
3 Chapter 3. Making Estimates
The most basic kind of inference about a population is an estimate of the location (or shape) of a distribution. The central limit theorem says that the sample mean is an unbiased estimator of the population mean and can be used to make a single point inference of the population mean. While making this kind of inference will give you the correct estimate on average, it seldom gives you exactly the correct estimate. As an alternative, statisticians have found out how to estimate an interval that almost certainly contains the population mean. In the next few pages, you will learn how to make three different inferences about a population from a sample. You will learn how to make interval estimates of the mean, the proportion of members with a certain characteristic, and the variance. Each of these procedures follows the same outline, yet each uses a different sampling distribution to link the sample you have chosen with the population you are trying to learn about.
Estimating the population mean
Though the sample mean is an unbiased estimator of the population mean, very few samples have a mean exactly equal to the population mean. Though few samples have a mean exactly equal to the population mean m, the central limit theorem tells us that most samples have a mean that is close to the population mean. As a result, if you use the central limit theorem to estimate μ, you will seldom be exactly right, but you will seldom be far wrong. Statisticians have learned how often a point estimate will be how wrong. Using this knowledge you can find an interval, a range of values that probably contains the population mean. You even get to choose how great a probability you want to have, though to raise the probability, the interval must be wider.
Most of the time, estimates are interval estimates. When you make an interval estimate, you can say, “I am z per cent sure that the mean of this population is between x and y“. Quite often, you will hear someone say that they have estimated that the mean is some number “± so much”. What they have done is quoted the midpoint of the interval for the “some number”, so that the interval between x and y can then be split in half with + “so much” above the midpoint and – “so much” below. They usually do not tell you that they are only “z per cent sure”. Making such an estimate is not hard— it is what Kevin did at the end of the last chapter. It is worth your while to go through the steps carefully now, because the same basic steps are followed for making any interval estimate.
In making any interval estimate, you need to use a sampling distribution. In making an interval estimate of the population mean, the sampling distribution you use is the t-distribution.
The basic method is to pick a sample and then find the range of population means that would put your sample’s t-score in the central part of the t-distribution. To make this a little clearer, look at the formula for t:
[latex]t=(\bar{x}-\mu)/(s/\sqrt{n})[/latex]
where n is your sample’s size and x and s are computed from your sample. μ is what you are trying to estimate. From the t-table, you can find the range of t-scores that include the middle 80 per cent, or 90 per cent, or whatever per cent, for n-1 degrees of freedom. Choose the percentage you want and use the table. You now have the lowest and highest t-scores, x, s, and n. You can then substitute the lowest t-score into the equation and solve for μ to find one of the limits for μ if your sample’s t-score is in the middle of the distribution. Then substitute the highest t-score into the equation, and find the other limit. Remember that you want two μ’s because you want to be able to say that the population mean is between two numbers.
The two t-scores are almost always ± the same number. The only heroic thing you have done is to assume that your sample has a t-score that is “in the middle” of the distribution. As long as your sample meets that assumption, the population mean will be within the limits of your interval. The probability part of your interval estimate, “I am z per cent sure that the mean is between…”, or “with z confidence, the mean is between…”, comes from how much of the t-distribution you want to include as “in the middle”. If you have a sample of 25 (so there are 24 df), looking at the table you will see that .95 of all samples of 25 will have a t-score between ±2.064; that also means that for any sample of 25, the probability that its t is between ±2.064 is .95.
As the probability goes up, the range of t-scores necessary to cover the larger proportion of the sample gets larger. This makes sense. If you want to improve the chance that your interval contains the population mean, you could simply choose a wider interval. For example, if your sample mean was 15, sample standard deviation was 10, and sample size was 25, to be .95 sure you were correct, you would need to base your mean on t-scores of ±2.064. Working through the arithmetic gives you an interval from 10.872 to 19.128. To have .99 confidence, you would need to base your interval on t-scores of ±2.797. Using these larger t-scores gives you a wider interval, one from 9.416 to 20.584. This trade-off between precision (a narrower interval is more precise) and confidence (probability of being correct), occurs in any interval estimation situation. There is also a trade-off with sample size. Looking at the t-table, note that the t-scores for any level of confidence are smaller when there are more degrees of freedom. Because sample size determines degrees of freedom, you can make an interval estimate for any level of confidence more precise if you have a larger sample. Larger samples are more expensive to collect, however, and one of the main reasons we want to learn statistics is to save money. There is a three-way trade-off in interval estimation between precision, confidence, and cost.
