm are immobile at body temperature; therefore, the scrotum and penis are external to the body, as illustrated in (Figure) so that a proper temperature is maintained for motility. In land mammals, the pair of testes must be suspended outside the body at about 2° C lower than body temperature to produce viable sperm. Infertility can occur in land mammals when the testes do not descend through the abdominal cavity during fetal development.
Which of the following statements about the male reproductive system is false?
<!–<para>D–>
Sperm mature in seminiferous tubules that are coiled inside the testes, as illustrated in (Figure). The walls of the seminiferous tubules are made up of the developing sperm cells, with the least developed sperm at the periphery of the tubule and the fully developed sperm in the lumen. The sperm cells are mixed with “nursemaid” cells called Sertoli cells which protect the germ cells and promote their development. Other cells mixed in the wall of the tubules are the interstitial cells of Leydig. These cells produce high levels of testosterone once the male reaches adolescence.
When the sperm have developed flagella and are nearly mature, they leave the testicles and enter the epididymis, shown in (Figure). This structure resembles a comma and lies along the top and posterior portion of the testes; it is the site of sperm maturation. The sperm leave the epididymis and enter the vas deferens (or ductus deferens), which carries the sperm, behind the bladder, and forms the ejaculatory duct with the duct from the seminal vesicles. During a vasectomy, a section of the vas deferens is removed, preventing sperm from being passed out of the body during ejaculation and preventing fertilization.
Semen is a mixture of sperm and spermatic duct secretions (about 10 percent of the total) and fluids from accessory glands that contribute most of the semen’s volume. Sperm are haploid cells, consisting of a flagellum as a tail, a neck that contains the cell’s energy-producing mitochondria, and a head that contains the genetic material. (Figure) shows a micrograph of human sperm as well as a diagram of the parts of the sperm. An acrosome is found at the top of the head of the sperm. This structure contains lysosomal enzymes that can digest the protective coverings that surround the egg to help the sperm penetrate and fertilize the egg. An ejaculate will contain from two to five milliliters of fluid with from 50–120 million sperm per milliliter.
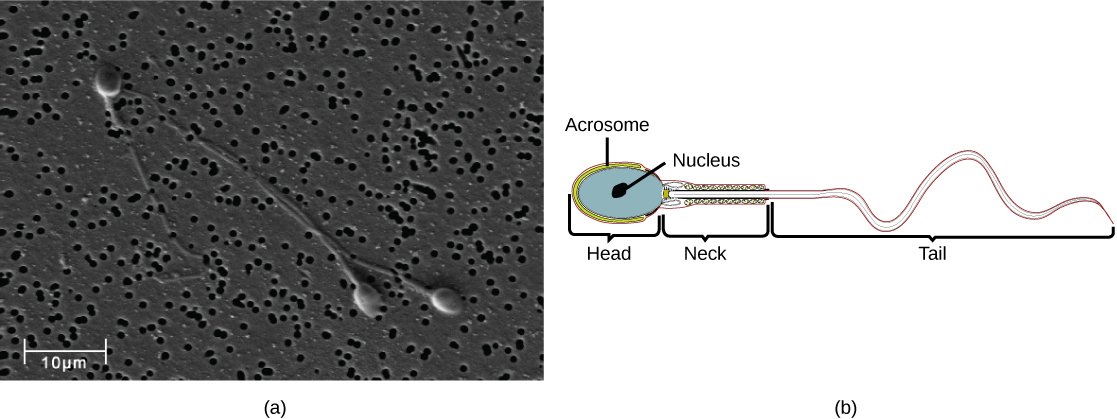
The bulk of the semen comes from the accessory glands associated with the male reproductive system. These are the seminal vesicles, the prostate gland, and the bulbourethral gland, all of which are illustrated in (Figure). The seminal vesicles are a pair of glands that lie along the posterior border of the urinary bladder. The glands make a solution that is thick, yellowish, and alkaline. As sperm are only motile in an alkaline environment, a basic pH is important to reverse the acidity of the vaginal environment. The solution also contains mucus, fructose (a sperm mitochondrial nutrient), a coagulating enzyme, ascorbic acid, and local-acting hormones called prostaglandins. The seminal vesicle glands account for 60 percent of the bulk of semen.
The penis, illustrated in (Figure), is an organ that drains urine from the renal bladder and functions as a copulatory organ during intercourse. The penis contains three tubes of erectile tissue running through the length of the organ. These consist of a pair of tubes on the dorsal side, called the corpus cavernosum, and a single tube of tissue on the ventral side, called the corpus spongiosum. This tissue will become engorged with blood, becoming erect and hard, in preparation for intercourse. The organ is inserted into the vagina culminating with an ejaculation. During intercourse, the smooth muscle sphincters at the opening to the renal bladder close and prevent urine from entering the penis. An orgasm is a two-stage process: first, glands and accessory organs connected to the testes contract, then semen (containing sperm) is expelled through the urethra during ejaculation. After intercourse, the blood drains from the erectile tissue and the penis becomes flaccid.
The walnut-shaped prostate gland surrounds the urethra, the connection to the urinary bladder. It has a series of short ducts that directly connect to the urethra. The gland is a mixture of smooth muscle and glandular tissue. The muscle provides much of the force needed for ejaculation to occur. The glandular tissue makes a thin, milky fluid that contains citrate (a nutrient), enzymes, and prostate specific antigen (PSA). PSA is a proteolytic enzyme that helps to liquefy the ejaculate several minutes after release from the male. Prostate gland secretions account for about 30 percent of the bulk of semen.
The bulbourethral gland, or Cowper’s gland, releases its secretion prior to the release of the bulk of the semen. It neutralizes any acid residue in the urethra left over from urine. This usually accounts for a couple of drops of fluid in the total ejaculate and may contain a few sperm. Withdrawal of the penis from the vagina before ejaculation to prevent pregnancy may not work if sperm are present in the bulbourethral gland secretions. The location and functions of the male reproductive organs are summarized in (Figure).
| Male Reproductive Anatomy | ||
|---|---|---|
| Organ | Location | Function |
| Scrotum | External | Carry and support testes |
| Penis | External | Deliver urine, copulating organ |
| Testes | Internal | Produce sperm and male hormones |
| Seminal Vesicles | Internal | Contribute to semen production |
| Prostate Gland | Internal | Contribute to semen production |
| Bulbourethral Glands | Internal | Clean urethra at ejaculation |
A number of reproductive structures are exterior to the female’s body. These include the breasts and the vulva, which consists of the mons pubis, clitoris, labia majora, labia minora, and the vestibular glands, all illustrated in (Figure). The location and functions of the female reproductive organs are summarized in (Figure). The vulva is an area associated with the vestibule which includes the structures found in the inguinal (groin) area of women. The mons pubis is a round, fatty area that overlies the pubic symphysis. The clitoris is a structure with erectile tissue that contains a large number of sensory nerves and serves as a source of stimulation during intercourse. The labia majora are a pair of elongated folds of tissue that run posterior from the mons pubis and enclose the other components of the vulva. The labia majora derive from the same tissue that produces the scrotum in a male. The labia minora are thin folds of tissue centrally located within the labia majora. These labia protect the openings to the vagina and urethra. The mons pubis and the anterior portion of the labia majora become covered with hair during adolescence; the labia minora is hairless. The greater vestibular glands are found at the sides of the vaginal opening and provide lubrication during intercourse.
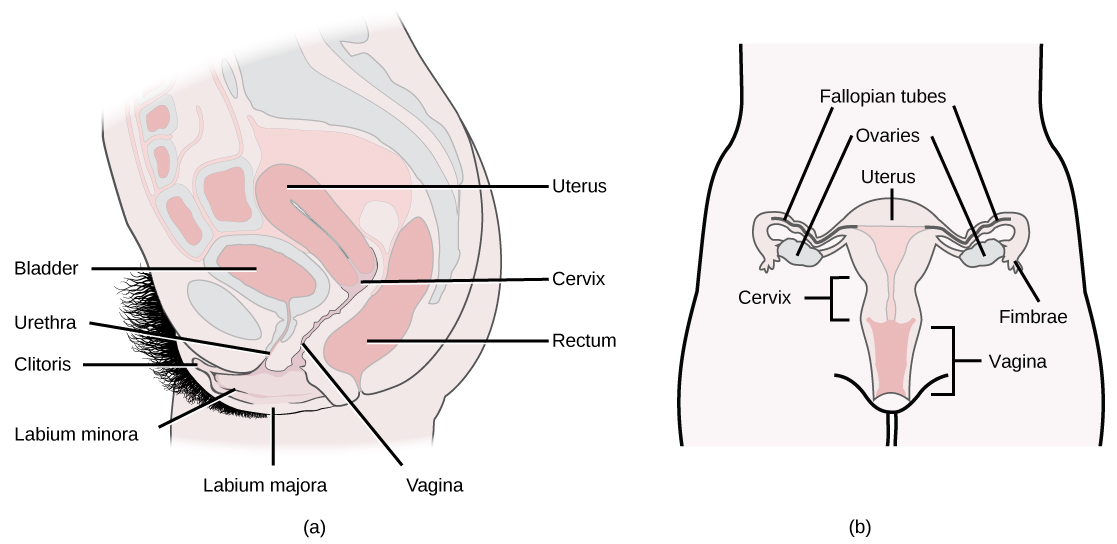
| Female Reproductive Anatomy | ||
|---|---|---|
| Organ | Location | Function |
| Clitoris | External | Sensory organ |
| Mons pubis | External | Fatty area overlying pubic bone |
| Labia majora | External | Covers labia minora |
| Labia minora | External | Covers vestibule |
| Greater vestibular glands | External | Secrete mucus; lubricate vagina |
| Breasts | External | Produce and deliver milk |
| Ovaries | Internal | Carry and develop eggs |
| Oviducts (Fallopian tubes) | Internal | Transport egg to uterus |
| Uterus | Internal | Support developing embryo |
| Vagina | Internal | Common tube for intercourse, birth canal, passing menstrual flow |
The breasts consist of mammary glands and fat. The size of the breast is determined by the amount of fat deposited behind the gland. Each gland consists of 15 to 25 lobes that have ducts that empty at the nipple and that supply the nursing child with nutrient- and antibody-rich milk to aid development and protect the child.
Internal female reproductive structures include ovaries, oviducts, the uterus, and the vagina, shown in (Figure). The pair of ovaries is held in place in the abdominal cavity by a system of ligaments. Ovaries consist of a medulla and cortex: the medulla contains nerves and blood vessels to supply the cortex with nutrients and remove waste. The outer layers of cells of the cortex are the functional parts of the ovaries. The cortex is made up of follicular cells that surround eggs that develop during fetal development in utero. During the menstrual period, a batch of follicular cells develops and prepares the eggs for release. At ovulation, one follicle ruptures and one egg is released, as illustrated in (Figure)a.