At Delta Beer Company in British Columbia, the director of human resources has become concerned that the hiring practices discriminate against older workers. He asks Kevin to look into the age at which new workers are hired, and Kevin decides to find the average age at hiring. He goes to the personnel office and finds out that over 2,500 different people have worked at this company in the past 15 years. In order to save time and money, Kevin decides to make an interval estimate of the mean age at date of hire. He decides that he wants to make this estimate with .95 confidence. Going into the personnel files, Kevin chooses 30 folders and records the birth date and date of hiring from each. He finds the age at hiring for each person, and computes the sample mean and standard deviation, finding x = 24.71 years and s = 2.13 years. Going to the t-table, he finds that .95 of t-scores with df=29 are between ±2.045. You can alternatively use the interactive Excel template in Figure 3.1 to find the same value for t-scores. In doing this, you can enter df=29 and choose alpha=.025. The reason you select .025 is that Kevin is constructing an interval estimate of the mean age. Therefore, the actual value of alpha to find out the correct t-score is .025=(1-.95)/2.
Figure 3.1 Interactive Excel Template for Determining the t-Values Cut-off Point – see Appendix 3.
He solves two equations:
[latex]\pm{2.045} = (24.71 - \mu)/(2.13/\sqrt{30})[/latex]
and finds that the limits to his interval are 23.91 and 25.51. Kevin tells the HR director: “With .95 confidence, the mean age at date of hire is between 23.91 years and 25.51 years.”
Estimating the population proportion
There are many times when you, or your boss, will want to estimate the proportion of a population that has a certain characteristic. The best known examples are political polls when the proportion of voters who would vote for a certain candidate is estimated. This is a little trickier than estimating a population mean. It should only be done with large samples, and adjustments should be made under various conditions. We will cover the simplest case here, assuming that the population is very large, the sample is large, and that once a member of the population is chosen to be in the sample, it is replaced so that it might be chosen again. Statisticians have found that, when all of the assumptions are met, there is a sample statistic that follows the standard normal distribution. If all of the possible samples of a certain size are chosen, and for each sample the proportion of the sample with a certain characteristic, p, is found, a z-statistic can then be computed using the formula:
[latex]z = (p-\pi)/(\sqrt{(p(1-p)/n})[/latex]
where π = proportion of population with the characteristic and will be distributed normally. Looking at the bottom line of the t-table, .90 of these z’s will be between ±1.645, .99 will be between ±2.326, etc.
Because statisticians know that the z-scores found from samples will be distributed normally, you can make an interval estimate of the proportion of the population with the characteristic. This is simple to do, and the method is parallel to that used to make an interval estimate of the population mean: (1) choose the sample, (2) find the sample p, (3) assume that your sample has a z-score that is not in the tails of the sampling distribution, (4) using the sample p as an estimate of the population π in the denominator and the table z-values for the desired level of confidence, solve twice to find the limits of the interval that you believe contains the population proportion p.
At the Delta Beer Company, the director of human resources also asked Ann Howard to look into the age at hiring at the plant. Ann takes a different approach than Kevin and decides to investigate what proportion of new hires were at least 35. She looks at the personnel records and, like Kevin, decides to make an inference from a sample after finding that over 2,500 different people have worked at this company at some time in the last 15 years. She chooses 100 personnel files, replacing each file after she has recorded the age of the person at hiring. She finds 17 who were 35 or older when they first worked at the Delta Beer Company. She decides to make her inference with .95 confidence, and from the last line of the t-table finds that .95 of z-scores lie between ±1.96. She finds her upper and lower bounds:
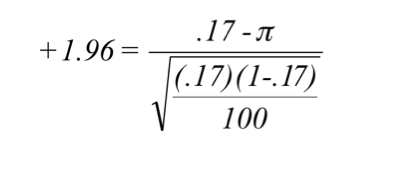
[latex]\pi = .17-(.038)(1.96) = .095[/latex]
and she finds the other boundary:
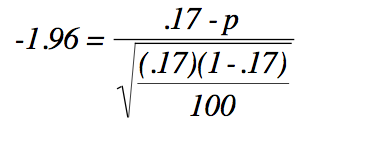
[latex]\pi = .17-(.038)(-1.96) = .245[/latex]
She concludes, that with .95 confidence, the proportion of people who have worked at Delta Beer Company who were over 35 when hired is between .095 and .245. This is a fairly wide interval. Looking at the equation for constructing the interval, you should be able to see that a larger sample size will result in a narrower interval, just as it did when estimating the population mean.