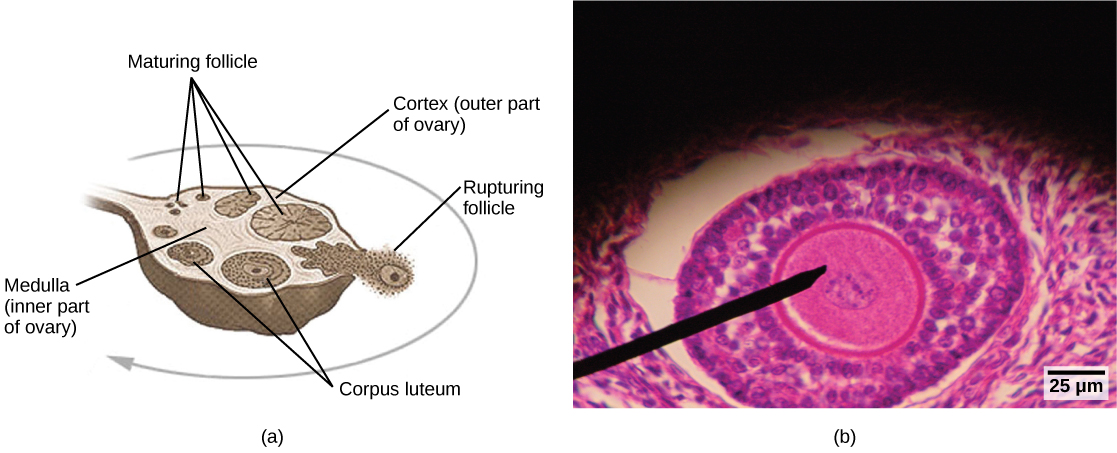
The oviducts, or fallopian tubes, extend from the uterus in the lower abdominal cavity to the ovaries, but they are not in contact with the ovaries. The lateral ends of the oviducts flare out into a trumpet-like structure and have a fringe of finger-like projections called fimbriae, illustrated in (Figure)b. When an egg is released at ovulation, the fimbrae help the nonmotile egg enter into the tube and passage to the uterus. The walls of the oviducts are ciliated and are made up mostly of smooth muscle. The cilia beat toward the middle, and the smooth muscle contracts in the same direction, moving the egg toward the uterus. Fertilization usually takes place within the oviducts and the developing embryo is moved toward the uterus for development. It usually takes the egg or embryo a week to travel through the oviduct. Sterilization in women is called a tubal ligation; it is analogous to a vasectomy in males in that the oviducts are severed and sealed.
The uterus is a structure about the size of a woman’s fist. This is lined with an endometrium rich in blood vessels and mucus glands. The uterus supports the developing embryo and fetus during gestation. The thickest portion of the wall of the uterus is made of smooth muscle. Contractions of the smooth muscle in the uterus aid in passing the baby through the vagina during labor. A portion of the lining of the uterus sloughs off during each menstrual period, and then builds up again in preparation for an implantation. Part of the uterus, called the cervix, protrudes into the top of the vagina. The cervix functions as the birth canal.
The vagina is a muscular tube that serves several purposes. It allows menstrual flow to leave the body. It is the receptacle for the penis during intercourse and the vessel for the delivery of offspring. It is lined by stratified squamous epithelial cells to protect the underlying tissue.
The sexual response in humans is both psychological and physiological. Both sexes experience sexual arousal through psychological and physical stimulation. There are four phases of the sexual response. During phase one, called excitement, vasodilation leads to vasocongestion in erectile tissues in both men and women. The nipples, clitoris, labia, and penis engorge with blood and become enlarged. Vaginal secretions are released to lubricate the vagina to facilitate intercourse. During the second phase, called the plateau, stimulation continues, the outer third of the vaginal wall enlarges with blood, and breathing and heart rate increase.
During phase three, or orgasm, rhythmic, involuntary contractions of muscles occur in both sexes. In the male, the reproductive accessory glands and tubules constrict placing semen in the urethra, then the urethra contracts expelling the semen through the penis. In women, the uterus and vaginal muscles contract in waves that may last slightly less than a second each. During phase four, or resolution, the processes described in the first three phases reverse themselves and return to their normal state. Men experience a refractory period in which they cannot maintain an erection or ejaculate for a period of time ranging from minutes to hours.
Gametogenesis, the production of sperm and eggs, takes place through the process of meiosis. During meiosis, two cell divisions separate the paired chromosomes in the nucleus and then separate the chromatids that were made during an earlier stage of the cell’s life cycle. Meiosis produces haploid cells with half of each pair of chromosomes normally found in diploid cells. The production of sperm is called spermatogenesis and the production of eggs is called oogenesis.
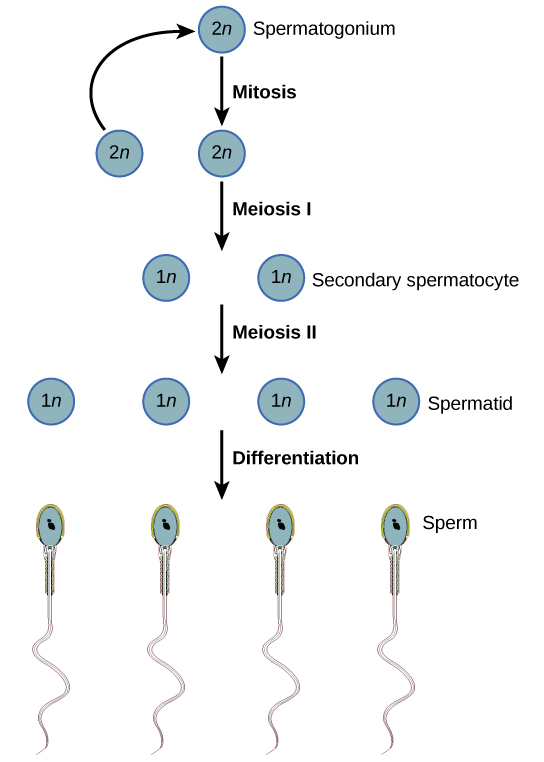
Spermatogenesis, illustrated in (Figure), occurs in the wall of the seminiferous tubules ((Figure)), with stem cells at the periphery of the tube and the spermatozoa at the lumen of the tube. Immediately under the capsule of the tubule are diploid, undifferentiated cells. These stem cells, called spermatogonia (singular: spermatagonium), go through mitosis with one offspring going on to differentiate into a sperm cell and the other giving rise to the next generation of sperm.
Meiosis starts with a cell called a primary spermatocyte. At the end of the first meiotic division, a haploid cell is produced called a secondary spermatocyte. This cell is haploid and must go through another meiotic cell division. The cell produced at the end of meiosis is called a spermatid and when it reaches the lumen of the tubule and grows a flagellum, it is called a sperm cell. Four sperm result from each primary spermatocyte that goes through meiosis.
Stem cells are deposited during gestation and are present at birth through the beginning of adolescence, but in an inactive state. During adolescence, gonadotropic hormones from the anterior pituitary cause the activation of these cells and the production of viable sperm. This continues into old age.
Visit this site to see the process of spermatogenesis.
Oogenesis, illustrated in (Figure), occurs in the outermost layers of the ovaries. As with sperm production, oogenesis starts with a germ cell, called an oogonium (plural: oogonia), but this cell undergoes mitosis to increase in number, eventually resulting in up to about one to two million cells in the embryo.
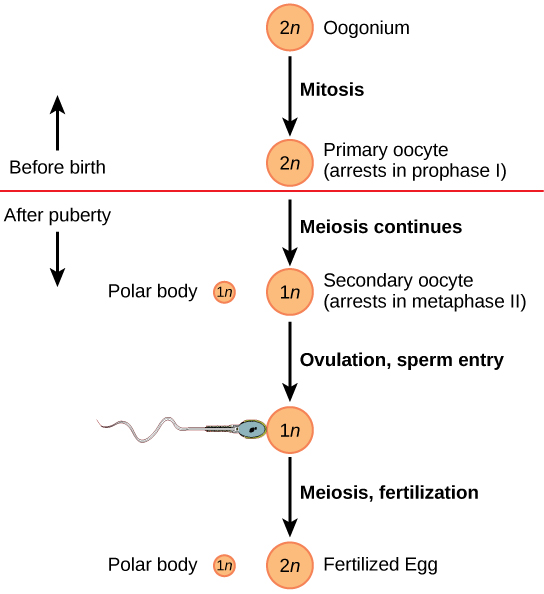
The cell starting meiosis is called a primary oocyte, as shown in (Figure). This cell will start the first meiotic division and be arrested in its progress in the first prophase stage. At the time of birth, all future eggs are in the prophase stage. At adolescence, anterior pituitary hormones cause the development of a number of follicles in an ovary. This results in the primary oocyte finishing the first meiotic division. The cell divides unequally, with most of the cellular material and organelles going to one cell, called a secondary oocyte, and only one set of chromosomes and a small amount of cytoplasm going to the other cell. This second cell is called a polar body and usually dies. A secondary meiotic arrest occurs, this time at the metaphase II stage. At ovulation, this secondary oocyte will be released and travel toward the uterus through the oviduct. If the secondary oocyte is fertilized, the cell continues through the meiosis II, producing a second polar body and a fertilized egg containing all 46 chromosomes of a human being, half of them coming from the sperm.
Egg production begins before birth, is arrested during meiosis until puberty, and then individual cells continue through at each menstrual cycle. One egg is produced from each meiotic process, with the extra chromosomes and chromatids going into polar bodies that degenerate and are reabsorbed by the body.
As animals became more complex, specific organs and organ systems developed to support specific functions for the organism. The reproductive structures that evolved in land animals allow males and females to mate, fertilize internally, and support the growth and development of offspring. Processes developed to produce reproductive cells that had exactly half the number of chromosomes of each parent so that new combinations would have the appropriate amount of genetic material. Gametogenesis, the production of sperm (spermatogenesis) and eggs (oogenesis), takes place through the process of meiosis.
(Figure) Which of the following statements about the male reproductive system is false?
(Figure) D
Sperm are produced in the ________.
C
Most of the bulk of semen is made by the ________.
C
Which of the following cells in spermatogenesis is diploid?
A
Which female organ has the same embryonic origin as the penis?
A
Which female organ has an endometrial lining that will support a developing baby?
D
How many eggs are produced as a result of one meiotic series of cell divisions?
A
Describe the phases of the human sexual response.
In phase one (excitement), vasodilation leads to vasocongestion and enlargement of erectile tissues. Vaginal secretions are released to lubricate the vagina during intercourse. In phase two (plateau), stimulation continues, the outer third of the vaginal wall enlarges with blood, and breathing and heart rate increase. In phase three (orgasm), rhythmic, involuntary contractions of muscles occur. In the male, reproductive accessory glands and tubules constrict, depositing semen in the urethra; then, the urethra contracts, expelling the semen through the penis. In women, the uterus and vaginal muscles contract in waves that may last slightly less than a second each. In phase four (resolution), the processes listed in the first three phases reverse themselves and return to their normal state. Men experience a refractory period in which they cannot maintain an erection or ejaculate for a period of time ranging from minutes to hours. Women do not experience a refractory period.
Compare spermatogenesis and oogenesis as to timing of the processes and the number and type of cells finally produced.
Stem cells are laid down in the male during gestation and lie dormant until adolescence. Stem cells in the female increase to one to two million and enter the first meiotic division and are arrested in prophase. At adolescence, spermatogenesis begins and continues until death, producing the maximum number of sperm with each meiotic division. Oogenesis continues again at adolescence in batches of oogonia with each menstrual cycle. These oogonia finish the first meiotic division, producing a primary oocyte with most of the cytoplasm and its contents, and a second cell called a polar body containing 23 chromosomes. The second meiotic division results in a secondary oocyte and a second oocyte. At ovulation, a mature haploid egg is released. If this egg is fertilized, it finishes the second meiotic division, including the chromosomes donated by the sperm in the finished cell. This is a diploid, fertilized egg.
Chapter 43 in OpenStax Concepts of Biology 2e
By the end of this chapter, you will be able to do the following:
The human male and female reproductive cycles are controlled by the interaction of hormones from the hypothalamus and anterior pituitary with hormones from reproductive tissues and organs. In both sexes, the hypothalamus monitors and causes the release of hormones from the pituitary gland. When the reproductive hormone is required, the hypothalamus sends a gonadotropin-releasing hormone (GnRH) to the anterior pituitary. This causes the release of follicle stimulating hormone (FSH) and luteinizing hormone (LH) from the anterior pituitary into the blood. Note that the body must reach puberty in order for the adrenals to release the hormones that must be present for GnRH to be produced. Although FSH and LH are named after their functions in female reproduction, they are produced in both sexes and play important roles in controlling reproduction. Other hormones have specific functions in the male and female reproductive systems.
At the onset of puberty, the hypothalamus causes the release of FSH and LH into the male system for the first time. FSH enters the testes and stimulates the Sertoli cells to begin facilitating spermatogenesis using negative feedback, as illustrated in (Figure). LH also enters the testes and stimulates the interstitial cells of Leydig to make and release testosterone into the testes and the blood.
Testosterone, the hormone responsible for the secondary sexual characteristics that develop in the male during adolescence, stimulates spermatogenesis. These secondary sex characteristics include a deepening of the voice, the growth of facial, axillary, and pubic hair, and the beginnings of the sex drive.
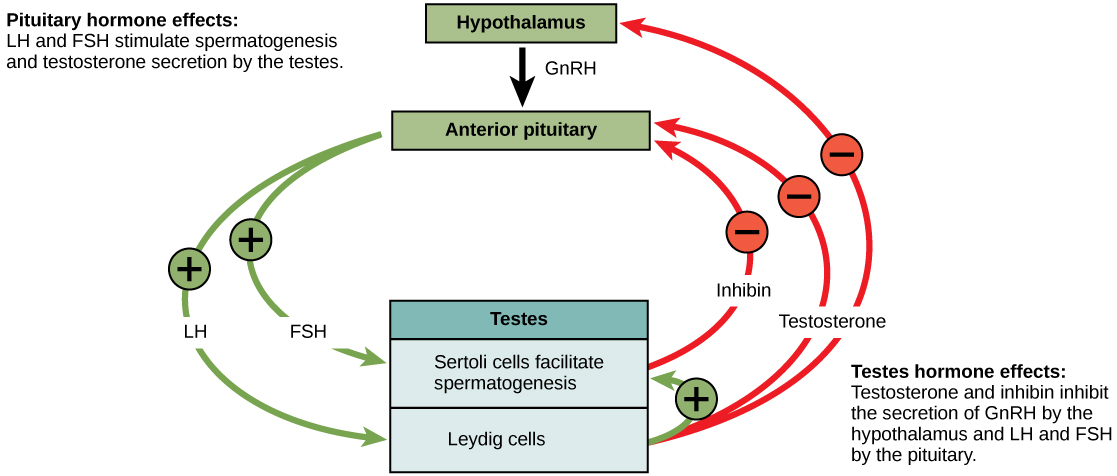
A negative feedback system occurs in the male with rising levels of testosterone acting on the hypothalamus and anterior pituitary to inhibit the release of GnRH, FSH, and LH. The Sertoli cells produce the hormone inhibin, which is released into the blood when the sperm count is too high. This inhibits the release of GnRH and FSH, which will cause spermatogenesis to slow down. If the sperm count reaches 20 million/ml, the Sertoli cells cease the release of inhibin, and the sperm count increases.
The control of reproduction in females is more complex. As with the male, the anterior pituitary hormones cause the release of the hormones FSH and LH. In addition, estrogens and progesterone are released from the developing follicles. Estrogen is the reproductive hormone in females that assists in endometrial regrowth, ovulation, and calcium absorption; it is also responsible for the secondary sexual characteristics of females. These include breast development, flaring of the hips, and a shorter period necessary for bone maturation. Progesterone assists in endometrial regrowth and inhibition of FSH and LH release.
In females, FSH stimulates development of egg cells, called ova, which develop in structures called follicles. Follicle cells produce the hormone inhibin, which inhibits FSH production. LH also plays a role in the development of ova, induction of ovulation, and stimulation of estradiol and progesterone production by the ovaries. Estradiol and progesterone are steroid hormones that prepare the body for pregnancy. Estradiol produces secondary sex characteristics in females, while both estradiol and progesterone regulate the menstrual cycle.
The ovarian cycle governs the preparation of endocrine tissues and release of eggs, while the menstrual cycle governs the preparation and maintenance of the uterine lining. These cycles occur concurrently and are coordinated over a 22–32 day cycle, with an average length of 28 days.
The first half of the ovarian cycle is the follicular phase shown in (Figure). Slowly rising levels of FSH and LH cause the growth of follicles on the surface of the ovary. This process prepares the egg for ovulation. As the follicles grow, they begin releasing estrogens and a low level of progesterone. Progesterone maintains the endometrium to help ensure pregnancy. The trip through the fallopian tube takes about seven days. At this stage of development, called the morula, there are 30-60 cells. If pregnancy implantation does not occur, the lining is sloughed off. After about five days, estrogen levels rise and the menstrual cycle enters the proliferative phase. The endometrium begins to regrow, replacing the blood vessels and glands that deteriorated during the end of the last cycle.
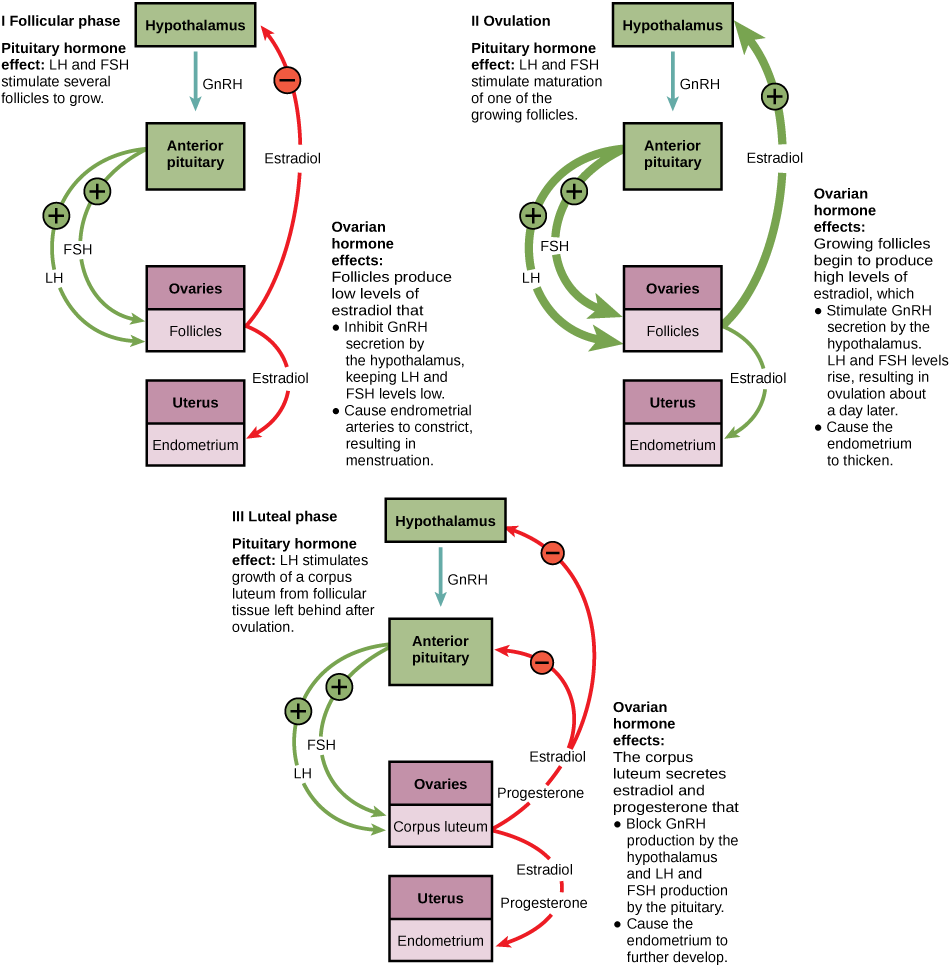
Which of the following statements about hormone regulation of the female reproductive cycle is false?
<!–<para>C–>
Just prior to the middle of the cycle (approximately day 14), the high level of estrogen causes FSH and especially LH to rise rapidly, then fall. The spike in LH causes ovulation: the most mature follicle, like that shown in (Figure), ruptures and releases its egg. The follicles that did not rupture degenerate and their eggs are lost. The level of estrogen decreases when the extra follicles degenerate.