Estimating population variance
Another common interval estimation task is to estimate the variance of a population. High quality products not only need to have the proper mean dimension, the variance should be small. The estimation of population variance follows the same strategy as the other estimations. By choosing a sample and assuming that it is from the middle of the population, you can use a known sampling distribution to find a range of values that you are confident contains the population variance. Once again, we will use a sampling distribution that statisticians have discovered forms a link between samples and populations.
Take a sample of size n from a normal population with known variance, and compute a statistic called χ2 (pronounced chi square) for that sample using the following formula:
[latex]\chi^2 = (\sum{(x-\bar{x})^2})/(\sigma^2)[/latex]
You can see that χ2 will always be positive, because both the numerator and denominator will always be positive. Thinking it through a little, you can also see that as n gets larger, χ2 will generally be larger since the numerator will tend to be larger as more and more (x – x)2 are summed together. It should not be too surprising by now to find out that if all of the possible samples of a size n are taken from any normal population, χ2 is computed for each sample, and those χ2 are arranged into a relative frequency distribution, the distribution is always the same.
Because the size of the sample obviously affects χ2, there is a different distribution for each different sample size. There are other sample statistics that are distributed like χ2, so, like the t-distribution, tables of the χ2 distribution are arranged by degrees of freedom so that they can be used in any procedure where appropriate. As you might expect, in this procedure, df = n-1. A portion of a χ2 table is reproduced below in Figure 3.2. You can use the following interactive Excel template to find the cut-off point for χ2. In this template, you have a choice to enter df and select the upper tail of the distribution; the appropriate χ2 will be created along with its graph.
Figure 3.2 Interactive Excel Template for Determining the χ2 Cut-off Point – see Appendix 3.
Variance is important in quality control because you want your product to be consistently the same. The quality control manager of Delta Beer Company, Peter, has just returned from a seminar called “Quality Beer, Quality Profits”. He learned something about variance and has asked Kevin to measure the variance of the volume of the beer bottles produced by Delta. Kevin decides that he can fulfill this request by taking random samples directly from the production line. Kevin knows that the sample variance is an unbiased estimator of the population variance, but he decides to produce an interval estimate of the variance of the volume of beer bottles. He also decides that .90 confidence will be good until he finds out more about what Peter wants.
Kevin goes and finds the data for the volume of 15 randomly selected bottles of beer, and then gets ready to use the χ2 distribution to make a .90 confidence interval estimate of the variance of the volume of the beer bottles. His collected data are shown below in millilitres:
370.12, 369.25, 372.15, 370.14, 367.5, 369.54, 371.15, 369.36, 370.4, 368.95, 372.4, 370, 368.59, 369.12, 370.25
With his sample of 15 bottles, he will have 14 df Using the Excel template in Figure 3.2 above, he simply enters .05 with 14 df one time, and .975 with the same df another time in the yellow cells. He will find that .95 of χ2 are greater than 6.571 and only .05 are greater than 23.685 when there are 14 df This means that .90 are between 6.57 and 23.7. Assuming that his sample has a χ2 that is in the middle .90, Kevin gets ready to compute the limits of his interval. This time Kevin uses the Excel spreadsheet’s built-in functions to calculate variance and standard deviation of the sample data. He uses both VAR.S, and STDEV.S. to calculate both sample variance and standard deviation. He comes up with 1.66 as sample variance, and 1.29 mL as his sample standard deviation.
Kevin then takes the χ2 formula and solves it twice, once by setting χ2 equal to 6.57:
[latex]\chi^2 = 6.571 = 1.66/{\sigma_2}[/latex]
Solving for σ2, he finds one limit for his interval is .253. He solves the second time by setting χ2 equal to 23.685:
[latex]23.685 = 1.66/{\sigma_2}[/latex]
and find that the other limit is .07. Armed with his data, Kevin reports to the quality control manager that “with .90 confidence, the variance of volume of bottles of beer is between .07 and .253”.
Summary
What does this confidence stuff mean anyway? In the example we did earlier, Ann found that “with .95 confidence…” What exactly does “with .95 confidence” mean? The easiest way to understand this is to think about the assumption that Ann had made that she had a sample with a z-score that was not in the tails of the sampling distribution. More specifically, she assumed that her sample had a z-score between ±1.96; that it was in the middle 95 per cent of z-scores. Her assumption is true 95% of the time because 95% of z-scores are between ±1.96. If Ann did this same estimate, including drawing a new sample, over and over, in .95 of those repetitions, the population proportion would be within the interval because in .95 of the samples the z-score would be between ±1.96. In .95 of the repetitions, her estimate would be right.