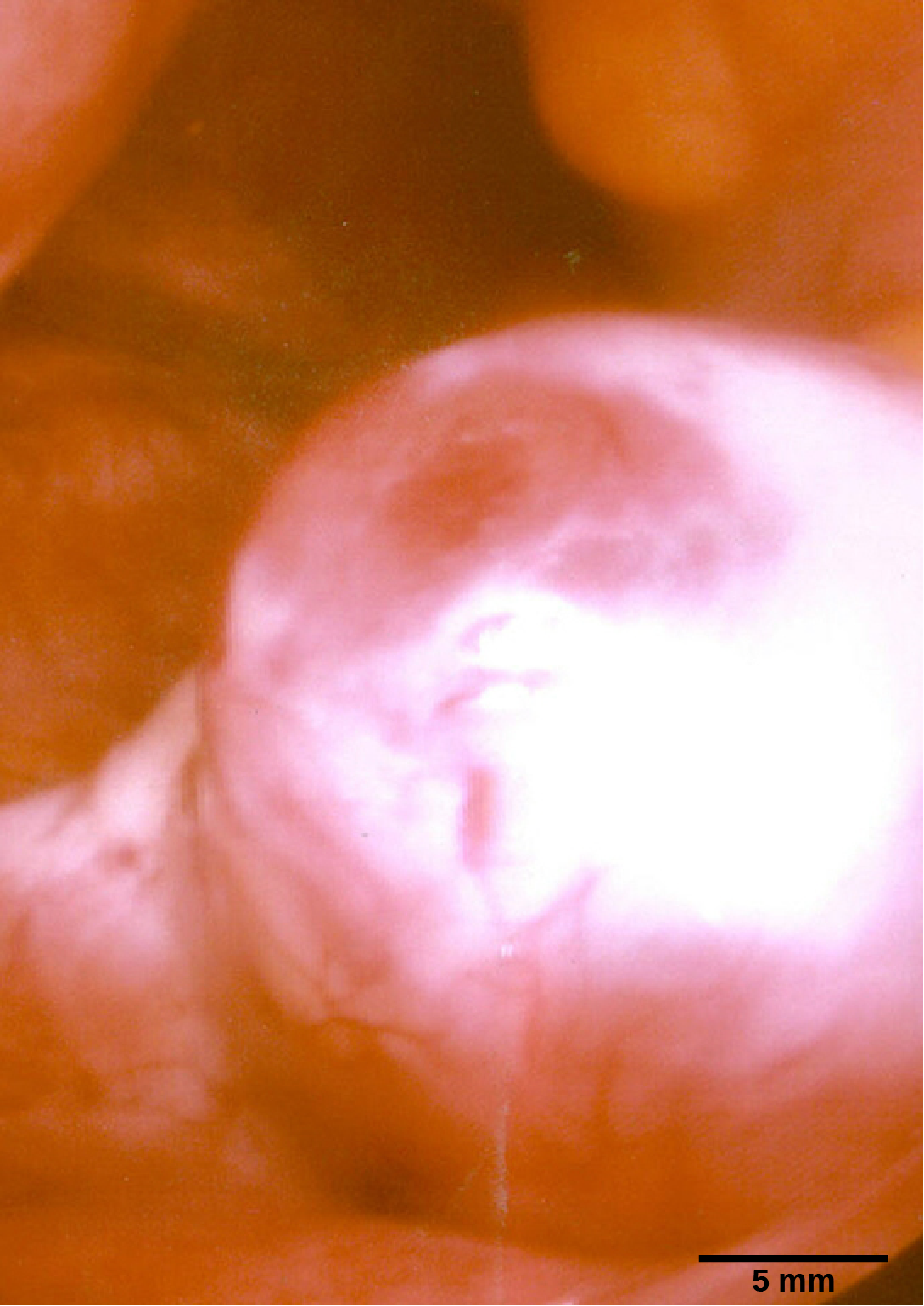
Following ovulation, the ovarian cycle enters its luteal phase, illustrated in (Figure) and the menstrual cycle enters its secretory phase, both of which run from about day 15 to 28. The luteal and secretory phases refer to changes in the ruptured follicle. The cells in the follicle undergo physical changes and produce a structure called a corpus luteum. The corpus luteum produces estrogen and progesterone. The progesterone facilitates the regrowth of the uterine lining and inhibits the release of further FSH and LH. The uterus is being prepared to accept a fertilized egg, should it occur during this cycle. The inhibition of FSH and LH prevents any further eggs and follicles from developing, while the progesterone is elevated. The level of estrogen produced by the corpus luteum increases to a steady level for the next few days.
If no fertilized egg is implanted into the uterus, the corpus luteum degenerates and the levels of estrogen and progesterone decrease. The endometrium begins to degenerate as the progesterone levels drop, initiating the next menstrual cycle. The decrease in progesterone also allows the hypothalamus to send GnRH to the anterior pituitary, releasing FSH and LH and starting the cycles again. (Figure) visually compares the ovarian and uterine cycles as well as the commensurate hormone levels.
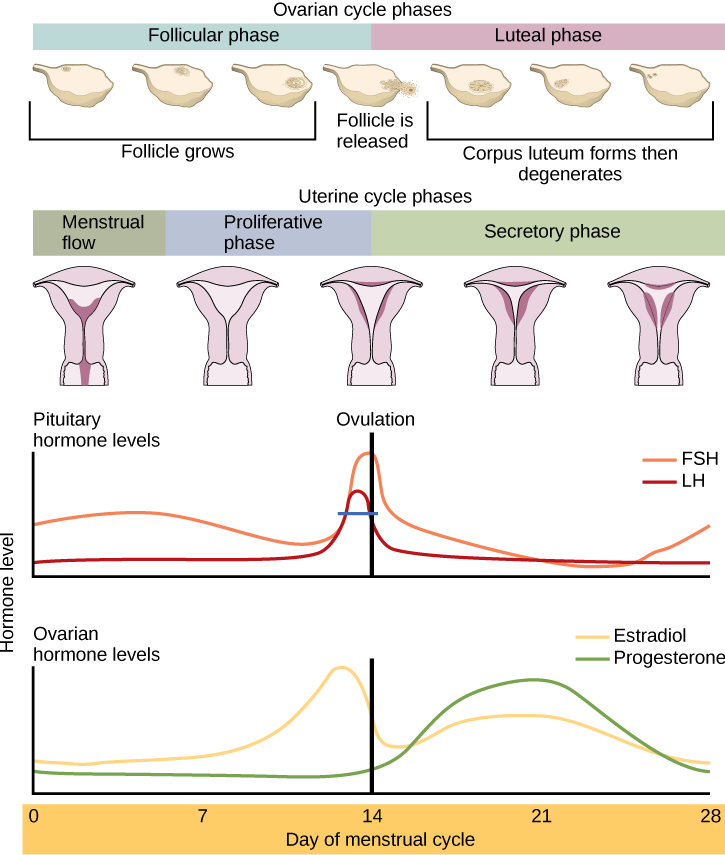
Which of the following statements about the menstrual cycle is false?
<!–<para>B–>
As women approach their mid-40s to mid-50s, their ovaries begin to lose their sensitivity to FSH and LH. Menstrual periods become less frequent and finally cease; this is menopause. There are still eggs and potential follicles on the ovaries, but without the stimulation of FSH and LH, they will not produce a viable egg to be released. The outcome of this is the inability to have children.
The side effects of menopause include hot flashes, heavy sweating (especially at night), headaches, some hair loss, muscle pain, vaginal dryness, insomnia, depression, weight gain, and mood swings. Estrogen is involved in calcium metabolism and, without it, blood levels of calcium decrease. To replenish the blood, calcium is lost from bone which may decrease the bone density and lead to osteoporosis. Supplementation of estrogen in the form of hormone replacement therapy (HRT) can prevent bone loss, but the therapy can have negative side effects. While HRT is thought to give some protection from colon cancer, osteoporosis, heart disease, macular degeneration, and possibly depression, its negative side effects include increased risk of: stroke or heart attack, blood clots, breast cancer, ovarian cancer, endometrial cancer, gall bladder disease, and possibly dementia.
Reproductive Endocrinologist
A reproductive endocrinologist is a physician who treats a variety of hormonal disorders related to reproduction and infertility in both men and women. The disorders include menstrual problems, infertility, pregnancy loss, sexual dysfunction, and menopause. Doctors may use fertility drugs, surgery, or assisted reproductive techniques (ART) in their therapy. ART involves the use of procedures to manipulate the egg or sperm to facilitate reproduction, such as in vitro fertilization.
Reproductive endocrinologists undergo extensive medical training, first in a four-year residency in obstetrics and gynecology, then in a three-year fellowship in reproductive endocrinology. To be board certified in this area, the physician must pass written and oral exams in both areas.
The male and female reproductive cycles are controlled by hormones released from the hypothalamus and anterior pituitary as well as hormones from reproductive tissues and organs. The hypothalamus monitors the need for the FSH and LH hormones made and released from the anterior pituitary. FSH and LH affect reproductive structures to cause the formation of sperm and the preparation of eggs for release and possible fertilization. In the male, FSH and LH stimulate Sertoli cells and interstitial cells of Leydig in the testes to facilitate sperm production. The Leydig cells produce testosterone, which also is responsible for the secondary sexual characteristics of males. In females, FSH and LH cause estrogen and progesterone to be produced. They regulate the female reproductive system which is divided into the ovarian cycle and the menstrual cycle. Menopause occurs when the ovaries lose their sensitivity to FSH and LH and the female reproductive cycles slow to a stop.
(Figure) Which of the following statements about hormone regulation of the female reproductive cycle is false?
(Figure) C
(Figure) Which of the following statements about the menstrual cycle is false?
(Figure) B
Which hormone causes Leydig cells to make testosterone?
A
Which hormone causes FSH and LH to be released?
C
Which hormone signals ovulation?
B
Which hormone causes the regrowth of the endometrial lining of the uterus?
D
If male reproductive pathways are not cyclical, how are they controlled?
Negative feedback in the male system is supplied through two hormones: inhibin and testosterone. Inhibin is produced by Sertoli cells when the sperm count exceeds set limits. The hormone inhibits GnRH and FSH, decreasing the activity of the Sertoli cells. Increased levels of testosterone affect the release of both GnRH and LH, decreasing the activity of the Leydig cells, resulting in decreased testosterone and sperm production.
Describe the events in the ovarian cycle leading up to ovulation.
Low levels of progesterone allow the hypothalamus to send GnRH to the anterior pituitary and cause the release of FSH and LH. FSH stimulates follicles on the ovary to grow and prepare the eggs for ovulation. As the follicles increase in size, they begin to release estrogen and a low level of progesterone into the blood. The level of estrogen rises to a peak, causing a spike in the concentration of LH. This causes the most mature follicle to rupture and ovulation occurs.
Chapter 43 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Pregnancy begins with the fertilization of an egg and continues through to the birth of the individual. The length of time of gestation varies among animals, but is very similar among the great apes: human gestation is 266 days, while chimpanzee gestation is 237 days, a gorilla’s is 257 days, and orangutan gestation is 260 days long. The fox has a 57-day gestation. Dogs and cats have similar gestations averaging 60 days. The longest gestation for a land mammal is an African elephant at 640 days. The longest gestations among marine mammals are the beluga and sperm whales at 460 days.
Twenty-four hours before fertilization, the egg has finished meiosis and becomes a mature oocyte. When fertilized (at conception) the egg becomes known as a zygote. The zygote travels through the oviduct to the uterus ((Figure)). The developing embryo must implant into the wall of the uterus within seven days, or it will deteriorate and die. The outer layers of the zygote (blastocyst) grow into the endometrium by digesting the endometrial cells, and wound healing of the endometrium closes up the blastocyst into the tissue. Another layer of the blastocyst, the chorion, begins releasing a hormone called human beta chorionic gonadotropin (β-HCG) which makes its way to the corpus luteum and keeps that structure active. This ensures adequate levels of progesterone that will maintain the endometrium of the uterus for the support of the developing embryo. Pregnancy tests determine the level of β-HCG in urine or serum. If the hormone is present, the test is positive.
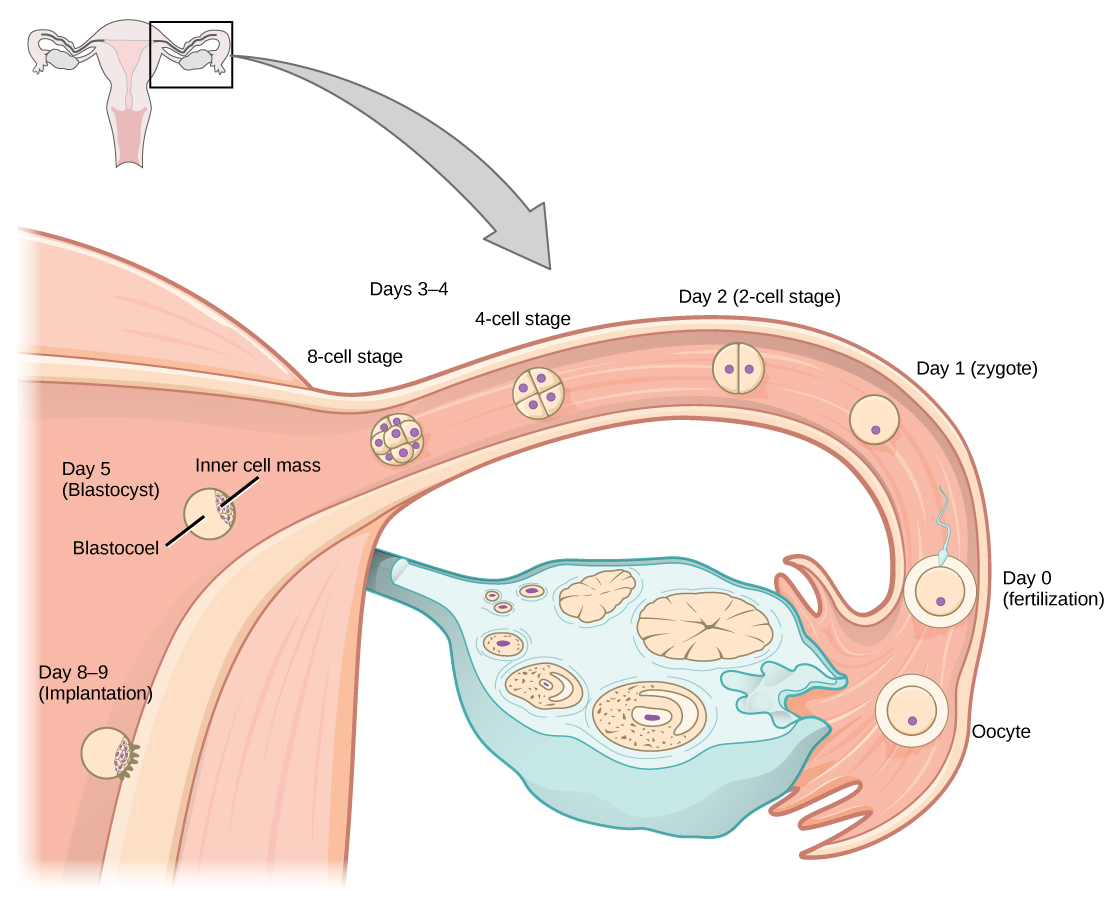
The gestation period is divided into three equal periods or trimesters. During the first two to four weeks of the first trimester, nutrition and waste are handled by the endometrial lining through diffusion. As the trimester progresses, the outer layer of the embryo begins to merge with the endometrium, and the placenta forms. This organ takes over the nutrient and waste requirements of the embryo and fetus, with the mother’s blood passing nutrients to the placenta and removing waste from it. Chemicals from the fetus, such as bilirubin, are processed by the mother’s liver for elimination. Some of the mother’s immunoglobulins will pass through the placenta, providing passive immunity against some potential infections.
Internal organs and body structures begin to develop during the first trimester. By five weeks, limb buds, eyes, the heart, and liver have been basically formed. By eight weeks, the term fetus applies, and the body is essentially formed, as shown in (Figure). The individual is about five centimeters (two inches) in length and many of the organs, such as the lungs and liver, are not yet functioning. Exposure to any toxins is especially dangerous during the first trimester, as all of the body’s organs and structures are going through initial development. Anything that affects that development can have a severe effect on the fetus’ survival.
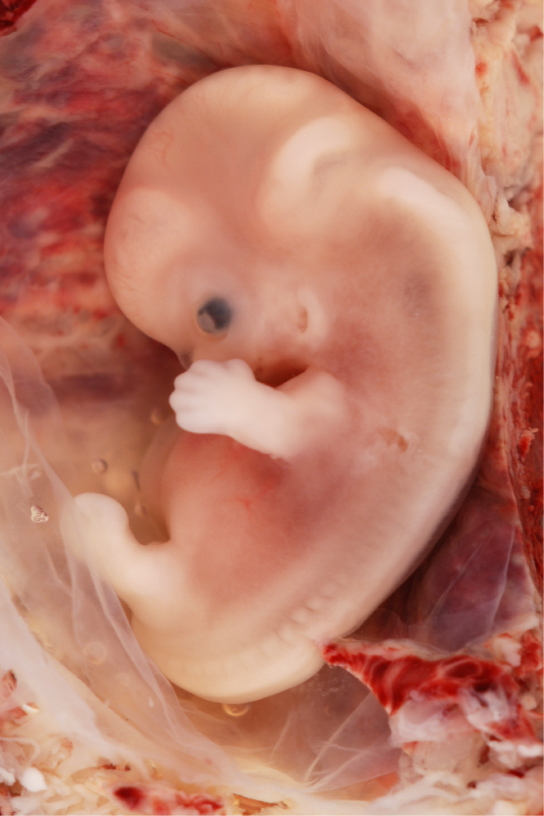
During the second trimester, the fetus grows to about 30 cm (12 inches), as shown in (Figure). It becomes active and the mother usually feels the first movements. All organs and structures continue to develop. The placenta has taken over the functions of nutrition and waste and the production of estrogen and progesterone from the corpus luteum, which has degenerated. The placenta will continue functioning up through the delivery of the baby.
During the third trimester, the fetus grows to 3 to 4 kg (6 ½ -8 ½ lbs.) and about 50 cm (19-20 inches) long, as illustrated in (Figure). This is the period of the most rapid growth during the pregnancy. Organ development continues to birth (and some systems, such as the nervous system and liver, continue to develop after birth). The mother will be at her most uncomfortable during this trimester. She may urinate frequently due to pressure on the bladder from the fetus. There may also be intestinal blockage and circulatory problems, especially in her legs. Clots may form in her legs due to pressure from the fetus on returning veins as they enter the abdominal cavity.
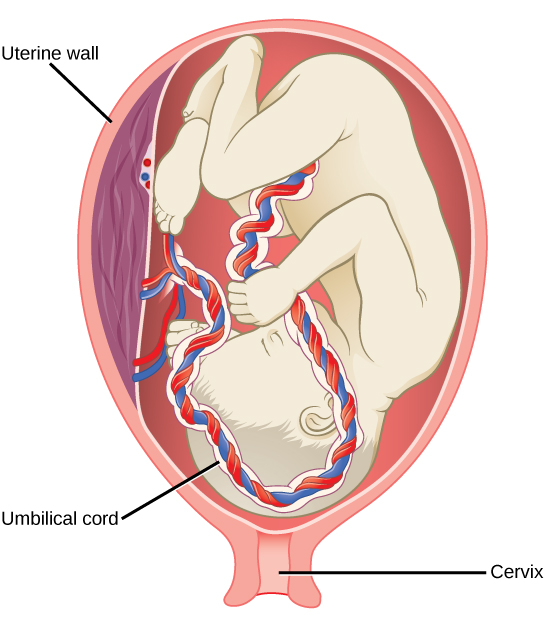
Visit this site to see the stages of human fetal development.
Labor is the physical efforts of expulsion of the fetus and the placenta from the uterus during birth (parturition). Toward the end of the third trimester, estrogen causes receptors on the uterine wall to develop and bind the hormone oxytocin. At this time, the baby reorients, facing forward and down with the back or crown of the head engaging the cervix (uterine opening). This causes the cervix to stretch and nerve impulses are sent to the hypothalamus, which signals for the release of oxytocin from the posterior pituitary. The oxytocin causes the smooth muscle in the uterine wall to contract. At the same time, the placenta releases prostaglandins into the uterus, increasing the contractions. A positive feedback relay occurs between the uterus, hypothalamus, and the posterior pituitary to assure an adequate supply of oxytocin. As more smooth muscle cells are recruited, the contractions increase in intensity and force.
There are three stages to labor. During stage one, the cervix thins and dilates. This is necessary for the baby and placenta to be expelled during birth. The cervix will eventually dilate to about 10 cm. During stage two, the baby is expelled from the uterus. The uterus contracts and the mother pushes as she compresses her abdominal muscles to aid the delivery. The last stage is the passage of the placenta after the baby has been born and the organ has completely disengaged from the uterine wall. If labor should stop before stage two is reached, synthetic oxytocin, known as Pitocin, can be administered to restart and maintain labor.
An alternative to labor and delivery is the surgical delivery of the baby through a procedure called a Caesarian section. This is major abdominal surgery and can lead to post-surgical complications for the mother, but in some cases it may be the only way to safely deliver the baby.
The mother’s mammary glands go through changes during the third trimester to prepare for lactation and breastfeeding. When the baby begins suckling at the breast, signals are sent to the hypothalamus causing the release of prolactin from the anterior pituitary. Prolactin causes the mammary glands to produce milk. Oxytocin is also released, promoting the release of the milk. The milk contains nutrients for the baby’s development and growth as well as immunoglobulins to protect the child from bacterial and viral infections.
The prevention of a pregnancy comes under the terms contraception or birth control. Strictly speaking, contraception refers to preventing the sperm and egg from joining. Both terms are, however, frequently used interchangeably.
| Contraceptive Methods | ||
|---|---|---|
| Method | Examples | Failure Rate in Typical Use Over 12 Months |
| Barrier | male condom, female condom, sponge, cervical cap, diaphragm, spermicides | 15 to 24% |
| Hormonal | oral, patch, vaginal ring | 8% |
| injection | 3% | |
| implant | less than 1% | |
| Other | natural family planning | 12 to 25% |
| withdrawal | 27% | |
| sterilization | less than 1% | |
(Figure) lists common methods of contraception. The failure rates listed are not the ideal rates that could be realized, but the typical rates that occur. A failure rate is the number of pregnancies resulting from the method’s use over a twelve-month period. Barrier methods, such as condoms, cervical caps, and diaphragms, block sperm from entering the uterus, preventing fertilization. Spermicides are chemicals that are placed in the vagina that kill sperm. Sponges, which are saturated with spermicides, are placed in the vagina at the cervical opening. Combinations of spermicidal chemicals and barrier methods achieve lower failure rates than do the methods when used separately.
Nearly a quarter of the couples using barrier methods, natural family planning, or withdrawal can expect a failure of the method. Natural family planning is based on the monitoring of the menstrual cycle and having intercourse only during times when the egg is not available. A woman’s body temperature may rise a degree Celsius at ovulation and the cervical mucus may increase in volume and become more pliable. These changes give a general indication of when intercourse is more or less likely to result in fertilization. Withdrawal involves the removal of the penis from the vagina during intercourse, before ejaculation occurs. This is a risky method with a high failure rate due to the possible presence of sperm in the bulbourethral gland’s secretion, which may enter the vagina prior to removing the penis.
Hormonal methods use synthetic progesterone (sometimes in combination with estrogen), to inhibit the hypothalamus from releasing FSH or LH, and thus prevent an egg from being available for fertilization. The method of administering the hormone affects failure rate. The most reliable method, with a failure rate of less than 1 percent, is the implantation of the hormone under the skin. The same rate can be achieved through the sterilization procedures of vasectomy in the man or of tubal ligation in the woman, or by using an intrauterine device (IUD). IUDs are inserted into the uterus and establish an inflammatory condition that prevents fertilized eggs from implanting into the uterine wall.
Compliance with the contraceptive method is a strong contributor to the success or failure rate of any particular method. The only method that is completely effective at preventing conception is abstinence. The choice of contraceptive method depends on the goals of the woman or couple. Tubal ligation and vasectomy are considered permanent prevention, while other methods are reversible and provide short-term contraception.
Termination of an existing pregnancy can be spontaneous or voluntary. Spontaneous termination is a miscarriage and usually occurs very early in the pregnancy, usually within the first few weeks. This occurs when the fetus cannot develop properly and the gestation is naturally terminated. Voluntary termination of a pregnancy is an abortion. Laws regulating abortion vary between states and tend to view fetal viability as the criteria for allowing or preventing the procedure.
Infertility is the inability to conceive a child or carry a child to birth. About 75 percent of causes of infertility can be identified; these include diseases, such as sexually transmitted diseases that can cause scarring of the reproductive tubes in either men or women, or developmental problems frequently related to abnormal hormone levels in one of the individuals. Inadequate nutrition, especially starvation, can delay menstruation. Stress can also lead to infertility. Short-term stress can affect hormone levels, while long-term stress can delay puberty and cause less frequent menstrual cycles. Other factors that affect fertility include toxins (such as cadmium), tobacco smoking, marijuana use, gonadal injuries, and aging.
If infertility is identified, several assisted reproductive technologies (ART) are available to aid conception. A common type of ART is in vitro fertilization (IVF) where an egg and sperm are combined outside the body and then placed in the uterus. Eggs are obtained from the woman after extensive hormonal treatments that prepare mature eggs for fertilization and prepare the uterus for implantation of the fertilized egg. Sperm are obtained from the man and they are combined with the eggs and supported through several cell divisions to ensure viability of the zygotes. When the embryos have reached the eight-cell stage, one or more is implanted into the woman’s uterus. If fertilization is not accomplished by simple IVF, a procedure that injects the sperm into an egg can be used. This is called intracytoplasmic sperm injection (ICSI) and is shown in (Figure). IVF procedures produce a surplus of fertilized eggs and embryos that can be frozen and stored for future use. The procedures can also result in multiple births.
Human pregnancy begins with fertilization of an egg and proceeds through the three trimesters of gestation. The labor process has three stages (contractions, delivery of the fetus, expulsion of the placenta), each propelled by hormones. The first trimester lays down the basic structures of the body, including the limb buds, heart, eyes, and the liver. The second trimester continues the development of all of the organs and systems. The third trimester exhibits the greatest growth of the fetus and culminates in labor and delivery. Prevention of a pregnancy can be accomplished through a variety of methods including barriers, hormones, or other means. Assisted reproductive technologies may help individuals who have infertility problems.
Nutrient and waste requirements for the developing fetus are handled during the first few weeks by:
B
Progesterone is made during the third trimester by the:
A
Which contraceptive method is 100 percent effective at preventing pregnancy?
D
Which type of short term contraceptive method is generally more effective than others?
B
Which hormone is primarily responsible for the contractions during labor?
A
Major organs begin to develop during which part of human gestation?
B
Describe the major developments during each trimester of human gestation.
The first trimester lays down the basic structures of the body, including the limb buds, heart, eyes, and the liver. The second trimester continues the development of all of the organs and systems established during the first trimester. The placenta takes over the production of estrogen and high levels of progesterone and handles the nutrient and waste requirements of the fetus. The third trimester exhibits the greatest growth of the fetus, culminating in labor and delivery.
Describe the stages of labor.
Stage one of labor results in the thinning of the cervix and the dilation of the cervical opening. Stage two delivers the baby, and stage three delivers the placenta.
Chapter 43 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
The process in which an organism develops from a single-celled zygote to a multi-cellular organism is complex and well-regulated. The early stages of embryonic development are also crucial for ensuring the fitness of the organism.
Fertilization, pictured in (Figure)a is the process in which gametes (an egg and sperm) fuse to form a zygote. The egg and sperm each contain one set of chromosomes. To ensure that the offspring has only one complete diploid set of chromosomes, only one sperm must fuse with one egg. In mammals, the egg is protected by a layer of extracellular matrix consisting mainly of glycoproteins called the zona pellucida. When a sperm binds to the zona pellucida, a series of biochemical events, called the acrosomal reactions, take place. In placental mammals, the acrosome contains digestive enzymes that initiate the degradation of the glycoprotein matrix protecting the egg and allowing the sperm plasma membrane to fuse with the egg plasma membrane, as illustrated in (Figure)b. The fusion of these two membranes creates an opening through which the sperm nucleus is transferred into the ovum. The nuclear membranes of the egg and sperm break down and the two haploid genomes condense to form a diploid genome.
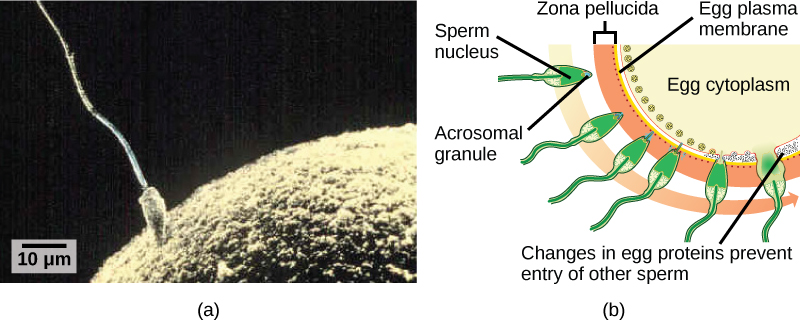
To ensure that no more than one sperm fertilizes the egg, once the acrosomal reactions take place at one location of the egg membrane, the egg releases proteins in other locations to prevent other sperm from fusing with the egg. If this mechanism fails, multiple sperm can fuse with the egg, resulting in polyspermy. The resulting embryo is not genetically viable and dies within a few days.
The development of multi-cellular organisms begins from a single-celled zygote, which undergoes rapid cell division to form the blastula. The rapid, multiple rounds of cell division are termed cleavage. Cleavage is illustrated in ((Figure)a). After the cleavage has produced over 100 cells, the embryo is called a blastula. The blastula is usually a spherical layer of cells (the blastoderm) surrounding a fluid-filled or yolk-filled cavity (the blastocoel). Mammals at this stage form a structure called the blastocyst, characterized by an inner cell mass that is distinct from the surrounding blastula, shown in (Figure)b. During cleavage, the cells divide without an increase in mass; that is, one large single-celled zygote divides into multiple smaller cells. Each cell within the blastula is called a blastomere.

Cleavage can take place in two ways: holoblastic (total) cleavage or meroblastic (partial) cleavage. The type of cleavage depends on the amount of yolk in the eggs. In placental mammals (including humans) where nourishment is provided by the mother’s body, the eggs have a very small amount of yolk and undergo holoblastic cleavage. Other species, such as birds, with a lot of yolk in the egg to nourish the embryo during development, undergo meroblastic cleavage.
In mammals, the blastula forms the blastocyst in the next stage of development. Here the cells in the blastula arrange themselves in two layers: the inner cell mass, and an outer layer called the trophoblast. The inner cell mass is also known as the embryoblast and this mass of cells will go on to form the embryo. At this stage of development, illustrated in (Figure) the inner cell mass consists of embryonic stem cells that will differentiate into the different cell types needed by the organism. The trophoblast will contribute to the placenta and nourish the embryo.
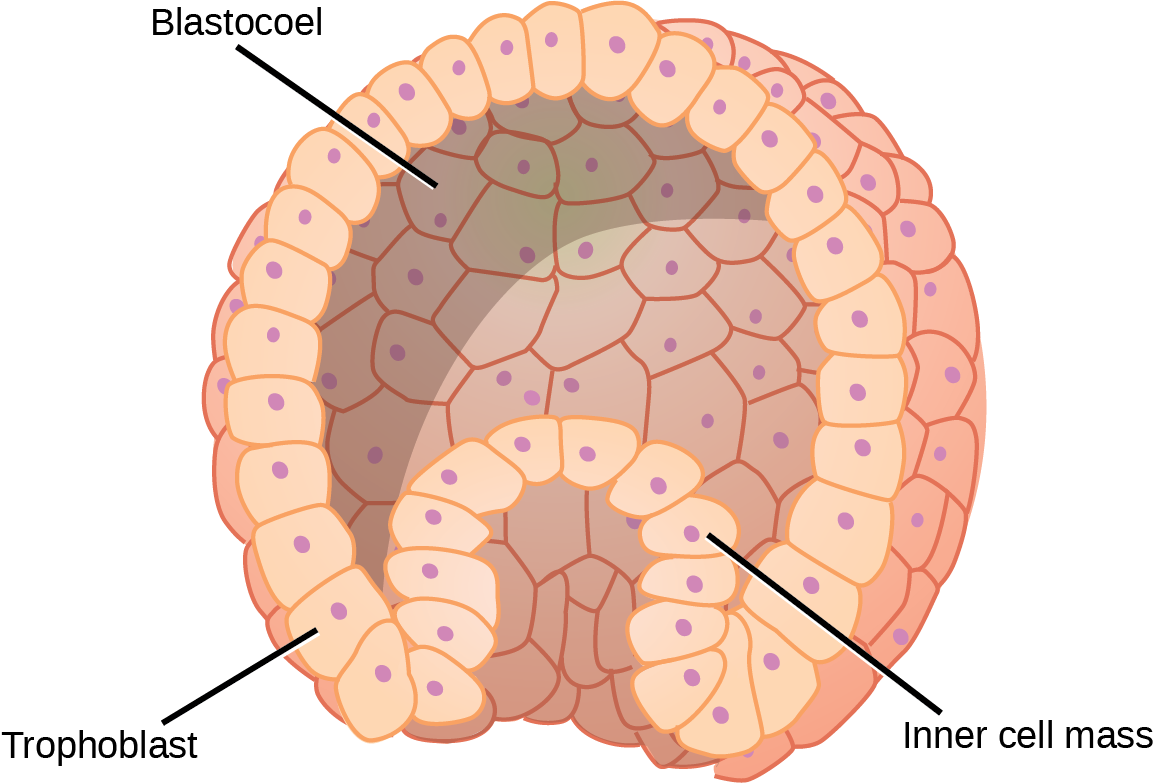
Visit the Virtual Human Embryo project at the Endowment for Human Development site to step through an interactive that shows the stages of embryo development, including micrographs and rotating 3-D images.
The typical blastula is a ball of cells. The next stage in embryonic development is the formation of the body plan. The cells in the blastula rearrange themselves spatially to form three layers of cells. This process is called gastrulation. During gastrulation, the blastula folds upon itself to form the three layers of cells. Each of these layers is called a germ layer and each germ layer differentiates into different organ systems.
The three germ layers, shown in (Figure), are the endoderm, the ectoderm, and the mesoderm. The ectoderm gives rise to the nervous system and the epidermis. The mesoderm gives rise to the muscle cells and connective tissue in the body. The endoderm gives rise to columnar cells found in the digestive system and many internal organs.
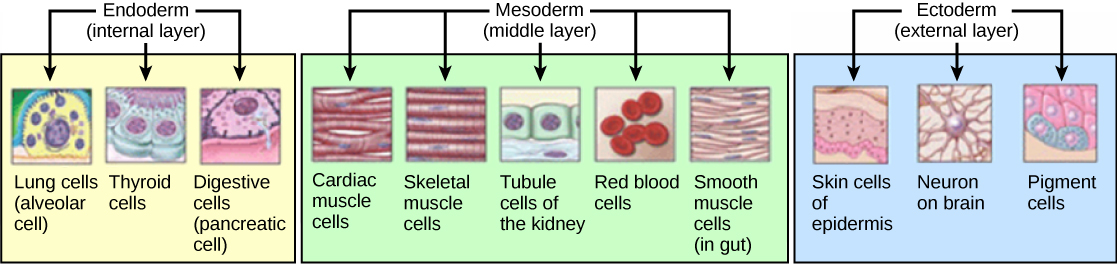
Are Designer Babies in Our Future?
If you could prevent your child from getting a devastating genetic disease, would you do it? Would you select the sex of your child or select for their attractiveness, strength, or intelligence? How far would you go to maximize the possibility of resistance to disease? The genetic engineering of a human child, the production of “designer babies” with desirable phenotypic characteristics, was once a topic restricted to science fiction. This is the case no longer: science fiction is now overlapping into science fact. Many phenotypic choices for offspring are already available, with many more likely to be possible in the not too distant future. Which traits should be selected and how they should be selected are topics of much debate within the worldwide medical community. The ethical and moral line is not always clear or agreed upon, and some fear that modern reproductive technologies could lead to a new form of eugenics.
Eugenics is the use of information and technology from a variety of sources to improve the genetic makeup of the human race. The goal of creating genetically superior humans was quite prevalent (although controversial) in several countries during the early 20th century, but fell into disrepute when Nazi Germany developed an extensive eugenics program in the 1930s and 40s. As part of their program, the Nazis forcibly sterilized hundreds of thousands of the so-called “unfit” and killed tens of thousands of institutionally disabled people as part of a systematic program to develop a genetically superior race of Germans known as Aryans. Ever since, eugenic ideas have not been as publicly expressed, but there are still those who promote them.
Efforts have been made in the past to control traits in human children using donated sperm from men with desired traits. In fact, eugenicist Robert Klark Graham established a sperm bank in 1980 that included samples exclusively from donors with high IQs. The “genius” sperm bank failed to capture the public’s imagination and the operation closed in 1999.
In more recent times, the procedure known as prenatal genetic diagnosis (PGD) has been developed. PGD involves the screening of human embryos as part of the process of in vitro fertilization, during which embryos are conceived and grown outside the mother’s body for some period of time before they are implanted. The term PGD usually refers to both the diagnosis, selection, and the implantation of the selected embryos.
In the least controversial use of PGD, embryos are tested for the presence of alleles which cause genetic diseases such as sickle cell disease, muscular dystrophy, and hemophilia, in which a single disease-causing allele or pair of alleles has been identified. By excluding embryos containing these alleles from implantation into the mother, the disease is prevented, and the unused embryos are either donated to science or discarded. There are relatively few in the worldwide medical community that question the ethics of this type of procedure, which allows individuals scared to have children because of the alleles they carry to do so successfully. The major limitation to this procedure is its expense. Not usually covered by medical insurance and thus out of reach financially for most couples, only a very small percentage of all live births use such complicated methodologies. Yet, even in cases like these where the ethical issues may seem to be clear-cut, not everyone agrees with the morality of these types of procedures. For example, to those who take the position that human life begins at conception, the discarding of unused embryos, a necessary result of PGD, is unacceptable under any circumstances.
A murkier ethical situation is found in the selection of a child’s sex, which is easily performed by PGD. Currently, countries such as Great Britain have banned the selection of a child’s sex for reasons other than preventing sex-linked diseases. Other countries allow the procedure for “family balancing”, based on the desire of some parents to have at least one child of each sex. Still others, including the United States, have taken a scattershot approach to regulating these practices, essentially leaving it to the individual practicing physician to decide which practices are acceptable and which are not.
Even murkier are rare instances of disabled parents, such as those with deafness or dwarfism, who select embryos via PGD to ensure that they share their disability. These parents usually cite many positive aspects of their disabilities and associated culture as reasons for their choice, which they see as their moral right. To others, to purposely cause a disability in a child violates the basic medical principle of Primum non nocere, “first, do no harm.” This procedure, although not illegal in most countries, demonstrates the complexity of ethical issues associated with choosing genetic traits in offspring.
Where could this process lead? Will this technology become more affordable and how should it be used? With the ability of technology to progress rapidly and unpredictably, a lack of definitive guidelines for the use of reproductive technologies before they arise might make it difficult for legislators to keep pace once they are in fact realized, assuming the process needs any government regulation at all. Other bioethicists argue that we should only deal with technologies that exist now, and not in some uncertain future. They argue that these types of procedures will always be expensive and rare, so the fears of eugenics and “master” races are unfounded and overstated. The debate continues.
The early stages of embryonic development begin with fertilization. The process of fertilization is tightly controlled to ensure that only one sperm fuses with one egg. After fertilization, the zygote undergoes cleavage to form the blastula. The blastula, which in some species is a hollow ball of cells, undergoes a process called gastrulation, in which the three germ layers form. The ectoderm gives rise to the nervous system and the epidermal skin cells, the mesoderm gives rise to the muscle cells and connective tissue in the body, and the endoderm gives rise to columnar cells and internal organs.
Which of the following is false?
B
During cleavage, the mass of cells:
D
What do you think would happen if multiple sperm fused with one egg?
Multiple sperm can fuse with the egg, resulting in polyspermy. The resulting embryo is not genetically viable and dies within a few days.
Why do mammalian eggs have a small concentration of yolk, while bird and reptile eggs have a large concentration of yolk?
Mammalian eggs do not need a lot of yolk because the developing fetus obtains nutrients from the mother. Other species, in which the fetus develops outside of the mother’s body, such as occurs with birds, require a lot of yolk in the egg to nourish the embryo during development.
Chapter 43 in OpenStax Concepts of Biology 2e
By the end of this section, you will be able to do the following:
Gastrulation leads to the formation of the three germ layers that give rise, during further development, to the different organs in the animal body. This process is called organogenesis. Organogenesis is characterized by rapid and precise movements of the cells within the embryo.
Organs form from the germ layers through the process of differentiation. During differentiation, the embryonic stem cells express specific sets of genes which will determine their ultimate cell type. For example, some cells in the ectoderm will express the genes specific to skin cells. As a result, these cells will differentiate into epidermal cells. The process of differentiation is regulated by cellular signaling cascades.
Scientists study organogenesis extensively in the lab in fruit flies (Drosophila) and the nematode Caenorhabditis elegans. Drosophila have segments along their bodies, and the patterning associated with the segment formation has allowed scientists to study which genes play important roles in organogenesis along the length of the embryo at different time points. The nematode C.elegans has roughly 1000 somatic cells and scientists have studied the fate of each of these cells during their development in the nematode life cycle. There is little variation in patterns of cell lineage between individuals, unlike in mammals where cell development from the embryo is dependent on cellular cues.
In vertebrates, one of the primary steps during organogenesis is the formation of the neural system. The ectoderm forms epithelial cells and tissues, and neuronal tissues. During the formation of the neural system, special signaling molecules called growth factors signal some cells at the edge of the ectoderm to become epidermis cells. The remaining cells in the center form the neural plate. If the signaling by growth factors were disrupted, then the entire ectoderm would differentiate into neural tissue.
The neural plate undergoes a series of cell movements where it rolls up and forms a tube called the neural tube, as illustrated in (Figure). In further development, the neural tube will give rise to the brain and the spinal cord.
The mesoderm that lies on either side of the vertebrate neural tube will develop into the various connective tissues of the animal body. A spatial pattern of gene expression reorganizes the mesoderm into groups of cells called somites with spaces between them. The somites, illustrated in (Figure) will further develop into the ribs, lungs, and segmental (spine) muscle. The mesoderm also forms a structure called the notochord, which is rod-shaped and forms the central axis of the animal body.
Even as the germ layers form, the ball of cells still retains its spherical shape. However, animal bodies have lateral-medial (left-right), dorsal-ventral (back-belly), and anterior-posterior (head-feet) axes, illustrated in (Figure).
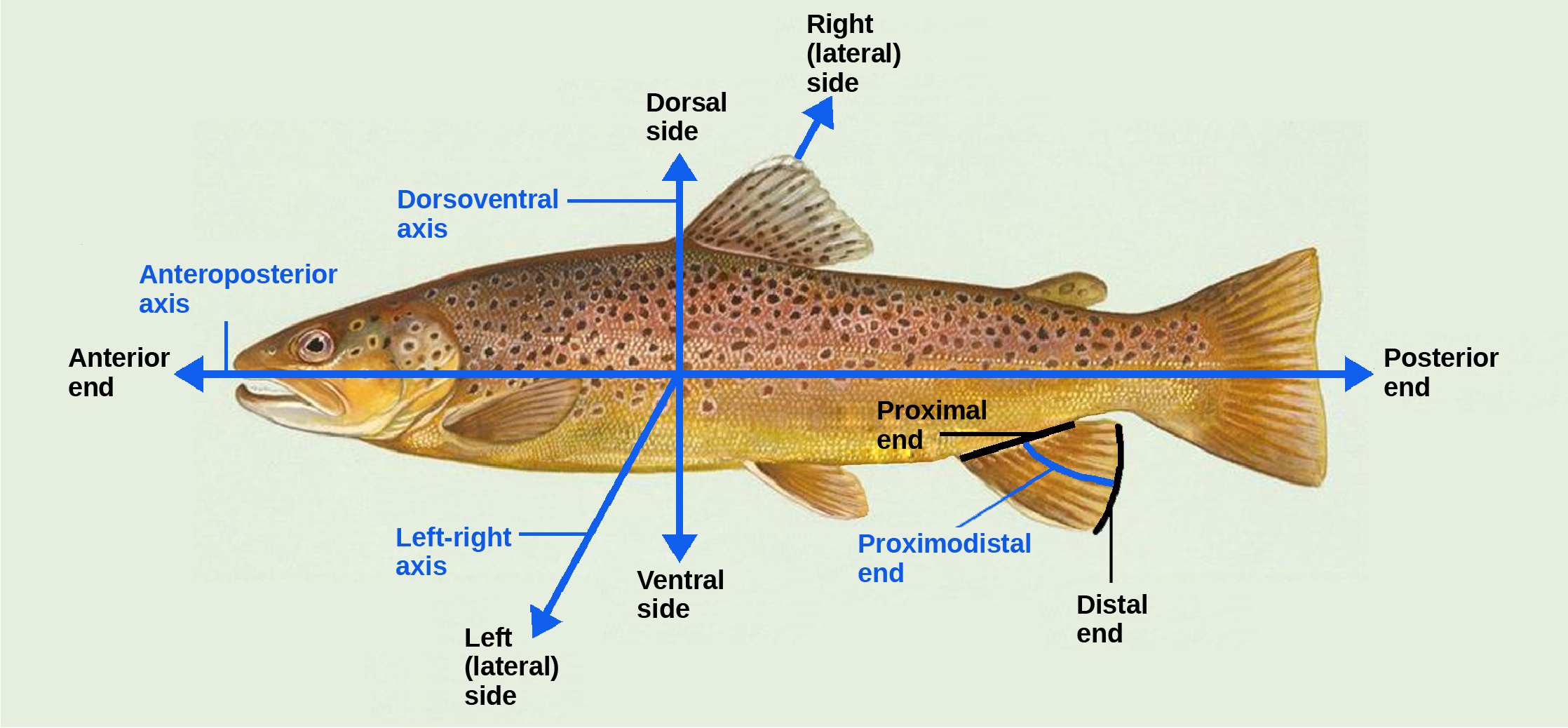
How are these established? In one of the most seminal experiments ever to be carried out in developmental biology, Spemann and Mangold took dorsal cells from one embryo and transplanted them into the belly region of another embryo. They found that the transplanted embryo now had two notochords: one at the dorsal site from the original cells and another at the transplanted site. This suggested that the dorsal cells were genetically programmed to form the notochord and define the axis. Since then, researchers have identified many genes that are responsible for axis formation. Mutations in these genes leads to the loss of symmetry required for organism development.
Animal bodies have externally visible symmetry. However, the internal organs are not symmetric. For example, the heart is on the left side and the liver on the right. The formation of the central left-right axis is an important process during development. This internal asymmetry is established very early during development and involves many genes. Research is still ongoing to fully understand the developmental implications of these genes.
Organogenesis is the formation of organs from the germ layers. Each germ layer gives rise to specific tissue types. The first stage is the formation of the neural system in the ectoderm. The mesoderm gives rise to somites and the notochord. Formation of vertebrate axis is another important developmental stage.
Which of the following gives rise to the skin cells?
A
The ribs form from the ________.
D
Explain how the different germ layers give rise to different tissue types.
Organs form from the germ layers through the process of differentiation. During differentiation, the embryonic stem cells express a specific set of genes that will determine their ultimate fate as a cell type. For example, some cells in the ectoderm will express the genes specific to skin cells. As a result, these cells will differentiate into epidermal cells. The process of differentiation is regulated by cellular signaling cascades.
Explain the role of axis formation in development.
Animal bodies have lateral-medial (left-right), dorsal-ventral (back-belly), and anterior-posterior (head-feet) axes. The dorsal cells are genetically programmed to form the notochord and define the axis. There are many genes responsible for axis formation. Mutations in these genes lead to the loss of symmetry required for organism development.
Chapter 43 in OpenStax Concepts of Biology 2e
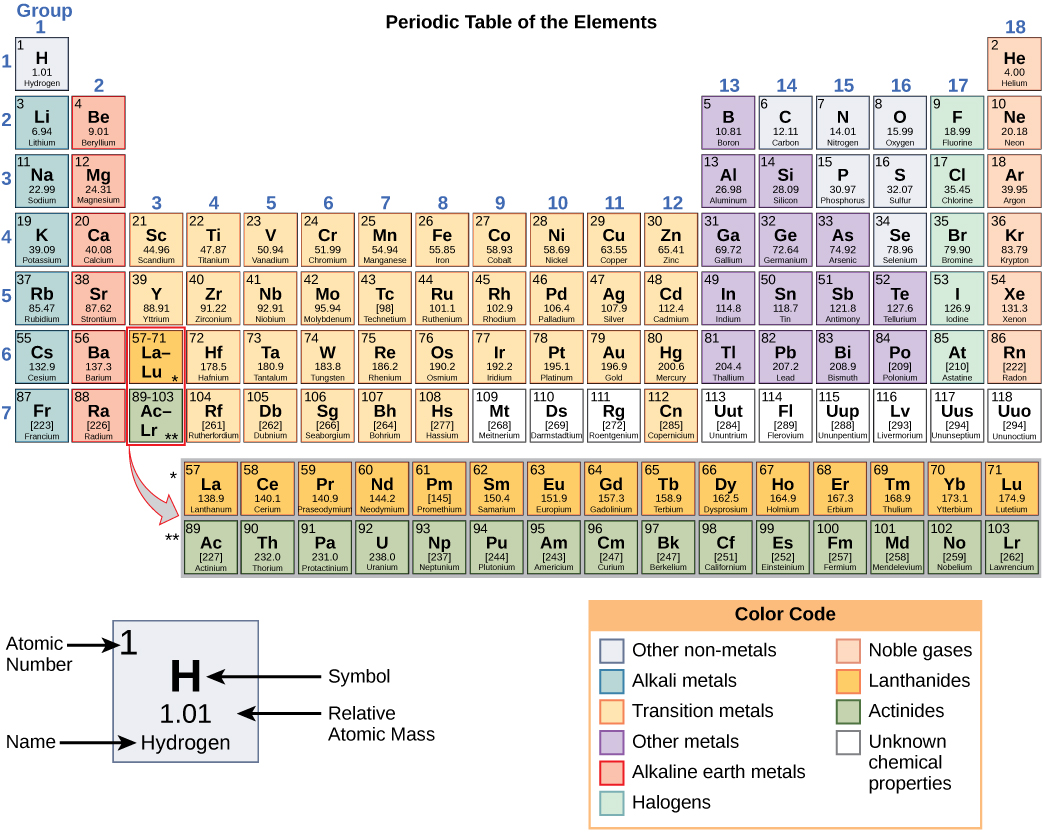
| Measurement | Unit | Abbreviation | Metric Equivalent | Approximate Standard Equivalent |
|---|---|---|---|---|
| Length | nanometer | nm | 1 nm = 10−9 m |
|
| micrometer | µm | 1 µm = 10−6 m | ||
| millimeter | mm | 1 mm = 0.001 m | ||
| centimeter | cm | 1 cm = 0.01 m | ||
| meter | m |
| ||
| kilometer | km | 1 km = 1000 m | ||
| Mass | microgram | µg | 1 µg = 10−6 g |
|
| milligram | mg | 1 mg = 10−3 g | ||
| gram | g | 1 g = 1000 mg | ||
| kilogram | kg | 1 kg = 1000 g | ||
| Volume | microliter | µl | 1 µl = 10−6 l |
|
| milliliter | ml | 1 ml = 10−3 l | ||
| liter | l | 1 l = 1000 ml | ||
| kiloliter | kl | 1 kl = 1000 l | ||
| Area | square centimeter | cm2 | 1 cm2 = 100 mm2 |
|
| square meter | m2 | 1 m2 = 10,000 cm2 | ||
| hectare | ha | 1 ha = 10,000 m2 | ||
| Temperature | Celsius | °C | — | 1 °C = 5/9 × (°F − 32) |
NSCC Edition
Chapters from two open textbooks were used to create this new NSCC edition:
Molnar, C., & Gair, J. (2015). Concepts of Biology – 1st Canadian Edition. BCcampus. https://opentextbc.ca/biology/ CC BY 4.0 Licence.
Clark, M. A., Choi, J. & Douglas, M. ( 2018). OpenStax Concepts of Biology 2e. https://opentextbc.ca/biology2eopenstax/ CC BY 4.0 Licence.
See table below for a adoption breakdown.
| Current Chapter | Textbook | Chapter Copied |
| Ch. 1 Intro to Biology | Concepts of Biology: 1st Canadian Edition | Ch. 1 Intro to Biology |
| Ch. 2 Chemistry of Life | Concepts of Biology: 1st Canadian Edition | Ch. 2 Chemistry of Life |
| Ch. 3 Cell Structure/Function | Concepts of Biology: 1st Canadian Edition | Ch. 3 Cell Structure/Function |
| Ch. 4 How Cells Obtain Energy | Concepts of Biology: 1st Canadian Edition | Ch. 4 How Cells Obtain Energy |
| Ch. 5 Reproduction Cellular Level | Concepts of Biology: 1st Canadian Edition | Ch. 6 Reproduction Cellular Level |
| Ch. 6 Cellular Basis of Inheritance | Concepts of Biology: 1st Canadian Edition | Ch. 7 Cellular Basis of Inheritance |
| Ch. 7 Patterns of Inheritance | Concepts of Biology: 1st Canadian Edition | Ch. 8 Patterns of Inheritance |
| Ch. 8 Molecular Bio | Concepts of Biology: 1st Canadian Edition | Ch. 9 Molecular Bio |
| Ch. 9 Evolution | OpenStax Concepts of Biology 2e | Ch. 18 – Evolution |
| Ch. 10 Form and Function | OpenStax Concepts of Biology 2e | Ch. 33 Form and Function |
| Ch. 11 Excretion | OpenStax Concepts of Biology 2e | Ch 41. Excretion |
| Ch. 12 Digestion | OpenStax Concepts of Biology 2e | Ch. 34 Digestive System |
| Ch. 13 Circulation | OpenStax Concepts of Biology 2e | Ch. 40 Circulatory System |
| Ch. 14 Respiration | OpenStax Concepts of Biology 2e | Ch. 39 Respiratory system |
| Ch. 15 Immune system | OpenStax Concepts of Biology 2e | Ch. 42 Immune system |
| Ch. 16 Nervous system | OpenStax Concepts of Biology 2e | Ch. 35 Nervous System |
| Ch. 17 Sensory | OpenStax Concepts of Biology 2e | Ch. 36 Sensory Systems |
| Ch. 18 Musculoskeletal | OpenStax Concepts of Biology 2e | Ch. 38 Musculoskeletal system |
| Ch. 19 Endocrine | OpenStax Concepts of Biology 2e | Ch. 37 Endocrine system |
| Ch. 20 Reproductive system | OpenStax Concepts of Biology 2e | Ch. 43 Reproductive |
Concepts of Biology 1st Canadian Edition Version History
The following table provides a record of edits and changes made to Concepts of Biology 1st Canadian Edition, since its initial publication in the B.C. Open Textbook Collection. Whenever edits or updates are made, we make the required changes in the text and provide a record and description of those changes here. If the change is minor, the version number increases by 0.01. However, if the edits involve substantial updates, the version number goes up to the next full number. The files on our website always reflect the most recent version, including the print-on-demand copy.
If you find an error in this book, please fill out the Report an Open Textbook Error form.
| Version | Date | Change | Details |
|---|---|---|---|
| 1.01 | May 1, 2015 | Book added to the B.C. Open Textbook collection. | |
| 1.02 | November 21, 2017 |
| Some <a id=””> tags in the book were causing large sections of text to turn blue. These tags were removed. In addition, all of the exercise questions were edited to ensure a consistent format. This involved putting the content into ordered lists and grouping questions and answers together. Note: We are aware that there is some text missing in Chapter 20.4, that Chapter 14.1 is missing exercise questions, and that Chapter 14.2 and 14.3 have the same exercise questions. The author has been informed of these issues and we will update the book once we receive the corrections. |
| 1.03 | September 17, 2018 | Image 2.15 replaced. | Original Figure 2.15 image was a duplicate of Figure 2.17. Replaced Figure 2.15 with the correct image. |
| 1.04 | June 13, 2019 | Updated the book’s theme. | The styles of this book have been updated, which may affect the page numbers of the PDF and print copy. |
| 2.01 | March 3, 2021 | Added H5P activities and improved book structure and formatting. | 80 H5P activities were embedded throughout the book, book structure was revised to improve navigation (but the order of all chapters remains the same), all PowerPoint files were compiled in the back matter of the book, and front matter and metadata was updated. |
NOTE: The PowerPoints match the chapter order in Concepts of Biology 1st Canadian Edition. They have not (yet) been revised to match the chapters in the NSCC edition.








{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}